
Cursus
Principes fondamentaux de l'IA
10 h
Les modèles d'apprentissage par renforcement (RL) simples et profonds peuvent souvent ressembler davantage à des IA de science-fiction qu'à n'importe quel grand modèle de langage actuel. Voyons comment RL permet à cet agent de terminer un niveau très difficile dans Super Mario :

Au début, l'agent ne sait pas du tout comment jouer à ce jeu. Il ne connaît pas les commandes, ne sait pas comment progresser, ne connaît pas les obstacles et ne sait pas comment se termine le jeu. L'agent doit apprendre tout cela sans aucune intervention humaine, grâce à la puissance des algorithmes d'apprentissage par renforcement.
Les agents RL peuvent résoudre des problèmes sans solutions prédéfinies ou actions explicitement programmées et, surtout, sans grandes quantités de données. C'est pourquoi la LR a un impact significatif dans de nombreux domaines. Par exemple, il est utilisé dans :
L'apprentissage par renforcement est un domaine qui évolue rapidement et dont le potentiel est immense. Au fur et à mesure que la recherche progresse, nous pouvons nous attendre à des applications encore plus innovantes dans des domaines tels que la gestion des ressources, les soins de santé et l'apprentissage personnalisé.
C'est pourquoi le moment est idéal pour se familiariser avec ce domaine fascinant qu'est l'apprentissage automatique. Dans ce tutoriel, nous vous aiderons à comprendre les principes fondamentaux de l'apprentissage par renforcement et expliquerons étape par étape des concepts tels que l'agent, l'environnement, l'action, l'état, les récompenses, etc.
Supposons que vous souhaitiez apprendre à votre chat, Bob, à utiliser plusieurs griffoirs dans une pièce au lieu de vos meubles coûteux. En termes d'apprentissage par renforcement, Bob est l'agent, l'apprenant et le décideur. Il doit apprendre quelles sont les choses qu'il peut gratter (tapis et poteaux) et celles qui ne le sont pas (canapés et rideaux).
La pièce est appelée l'environnement avec lequel notre agent interagit. Il propose des défis (des meubles tentants) et l'objectif souhaité (un griffoir satisfaisant).
Il existe deux principaux types d'environnements dans le domaine de la réalité virtuelle :
Notre chambre est également un environnement statique. Les meubles ne bougent pas et les griffoirs restent en place.
Mais si vous déplacez les meubles et les griffoirs de manière aléatoire toutes les quelques heures (comme dans les différents niveaux du jeu Super Mario), la pièce devient un environnement dynamique, ce qui est plus difficile à apprendre pour un agent car les choses changent constamment.
L'espace d'état et l'espace d'action sont deux aspects importants de tous les problèmes d'apprentissage par renforcement.
L'espace d'état représente tous les états (situations) possibles dans lesquels l'agent et l'environnement se trouvent à un moment donné. La taille de l'espace d'état dépend du type d'environnement :
L'espace d'action correspond à toutes les choses que Bob peut faire dans l'environnement. Dans notre exemple du poteau à gratter, les actions de Bob peuvent être de gratter le poteau, de faire la sieste sur le canapé ou même de courir après sa queue.
Comme pour l'espace d'état, le nombre d'actions que Bob peut entreprendre dépend de l'environnement :
Lorsque Bob commence son aventure avec le grattoir, l'environnement est dans un état par défaut, que nous appellerons l'état zéro. Dans notre cas, il s'agit de la pièce où se trouve le griffoir. Chaque action qu'il entreprend fait évoluer l'environnement vers de nouveaux états ultérieurs.
Pour que Bob atteigne son objectif global, il a besoin d'incitations ou de récompenses.
La plupart des problèmes de NR ont des récompenses prédéfinies. Par exemple, aux échecs, capturer une pièce est une récompense positive, tandis que recevoir un échec est une récompense négative.
