Curso
Introdução ao Processamento de Linguagem Natural em Python
4 h
141K
O objetivo da análise é obter insights a partir dos dados. Tradicionalmente, esses dados eram estruturados, ou seja, estavam em um formato padronizado para acesso eficiente. À medida que o mundo muda e se torna mais digitalizado, muitos dos dados que estão sendo gerados não são estruturados, o que significa que não há um modelo de dados predefinido.
De acordo com a Gartner, os dados não estruturados representam de 80 a 90% de todos os novos dados corporativos. Além disso, ele está crescendo três vezes mais rápido do que os dados estruturados. Como resultado, os especialistas em análise precisam empregar novas técnicas para obter informações relevantes de seus conjuntos de dados.
Uma dessas técnicas que está sendo aproveitada é a modelagem de tópicos do campo de mineração de texto. No restante deste artigo, abordaremos:
A modelagem de tópicos é uma abordagem usada com frequência para descobrir padrões semânticos ocultos retratados por um corpus de texto e identificar automaticamente os tópicos existentes nele.
Ou seja, é um tipo de modelagem estatística que aproveita o aprendizado de máquina não supervisionado para analisar e identificar clusters ou grupos de palavras semelhantes em um corpo de texto.
Por exemplo, um algoritmo de modelagem de tópicos pode ser implementado para determinar se o conteúdo de um documento implica que ele é uma fatura, uma reclamação ou um contrato.
De acordo com algumas fontes, uma pessoa comum gera mais de 1,7 MB de dados digitais por segundo. Esse número equivale a mais de 2,5 quintilhões de bytes de dados por dia, dos quais 80 a 90% não são estruturados.
Considere um cenário em que uma empresa emprega um único indivíduo para analisar cada dado não estruturado e segmentá-lo com base no tópico subjacente. Seria uma tarefa impossível.
Isso levaria um tempo significativo para ser concluído e seria extremamente tedioso, além de envolver um risco muito maior, pois os seres humanos são naturalmente tendenciosos e mais propensos a erros do que as máquinas.
A solução é a modelagem de tópicos.
Com a modelagem de tópicos, os insights dos dados podem ser obtidos com mais rapidez e, possivelmente, com mais qualidade. Essa técnica combina os tópicos em uma estrutura compreensível, permitindo que as empresas entendam rapidamente o que está acontecendo.
Por exemplo, uma empresa que deseja entender os maiores desafios dos clientes pode empregar a modelagem de tópicos para obter essas informações por meio de dados não estruturados.
Em resumo, a modelagem de tópicos ajuda as empresas a:
Estabelecemos que a modelagem de tópicos permite que os profissionais de dados analisem e identifiquem rapidamente clusters ou grupos de palavras semelhantes em um corpo de texto em escala.
Mas o que são tópicos e como funciona a modelagem de tópicos?
Os tópicos são as descrições latentes de um corpus (grande grupo) de texto. Intuitivamente, os documentos relacionados a um tópico específico têm maior probabilidade de produzir determinadas palavras com mais frequência.
Por exemplo, é mais provável que as palavras "dog" (cachorro) e "bone" (osso) apareçam em documentos sobre cachorros, enquanto "cat" (gato) e "meow" (miau) têm mais probabilidade de serem encontradas em documentos sobre gatos. Consequentemente, o modelo de tópico examinaria os documentos e produziria grupos de palavras semelhantes.
Essencialmente, os modelos de tópicos funcionam deduzindo palavras e agrupando outras semelhantes em tópicos para criar grupos de tópicos.
