
Kurs
Einführung in Natural Language Processing mit Python
4 Std.
141K
Die Themenmodellierung ist ein häufig genutzter Ansatz, um verborgene semantische Muster in einem Textkorpus zu entdecken und darin enthaltene Themen automatisch zu identifizieren.
Dabei handelt es sich um eine Art der statistischen Modellierung, die unbeaufsichtigtes maschinelles Lernen nutzt, um Cluster oder Gruppen ähnlicher Wörter innerhalb eines Textes zu analysieren und zu identifizieren.
Zum Beispiel kann ein Topic Modeling Algorithmus eingesetzt werden, um festzustellen, ob es sich bei einem Dokument um eine Rechnung, eine Beschwerde oder einen Vertrag handelt.
Einigen Quellen zufolge erzeugt die durchschnittliche Person mehr als 1,7 MB an digitalen Daten pro Sekunde. Das sind mehr als 2,5 Quintillionen Bytes an Daten pro Tag, von denen 80-90% unstrukturiert sind.
Stell dir ein Szenario vor, in dem ein Unternehmen eine einzelne Person damit beauftragt, alle unstrukturierten Daten zu überprüfen und sie nach dem zugrunde liegenden Thema zu segmentieren. Das wäre eine unmögliche Aufgabe.
Das würde sehr viel Zeit in Anspruch nehmen und wäre extrem mühsam. Außerdem ist das Risiko viel größer, da Menschen von Natur aus voreingenommen und fehleranfälliger sind als Maschinen.
Die Lösung ist die Themenmodellierung.
Mit Topic Modeling können Erkenntnisse aus den Daten schneller und möglicherweise besser abgeleitet werden. Diese Technik fasst die Themen in einer verständlichen Struktur zusammen und ermöglicht es den Unternehmen, schnell zu verstehen, was passiert ist.
Ein Unternehmen, das die größten Herausforderungen seiner Kunden verstehen will, kann zum Beispiel Topic Modeling einsetzen, um diese Informationen aus unstrukturierten Daten zu gewinnen.
Kurz gesagt, Topic Modeling hilft Unternehmen dabei:
Wir haben festgestellt, dass die Themenmodellierung Datenexperten in die Lage versetzt, Cluster oder Gruppen ähnlicher Wörter innerhalb eines Textes schnell und in großem Umfang zu analysieren und zu identifizieren.
Aber was sind Themen und wie funktioniert die Themenmodellierung?
Themen sind die latenten Beschreibungen eines Textkorpus (einer großen Gruppe). Intuitiv betrachtet ist es wahrscheinlicher, dass in Dokumenten zu einem bestimmten Thema bestimmte Wörter häufiger vorkommen.
Die Wörter "Hund" und "Knochen" tauchen zum Beispiel eher in Dokumenten über Hunde auf, während "Katze" und "Miau" eher in Dokumenten über Katzen zu finden sind. Folglich würde das Themenmodell die Dokumente scannen und Cluster ähnlicher Wörter erstellen.
Im Wesentlichen funktionieren Themenmodelle, indem sie Wörter ableiten und ähnliche Wörter zu Themen gruppieren, um Themencluster zu erstellen.
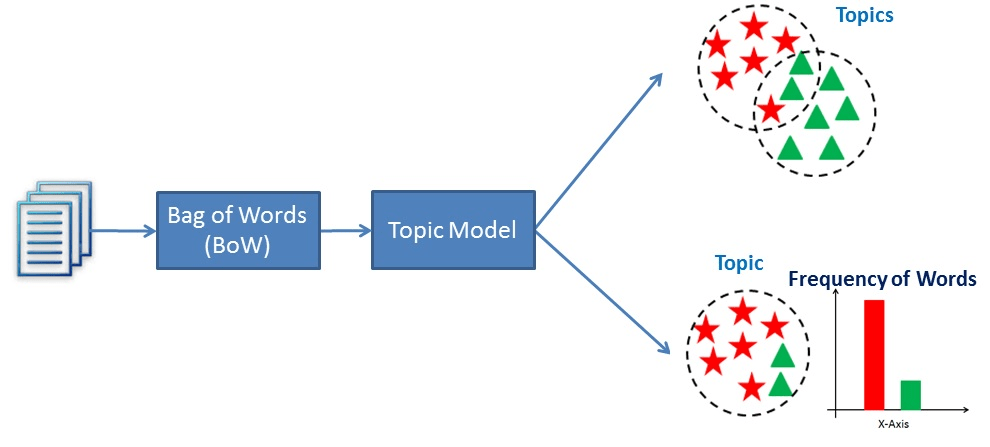
Eine Visualisierung, wie Topic Modeling funktioniert
Zwei beliebte Techniken zur Themenmodellierung sind die Latent Semantic Analysis (LSA) und die Latent Dirichlet Allocation (LDA). Ihr Ziel, verborgene semantische Muster in Textdaten zu entdecken, ist das gleiche, aber die Art und Weise, wie sie es erreichen, ist unterschiedlich.
