programa
Ingeniero de datos en Python
40 h
Apache Spark y Apache Flink son dos marcos de procesamiento de datos de código abierto muy utilizados para big data y analítica. Aunque ambas destacan como potentes herramientas con sólidas capacidades de procesamiento de datos, difieren en su arquitectura y funcionalidades clave.
Exploraremos las características clave de Spark y Flink, centrándonos en los modelos de procesamiento, las abstracciones de datos, la gestión de estados y el rendimiento. También exploraremos cómo maneja cada marco el procesamiento de datos por lotes y en tiempo real. Comprender sus diferencias y similitudes te ayudará a elegir el marco adecuado a tus necesidades.
Todos sabemos que el volumen de datos disponibles crece exponencialmente. Las organizaciones que intentan hacer uso del big data pueden encontrarse con retos de escalabilidad y eficiencia.
Los marcos de procesamiento de datos son una solución muy necesaria porque pueden admitir diversas operaciones de datos, como la ingestión, la transformación y el almacenamiento, incluso cuando se trabaja con terabytes de datos. Proporcionan un amplio espectro de herramientas y API, dándote flexibilidad para realizar tareas que van desde las operaciones básicas hasta el modelado de aprendizaje automático. Además, los marcos de procesamiento de datos te ofrecen una abstracción de la complejidad que simplifica los procesos de desarrollo y depuración de las aplicaciones de procesamiento de datos.
En términos generales, los marcos de procesamiento de datos funcionan distribuyendo la carga de trabajo entre varios nodos de un clúster. Algunos marcos están especialmente pensados para procesar datos en tiempo real, lo que te permite analizar los datos a medida que llegan. Otros están optimizados para procesar datos por lotes, lo que resulta útil para tus análisis retrospectivos.
Apache Spark es un marco informático distribuido de código abierto diseñado para manejar grandes volúmenes de datos de forma eficiente y rápida. Utiliza un modelo de programación en memoria, lo que implica que puede almacenar datos en la memoria principal de los nodos del clúster, lo que acelera significativamente el procesamiento en comparación con otras herramientas que se basan más en el acceso al disco. Su interfaz fácil de usar te permite realizar operaciones de datos complejas a través de un conjunto de API en varios lenguajes, como Python y R, dos de los principales lenguajes para la Ciencia de Datos.
Apache Spark puede ejecutar operaciones de forma resiliente, lo que significa que puede tolerar fallos en los nodos del clúster y recuperarse automáticamente. Esta potente característica se debe a su componente, el Conjunto de Datos Distribuido Resistente (RDD), que es una colección distribuida de unidades básicas que contienen registros de datos.
Por otro lado, el modelo de ejecución de Spark, Directed Acyclic Graph (DAG), te permite optimizar la forma de ejecutar tus tareas en paralelo. Este componente permite a Spark distribuir las tareas entre distintos nodos de un mismo cluster, aprovechando todos los recursos disponibles.
 Características principales de Apache SparkCaracterísticas principales de Apache Spark. Fuente
Características principales de Apache SparkCaracterísticas principales de Apache Spark. Fuente
Apache Flink es un sistema de procesamiento de datos de código abierto que destaca cuando necesitas analizar datos en tiempo real y procesar grandes datos con baja latencia y alto rendimiento. Utilizando la misma infraestructura, Apache Flink también puede procesar datos por lotes, lo que representa una gran ventaja cuando necesitas construir y ejecutar canalizaciones de datos complejas que procesen datos en tiempo real en sistemas distribuidos. Ofrece un conjunto de API en varios lenguajes, incluidos Python y R, y bibliotecas especializadas que te ayudan a construir canalizaciones de procesamiento de eventos de aprendizaje automático.
Apache Flink trata tus datos como flujos continuos de eventos, lo que resulta útil en aplicaciones en las que los datos se reciben y procesan constantemente. Este modelo de programación basado en el flujo es una característica clave que conduce a una baja latencia en la respuesta a los eventos. Además, puedes construir pipelines de procesamiento de datos complejos y altamente personalizados utilizando las operaciones de Apache Flink.
Flink gestiona eficazmente el estado en aplicaciones de procesamiento de datos en tiempo real. Esto significa que puedes mantener y actualizar el estado de tus aplicaciones a medida que llegan los datos, con tolerancia a fallos.
