
Lernpfad
Grundlagen der KI
10 Std.
Grundlegende und tiefe Reinforcement Learning (RL)-Modelle ähneln oft mehr einer Science-Fiction-KI als jedes große Sprachmodell von heute. Schauen wir uns an, wie RL es diesem Agenten ermöglicht, ein sehr schwieriges Level in Super Mario zu bewältigen:

Am Anfang hat der Agent keine Ahnung, wie er dieses Spiel spielen soll. Es kennt die Steuerung nicht, weiß nicht, wie man vorankommt, welche Hindernisse es gibt und wie das Spiel endet. Der Agent muss all diese Dinge ohne menschliches Zutun lernen - mit Hilfe von Verstärkungslernalgorithmen.
RL-Agenten können Probleme ohne vordefinierte Lösungen oder explizit programmierte Aktionen und vor allem ohne große Datenmengen lösen. Deshalb hat das RL einen großen Einfluss auf viele Bereiche. Es wird zum Beispiel verwendet in:
Reinforcement Learning ist ein sich schnell entwickelndes Feld mit großem Potenzial. Wenn die Forschung weiter voranschreitet, können wir noch mehr bahnbrechende Anwendungen in Bereichen wie Ressourcenmanagement, Gesundheitswesen und personalisiertes Lernen erwarten.
Deshalb ist jetzt ein guter Zeitpunkt, um etwas über dieses faszinierende Gebiet des maschinellen Lernens zu erfahren. In diesem Tutorial helfen wir dir, die Grundlagen des Reinforcement Learning zu verstehen und erklären dir Schritt für Schritt Konzepte wie Agent, Umgebung, Aktion, Zustand, Belohnungen und mehr.
Nehmen wir an, du willst deiner Katze Bob beibringen, mehrere Kratzbäume in einem Raum zu benutzen, anstatt deine teuren Möbel. Im Sinne des Reinforcement Learning ist Bob der Agent, der Lernende und der Entscheidungsträger. Es muss lernen, welche Dinge zum Kratzen geeignet sind (Teppiche und Pfosten) und welche nicht (Sofas und Vorhänge).
Der Raum wird als die Umgebung bezeichnet, mit der unser Agent interagiert. Sie bietet Herausforderungen (verlockende Möbel) und das gewünschte Ziel (einen zufriedenstellenden Kratzbaum).
Es gibt zwei Haupttypen von Umgebungen im RL:
Unser Zimmer ist auch eine statische Umgebung. Die Möbel bewegen sich nicht und die Kratzbäume bleiben an ihrem Platz.
Wenn du aber alle paar Stunden die Möbel und Kratzbäume zufällig umstellst (wie in den verschiedenen Levels von Super Mario), wird der Raum zu einer dynamischen Umgebung, die für einen Agenten schwieriger zu erlernen ist, weil sich die Dinge ständig ändern.
Zwei wichtige Aspekte aller Verstärkungslernprobleme sind der Zustandsraum und der Aktionsraum.
Der Zustandsraum stellt alle möglichen Zustände (Situationen) dar, in denen sich der Agent und die Umwelt zu einem bestimmten Zeitpunkt befinden. Die Größe des Zustandsraums hängt von der Art der Umgebung ab:
Der Aktionsraum sind alle Dinge, die Bob in der Umgebung tun kann. In unserem Beispiel mit dem Kratzbaum könnte Bob den Kratzbaum zerkratzen, auf der Couch ein Nickerchen machen oder sogar seinen Schwanz jagen.
Ähnlich wie beim Zustandsraum hängt auch die Anzahl der Aktionen, die Bob ausführen kann, von der Umgebung ab:
Wenn Bob sein Kratzbaum-Abenteuer beginnt, befindet sich die Umgebung in einem Standardzustand, nennen wir ihn Zustand Null. In unserem Fall könnte das der Raum sein, in dem der Kratzbaum aufgestellt ist. Jede Aktion, die er unternimmt, versetzt die Umwelt in neue Folgezustände.
Damit Bob sein übergeordnetes Ziel erreichen kann, braucht er Anreize oder Belohnungen.
Die meisten RL-Probleme haben vordefinierte Belohnungen. Beim Schach zum Beispiel ist das Schlagen einer Figur eine positive Belohnung, während ein Schachspiel eine negative Belohnung ist.