Die latente semantische Analyse (LSA) ist eine Technik zur Verarbeitung natürlicher Sprache, mit der Beziehungen zwischen Dokumenten und den darin enthaltenen Begriffen analysiert werden. Die Methode wurde erstmals 1988 in einem Papier mit dem Titel "Using Latent Semantic Analysis to Improve Access to Textual Information" vorgestellt und wird auch heute noch verwendet, um strukturierte Daten aus einer Sammlung von unstrukturiertem Text zu erstellen.
LSA geht nämlich davon aus, dass Wörter mit ähnlichen Bedeutungen in ähnlichen Dokumenten vorkommen. Dazu wird eine Matrix erstellt, die die Anzahl der Wörter pro Dokument enthält, wobei jede Zeile für ein einzelnes Wort und die Spalten für jedes Dokument stehen. Anschließend wird eine Singular Value Decomposition (SVD) verwendet, um die Anzahl der Zeilen zu reduzieren, während die Ähnlichkeitsstruktur zwischen den Spalten erhalten bleibt. SVD ist eine mathematische Methode, die Daten vereinfacht und dabei ihre wichtigen Merkmale beibehält. Sie wird hier verwendet, um die Beziehungen zwischen Wörtern und Dokumenten zu erhalten.
Um die Ähnlichkeit zwischen Dokumenten zu bestimmen, wird die Kosinus-Ähnlichkeit verwendet. Dies ist ein Maß, das den Kosinus des Winkels zwischen zwei Vektoren berechnet, die in diesem Fall Dokumente darstellen. Ein Wert nahe 1 bedeutet, dass sich die Dokumente aufgrund der enthaltenen Wörter sehr ähnlich sind, während ein Wert nahe 0 bedeutet, dass sie sehr unterschiedlich sind.
Die Latent-Dirichlet-Allokation (LDA) wurde erstmals im Jahr 2000 in einer Arbeit mit dem Titel "Inference of population structure using multilocus genotype data" vorgeschlagen . Die Arbeit konzentrierte sich hauptsächlich auf die Populationsgenetik, ein Teilgebiet der Genetik, das sich mit genetischen Unterschieden innerhalb und zwischen Populationen befasst. Drei Jahre später wurde die Latent-Dirichlet-Allokation im maschinellen Lernen eingesetzt.
Die Autoren des Papiers beschreiben die Technik als "ein generatives Modell für Texte und andere Sammlungen diskreter Daten". LDA kann also als eine natürlichsprachliche Technik beschrieben werden, die verwendet wird, um Themen, zu denen ein Dokument gehört, anhand der darin enthaltenen Wörter zu identifizieren.
Genauer gesagt ist LDA ein Bayes'sches Netzwerk, d.h. es ist ein generatives statistisches Modell, das davon ausgeht, dass Dokumente aus Wörtern bestehen, die bei der Bestimmung der Themen helfen. So werden Dokumente einer Liste von Themen zugeordnet, indem jedes Wort des Dokuments einem anderen Thema zugeordnet wird. Dieses Modell ignoriert die Reihenfolge der Wörter, die in einem Dokument vorkommen, und behandelt sie als einen Sack voller Wörter.
Latent Semantic Analysis (LSA) und Latent Dirichlet Allocation (LDA) sind beides Techniken zur Verarbeitung natürlicher Sprache, die verwendet werden, um strukturierte Daten aus einer Sammlung unstrukturierter Texte zu erstellen.
LSA nutzt jedoch die Singular Value Decomposition (SVD), um die Dimensionalität der Term-Dokument-Matrix zu reduzieren, und basiert auf der Annahme, dass Wörter mit ähnlichen Bedeutungen in ähnlichen Dokumenten vorkommen. Durch die Erstellung einer niedrigdimensionalen Darstellung des Textes kann das Modell die zugrunde liegenden Beziehungen zwischen den Wörtern erfassen, um zu bestimmen, wie ähnlich zwei Dokumente sind.
Im Gegensatz dazu ist LDA ein generatives probabilistisches Modell, das die Bayes'sche Inferenz nutzt, um die zugrunde liegenden Themen in einem Textkorpus zu finden. Sie geht davon aus, dass jedes Dokument eine Kombination aus einer kleinen Anzahl von latenten Themen ist und jedes Wort von einem bestimmten Thema erzeugt wird.
Letztendlich versucht LSA, die zugrunde liegenden Beziehungen zwischen Wörtern zu entdecken, während LDA versucht, die zugrunde liegenden Themen in einem Textkorpus zu entdecken. Obwohl es sich bei beiden um Techniken zur Erstellung einer Vektordarstellung von Text handelt, gehen sie von unterschiedlichen Grundannahmen aus.