Dans notre cas, nous pouvons donner des friandises à Bob si nous observons une action positive, par exemple s'il ne gratte pas les meubles pendant un certain temps ou s'il trouve l'un des griffoirs. Nous pourrions également le punir en lui envoyant de l'eau dans le visage s'il griffe les rideaux.
Pour mesurer les progrès du parcours d'apprentissage de Bob, nous pouvons considérer ses actions en termes d' étapes temporelles. Par exemple, à l'étape t1, Bob entreprend l'action a1, qui aboutit à un nouvel état s1 (s0 étant l'état par défaut). Il peut également recevoir une récompense r1.
Un ensemble de pas de temps est appelé épisode. Un épisode commence toujours dans un état par défaut (les meubles et les poteaux sont installés) et se termine lorsque l'objectif est atteint (un poteau est trouvé) ou que l'agent échoue (meubles rayés). Parfois, un épisode peut également se terminer en fonction du temps écoulé (comme aux échecs).
Comme un joueur d'échecs chevronné, Bob ne doit pas chercher n'importe quel griffoir. Bob doit choisir celui qui donne les friandises les plus gratifiantes. Cela met en évidence un dilemme classique de l'apprentissage par renforcement : l'exploration ou l'exploitation.
Alors qu'un message alléchant peut offrir une satisfaction immédiate, une exploration plus stratégique peut conduire à une récompense plus tardive. Tout comme un joueur d'échecs peut renoncer à une prise pour obtenir une position supérieure, Bob peut commencer par gratter un poste sous-optimal (exploration) pour découvrir le lieu de grattage ultime (exploitation). Cette stratégie à long terme est essentielle pour permettre aux agents de maximiser les récompenses dans des environnements complexes.
En d'autres termes, Bob doit trouver un équilibre entre l'exploitation (s'en tenir à ce qui fonctionne le mieux) et l'exploration (s'aventurer de temps en temps à la recherche de nouveaux griffoirs). Trop explorer peut faire perdre du temps, en particulier dans les environnements continus, tandis que trop exploiter peut faire passer Bob à côté de quelque chose d'encore mieux.
Heureusement, il existe quelques stratégies astucieuses que Bob peut adopter :
En utilisant ces stratégies (ou d'autres qui dépassent le cadre de notre tutoriel), Bob peut trouver un équilibre entre l'exploration de l'inconnu et le maintien des bonnes choses.
Bob n'arrive pas à trouver comment maximiser le nombre de friandises tout seul. Elle a besoin de méthodes et d'outils pour guider ses décisions dans chaque état de l'environnement. C'est là que les algorithmes d'apprentissage par renforcement viennent à la rescousse de Bob.
D'un point de vue plus général, les algorithmes d'apprentissage par renforcement peuvent être classés en fonction de la manière dont ils font interagir les agents avec l'environnement et dont ils tirent des enseignements de l'expérience. Les deux principales catégories d'algorithmes d'apprentissage par renforcement sont les algorithmes basés sur un modèle et les algorithmes sans modèle.
Dans les algorithmes basés sur des modèles, l'agent (comme Bob) construit un modèle interne de l'environnement. Ce modèle représente la dynamique de l'environnement, y compris les transitions d'état et les probabilités de récompense. L'agent peut ensuite utiliser ce modèle pour planifier et évaluer différentes actions avant de les entreprendre dans l'environnement réel.
Cette approche présente l'avantage d'être plus efficace en termes d'échantillonnage, en particulier dans les environnements complexes. Cela signifie que Bob pourrait avoir besoin de moins de tentatives de grattage pour identifier le poste optimal par rapport à des approches purement basées sur l'essai et l'erreur. Et ce, parce que Bob peut planifier et évaluer avant d'agir.
L'inconvénient est que la construction d'un modèle précis peut s'avérer difficile, en particulier pour les environnements complexes. Le modèle peut ne pas refléter fidèlement l'environnement réel, ce qui entraîne un comportement sous-optimal.
