Programa
Fundamentos da IA
10 h
Os modelos básicos e profundos de aprendizado por reforço (RL) podem se assemelhar mais à IA de ficção científica do que a qualquer modelo de linguagem grande atualmente. Vamos dar uma olhada em como a RL permite que esse agente conclua um nível muito difícil em Super Mario:

No início, o agente não tem ideia de como jogar esse jogo. Ele não conhece os controles, como progredir, quais são os obstáculos ou o que finaliza o jogo. O agente deve aprender todas essas coisas sem nenhuma intervenção humana - tudo por meio do poder dos algoritmos de aprendizagem por reforço.
Os agentes de RL podem resolver problemas sem soluções predefinidas ou ações explicitamente programadas e, o que é mais importante, sem grandes quantidades de dados. É por isso que a RL está tendo um impacto significativo em muitos campos. Por exemplo, ele é usado em:
O aprendizado por reforço é um campo em rápida evolução com grande potencial. Com o avanço das pesquisas, podemos esperar aplicações ainda mais inovadoras em áreas como gerenciamento de recursos, saúde e aprendizado personalizado.
É por isso que agora é um ótimo momento para você aprender sobre esse fascinante campo do machine learning. Neste tutorial, ajudaremos você a entender os fundamentos da aprendizagem por reforço e explicaremos passo a passo conceitos como agente, ambiente, ação, estado, recompensas e muito mais.
Digamos que você queira ensinar seu gato, Bob, a usar vários postes para arranhar em um cômodo, em vez dos móveis caros. Em termos de aprendizado por reforço, Bob é o agente, o aluno e o tomador de decisões. Ele precisa aprender quais coisas podem ser arranhadas (tapetes e postes) e quais não podem (sofás e cortinas).
A sala é chamada de ambiente com o qual nosso agente interage. Ele oferece desafios (móveis tentadores) e o objetivo desejado (um poste de arranhar satisfatório).
Há dois tipos principais de ambientes na RL:
Nossa sala também é um ambiente estático. Os móveis não se movem e os postes para arranhar ficam no lugar.
Mas se você mover aleatoriamente a mobília e os postes de arranhar uma vez a cada poucas horas (como diferentes níveis do jogo Super Mario), a sala se tornaria um ambiente dinâmico, o que é mais complicado para um agente aprender, pois as coisas estão sempre mudando.
Dois aspectos importantes de todos os problemas de aprendizado por reforço são o espaço de estado e o espaço de ação.
O espaço de estado representa todos os estados (situações) possíveis em que o agente e o ambiente se encontram em um determinado momento. O tamanho do espaço de estado depende do tipo de ambiente:
O espaço de ação é tudo o que Bob pode fazer no ambiente. Em nosso exemplo do poste para coçar, as ações de Bob poderiam ser coçar o poste, cochilar no sofá ou até mesmo correr atrás da cauda.
Da mesma forma que o espaço de estado, o número de ações que Bob pode realizar depende do ambiente:
Quando Bob inicia sua aventura com o poste para coçar, o ambiente está em um estado padrão, vamos chamá-lo de estado zero. No nosso caso, esse pode ser o cômodo com o poste para arranhar. Cada ação que ele realiza move o ambiente para novos estados subsequentes.
Para que o Bob atinja seu objetivo geral, ele precisa de incentivos ou recompensas.
A maioria dos problemas de RL tem recompensas predefinidas. Por exemplo, no xadrez, capturar uma peça é uma recompensa positiva, enquanto receber um cheque é uma recompensa negativa.
No nosso caso, podemos dar petiscos ao Bob se observarmos uma ação positiva, como não arranhar os móveis por algum tempo ou se ele realmente encontrar um dos postes de arranhar. Também podemos puni-lo com alguns esguichos de água no rosto se ele arranhar as cortinas.
Para medir o progresso da jornada de aprendizagem de Bob, podemos pensar em suas ações em termos de etapas de tempo. Por exemplo, na etapa de tempo t1, Bob executa a ação a1, que resulta em um novo estado s1 (s0 era o estado padrão). Ele também pode receber uma recompensa r1.
Um conjunto de etapas de tempo é chamado de episódio. Um episódio sempre começa em um estado padrão (a mobília e os postes estão instalados) e termina quando o objetivo é alcançado (um poste é encontrado) ou o agente falha (arranha a mobília). Às vezes, um episódio também pode terminar com base no tempo decorrido (como no xadrez).
