Entender como os dados fluem e aproveitar seu potencial tornou-se absolutamente essencial para as organizações modernas. O Kafka é a principal plataforma para ingestão, armazenamento e processamento de fluxos de dados em tempo real no cenário de aplicativos modernos.
Nesta publicação, descreveremos algumas perguntas da entrevista sobre o Kafka e exploraremos a função crucial da ferramenta no processamento de dados. Exploraremos diferentes níveis de perguntas de entrevistas, do básico ao avançado, e daremos dicas para ajudar você a se preparar de forma eficaz. Se você é novo no Kafka, não deixe de conferir nosso curso Introdução ao Apache Kafka.
Perguntas básicas da entrevista sobre o Kafka
Essas perguntas testarão sua compreensão básica do Kafka como uma ferramenta para engenharia de dados.
1. O que é o Apache Kafka?
O Apache Kafka é uma plataforma avançada e de código aberto de fluxo de eventos distribuídos. Originalmente desenvolvido pelo LinkedIn como uma fila de mensagens, ele evoluiu para uma ferramenta para lidar com fluxos de dados em vários cenários.
A arquitetura do sistema distribuído do Kafka permite a escalabilidade horizontal, permitindo que os consumidores recuperem mensagens em seu próprio ritmo e facilitando a adição de nós (servidores) do Kafka ao cluster.
O Kafka foi projetado para processar grandes quantidades de dados rapidamente com baixa latência. Embora tenha sido escrito em Scala e Java, ele oferece suporte a uma ampla variedade de linguagens de programação.

O Apache Kafka atua como um coletor de logs distribuído, em que as mensagens de log são armazenadas como pares de valores-chave em um arquivo de log somente de anexo para armazenamento e recuperação duráveis e de longo prazo. Ao contrário das filas de mensagens tradicionais, como o RabbitMQ, que excluem as mensagens depois de consumidas, o Kafka retém as mensagens por um período configurável, o que o torna ideal para casos de uso que exigem repetição de dados ou fornecimento de eventos.
Enquanto o RabbitMQ se concentra na entrega de mensagens em tempo real sem armazenar mensagens a longo prazo, a política de retenção do Kafka oferece suporte a aplicativos mais complexos e orientados por dados.
Os casos de uso comuns do Kafka incluem rastreamento de aplicativos, agregação de logs e mensagens, embora ele não tenha os recursos tradicionais de banco de dados, como consulta e indexação. Seu ponto forte é lidar com fluxos de dados em tempo real, o que o torna indispensável para sistemas distribuídos e análises em tempo real.
2. Quais são alguns dos recursos do Kafka?
O Apache Kafka é uma plataforma de streaming distribuído de código aberto amplamente usada para criar pipelines de dados em tempo real e aplicativos de streaming. Ele oferece os seguintes recursos:
1. Alto rendimento
O Kafka é capaz de lidar com grandes volumes de dados. Ele foi projetado para ler e gravar centenas de gigabytes de clientes de origem com eficiência.
2. Arquitetura distribuída
O Apache Kafka tem uma arquitetura centrada em clusters e suporta inerentemente o particionamento de mensagens entre servidores Kafka. Esse design também permite o consumo distribuído em um cluster de máquinas consumidoras, preservando a ordem das mensagens em cada partição. Além disso, um cluster do Kafka pode ser dimensionado de forma elástica e transparente, sem exigir tempo de inatividade.
3. Suporte a vários clientes
O Apache Kafka oferece suporte à integração de clientes de diferentes plataformas, como .NET, JAVA, PHP e Python.
4. Mensagens em tempo real
O Kafka produz mensagens em tempo real que devem ser visíveis para os consumidores; isso é importante para sistemas complexos de processamento de eventos.
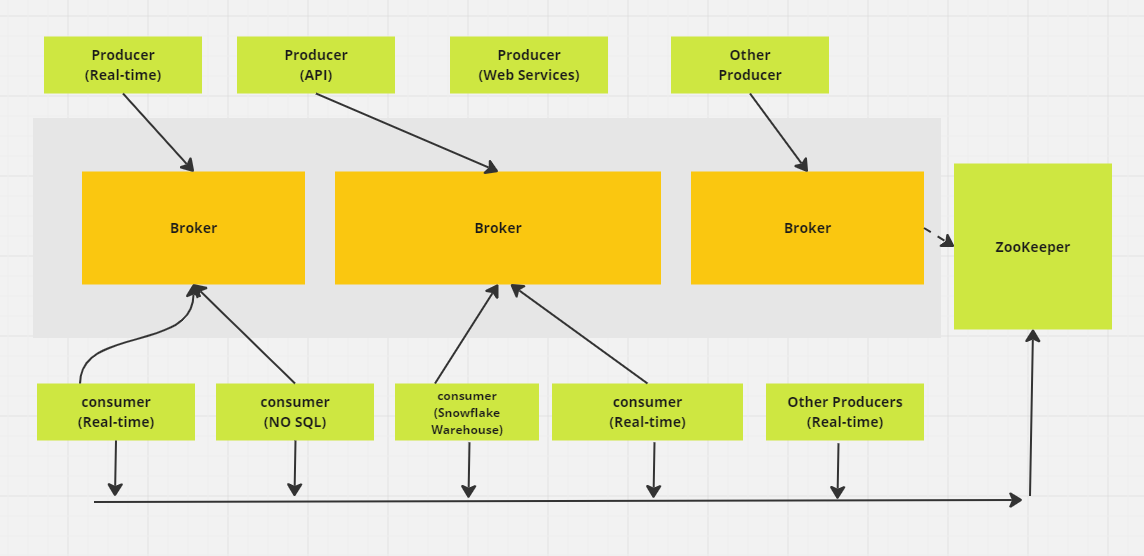
Sistema distribuído de mensagens Apache Kafka. (Imagem do autor)
3. Como as partições funcionam no Kafka?
No Kafka, um tópico serve como um espaço de armazenamento onde todas as mensagens dos produtores são mantidas. Normalmente, os dados relacionados são armazenados em tópicos separados. Por exemplo, um tópico chamado "transactions" (transações) armazenaria detalhes das compras do usuário em um site de comércio eletrônico, enquanto um tópico chamado "customers" (clientes) manteria informações sobre os clientes.
Os tópicos são divididos em partições. Por padrão, um tópico tem uma partição, mas você pode configurá-lo para ter mais. As mensagens são distribuídas entre essas partições, sendo que cada partição tem seu próprio deslocamento e é armazenada em um servidor diferente no cluster do Kafka.
Por exemplo, se um tópico tiver três partições em três corretores e um produtor enviar 15 mensagens, as mensagens serão distribuídas em sequência:
- O registro 1 vai para a partição 0
- O registro 2 vai para a partição 1
- O registro 3 vai para a partição 2
Em seguida, o ciclo se repete, com o Registro 4 voltando para a Partição 0, e assim por diante.
4. Por que você escolheria o Kafka em vez de outros serviços de mensagens?
A escolha do Kafka em relação a outros serviços de mensagens geralmente se resume a seus pontos fortes exclusivos, especialmente para casos de uso que precisam de alta taxa de transferência e processamento de dados em tempo real. Veja por que Kafka se destaca:
- Alta taxa de transferência e escalabilidade: O Kafka pode lidar com grandes volumes de dados de forma eficiente. Sua arquitetura oferece suporte ao dimensionamento horizontal, permitindo que você adicione mais brokers e partições para gerenciar cargas de dados cada vez maiores sem sacrificar o desempenho.
- Processamento em tempo real: É excelente para transmissão de dados em tempo real, o que o torna perfeito para casos de uso como rastreamento de atividades e monitoramento operacional. Por exemplo, o LinkedIn criou o Kafka para lidar com seu pipeline de rastreamento de atividades, permitindo a publicação de feeds em tempo real de interações de usuários, como cliques e curtidas.
- Repetição da mensagem: O Kafka permite que os consumidores reproduzam mensagens, o que é útil se um consumidor encontrar um erro ou ficar sobrecarregado. Isso garante que nenhum dado seja perdido - os consumidores podem recuperar e reproduzir mensagens perdidas para manter a integridade dos dados.
- Durabilidade e tolerância a falhas: A ferramenta replica os dados em vários brokers, garantindo a confiabilidade mesmo que alguns brokers falhem. Esse design tolerante a falhas mantém os dados acessíveis, proporcionando segurança para operações críticas.
5. Explique todas as APIs fornecidas pelo Apache Kafka.
Uma API (Interface de Programação de Aplicativos) permite a comunicação entre diferentes serviços, microsserviços e sistemas. O Kafka fornece um conjunto de APIs projetadas para criar plataformas de streaming de eventos e interagir com seu sistema de mensagens.
As principais APIs do Kafka são:
- API do produtor: Usado para enviar dados em tempo real para tópicos do Kafka. Os produtores determinam para qual partição dentro de um tópico cada mensagem deve ir, com retornos de chamada que tratam do sucesso ou da falha das operações de envio.
- API do consumidor: Permite que você leia dados em tempo real dos tópicos do Kafka. Os consumidores podem fazer parte de um grupo de consumidores para balanceamento de carga e processamento paralelo, assinando tópicos e pesquisando continuamente o Kafka em busca de novas mensagens.
- API de fluxos: Oferece suporte à criação de aplicativos em tempo real que transformam, agregam e analisam dados no Kafka. Ele oferece uma DSL (Domain Specific Language) de alto nível para definir a lógica complexa de processamento de fluxo.
- API de conexão do Kafka: Usado para criar e executar conectores reutilizáveis para importar e exportar dados entre o Kafka e sistemas externos.
- API do administrador: Fornece ferramentas para gerenciar e configurar tópicos, corretores e outros recursos do Kafka para garantir a operação e o dimensionamento sem problemas.
Essas APIs permitem que você produza, consuma, processe e gerencie dados sem interrupções no Kafka.
Perguntas da entrevista sobre o Kafka intermediário
Essas perguntas são direcionadas a profissionais mais experientes que já têm uma compreensão sólida dos usos de Kafka.
6. Quais são as implicações de aumentar o número de partições em um tópico do Kafka?
Aumentar o número de partições em um tópico do Kafka pode melhorar a simultaneidade e a taxa de transferência, permitindo que mais consumidores leiam em paralelo. No entanto, ele também apresenta alguns desafios:
- Aumento da sobrecarga do cluster: Mais partições consomem recursos adicionais do cluster, levando a um maior tráfego de rede para replicação e maiores requisitos de armazenamento.
- Possível desequilíbrio de dados: À medida que as partições aumentam, os dados podem não ser distribuídos uniformemente, o que pode fazer com que algumas partições fiquem sobrecarregadas enquanto outras permanecem subutilizadas.
- Gerenciamento mais complexo de grupos de consumidores: Com mais partições, o gerenciamento de atribuições de grupos de consumidores e o rastreamento de compensações se tornam mais complicados.
- Tempos de rebalanceamento mais longos: Quando os consumidores entram ou saem, o reequilíbrio das partições no grupo pode demorar mais, afetando a capacidade de resposta geral do sistema.
7. Explicar os quatro componentes da arquitetura do Kafka
O Kafka é uma arquitetura distribuída composta por vários componentes principais:
Nós do corretor
A arquitetura distribuída do Kafka é composta por vários componentes principais, um dos quais é o nó do broker. Os corretores fazem o trabalho pesado das operações de entrada/saída e gerenciam o armazenamento durável das mensagens. Eles recebem dados dos produtores, armazenam-nos e os disponibilizam aos consumidores. Cada corretor faz parte de um cluster do Kafka e tem um ID exclusivo para ajudar na coordenação.
Em versões mais antigas do Kafka, o cluster é gerenciado usando o Zookeeper, que garante a coordenação adequada entre os brokers e rastreia metadados, como locais de partição (embora o Kafka esteja migrando para um modo KRaft interno para isso). Os corretores Kafka são altamente dimensionáveis e capazes de lidar com grandes volumes de solicitações de leitura e gravação de mensagens em sistemas distribuídos.
Nós do ZooKeeper
O ZooKeeper desempenha uma função crucial no Kafka, gerenciando o registro do corretor e elegendo o controlador do Kafka, que lida com as operações administrativas do cluster. O ZooKeeper opera como um cluster, chamado de ensemble, em que vários processos trabalham juntos para garantir que apenas um broker de cada vez seja atribuído como controlador.
Se o controlador atual falhar, o ZooKeeper elegerá rapidamente um novo broker para assumir o controle. Embora o ZooKeeper tenha sido uma parte essencial da arquitetura do Kafka, o Kafka está fazendo a transição para um novo modo KRaft que elimina a necessidade do ZooKeeper. O ZooKeeper é um projeto independente de código aberto e não um componente nativo do Kafka.
Produtores
Um produtor do Kafka é um aplicativo cliente que serve como fonte de dados para o Kafka, publicando registros em um ou mais tópicos do Kafka por meio de conexões TCP persistentes com corretores.
Vários produtores podem enviar registros para o mesmo tópico ao mesmo tempo. Os tópicos do Kafka são append-only, o que significa que os produtores podem gravar novos dados, mas nem os produtores nem os consumidores podem modificar ou excluir registros existentes, o que garante a imutabilidade dos dados.
Consumidores
Um consumidor do Kafka é um aplicativo cliente que se inscreve em um ou mais tópicos do Kafka para consumir fluxos de registros. Normalmente, os consumidores trabalham em grupos de consumidores, onde a carga de leitura e processamento de registros é distribuída entre vários consumidores.
Cada consumidor acompanha seu progresso no fluxo mantendo offsets, garantindo que nenhum dado seja processado duas vezes e que os registros não processados não sejam perdidos. Os consumidores Kafka atuam como a etapa final do pipeline de dados, em que os registros são processados ou encaminhados para sistemas downstream.
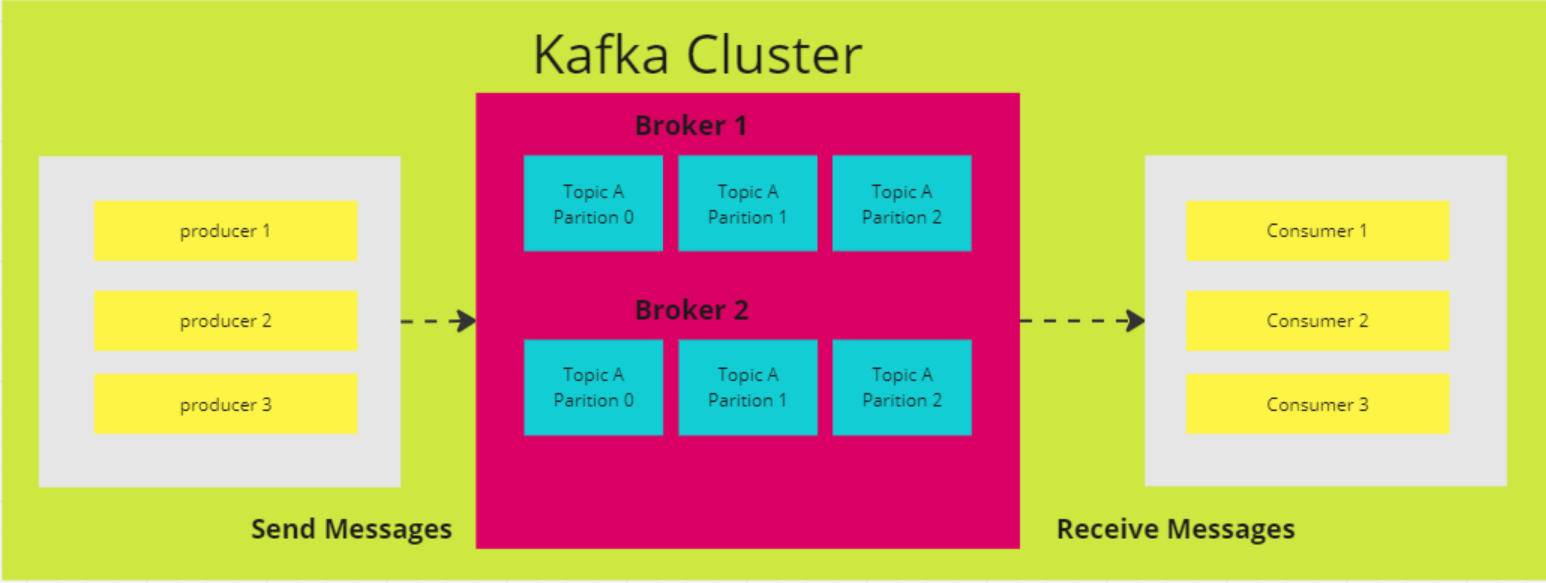
Diagrama de arquitetura do Apache Kafka (Imagem do autor)
8. Qual é o principal objetivo da compactação de registros no Kafka? Como a compactação de registros afeta o desempenho dos consumidores do Kafka?
O principal objetivo da compactação de logs no Kafka é reter o valor mais recente de cada chave exclusiva no log de um tópico, garantindo que o estado mais recente dos dados seja preservado e reduzindo o uso do armazenamento. Isso permite que os consumidores acessem o valor atual com mais eficiência, sem precisar processar duplicatas antigas.
Ao contrário da política de retenção tradicional do Kafka, que exclui mensagens após um determinado período de tempo, a compactação de logs exclui apenas os registros mais antigos de cada chave, mantendo o valor mais recente dessa chave. Esse recurso ajuda a garantir que os consumidores sempre tenham acesso ao estado atual e, ao mesmo tempo, mantém um registro compacto para maior eficiência de armazenamento e pesquisas mais rápidas.
9. Qual é a diferença entre partições e réplicas em um cluster do Kafka?
As partições e réplicas são componentes essenciais da arquitetura do Kafka, garantindo o desempenho e a tolerância a falhas. As partições aumentam a taxa de transferência ao permitir que um tópico seja dividido em várias partes, possibilitando que os consumidores leiam de diferentes partições em paralelo, o que melhora a escalabilidade e a eficiência do Kafka.
As réplicas, por outro lado, oferecem redundância ao criar cópias de partições em vários brokers. Isso garante a tolerância a falhas porque, no caso de uma falha do broker líder (o broker que gerencia as operações de leitura e gravação de uma partição), uma das réplicas seguidoras pode ser promovida para assumir o papel de novo líder.
O Kafka mantém várias réplicas de cada partição para garantir a alta disponibilidade e a durabilidade dos dados, minimizando o risco de perda de dados durante falhas, embora a durabilidade total dependa das configurações de replicação.
10. O que é um esquema no Kafka e por que ele é importante para os sistemas distribuídos?
No Kafka, um esquema define a estrutura e o formato dos dados, como campos como CustomerID (número inteiro), CustomerName (cadeia de caracteres) e Designation (cadeia de caracteres).
Em sistemas distribuídos como o Kafka, os produtores e consumidores devem concordar com o formato dos dados para evitar erros na troca de dados. O Kafka Schema Registry gerencia e impõe esses esquemas, garantindo que tanto os produtores quanto os consumidores usem versões compatíveis.
O Schema Registry armazena esquemas (geralmente em formatos como Avro, Protobuf ou JSON Schema) e oferece suporte à evolução de esquemas, permitindo que os formatos de dados sejam alterados sem quebrar os consumidores existentes. Isso garante a troca de dados sem problemas e a confiabilidade do sistema à medida que os esquemas evoluem.
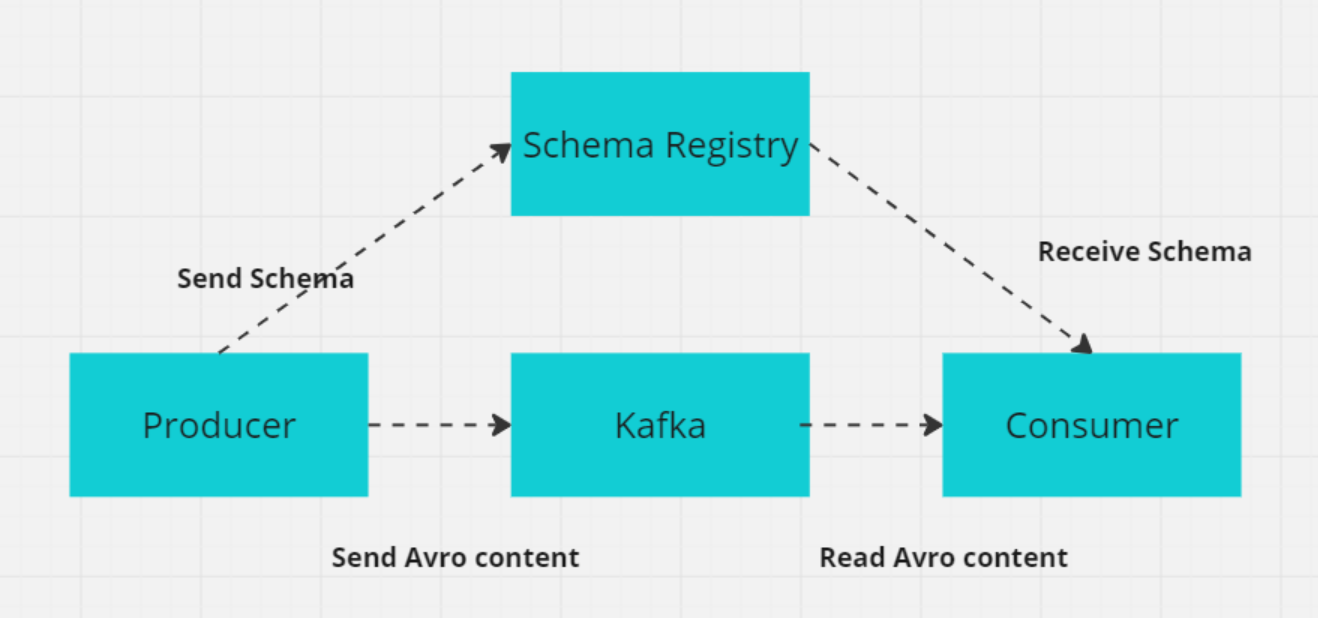
Como o registro de esquema funciona com produtor/consumidor (Imagem do autor)
Perguntas avançadas da entrevista sobre o Kafka
Para usuários mais avançados do Kafka, as perguntas da entrevista que você enfrentará provavelmente serão de natureza mais técnica.
11. Como o Kafka garante a prevenção de perda de mensagens?
O Kafka emprega vários mecanismos para evitar a perda de mensagens e garantir a entrega confiável de mensagens:
- Compromisso de deslocamento manual: Os consumidores podem desativar os commits automáticos de deslocamento e confirmar manualmente os deslocamentos após o processamento bem-sucedido das mensagens para evitar a perda de mensagens não processadas no caso de uma falha do consumidor.
- Agradecimentos ao produtor (
acks=all): A configuração deacks=allno produtor garante que as mensagens sejam reconhecidas por todas as réplicas sincronizadas antes de serem consideradas gravadas com êxito, reduzindo o risco de perda de mensagens em caso de falha do broker. - Replicação (
min.insync.replicasereplication.factor): O Kafka replica os dados de cada partição em vários brokers. Um fator de replicação maior que 1 garante a tolerância a falhas, permitindo que os dados permaneçam disponíveis mesmo que um broker falhe. A configuraçãomin.insync.replicasgarante que um número mínimo de réplicas reconheça uma mensagem antes que ela seja gravada, garantindo maior durabilidade dos dados. Por exemplo, com um fator de replicação de 3, se um broker ficar inativo, os dados continuarão disponíveis nos outros dois brokers. - O produtor tenta novamente: A configuração de novas tentativas com um valor alto garante que os produtores tentarão enviar mensagens novamente se ocorrer uma falha transitória. Combinado com uma configuração cuidadosa, como
max.in.flight.requests.per.connection=1, isso reduz a chance de reordenação de mensagens e garante que as mensagens sejam entregues sem serem perdidas.
12. Qual é a diferença entre o Kafka e o RabbitMq?
O Kafka e o RabbitMQ são dois sistemas de mensagens populares e diferentes em termos de arquitetura e uso. Você pode ver como eles se comparam em áreas importantes:
1. Uso e design
O Kafka foi projetado para lidar com fluxos de dados em grande escala e pipelines em tempo real, otimizados para alta taxa de transferência e baixa latência. Sua arquitetura baseada em log garante durabilidade e permite que os dados sejam reprocessados, tornando-o ideal para casos de uso como fornecimento de eventos e processamento de fluxo.
O RabbitMQ é um corretor de mensagens de uso geral que oferece suporte a roteamento complexo e é normalmente usado para troca de mensagens entre microsserviços ou distribuição de tarefas entre trabalhadores. Ele se destaca em ambientes em que o fornecimento confiável de mensagens, a flexibilidade de roteamento e a interação entre serviços são essenciais.
2. Arquitetura
O Kafka categoriza as mensagens em tópicos, que são divididos em partições. Cada partição pode ser processada por vários consumidores, permitindo o processamento paralelo e o dimensionamento. Os dados são armazenados em disco com um período de retenção configurável, garantindo a durabilidade e permitindo o reprocessamento de mensagens quando necessário.
O RabbitMQ envia mensagens para filas, onde elas são consumidas por um ou mais consumidores. Ele garante uma entrega confiável por meio de confirmações de mensagens, novas tentativas e trocas de letras mortas para lidar com mensagens com falha. Essa arquitetura se concentra na integridade da mensagem e na flexibilidade do roteamento.
3. Desempenho e escalabilidade
O Kafka foi desenvolvido para ser escalonável horizontalmente, adicionando mais brokers e partições, o que permite que ele processe milhões de mensagens por segundo. Sua arquitetura suporta processamento paralelo e alta taxa de transferência, tornando-o ideal para streaming de dados em grande escala.
O RabbitMQ pode ser dimensionado, embora não com a mesma eficiência do Kafka, quando você lida com volumes muito grandes de dados. Ele é adequado para cenários de taxa de transferência moderada a alta, mas não é otimizado para a taxa de transferência extrema que o Kafka pode suportar em aplicativos de streaming em grande escala.
Resumo: Tanto o Kafka quanto o RabbitMQ são ferramentas poderosas para troca de mensagens, mas se destacam em casos de uso diferentes. O Kafka é ideal para aplicativos de alto rendimento, streaming de dados em tempo real e fornecimento de eventos, nos quais é necessário um processamento paralelo e em grande escala.
O RabbitMQ é adequado para a entrega confiável de mensagens, distribuição de tarefas em arquiteturas de microsserviços e roteamento complexo de mensagens. Ele se destaca em cenários que exigem acoplamento frouxo entre serviços, processamento assíncrono e confiabilidade.
13. Como o Kafka ajuda no desenvolvimento de aplicativos baseados em microsserviços?
O Apache Kafka é uma ferramenta valiosa para a criação de arquiteturas de microsserviços devido aos seus recursos de manipulação de dados em tempo real, comunicação orientada por eventos e mensagens confiáveis. Veja como o Kafka oferece suporte ao desenvolvimento de microsserviços:
1. Arquitetura orientada por eventos
- Desacoplamento de serviços: O Kafka permite que os serviços se comuniquem por meio de eventos em vez de chamadas diretas, reduzindo as dependências entre eles. Esse desacoplamento permite que os serviços produzam e consumam eventos de forma independente, simplificando a evolução e a manutenção do serviço.
- Processamento assíncrono: Os serviços podem publicar eventos e continuar o processamento sem esperar que outros serviços respondam, melhorando a capacidade de resposta e a eficiência do sistema.
2. Escalabilidade
- Escalabilidade horizontal: O Kafka pode lidar com grandes volumes de dados distribuindo a carga entre vários brokers e partições. Cada partição pode ser processada por diferentes instâncias de consumidores, permitindo que o sistema seja dimensionado horizontalmente.
- Consumo paralelo: Vários consumidores podem ler de diferentes partições simultaneamente, aumentando a taxa de transferência e o desempenho.
3. Confiabilidade e tolerância a falhas
- Replicação de dados: O Kafka replica dados em vários brokers, garantindo alta disponibilidade e tolerância a falhas. Se um broker falhar, outro poderá assumir o controle com os dados replicados. O Kafka armazena dados em disco com períodos de retenção configuráveis, garantindo que os eventos não sejam perdidos e possam ser reprocessados, se necessário.
4. Integração de dados
- Hub central de dados: O Kafka atua como um hub central para o fluxo de dados em uma arquitetura de microsserviço, facilitando a integração entre várias fontes e coletores de dados. Isso simplifica a manutenção da consistência dos dados entre os serviços.
- Kafka Connect: O Kafka Connect fornece conectores para integrar o Kafka a vários bancos de dados, armazenamentos de valores-chave, índices de pesquisa e outros sistemas, simplificando a movimentação de dados entre microsserviços e sistemas externos.
14. O que é o Kafka Zookeeper e como ele funciona?
O Apache ZooKeeper é um serviço de código aberto que ajuda a coordenar e gerenciar dados de configuração, sincronização e serviços de grupo em sistemas distribuídos. Nas versões anteriores do Kafka, o ZooKeeper desempenhava uma função essencial no gerenciamento de metadados, na eleição de líderes e na coordenação de corretores.
No entanto, o Kafka está em transição para o modo KRaft desde a versão 2.8, o que elimina a necessidade do ZooKeeper. O ZooKeeper agora é considerado obsoleto e será removido na versão 4.0, que está prevista para 2024.
O ZooKeeper armazena dados em uma estrutura hierárquica de nós chamada "znodes", em que cada znode pode armazenar metadados e ter znodes filhos, semelhante a um sistema de arquivos. Essa estrutura é fundamental para a manutenção de metadados relacionados a corretores, tópicos e partições do Kafka. O mecanismo baseado em quorum do ZooKeeper garante a consistência: a maioria dos nós (quorum) deve concordar com qualquer alteração, o que torna o ZooKeeper altamente confiável e tolerante a falhas.
Nas versões mais antigas do Kafka, o ZooKeeper é usado para várias funções críticas:
- Eleição do líder: O ZooKeeper elege um nó controlador, que gerencia as atribuições do líder da partição e outras tarefas de todo o cluster.
- Gerenciamento de metadados do broker: Ele mantém um registro centralizado de corretores ativos e seu status.
- Reatribuição de partição: O ZooKeeper ajuda a gerenciar o rebalanceamento de partições entre os brokers durante falhas ou expansões de cluster.
O protocolo ZAB (ZooKeeper Atomic Broadcast) do ZooKeeper garante a consistência entre os nós, mesmo diante de partições de rede, assegurando que o Kafka permaneça tolerante a falhas. Essa consistência e confiabilidade tornam o ZooKeeper essencial para gerenciar a natureza distribuída do Kafka, embora o futuro da arquitetura do Kafka dependa menos do ZooKeeper à medida que o KRaft se tornar o modo padrão.
15. Como você pode reduzir o uso do disco no Kafka?
O Kafka oferece várias maneiras de reduzir efetivamente o uso do disco. Aqui estão as principais estratégias:
1. Ajustar as configurações de retenção de registros
Modifique a política de retenção de logs para reduzir o tempo em que as mensagens são retidas no disco. Isso pode ser feito ajustando retention.ms (retenção baseada em tempo) ou retention.bytes (retenção baseada em tamanho) para limitar o tempo ou a quantidade de dados que o Kafka armazena antes de excluir mensagens mais antigas.
2. Implementar a compactação de registros
Use a compactação de logs para reter apenas a mensagem mais recente de cada chave exclusiva, removendo dados desatualizados ou redundantes. Isso é particularmente útil para cenários em que somente o estado mais recente é relevante, reduzindo o uso de espaço em disco sem perder informações importantes.
3. Configurar políticas de limpeza
Defina políticas de limpeza eficazes com base em seu caso de uso. Você pode configurar políticas de retenção baseadas no tempo (retention.ms) e no tamanho (retention.bytes) para excluir automaticamente as mensagens mais antigas e gerenciar o espaço em disco do Kafka.
4. Comprimir mensagens
Ative a compactação de mensagens no lado do produtor usando formatos como GZIP, Snappy ou LZ4. A compactação reduz o tamanho da mensagem, levando a um menor consumo de espaço em disco. No entanto, é importante considerar a compensação entre a redução do uso do disco e o aumento da sobrecarga da CPU devido à compactação e descompactação.
5. Ajustar o tamanho do segmento de registro
Configure o tamanho do segmento de registro do Kafka (segment.bytes) para controlar a frequência com que os segmentos de registro são rolados. Tamanhos menores de segmentos permitem a rolagem mais frequente do registro, o que pode ajudar a tornar o uso do disco mais eficiente, permitindo a exclusão mais rápida de dados antigos.
6. Excluir tópicos ou partições desnecessários
Revise e exclua periodicamente tópicos e partições não utilizados ou desnecessários. Isso pode liberar espaço em disco e ajudar a manter o uso do disco do Kafka sob controle.
Perguntas da entrevista sobre o Kafka para engenheiros de dados
Se você estiver fazendo uma entrevista para um cargo de engenheiro de dados, talvez queira se preparar para as seguintes perguntas da entrevista sobre o Kafka.
16. Quais são as diferenças entre a réplica do líder e a réplica do seguidor no Kafka?
Réplica do líder
A réplica líder lida com todas as solicitações de leitura e gravação do cliente. Ele gerencia o estado da partição e é o principal ponto de interação para produtores e consumidores. Se o líder falhar, sua função será transferida para uma das réplicas seguidoras para manter a disponibilidade.
Réplica de seguidor
A réplica seguidora replica os dados do líder, mas não lida diretamente com as solicitações do cliente. Sua função é garantir a tolerância a falhas, mantendo uma cópia atualizada dos dados da partição. A partir do Kafka 2.4, sob determinadas condições, as réplicas seguidoras também podem lidar com solicitações de leitura para ajudar a distribuir a carga e melhorar o rendimento da leitura. Se o líder falhar, um seguidor é eleito como o novo líder para manter a consistência e a disponibilidade dos dados.
17. Por que usamos clusters no Kafka e quais são seus benefícios?
Um cluster do Kafka é composto de vários brokers que distribuem dados em várias instâncias, permitindo a escalabilidade sem tempo de inatividade. Esses clusters são projetados para minimizar atrasos e, caso o cluster principal falhe, outros clusters do Kafka podem assumir o controle para manter a continuidade do serviço.
A arquitetura de um cluster do Kafka inclui tópicos, corretores, produtores e consumidores. Ele gerencia com eficiência os fluxos de dados, o que o torna ideal para aplicativos de big data e para o desenvolvimento de aplicativos orientados por dados.
18. Como o Kafka garante a ordenação das mensagens?
O Kafka garante a ordenação das mensagens de duas maneiras principais:
- Usando as teclas de mensagem: Quando uma mensagem é atribuída a uma chave, todas as mensagens com a mesma chave são enviadas para a mesma partição. Isso garante que as mensagens com a mesma chave sejam processadas na ordem em que foram recebidas, pois o Kafka preserva a ordem dentro de cada partição.
- Processamento de consumidor com thread único: Para manter a ordem, o consumidor deve processar as mensagens de uma partição em um único thread. Se forem usadas várias threads, configure filas separadas na memória para cada partição a fim de garantir que as mensagens sejam processadas na ordem correta durante o tratamento simultâneo.
19. O que ISR e AR representam no Kafka? O que significa expansão de ISR?
ISR (réplicas em sincronia)
ISR refere-se às réplicas que estão totalmente sincronizadas com a réplica líder. Essas réplicas têm os dados mais recentes e são consideradas confiáveis para operações de leitura e gravação.
AR (réplicas atribuídas)
O AR inclui todas as réplicas atribuídas a uma partição, tanto as réplicas sincronizadas quanto as fora de sincronia. Ele representa o conjunto completo de réplicas de uma partição.
Expansão do ISR
A expansão da ISR ocorre quando novas réplicas alcançam o líder e são adicionadas à lista de ISRs. Isso aumenta o número de réplicas atualizadas, melhorando a tolerância a falhas e a confiabilidade.
20. O que é um cenário de uso de cópia zero no Kafka?
O Kafka usa a cópia zero para transferir com eficiência grandes volumes de dados entre produtores e consumidores. Ele aproveita o método FileChannel.transferTo para mover dados diretamente do sistema de arquivos para soquetes de rede sem cópia adicional, melhorando o desempenho e a taxa de transferência.
Essa técnica utiliza arquivos mapeados na memória (mmap) para a leitura de arquivos de índice, permitindo que os buffers de dados sejam compartilhados entre o espaço do usuário e o espaço do kernel, reduzindo ainda mais a necessidade de cópia extra de dados. Isso faz com que o Kafka seja adequado para lidar com fluxos de dados em tempo real em grande escala de forma eficiente.
Preparando-se para sua entrevista com a Kafka
Enquanto você se prepara para uma entrevista de engenharia de dados com foco no Kafka, é fundamental ter uma base técnica sólida e uma compreensão clara de como o Kafka se integra aos sistemas modernos. O Kafka é fundamental para muitas plataformas de dados em tempo real, portanto, os entrevistadores esperam que você conheça os conceitos básicos e saiba como o Kafka funciona em ambientes escalonáveis e tolerantes a falhas.
Áreas-chave nas quais você deve se concentrar
Como vimos nas perguntas da entrevista sobre o Kafka que abordamos aqui, há várias áreas importantes nas quais você precisará se aperfeiçoar:
- Arquitetura: Você terá confiança para discutir a arquitetura do Kafka, incluindo corretores, partições e a interação entre produtores e consumidores. Você também deve explicar as garantias de entrega de mensagens do Kafka - como a entrega "pelo menos uma vez" ou "exatamente uma vez" - e como o Kafka garante a ordenação das mensagens por meio de recursos como as réplicas sincronizadas (ISR).
- Integração: Entenda como o Kafka se integra a outros sistemas usando ferramentas como o Kafka Connect, que conecta bancos de dados, armazenamentos de valores-chave e outros sistemas. Os entrevistadores podem perguntar sobre a função do Kafka na manutenção da consistência dos dados em microsserviços ou sistemas distribuídos.
- Monitoramento e solução de problemas: É importante que você esteja familiarizado com ferramentas de monitoramento, como o Kafka Manager e o Prometheus. Você precisará demonstrar sua capacidade de gerenciar e otimizar clusters do Kafka com eficiência.
- Resolução de problemas: Prepare-se para projetar soluções de mensagens que resolvam desafios do mundo real, como lidar com grandes fluxos de dados ou garantir a confiabilidade das mensagens. Os entrevistadores podem apresentar cenários hipotéticos em que você precisará solucionar problemas ou otimizar o desempenho do Kafka.
- Comunicação: O Kafka é complexo, portanto, você deve ser capaz de explicar claramente suas decisões de projeto ou as etapas de solução de problemas, seja para equipes técnicas ou partes interessadas do negócio. Você se destacará por suas sólidas habilidades de comunicação.
- Experiência prática: Destaque qualquer experiência prática, como a configuração de clusters do Kafka, o gerenciamento da retenção de dados ou a integração do Kafka com outras ferramentas. O conhecimento prático é altamente valorizado.
- Aprendizado contínuo: Mantenha-se atualizado com os recursos mais recentes e as práticas recomendadas do Kafka. Ler a documentação ou contribuir com projetos de código aberto mostra que você está comprometido com o aprendizado contínuo.
Dicas para entrevistas
Aqui estão algumas das principais dicas para você se sair bem na entrevista:
- Pesquise a empresa, o setor e o histórico do entrevistador.
- Prepare-se para diferentes rodadas de entrevistas (técnica, RH, telefônica e presencial) com uma abordagem personalizada.
- Analise regularmente recursos técnicos como:
Ao aperfeiçoar essas habilidades e se preparar de forma eficaz, você estará bem equipado para entrevistas relacionadas ao Kafka. Lembre-se de que os entrevistadores estão procurando não apenas conhecimento técnico, mas também uma comunicação clara e habilidades de resolução de problemas do mundo real. Mostre sua paixão pela engenharia de dados durante o processo de entrevista.