Un algorithme RL courant basé sur un modèle est Dyna-Q, qui combine en fait l'apprentissage basé sur un modèle et l'apprentissage sans modèle. Il construit un modèle de l'environnement et l'utilise pour planifier des actions tout en apprenant directement de l'expérience grâce à l'apprentissage Q sans modèle (que nous expliquerons dans un instant).
Cette approche se concentre sur l'apprentissage directement à partir de l'interaction avec l'environnement sans construire explicitement un modèle interne. L'agent (Bob) apprend la valeur des états et des actions ou la stratégie optimale par essais et erreurs.
Le RL sans modèle offre une approche plus simple dans les environnements où la construction d'un modèle précis est difficile. Pour Bob, cela signifie qu'il n'a pas besoin de créer une carte mentale complexe de la pièce - il peut apprendre en grattant et en expérimentant les conséquences.
Le RL sans modèle excelle dans les environnements dynamiques où les règles sont susceptibles de changer. Si la disposition des meubles de la pièce change, Bob peut adapter son exploration et apprendre les nouveaux endroits optimaux pour faire ses griffes.
Cependant, l'apprentissage par essais et erreurs peut s'avérer moins efficace en termes d'échantillonnage. Bob devra peut-être gratter beaucoup de meubles avant de trouver le poste le plus gratifiant.
Parmi les algorithmes RL sans modèle les plus courants, on peut citer
Le choix de l'algorithme dépend de plusieurs facteurs : la complexité de l'environnement, la disponibilité des ressources ou le niveau d'interprétabilité souhaité.
Les approches basées sur des modèles pourraient être préférables pour des environnements plus simples où la construction d'un modèle précis est possible. D'autre part, les approches sans modèle sont souvent plus pratiques pour les scénarios complexes du monde réel.
En outre, avec l'essor de l'apprentissage en profondeur, les réseaux Q profonds (DQN) et d'autres algorithmes RL profonds deviennent de plus en plus populaires pour s'attaquer à des tâches complexes avec des espaces d'état à haute dimension.
