
Curso
Manipulación de datos en SQL
4 h
324.1K
SQL es una herramienta importante para cualquiera que gestione y manipule datos en bases de datos relacionales. Nos permite interactuar con bases de datos y realizar tareas esenciales con eficacia. Con la cantidad de datos disponibles creciendo cada día, nos enfrentamos al reto de escribir consultas complejas para recuperar esos datos.
Las consultas lentas pueden ser un verdadero cuello de botella, que afecta a todo, desde el rendimiento de la aplicación hasta la experiencia del usuario. Optimizar las consultas SQL mejora el rendimiento, reduce el consumo de recursos y garantiza la escalabilidad.
En este artículo, veremos algunas de las técnicas más eficaces para optimizar nuestras consultas SQL. Nos sumergiremos en las ventajas e inconvenientes de cada técnica para comprender su impacto en el rendimiento de las consultas SQL. ¡Empecemos!
Imagina que buscamos un libro en una biblioteca sin catálogo. Teníamos que revisar cada estante y cada fila hasta que por fin lo encontrábamos. Los índices de una base de datos son similares a los catálogos. Nos ayudan a localizar rápidamente los datos que necesitamos sin necesidad de escanear toda la tabla.
Los índices son estructuras de datos que mejoran la velocidad de recuperación de los datos. Funcionan creando una copia ordenada de las columnas indexadas, lo que permite a la base de datos localizar rápidamente las filas que coinciden con nuestra consulta, ahorrándonos mucho tiempo.
Hay tres tipos principales de índices en las bases de datos:
Entonces, ¿cómo podemos utilizar los índices para mejorar el rendimiento de las consultas SQL? Veamos algunas buenas prácticas:
customer_id o item_id, indexar esas columnas tendrá un gran impacto en la velocidad. Comprueba a continuación cómo crear un índice:CREATE INDEX index_customer_id ON customers (customer_id);
SELECT, pueden ralentizar ligeramente las operaciones en INSERT, UPDATE y DELETE. Esto se debe a que el índice debe actualizarse cada vez que modificas datos. Por tanto, demasiados índices pueden ralentizar las cosas al aumentar la sobrecarga de las modificaciones de datos. A veces, tenemos la tentación de utilizar SELECT * para coger todas las columnas, incluso las que no son relevantes para nuestro análisis. Aunque esto pueda parecer cómodo, da lugar a consultas muy ineficaces que pueden ralentizar el rendimiento.
La base de datos tiene que leer y transferir más datos de los necesarios, lo que requiere un mayor uso de memoria, ya que el servidor debe procesar y almacenar más información de la necesaria.
Como buena práctica general, sólo debemos seleccionar las columnas específicas que necesitemos. Minimizar los datos innecesarios no sólo mantendrá nuestro código limpio y fácil de entender, sino que también ayudará a optimizar el rendimiento.
Así que, en lugar de escribir
SELECT *
FROM products;Deberíamos escribir:
SELECT product_id, product_name, product_price
FROM products;Acabamos de comentar que seleccionar sólo las columnas relevantes se considera una buena práctica para optimizar las consultas SQL. Sin embargo, también es importante limitar el número de filas que estamos recuperando, no sólo de columnas. Las consultas suelen ralentizarse cuando aumenta el número de filas.
Podemos utilizar LIMIT para reducir el número de filas devueltas. Esta función evita que recuperemos involuntariamente miles de filas de datos cuando sólo necesitamos trabajar con unas pocas.
La función LIMIT es especialmente útil para consultas de validación o para inspeccionar la salida de una transformación en la que estemos trabajando. Es ideal para experimentar y comprender cómo se comporta nuestro código. Sin embargo, puede no ser adecuado para modelos de datos automatizados, en los que necesitamos devolver todo el conjunto de datos.
Aquí tenemos un ejemplo de cómo funciona LIMIT:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;Cuando se trabaja con bases de datos relacionales, los datos suelen organizarse en tablas separadas para evitar la redundancia y mejorar la eficacia. Sin embargo, esto significa que tenemos que recuperar datos de distintos lugares y unirlos para obtener toda la información relevante que necesitamos.
Las uniones nos permiten combinar filas de dos o más tablas basándonos en una columna relacionada entre ellas en una única consulta, lo que hace posible realizar análisis más complejos.
