Zu verstehen, wie Daten fließen und ihr Potenzial zu nutzen, ist für moderne Unternehmen absolut entscheidend geworden. Kafka ist die führende Plattform für das Aufnehmen, Speichern und Verarbeiten von Echtzeit-Datenströmen in der modernen Anwendungslandschaft.
In diesem Beitrag stellen wir dir einige Kafka-Interviewfragen vor und gehen auf die entscheidende Rolle des Tools bei der Datenverarbeitung ein. Wir werden uns mit den verschiedenen Stufen von Vorstellungsgesprächen beschäftigen, von einfachen bis hin zu fortgeschrittenen Fragen, und dir Tipps geben, wie du dich effektiv vorbereiten kannst. Wenn du neu bei Kafka bist, solltest du dir unseren Kurs Einführung in Apache Kafka ansehen.
Grundlegende Fragen zum Kafka-Interview
Diese Fragen testen dein grundlegendes Verständnis von Kafka als Werkzeug für Data Engineering.
1. Was ist Apache Kafka?
Apache Kafka ist eine leistungsstarke, verteilte Open-Source-Plattform für Event-Streaming. Ursprünglich von LinkedIn als Messaging-Queue entwickelt, hat sie sich zu einem Tool für die Verarbeitung von Datenströmen in verschiedenen Szenarien entwickelt.
Die verteilte Systemarchitektur von Kafka ermöglicht eine horizontale Skalierbarkeit, so dass die Verbraucher Nachrichten in ihrem eigenen Tempo abrufen können und es einfach ist, Kafka-Knoten (Server) zum Cluster hinzuzufügen.
Kafka ist darauf ausgelegt, große Datenmengen schnell und mit geringer Latenz zu verarbeiten. Obwohl es in Scala und Java geschrieben ist, unterstützt es eine breite Palette von Programmiersprachen.

Apache Kafka fungiert als verteilter Log-Collector, in dem Log-Meldungen als Key-Value-Paare in einer Append-Only-Log-Datei für eine dauerhafte, langfristige Speicherung und Abfrage gespeichert werden. Im Gegensatz zu traditionellen Nachrichtenwarteschlangen wie RabbitMQ, die Nachrichten löschen, nachdem sie verbraucht wurden, speichert Kafka Nachrichten für einen konfigurierbaren Zeitraum, was es ideal für Anwendungsfälle macht, die eine Wiederholung von Daten oder eine Ereignisbeschaffung erfordern.
Während RabbitMQ sich auf die Nachrichtenübermittlung in Echtzeit konzentriert, ohne Nachrichten langfristig zu speichern, unterstützt die Aufbewahrungsrichtlinie von Kafka komplexere, datengetriebene Anwendungen.
Zu den üblichen Anwendungsfällen für Kafka gehören die Verfolgung von Anwendungen, die Aggregation von Protokollen und das Messaging, obwohl es keine traditionellen Datenbankfunktionen wie Abfragen und Indizierung gibt. Seine Stärke liegt in der Verarbeitung von Echtzeit-Datenströmen, was ihn für verteilte Systeme und Echtzeit-Analysen unverzichtbar macht.
2. Was sind einige der Funktionen von Kafka?
Apache Kafka ist eine Open-Source-Plattform für verteiltes Streaming, die häufig für den Aufbau von Echtzeit-Datenpipelines und Streaming-Anwendungen verwendet wird. Es bietet die folgenden Funktionen:
1. Hoher Durchsatz
Kafka ist in der Lage, riesige Datenmengen zu verarbeiten. Er wurde entwickelt, um effizient Hunderte von Gigabytes von Quellclients zu lesen und zu schreiben.
2. Verteilte Architektur
Apache Kafka hat eine cluster-zentrierte Architektur und unterstützt von Haus aus die Partitionierung von Nachrichten zwischen Kafka-Servern. Dieses Design ermöglicht auch einen verteilten Verbrauch über einen Cluster von Verbrauchermaschinen, wobei die Reihenfolge der Nachrichten innerhalb jeder Partition beibehalten wird. Außerdem kann ein Kafka-Cluster elastisch und transparent skaliert werden, ohne dass es zu Ausfallzeiten kommt.
3. Unterstützung für verschiedene Kunden
Apache Kafka unterstützt die Integration von Clients aus verschiedenen Plattformen wie .NET, JAVA, PHP und Python.
4. Echtzeit-Nachrichten
Kafka produziert Echtzeitnachrichten, die für die Konsumenten sichtbar sein sollten; dies ist wichtig für komplexe Ereignisverarbeitungssysteme.
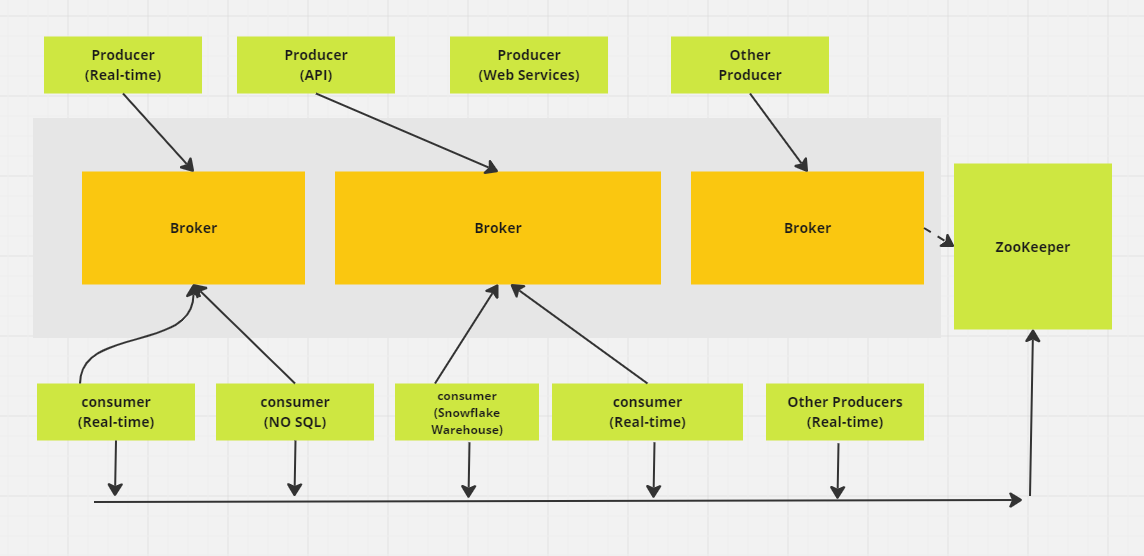
Apache Kafka Messaging Verteiltes System. (Bild vom Autor)