Concentrons-nous à présent sur un seul algorithme pour en savoir plus sur l'apprentissage Q.
L'apprentissage Q est un algorithme sans modèle qui apprend aux agents la stratégie gagnante optimale grâce à des interactions intelligentes avec l'environnement.
Revenons à notre exemple du chat et imaginons que nous résolvons une version arcade du problème avec un environnement discret et un ensemble fini d'actions.
Supposons que nous donnions un tableau à Bob. Les colonnes représentent les actions disponibles, tandis que chaque ligne associe l'action à un état spécifique de l'espace des états.
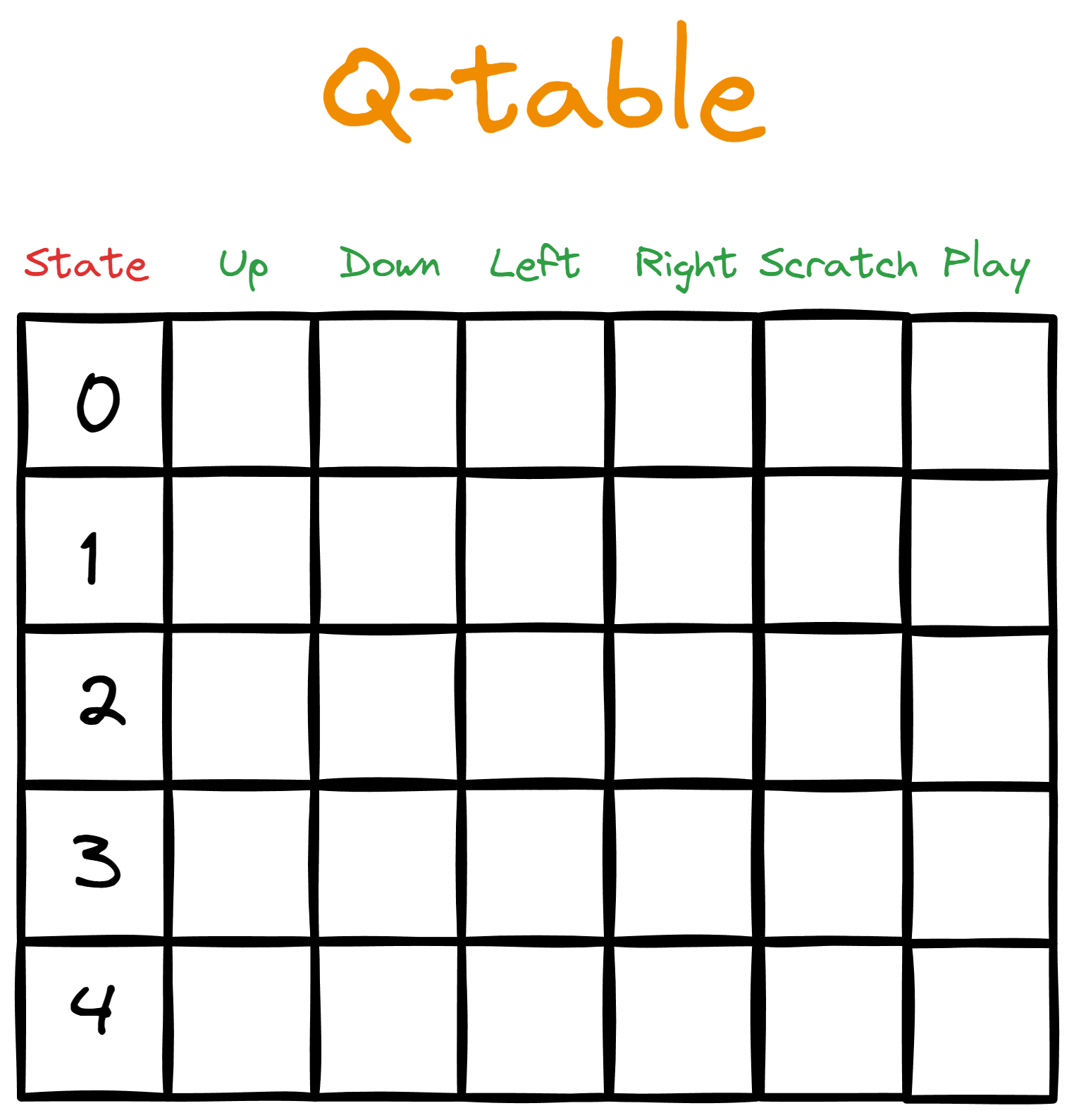
Dans un premier temps, nous remplissons le tableau avec des zéros, représentant les valeurs Qinitiales - c'est pourquoi nous l'appelons tableau Q.
Ensuite, nous démarrons une boucle d'interaction à partir de l'état par défaut (le début d'un épisode). Dans la boucle, Bob entreprend l'action ayant la valeur Q la plus élevée pour l'état donné. Cependant, lors du premier passage dans la boucle, il n'y aura pas de valeur Q la plus élevée pour guider l'action de Bob puisque toutes les valeurs Q sont initialement nulles.
C'est là que les stratégies d'exploration (comme l'exploration aléatoire ou l'epsilon-greedy) entrent en jeu. Ces stratégies permettent à Bob de recueillir des informations lorsque le tableau Q est vide.
Une fois le tableau Q mis à jour, Bob recommence une boucle d'interaction. L'action qu'il entreprend donne lieu à une récompense et à un nouvel état. Ensuite, nous calculons de nouvelles valeurs Q pour chaque action que Bob peut entreprendre dans le nouvel état (nous verrons plus loin comment calculer les valeurs Q).
L'épisode se poursuit jusqu'à son terme (Bob peut effectuer un nombre quelconque d'étapes dans chaque épisode), puis nous recommençons. Chaque épisode suivant aura un tableau de Q plus riche, ce qui rendra Bob plus intelligent.
