
Lernpfad
Grundlagen der KI
10 Std.
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Dieses Video wurde mit Hilfe von erstellt:
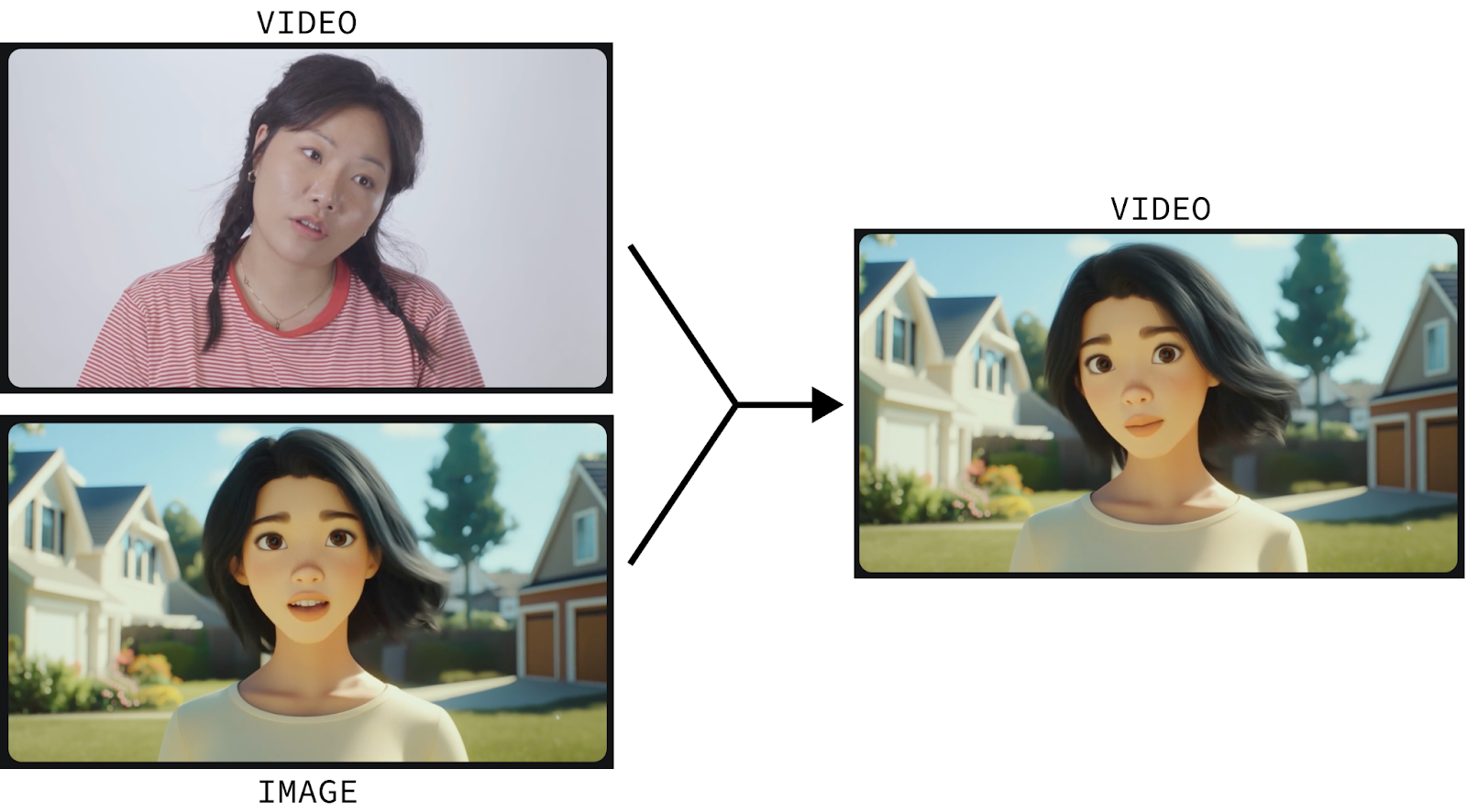
Runway Act-One animiert die Figur dann so, dass sie die Gesichtsbewegungen und die Mimik des menschlichen Schauspielers widerspiegelt.
Das Animieren von Figuren ist ein anspruchsvoller Prozess, den nur gut ausgebildete Profis von Grund auf beherrschen. Act-One versucht, das Spiel zu verändern, indem es jedem ermöglicht, eine Figur zu animieren, indem er sich selbst aufnimmt und ein Standbild der Figur, die er animieren möchte, bereitstellt.
Und das gilt nicht nur für Zeichentrickfiguren. Es funktioniert auch bei filmischen und realistischen Charakteren. Und wir können auch einen fesselnden Dialog erstellen, indem wir mehrere kurze Videos erstellen, in denen die Charaktere hin und her sprechen, und diese miteinander verbinden:
Lass uns Runway Act-One selbst erkunden. Es gibt zwar eine kostenlose Stufe, die 125 Credits und Warteschlangenoptionen bietet, aber Act-One ist in dieser Stufe nicht enthalten und erfordert ein Abonnement.
Gehe zuerst auf die Runway-Anmeldeseite und logge dich ein oder erstelle ein Konto. Als Nächstes abonnierst du einen der verfügbaren Pläne. Es ist wichtig zu wissen, dass auch mit einem Abonnement die Anzahl der Videos, die wir erstellen können, begrenzt ist. Ich habe das $15 Monatsabo ausprobiert, mit dem ich 625 Credits bekam (plus die 125 kostenlosen Credits, also insgesamt 750 Credits).