3. Wie funktionieren die Partitionen in Kafka?
In Kafka dient ein Topic als Speicherplatz, in dem alle Nachrichten von Produzenten aufbewahrt werden. Normalerweise werden zusammengehörige Daten in separaten Themen gespeichert. Ein Thema mit dem Namen "Transaktionen" würde zum Beispiel Details zu den Einkäufen der Nutzer auf einer E-Commerce-Website speichern, während ein Thema mit dem Namen "Kunden" Kundeninformationen enthält.
Die Themen sind in Fächer unterteilt. Standardmäßig hat ein Thema eine Partition, aber du kannst es so konfigurieren, dass es mehrere hat. Die Nachrichten werden auf diese Partitionen verteilt, wobei jede Partition ihren eigenen Offset hat und auf einem anderen Server im Kafka-Cluster gespeichert wird.
Wenn ein Thema zum Beispiel drei Partitionen hat, die sich auf drei Broker verteilen, und ein Produzent 15 Nachrichten sendet, werden die Nachrichten der Reihe nach verteilt:
- Datensatz 1 geht an Partition 0
- Datensatz 2 geht an Partition 1
- Datensatz 3 geht an Partition 2
Dann wiederholt sich der Zyklus, wobei Datensatz 4 zurück in Partition 0 geht, und so weiter.
4. Warum solltest du Kafka anderen Messaging-Diensten vorziehen?
Die Entscheidung, Kafka anderen Messaging-Diensten vorzuziehen, hängt oft mit seinen einzigartigen Stärken zusammen, insbesondere bei Anwendungsfällen, die einen hohen Durchsatz und Datenverarbeitung in Echtzeit erfordern. Hier ist der Grund, warum Kafka so besonders ist:
- Hoher Durchsatz und Skalierbarkeit: Kafka kann große Datenmengen effizient verarbeiten. Seine Architektur unterstützt die horizontale Skalierung, so dass du weitere Broker und Partitionen hinzufügen kannst, um steigende Datenmengen ohne Leistungseinbußen zu bewältigen.
- Verarbeitung in Echtzeit: Sie eignet sich hervorragend für das Streaming von Daten in Echtzeit und ist damit perfekt für Anwendungsfälle wie Aktivitätsverfolgung und Betriebsüberwachung. LinkedIn hat zum Beispiel Kafka entwickelt, um seine Pipeline für die Aktivitätsverfolgung zu verwalten und so Echtzeit-Feeds von Nutzerinteraktionen wie Klicks und Likes zu veröffentlichen.
- Nachrichtenwiederholung: Kafka ermöglicht es Verbrauchern, Nachrichten wiederzugeben, was hilfreich ist, wenn ein Verbraucher auf einen Fehler stößt oder überlastet ist. So wird sichergestellt, dass keine Daten verloren gehen - die Verbraucher können verpasste Nachrichten wiederherstellen und abspielen, um die Datenintegrität zu wahren.
- Langlebigkeit und Fehlertoleranz: Das Tool repliziert Daten über mehrere Broker hinweg und sorgt so für Zuverlässigkeit, selbst wenn einige Broker ausfallen. Durch dieses fehlertolerante Design bleiben die Daten zugänglich und bieten Sicherheit für kritische Vorgänge.
5. Erkläre alle von Apache Kafka bereitgestellten APIs.
Eine API (Application Programming Interface) ermöglicht die Kommunikation zwischen verschiedenen Diensten, Microservices und Systemen. Kafka bietet eine Reihe von APIs zum Aufbau von Event-Streaming-Plattformen und zur Interaktion mit seinem Nachrichtensystem.
Die wichtigsten Kafka-APIs sind:
- Erzeuger-API: Wird verwendet, um Echtzeitdaten an Kafka-Themen zu senden. Producer bestimmen, an welche Partition innerhalb eines Topics jede Nachricht gehen soll, wobei Callbacks den Erfolg oder Misserfolg von Sendevorgängen behandeln.
- Verbraucher-API: Ermöglicht das Lesen von Echtzeitdaten aus Kafka-Themen. Verbraucher können Teil einer Verbrauchergruppe sein, um die Last zu verteilen und parallel zu verarbeiten, Themen zu abonnieren und Kafka kontinuierlich nach neuen Nachrichten abzufragen.
- Streams API: Unterstützt die Entwicklung von Echtzeitanwendungen, die Daten in Kafka transformieren, aggregieren und analysieren. Sie bietet eine High-Level-DSL (Domain Specific Language) zur Definition komplexer Stromverarbeitungslogik.
- Kafka Connect API: Wird verwendet, um wiederverwendbare Konnektoren zum Importieren und Exportieren von Daten zwischen Kafka und externen Systemen zu erstellen und auszuführen.
- Admin API: Stellt Werkzeuge für die Verwaltung und Konfiguration von Kafka-Themen, Brokern und anderen Ressourcen bereit, um einen reibungslosen Betrieb und Skalierbarkeit zu gewährleisten.
Diese APIs ermöglichen eine nahtlose Datenproduktion, -nutzung, -verarbeitung und -verwaltung innerhalb von Kafka.
Kafka-Interview-Fragen für Fortgeschrittene
Diese Fragen richten sich an erfahrene Praktiker, die Kafkas Einsatzmöglichkeiten bereits gut kennen.
6. Was bedeutet es, wenn man die Anzahl der Partitionen in einem Kafka-Topic erhöht?
Wenn du die Anzahl der Partitionen in einem Kafka-Topic erhöhst, kannst du die Gleichzeitigkeit und den Durchsatz verbessern, da mehr Konsumenten parallel lesen können. Allerdings bringt sie auch einige Herausforderungen mit sich:
- Erhöhter Cluster-Overhead: Mehr Partitionen verbrauchen zusätzliche Cluster-Ressourcen, was zu einem höheren Netzwerkverkehr für die Replikation und einem höheren Speicherbedarf führt.
- Mögliche Unausgewogenheit der Daten: Wenn die Zahl der Partitionen zunimmt, sind die Daten möglicherweise nicht gleichmäßig verteilt, was dazu führen kann, dass einige Partitionen überlastet sind, während andere nicht ausgelastet sind.
- Komplexere Verwaltung von Verbrauchergruppen: Je mehr Partitionen, desto komplizierter wird die Verwaltung der Verbrauchergruppenzuweisungen und die Nachverfolgung von Offsets.
- Längere Umschichtungszeiten: Wenn Verbraucher hinzukommen oder die Gruppe verlassen, kann die Neuverteilung der Partitionen in der Gruppe länger dauern, was die Reaktionsfähigkeit des Systems insgesamt beeinträchtigt.
7. Erkläre die vier Komponenten der Kafka-Architektur
Kafka ist eine verteilte Architektur, die aus mehreren Schlüsselkomponenten besteht:
Broker-Knoten
Die verteilte Architektur von Kafka besteht aus mehreren Schlüsselkomponenten, von denen eine der Broker-Knoten ist. Broker übernehmen die schwere Arbeit der Ein- und Ausgabeoperationen und verwalten die dauerhafte Speicherung von Nachrichten. Sie erhalten Daten von den Produzenten, speichern sie und stellen sie den Verbrauchern zur Verfügung. Jeder Broker ist Teil eines Kafka-Clusters und hat eine eindeutige ID, die bei der Koordination hilft.
In älteren Versionen von Kafka wird der Cluster mithilfe von Zookeeper verwaltet, der die ordnungsgemäße Koordination zwischen den Brokern sicherstellt und Metadaten wie die Standorte der Partitionen verfolgt (Kafka bewegt sich jedoch in Richtung eines internen KRaft-Modus für diese Aufgabe). Kafka-Broker sind hoch skalierbar und in der Lage, große Mengen von Lese- und Schreibanfragen für Nachrichten über verteilte Systeme hinweg zu verarbeiten.
ZooKeeper-Knoten
ZooKeeper spielt eine entscheidende Rolle bei Kafka, indem er die Registrierung der Broker verwaltet und den Kafka-Controller wählt, der die Verwaltungsaufgaben für den Cluster übernimmt. ZooKeeper arbeitet selbst als Cluster, ein sogenanntes Ensemble, in dem mehrere Prozesse zusammenarbeiten, um sicherzustellen, dass jeweils nur ein Broker als Controller eingesetzt wird.
Wenn der aktuelle Controller ausfällt, wählt ZooKeeper schnell einen neuen Broker, der die Aufgabe übernimmt. Obwohl der ZooKeeper ein wesentlicher Bestandteil der Kafka-Architektur war, geht Kafka zu einem neuen KRaft-Modus über, der den ZooKeeper überflüssig macht. ZooKeeper ist ein unabhängiges Open-Source-Projekt und keine native Kafka-Komponente.
Erzeuger
Ein Kafka-Producer ist eine Client-Anwendung, die als Datenquelle für Kafka dient und Datensätze in einem oder mehreren Kafka-Themen über dauerhafte TCP-Verbindungen zu Brokern veröffentlicht.
Mehrere Produzenten können gleichzeitig Datensätze an dasselbe Thema senden. Kafka-Themen sind "append-only", d.h. Produzenten können neue Daten schreiben, aber weder Produzenten noch Konsumenten können bestehende Datensätze ändern oder löschen, was die Unveränderlichkeit der Daten gewährleistet.
Verbraucherinnen und Verbraucher
Ein Kafka-Konsument ist eine Client-Anwendung, die ein oder mehrere Kafka-Themen abonniert, um Datensatzströme zu konsumieren. Verbraucher arbeiten normalerweise in Verbrauchergruppen, in denen die Last des Lesens und Verarbeitens von Datensätzen auf mehrere Verbraucher verteilt wird.
Jeder Verbraucher verfolgt seinen Weg durch den Stream, indem er Offsets beibehält. So wird sichergestellt, dass keine Daten doppelt verarbeitet werden und keine unbearbeiteten Datensätze verloren gehen. Kafka-Konsumenten fungieren als letzter Schritt in der Datenpipeline, wo Datensätze verarbeitet oder an nachgelagerte Systeme weitergeleitet werden.
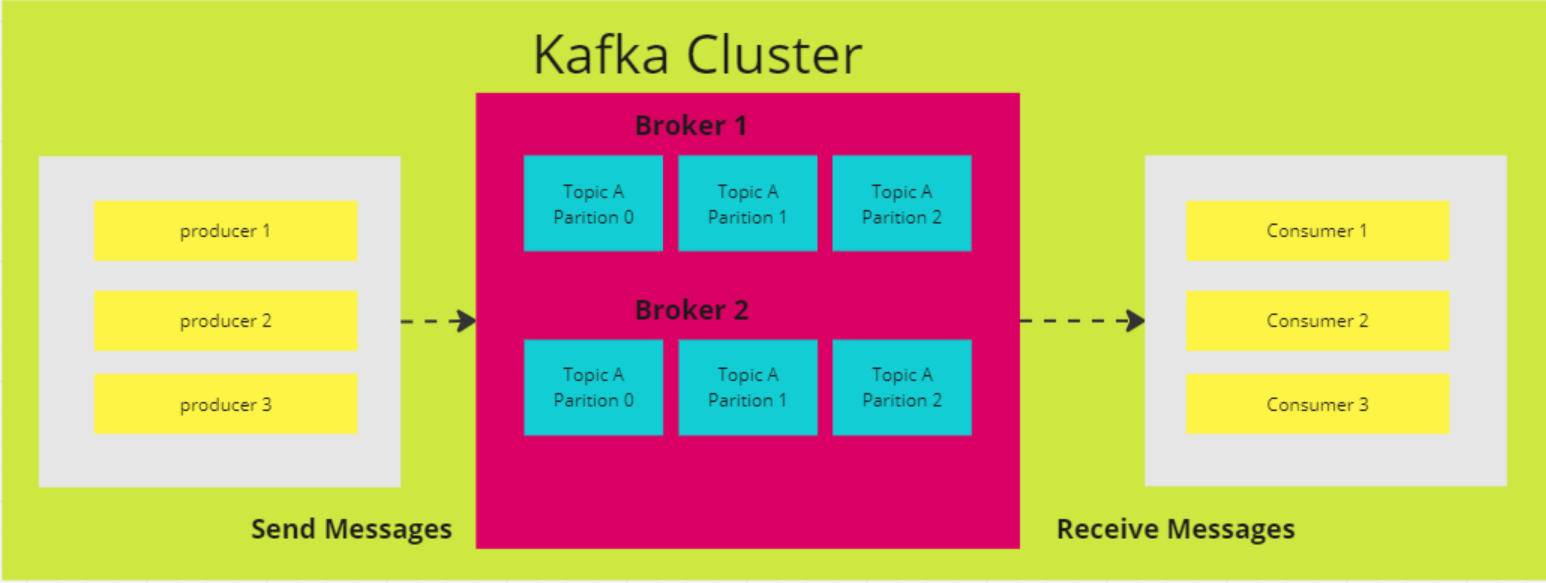
Architekturdiagramm von Apache Kafka (Bild vom Autor)
8. Was ist der Hauptzweck der Log-Verdichtung in Kafka? Wie wirkt sich die Protokollverdichtung auf die Leistung von Kafka-Konsumenten aus?
Das Hauptziel der Protokollverdichtung in Kafka ist es, den aktuellsten Wert für jeden eindeutigen Schlüssel im Protokoll eines Themas beizubehalten, um sicherzustellen, dass der aktuelle Stand der Daten erhalten bleibt und der Speicherbedarf reduziert wird. So können die Verbraucherinnen und Verbraucher effizienter auf den aktuellen Wert zugreifen, ohne ältere Duplikate bearbeiten zu müssen.
Im Gegensatz zur traditionellen Aufbewahrungsrichtlinie von Kafka, bei der Nachrichten nach einer bestimmten Zeitspanne gelöscht werden, werden bei der Protokollverdichtung nur ältere Datensätze für jeden Schlüssel gelöscht, wobei der neueste Wert für diesen Schlüssel erhalten bleibt. Diese Funktion stellt sicher, dass die Verbraucher immer Zugriff auf den aktuellen Stand haben und gleichzeitig ein kompaktes Protokoll für eine bessere Speichereffizienz und schnellere Nachforschungen erhalten.
9. Was ist der Unterschied zwischen Partitionen und Replikaten in einem Kafka-Cluster?
Partitionen und Replikate sind Schlüsselkomponenten der Kafka-Architektur, die sowohl Leistung als auch Fehlertoleranz gewährleisten. Partitionen erhöhen den Durchsatz, indem sie es ermöglichen, ein Topic in mehrere Teile aufzuteilen, so dass die Konsumenten parallel aus verschiedenen Partitionen lesen können, was die Skalierbarkeit und Effizienz von Kafka verbessert.
Replikate hingegen sorgen für Redundanz, indem sie Kopien von Partitionen auf mehreren Brokern erstellen. Dies gewährleistet Fehlertoleranz, da im Falle eines Ausfalls des Leader-Brokers (des Brokers, der die Lese- und Schreibvorgänge für eine Partition verwaltet) eines der Follower-Replikate die Rolle des neuen Leaders übernehmen kann.
Kafka unterhält mehrere Replikate jeder Partition, um hohe Verfügbarkeit und Datenbeständigkeit zu gewährleisten und das Risiko von Datenverlusten bei Ausfällen zu minimieren.
10. Was ist ein Schema in Kafka, und warum ist es für verteilte Systeme wichtig?
In Kafka definiert ein Schema die Struktur und das Format der Daten, z. B. Felder wie CustomerID (Integer), CustomerName (String) und Designation (String).
In verteilten Systemen wie Kafka müssen sich Produzenten und Konsumenten auf das Datenformat einigen, um Fehler beim Datenaustausch zu vermeiden. Die Kafka Schema Registry verwaltet und erzwingt diese Schemata und stellt sicher, dass sowohl Produzenten als auch Konsumenten kompatible Versionen verwenden.
Die Schema Registry speichert Schemata (üblicherweise in Formaten wie Avro, Protobuf oder JSON Schema) und unterstützt die Entwicklung von Schemata, so dass sich Datenformate ändern können, ohne dass die bestehenden Konsumenten darunter leiden. Dies gewährleistet einen reibungslosen Datenaustausch und die Zuverlässigkeit des Systems, wenn sich die Schemata weiterentwickeln.
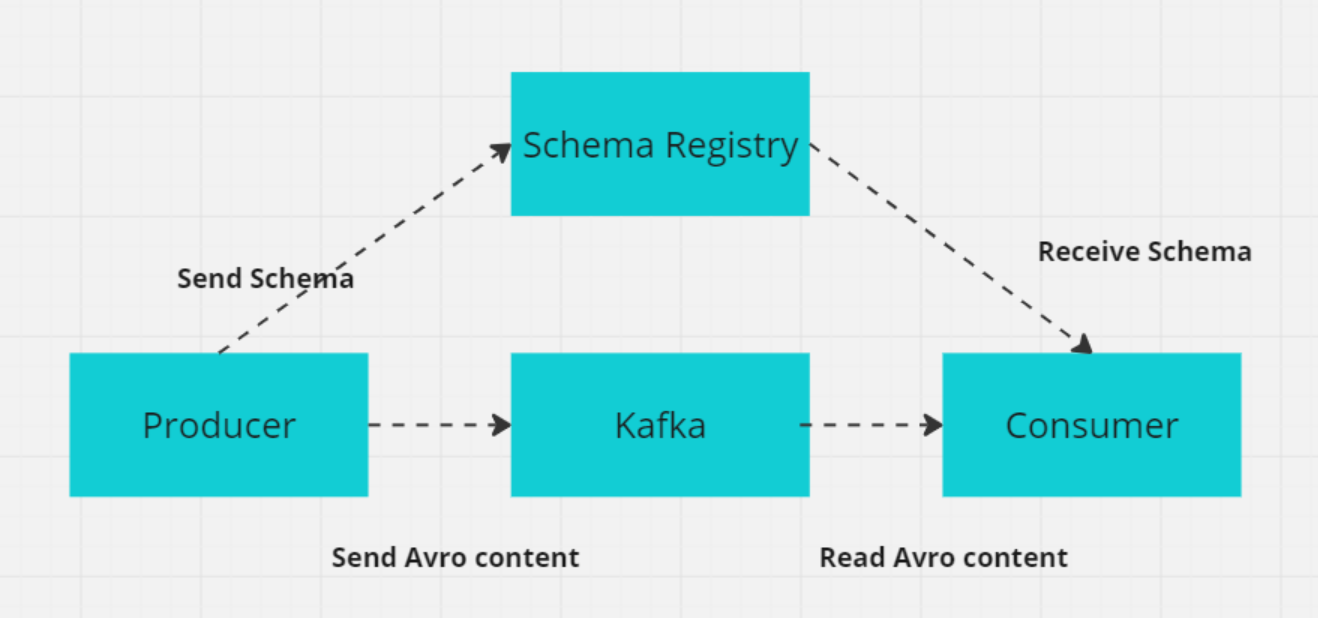
Wie die Schema-Registrierung mit Producer/Consumer funktioniert (Bild vom Autor)
Fortgeschrittene Kafka Interview Fragen
Für fortgeschrittene Kafka-Benutzer sind die Interviewfragen wahrscheinlich eher technischer Natur.
11. Wie sorgt Kafka für die Vermeidung von Nachrichtenverlusten?
Kafka verwendet mehrere Mechanismen, um den Verlust von Nachrichten zu verhindern und eine zuverlässige Zustellung der Nachrichten zu gewährleisten:
- Manuelles Offset Commit: Verbraucher können automatische Offset-Commits deaktivieren und Offsets nach erfolgreicher Verarbeitung von Nachrichten manuell committen, um zu verhindern, dass unverarbeitete Nachrichten im Falle eines Verbraucherabsturzes verloren gehen.
- Herstelleranerkennungen (
acks=all): Die Einstellungacks=allauf dem Producer stellt sicher, dass die Nachrichten von allen synchronisierten Repliken bestätigt werden, bevor sie als erfolgreich geschrieben gelten, wodurch das Risiko eines Nachrichtenverlusts im Falle eines Brokerausfalls verringert wird. - Replikation (
min.insync.replicasundreplication.factor): Kafka repliziert die Daten jeder Partition über mehrere Broker. Ein Replikationsfaktor größer als 1 sorgt für Fehlertoleranz, so dass die Daten auch dann verfügbar bleiben, wenn ein Broker ausfällt. Die Einstellungmin.insync.replicasstellt sicher, dass eine Mindestanzahl von Replikaten eine Nachricht bestätigt, bevor sie geschrieben wird, und sorgt so für eine bessere Haltbarkeit der Daten. Wenn zum Beispiel bei einem Replikationsfaktor von 3 ein Broker ausfällt, bleiben die Daten auf den anderen beiden Brokern verfügbar. - Der Produzent versucht es erneut: Wenn du die Wiederholungsversuche auf einen hohen Wert einstellst, wird sichergestellt, dass die Produzenten bei einem vorübergehenden Ausfall erneut versuchen, Nachrichten zu senden. In Kombination mit einer sorgfältigen Konfiguration, wie z. B.
max.in.flight.requests.per.connection=1, verringert dies die Wahrscheinlichkeit, dass Nachrichten neu geordnet werden, und stellt sicher, dass die Nachrichten schließlich zugestellt werden, ohne verloren zu gehen.
12. Wie unterscheidet sich Kafka von RabbitMq?
Kafka und RabbitMQ sind zwei beliebte Messaging-Systeme, die sich in Bezug auf die Architektur und die Nutzung unterscheiden. Du kannst sehen, wie sie sich in den wichtigsten Bereichen unterscheiden:
1. Verwendung und Gestaltung
Kafka wurde entwickelt, um große Datenströme und Echtzeit-Pipelines zu verarbeiten, die für hohen Durchsatz und niedrige Latenzzeiten optimiert sind. Die logbasierte Architektur sorgt für Langlebigkeit und ermöglicht die Wiederverarbeitung von Daten, was sie ideal für Anwendungsfälle wie Event Sourcing und Stream Processing macht.
RabbitMQ ist ein universeller Message Broker, der komplexes Routing unterstützt und typischerweise für den Nachrichtenaustausch zwischen Microservices oder die Verteilung von Aufgaben auf Worker verwendet wird. Es eignet sich hervorragend für Umgebungen, in denen eine zuverlässige Nachrichtenübermittlung, Flexibilität beim Routing und Interaktion zwischen Diensten wichtig sind.
2. Architektur
Kafka kategorisiert Nachrichten in Topics, die wiederum in Partitionen unterteilt sind. Jede Partition kann von mehreren Verbrauchern verarbeitet werden, was eine parallele Verarbeitung und Skalierung ermöglicht. Die Daten werden mit einer konfigurierbaren Aufbewahrungsfrist auf der Festplatte gespeichert, um die Haltbarkeit zu gewährleisten und eine erneute Verarbeitung der Nachrichten bei Bedarf zu ermöglichen.
RabbitMQ sendet Nachrichten an Warteschlangen, wo sie von einem oder mehreren Konsumenten konsumiert werden. Es sorgt für eine zuverlässige Zustellung durch Nachrichtenbestätigungen, Wiederholungsversuche und den Austausch von toten Buchstaben, um fehlgeschlagene Nachrichten zu behandeln. Diese Architektur konzentriert sich auf die Integrität der Nachrichten und die Flexibilität beim Routing.
3. Leistung und Skalierbarkeit
Kafka ist für horizontale Skalierbarkeit ausgelegt, indem weitere Broker und Partitionen hinzugefügt werden, so dass Millionen von Nachrichten pro Sekunde verarbeitet werden können. Seine Architektur unterstützt die parallele Verarbeitung und einen hohen Durchsatz und ist damit ideal für umfangreiches Datenstreaming.
RabbitMQ kann skalieren, wenn auch nicht so effizient wie Kafka, wenn es um sehr große Datenmengen geht. Es eignet sich für mittlere bis hohe Durchsatzszenarien, ist aber nicht für den extremen Durchsatz optimiert, den Kafka in großen Streaming-Anwendungen bewältigen kann.
Zusammenfassung: Sowohl Kafka als auch RabbitMQ sind leistungsstarke Tools für das Messaging, aber sie eignen sich für unterschiedliche Anwendungsfälle. Kafka ist ideal für Echtzeit-Daten-Streaming und Event-Sourcing-Anwendungen mit hohem Durchsatz, bei denen eine groß angelegte, parallele Verarbeitung erforderlich ist.
RabbitMQ eignet sich hervorragend für die zuverlässige Zustellung von Nachrichten, die Verteilung von Aufgaben in Microservice-Architekturen und komplexes Nachrichten-Routing. Sie eignet sich hervorragend für Szenarien, die eine lose Kopplung zwischen Diensten, asynchrone Verarbeitung und Zuverlässigkeit erfordern.
13. Wie hilft Kafka bei der Entwicklung von Microservice-basierten Anwendungen?
Apache Kafka ist ein wertvolles Werkzeug für den Aufbau von Microservice-Architekturen, da es Echtzeit-Datenverarbeitung, ereignisgesteuerte Kommunikation und zuverlässiges Messaging ermöglicht. Hier erfährst du, wie Kafka die Entwicklung von Microservices unterstützt:
1. Ereignisgesteuerte Architektur
- Entkopplung der Dienste: Kafka ermöglicht es Diensten, über Ereignisse statt über direkte Aufrufe zu kommunizieren und so Abhängigkeiten zwischen ihnen zu reduzieren. Diese Entkopplung ermöglicht es den Diensten, Ereignisse unabhängig voneinander zu produzieren und zu konsumieren, was die Entwicklung und Wartung der Dienste vereinfacht.
- Asynchrone Verarbeitung: Dienste können Ereignisse veröffentlichen und die Verarbeitung fortsetzen, ohne auf die Antwort anderer Dienste zu warten, was die Reaktionsfähigkeit und Effizienz des Systems verbessert.
2. Skalierbarkeit
- Horizontale Skalierbarkeit: Kafka kann große Datenmengen bewältigen, indem die Last auf mehrere Broker und Partitionen verteilt wird. Jede Partition kann von verschiedenen Konsumenteninstanzen bearbeitet werden, so dass das System horizontal skaliert werden kann.
- Paralleler Verbrauch: Mehrere Verbraucher können gleichzeitig von verschiedenen Partitionen lesen, was den Durchsatz und die Leistung erhöht.
3. Verlässlichkeit und Fehlertoleranz
- Datenreplikation: Kafka repliziert Daten über mehrere Broker und sorgt so für hohe Verfügbarkeit und Fehlertoleranz. Wenn ein Broker ausfällt, kann ein anderer mit den replizierten Daten einspringen. Kafka speichert Daten auf der Festplatte mit konfigurierbaren Aufbewahrungsfristen. So wird sichergestellt, dass Ereignisse nicht verloren gehen und bei Bedarf erneut verarbeitet werden können.
4. Datenintegration
- Zentrale Datendrehscheibe: Kafka fungiert als zentraler Knotenpunkt für den Datenfluss innerhalb einer Microservice-Architektur und erleichtert die Integration zwischen verschiedenen Datenquellen und -senken. Dies vereinfacht die Wahrung der Datenkonsistenz zwischen den Diensten.
- Kafka Connect: Kafka Connect bietet Konnektoren für die Integration von Kafka mit zahlreichen Datenbanken, Key-Value-Stores, Suchindizes und anderen Systemen und vereinfacht so den Datenaustausch zwischen Microservices und externen Systemen.
14. Was ist Kafka Zookeeper, und wie funktioniert er?
Apache ZooKeeper ist ein Open-Source-Dienst, der die Koordination und Verwaltung von Konfigurationsdaten, Synchronisation und Gruppendiensten in verteilten Systemen unterstützt. In älteren Versionen von Kafka spielte ZooKeeper eine wichtige Rolle bei der Verwaltung von Metadaten, der Wahl der Leader und der Koordination der Broker.
Allerdings ist Kafka seit Version 2.8 in den KRaft-Modus übergegangen, der den ZooKeeper überflüssig macht. ZooKeeper gilt jetzt als veraltet und wird in der Version 4.0, die für 2024 erwartet wird, entfernt werden.
ZooKeeper speichert Daten in einer hierarchischen Struktur von Knoten, die "znodes" genannt werden, wobei jeder znode Metadaten speichern und untergeordnete znodes haben kann, ähnlich wie ein Dateisystem. Diese Struktur ist entscheidend für die Verwaltung von Metadaten zu Kafka-Brokern, Themen und Partitionen. Der Quorum-basierte Mechanismus von ZooKeeper sorgt für Konsistenz: Eine Mehrheit der Knoten (Quorum) muss jeder Änderung zustimmen, was ZooKeeper äußerst zuverlässig und fehlertolerant macht.
In älteren Versionen von Kafka wird ZooKeeper für mehrere kritische Funktionen verwendet:
- Leader-Wahl: ZooKeeper wählt einen Controller-Knoten, der die Zuweisung der Partitionsleiter und andere clusterweite Aufgaben verwaltet.
- Verwaltung von Broker-Metadaten: Sie führt ein zentrales Register der aktiven Makler und ihres Status.
- Neuzuordnung der Partition: ZooKeeper hilft dabei, die Partitionen zwischen den Brokern bei Ausfällen oder Erweiterungen des Clusters neu zu verteilen.