Voici une vue d'ensemble des étapes à suivre :
Les étapes 1 et 2 peuvent être simples, mais les autres nécessitent plus d'explications.
À l'étape 1 du temps, lorsque Bob entreprend sa première action, celle-ci est aléatoire, puisque toutes les valeurs Q sont nulles. Au cours des étapes suivantes, Bob doit prendre en compte l'équilibre entre l'exploration et l'exploitation.
Pour faciliter cette tâche, nous attribuons à Bob un hyperparamètre appelé epsilon, dont la valeur est faible (généralement 0,1). Ensuite, nous demandons à Bob de générer un nombre aléatoire entre 0 et 1 et si ce nombre est inférieur à epsilon, il choisira une action aléatoire quelle que soit sa valeur Q.
Si elle est supérieure à epsilon, Bob choisira l'action ayant la valeur Q la plus élevée. Ainsi, Bob explorera epsilon (0,1 ou 10 %) du temps et exploitera (1 - epsilon ou 0,9 ou 90 %) du temps.
Ce que nous venons de décrire s'appelle la politique epsilon-greedy. Les politiques définissent comment l'agent agit et comment les valeurs Q sont calculées.
Les règles de calcul de la récompense sont généralement fixées par la personne qui crée l'environnement. Par exemple, vous pouvez décider de donner à Bob une seule friandise pour avoir utilisé un tapis à gratter et cinq friandises pour avoir sauté suffisamment haut pour gratter celui qui est accroché au mur. Il est également possible que vous punissiez Bob pour avoir griffé des objets de valeur.
Mais la plupart du temps, il n'y aura pas de récompense puisque Bob dormira, marchera ou jouera.
La formule de calcul de la valeur Q peut être intimidante, c'est pourquoi nous allons d'abord la voir dans son intégralité, puis l'expliquer étape par étape :

Considérons le début de la formule :
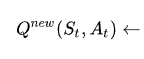
Cette partie dit : "Compte tenu de l'état et de l'action précédents, la nouvelle valeur Q est calculée comme (...)".
La partie ci-dessous est la valeur Q actuelle (bientôt ancienne) que l'agent a utilisée pour effectuer l'action.
![]()
Examinons maintenant la dernière partie :
![]()
St+1 est le nouvel état résultant de l'actionAt. Cette partie consiste donc à trouver la plus grande valeur Q de toutes les actions (a) dans ce nouvel état. Nous multiplions cette valeur par un paramètre γ appelé gamma (facteur d'actualisation) et ajoutons le résultat à la récompense reçue.
Si nous fixons gamma à une valeur proche de 1, nous accordons plus d'importance aux récompenses futures. Si nous le ramenons à zéro, nous mettons davantage l'accent sur la récompense actuelle Rt+1. Cela signifie que gamma est un autre paramètre que nous pouvons utiliser pour équilibrer l'exploration et l'exploitation.
Enfin, nous avons alpha (α), qui contrôle la vitesse d'apprentissage et varie de 0 à 1. Les valeurs proches de 1 augmentent les mises à jour des valeurs Q, de sorte que l'agent apprend plus rapidement, ce qui alourdit le côté droit du signe plus. En revanche, les valeurs proches de 0 alourdissent le côté gauche, qui contient la valeur Q actuelle.
L'utilisation du taux d'apprentissage pour contrôler la vitesse de formation permet de s'assurer que l'agent ne progresse pas trop rapidement et n'oublie pas les anciennes informations. Cela permet également de s'assurer qu'il n'apprend pas très lentement et qu'il ne risque pas de passer à côté d'informations importantes.
C'est la partie la plus difficile de la compréhension de l'apprentissage quantitatif, et j'espère que vous avez une idée approximative de son fonctionnement.
Comme pour tout, Python dispose de frameworks pour résoudre les problèmes d'apprentissage par renforcement. Le plus populaire est Gymnasium, qui est livré avec plus de 2000 environnements (tous documentés de manière exhaustive).