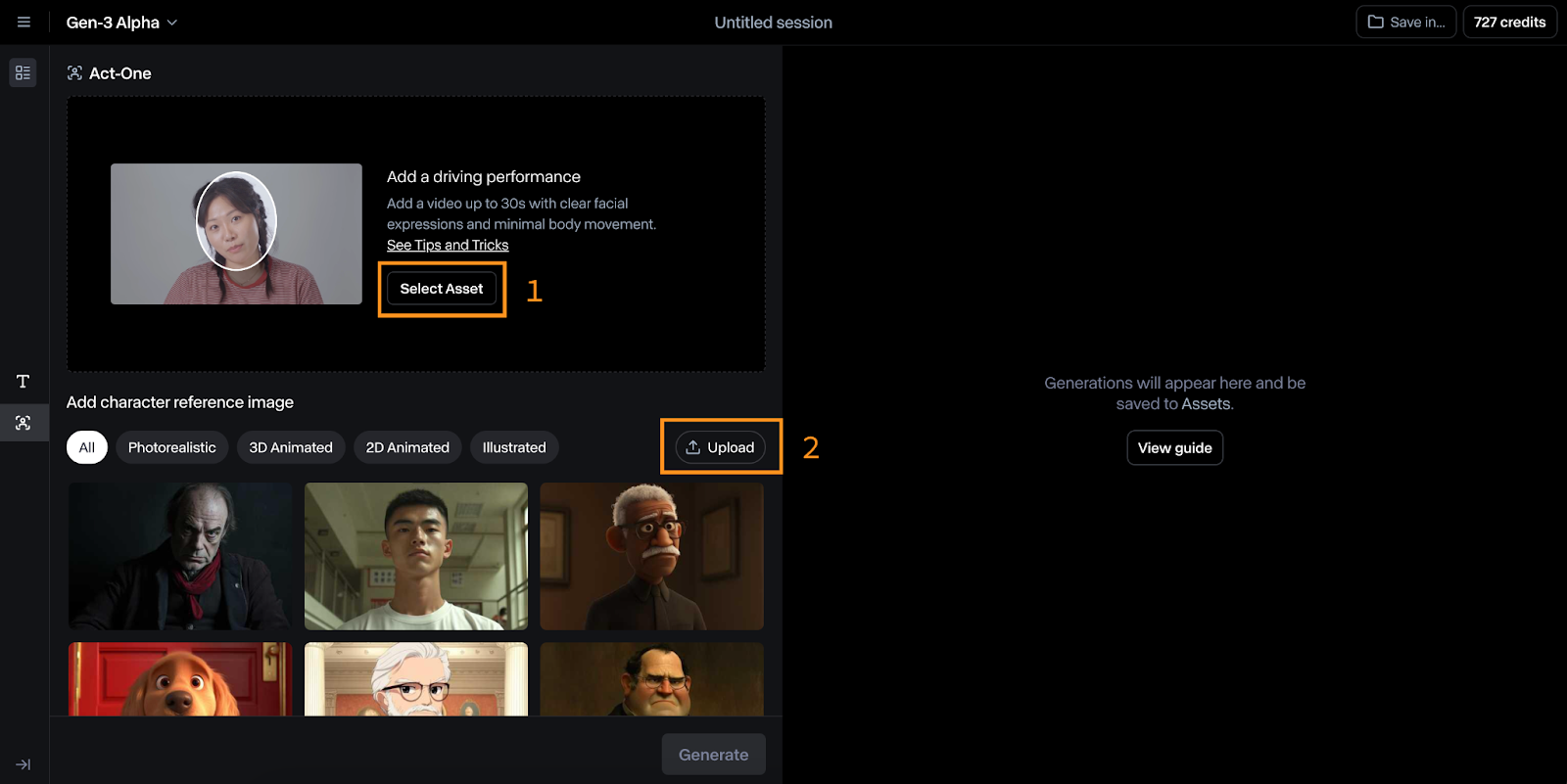
Um ein Video mit Act-One zu erstellen, klicke auf die Schaltfläche "Jetzt ausprobieren" auf dem Dashboard.
Die Act-One Schnittstelle ist relativ einfach zu bedienen. Auf dem Bild unten kannst du das sehen:
Um es auszuprobieren, habe ich mich dabei gefilmt, wie ich ein überraschtes Gesicht mache, und habe es dann mit der Hundemarke ausprobiert.
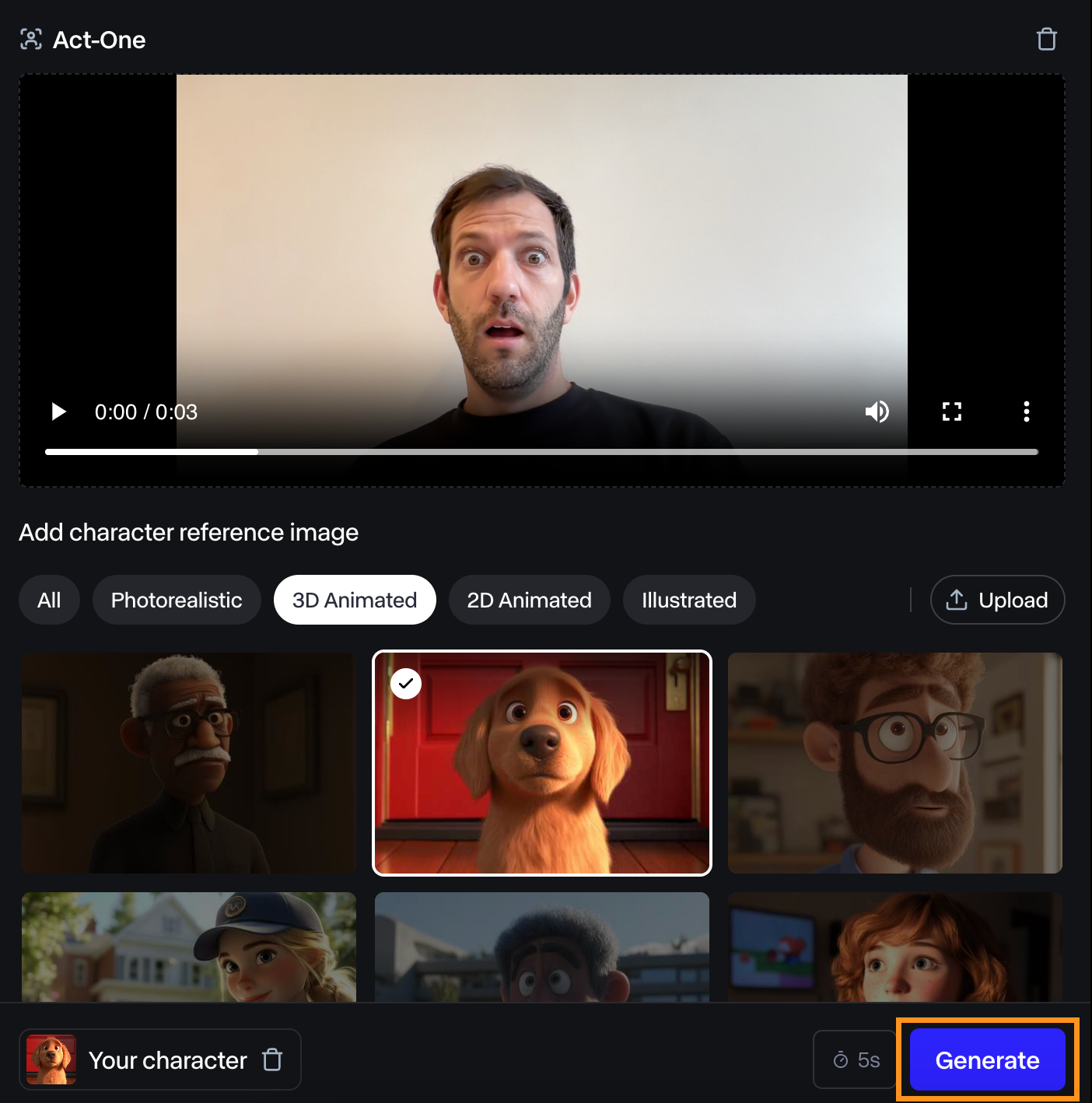
Ich fand das Video, das dabei herauskam, ganz okay. Der Gesichtsausdruck ist nicht sehr ausgeprägt, aber er passt trotzdem zu meinem.