Hay distintos tipos de unión, y tenemos que entender cómo utilizarlos. Utilizar una unión incorrecta puede crear duplicados en nuestro conjunto de datos y ralentizarlo.
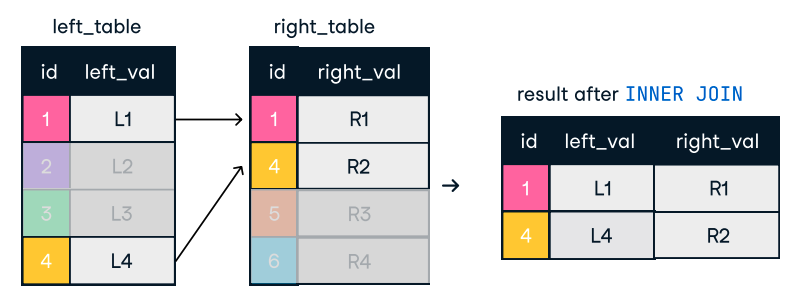
Figura: Junta interior. Fuente de la imagen: Hoja de trucos SQL-Join del DataCamp.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
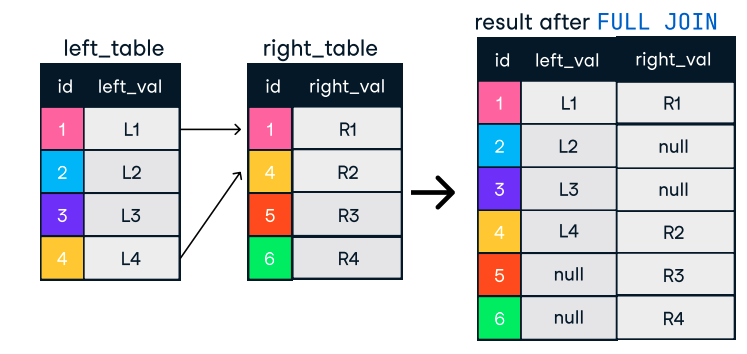
Figura: Unión externa o completa. Fuente de la imagen: Hoja de trucos SQL-Join del DataCamp.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;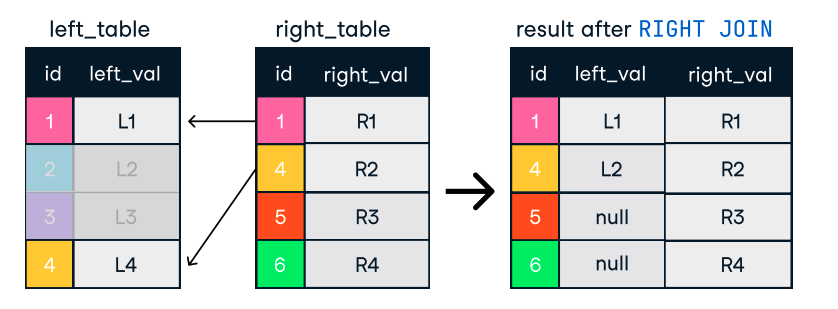
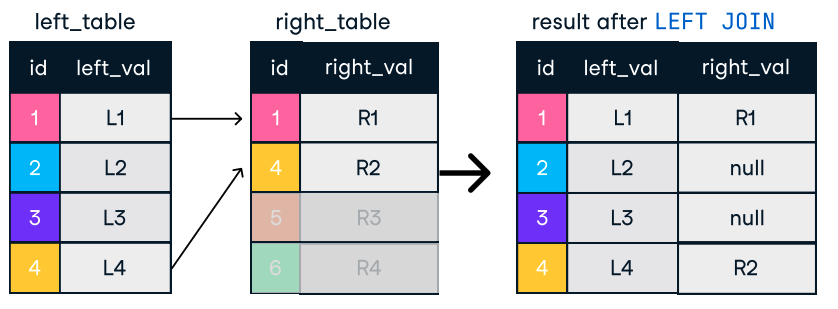
Figura: Junta izquierda y derecha. Fuente de la imagen: Hoja de trucos SQL-Join del DataCamp.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Consejos para uniones eficientes:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;La mayoría de las veces, ejecutamos consultas SQL y sólo comprobamos si la salida o el resultado obtenido es lo que esperábamos. Sin embargo, pocas veces nos preguntamos qué ocurre entre bastidores cuando ejecutamos una consulta SQL.