In unserem Fall können wir Bob Leckerlis geben, wenn wir eine positive Handlung beobachten, z. B. wenn er eine Zeit lang nicht an den Möbeln kratzt oder wenn er tatsächlich einen der Kratzbäume findet. Wir könnten ihn auch mit ein paar Wasserspritzern im Gesicht bestrafen, wenn er die Vorhänge hochkratzt.
Um den Fortschritt von Bobs Lernreise zu messen, können wir seine Aktionen in Form von Zeitschritten betrachten. Zum Beispiel führt Bob im Zeitschritt t1 die Aktion a1 aus, die zu einem neuen Zustand s1 führt (s0 war der Standardzustand). Er kann auch eine Belohnung r1 erhalten.
Eine Sammlung von Zeitschritten wird als Episode bezeichnet. Eine Episode beginnt immer in einem Standardzustand (die Möbel und Pfosten sind aufgestellt) und endet, wenn das Ziel erreicht ist (ein Pfosten gefunden wird) oder der Agent versagt (Möbel zerkratzt). Manchmal kann eine Episode auch nach der verstrichenen Zeit enden (wie beim Schach).
Wie ein geschickter Schachspieler sollte Bob nicht einfach irgendeinen Kratzbaum suchen. Bob sollte sich diejenige aussuchen, die ihm die meisten Leckereien beschert. Dies verdeutlicht ein klassisches Dilemma beim Verstärkungslernen: Exploration vs. Exploitation.
Während ein verlockender Posten vielleicht sofortige Befriedigung bietet, könnte eine strategischere Erkundung später zu einem Jackpot führen. So wie ein Schachspieler auf einen Schlag verzichtet, um eine bessere Position zu erreichen, könnte Bob zunächst an einem suboptimalen Posten kratzen (Erkundung), um den ultimativen Kratzplatz zu entdecken (Ausbeutung). Diese langfristige Strategie ist für Agenten entscheidend, um in komplexen Umgebungen die Belohnungen zu maximieren.
Mit anderen Worten: Bob muss ein Gleichgewicht zwischen Ausbeutung (das Festhalten an dem, was am besten funktioniert) und Erkundung (gelegentliches Aufbrechen, um nach neuen Kratzbäumen zu suchen) finden. Wenn du zu viel erkundest, vergeudest du Zeit, vor allem in kontinuierlichen Umgebungen, und wenn du zu viel ausnutzt, verpasst Bob vielleicht etwas noch Besseres.
Zum Glück gibt es einige clevere Strategien, die Bob anwenden kann:
Mit diesen Strategien (oder anderen, die den Rahmen unseres Tutorials sprengen) kann Bob ein Gleichgewicht zwischen der Erkundung des Unbekannten und dem Festhalten an den guten Sachen finden.
Bob findet nicht von alleine heraus, wie er die Anzahl der Leckereien maximieren kann. Sie braucht einige Methoden und Werkzeuge, um ihre Entscheidungen in jedem Zustand der Umwelt zu treffen. Hier kommen die Algorithmen des Reinforcement Learning zu Bobs Rettung.
Aus einer breiteren Perspektive lassen sich die Algorithmen des Verstärkungslernens danach kategorisieren, wie sie Agenten mit der Umwelt interagieren und aus Erfahrungen lernen lassen. Die beiden Hauptkategorien von Verstärkungslernalgorithmen sind modellbasierte und modellfreie Algorithmen.
Bei modellbasierten Algorithmen baut der Agent (wie Bob) ein internes Modell der Umgebung auf. Dieses Modell stellt die Dynamik der Umwelt dar, einschließlich der Zustandsübergänge und Belohnungswahrscheinlichkeiten. Der Agent kann dieses Modell dann nutzen, um verschiedene Aktionen zu planen und zu bewerten, bevor er sie in der realen Umgebung ausführt.
Dieser Ansatz hat den Vorteil, dass er vor allem in komplexen Umgebungen stichprobeneffizienter ist. Das bedeutet, dass Bob möglicherweise weniger Kratzversuche braucht, um den optimalen Pfosten zu finden, als bei reinen Trial-and-Error-Ansätzen. Das liegt daran, dass Bob planen und abwägen kann, bevor er aktiv wird.