Ich habe andere Experimente mit der gleichen Figur gemacht, und Runway Act-One hat mich nie beeindruckt. In manchen Fällen gab es nicht einmal einen Ausdruck. In dem Beispiel unten hat sich der Hund trotz meines Gesichtsausdrucks überhaupt nicht bewegt.
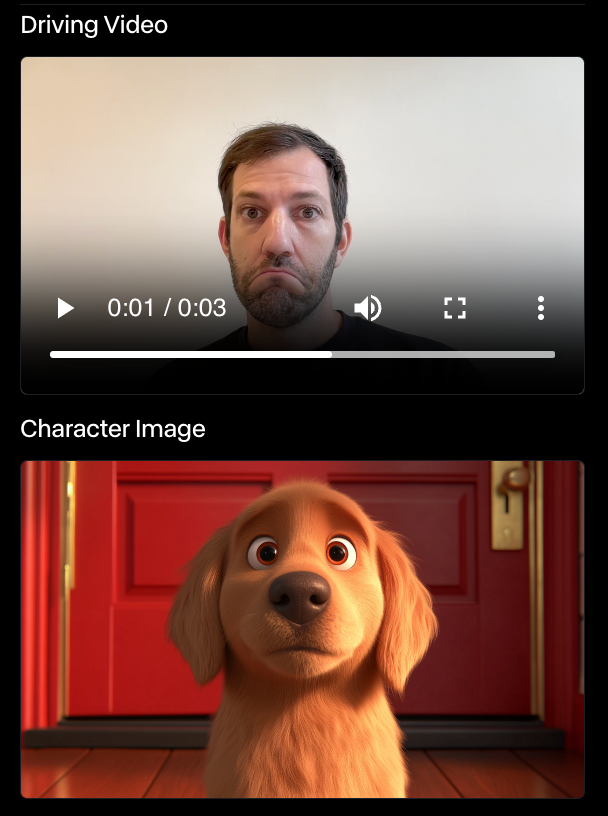
Ich bin kein Schauspieler, also ist das vielleicht das Problem. Wenn das Ziel von Act-One jedoch darin besteht, jeden in die Lage zu versetzen, Charaktere zu animieren, ist es noch ein weiter Weg, bis es wirklich von jedem ohne Branchenerfahrung genutzt werden kann.