Das ZAB-Protokoll (ZooKeeper Atomic Broadcast) von ZooKeeper garantiert die Konsistenz zwischen den Knoten, selbst wenn das Netzwerk unterbrochen ist, und sorgt dafür, dass Kafka fehlertolerant bleibt. Diese Konsistenz und Zuverlässigkeit machen ZooKeeper für die Verwaltung der verteilten Natur von Kafka unentbehrlich, obwohl die Zukunft der Kafka-Architektur weniger von ZooKeeper abhängen wird, da KRaft der Standardmodus wird.
15. Wie kannst du die Festplattennutzung in Kafka reduzieren?
Kafka bietet mehrere Möglichkeiten, die Festplattennutzung effektiv zu reduzieren. Hier sind die wichtigsten Strategien:
1. Einstellungen für die Protokollspeicherung anpassen
Ändere die Richtlinie zur Aufbewahrung von Protokollen, um die Zeit zu verkürzen, in der Nachrichten auf der Festplatte gespeichert werden. Dies kann durch die Anpassung von retention.ms (zeitbasierte Speicherung) oder retention.bytes (größenbasierte Speicherung) geschehen, um zu begrenzen, wie lange oder wie viele Daten Kafka speichert, bevor es ältere Nachrichten löscht.
2. Log-Verdichtung implementieren
Verwende die Protokollverdichtung, um nur die aktuellste Nachricht für jeden eindeutigen Schlüssel aufzubewahren und veraltete oder redundante Daten zu entfernen. Das ist besonders nützlich für Szenarien, in denen nur der letzte Stand relevant ist. So wird weniger Speicherplatz benötigt, ohne dass wichtige Informationen verloren gehen.
3. Bereinigungsrichtlinien konfigurieren
Lege effektive Bereinigungsrichtlinien fest, die auf deinen Anwendungsfall abgestimmt sind. Du kannst sowohl zeitbasierte (retention.ms) als auch größenbasierte (retention.bytes) Aufbewahrungsrichtlinien konfigurieren, um ältere Nachrichten automatisch zu löschen und den Speicherplatzbedarf von Kafka zu verwalten.
4. Nachrichten komprimieren
Aktiviere die Nachrichtenkomprimierung auf der Produzentenseite mit Formaten wie GZIP, Snappy oder LZ4. Durch die Komprimierung wird die Nachrichtengröße reduziert, was zu einem geringeren Speicherplatzverbrauch führt. Es ist jedoch wichtig, den Kompromiss zwischen reduzierter Festplattennutzung und erhöhtem CPU-Overhead aufgrund von Komprimierung und Dekomprimierung zu berücksichtigen.
5. Log-Segmentgröße anpassen
Konfiguriere die Logsegmentgröße von Kafka (segment.bytes), um zu steuern, wie oft Logsegmente gerollt werden. Kleinere Segmentgrößen ermöglichen ein häufigeres Rollen des Logs, was zu einer effizienteren Festplattennutzung beitragen kann, da ältere Daten schneller gelöscht werden können.
6. Unnötige Themen oder Partitionen löschen
Überprüfe regelmäßig ungenutzte oder unnötige Themen und Fächer und lösche sie. Dies kann Speicherplatz freigeben und dazu beitragen, die Festplattennutzung von Kafka unter Kontrolle zu halten.
Kafka Interviewfragen für Dateningenieure
Wenn du dich für eine Stelle als Dateningenieur/in bewirbst, solltest du dich auf die folgenden Kafka-Interviewfragen vorbereiten.
16. Was sind die Unterschiede zwischen Leader Replica und Follower Replica in Kafka?
Anführer-Nachbildung
Die führende Replik bearbeitet alle Lese- und Schreibanfragen der Kunden. Sie verwaltet den Zustand der Partition und ist der wichtigste Interaktionspunkt für Produzenten und Verbraucher. Wenn der Leader ausfällt, wird seine Rolle auf eines der Follower-Replikate übertragen, um die Verfügbarkeit zu gewährleisten.
Nachbildung eines Anhängers
Der Follower repliziert die Daten des Leaders, bearbeitet aber nicht direkt Client-Anfragen. Ihre Aufgabe ist es, Fehlertoleranz zu gewährleisten, indem sie eine aktuelle Kopie der Daten der Partition bereithält. Ab Kafka 2.4 können die Follower-Replikate unter bestimmten Bedingungen auch Leseanfragen bearbeiten, um die Last zu verteilen und den Lesedurchsatz zu verbessern. Wenn der Leader ausfällt, wird ein Follower zum neuen Leader gewählt, um die Datenkonsistenz und -verfügbarkeit zu gewährleisten.
17. Warum verwenden wir Cluster in Kafka und was sind ihre Vorteile?
Ein Kafka-Cluster besteht aus mehreren Brokern, die die Daten auf mehrere Instanzen verteilen und so für Skalierbarkeit ohne Ausfallzeiten sorgen. Diese Cluster sind so konzipiert, dass sie Verzögerungen minimieren und bei einem Ausfall des primären Clusters andere Kafka-Cluster übernehmen können, um die Kontinuität des Dienstes aufrechtzuerhalten.
Die Architektur eines Kafka-Clusters besteht aus Topics, Brokern, Producern und Consumern. Sie verwaltet Datenströme effizient und ist damit ideal für Big-Data-Anwendungen und die Entwicklung von datengesteuerten Anwendungen.
18. Wie stellt Kafka die Reihenfolge der Nachrichten sicher?
Kafka stellt die Ordnung der Nachrichten auf zwei Arten sicher:
- Verwendung von Nachrichtentasten: Wenn einer Nachricht ein Schlüssel zugewiesen wird, werden alle Nachrichten mit demselben Schlüssel an dieselbe Partition gesendet. Dadurch wird sichergestellt, dass Nachrichten mit demselben Schlüssel in der Reihenfolge ihres Eingangs verarbeitet werden, da Kafka die Reihenfolge innerhalb jeder Partition beibehält.
- Single-Thread-Verbraucherverarbeitung: Um die Ordnung aufrechtzuerhalten, sollte der Konsument Nachrichten aus einer Partition in einem einzigen Thread verarbeiten. Wenn mehrere Threads verwendet werden, richte für jede Partition eine eigene In-Memory-Warteschlange ein, um sicherzustellen, dass die Nachrichten bei gleichzeitiger Bearbeitung in der richtigen Reihenfolge verarbeitet werden.
19. Was bedeuten ISR und AR in Kafka? Was bedeutet ISR-Erweiterung?
ISR (in-sync replicas)
ISR bezieht sich auf die Replikate, die vollständig mit dem führenden Replikat synchronisiert sind. Diese Replikate haben die neuesten Daten und gelten als zuverlässig für Lese- und Schreibvorgänge.
AR (zugewiesene Replikate)
AR umfasst alle Replikate, die einer Partition zugewiesen sind, sowohl die synchronen als auch die nicht synchronen Replikate. Sie stellt den kompletten Satz an Replikaten für eine Partition dar.
ISR-Erweiterung
Eine ISR-Erweiterung findet statt, wenn neue Repliken den Spitzenreiter einholen und der ISR-Liste hinzugefügt werden. Dadurch erhöht sich die Anzahl der aktuellen Replikate, was die Fehlertoleranz und Zuverlässigkeit verbessert.
20. Was ist ein Null-Kopie-Nutzungsszenario in Kafka?
Kafka nutzt Zero-Copy, um große Datenmengen effizient zwischen Produzenten und Konsumenten zu übertragen. Es nutzt die FileChannel.transferTo Methode, um Daten direkt vom Dateisystem zu den Netzwerk-Sockets zu übertragen, ohne zusätzliche Kopiervorgänge, was die Leistung und den Durchsatz verbessert.
Diese Technik nutzt memory-mapped files (mmap) für das Lesen von Indexdateien, so dass Datenpuffer zwischen dem User Space und dem Kernel Space gemeinsam genutzt werden können, was den Bedarf an zusätzlichen Datenkopien weiter reduziert. Dadurch ist Kafka gut geeignet, um große Echtzeit-Datenströme effizient zu verarbeiten.
Vorbereitung auf dein Kafka-Interview
Wenn du dich auf ein Vorstellungsgespräch zum Thema Kafka vorbereitest, ist es wichtig, dass du sowohl eine solide technische Grundlage als auch ein klares Verständnis davon hast, wie Kafka in moderne Systeme integriert wird. Kafka ist für viele Echtzeitdatenplattformen von zentraler Bedeutung. Daher erwarten die Interviewer, dass du sowohl die Grundlagen als auch die Funktionsweise von Kafka in skalierbaren, fehlertoleranten Umgebungen kennst.
Wichtige Bereiche, auf die du dich konzentrieren solltest
Wie wir bei den Kafka-Interviewfragen gesehen haben, gibt es einige Schlüsselbereiche, die du auffrischen musst:
- Architektur: Du kannst die Architektur von Kafka, einschließlich der Broker, Partitionen und der Interaktion zwischen Produzenten und Konsumenten, sicher diskutieren. Du solltest auch erklären, welche Garantien Kafka für die Zustellung von Nachrichten gibt - wie z.B. "mindestens einmal" oder "genau einmal" - und wie Kafka die Reihenfolge der Nachrichten durch Funktionen wie In-Sync Replicas (ISR) sicherstellt.
- Integration: Verstehe, wie Kafka mit anderen Systemen integriert werden kann, indem du Tools wie Kafka Connect verwendest, das Datenbanken, Key-Value-Stores und andere Systeme miteinander verbindet. Interviewer können nach der Rolle von Kafka bei der Aufrechterhaltung der Datenkonsistenz in Microservices oder verteilten Systemen fragen.
- Überwachung und Fehlerbehebung: Vertrautheit mit Monitoring-Tools wie Kafka Manager und Prometheus ist wichtig. Du musst nachweisen, dass du in der Lage bist, Kafka-Cluster effektiv zu verwalten und zu optimieren.
- Problemlösung: Sei darauf vorbereitet, Messaging-Lösungen zu entwickeln, die reale Herausforderungen lösen, wie z.B. die Handhabung großer Datenströme oder die Gewährleistung der Zuverlässigkeit von Nachrichten. Die Interviewer geben dir vielleicht hypothetische Szenarien vor, in denen du die Leistung von Kafka beheben oder optimieren musst.
- Kommunikation: Kafka ist komplex, daher musst du in der Lage sein, deine Design-Entscheidungen oder Schritte zur Fehlerbehebung klar zu erklären, egal ob für technische Teams oder Geschäftsinteressenten. Starke Kommunikationsfähigkeiten zeichnen dich aus.
- Praktische Erfahrung: Hebe praktische Erfahrungen hervor, wie z.B. die Einrichtung von Kafka-Clustern, die Verwaltung der Datenspeicherung oder die Integration von Kafka mit anderen Tools. Praktisches Wissen wird hoch geschätzt.
- Kontinuierliches Lernen: Bleib auf dem Laufenden über die neuesten Funktionen und Best Practices von Kafka. Wenn du Dokumentationen liest oder zu Open-Source-Projekten beiträgst, zeigst du, dass du bereit bist, dich weiterzubilden.
Interview-Tipps
Hier sind die besten Tipps, um das Vorstellungsgespräch zu meistern:
- Recherchiere das Unternehmen, die Branche und den Hintergrund deines Gesprächspartners.
- Bereite dich mit einem maßgeschneiderten Ansatz auf die verschiedenen Gesprächsrunden vor (Fach-, Personal-, Telefon- und persönliches Gespräch).
- Überprüfe regelmäßig technische Ressourcen wie:
Wenn du diese Fähigkeiten trainierst und dich gut vorbereitest, bist du für Vorstellungsgespräche mit Kafka gut gerüstet. Denke daran, dass die Interviewer nicht nur auf technisches Fachwissen achten, sondern auch auf eine klare Kommunikation und praktische Problemlösungsfähigkeiten. Zeige während des gesamten Vorstellungsgesprächs deine Leidenschaft für Data Engineering.