Assim como um jogador de xadrez habilidoso, Bob não deve procurar qualquer poste para arranhar. O Bob deve escolher aquele que lhe dê mais recompensas. Isso destaca um dilema clássico no aprendizado por reforço: exploração versus aproveitamento.
Embora uma postagem tentadora possa oferecer gratificação imediata, uma exploração mais estratégica pode levar a uma recompensa mais tarde. Assim como um jogador de xadrez pode renunciar a uma captura para obter uma posição superior, Bob pode inicialmente arranhar um poste abaixo do ideal (exploração) para descobrir o melhor paraíso para arranhar (exploração). Essa estratégia de longo prazo é fundamental para que os agentes maximizem as recompensas em ambientes complexos.
Em outras palavras, Bob deve equilibrar a exploração (manter-se fiel ao que funciona melhor) com a exploração (aventurar-se ocasionalmente em busca de novos pontos de arranhadura). Explorar demais pode desperdiçar tempo, especialmente em ambientes contínuos, enquanto explorar demais pode fazer com que Bob perca algo ainda melhor.
Felizmente, existem algumas estratégias inteligentes que Bob pode adotar:
Ao usar essas estratégias (ou outras que estão além do escopo do nosso tutorial), Bob pode encontrar um equilíbrio entre explorar o desconhecido e se ater ao que é bom.
O Bob não consegue descobrir como maximizar o número de guloseimas sozinho. Ele precisa de alguns métodos e ferramentas para orientar suas decisões em cada estado do ambiente. É nesse ponto que os algoritmos de aprendizagem por reforço vêm em socorro de Bob.
De uma perspectiva mais ampla, os algoritmos de aprendizagem por reforço podem ser categorizados com base em como eles fazem os agentes interagirem com o ambiente e aprenderem com a experiência. As duas principais categorias de algoritmos de aprendizado por reforço são baseadas em modelos e livres de modelos.
Nos algoritmos baseados em modelos, o agente (como Bob) cria um modelo interno do ambiente. Esse modelo representa a dinâmica do ambiente, incluindo transições de estado e probabilidades de recompensa. O agente pode então usar esse modelo para planejar e avaliar diferentes ações antes de executá-las no ambiente real.
Essa abordagem tem a vantagem de ser mais eficiente em termos de amostragem, especialmente em ambientes complexos. Isso significa que Bob pode precisar de menos tentativas de raspagem para identificar o posto ideal em comparação com abordagens puramente de tentativa e erro. E isso porque Bob pode planejar e avaliar antes de agir.
A desvantagem é que a criação de um modelo preciso pode ser um desafio, especialmente para ambientes complexos. O modelo pode não refletir com precisão o ambiente real, levando a um comportamento abaixo do ideal.
Um algoritmo comum de RL baseado em modelos é o Dyna-Q, que na verdade combina aprendizado baseado em modelos e aprendizado sem modelos. Ele constrói um modelo do ambiente e o utiliza para o planejamento de ações e, ao mesmo tempo, aprende diretamente com a experiência por meio do Q-learning sem modelo (que explicaremos em breve).
Essa abordagem se concentra em aprender diretamente da interação com o ambiente sem criar explicitamente um modelo interno. O agente (Bob) aprende o valor dos estados e das ações ou a estratégia ideal por meio de tentativa e erro.
A RL sem modelo oferece uma abordagem mais simples em ambientes em que a criação de um modelo preciso é um desafio. Para Bob, isso significa que ele não precisa criar um mapa mental complexo da sala - ele pode aprender arranhando e experimentando as consequências.
A RL sem modelos é excelente em ambientes dinâmicos em que as regras podem mudar. Se a disposição dos móveis do cômodo mudar, Bob poderá adaptar sua exploração e aprender os novos pontos ideais para arranhar.
No entanto, somente o aprendizado por tentativa e erro pode ser menos eficiente em termos de amostragem. Talvez você precise arranhar muitos móveis antes de encontrar o posto mais gratificante.
Alguns algoritmos comuns de RL sem modelo incluem:
O algoritmo que devemos escolher depende de vários fatores: a complexidade do ambiente, a disponibilidade de recursos ou o nível desejado de interpretabilidade.
As abordagens baseadas em modelos podem ser preferíveis para ambientes mais simples, nos quais a criação de um modelo preciso é viável. Por outro lado, as abordagens sem modelos costumam ser mais práticas para cenários complexos do mundo real.