Ich fand es auch unmöglich, ein eigenes Charakterbild zu verwenden. Ich habe etwa 10 verschiedene Charaktere mit Dall-E 3 erstellt, und Runway hat jedes Mal kein Gesicht gefunden. Hier ist ein Beispiel:
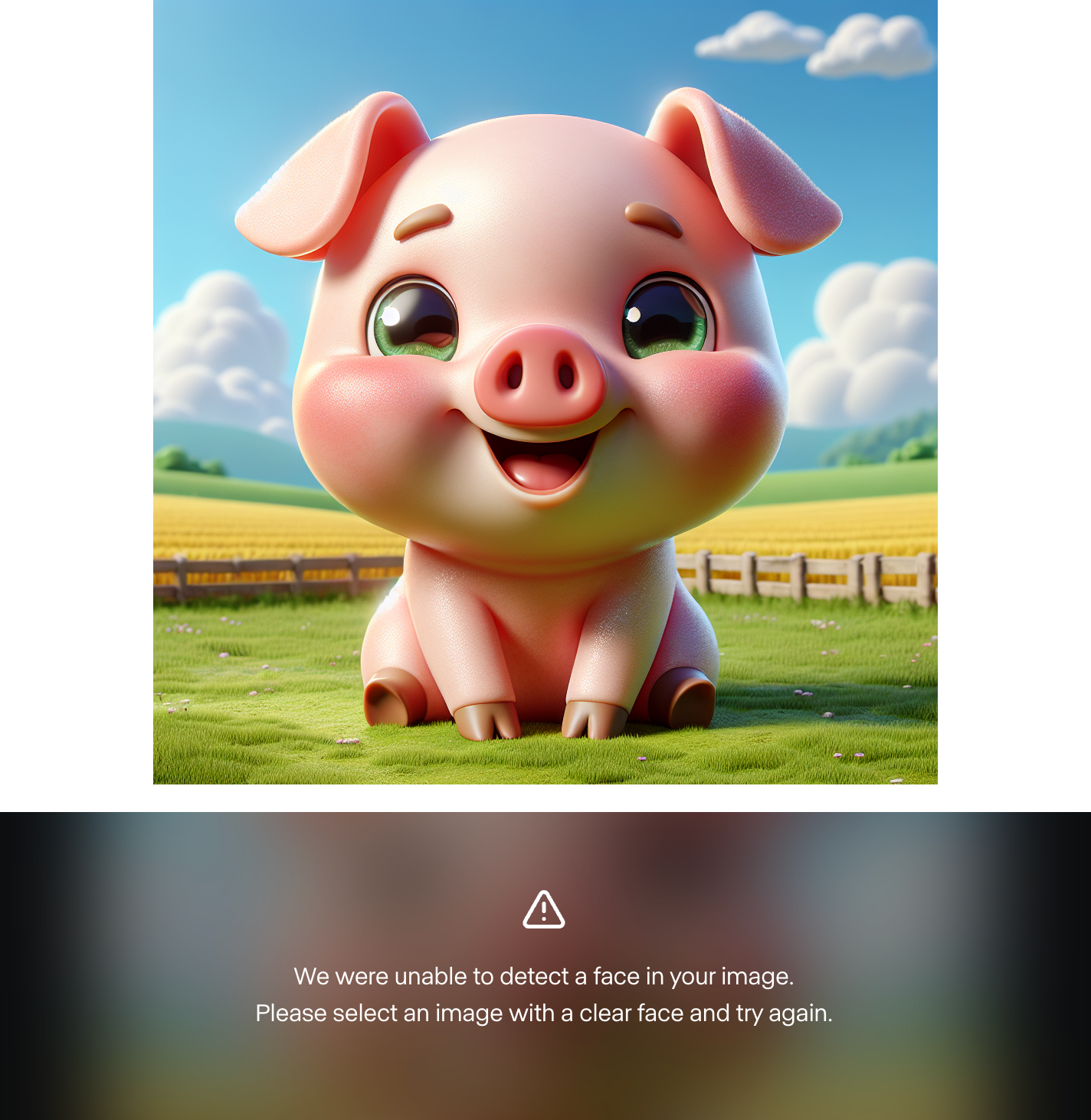
Das deutet für mich darauf hin, dass es sich bei den gezeigten Beispielen um eine Auslese handelt und das Modell noch nicht für die breite Öffentlichkeit bereit ist. Ich habe es aber mit menschlichen Charakteren ausprobiert und es hat funktioniert. Es könnte also sein, dass das Modell noch keine benutzerdefinierten animierten Charaktere unterstützt.
Hier ist ein Beispiel mit einem menschlichen Charakter:
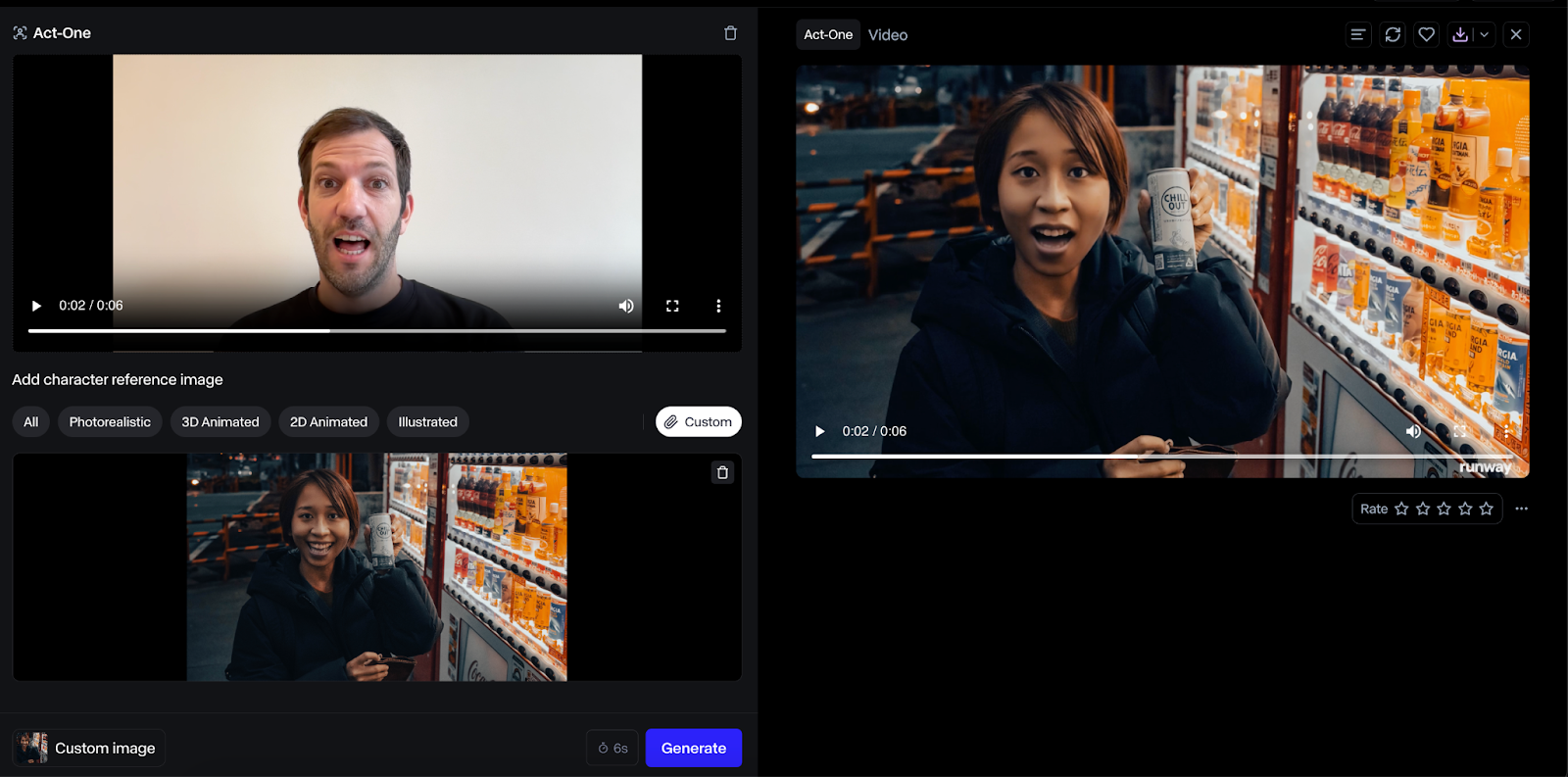
Das Ergebnis mit einem menschlichen Gesicht war viel besser, und ich fand, dass die Ausgabe originalgetreuer war. Dieser Anwendungsfall scheint jedoch weniger sinnvoll zu sein, da wir stattdessen einfach den Menschen direkt handeln lassen könnten.