Der Nachteil ist, dass die Erstellung eines genauen Modells eine Herausforderung sein kann, insbesondere bei komplexen Umgebungen. Das Modell kann die reale Umgebung nicht genau widerspiegeln, was zu suboptimalem Verhalten führt.
Ein gängiger modellbasierter RL-Algorithmus ist Dyna-Q, der modellbasiertes und modellfreies Lernen kombiniert. Es konstruiert ein Modell der Umgebung und nutzt es für die Handlungsplanung, während es gleichzeitig durch modellfreies Q-Learning (das wir gleich erklären werden) direkt aus der Erfahrung lernt.
Dieser Ansatz konzentriert sich darauf, direkt aus der Interaktion mit der Umwelt zu lernen, ohne explizit ein internes Modell aufzubauen. Der Agent (Bob) lernt den Wert von Zuständen und Aktionen oder die optimale Strategie durch Versuch und Irrtum.
Modellfreies RL bietet einen einfacheren Ansatz in Umgebungen, in denen die Erstellung eines genauen Modells schwierig ist. Für Bob bedeutet das, dass er keine komplexe mentale Karte des Raums erstellen muss - er kann durch Kratzen und das Erleben der Konsequenzen lernen.
Modellfreies RL eignet sich hervorragend für dynamische Umgebungen, in denen sich die Regeln ändern können. Wenn sich die Einrichtung des Zimmers ändert, kann Bob seine Erkundungstour anpassen und die neuen optimalen Kratzplätze lernen.
Aber nur durch Versuch und Irrtum zu lernen, kann weniger stichhaltig sein. Bob muss vielleicht viele Möbel ankratzen, bevor er den lohnendsten Posten findet.
Einige gängige modellfreie RL-Algorithmen sind:
Welchen Algorithmus wir wählen sollten, hängt von verschiedenen Faktoren ab: von der Komplexität der Umgebung, der Verfügbarkeit von Ressourcen oder dem gewünschten Grad der Interpretierbarkeit.
Für einfachere Umgebungen, in denen die Erstellung eines genauen Modells möglich ist, könnten modellbasierte Ansätze besser geeignet sein. Andererseits sind modellfreie Ansätze für komplexe, reale Szenarien oft praktischer.
Mit dem Aufkommen des Deep Learning werden Deep Q-Networks (DQN) und andere Deep-RL-Algorithmen immer beliebter, um komplexe Aufgaben mit hochdimensionalen Zustandsräumen zu bewältigen.
Konzentrieren wir uns jetzt auf einen einzelnen Algorithmus und lernen wir mehr über Q-Learning.
Q-Learning ist ein modellfreier Algorithmus, der Agenten durch intelligente Interaktionen mit der Umwelt die optimale Gewinnstrategie beibringt.
Kehren wir zu unserem Katzenbeispiel zurück und stellen uns vor, wir lösen eine Arcade-Version des Problems mit einer diskreten Umgebung und einer endlichen Anzahl von Aktionen.
Nehmen wir an, wir geben Bob eine Tabelle. Die Spalten stellen die verfügbaren Aktionen dar, während jede Zeile die Aktion einem bestimmten Zustand aus dem Zustandsraum zuordnet.