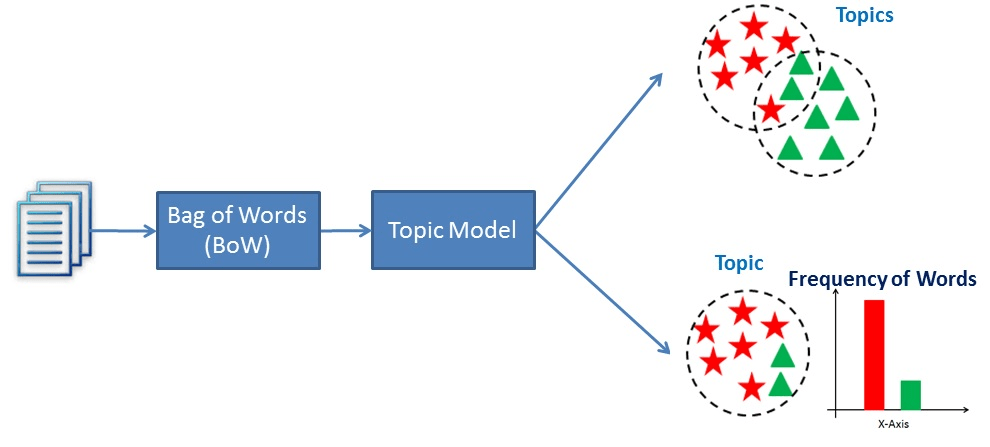
Uma visualização de como funciona a modelagem de tópicos
Duas técnicas populares de modelagem de tópicos são a Análise Semântica Latente (LSA) e a Alocação de Dirichlet Latente (LDA). Seu objetivo de descobrir padrões semânticos ocultos retratados por dados de texto é o mesmo, mas a forma de alcançá-lo é diferente.
A Análise Semântica Latente (LSA) é uma técnica de processamento de linguagem natural usada para analisar as relações entre documentos e os termos que eles contêm. O método foi apresentado pela primeira vez em um artigo de 1988 intitulado "Using Latent Semantic Analysis to Improve Access to Textual Information" (Usando a análise semântica latente para melhorar o acesso a informações textuais ) e ainda hoje é usado para criar dados estruturados a partir de uma coleção de textos não estruturados.
Ou seja, o LSA pressupõe que palavras com significados semelhantes aparecerão em documentos semelhantes. Para isso, ele constrói uma matriz que contém as contagens de palavras por documento, em que cada linha representa uma palavra exclusiva e as colunas representam cada documento, e depois usa uma Decomposição de Valor Singular (SVD) para reduzir o número de linhas e, ao mesmo tempo, preservar a estrutura de similaridade entre as colunas. A SVD é um método matemático que simplifica os dados e mantém seus recursos importantes. Ele é usado aqui para manter as relações entre palavras e documentos.
Para determinar a similaridade entre os documentos, é usada a similaridade de cosseno. Essa é uma medida que calcula o cosseno do ângulo entre dois vetores, nesse caso, representando documentos. Um valor próximo a 1 significa que os documentos são muito semelhantes com base nas palavras contidas neles, enquanto um valor próximo a 0 significa que eles são muito diferentes.
A alocação latente de Dirichlet (LDA) foi proposta inicialmente em 2000 em um artigo intitulado "Inference of population structure using multilocus genotype data". O artigo se concentrava predominantemente na genética populacional, que é um subcampo da genética que se preocupa com as diferenças genéticas dentro e entre as populações. Três anos depois, a alocação de Dirichlet latente foi aplicada no aprendizado de máquina.
Os autores do artigo descrevem a técnica como "um modelo generativo para texto e outras coleções de dados discretos". Assim, a LDA pode ser descrita como uma técnica de linguagem natural usada para identificar tópicos aos quais um documento pertence com base nas palavras contidas nele.
Mais especificamente, a LDA é uma rede bayesiana, o que significa que é um modelo estatístico generativo que pressupõe que os documentos são compostos de palavras que ajudam a determinar os tópicos. Assim, os documentos são mapeados para uma lista de tópicos, atribuindo cada palavra do documento a diferentes tópicos. Esse modelo ignora a ordem das palavras que ocorrem em um documento e as trata como um conjunto de palavras.
A Análise Semântica Latente (LSA) e a Alocação de Dirichlet Latente (LDA) são técnicas de processamento de linguagem natural usadas para criar dados estruturados a partir de uma coleção de textos não estruturados.
No entanto, o LSA utiliza a Decomposição de Valor Singular (SVD) para reduzir a dimensionalidade da matriz termo-documento e baseia-se na suposição de que palavras com significados semelhantes aparecerão em documentos semelhantes. Ao criar uma representação de menor dimensão do texto, o modelo pode capturar as relações subjacentes entre as palavras para determinar a semelhança entre dois documentos.
Por outro lado, a LDA é um modelo probabilístico generativo que aproveita a inferência bayesiana para encontrar os tópicos subjacentes em um corpus de textos. Ele pressupõe que cada documento é uma combinação de um pequeno número de tópicos latentes, e cada palavra é gerada por um tópico específico.
Em última análise, a LSA tenta descobrir as relações subjacentes entre as palavras, enquanto a LDA procura descobrir os tópicos subjacentes em um corpus de texto. Embora ambas as técnicas sejam usadas para criar uma representação vetorial do texto, elas têm pressupostos subjacentes diferentes.