Die Länge des Ausgabevideos entspricht der des Eingabevideos, und je nach Länge des Videos werden Credits berechnet.
Anfang Juni dieses Jahres stellte Runway ML sein Gen-3 Alpha-Modell vor, das Videos auf der Grundlage eines Standbildes und einer Textaufforderung erstellt.
Da Act-One sich auf Nahaufnahmen von Gesichtern konzentriert, ergänzen sich diese beiden Modelle. Act-One kann zum Erstellen von Dialogen verwendet werden, während Gen-3 Alpha die Szenen zwischen den Dialogen erzeugen kann.
Um zu Gen-3 Alpha zu wechseln, klicke auf das "T"-Symbol auf der linken Seite (Nr. 1 in der Abbildung unten).
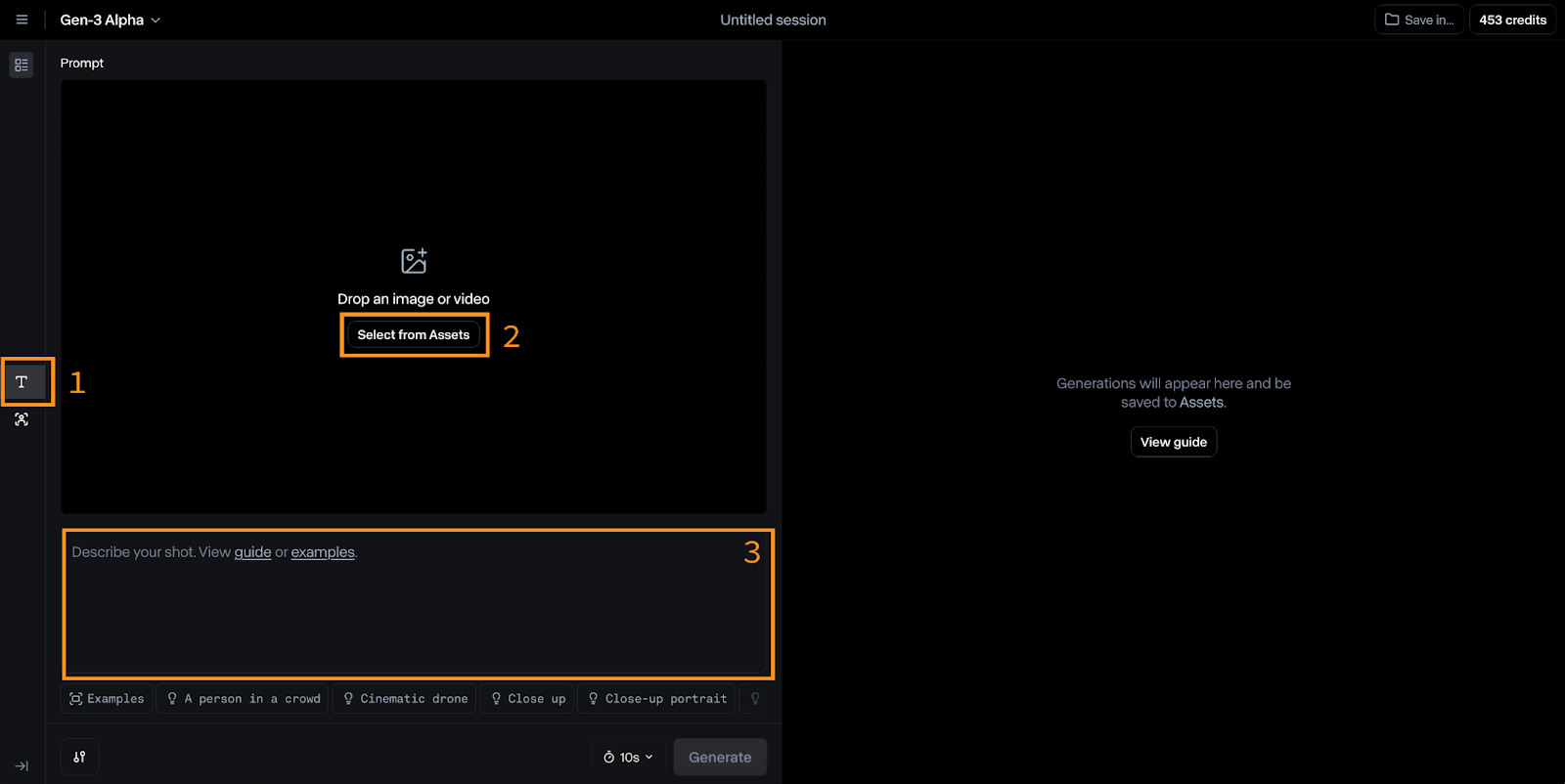
Die Eingaben für dieses Modell sind ein Bild (#2) und eine Textaufforderung (#3). Runway schlägt vor, dass die Textaufforderung diesem Format folgt:
[camera movement]: [establishing scene]. [additional details].Zum Beispiel:
Low-angle static shot: The camera is angled up at a woman wearing all orange as she stands in a tropical rainforest with colorful flora. The dramatic sky is overcast and gray.Ich habe es ausprobiert, um ein Foto zu animieren, das ich kürzlich aufgenommen habe. Hier sind die Eingaben, die ich verwendet habe:
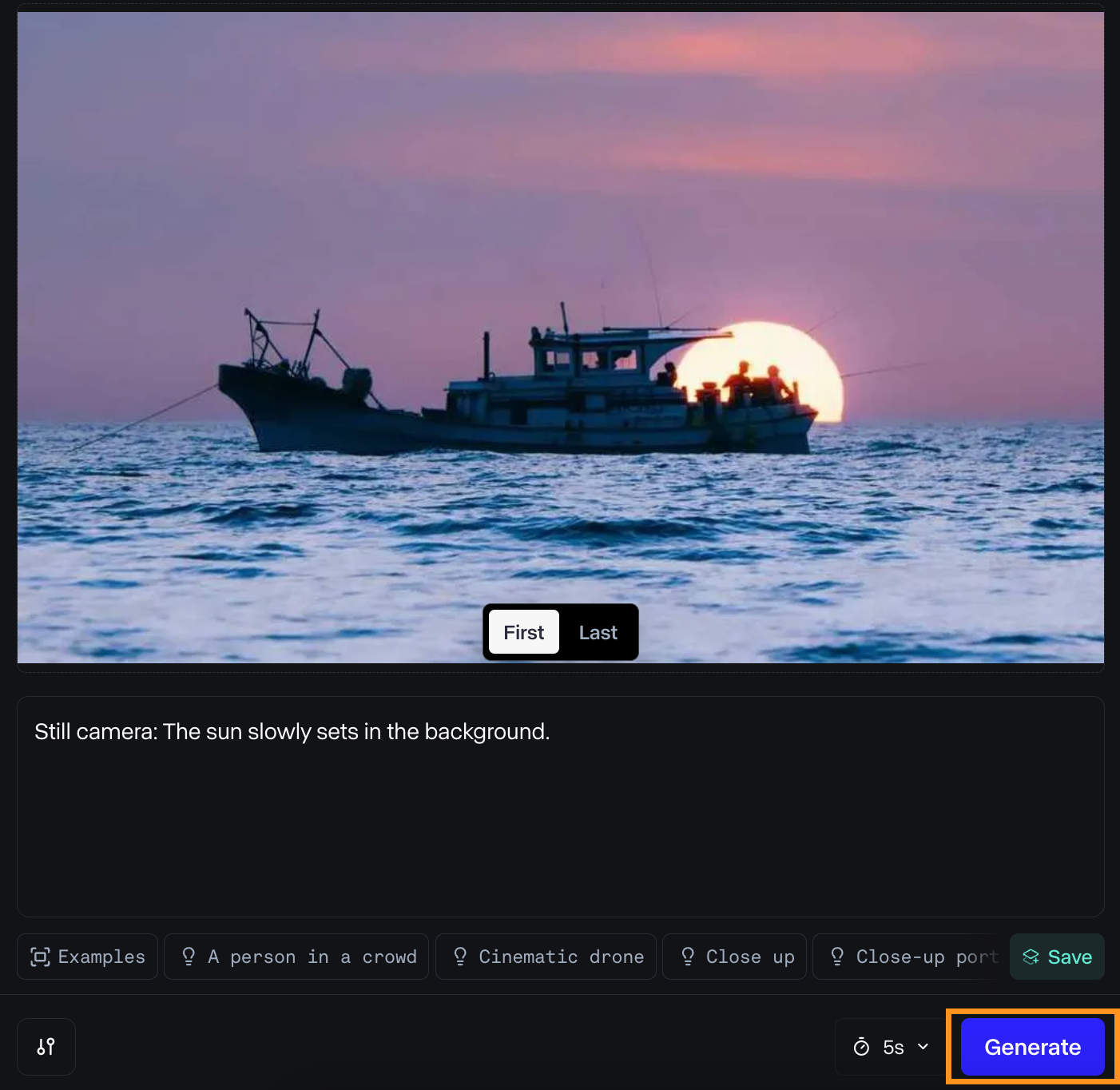
Und hier ist das Ergebnis:
Das Ergebnis hat mir gefallen. Das Licht sieht gut aus, wenn sich das Boot von der Sonne wegbewegt, und die Wasserbewegung ist gleichmäßig.
Das Ergebnis ist jedoch ganz anders, als ich es mir ursprünglich vorgestellt habe. Das ist definitiv eines der Hauptprobleme für Videoproduzenten: die Unfähigkeit, jedes Detail in einer Szene zu kontrollieren, was mit traditionellen Methoden der Filmerstellung möglich ist. Wenn diese Einschränkung bestehen bleibt, könnten sich künftige Regisseure, die KI einsetzen, auf von KI generierte Szenen beschränken, anstatt ihre ursprüngliche Vision zu verwirklichen.
In diesem Fall können wir drei verschiedene Videoclips kreativ kombinieren.
Erstens haben wir ein Video von einem Boot, das über das Wasser fährt. Dieser Clip schafft den Rahmen und liefert den Kontext für die folgenden Aktionen.
Als Nächstes könnten wir eine Nahaufnahme einer Person machen, die am Ufer steht, ihren Blick auf das Boot gerichtet hat und ein Gefühl der Sehnsucht ausdrückt.