Além disso, com o aumento da aprendizagem profunda, as redes Q profundas (DQN) e outros algoritmos de RL profunda estão se tornando cada vez mais populares para lidar com tarefas complexas com espaços de estado de alta dimensão.
Agora vamos nos concentrar em um único algoritmo e aprender mais sobre o Q-learning.
O Q-learning é um algoritmo sem modelos que ensina aos agentes a estratégia vencedora ideal por meio de interações inteligentes com o ambiente.
Voltemos ao nosso exemplo do gato e imaginemos que estamos resolvendo uma versão arcade do problema com um ambiente discreto e um conjunto finito de ações.
Digamos que você dê a Bob uma tabela. As colunas representam as ações disponíveis, enquanto cada linha mapeia a ação para um estado específico do espaço de estado.
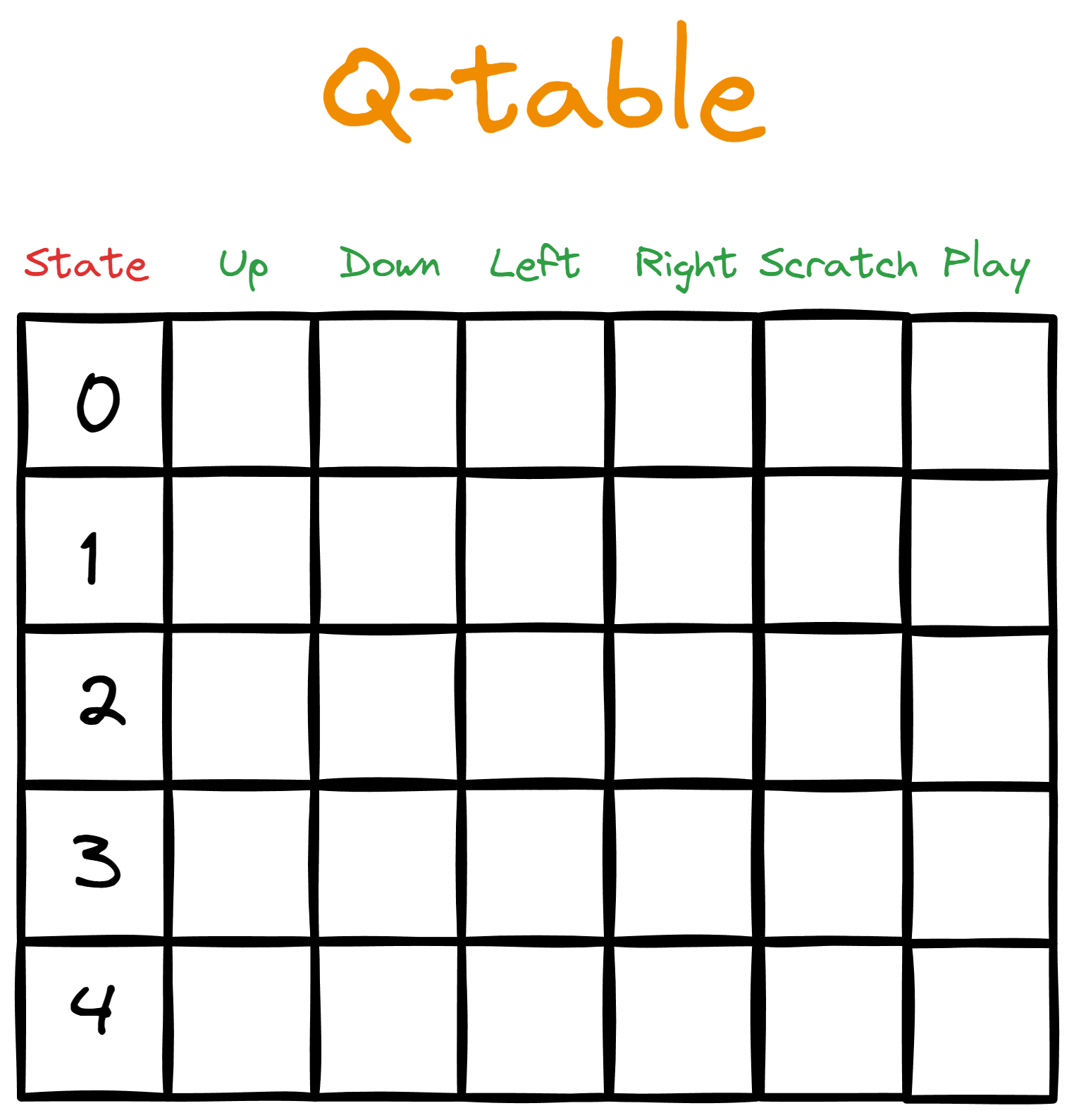
Inicialmente, preenchemos a tabela com zeros, representando os valores Qiniciais - poresse motivo, chamamos isso de tabela Q.