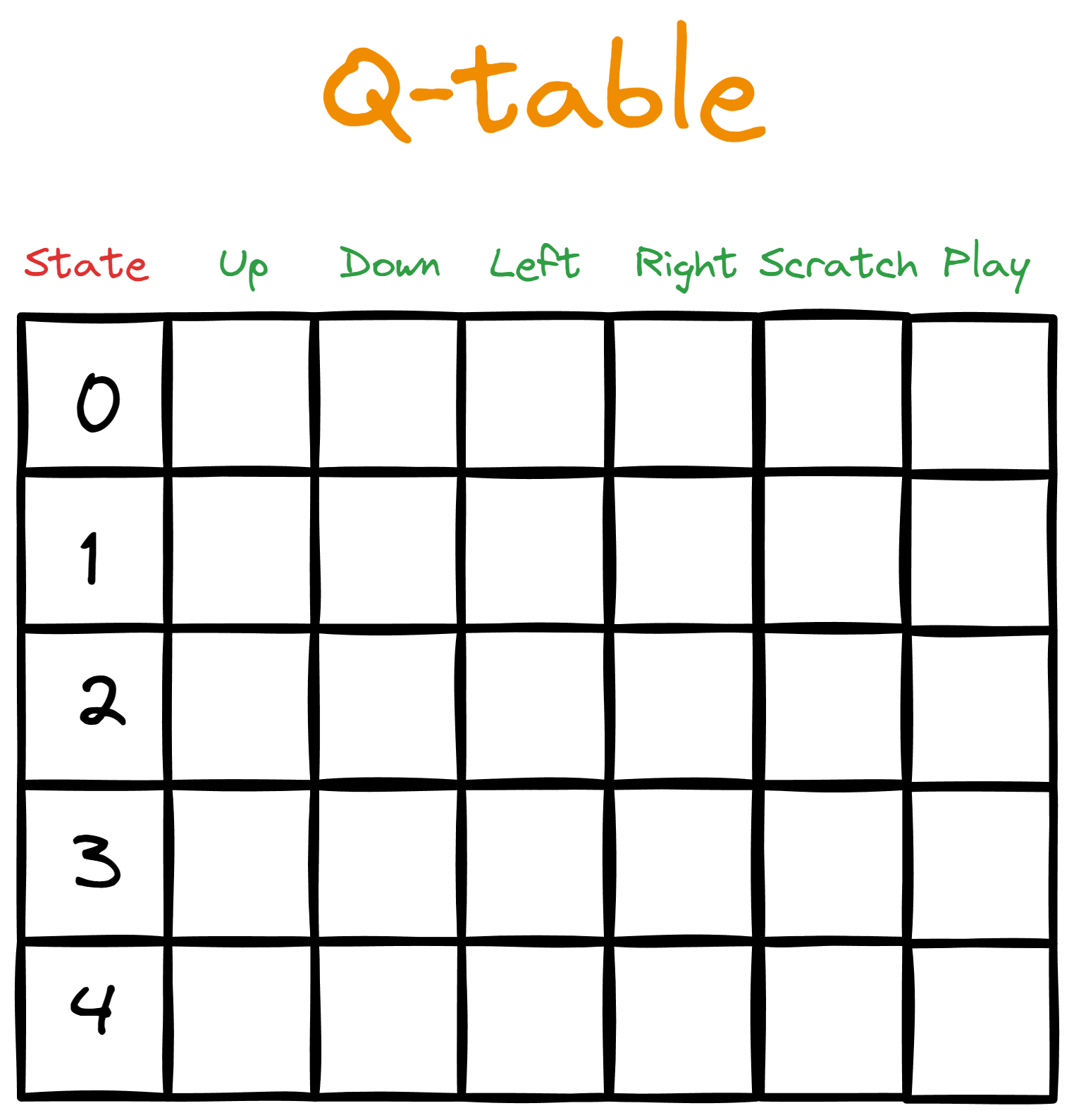
Zunächst füllen wir die Tabelle mit Nullen, die die anfänglichen Q-Wertedarstellen -deshalb nennen wir sie Q-Tabelle.
Dann starten wir eine Interaktionsschleife vom Standardzustand aus (dem Beginn einer Episode). In der Schleife nimmt Bob die Aktion mit dem höchsten Q-Wert für den gegebenen Zustand. Beim ersten Durchlauf durch die Schleife gibt es jedoch keinen höchsten Q-Wert, an dem sich Bobs Handeln orientieren kann, da alle Q-Werte anfangs null sind.
Hier kommen Erkundungsstrategien (wie zufällige Erkundung oder Epsilon-Greedy) ins Spiel. Diese Strategien helfen Bob, Informationen zu sammeln, wenn die Q-Tabelle leer ist.
Sobald die Q-Tabelle aktualisiert wurde, startet Bob erneut eine Interaktionsschleife. Die Aktion, die er ausführt, führt zu einer Belohnung und einem neuen Zustand. Dann berechnen wir neue Q-Werte für jede Aktion, die Bob in dem neuen Zustand ausführen kann (wir werden gleich zeigen, wie man Q-Werte berechnet).
Die Episode geht weiter, bis sie beendet wird (Bob kann in jeder Episode beliebig viele Schritte machen), und dann fangen wir wieder an. Jede weitere Folge wird eine reichhaltigere Q-Tabelle haben, die Bob schlauer macht.