Schließlich gibt es noch ein Video, das zeigt, wie sich das Boot vom Ufer entfernt, und zwar aus der Sicht der Figur. Dieser dritte Clip vermittelt ein Gefühl der Bewegung und des Fortschreitens.
Runway ML bietet auch eine API an, um seine Modelle außerhalb der Weboberfläche zu nutzen. Es unterstützt zwar Gen-3 Alpha Turbo, aber es scheint, dass Act-One noch nicht verfügbar ist. Dieser Leitfaden behandelt die Grundlagen der Nutzung der API, die auch nach der Einführung von Act-One unverändert bleiben werden.
Um loszulegen, müssen wir ein Entwicklerkonto anlegen und einen API-Schlüssel generieren.
Navigiere zur die Entwicklerseite und klicke auf die Schaltfläche Anmelden. Wenn du noch kein Konto hast, kannst du dort eines erstellen.
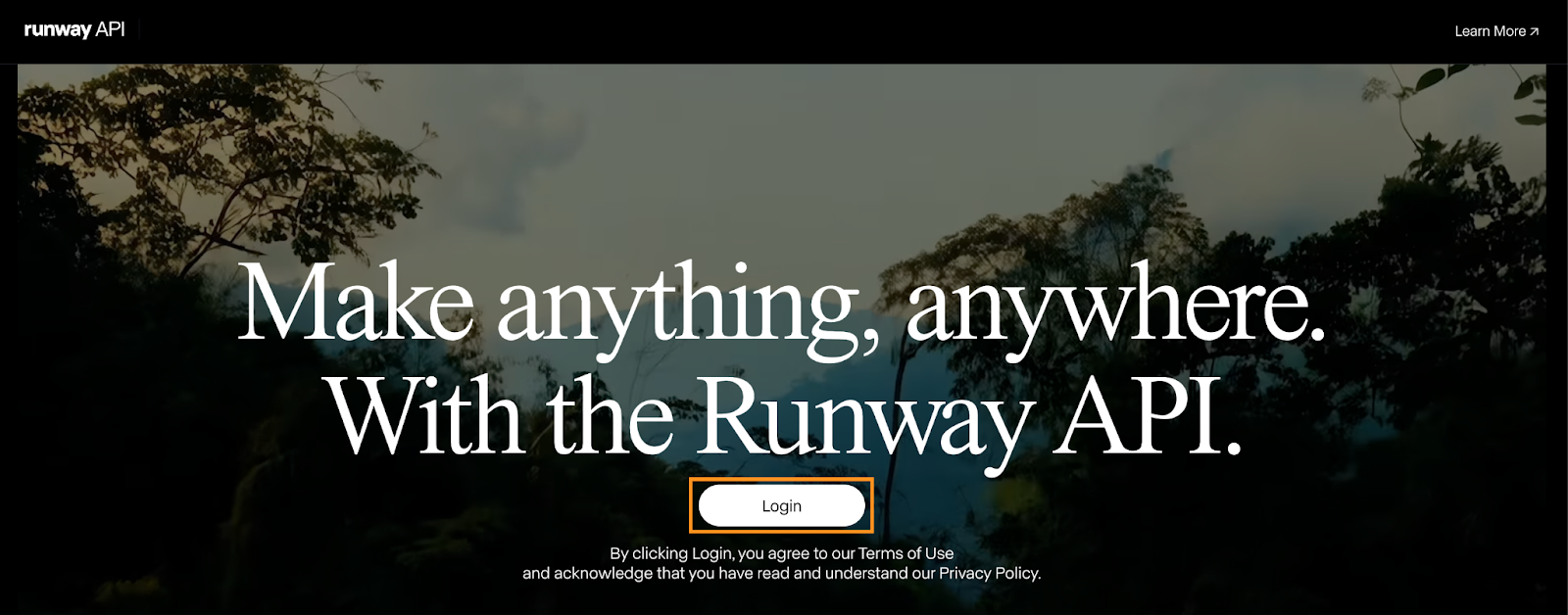
Sobald das Konto erstellt ist, navigierst du zur Seite "API-Schlüssel" und klickst auf "Neuer API-Schlüssel":

Daraufhin öffnet sich ein Pop-up-Fenster, in dem du nach dem Namen des Schlüssels gefragt wirst. Wir können es leer lassen und auf "Erstellen" klicken.
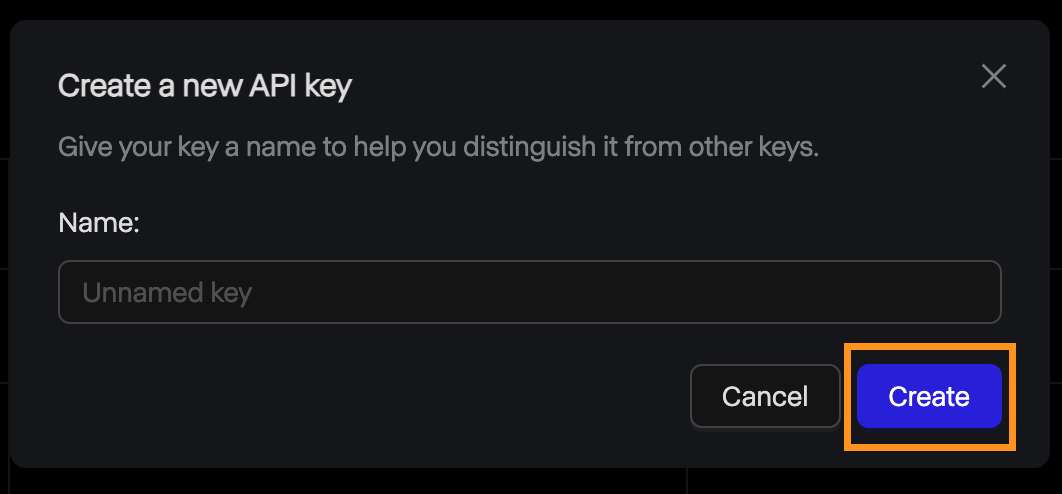
Danach wird der Schlüssel angezeigt, und wir können ihn kopieren. Denke daran, dass der Schlüssel aus Sicherheitsgründen nur hier angezeigt wird, also kopiere ihn unbedingt. Wenn sie aus irgendeinem Grund verloren geht, können wir sie jederzeit löschen und eine neue erstellen.