Em seguida, iniciamos um loop de interação a partir do estado padrão (o início de um episódio). No loop, Bob executa a ação com o valor Q mais alto para o estado em questão. Entretanto, na primeira passagem pelo loop, não haverá nenhum valor Q mais alto para orientar a ação de Bob, pois todos os valores Q são inicialmente zero.
É nesse ponto que as estratégias de exploração (como exploração aleatória ou epsilon-greedy) entram em ação. Essas estratégias ajudam Bob a coletar informações quando a tabela Q está vazia.
Quando a tabela Q tiver sido atualizada, Bob iniciará um loop de interação novamente. A ação que ele executa resulta em uma recompensa e em um novo estado. Em seguida, calculamos novos valores Q para cada ação que Bob pode realizar no novo estado (mostraremos daqui a pouco como calcular os valores Q).
O episódio continua até o término (Bob pode realizar qualquer número de etapas em cada episódio) e, em seguida, começamos novamente. A cada episódio subsequente, você terá uma tabela Q mais rica, tornando Bob mais inteligente.
Aqui está uma visão geral de alto nível das etapas envolvidas:
Etapas como a primeira e a segunda podem ser simples, mas as demais precisam de mais explicações.
Na etapa de tempo 1, quando Bob realizar sua primeira ação, ela será aleatória, pois todos os valores Q são zero. Nas etapas de tempo subsequentes, Bob precisa considerar o equilíbrio entre exploração e aproveitamento.
Para ajudar nisso, damos a Bob um hiperparâmetro chamado epsilon com um valor pequeno, normalmente 0,1. Em seguida, dizemos a Bob para gerar um número aleatório entre 0 e 1 e, se o número for menor que epsilon, ele escolherá uma ação aleatória independentemente do valor Q.
Se for maior que epsilon, Bob escolherá a ação com o valor Q mais alto. Dessa forma, Bob estará explorando epsilon (0,1 ou 10%) do tempo e explorando (1 - epsilon ou 0,9 ou 90%) do tempo.
O que acabamos de descrever é chamado de política epsilon-greedy. As políticas definem como o agente age e como os valores Q são calculados.
As regras para calcular a recompensa geralmente são definidas pela pessoa que cria o ambiente. Por exemplo, você pode decidir dar ao Bob um único petisco por usar um tapete de arranhar e cinco petiscos por pular alto o suficiente para arranhar o tapete na parede. Há também a possibilidade de você castigar o Bob por arranhar objetos valiosos.
Mas, na maioria das vezes, não haverá recompensa, pois Bob dormirá, caminhará ou brincará.
A fórmula para calcular o valor Q pode ser intimidadora, portanto, vamos vê-la primeiro em sua totalidade e depois explicá-la passo a passo:

Vamos considerar o início da fórmula:
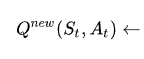
Essa parte diz: "Dado o estado e a ação anteriores, o novo valor Q é calculado como (...)."
A parte abaixo é o valor Q atual (que em breve será antigo) que o agente usou para realizar a ação.
![]()
Agora vamos considerar a parte final:
![]()
St+1 é o novo estado resultante da açãoAt. Portanto, essa parte é encontrar o maior valor Q de todas as ações (a) nesse novo estado. Multiplicamos esse valor por um parâmetro γ chamado gama (fator de desconto) e adicionamos o resultado à recompensa recebida.
Se definirmos gama próximo a 1, daremos mais importância às recompensas futuras. Se reduzirmos para zero, enfatizamos mais a recompensa atual Rt+1. Isso significa que a gama é outro parâmetro que podemos usar para equilibrar a exploração e o aproveitamento.