Hier findest du einen Überblick über die einzelnen Schritte:
Die Schritte eins und zwei sind vielleicht ganz einfach, aber die anderen brauchen mehr Erklärung.
In Zeitschritt 1, wenn Bob seine erste Aktion durchführt, ist diese zufällig, da alle Q-Werte Null sind. In den folgenden Zeitschritten muss Bob das Gleichgewicht zwischen Erkundung und Ausbeutung berücksichtigen.
Um das zu erleichtern, geben wir Bob einen Hyperparameter namens epsilon mit einem kleinen Wert - normalerweise 0,1. Dann sagen wir Bob, dass er eine Zufallszahl zwischen 0 und 1 generieren soll. Wenn die Zahl kleiner als epsilon ist, wählt er eine zufällige Aktion, unabhängig von ihrem Q-Wert.
Wenn er höher als Epsilon ist, wählt Bob die Aktion mit dem höchsten Q-Wert. Auf diese Weise wird Bob epsilon (0,1 oder 10%) der Zeit erkunden und (1 - epsilon oder 0,9 oder 90%) der Zeit ausbeuten.
Was wir gerade beschrieben haben, nennt man die Epsilon-gierige Politik. Die Richtlinien legen fest, wie der Agent handelt und wie die Q-Werte berechnet werden.
Die Regeln für die Berechnung der Belohnung werden normalerweise von der Person festgelegt, die die Umgebung schafft. Du könntest zum Beispiel beschließen, Bob ein einziges Leckerli zu geben, wenn er einen Kratzteppich benutzt, und fünf Leckerlis, wenn er hoch genug springt, um den Teppich an der Wand zu kratzen. Es besteht auch die Möglichkeit, dass du Bob dafür bestrafst, dass er wertvolle Gegenstände zerkratzt.
Aber die meiste Zeit wird es keine Belohnung geben, denn Bob wird entweder schlafen, laufen oder spielen.
Die Formel zur Berechnung des Q-Werts kann einschüchternd sein, also sehen wir sie uns zuerst in voller Länge an und erklären sie dann Schritt für Schritt:

Schauen wir uns den Anfang der Formel an:
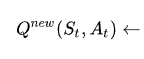
Hier heißt es: "Ausgehend vom vorherigen Zustand und der Aktion wird der neue Q-Wert berechnet als (...)".
Der Teil darunter ist der aktuelle (bald alte) Q-Wert, mit dem der Agent die Aktion durchgeführt hat.
![]()
Betrachten wir nun den letzten Teil:
![]()
St+1 ist der neue Zustand, der sich aus der AktionAt ergibt. In diesem Teil geht es also darum, den größten Q-Wert aus allen Aktionen (a) in diesem neuen Zustand zu finden. Wir multiplizieren diesen Wert mit einem Parameter γ, der Gamma (Diskontierungsfaktor) genannt wird, und addieren das Ergebnis zu der erhaltenen Belohnung.
Wenn wir Gamma nahe an 1 setzen, legen wir mehr Gewicht auf zukünftige Belohnungen. Wenn wir ihn gegen Null senken, betonen wir die aktuelle Belohnung Rt+1 stärker. Das bedeutet, dass Gamma ein weiterer Parameter ist, mit dem wir ein Gleichgewicht zwischen Erkundung und Ausbeutung herstellen können.
Schließlich haben wir Alpha (α), das die Trainingsgeschwindigkeit steuert und zwischen 0 und 1 liegt. Werte nahe bei 1 führen dazu, dass die Aktualisierungen der Q-Werte größer werden, so dass der Agent schneller lernt und die rechte Seite des Pluszeichens größer wird. Im Gegensatz dazu wird bei Werten nahe 0 die linke Seite schwerer, die den aktuellen Q-Wert enthält.
Mit der Lernrate wird die Trainingsgeschwindigkeit gesteuert, damit der Agent nicht zu schnell Fortschritte macht und alte Informationen vergisst. Es stellt auch sicher, dass es nicht sehr langsam lernt und möglicherweise wichtige Informationen verpasst.
Das ist der schwierigste Teil, um Q-Learning zu verstehen, und ich hoffe, du hast ein ungefähres Gefühl dafür bekommen, wie es funktioniert.
Wie für alles andere gibt es auch für Python Frameworks zum Lösen von Reinforcement Learning-Problemen. Das beliebteste ist Gymnasium, das mit über 2000 Umgebungen (die alle ausführlich dokumentiert sind) vorkonfiguriert ist.
$ pip install "gymnasium[atari]"
$ pip install autorom[accept-rom-license]
$ AutoROM --accept-license
import gymnasium as gym
env = gym.make("ALE/Breakout-v5")Die Umgebung, die wir gerade geladen haben, heißt Breakout. So sieht es aus:

Das Ziel ist es, dass das Brett (der Agent) durch Ausprobieren lernt, wie man alle Steine beseitigt. Die Regeln des Spiels bestimmen die Strafen und Belohnungen.
Am Ende des Artikels zeigen wir dir, wie du deine eigenen Interaktions-Episoden laufen lassen und den Fortschritt des Agenten mit einem GIF wie dem oben abgebildeten visualisieren kannst.
Hier ist der Code für die Interaktionsschleife:
epochs = 0
frames = [] # for animation
done = False
env = gym.make("ALE/Breakout-v5", render_mode="rgb_array")
observation, info = env.reset()
while not done:
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
# Put each rendered frame into dict for animation
frames.append(
{
"frame": env.render(),
"state": observation,
"action": action,
"reward": reward,
}
)
epochs += 1
if epochs == 1000:
breakWir haben gerade tausend Zeitschritte ausgeführt, oder anders gesagt, der Agent hat 1000 Aktionen durchgeführt. All diese Aktionen sind jedoch rein zufällig - es geht nicht darum, aus vergangenen Fehlern zu lernen. Um dies zu überprüfen, können wir die Variable frames verwenden, um ein GIF zu erstellen:
from moviepy.editor import ImageSequenceClip
# !pip install moviepy - if you don’t have moviepy
def create_gif(frames: dict, filename, fps=100):
"""
Creates a GIF animation from a list of RGBA NumPy arrays.
Args:
frames: A list of RGBA NumPy arrays representing the animation frames.
filename: The output filename for the GIF animation.
fps: The frames per second of the animation (default: 10).
"""
rgba_frames = [frame["frame"] for frame in frames]
clip = ImageSequenceClip(rgba_frames, fps=fps)
clip.write_gif(filename, fps=fps)
# Example usage
create_gif(frames, "animation.gif") #saves the GIF locally
Hinweis: Wenn du auf einen "RuntimeError: Fehler "No ffmpeg exe could be found", versuche die folgenden zwei Codezeilen hinzuzufügen, bevor du moviepy importierst:
from moviepy.config import change_settings
change_settings({"FFMPEG_BINARY": "/usr/bin/ffmpeg"})Unser erstes Snippet hat den Zustand der Umgebung als RGBA-Arrays für jeden Zeitschritt zurückgegeben, und sie werden in Frames gespeichert. Wenn wir alle Bilder mit der moviepy-Bibliothek zusammenfügen, können wir das GIF erstellen, das du vorhin gesehen hast:

Nebenbei bemerkt, kannst du den fps-Parameter anpassen, um das GIF schneller zu machen, wenn du viele Zeitschritte ausführst.
Jetzt, wo wir sehen, dass der Agent einfach nur zufällige Aktionen ausführt, ist es an der Zeit, einige Algorithmen auszuprobieren. In diesem Kurs über Reinforcement Learning mit Gymnasium in Python kannst du das Schritt für Schritt tun und viele Algorithmen wie Q-Learning, SARSA und andere kennenlernen.
Verwende die Funktion, die wir gerade erstellt haben, um den Fortschritt deiner Agenten zu animieren, und viel Spaß!
Verstärkungslernen ist eines der faszinierendsten Gebiete der Informatik und des maschinellen Lernens. In diesem Tutorium haben wir die grundlegenden Konzepte von RL kennengelernt - von Agenten und Umgebungen bis hin zu modellfreien Algorithmen wie Q-Learning.
Die Entwicklung von Weltklasse-Agenten, die komplexe Probleme wie Schach oder Videospiele lösen können, braucht jedoch Zeit und Übung. Hier sind also einige Ressourcen, die dir auf deinem Weg helfen können:
Danke fürs Lesen!
Erfahre mehr über KI und Reinforcement Learning!
Lernpfad
Kurs
Kurs