Comprender cómo fluyen los datos y aprovechar su potencial se ha convertido en algo absolutamente crítico para las organizaciones modernas. Kafka es la plataforma líder para ingerir, almacenar y procesar flujos de datos en tiempo real en el panorama de las aplicaciones modernas.
En este post, esbozaremos algunas preguntas de entrevista sobre Kafka y exploraremos el papel crucial de la herramienta en el procesamiento de datos. Exploraremos distintos niveles de preguntas de entrevista, desde las básicas hasta las avanzadas, y te daremos consejos para que te prepares eficazmente. Si eres nuevo en Kafka, no dejes de consultar nuestro curso Introducción a Apache Kafka.
Preguntas básicas de la entrevista sobre Kafka
Estas preguntas pondrán a prueba tus conocimientos básicos de Kafka como herramienta para la ingeniería de datos.
1. ¿Qué es Apache Kafka?
Apache Kafka es una potente plataforma distribuida de flujo de eventos de código abierto. Desarrollado originalmente por LinkedIn como una cola de mensajería, ha evolucionado hasta convertirse en una herramienta para manejar flujos de datos en diversos escenarios.
La arquitectura de sistema distribuido de Kafka permite la escalabilidad horizontal, permitiendo a los consumidores recuperar mensajes a su propio ritmo y facilitando la adición de nodos Kafka (servidores) al clúster.
Kafka está diseñado para procesar grandes cantidades de datos rápidamente con baja latencia. Aunque está escrito en Scala y Java, admite una amplia gama de lenguajes de programación.

Apache Kafka actúa como un recopilador de registros distribuido, en el que los mensajes de registro se almacenan como pares clave-valor en un archivo de registro de sólo apéndice para un almacenamiento y recuperación duraderos y a largo plazo. A diferencia de las colas de mensajes tradicionales como RabbitMQ, que eliminan los mensajes una vez consumidos, Kafka retiene los mensajes durante un periodo configurable, lo que lo hace ideal para casos de uso que requieren la repetición de datos o la obtención de eventos.
Mientras que RabbitMQ se centra en la entrega de mensajes en tiempo real sin almacenarlos a largo plazo, la política de retención de Kafka admite aplicaciones más complejas y basadas en datos.
Los casos de uso habituales de Kafka incluyen el seguimiento de aplicaciones, la agregación de registros y la mensajería, aunque carece de las funciones tradicionales de las bases de datos, como la consulta y la indexación. Su punto fuerte es el manejo de flujos de datos en tiempo real, lo que lo hace indispensable para los sistemas distribuidos y la analítica en tiempo real.
2. ¿Cuáles son algunas de las características de Kafka?
Apache Kafka es una plataforma de streaming distribuido de código abierto ampliamente utilizada para construir canalizaciones de datos en tiempo real y aplicaciones de streaming. Ofrece las siguientes prestaciones:
1. Alto rendimiento
Kafka es capaz de manejar volúmenes masivos de datos. Está diseñado para leer y escribir cientos de gigabytes desde clientes fuente de forma eficiente.
2. Arquitectura distribuida
Apache Kafka tiene una arquitectura centrada en clústeres y admite intrínsecamente la partición de mensajes entre servidores Kafka. Este diseño también permite el consumo distribuido a través de un clúster de máquinas consumidoras, todo ello conservando el orden de los mensajes dentro de cada partición. Además, un clúster de Kafka puede escalar de forma elástica y transparente, sin necesidad de tiempo de inactividad.
3. Apoyo a varios clientes
Apache Kafka admite la integración de clientes de distintas plataformas, como .NET, JAVA, PHP y Python.
4. Mensajes en tiempo real
Kafka produce mensajes en tiempo real que deben ser visibles para los consumidores; esto es importante para los sistemas complejos de procesamiento de eventos.
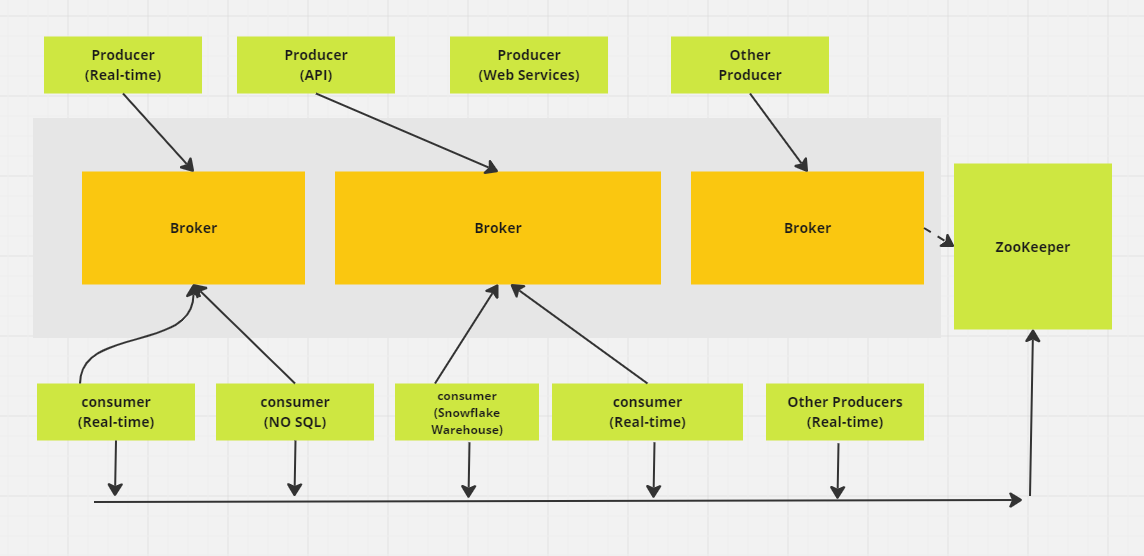
Sistema distribuido de mensajería Apache Kafka. (Imagen del autor)
3. ¿Cómo funcionan las Particiones en Kafka?
En Kafka, un tema sirve como espacio de almacenamiento donde se guardan todos los mensajes de los productores. Normalmente, los datos relacionados se almacenan en temas separados. Por ejemplo, un tema llamado "transacciones" almacenaría los detalles de las compras de los usuarios en un sitio de comercio electrónico, mientras que un tema llamado "clientes" contendría información sobre los clientes.
Los temas se dividen en particiones. Por defecto, un tema tiene una partición, pero puedes configurarlo para que tenga más. Los mensajes se distribuyen a través de estas particiones, teniendo cada partición su propio desplazamiento y almacenándose en un servidor diferente del clúster Kafka.
Por ejemplo, si un tema tiene tres particiones en tres corredores, y un productor envía 15 mensajes, los mensajes se distribuyen en secuencia:
- El registro 1 va a la Partición 0
- El registro 2 va a la Partición 1
- El registro 3 va a la Partición 2
Luego el ciclo se repite, y el Registro 4 vuelve a la Partición 0, y así sucesivamente.
4. ¿Por qué elegir Kafka en lugar de otros servicios de mensajería?
La elección de Kafka frente a otros servicios de mensajería a menudo se reduce a sus puntos fuertes únicos, especialmente para casos de uso que necesitan un alto rendimiento y procesamiento de datos en tiempo real. He aquí por qué destaca Kafka:
- Alto rendimiento y escalabilidad: Kafka puede manejar grandes volúmenes de datos de forma eficiente. Su arquitectura admite el escalado horizontal, lo que te permite añadir más corredores y particiones para gestionar cargas de datos cada vez mayores sin sacrificar el rendimiento.
- Procesamiento en tiempo real: Es excelente para la transmisión de datos en tiempo real, lo que la hace perfecta para casos de uso como el seguimiento de la actividad y la supervisión operativa. Por ejemplo, LinkedIn creó Kafka para gestionar su canal de seguimiento de la actividad, lo que le permite publicar feeds en tiempo real de las interacciones de los usuarios, como clics y me gusta.
- Repetición del mensaje: Kafka permite a los consumidores reproducir mensajes, lo que resulta útil si un consumidor encuentra un error o se sobrecarga. Esto garantiza que no se pierdan datos: los consumidores pueden recuperar y reproducir los mensajes perdidos para mantener la integridad de los datos.
- Durabilidad y tolerancia a fallos: La herramienta replica los datos en varios corredores, garantizando la fiabilidad incluso si algunos fallan. Este diseño tolerante a fallos mantiene los datos accesibles, proporcionando seguridad a las operaciones críticas.
5. Explica todas las API que proporciona Apache Kafka.
Una API (Interfaz de Programación de Aplicaciones) permite la comunicación entre diferentes servicios, microservicios y sistemas. Kafka proporciona un conjunto de APIs diseñadas para construir plataformas de streaming de eventos e interactuar con su sistema de mensajería.
Las principales API de Kafka son
- API del productor: Se utiliza para enviar datos en tiempo real a temas Kafka. Los productores determinan a qué partición dentro de un tema debe ir cada mensaje, con llamadas de retorno que gestionan el éxito o el fracaso de las operaciones de envío.
- API del consumidor: Permite leer datos en tiempo real de temas Kafka. Los consumidores pueden formar parte de un grupo de consumidores para equilibrar la carga y procesar en paralelo, suscribiéndose a temas y sondeando continuamente Kafka en busca de nuevos mensajes.
- API de flujos: Admite la creación de aplicaciones en tiempo real que transforman, agregan y analizan datos dentro de Kafka. Ofrece un DSL (Lenguaje Específico de Dominio) de alto nivel para definir la lógica compleja del procesamiento de flujos.
- API de conexión Kafka: Se utiliza para crear y ejecutar conectores reutilizables para importar y exportar datos entre Kafka y sistemas externos.
- Admin API: Proporciona herramientas para gestionar y configurar temas Kafka, brokers y otros recursos para garantizar un funcionamiento y una escalabilidad sin problemas.
Estas API permiten la producción, el consumo, el procesamiento y la gestión de datos sin fisuras dentro de Kafka.
Preguntas de la entrevista sobre Kafka intermedio
Estas preguntas están dirigidas a profesionales más experimentados que ya conocen bien los usos de Kafka.
6. ¿Qué implicaciones tiene aumentar el número de particiones en un tema Kafka?
Aumentar el número de particiones en un tema Kafka puede mejorar la concurrencia y el rendimiento al permitir que más consumidores lean en paralelo. Sin embargo, también introduce ciertos retos:
- Aumento de la sobrecarga del clúster: Más particiones consumen recursos adicionales del clúster, lo que conlleva un mayor tráfico de red para la replicación y mayores requisitos de almacenamiento.
- Posible desequilibrio de los datos: A medida que aumentan las particiones, es posible que los datos no se distribuyan uniformemente, lo que puede provocar que algunas particiones se sobrecarguen mientras otras permanecen infrautilizadas.
- Gestión de grupos de consumidores más compleja: Con más particiones, la gestión de las asignaciones de grupos de consumidores y el seguimiento de las compensaciones se vuelven más complicados.
- Tiempos de reequilibrio más largos: Cuando los consumidores se unen o se van, reequilibrar las particiones en el grupo puede llevar más tiempo, lo que afecta a la capacidad de respuesta general del sistema.
7. Explica los cuatro componentes de la arquitectura Kafka
Kafka es una arquitectura distribuida formada por varios componentes clave:
Nodos intermediarios
La arquitectura distribuida de Kafka consta de varios componentes clave, uno de los cuales es el nodo intermediario. Los intermediarios se encargan del trabajo pesado de las operaciones de entrada/salida y gestionan el almacenamiento duradero de los mensajes. Reciben datos de los productores, los almacenan y los ponen a disposición de los consumidores. Cada corredor forma parte de un clúster Kafka y tiene un ID único para ayudar a la coordinación.
En versiones anteriores de Kafka, el clúster se gestiona mediante Zookeeper, que garantiza una coordinación adecuada entre los corredores y realiza un seguimiento de metadatos como la ubicación de las particiones (aunque Kafka está avanzando hacia un modo interno de KRaft para esto). Los brokers Kafka son altamente escalables y capaces de gestionar grandes volúmenes de solicitudes de lectura y escritura de mensajes a través de sistemas distribuidos.
Nodos ZooKeeper
ZooKeeper desempeña un papel crucial en Kafka al gestionar el registro de intermediarios y elegir al controlador de Kafka, que se encarga de las operaciones administrativas del clúster. ZooKeeper funciona como un clúster en sí mismo, llamado conjunto, en el que varios procesos trabajan juntos para garantizar que sólo se asigna como controlador a un corredor a la vez.
Si el controlador actual falla, ZooKeeper elige rápidamente un nuevo controlador para que tome el relevo. Aunque ZooKeeper ha sido una parte esencial de la arquitectura de Kafka, Kafka está pasando a un nuevo modo KRaft que elimina la necesidad de ZooKeeper. ZooKeeper es un proyecto independiente de código abierto y no un componente nativo de Kafka.
Productores
Un productor de Kafka es una aplicación cliente que sirve como fuente de datos para Kafka, publicando registros en uno o más temas de Kafka mediante conexiones TCP persistentes con los brokers.
Varios productores pueden enviar registros al mismo tema simultáneamente. Los temas de Kafka son de sólo adición, lo que significa que los productores pueden escribir nuevos datos, pero ni los productores ni los consumidores pueden modificar o eliminar los registros existentes, lo que garantiza la inmutabilidad de los datos.
Consumidores
Un consumidor Kafka es una aplicación cliente que se suscribe a uno o varios temas Kafka para consumir flujos de registros. Los consumidores suelen trabajar en grupos de consumidores, donde la carga de lectura y procesamiento de registros se distribuye entre varios consumidores.
Cada consumidor hace un seguimiento de su progreso a través del flujo manteniendo los desplazamientos, lo que garantiza que ningún dato se procese dos veces y que no se pierdan los registros no procesados. Los consumidores de Kafka actúan como paso final en la canalización de datos, donde se procesan los registros o se reenvían a sistemas posteriores.
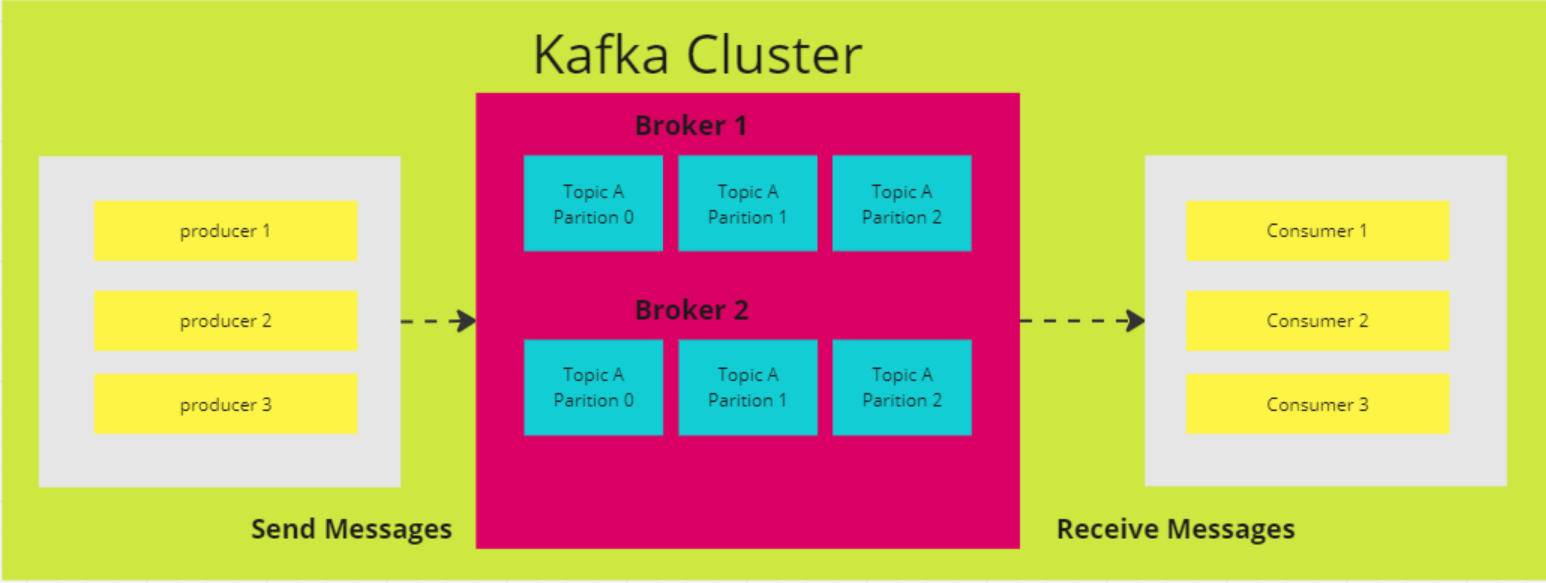
Diagrama de arquitectura de Apache Kafka (Imagen del autor)
8. ¿Cuál es el objetivo principal de la compactación de logs en Kafka? ¿Cómo afecta la compactación de logs al rendimiento de los consumidores Kafka?
El objetivo principal de la compactación del registro en Kafka es conservar el valor más reciente para cada clave única en el registro de un tema, garantizando que se conserva el estado más reciente de los datos y reduciendo el uso de almacenamiento. Esto permite a los consumidores acceder al valor actual de forma más eficiente, sin tener que procesar duplicados antiguos.
A diferencia de la política de retención tradicional de Kafka, que borra los mensajes después de un determinado periodo de tiempo, la compactación de registros borra los registros más antiguos sólo para cada clave, conservando el valor más reciente para esa clave. Esta función ayuda a garantizar que los consumidores siempre tengan acceso al estado actual, manteniendo un registro compacto para una mayor eficacia de almacenamiento y búsquedas más rápidas.
9. ¿Cuál es la diferencia entre Particiones y Réplicas en un clúster Kafka?
Las particiones y réplicas son componentes clave de la arquitectura de Kafka, que garantizan tanto el rendimiento como la tolerancia a fallos. Las particiones aumentan el rendimiento al permitir que un tema se divida en varias partes, lo que permite a los consumidores leer de diferentes particiones en paralelo, lo que mejora la escalabilidad y eficiencia de Kafka.
Las réplicas, por otro lado, proporcionan redundancia creando copias de las particiones en varios corredores. Esto garantiza la tolerancia a fallos porque, en caso de fallo de un broker líder (el broker que gestiona las operaciones de lectura y escritura de una partición), una de las réplicas seguidoras puede ser promocionada para asumir el papel de nuevo líder.
Kafka mantiene múltiples réplicas de cada partición para garantizar una alta disponibilidad y durabilidad de los datos, minimizando el riesgo de pérdida de datos durante los fallos, aunque la durabilidad total depende de la configuración de la replicación.
10. ¿Qué es un esquema en Kafka y por qué es importante para los sistemas distribuidos?
En Kafka, un esquema define la estructura y el formato de los datos, como los campos CustomerID (entero), CustomerName (cadena) y Designation (cadena).
En sistemas distribuidos como Kafka, productores y consumidores deben ponerse de acuerdo sobre el formato de los datos para evitar errores al intercambiarlos. El Registro de Esquemas de Kafka gestiona y hace cumplir estos esquemas, garantizando que tanto productores como consumidores utilicen versiones compatibles.
El Registro de Esquemas almacena esquemas (normalmente en formatos como Avro, Protobuf o JSON Schema) y admite la evolución de esquemas, permitiendo que los formatos de datos cambien sin romper los consumidores existentes. Esto garantiza un intercambio de datos fluido y la fiabilidad del sistema a medida que evolucionan los esquemas.
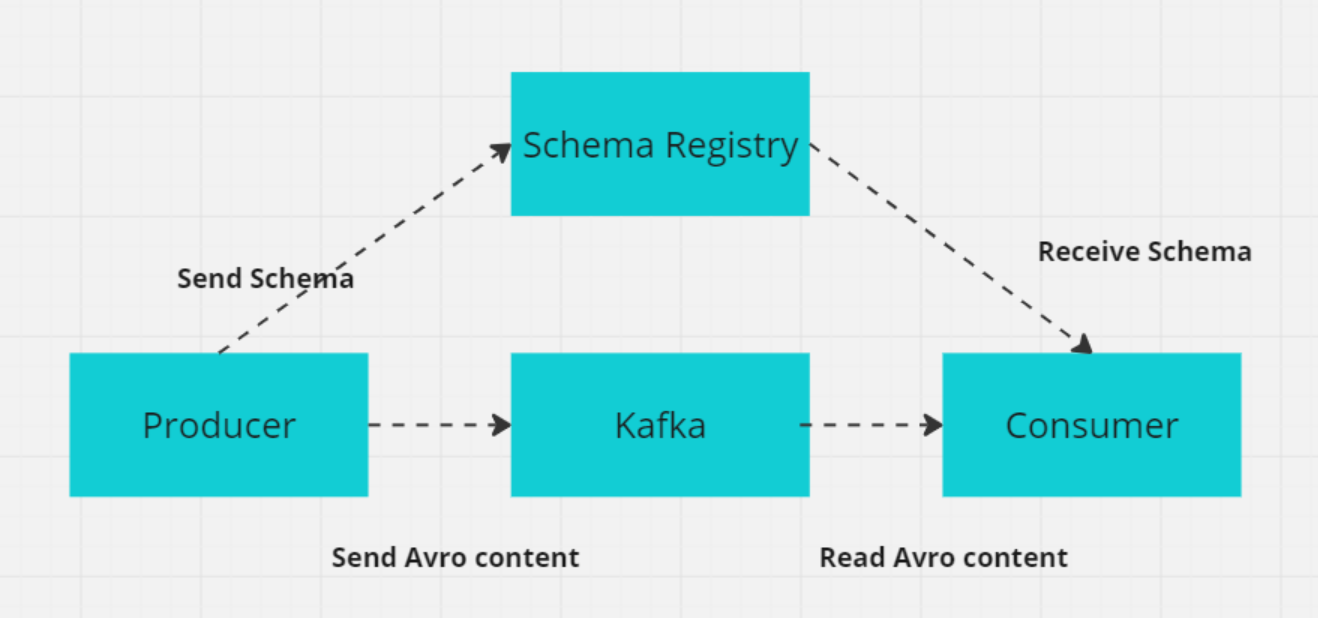
Cómo funciona el registro de esquemas con productor/consumidor (Imagen del autor)
Preguntas avanzadas de la entrevista sobre Kafka
Para los usuarios más avanzados de Kafka, es probable que las preguntas de la entrevista sean de naturaleza más técnica.
11. ¿Cómo garantiza Kafka la prevención de pérdida de mensajes?
Kafka emplea varios mecanismos para evitar la pérdida de mensajes y garantizar una entrega fiable de los mismos:
- Compensación manual: Los consumidores pueden desactivar las confirmaciones automáticas de compensaciones y confirmarlas manualmente después de procesar correctamente los mensajes, para evitar perder los mensajes no procesados en caso de caída del consumidor.
- Agradecimientos del productor (
acks=all): Estableceracks=allen el productor garantiza que los mensajes sean reconocidos por todas las réplicas sincronizadas antes de considerarse escritos con éxito, reduciendo el riesgo de pérdida de mensajes en caso de fallo del intermediario. - Replicación (
min.insync.replicasyreplication.factor): Kafka replica los datos de cada partición en varios intermediarios. Un factor de replicación superior a 1 garantiza la tolerancia a fallos, permitiendo que los datos sigan disponibles aunque falle un intermediario. El ajustemin.insync.replicasgarantiza que un número mínimo de réplicas acusen recibo de un mensaje antes de que se escriba, asegurando una mayor durabilidad de los datos. Por ejemplo, con un factor de replicación de 3, si un corredor se cae, los datos siguen estando disponibles en los otros dos corredores. - Reintentos del productor: Configurar los reintentos a un valor alto garantiza que los productores reintentarán enviar mensajes si se produce un fallo transitorio. Combinado con una configuración cuidadosa, como
max.in.flight.requests.per.connection=1, esto reduce la posibilidad de reordenación de mensajes y garantiza que los mensajes se entreguen finalmente sin perderse.
12. ¿En qué se diferencia Kafka de RabbitMq?
Kafka y RabbitMQ son dos sistemas de mensajería populares y diferentes en términos de arquitectura y uso. Puedes ver cómo se comparan en áreas clave:
1. Uso y diseño
Kafka está diseñado para manejar flujos de datos a gran escala y canalizaciones en tiempo real, optimizado para un alto rendimiento y baja latencia. Su arquitectura basada en registros garantiza la durabilidad y permite reprocesar los datos, por lo que es ideal para casos de uso como el abastecimiento de eventos y el procesamiento de flujos.
RabbitMQ es un broker de mensajes de propósito general que admite enrutamientos complejos y se utiliza normalmente para mensajería entre microservicios o para distribuir tareas entre trabajadores. Sobresale en entornos en los que son esenciales la entrega fiable de mensajes, la flexibilidad de encaminamiento y la interacción entre servicios.
2. Arquitectura
Kafka categoriza los mensajes en temas, que se dividen en particiones. Cada partición puede ser procesada por varios consumidores, lo que permite el procesamiento paralelo y el escalado. Los datos se almacenan en disco con un periodo de retención configurable, lo que garantiza su durabilidad y permite reprocesar los mensajes cuando sea necesario.
RabbitMQ envía mensajes a colas, donde son consumidos por uno o más consumidores. Garantiza la fiabilidad de la entrega mediante acuses de recibo de mensajes, reintentos e intercambios de letra muerta para gestionar los mensajes fallidos. Esta arquitectura se centra en la integridad de los mensajes y la flexibilidad en el encaminamiento.
3. Rendimiento y escalabilidad
Kafka está construido para la escalabilidad horizontal mediante la adición de más corredores y particiones, lo que le permite manejar millones de mensajes por segundo. Su arquitectura admite el procesamiento paralelo y un alto rendimiento, por lo que es ideal para el flujo de datos a gran escala.
RabbitMQ puede escalar, aunque no tan eficientemente como Kafka cuando se trata de volúmenes muy grandes de datos. Es adecuado para escenarios de rendimiento moderado a alto, pero no está optimizado para el rendimiento extremo que Kafka puede manejar en aplicaciones de streaming a gran escala.
Resumen: Tanto Kafka como RabbitMQ son herramientas potentes para la mensajería, pero destacan en casos de uso diferentes. Kafka es ideal para aplicaciones de alto rendimiento, flujo de datos en tiempo real y aprovisionamiento de eventos en las que se necesita un procesamiento paralelo a gran escala.
RabbitMQ es muy adecuado para la entrega fiable de mensajes, la distribución de tareas en arquitecturas de microservicios y el enrutamiento complejo de mensajes. Sobresale en escenarios que requieren un acoplamiento flexible entre servicios, procesamiento asíncrono y fiabilidad.
13. ¿Cómo ayuda Kafka a desarrollar aplicaciones basadas en microservicios?
Apache Kafka es una herramienta valiosa para construir arquitecturas de microservicios debido a sus capacidades en el manejo de datos en tiempo real, la comunicación basada en eventos y la mensajería fiable. He aquí cómo Kafka apoya el desarrollo de microservicios:
1. Arquitectura basada en eventos
- Desacoplamiento de servicios: Kafka permite que los servicios se comuniquen a través de eventos en lugar de llamadas directas, reduciendo las dependencias entre ellos. Este desacoplamiento permite a los servicios producir y consumir eventos de forma independiente, lo que simplifica la evolución y el mantenimiento de los servicios.
- Procesamiento asíncrono: Los servicios pueden publicar eventos y seguir procesándolos sin esperar a que otros servicios respondan, lo que mejora la capacidad de respuesta y la eficacia del sistema.
2. Escalabilidad
- Escalabilidad horizontal: Kafka puede manejar grandes volúmenes de datos distribuyendo la carga entre varios corredores y particiones. Cada partición puede ser procesada por diferentes instancias consumidoras, lo que permite al sistema escalar horizontalmente.
- Consumo paralelo: Varios consumidores pueden leer simultáneamente de distintas particiones, lo que aumenta el rendimiento y las prestaciones.
3. Fiabilidad y tolerancia a fallos
- Replicación de datos: Kafka replica los datos a través de múltiples brokers, asegurando una alta disponibilidad y tolerancia a fallos. Si un corredor falla, otro puede tomar el relevo con los datos replicados. Kafka almacena los datos en disco con periodos de retención configurables, lo que garantiza que los eventos no se pierdan y puedan volver a procesarse si es necesario.
4. Integración de datos
- Concentrador central de datos: Kafka actúa como un eje central para el flujo de datos dentro de una arquitectura de microservicios, facilitando la integración entre diversas fuentes y sumideros de datos. Esto simplifica el mantenimiento de la coherencia de los datos entre servicios.
- Kafka Connect: Kafka Connect proporciona conectores para integrar Kafka con numerosas bases de datos, almacenes de valores clave, índices de búsqueda y otros sistemas, agilizando el movimiento de datos entre microservicios y sistemas externos.
14. ¿Qué es Kafka Zookeeper y cómo funciona?
Apache ZooKeeper es un servicio de código abierto que ayuda a coordinar y gestionar datos de configuración, sincronización y servicios de grupo en sistemas distribuidos. En versiones anteriores de Kafka, ZooKeeper desempeñaba un papel fundamental en la gestión de metadatos, elección de líderes y coordinación de brokers.
Sin embargo, Kafka ha pasado al modo KRaft desde la versión 2.8, que elimina la necesidad de ZooKeeper. ZooKeeper se considera ahora obsoleto y se eliminará en la versión 4.0, prevista para 2024.
ZooKeeper almacena los datos en una estructura jerárquica de nodos llamados "znodos", donde cada znodo puede almacenar metadatos y tener znodos hijos, de forma similar a un sistema de archivos. Esta estructura es crucial para mantener los metadatos relacionados con los corredores, temas y particiones de Kafka. El mecanismo basado en el quórum de ZooKeeper garantiza la coherencia: una mayoría de nodos (quórum) debe estar de acuerdo con cualquier cambio, lo que hace que ZooKeeper sea altamente fiable y tolerante a fallos.
En versiones anteriores de Kafka, ZooKeeper se utiliza para varias funciones críticas:
- Elección de líder: ZooKeeper elige un nodo controlador, que gestiona la asignación de líderes de partición y otras tareas de todo el clúster.
- Gestión de metadatos del intermediario: Mantiene un registro centralizado de corredores activos y su estado.
- Reasignación de particiones: ZooKeeper ayuda a gestionar el reequilibrio de particiones entre brokers durante fallos o ampliaciones del clúster.
El protocolo ZAB de ZooKeeper (ZooKeeper Atomic Broadcast) garantiza la coherencia entre nodos, incluso ante particiones de la red, asegurando que Kafka siga siendo tolerante a fallos. Esta coherencia y fiabilidad hacen que ZooKeeper sea crucial para gestionar la naturaleza distribuida de Kafka, aunque el futuro de la arquitectura de Kafka dependerá menos de ZooKeeper a medida que KRaft se convierta en el modo por defecto.
15. ¿Cómo puedes reducir el uso de disco en Kafka?
Kafka proporciona varias formas de reducir eficazmente el uso del disco. Aquí tienes estrategias clave:
1. Ajustar la configuración de retención de registros
Modifica la política de retención de registros para reducir el tiempo de retención de los mensajes en disco. Esto puede hacerse ajustando retention.ms (retención basada en el tiempo) o retention.bytes (retención basada en el tamaño) para limitar cuánto tiempo o cuántos datos almacena Kafka antes de borrar los mensajes más antiguos.
2. Implementar la compactación del registro
Utiliza la compactación del registro para conservar sólo el mensaje más reciente de cada clave única, eliminando los datos obsoletos o redundantes. Esto es especialmente útil para situaciones en las que sólo es relevante el último estado, reduciendo el uso de espacio en disco sin perder información importante.
3. Configurar políticas de limpieza
Establece políticas de limpieza eficaces basadas en tu caso de uso. Puedes configurar políticas de retención basadas tanto en el tiempo (retention.ms) como en el tamaño (retention.bytes) para eliminar automáticamente los mensajes más antiguos y gestionar la huella de disco de Kafka.
4. Comprimir mensajes
Activa la compresión de mensajes en el lado del productor utilizando formatos como GZIP, Snappy o LZ4. La compresión reduce el tamaño de los mensajes, lo que conlleva un menor consumo de espacio en disco. Sin embargo, es importante tener en cuenta la compensación entre la reducción del uso del disco y el aumento de la sobrecarga de la CPU debido a la compresión y descompresión.
5. Ajustar el tamaño del segmento de registro
Configura el tamaño del segmento de registro de Kafka (segment.bytes) para controlar la frecuencia con la que se enrollan los segmentos de registro. Los segmentos de menor tamaño permiten una rotación más frecuente de los registros, lo que puede contribuir a un uso más eficiente del disco al permitir un borrado más rápido de los datos más antiguos.
6. Eliminar temas o particiones innecesarios
Revisa y elimina periódicamente los temas y particiones no utilizados o innecesarios. Esto puede liberar espacio en disco y ayudar a mantener bajo control el uso de disco de Kafka.
Preguntas de entrevista sobre Kafka para ingenieros de datos
Si vas a realizar una entrevista para un puesto de ingeniero de datos, quizá quieras prepararte para las siguientes preguntas de la entrevista sobre Kafka.
16. ¿Cuáles son las diferencias entre la réplica del líder y la réplica del seguidor en Kafka?
Réplica del líder
La réplica líder gestiona todas las peticiones de lectura y escritura de los clientes. Gestiona el estado de la partición y es el principal punto de interacción entre productores y consumidores. Si el líder falla, su función se transfiere a una de las réplicas seguidoras para mantener la disponibilidad.
Réplica de seguidores
La réplica seguidora replica los datos de la líder, pero no gestiona directamente las peticiones de los clientes. Su función es garantizar la tolerancia a fallos manteniendo una copia actualizada de los datos de la partición. A partir de Kafka 2.4, en determinadas condiciones, las réplicas seguidoras también pueden gestionar peticiones de lectura para ayudar a distribuir la carga y mejorar el rendimiento de la lectura. Si el líder falla, se elige a un seguidor como nuevo líder para mantener la coherencia y disponibilidad de los datos.
17. ¿Por qué utilizamos clusters en Kafka y cuáles son sus ventajas?
Un clúster de Kafka está formado por varios intermediarios que distribuyen los datos entre varias instancias, lo que permite la escalabilidad sin tiempo de inactividad. Estos clusters están diseñados para minimizar los retrasos, y en caso de que falle el cluster primario, otros clusters Kafka pueden tomar el relevo para mantener la continuidad del servicio.
La arquitectura de un clúster Kafka incluye Temas, Intermediarios, Productores y Consumidores. Gestiona eficazmente los flujos de datos, por lo que es ideal para las aplicaciones de big data y el desarrollo de aplicaciones basadas en datos.
18. ¿Cómo garantiza Kafka el orden de los mensajes?
Kafka garantiza el ordenamiento de los mensajes de dos formas principales:
- Utilizar las teclas de mensaje: Cuando se asigna una clave a un mensaje, todos los mensajes con la misma clave se envían a la misma partición. Esto garantiza que los mensajes con la misma clave se procesen en el orden en que se reciben, ya que Kafka conserva el orden dentro de cada partición.
- Procesamiento de consumidores de un solo hilo: Para mantener el orden, el consumidor debe procesar los mensajes de una partición en un único hilo. Si se utilizan varios hilos, configura colas en memoria separadas para cada partición, para garantizar que los mensajes se procesan en el orden correcto durante la manipulación concurrente.
19. ¿Qué representan ISR y AR en Kafka? ¿Qué significa expansión ISR?
ISR (réplicas sincronizadas)
ISR se refiere a las réplicas que están totalmente sincronizadas con la réplica líder. Estas réplicas tienen los datos más recientes y se consideran fiables tanto para operaciones de lectura como de escritura.
AR (réplicas asignadas)
AR incluye todas las réplicas asignadas a una partición, tanto las réplicas sincronizadas como las no sincronizadas. Representa el conjunto completo de réplicas de una partición.
Ampliación ISR
La expansión de ISR se produce cuando las nuevas réplicas alcanzan al líder y se añaden a la lista de ISR. Esto aumenta el número de réplicas actualizadas, mejorando la tolerancia a fallos y la fiabilidad.
20. ¿Qué es un escenario de uso de copia cero en Kafka?
Kafka utiliza la copia cero para transferir eficazmente grandes volúmenes de datos entre productores y consumidores. Aprovecha el método FileChannel.transferTo para mover los datos directamente del sistema de archivos a los sockets de red sin copias adicionales, mejorando el rendimiento y el rendimiento.
Esta técnica utiliza archivos mapeados en memoria (mmap) para leer los archivos índice, lo que permite compartir los búferes de datos entre el espacio de usuario y el espacio del núcleo, reduciendo aún más la necesidad de copiar datos adicionales. Esto hace que Kafka sea muy adecuado para manejar flujos de datos en tiempo real a gran escala de forma eficiente.
Cómo preparar tu entrevista con Kafka
Cuando te prepares para una entrevista de ingeniería de datos centrada en Kafka, es crucial que tengas tanto una sólida base técnica como una clara comprensión de cómo se integra Kafka en los sistemas modernos. Kafka es fundamental para muchas plataformas de datos en tiempo real, por lo que los entrevistadores esperarán que conozcas tanto los fundamentos como el funcionamiento de Kafka en entornos escalables y tolerantes a fallos.
Áreas clave en las que centrarse
Como hemos visto en las preguntas de la entrevista de Kafka que hemos cubierto aquí, hay varias áreas clave que tendrás que repasar:
- Arquitectura: Ten confianza para hablar de la arquitectura de Kafka, incluidos los corredores, las particiones y la interacción entre productores y consumidores. También debes explicar las garantías de entrega de mensajes de Kafka -como la entrega "al menos una vez" o "exactamente una vez"- y cómo Kafka garantiza el orden de los mensajes mediante funciones como las réplicas en sincronía (ISR).
- Integración: Comprende cómo Kafka se integra con otros sistemas utilizando herramientas como Kafka Connect, que conecta bases de datos, almacenes de valores clave y otros sistemas. Los entrevistadores pueden preguntar sobre el papel de Kafka en el mantenimiento de la coherencia de los datos en microservicios o sistemas distribuidos.
- Supervisión y solución de problemas: Es importante estar familiarizado con herramientas de supervisión como Kafka Manager y Prometheus. Tendrás que demostrar tu capacidad para gestionar y optimizar clusters de Kafka de forma eficaz.
- Resolución de problemas: Prepárate para diseñar soluciones de mensajería que resuelvan retos del mundo real, como gestionar grandes flujos de datos o garantizar la fiabilidad de los mensajes. Los entrevistadores pueden darte escenarios hipotéticos en los que tendrás que solucionar problemas u optimizar el rendimiento de Kafka.
- Comunicación: Kafka es complejo, por lo que debes ser capaz de explicar claramente tus decisiones de diseño o los pasos para solucionar problemas, ya sea a los equipos técnicos o a las partes interesadas del negocio. Una gran capacidad de comunicación te distinguirá.
- Experiencia práctica: Destaca cualquier experiencia práctica, como la configuración de clusters de Kafka, la gestión de la retención de datos o la integración de Kafka con otras herramientas. Se valoran mucho los conocimientos prácticos.
- Aprendizaje continuo: Mantente al día de las últimas funciones y mejores prácticas de Kafka. Leer documentación o contribuir a proyectos de código abierto demuestra tu compromiso con el aprendizaje continuo.
Consejos para la entrevista
Aquí tienes algunos consejos para asegurarte de que superas la entrevista:
- Investiga sobre la empresa, el sector y los antecedentes de tu entrevistador.
- Prepárate para las distintas rondas de entrevistas (técnicas, RRHH, telefónicas y en persona) con un enfoque adaptado.
- Revisa periódicamente recursos técnicos como:
Si perfeccionas estas habilidades y te preparas eficazmente, estarás bien equipado para las entrevistas relacionadas con Kafka. Recuerda que los entrevistadores no sólo buscan conocimientos técnicos, sino también una comunicación clara y capacidad para resolver problemas del mundo real. Muestra tu pasión por la ingeniería de datos durante todo el proceso de la entrevista.