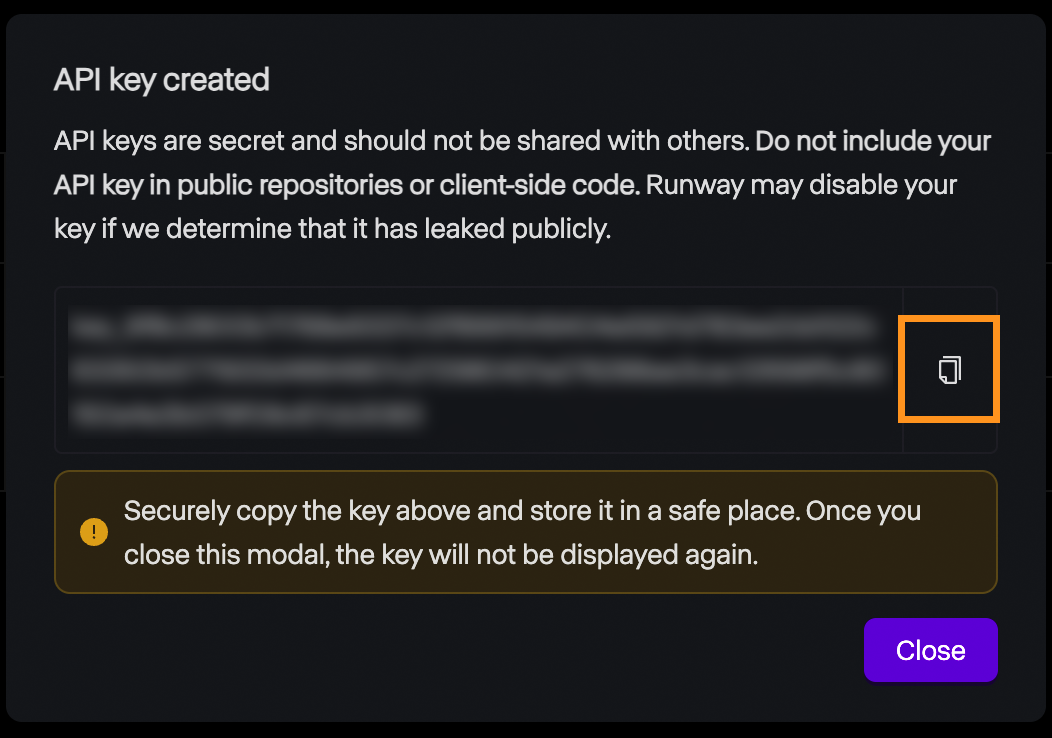
Die Runway ML API bietet keine kostenlose Version an. Um damit zu experimentieren, müssen wir Guthaben auf unser Konto laden. Die Preise sind identisch mit denen des Webinterfaces: 0,25 $ für ein 5-Sekunden-Video und 0,50 $ für ein 10-Sekunden-Video.
Es ist wichtig zu wissen, dass sich API-Guthaben von denen eines Abonnement-Kontos unterscheiden, d.h. diese Guthaben können nicht verwendet werden, um Videos über die Weboberfläche zu erstellen und umgekehrt.
Runway ML bietet eine Python-Bibliothek namens runwayml, die wir installieren müssen, um mit der API zu interagieren. Um es zu installieren, benutze den Befehl:
pip install runwaymlUm auf die API zuzugreifen, sollte der API-Schlüssel als Umgebungsvariable namens RUNWAYML_API_SECRET gesetzt werden. Wir können dies mit dem folgenden Befehl tun:
export RUNWAYML_API_SECRET=api_key
```Replacing api_key with the key created above.
Generating a videoRecently, I took this photo of the night sky:
Source: Instagram @fran.a.photo
I wanted to try out runwayml to see if it could generate a time-lapse video from the photo. To generate a video from an image using the API, we:
Import and initialize RunwayML client. Note that we don’t need to provide the API key as it is automatically loaded from the environment variable we set up before.Call the image_to_video.create() method from the client, providing the name of the model, the image URL, and the prompt.Store the task into a variable and print its identifier so that we can retrieve the video later. This is important as it seems that their API doesn’t have any way to list the past tasks. Without it, we’ll pay the generation credits but won’t have a way to get our video.```python
from runwayml import RunwayML
url = "https://i.ibb.co/LC7Kfrq/Z72-5415.jpg"
client = RunwayML()
task = client.image_to_video.create(
model="gen3a_turbo",
prompt_image=url,
prompt_text="Camera slowly zooms out: Astrophotography time-lapse featuring shooting stars.",
)
print(task.id)Um das Ergebnis zu sehen, müssen wir warten, bis die Aufgabe abgeschlossen ist. Wir können den Status der Aufgabe mit task.status abrufen. Der Status ist gleich der Zeichenkette ”SUCCEEDED”, wenn das Video erfolgreich erstellt wurde.
Wir können die Video-URL mit task.output aufrufen. Beachte, dass dieses Feld eine Liste von Ausgaben ist. Standardmäßig wird ein einzelnes Video erstellt, so dass die Video-URL task.output[0] lautet.
Hier ist ein einfaches Skript, das die Video-URL anhand der Aufgabenkennung ausgibt:
from runwayml import RunwayML
task_id = "af0a95ed-b0ff-4120-aecd-2473d7a42891"
client = RunwayML()
task = client.tasks.retrieve(id=task_id)
if task.status == "SUCCEEDED":
print(task.output[0])
else:
print(f"Video not ready, status={task.status}")Das ist das Video, das wir aus dem Foto erstellt haben:
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