Schauen wir uns an, wie diese Techniken funktionieren. Verwende diese DataLab-Arbeitsmappe, um dem Code zu folgen.
Das erste, was wir brauchen, sind Daten.
Bei der Themenmodellierung werden die Daten, die wir verwenden, als Korpus bezeichnet, der einfach eine Textsammlung ist.
Hier ist ein kleiner Korpus, den ich mit Fakten aus dem Internet erstellt habe:
# Creating example documents
doc_1 = "A whopping 96.5 percent of water on Earth is in our oceans, covering 71 percent of the surface of our planet. And at any given time, about 0.001 percent is floating above us in the atmosphere. If all of that water fell as rain at once, the whole planet would get about 1 inch of rain."
doc_2 = "One-third of your life is spent sleeping. Sleeping 7-9 hours each night should help your body heal itself, activate the immune system, and give your heart a break. Beyond that--sleep experts are still trying to learn more about what happens once we fall asleep."
doc_3 = "A newborn baby is 78 percent water. Adults are 55-60 percent water. Water is involved in just about everything our body does."
doc_4 = "While still in high school, a student went 264.4 hours without sleep, for which he won first place in the 10th Annual Great San Diego Science Fair in 1964."
doc_5 = "We experience water in all three states: solid ice, liquid water, and gas water vapor."
# Create corpus
corpus = [doc_1, doc_2, doc_3, doc_4, doc_5]Der nächste Schritt ist das Bereinigen des Textes:
# Code source: https://www.analyticsvidhya.com/blog/2016/08/beginners-guide-to-topic-modeling-in-python/
import string
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('omw-1.4')
from nltk.corpus import stopwords
from nltk.stem.wordnet import WordNetLemmatizer
# remove stopwords, punctuation, and normalize the corpus
stop = set(stopwords.words('english'))
exclude = set(string.punctuation)
lemma = WordNetLemmatizer()
def clean(doc):
stop_free = " ".join([i for i in doc.lower().split() if i not in stop])
punc_free = "".join(ch for ch in stop_free if ch not in exclude)
normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split())
return normalized
clean_corpus = [clean(doc).split() for doc in corpus]In dem obigen Code haben wir:
Aber das heißt noch lange nicht, dass wir bereit sind.
Bevor wir diese Daten als Eingabe für ein LDA- oder LSA-Modell verwenden können, müssen sie in eine Term-Dokumenten-Matrix umgewandelt werden. Eine Term-Dokument-Matrix ist lediglich eine mathematische Darstellung einer Menge von Dokumenten und der darin enthaltenen Begriffe.
Sie wird erstellt, indem das Vorkommen jedes Begriffs in jedem Dokument gezählt und die Zählungen dann normalisiert werden, um eine Matrix von Werten zu erstellen, die für die Analyse verwendet werden können.
Um dies in Python zu tun, werden wir die Gensim-Bibliothek nutzen.
from gensim import corpora
# Creating document-term matrix
dictionary = corpora.Dictionary(clean_corpus)
doc_term_matrix = [dictionary.doc2bow(doc) for doc in clean_corpus]Jetzt können wir unsere Modelle anpassen.
Das erste Modell, das wir in LSA verwenden werden:
from gensim.models import LsiModel
# LSA model
lsa = LsiModel(doc_term_matrix, num_topics=3, id2word = dictionary)
# LSA model
print(lsa.print_topics(num_topics=3, num_words=3))
"""
[
(0, '0.555*"water" + 0.489*"percent" + 0.239*"planet"'),
(1, '0.361*"sleeping" + 0.215*"hour" + 0.215*"still"'),
(2, '-0.562*"water" + 0.231*"rain" + 0.231*"planet"')
]
"""Dies gibt die Themen (jede Zeile) mit einzelnen Themenbegriffen (Terme) und deren Gewichtung aus.
Probieren wir es mit LDA aus:
from gensim.models import LdaModel
# LDA model
lda = LdaModel(doc_term_matrix, num_topics=3, id2word = dictionary)
# Results
print(lda.print_topics(num_topics=3, num_words=3))
"""
[
(0, '0.071*"water" + 0.025*"state" + 0.025*"three"'),
(1, '0.030*"still" + 0.028*"hour" + 0.026*"sleeping"'),
(2, '0.073*"percent" + 0.069*"water" + 0.031*"rain"')
]
"""Durch den Wegfall manueller und sich wiederholender Aufgaben kann die Themenmodellierung auf einfache Weise und kostengünstig Prozesse beschleunigen. Hier sind ein paar Beispiele:
Die Themenmodellierung kann Kundendienstmitarbeitern dabei helfen, Supportanfragen zu analysieren, um die wichtigsten Probleme zu identifizieren und solche zu ermitteln, die wiederholt auftreten. Auf der Grundlage dieser Daten können sie vielleicht informativere Self-Service-Inhalte erstellen oder den Kunden direkt helfen.
Die Themenmodellierung kann genutzt werden, um Unterhaltungen zu markieren, damit sie an das am besten geeignete Team weitergeleitet werden können. Zum Beispiel könnte eine Konversation, die Wörter wie "Preise", "Abonnement", "Erneuerung" usw. enthält, direkt an die Buchhaltungsabteilung geschickt werden.
Die Themenmodellierung wird verwendet, um latente Themen zu entdecken, die in einer Sammlung von Dokumenten vorhanden sind. Dabei werden Muster in den Wörtern und Sätzen, die in den Dokumenten vorkommen, identifiziert und anhand ihrer Ähnlichkeit in Themengruppen eingeteilt.
Im Gegensatz dazu ist das Clustering eine Technik, mit der ähnliche Objekte auf der Grundlage eines Ähnlichkeitsmaßes gruppiert werden. Solche Methoden werden eingesetzt, um Muster und Strukturen in Daten zu entdecken, indem ähnliche Datenpunkte gruppiert werden.
Obwohl beide Ansätze Muster in Textdaten aufdecken können, haben sie unterschiedliche Ziele. Bei der Themenmodellierung geht es darum, latente Themen in einer Sammlung von Dokumenten zu identifizieren, während es beim Clustering darum geht, ähnliche Datenpunkte zu gruppieren.
Die Textklassifizierung ist zwar eine Technik zur Verarbeitung natürlicher Sprache, fällt aber in die Kategorie des überwachten Lernens. Bei der Textklassifizierung geht es darum, vordefinierte Kategorien oder ein bestimmtes Stück Text zu kennzeichnen. Damit das Modell diese Leistung erbringen kann, muss es zunächst aus einem markierten Datensatz lernen, bevor es Vorhersagen für neue, ungesehene Textproben machen kann.
Andererseits ist die Themenmodellierung eine unüberwachte Lerntechnik, die dazu dient, die zugrunde liegenden Themen in einer Sammlung von Textdokumenten zu finden. Das bedeutet, dass es nicht aus einem markierten Datensatz lernen muss.
Der Unterschied zwischen den beiden Methoden besteht also darin, dass die Textklassifizierung dazu verwendet wird, dem Text vordefinierte Etiketten zuzuweisen, während die Themenmodellierung die zugrunde liegenden Themen in einer Sammlung von Dokumenten entdeckt.
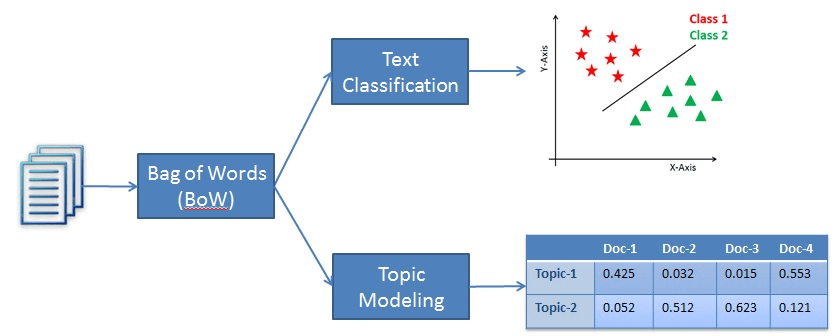
Ein Beispiel für Klassifizierung und Themenmodellierung
Die Themenmodellierung ist ein beliebtes Verfahren zur Verarbeitung natürlicher Sprache, mit dem strukturierte Daten aus einer Sammlung unstrukturierter Daten erstellt werden können. Mit anderen Worten: Die Technik ermöglicht es Unternehmen, die verborgenen semantischen Muster eines Textkorpus zu lernen und die darin enthaltenen Themen automatisch zu identifizieren.
Zwei beliebte Ansätze zur Themenmodellierung sind LSA und LDA. Beide versuchen, die versteckten Muster in Textdaten zu entdecken, aber sie gehen von unterschiedlichen Voraussetzungen aus, um ihr Ziel zu erreichen. Während LSA davon ausgeht, dass Wörter mit ähnlicher Bedeutung in ähnlichen Dokumenten vorkommen, geht LDA davon aus, dass die Dokumente aus Wörtern bestehen, die bei der Bestimmung der Themen helfen.
In diesem Tutorial haben wir die Kernkonzepte der Themenmodellierung, eine praktische Umsetzung und den Unterschied zwischen Themenmodellierung und anderen Techniken wie Textklassifizierung und Clustering behandelt. Um weiter zu lernen, schau dir einige unserer anderen Ressourcen an:
Beginne deine Reise zum Thema Modellierung noch heute!
Kurs
Kurs
Kurs