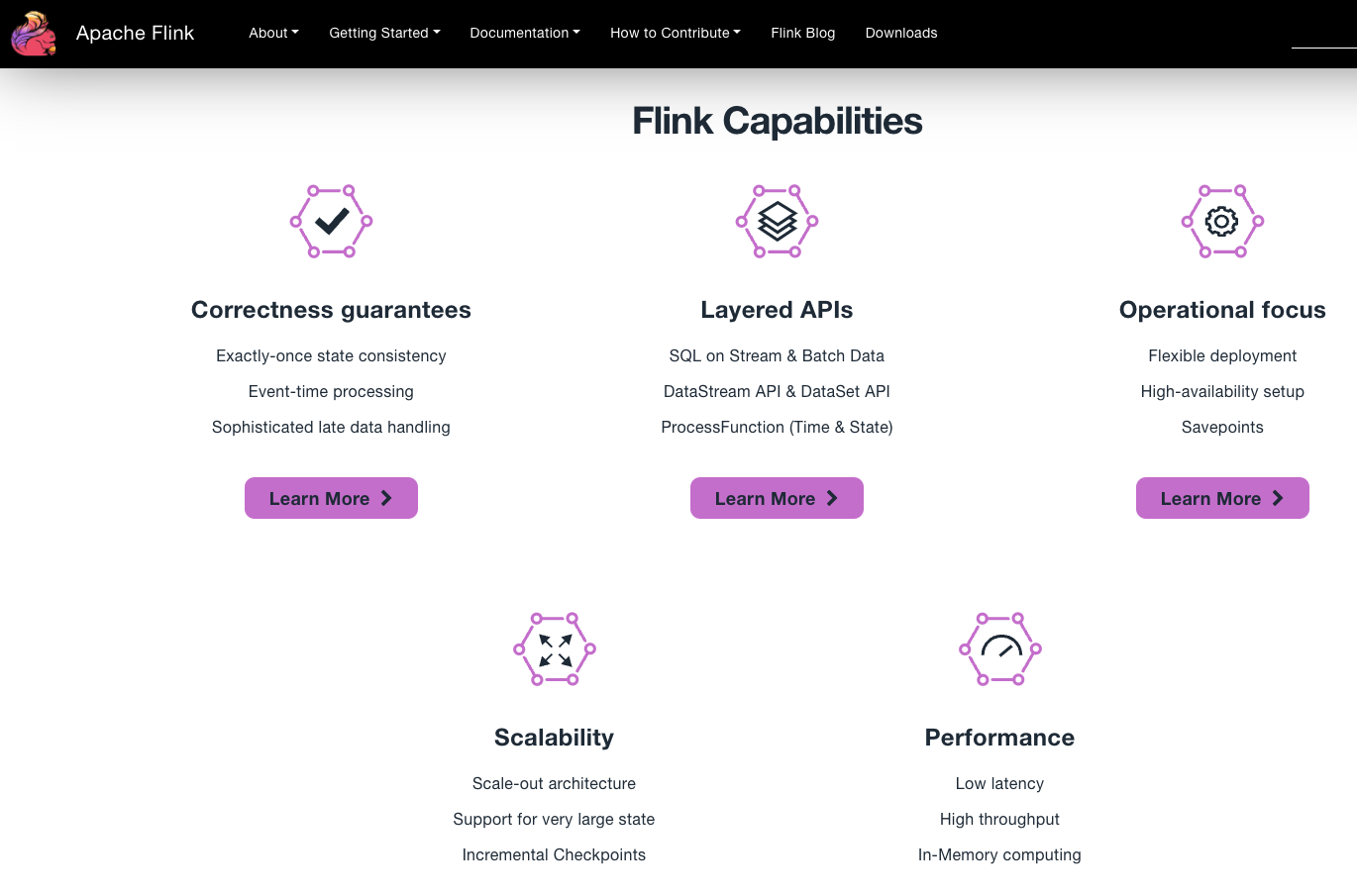 principales de principales de . Fuente
principales de principales de . Fuente
Aprovechar las características de un marco de procesamiento de datos adecuado puede ayudarte a mejorar el rendimiento y la eficacia de tu canalización de datos. Entre todas las características que ofrecen Spark y Flink, hay algunos puntos clave que debes evaluar a la hora de elegir entre estas herramientas:
Aunque Spark y Flink tienen rasgos distintivos clave, comparten varias características importantes. Ambos están diseñados para realizar tareas de procesamiento de datos a gran escala con baja latencia. Ambas ofrecen un conjunto de API en varios lenguajes, como Python, Scala, Java y R, y están integradas en un ecosistema más amplio de herramientas de big data. Además, Spark y Flink implementan optimizaciones de rendimiento.
Veamos cada una de estas similitudes:
Apache Flink y Apache Spark están diseñados para procesar grandes volúmenes de datos en un clúster de ordenadores. Esta función te permite escalar horizontalmente tu aplicación para manejar enormes conjuntos de datos, asignando y desasignando dinámicamente recursos a la carga de trabajo en varios nodos con baja latencia. Ambos marcos pueden procesar datos por lotes y en flujo.