Vamos ver como essas técnicas funcionam. Use este espaço de trabalho do DataCamp para acompanhar o código.
A primeira coisa que precisamos é de dados.
Para modelagem de tópicos, os dados que usamos são chamados de corpus, que é simplesmente uma coleção de textos.
Aqui está um pequeno corpus que criei usando fatos da Internet:
# Creating example documents
doc_1 = "A whopping 96.5 percent of water on Earth is in our oceans, covering 71 percent of the surface of our planet. And at any given time, about 0.001 percent is floating above us in the atmosphere. If all of that water fell as rain at once, the whole planet would get about 1 inch of rain."
doc_2 = "One-third of your life is spent sleeping. Sleeping 7-9 hours each night should help your body heal itself, activate the immune system, and give your heart a break. Beyond that--sleep experts are still trying to learn more about what happens once we fall asleep."
doc_3 = "A newborn baby is 78 percent water. Adults are 55-60 percent water. Water is involved in just about everything our body does."
doc_4 = "While still in high school, a student went 264.4 hours without sleep, for which he won first place in the 10th Annual Great San Diego Science Fair in 1964."
doc_5 = "We experience water in all three states: solid ice, liquid water, and gas water vapor."
# Create corpus
corpus = [doc_1, doc_2, doc_3, doc_4, doc_5]A próxima etapa é a limpeza do texto:
# Code source: https://www.analyticsvidhya.com/blog/2016/08/beginners-guide-to-topic-modeling-in-python/
import string
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('omw-1.4')
from nltk.corpus import stopwords
from nltk.stem.wordnet import WordNetLemmatizer
# remove stopwords, punctuation, and normalize the corpus
stop = set(stopwords.words('english'))
exclude = set(string.punctuation)
lemma = WordNetLemmatizer()
def clean(doc):
stop_free = " ".join([i for i in doc.lower().split() if i not in stop])
punc_free = "".join(ch for ch in stop_free if ch not in exclude)
normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split())
return normalized
clean_corpus = [clean(doc).split() for doc in corpus]No código acima, nós:
Mas isso ainda não significa que estamos prontos.
Antes de podermos usar esses dados como entrada para um modelo LDA ou LSA, eles devem ser convertidos em uma matriz termo-documento. Uma matriz termo-documento é simplesmente uma representação matemática de um conjunto de documentos e dos termos contidos neles.
Ele é criado contando a ocorrência de cada termo em cada documento e, em seguida, normalizando as contagens para criar uma matriz de valores que pode ser usada para análise.
Para fazer isso em Python, vamos aproveitar a biblioteca Gensim.
from gensim import corpora
# Creating document-term matrix
dictionary = corpora.Dictionary(clean_corpus)
doc_term_matrix = [dictionary.doc2bow(doc) for doc in clean_corpus]Agora, podemos ajustar nossos modelos.
O primeiro modelo que usaremos na LSA:
from gensim.models import LsiModel
# LSA model
lsa = LsiModel(doc_term_matrix, num_topics=3, id2word = dictionary)
# LSA model
print(lsa.print_topics(num_topics=3, num_words=3))
"""
[
(0, '0.555*"water" + 0.489*"percent" + 0.239*"planet"'),
(1, '0.361*"sleeping" + 0.215*"hour" + 0.215*"still"'),
(2, '-0.562*"water" + 0.231*"rain" + 0.231*"planet"')
]
"""Isso gera os tópicos (cada linha) com termos de tópicos individuais (termos) e seus pesos.
Vamos tentar com o LDA:
from gensim.models import LdaModel
# LDA model
lda = LdaModel(doc_term_matrix, num_topics=3, id2word = dictionary)
# Results
print(lda.print_topics(num_topics=3, num_words=3))
"""
[
(0, '0.071*"water" + 0.025*"state" + 0.025*"three"'),
(1, '0.030*"still" + 0.028*"hour" + 0.026*"sleeping"'),
(2, '0.073*"percent" + 0.069*"water" + 0.031*"rain"')
]
"""Ao remover tarefas manuais e repetitivas, a modelagem de tópicos pode acelerar os processos de forma simples e econômica. Aqui estão alguns exemplos:
A modelagem de tópicos pode ser usada para ajudar a equipe de atendimento ao cliente a analisar as consultas de suporte para identificar os principais problemas e determinar aqueles que ocorrem repetidamente. Com base nesses dados, eles podem criar conteúdo de autoatendimento mais informativo ou ajudar os clientes diretamente.
A modelagem de tópicos pode ser usada para marcar conversas de modo que elas possam ser encaminhadas para a equipe mais adequada. Por exemplo, uma conversa que inclua palavras como "preço", "assinatura", "renovação" etc. poderia ser enviada diretamente para o departamento de contabilidade para obter suporte.
A modelagem de tópicos é usada para descobrir tópicos latentes que existem em uma coleção de documentos. Isso envolve a identificação de padrões nas palavras e frases que aparecem nos documentos e o agrupamento delas em tópicos com base na semelhança entre elas.
Por outro lado, o agrupamento é uma técnica usada para agrupar objetos semelhantes com base em uma medida de similaridade. Esses métodos são empregados para descobrir padrões e estruturas nos dados, agrupando pontos de dados semelhantes.
Embora ambas as abordagens possam descobrir padrões em dados de texto, elas têm objetivos diferentes. A modelagem de tópicos se preocupa com a identificação de tópicos latentes em uma coleção de documentos, enquanto o agrupamento se preocupa com o agrupamento de pontos de dados semelhantes.
A classificação de texto, embora seja uma técnica de processamento de linguagem natural, se enquadra na categoria de aprendizado supervisionado. Ou seja, a classificação de texto é empregada para rotular categorias predefinidas ou um determinado trecho de texto. Para que o modelo consiga essa façanha, ele deve primeiro aprender com um conjunto de dados rotulados antes de poder ser usado para fazer previsões em amostras de texto novas e não vistas.
Por outro lado, a modelagem de tópicos é uma técnica de aprendizado não supervisionada usada para encontrar os tópicos subjacentes em uma coleção de documentos de texto. Isso significa que ele não precisa aprender com um conjunto de dados rotulados.
Assim, a diferença entre os dois métodos é que a classificação de texto é usada para atribuir rótulos predefinidos ao texto, enquanto a modelagem de tópicos descobre os tópicos subjacentes em uma coleção de documentos.
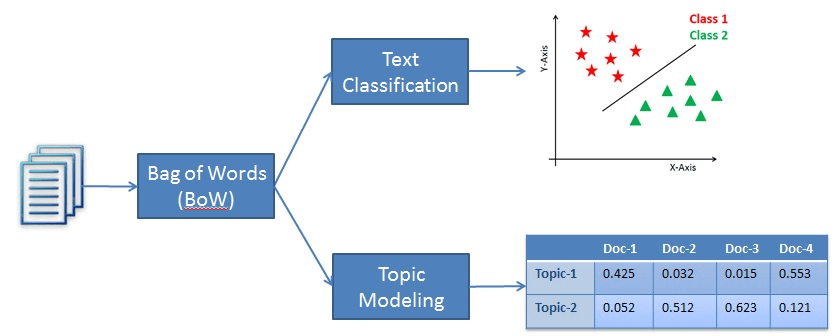
Um exemplo de classificação versus modelagem de tópicos
A modelagem de tópicos é uma técnica popular de processamento de linguagem natural usada para criar dados estruturados a partir de uma coleção de dados não estruturados. Em outras palavras, a técnica permite que as empresas aprendam os padrões semânticos ocultos retratados por um corpus de texto e identifiquem automaticamente os tópicos existentes nele.
Duas abordagens populares de modelagem de tópicos são LSA e LDA. Ambos buscam descobrir os padrões ocultos nos dados de texto, mas fazem suposições diferentes para atingir seu objetivo. Enquanto a LSA pressupõe que palavras com significados semelhantes aparecerão em documentos semelhantes, a LDA pressupõe que os documentos são compostos de palavras que ajudam a determinar os tópicos.
Neste tutorial, abordamos os principais conceitos de modelagem de tópicos, uma implementação prática e como a modelagem de tópicos difere de outras técnicas, como classificação e agrupamento de texto. Para continuar seu aprendizado, confira alguns de nossos outros recursos:
Comece sua jornada de modelagem de tópicos hoje mesmo!
Curso
Curso
Curso
blog
Tim Lu
12 min
blog
Natassha Selvaraj
15 min
blog
Javier Canales Luna
12 min
blog
Matt Crabtree
10 min
Tutorial
Somil Asthana
Tutorial
Josep Ferrer