$ pip install "gymnasium[atari]"
$ pip install autorom[accept-rom-license]
$ AutoROM --accept-license
import gymnasium as gym
env = gym.make("ALE/Breakout-v5")L'environnement que nous venons de charger s'appelle Breakout. Voici à quoi cela ressemble :

L'objectif est ici que le conseil (l'agent) apprenne à éliminer toutes les briques par essais et erreurs. Les règles du jeu dictent les sanctions et les récompenses.
Nous terminerons l'article en montrant comment vous pouvez lancer vos propres épisodes d'interaction et visualiser la progression de l'agent à l'aide d'un GIF comme celui ci-dessus.
Voici le code de la boucle d'interaction :
epochs = 0
frames = [] # for animation
done = False
env = gym.make("ALE/Breakout-v5", render_mode="rgb_array")
observation, info = env.reset()
while not done:
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
# Put each rendered frame into dict for animation
frames.append(
{
"frame": env.render(),
"state": observation,
"action": action,
"reward": reward,
}
)
epochs += 1
if epochs == 1000:
breakNous venons d'effectuer un millier de pas de temps ou, en d'autres termes, l'agent a effectué 1000 actions. Cependant, toutes ces actions sont purement aléatoires - il ne s'agit pas d'apprendre des erreurs du passé. Pour le vérifier, nous pouvons utiliser la variable frames pour créer un GIF :
from moviepy.editor import ImageSequenceClip
# !pip install moviepy - if you don’t have moviepy
def create_gif(frames: dict, filename, fps=100):
"""
Creates a GIF animation from a list of RGBA NumPy arrays.
Args:
frames: A list of RGBA NumPy arrays representing the animation frames.
filename: The output filename for the GIF animation.
fps: The frames per second of the animation (default: 10).
"""
rgba_frames = [frame["frame"] for frame in frames]
clip = ImageSequenceClip(rgba_frames, fps=fps)
clip.write_gif(filename, fps=fps)
# Example usage
create_gif(frames, "animation.gif") #saves the GIF locally
Note : Si vous rencontrez une "RuntimeError : No ffmpeg exe could be found", essayez d'ajouter les deux lignes de code suivantes avant d'importer moviepy:
from moviepy.config import change_settings
change_settings({"FFMPEG_BINARY": "/usr/bin/ffmpeg"})Notre premier extrait renvoyait l'état de l'environnement sous forme de tableaux RGBA pour chaque pas de temps, et ils sont stockés dans des images. En assemblant toutes les images à l'aide de la bibliothèque moviepy, nous pouvons créer le GIF que vous avez vu précédemment :

Par ailleurs, vous pouvez ajuster le paramètre fps pour accélérer le GIF si vous exécutez de nombreux pas de temps.
Maintenant que nous voyons que l'agent effectue simplement des actions aléatoires, il est temps d'essayer quelques algorithmes. Vous pouvez le faire étape par étape dans ce cours sur l'apprentissage par renforcement avec Python, où vous explorerez de nombreux algorithmes, notamment l'apprentissage Q, SARSA, et plus encore.
N'oubliez pas d'utiliser la fonction que nous venons de créer pour animer la progression de vos agents, et amusez-vous bien !
L'apprentissage par renforcement est l'un des aspects les plus fascinants de l'informatique et de l'apprentissage automatique. Dans ce tutoriel, nous avons appris les concepts fondamentaux de la logique rationnelle - des agents et des environnements aux algorithmes sans modèle comme l'apprentissage Q.
Cependant, la création d'agents de classe mondiale capables de résoudre des problèmes complexes tels que les échecs ou les jeux vidéo nécessitera du temps et de la pratique. Voici donc quelques ressources qui pourraient vous aider dans votre démarche :
Merci de votre lecture !
En savoir plus sur l'IA et l'apprentissage par renforcement !
Cursus
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach