Comprendre comment les données circulent et tirer parti de leur potentiel est devenu absolument essentiel pour les organisations modernes. Kafka est la principale plateforme d'ingestion, de stockage et de traitement des flux de données en temps réel dans le paysage applicatif moderne.
Dans ce billet, nous allons vous présenter quelques questions d'entretien sur Kafka et explorer le rôle crucial de cet outil dans le traitement des données. Nous explorerons les différents niveaux de questions d'entretien, des plus simples aux plus complexes, et nous vous donnerons des conseils pour vous aider à vous préparer efficacement. Si vous ne connaissez pas encore Kafka, n'hésitez pas à consulter notre cours Introduction à Apache Kafka.
Questions d'entretien de base sur Kafka
Ces questions testeront votre compréhension de base de Kafka en tant qu'outil d'ingénierie des données.
1. Qu'est-ce qu'Apache Kafka ?
Apache Kafka est une puissante plateforme open-source de flux d'événements distribués. Développé à l'origine par LinkedIn comme une file d'attente de messagerie, il a évolué pour devenir un outil permettant de traiter des flux de données dans différents scénarios.
L'architecture de système distribué de Kafka permet une évolutivité horizontale, permettant aux consommateurs de récupérer les messages à leur propre rythme et facilitant l'ajout de nœuds Kafka (serveurs) au cluster.
Kafka est conçu pour traiter rapidement de grandes quantités de données avec une faible latence. Bien qu'il soit écrit en Scala et en Java, il prend en charge un large éventail de langages de programmation.

Apache Kafka agit comme un collecteur de journaux distribué, où les messages sont stockés sous forme de paires clé-valeur dans un fichier journal en annexe seulement pour un stockage et une récupération durables à long terme. Contrairement aux files d'attente traditionnelles comme RabbitMQ, qui suppriment les messages après leur consommation, Kafka conserve les messages pendant une période configurable, ce qui en fait la solution idéale pour les cas d'utilisation qui nécessitent une relecture des données ou un approvisionnement en événements.
Alors que RabbitMQ se concentre sur la livraison de messages en temps réel sans stocker les messages à long terme, la politique de rétention de Kafka prend en charge des applications plus complexes, axées sur les données.
Les cas d'utilisation courants de Kafka comprennent le cursus des applications, l'agrégation des journaux et la messagerie, bien qu'il ne dispose pas des fonctionnalités traditionnelles d'une base de données telles que l'interrogation et l'indexation. Sa force réside dans le traitement des flux de données en temps réel, ce qui le rend indispensable pour les systèmes distribués et l'analyse en temps réel.
2. Quelles sont les caractéristiques de Kafka ?
Apache Kafka est une plateforme de streaming distribuée open-source largement utilisée pour construire des pipelines de données en temps réel et des applications de streaming. Il offre les caractéristiques suivantes :
1. Haut débit
Kafka est capable de traiter des volumes massifs de données. Il est conçu pour lire et écrire efficacement des centaines de gigaoctets à partir de clients sources.
2. Architecture distribuée
Apache Kafka a une architecture centrée sur les clusters et prend intrinsèquement en charge le partitionnement des messages entre les serveurs Kafka. Cette conception permet également une consommation distribuée sur une grappe de machines consommatrices, tout en préservant l'ordre des messages au sein de chaque partition. En outre, un cluster Kafka peut évoluer de manière élastique et transparente, sans nécessiter de temps d'arrêt.
3. Soutien à divers clients
Apache Kafka prend en charge l'intégration de clients issus de différentes plateformes, telles que .NET, JAVA, PHP et Python.
4. Messages en temps réel
Kafka produit des messages en temps réel qui doivent être visibles pour les consommateurs, ce qui est important pour les systèmes de traitement d'événements complexes.
Système distribué de messagerie Apache Kafka. (Image de l'auteur)
3. Comment fonctionnent les partitions dans Kafka ?
Dans Kafka, un sujet sert d'espace de stockage où sont conservés tous les messages des producteurs. En règle générale, les données connexes sont stockées dans des rubriques distinctes. Par exemple, un thème intitulé "transactions" stockera les détails des achats effectués par les utilisateurs sur un site de commerce électronique, tandis qu'un thème appelé "clients" contiendra des informations sur les clients.
Les sujets sont divisés en partitions. Par défaut, un sujet a une partition, mais vous pouvez en configurer plusieurs. Les messages sont répartis entre ces partitions, chaque partition ayant son propre décalage et étant stockée sur un serveur différent dans le cluster Kafka.
Par exemple, si un thème comporte trois partitions réparties entre trois courtiers et qu'un producteur envoie 15 messages, les messages sont distribués dans l'ordre :
- L'enregistrement 1 va à la partition 0
- L'enregistrement 2 va à la partition 1
- L'enregistrement 3 va à la partition 2
Le cycle se répète ensuite, l'enregistrement 4 revenant à la partition 0, et ainsi de suite.
4. Pourquoi choisir Kafka plutôt que d'autres services de messagerie ?
Le choix de Kafka par rapport à d'autres services de messagerie se résume souvent à ses atouts uniques, en particulier pour les cas d'utilisation qui nécessitent un débit élevé et un traitement des données en temps réel. Voici pourquoi Kafka se distingue :
- Débit élevé et évolutivité: Kafka peut traiter efficacement de grands volumes de données. Son architecture prend en charge la mise à l'échelle horizontale, ce qui vous permet d'ajouter des courtiers et des partitions pour gérer des charges de données croissantes sans sacrifier les performances.
- Traitement en temps réel: Il est excellent pour le flux de données en temps réel, ce qui le rend parfait pour des cas d'utilisation tels que le suivi d'activité et la surveillance opérationnelle. Par exemple, LinkedIn a créé Kafka pour gérer son pipeline de suivi des activités, ce qui lui permet de publier en temps réel des flux d'interactions avec les utilisateurs, comme les clics et les likes.
- Répétition du message: Kafka permet aux consommateurs de rejouer les messages, ce qui est utile si un consommateur rencontre une erreur ou est surchargé. Ainsi, aucune donnée n'est perdue - les consommateurs peuvent récupérer et réécouter les messages manqués pour maintenir l'intégrité des données.
- Durabilité et tolérance aux pannes: L'outil réplique les données entre plusieurs courtiers, ce qui garantit la fiabilité même si certains courtiers tombent en panne. Cette conception tolérante aux pannes permet de conserver l'accès aux données et d'assurer la sécurité des opérations critiques.
5. Expliquez toutes les API fournies par Apache Kafka.
Une API (interface de programmation d'applications) permet la communication entre différents services, microservices et systèmes. Kafka fournit un ensemble d'API conçues pour construire des plateformes de flux d'événements et interagir avec son système de messagerie.
Les principales API de Kafka sont les suivantes :
- API du producteur: Utilisé pour envoyer des données en temps réel aux sujets Kafka. Les producteurs déterminent à quelle partition d'un sujet chaque message doit être envoyé, les rappels gérant le succès ou l'échec des opérations d'envoi.
- API pour les consommateurs: Permet de lire des données en temps réel à partir de sujets Kafka. Les consommateurs peuvent faire partie d'un groupe de consommateurs pour l'équilibrage de la charge et le traitement parallèle, en s'abonnant à des sujets et en interrogeant continuellement Kafka pour de nouveaux messages.
- API de flux: Permet de créer des applications en temps réel qui transforment, agrègent et analysent les données dans Kafka. Il offre un DSL (Domain Specific Language) de haut niveau pour définir une logique complexe de traitement des flux.
- API Kafka Connect: Utilisé pour créer et exécuter des connecteurs réutilisables pour l'importation et l'exportation de données entre Kafka et des systèmes externes.
- Admin API : Fournit des outils pour gérer et configurer les sujets Kafka, les courtiers et d'autres ressources afin d'assurer un bon fonctionnement et une bonne évolutivité.
Ces API permettent de produire, de consommer, de traiter et de gérer les données de manière transparente dans Kafka.
Questions d'entretien intermédiaires sur Kafka
Ces questions s'adressent à des praticiens plus expérimentés qui ont déjà une bonne compréhension des utilisations de Kafka.
6. Quelles sont les conséquences de l'augmentation du nombre de partitions dans un sujet Kafka ?
L'augmentation du nombre de partitions dans un sujet Kafka peut améliorer la concurrence et le débit en permettant à un plus grand nombre de consommateurs de lire en parallèle. Cependant, elle pose également certains problèmes :
- Augmentation de la charge de travail de la grappe: Un plus grand nombre de partitions consomme des ressources supplémentaires du cluster, ce qui entraîne une augmentation du trafic réseau pour la réplication et des besoins en stockage.
- Déséquilibre potentiel des données: Au fur et à mesure que les partitions augmentent, les données peuvent ne pas être réparties uniformément, ce qui peut entraîner une surcharge de certaines partitions alors que d'autres restent sous-utilisées.
- Gestion plus complexe des groupes de consommateurs : Avec davantage de partitions, la gestion des affectations des groupes de consommateurs et le suivi des décalages deviennent plus compliqués.
- Des délais de rééquilibrage plus longs: Lorsque des consommateurs rejoignent ou quittent le groupe, le rééquilibrage des partitions dans le groupe peut prendre plus de temps, ce qui affecte la réactivité globale du système.
7. Expliquez les quatre composantes de l'architecture Kafka
Kafka est une architecture distribuée composée de plusieurs éléments clés :
Nœuds de courtage
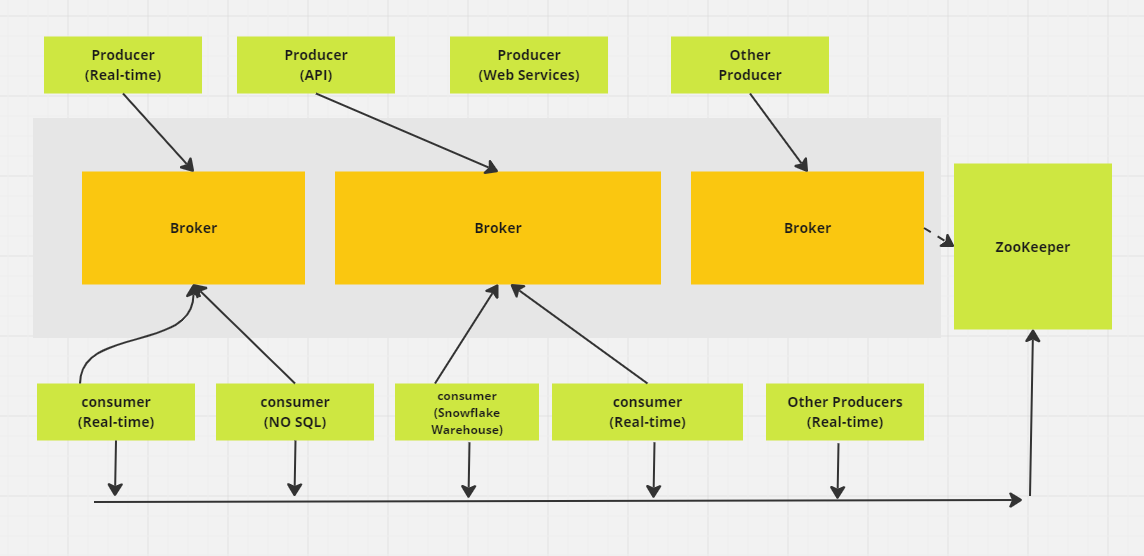
L'architecture distribuée de Kafka comprend plusieurs composants clés, dont le nœud de courtage. Les courtiers se chargent des opérations d'entrée/sortie et gèrent le stockage durable des messages. Ils reçoivent les données des producteurs, les stockent et les mettent à la disposition des consommateurs. Chaque courtier fait partie d'un cluster Kafka et possède un identifiant unique pour faciliter la coordination.
Dans les anciennes versions de Kafka, le cluster est géré à l'aide de Zookeeper, qui assure la bonne coordination entre les courtiers et suit les métadonnées telles que l'emplacement des partitions (bien que Kafka évolue vers un mode KRaft interne pour cela). Les brokers Kafka sont très évolutifs et capables de gérer de grands volumes de demandes de lecture et d'écriture de messages sur des systèmes distribués.
Nœuds ZooKeeper
ZooKeeper joue un rôle crucial dans Kafka en gérant l'enregistrement des courtiers et en élisant le contrôleur Kafka, qui s'occupe des opérations administratives pour le cluster. ZooKeeper fonctionne comme une grappe, appelée ensemble, où plusieurs processus travaillent ensemble pour s'assurer qu'un seul courtier à la fois est désigné comme contrôleur.
Si le contrôleur actuel tombe en panne, ZooKeeper élit rapidement un nouveau courtier pour prendre le relais. Bien que ZooKeeper ait été un élément essentiel de l'architecture de Kafka, Kafka est en train de passer à un nouveau mode KRaft qui supprime le besoin de ZooKeeper. ZooKeeper est un projet open-source indépendant et n'est pas un composant natif de Kafka.
Producteurs
Un producteur Kafka est une application client qui sert de source de données pour Kafka, en publiant des enregistrements dans un ou plusieurs sujets Kafka via des connexions TCP persistantes avec des courtiers.
Plusieurs producteurs peuvent envoyer simultanément des enregistrements à la même rubrique. Les sujets Kafka sont des append-only, ce qui signifie que les producteurs peuvent écrire de nouvelles données, mais que ni les producteurs ni les consommateurs ne peuvent modifier ou supprimer des enregistrements existants, ce qui garantit l'immuabilité des données.
Consommateurs
Un consommateur Kafka est une application client qui s'abonne à un ou plusieurs sujets Kafka pour consommer des flux d'enregistrements. Les consommateurs travaillent généralement dans des groupes de consommateurs, où la charge de lecture et de traitement des enregistrements est répartie entre plusieurs consommateurs.
Chaque consommateur suit sa progression dans le flux en conservant des décalages, ce qui garantit qu'aucune donnée n'est traitée deux fois et que les enregistrements non traités ne sont pas perdus. Les consommateurs Kafka constituent l'étape finale du pipeline de données, où les enregistrements sont traités ou transmis aux systèmes en aval.
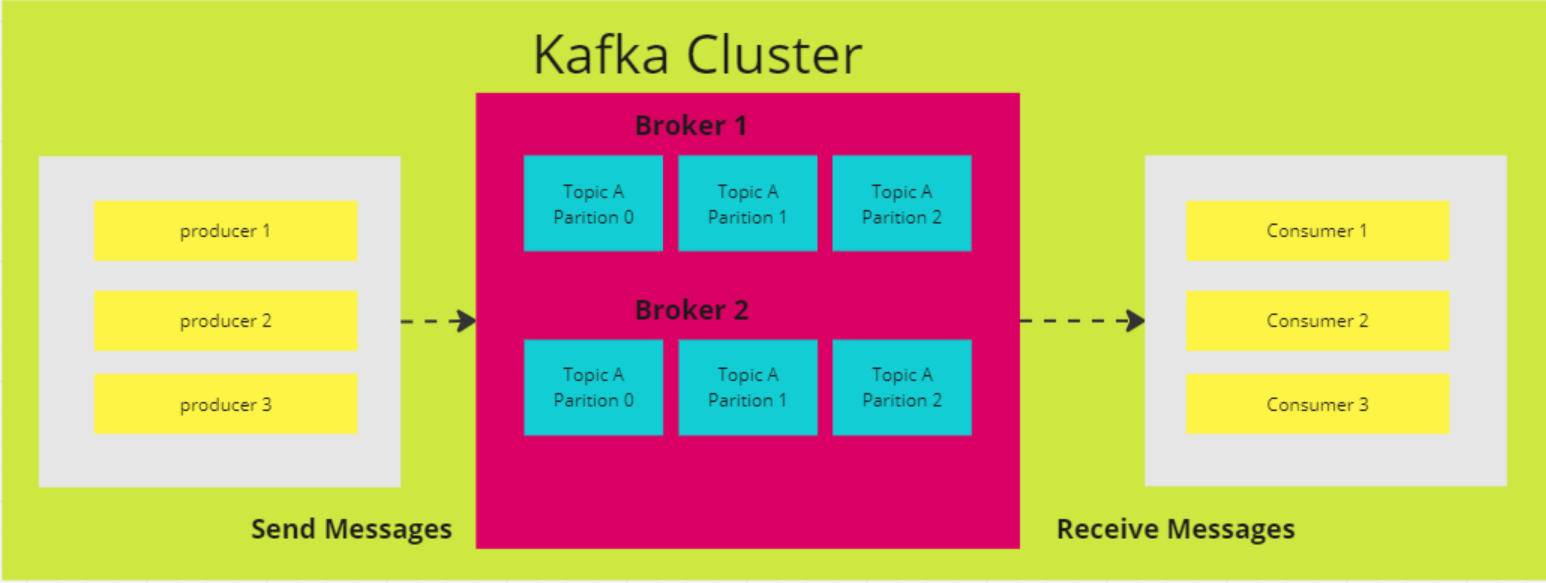
Schéma d'architecture d'Apache Kafka (Image de l'auteur)
8. Quel est l'objectif principal du compactage des journaux dans Kafka ? Quel est l'impact du compactage des journaux sur les performances des consommateurs Kafka ?
L'objectif principal du compactage du journal dans Kafka est de conserver la valeur la plus récente pour chaque clé unique dans le journal d'un sujet, en veillant à ce que l'état le plus récent des données soit préservé et en réduisant l'utilisation du stockage. Cela permet aux consommateurs d'accéder plus efficacement à la valeur actuelle sans avoir à traiter des duplicatas plus anciens.
Contrairement à la politique de conservation traditionnelle de Kafka, qui supprime les messages après une certaine période, le compactage des journaux supprime les enregistrements les plus anciens uniquement pour chaque clé, en conservant la valeur la plus récente pour cette clé. Cette fonction permet de garantir que les consommateurs ont toujours accès à l'état actuel tout en conservant un journal compact pour une meilleure efficacité de stockage et des recherches plus rapides.
9. Quelle est la différence entre les partitions et les répliques dans un cluster Kafka ?
Les partitions et les répliques sont des éléments clés de l'architecture de Kafka, qui garantissent à la fois les performances et la tolérance aux pannes. Les partitions augmentent le débit en permettant à un sujet d'être divisé en plusieurs parties, ce qui permet aux consommateurs de lire en parallèle différentes partitions, améliorant ainsi l'évolutivité et l'efficacité de Kafka.
Les répliques, quant à elles, assurent la redondance en créant des copies des partitions sur plusieurs courtiers. Cela garantit la tolérance aux pannes car, en cas de défaillance du courtier leader (le courtier qui gère les opérations de lecture et d'écriture pour une partition), l'une des répliques suiveuses peut être promue pour prendre le relais en tant que nouveau leader.
Kafka maintient plusieurs répliques de chaque partition pour assurer une haute disponibilité et la durabilité des données, minimisant ainsi le risque de perte de données en cas de défaillance, bien que la durabilité totale dépende des paramètres de réplication.
10. Qu'est-ce qu'un schéma dans Kafka, et pourquoi est-il important pour les systèmes distribués ?
Dans Kafka, un schéma définit la structure et le format des données, par exemple des champs tels que CustomerID (entier), CustomerName (chaîne de caractères) et Designation (chaîne de caractères).
Dans les systèmes distribués comme Kafka, les producteurs et les consommateurs doivent se mettre d'accord sur le format des données afin d'éviter les erreurs lors de l'échange de données. Le registre des schémas Kafka gère et applique ces schémas, en veillant à ce que les producteurs et les consommateurs utilisent des versions compatibles.
Le registre des schémas stocke les schémas (généralement dans des formats tels que Avro, Protobuf ou JSON Schema) et prend en charge l'évolution des schémas, ce qui permet de modifier les formats de données sans interrompre les consommateurs existants. Cela garantit un échange de données fluide et la fiabilité du système au fur et à mesure de l'évolution des schémas.
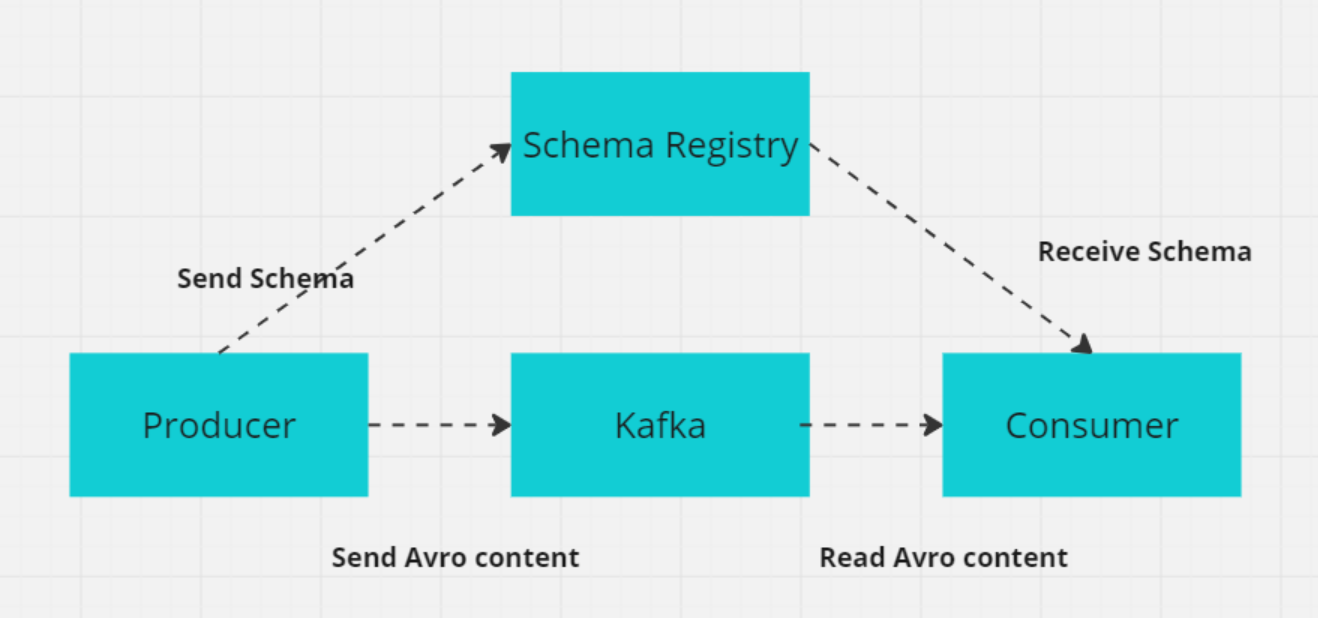
Comment le registre des schémas fonctionne avec le producteur/consommateur (Image de l'auteur)
Questions d'entretien avancées sur Kafka
Pour les utilisateurs plus avancés de Kafka, les questions d'entretien auxquelles vous serez confronté seront probablement de nature plus technique.
11. Comment Kafka assure-t-il la prévention des pertes de messages ?
Kafka utilise plusieurs mécanismes pour éviter la perte de messages et garantir la fiabilité de leur transmission :
- Commutation manuelle de l'offset: Les consommateurs peuvent désactiver la validation automatique des décalages et valider manuellement les décalages après avoir traité les messages avec succès afin d'éviter de perdre les messages non traités en cas de panne du consommateur.
- Remerciements aux producteurs (
acks=all) : Le fait de définiracks=allsur le producteur garantit que les messages sont acquittés par toutes les répliques synchronisées avant d'être considérés comme écrits avec succès, ce qui réduit le risque de perte de messages en cas de défaillance du courtier. - Réplication (
min.insync.replicasetreplication.factor) : Kafka réplique les données de chaque partition sur plusieurs courtiers. Un facteur de réplication supérieur à 1 garantit la tolérance aux pannes, ce qui permet aux données de rester disponibles même en cas de défaillance d'un courtier. Le paramètremin.insync.replicasgarantit qu'un nombre minimum de répliques accusent réception d'un message avant qu'il ne soit écrit, ce qui assure une meilleure durabilité des données. Par exemple, avec un facteur de réplication de 3, si un courtier tombe en panne, les données restent disponibles sur les deux autres courtiers. - Le producteur retente sa chance: Le fait de configurer les tentatives à une valeur élevée garantit que les producteurs tenteront à nouveau d'envoyer des messages en cas d'échec transitoire. Combiné à une configuration minutieuse, comme
max.in.flight.requests.per.connection=1, cela réduit le risque de réorganisation des messages et garantit que les messages sont finalement délivrés sans être perdus.
12. Quelle est la différence entre Kafka et RabbitMq ?
Kafka et RabbitMQ sont deux systèmes de messagerie populaires et différents en termes d'architecture et d'utilisation. Vous pouvez voir comment ils se comparent dans des domaines clés :
1. Utilisation et conception
Kafka est conçu pour gérer des flux de données à grande échelle et des pipelines en temps réel, optimisés pour un débit élevé et une faible latence. Son architecture basée sur les journaux garantit la durabilité et permet le retraitement des données, ce qui la rend idéale pour des cas d'utilisation tels que l'approvisionnement en événements et le traitement des flux.
RabbitMQ est un courtier de messages polyvalent qui prend en charge un routage complexe et qui est généralement utilisé pour la messagerie entre les microservices ou la distribution des tâches entre les travailleurs. Il excelle dans les environnements où la fiabilité de la transmission des messages, la souplesse du routage et l'interaction entre les services sont essentielles.
2. L'architecture
Kafka classe les messages en rubriques, qui sont elles-mêmes divisées en partitions. Chaque partition peut être traitée par plusieurs consommateurs, ce qui permet un traitement parallèle et une mise à l'échelle. Les données sont stockées sur disque avec une période de rétention configurable, ce qui garantit leur durabilité et permet de retraiter les messages en cas de besoin.
RabbitMQ envoie des messages aux files d'attente, où ils sont consommés par un ou plusieurs consommateurs. Il garantit une livraison fiable grâce à des accusés de réception, des tentatives et des échanges de lettres mortes pour traiter les messages qui échouent. Cette architecture met l'accent sur l'intégrité des messages et la flexibilité du routage.
3. Performance et évolutivité
Kafka est conçu pour évoluer horizontalement en ajoutant des courtiers et des partitions, ce qui lui permet de traiter des millions de messages par seconde. Son architecture prend en charge le traitement parallèle et un débit élevé, ce qui en fait un outil idéal pour la diffusion de données en continu à grande échelle.
RabbitMQ peut évoluer, mais pas aussi efficacement que Kafka, lorsqu'il s'agit de traiter de très gros volumes de données. Il convient aux scénarios de débit moyen à élevé, mais n'est pas optimisé pour le débit extrême que Kafka peut gérer dans les applications de streaming à grande échelle.
Résumé: Kafka et RabbitMQ sont tous deux des outils puissants pour la messagerie, mais ils excellent dans des cas d'utilisation différents. Kafka est idéal pour les applications de flux de données en temps réel à haut débit et d'approvisionnement en événements qui nécessitent un traitement parallèle à grande échelle.
RabbitMQ est bien adapté à la livraison fiable de messages, à la distribution de tâches dans les architectures de microservices et à l'acheminement complexe de messages. Il excelle dans les scénarios nécessitant un couplage lâche entre les services, un traitement asynchrone et la fiabilité.
13. Comment Kafka aide-t-il à développer des applications basées sur les microservices ?
Apache Kafka est un outil précieux pour la construction d'architectures de microservices en raison de ses capacités de traitement des données en temps réel, de communication pilotée par les événements et de messagerie fiable. Voici comment Kafka prend en charge le développement de microservices :
1. Architecture pilotée par les événements
- Découplage des services: Kafka permet aux services de communiquer par le biais d'événements plutôt que par des appels directs, ce qui réduit les dépendances entre eux. Ce découplage permet aux services de produire et de consommer des événements de manière indépendante, ce qui simplifie l'évolution et la maintenance des services.
- Traitement asynchrone: Les services peuvent publier des événements et poursuivre leur traitement sans attendre la réponse des autres services, ce qui améliore la réactivité et l'efficacité du système.
2. Évolutivité
- Évolutivité horizontale: Kafka peut gérer de gros volumes de données en répartissant la charge entre plusieurs courtiers et partitions. Chaque partition peut être traitée par différentes instances de consommateurs, ce qui permet au système d'évoluer horizontalement.
- Consommation parallèle: Plusieurs consommateurs peuvent lire simultanément dans différentes partitions, ce qui augmente le débit et les performances.
3. Fiabilité et tolérance aux pannes
- Réplication des données: Kafka réplique les données sur plusieurs courtiers, ce qui garantit une haute disponibilité et une tolérance aux pannes. Si un courtier tombe en panne, un autre peut prendre le relais avec les données répliquées. Kafka stocke les données sur disque avec des périodes de rétention configurables, ce qui garantit que les événements ne sont pas perdus et qu'ils peuvent être retraités si nécessaire.
4. Intégration des données
- Centre de données central: Kafka joue le rôle de plaque tournante pour le flux de données au sein d'une architecture de microservices, facilitant l'intégration entre diverses sources et puits de données. Cela simplifie le maintien de la cohérence des données entre les services.
- Kafka Connect: Kafka Connect fournit des connecteurs pour intégrer Kafka avec de nombreuses bases de données, des magasins de valeurs clés, des index de recherche et d'autres systèmes, rationalisant ainsi le mouvement des données entre les microservices et les systèmes externes.
14. Qu'est-ce que Kafka Zookeeper et comment fonctionne-t-il ?
Apache ZooKeeper est un service open-source qui aide à coordonner et à gérer les données de configuration, la synchronisation et les services de groupe dans les systèmes distribués. Dans les anciennes versions de Kafka, ZooKeeper jouait un rôle essentiel dans la gestion des métadonnées, l'élection des leaders et la coordination des courtiers.
Cependant, Kafka est passé en mode KRaft depuis la version 2.8, ce qui élimine le besoin de ZooKeeper. ZooKeeper est désormais considéré comme obsolète et sera supprimé dans la version 4.0, prévue pour 2024.
ZooKeeper stocke les données dans une structure hiérarchique de nœuds appelés "znodes", où chaque znode peut stocker des métadonnées et avoir des znodes enfants, comme dans un système de fichiers. Cette structure est cruciale pour la gestion des métadonnées relatives aux courtiers Kafka, aux sujets et aux partitions. Le mécanisme de ZooKeeper, basé sur le quorum, garantit la cohérence : une majorité de nœuds (quorum) doit approuver tout changement, ce qui rend ZooKeeper extrêmement fiable et tolérant aux pannes.
Dans les anciennes versions de Kafka, ZooKeeper est utilisé pour plusieurs fonctions critiques :
- Élection du chef de file: ZooKeeper élit un nœud contrôleur, qui gère l'attribution des chefs de partition et d'autres tâches à l'échelle du cluster.
- Gestion des métadonnées du courtier: Elle tient un registre centralisé des courtiers actifs et de leur statut.
- Réaffectation des partitions: ZooKeeper aide à gérer le rééquilibrage des partitions entre les courtiers en cas de défaillance ou d'extension de la grappe.
Le protocole ZAB (ZooKeeper Atomic Broadcast) de ZooKeeper garantit la cohérence entre les nœuds, même en cas de partition du réseau, ce qui permet à Kafka de rester tolérant aux pannes. Cette cohérence et cette fiabilité rendent ZooKeeper crucial pour gérer la nature distribuée de Kafka, même si l'avenir de l'architecture de Kafka reposera moins sur ZooKeeper à mesure que KRaft deviendra le mode par défaut.
15. Comment réduire l'utilisation du disque dans Kafka ?
Kafka propose plusieurs moyens de réduire efficacement l'utilisation du disque. Voici quelques stratégies clés :
1. Ajustez les paramètres de conservation des journaux
Modifiez la politique de conservation des journaux afin de réduire la durée de conservation des messages sur le disque. Pour ce faire, vous pouvez ajuster retention.ms (rétention basée sur le temps) ou retention.bytes (rétention basée sur la taille) afin de limiter la durée ou la quantité de données que Kafka stocke avant de supprimer les messages les plus anciens.
2. Mise en œuvre du compactage des grumes
Utilisez le compactage des journaux pour ne conserver que le message le plus récent pour chaque clé unique, en supprimant les données obsolètes ou redondantes. Cette fonction est particulièrement utile dans les scénarios où seul le dernier état est pertinent, ce qui permet de réduire l'utilisation de l'espace disque sans perdre d'informations importantes.
3. Configurer les politiques de nettoyage
Définissez des politiques de nettoyage efficaces en fonction de votre cas d'utilisation. Vous pouvez configurer des politiques de rétention basées sur la durée (retention.ms) et sur la taille (retention.bytes) pour supprimer automatiquement les messages les plus anciens et gérer l'empreinte disque de Kafka.
4. Compression des messages
Activez la compression des messages du côté du producteur en utilisant des formats tels que GZIP, Snappy ou LZ4. La compression réduit la taille des messages, ce qui permet de réduire la consommation d'espace disque. Cependant, il est important de prendre en compte le compromis entre la réduction de l'utilisation du disque et l'augmentation de la charge de travail du processeur due à la compression et à la décompression.
5. Ajuster la taille du segment du journal
Configurez la taille du segment de journal de Kafka (segment.bytes) pour contrôler la fréquence à laquelle les segments de journal sont roulés. La réduction de la taille des segments permet un renouvellement plus fréquent des journaux, ce qui peut contribuer à une utilisation plus efficace du disque en permettant une suppression plus rapide des données les plus anciennes.
6. Supprimez les rubriques ou les partitions inutiles
Examinez et supprimez périodiquement les rubriques et les partitions inutilisées ou superflues. Cela permet de libérer de l'espace disque et de contrôler l'utilisation du disque par Kafka.
Questions d'entretien sur Kafka pour les ingénieurs de données
Si vous passez un entretien pour un poste d'ingénieur en données, vous pouvez vous préparer aux questions suivantes sur Kafka.
16. Quelles sont les différences entre la réplique du leader et la réplique du suiveur dans Kafka ?
Réplique du chef de file
La réplique leader traite toutes les demandes de lecture et d'écriture des clients. Il gère l'état de la partition et constitue le principal point d'interaction entre les producteurs et les consommateurs. En cas de défaillance du leader, son rôle est transféré à l'une des répliques suiveuses afin de maintenir la disponibilité.
Réplique de l'adepte
La réplique du suiveur reproduit les données du leader mais ne traite pas directement les demandes des clients. Son rôle est d'assurer la tolérance aux pannes en conservant une copie à jour des données de la partition. À partir de Kafka 2.4, sous certaines conditions, les répliques suiveuses peuvent également traiter les demandes de lecture afin de répartir la charge et d'améliorer le débit de lecture. En cas de défaillance du leader, un suiveur est élu comme nouveau leader afin de maintenir la cohérence et la disponibilité des données.
17. Pourquoi utiliser des clusters dans Kafka, et quels sont leurs avantages ?
Un cluster Kafka est composé de plusieurs courtiers qui distribuent les données sur plusieurs instances, ce qui permet une évolutivité sans temps d'arrêt. Ces clusters sont conçus pour minimiser les délais et, en cas de défaillance du cluster primaire, d'autres clusters Kafka peuvent prendre le relais pour maintenir la continuité du service.
L'architecture d'un cluster Kafka comprend des sujets, des courtiers, des producteurs et des consommateurs. Il gère efficacement les flux de données, ce qui le rend idéal pour les applications big data et le développement d'applications basées sur les données.
18. Comment Kafka assure-t-il l'ordre des messages ?
Kafka assure l'ordre des messages de deux manières principales :
- Utilisation des touches de message: Lorsqu'une clé est attribuée à un message, tous les messages ayant la même clé sont envoyés à la même partition. Cela permet de s'assurer que les messages ayant la même clé sont traités dans l'ordre où ils ont été reçus, car Kafka préserve l'ordre au sein de chaque partition.
- Traitement des consommateurs en mode monotâche: Pour maintenir l'ordre, le consommateur doit traiter les messages d'une partition dans un seul thread. Si plusieurs threads sont utilisés, mettez en place des files d'attente en mémoire distinctes pour chaque partition afin de garantir que les messages sont traités dans le bon ordre lors d'un traitement simultané.
19. Que représentent ISR et AR dans Kafka ? Que signifie l'expansion de l'EIS ?
ISR (répliques synchronisées)
ISR fait référence aux répliques qui sont entièrement synchronisées avec la réplique leader. Ces répliques contiennent les données les plus récentes et sont considérées comme fiables pour les opérations de lecture et d'écriture.
AR (répliques affectées)
AR inclut toutes les répliques assignées à une partition, aussi bien les répliques synchronisées que celles qui ne le sont pas. Il représente l'ensemble des répliques d'une partition.
Expansion de l'EIS
L'expansion de l'EIS se produit lorsque de nouvelles répliques rattrapent le leader et sont ajoutées à la liste de l'EIS. Cela permet d'augmenter le nombre de répliques à jour et d'améliorer la tolérance aux pannes et la fiabilité.
20. Qu'est-ce qu'un scénario d'utilisation sans copie dans Kafka ?
Kafka utilise la fonction "zero-copy" pour transférer efficacement de grands volumes de données entre les producteurs et les consommateurs. Il s'appuie sur la méthode FileChannel.transferTo pour déplacer les données directement du système de fichiers vers les sockets du réseau sans copie supplémentaire, ce qui améliore les performances et le débit.
Cette technique utilise des fichiers mappés en mémoire (mmap) pour lire les fichiers d'index, ce qui permet de partager les tampons de données entre l'espace utilisateur et l'espace noyau, réduisant ainsi la nécessité de copier des données supplémentaires. Kafka est donc bien adapté au traitement efficace de flux de données en temps réel à grande échelle.
Préparer votre entretien avec Kafka
Alors que vous vous préparez à un entretien d'ingénierie des données axé sur Kafka, il est crucial d'avoir à la fois des bases techniques solides et une compréhension claire de la façon dont Kafka s'intègre dans les systèmes modernes. Kafka est au cœur de nombreuses plateformes de données en temps réel. Les recruteurs s'attendront donc à ce que vous connaissiez les bases et la manière dont Kafka fonctionne dans des environnements évolutifs et tolérants aux pannes.
Domaines clés sur lesquels se concentrer
Comme nous l'avons vu à travers les questions d'entretien Kafka que nous avons couvertes ici, il y a plusieurs domaines clés que vous devrez rafraîchir :
- Architecture: Vous pouvez discuter en toute confiance de l'architecture de Kafka, y compris les courtiers, les partitions et l'interaction entre les producteurs et les consommateurs. Vous devez également expliquer les garanties de livraison des messages de Kafka - comme la livraison "au moins une fois" ou "exactement une fois" - et la façon dont Kafka assure l'ordre des messages grâce à des fonctionnalités telles que les répliques In-Sync (ISR).
- Intégration: Comprendre comment Kafka s'intègre à d'autres systèmes à l'aide d'outils tels que Kafka Connect, qui connecte des bases de données, des magasins de valeurs clés et d'autres systèmes. Les enquêteurs peuvent poser des questions sur le rôle de Kafka dans le maintien de la cohérence des données dans les microservices ou les systèmes distribués.
- Surveillance et dépannage: Une bonne connaissance des outils de surveillance tels que Kafka Manager et Prometheus est importante. Vous devrez démontrer votre capacité à gérer et à optimiser efficacement les clusters Kafka.
- Résolution de problèmes: Préparez-vous à concevoir des solutions de messagerie permettant de résoudre des problèmes concrets, tels que la gestion de flux de données importants ou la garantie de la fiabilité des messages. Les intervieweurs peuvent vous proposer des scénarios hypothétiques dans lesquels vous devrez dépanner ou optimiser les performances de Kafka.
- Communication: Kafka est complexe, vous devez donc être en mesure d'expliquer clairement vos décisions de conception ou les étapes de dépannage, que ce soit aux équipes techniques ou aux parties prenantes de l'entreprise. De solides compétences en communication vous permettront de vous démarquer.
- Expérience pratique: Mettez en avant toute expérience pratique, telle que la mise en place de clusters Kafka, la gestion de la rétention des données ou l'intégration de Kafka avec d'autres outils. Les connaissances pratiques sont très appréciées.
- Apprentissage continu: Restez informé des dernières fonctionnalités et des meilleures pratiques de Kafka. La lecture de la documentation ou la participation à des projets à code source ouvert témoignent de votre engagement en faveur de l'apprentissage continu.
Conseils pour l'entretien
Voici quelques conseils pour réussir votre entretien :
- Faites des recherches sur l'entreprise, le secteur d'activité et les antécédents de votre interlocuteur.
- Préparez-vous aux différentes séries d'entretiens (technique, RH, téléphonique et en personne) avec une approche sur mesure.
- Examinez régulièrement les ressources techniques telles que
En perfectionnant ces compétences et en vous préparant efficacement, vous serez bien équipé pour les entretiens liés à Kafka. N'oubliez pas que les recruteurs ne recherchent pas seulement une expertise technique, mais aussi une communication claire et des compétences en matière de résolution de problèmes concrets. Montrez votre passion pour l'ingénierie des données tout au long du processus d'entretien.