Por fim, temos o alfa (α), que controla a velocidade de treinamento e varia de 0 a 1. Valores próximos a 1 tornam as atualizações dos valores Q maiores, de modo que o agente aprende mais rapidamente, tornando o lado direito do sinal de mais mais pesado. Por outro lado, valores próximos a 0 tornam o lado esquerdo mais pesado, que contém o valor Q atual.
O uso da taxa de aprendizagem para controlar a velocidade do treinamento garante que o agente não progrida muito rapidamente e esqueça informações antigas. Isso também garante que ele não aprenda muito lentamente, podendo perder informações importantes.
Essa é a parte mais desafiadora do entendimento do Q-learning, e espero que você tenha tido uma ideia aproximada de como ele funciona.
Como em tudo, o Python tem estruturas para resolver problemas de aprendizado por reforço. O mais popular é o Gymnasium, que vem pré-construído com mais de 2.000 ambientes (todos documentados minuciosamente).
$ pip install "gymnasium[atari]"
$ pip install autorom[accept-rom-license]
$ AutoROM --accept-license
import gymnasium as gym
env = gym.make("ALE/Breakout-v5")O ambiente que acabamos de carregar chama-se Breakout. Aqui está o que você vê:

O objetivo aqui é que o conselho (o agente) aprenda a eliminar todos os tijolos por tentativa e erro. As regras do jogo determinam as penalidades e recompensas.
Concluiremos o artigo mostrando como você pode executar seus próprios episódios de interação e visualizar o progresso do agente com um GIF como o mostrado acima.
Aqui está o código do loop de interação:
epochs = 0
frames = [] # for animation
done = False
env = gym.make("ALE/Breakout-v5", render_mode="rgb_array")
observation, info = env.reset()
while not done:
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
# Put each rendered frame into dict for animation
frames.append(
{
"frame": env.render(),
"state": observation,
"action": action,
"reward": reward,
}
)
epochs += 1
if epochs == 1000:
breakAcabamos de executar mil etapas de tempo ou, em outras palavras, o agente executou 1.000 ações. No entanto, todas essas ações são puramente aleatórias - você não está aprendendo com os erros do passado. Para verificar isso, podemos usar a variável frames para criar um GIF:
from moviepy.editor import ImageSequenceClip
# !pip install moviepy - if you don’t have moviepy
def create_gif(frames: dict, filename, fps=100):
"""
Creates a GIF animation from a list of RGBA NumPy arrays.
Args:
frames: A list of RGBA NumPy arrays representing the animation frames.
filename: The output filename for the GIF animation.
fps: The frames per second of the animation (default: 10).
"""
rgba_frames = [frame["frame"] for frame in frames]
clip = ImageSequenceClip(rgba_frames, fps=fps)
clip.write_gif(filename, fps=fps)
# Example usage
create_gif(frames, "animation.gif") #saves the GIF locally
Observação: Se você se deparar com o erro "RuntimeError: No ffmpeg exe could be found", tente adicionar as duas linhas de código a seguir antes de importar moviepy:
from moviepy.config import change_settings
change_settings({"FFMPEG_BINARY": "/usr/bin/ffmpeg"})Nosso primeiro snippet retornou o estado do ambiente como matrizes RGBA para cada etapa de tempo, e elas são armazenadas em quadros. Ao juntar todos os quadros usando a biblioteca moviepy, podemos criar o GIF que você viu anteriormente:

Como observação adicional, você pode ajustar o parâmetro fps para tornar o GIF mais rápido se executar muitas etapas de tempo.
Agora que vemos que o agente está simplesmente executando ações aleatórias, é hora de experimentar alguns algoritmos. Você pode fazer isso passo a passo neste curso sobre Reinforcement Learning with Gymnasium in Python, no qual você explorará muitos algoritmos, incluindo Q-learning, SARSA e outros.
Não deixe de usar a função que acabamos de criar para animar o progresso de seus agentes e divirta-se!
O aprendizado por reforço é um dos aspectos mais intrigantes da ciência da computação e do machine learning. Neste tutorial, aprendemos os conceitos fundamentais da RL, desde agentes e ambientes até algoritmos sem modelos, como o Q-learning.
No entanto, a criação de agentes de classe mundial que possam resolver problemas complexos, como xadrez ou videogames, exigirá tempo e prática. Então, aqui estão alguns recursos que podem ajudar você no caminho:
Obrigado a você por ler!
Saiba mais sobre IA e aprendizado por reforço!
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Avinash Navlani
Tutorial
Théo Vanderheyden