Tanto Spark como Flink proporcionan API de alto nivel y abstracciones implementadas en varios lenguajes, como Scala, Python y Java, que te permiten escribir y ejecutar canalizaciones en tu lenguaje preferido. Estas API facilitan el uso de estos marcos a la hora de desarrollar aplicaciones de procesamiento de datos. Además, Flink incluye bibliotecas para el aprendizaje automático (FlinkML), el procesamiento de eventos complejos (FlinkCEP) y el procesamiento de grafos (Gelly). Spark también ofrece bibliotecas para el aprendizaje automático (MLlib), el procesamiento de gráficos (GraphX) y el procesamiento de datos en tiempo real (GraphX).
Tanto Apache Spark como Apache Flink se integran con un exhaustivo ecosistema de herramientas de big data, que incluye Hadoop Distributed File System, Apache Kafka y sistemas de almacenamiento en la nube como Amazon S3.
Ambos marcos tienen una implementación de optimización del rendimiento que maximiza la eficacia en el procesamiento de datos. Esta función te permite realizar tareas complejas aprovechando la ejecución paralela de Spark y Flink, la planificación de tareas y la optimización de consultas. Spark emplea el optimizador Catalyst, mientras que Flink tiene un optimizador basado en costes para el procesamiento por lotes.
Apache Spark y Apache Flink comparten muchas similitudes cuando se consideran sus capacidades básicas y sus enfoques de procesamiento de datos. Sin embargo, también tienen diferencias significativas en cuanto a los puntos fuertes y las áreas de interés de sus modelos de procesamiento, la madurez de sus ecosistemas y el soporte lingüístico, y su enfoque de la optimización y la gestión del estado.
Apache Flink se centra principalmente en el procesamiento de datos en tiempo real. Porque este marco está construido sobre su tiempo de ejecución de streaming y también puede manejar el procesamiento por lotes. Por otro lado, Apache Spark se diseñó originalmente para el procesamiento por lotes, por lo que es más adecuado para el análisis retrospectivo de grandes conjuntos de datos. Al aplicar un enfoque de microlotes, Spark también puede procesar datos en flujo, pero con latencias que resultan superiores a las de Flink.
Como ya se ha dicho, ambos marcos proporcionan API en varios lenguajes de programación. Sin embargo, la compatibilidad de Flink con Python es menos madura, lo que puede representar una limitación si trabajas con un equipo centrado en la ciencia de datos.
Aunque ambos marcos tienen una buena integración con las herramientas de big data, Apache Spark tiene un ecosistema mayor y más maduro, que incluye una gran variedad de conectores, bibliotecas y herramientas disponibles. Apache Flink está aumentando el conjunto de herramientas y extensiones disponibles, pero aún puede considerarse un ecosistema menos maduro.

Ecosistema Apache Spark. Fuente
Apache Flink te permite trabajar con una gestión de estado más avanzada y flexible, lo que puede representar una ventaja si trabajas con pipelines que necesitan mantener y actualizar el estado en tiempo real, como el procesamiento de ventanas en tiempo de eventos y en tiempo de procesamiento, o ventanas para manejar patrones de eventos complejos. Spark te permite realizar una funcionalidad básica de ventanas que funciona bien cuando se requiere un procesamiento por lotes y microlotes.
Apache Flink y Apache Spark muestran muchas similitudes, pero también difieren sustancialmente en su enfoque de procesamiento y en la latencia, rendimiento y gestión de estados asociados. Además, tienen una madurez del ecosistema y un soporte lingüístico ligeramente diferentes. El marco que elijas dependerá principalmente de los requisitos específicos de tu proyecto. Sin embargo, hay algunas características en las que Spark o Flink destacan entre sí:
Spark se diseñó originalmente para el procesamiento por lotes, pero ahora admite el streaming de datos a través de su módulo Spark Streaming. Flink, por su parte, se desarrolló específicamente para el flujo de datos, pero ahora también admite el procesamiento por lotes.
Spark emplea conjuntos de datos distribuidos resistentes y técnicas de partición de datos para impulsar el procesamiento paralelo y optimizar el uso de recursos. Flink aprovecha el encadenamiento de operadores y la ejecución en pipeline, mejorando su eficacia de procesamiento paralelo y gestión de recursos. En general, Flink se considera más rápido y ofrece mejor rendimiento en aplicaciones de procesamiento en tiempo real.
Spark proporciona funciones básicas de ventana, adecuadas principalmente para implementaciones basadas en el tiempo, que se ajustan bien a ventanas de tiempo fijas o deslizantes, tanto para el procesamiento de datos por lotes como en flujo. Flink dispone de funciones de ventana más avanzadas, como ventanas basadas en el tiempo de eventos y de procesamiento, ventanas de sesión y funciones de ventana personalizadas. Las capacidades de ventana de Flink son notablemente más versátiles y eficientes, lo que lo convierte en la opción preferida para necesidades complejas.
Spark utiliza el optimizador Catalyst, que destaca en la optimización de la transformación de datos y el procesamiento de consultas, e integra el motor de ejecución Tungsten para mejorar el rendimiento del marco. Flink cuenta con un optimizador basado en costes, diseñado específicamente para tareas de procesamiento por lotes, que evalúa los recursos disponibles y las características de los datos para seleccionar el enfoque más eficiente. Además, la ejecución basada en canalizaciones y la programación de baja latencia de Flink mejoran significativamente la velocidad de procesamiento de los datos. La elección entre Spark y Flink para la optimización depende de los casos de uso específicos, ya que ambos ofrecen ventajas distintas.
Spark consigue la tolerancia a fallos mediante el uso de Conjuntos de Datos Distribuidos Resistentes (RDD), que son estructuras de datos particionadas inmutables que permiten una rápida reconstrucción en caso de fallos. Flink, por su parte, utiliza un enfoque distribuido basado en instantáneas, capturando el estado de la aplicación en puntos de control específicos, lo que facilita una rápida recuperación ante fallos con un impacto mínimo en el rendimiento. Aunque ambos marcos proporcionan una tolerancia eficaz a los fallos, el método de Flink suele dar como resultado tiempos de recuperación más rápidos y menos interrupciones de los procesos en curso, lo que lo convierte en la opción preferible en escenarios en los que minimizar el tiempo de inactividad es fundamental.
Spark es compatible con una serie de lenguajes de programación, como Scala, Java, Python y R, lo que lo hace muy atractivo tanto para desarrolladores como para científicos de datos debido a su amplio potencial de colaboración y a un completo conjunto de API para estos lenguajes. Flink, aunque admite Java, Scala y Python con API intuitivas y fáciles de usar, ofrece capacidades más limitadas de Python, lo que puede dificultar su adopción entre los equipos de ciencia de datos. El soporte superior de Python de Spark lo hace más atractivo para los equipos centrados en datos en los que se utiliza predominantemente Python.
Spark cuenta con un ecosistema completo y maduro, que se integra a la perfección con una amplia gama de herramientas de big data como Hadoop, Hive y Pig, entre otras. Esta amplia compatibilidad hace de Spark una opción sólida para entornos de datos complejos que requieren diversos conjuntos de herramientas. Flink tiene una gama más limitada de integraciones con otras herramientas de big data, aunque destaca por su integración con Apache Kafka. Debido a sus integraciones más completas y maduras, Spark presenta generalmente un ecosistema más fuerte.
A continuación encontrarás una tabla que resume las principales diferencias entre Spark y Flink:
| Categorías | Chispa | Flink | Ganador |
|---|---|---|---|
| Tratamiento de datos | Modelo orientado a lotes | Modelo orientado al tiempo real | Depende |
| Rendimiento | RDDs y partición de datos | Encadenamiento de operadores y ejecución en cadena | Flink |
| Windowing | Funcionalidades basadas en el tiempo | Tiempo de evento, sesión y funciones personalizadas | Flink |
| Optimización | Optimizador de catalizadores | Optimizador basado en costes | Depende |
| Tolerancia a fallos | Conseguido por los RDD | Instantáneas distribuidas | Flink |
| Soporte de idiomas y API | Apoyo integral | Varios lenguajes, Python no avanzado | Chispa |
| Ecosistema | Integración total con herramientas de big data | Integración con algunas herramientas, destaca con Kafka | Chispa |
Elegir el marco de procesamiento de datos más adecuado puede mejorar el rendimiento de tu canalización de datos. Entre todos los marcos de trabajo, Apache Spark y Apache Flink destacan como dos herramientas potentes y versátiles con sus puntos fuertes y capacidades distintas.
Spark es excelente para el procesamiento por lotes, ya que ofrece una gran variedad de herramientas, API y una integración total con otras tecnologías de big data. Si estás interesado en aprender a utilizar Spark desde Python, consulta nuestro curso Introducción a PySpark y nuestro tutorial Introducción a Pyspark. Flink destaca para el procesamiento de datos en tiempo real y en streaming porque ofrece una gestión eficaz del estado, funcionalidades de ventanas y un rendimiento de baja latencia.
En última instancia, la elección entre estos dos marcos dependerá de los requisitos y necesidades específicos de tu proyecto. Para entender bien estas herramientas, lo mejor es que sigas leyendo y practiques con los siguientes recursos.
Aprende con DataCamp
programa
Curso
Curso
blog
Tim Lu
11 min
blog
Gus Frazer
14 min
blog
DataCamp Team
12 min
Tutorial
Natassha Selvaraj
Tutorial
Amberle McKee
Tutorial
Zoumana Keita