La mayoría de las bases de datos ofrecen funciones como EXPLAIN o EXPLAIN PLAN para visualizar este proceso. Estos planes proporcionan un desglose paso a paso de cómo la base de datos recuperará los datos. Podemos utilizar esta función para identificar dónde tenemos los cuellos de botella de rendimiento y tomar decisiones informadas sobre la optimización de nuestras consultas.
Veamos cómo podemos utilizar EXPLAIN para identificar los cuellos de botella. Ejecutaremos el siguiente código:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id A continuación, podemos examinar los resultados:
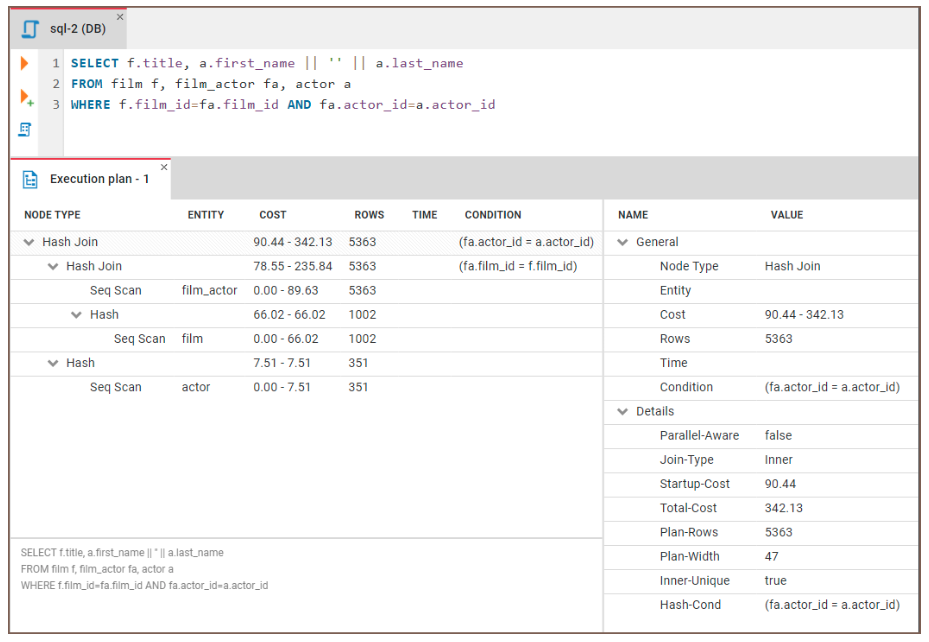
Figura: Ejemplo de plan de ejecución de una consulta. Fuente de la imagen: Página web de CloudDBeaver.
Aquí tienes una guía general sobre cómo interpretar los resultados:
WHERE es ineficaz.La cláusula WHERE es esencial en las consultas SQL porque nos permite filtrar los datos basándonos en condiciones específicas, asegurándonos de que sólo se devuelven los registros relevantes. Mejora la eficacia de la consulta reduciendo la cantidad de datos procesados, lo que es muy importante para trabajar con un gran conjunto de datos.
Por tanto, una cláusula WHERE correcta puede ser un poderoso aliado cuando optimizamos el rendimiento de una consulta SQL. Veamos algunas formas de aprovechar esta cláusula:
WHERE es bueno, pero no suficiente. Debemos tener cuidado con dónde colocamos la cláusula. Filtrar tantas filas como sea posible al principio de la cláusula WHERE puede ayudarnos a optimizar la consulta.WHERE. Cuando aplicamos una función a una columna, la base de datos tiene que aplicar esa función a todas las filas de la tabla antes de poder filtrar los resultados. Esto impide que la base de datos utilice los índices con eficacia.Por ejemplo, en lugar de:
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;Deberíamos utilizar:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= suele ser más rápido que LIKE, y utilizar intervalos de fechas específicos es más rápido que utilizar funciones como MONTH(order_date).Así, por ejemplo, en lugar de realizar esta consulta
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;Podemos realizar lo siguiente:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';En algunos casos, estamos escribiendo una consulta y sentimos que necesitamos realizar dinámicamente algún filtrado, agregación o unión de datos. No queremos hacer varias consultas, sino limitarnos a una sola.
Para esos casos, podemos utilizar subconsultas. Las subconsultas en SQL son consultas anidadas dentro de otra consulta, normalmente en las sentencias SELECT, INSERT, UPDATE, o DELETE.
Las subconsultas pueden ser potentes y rápidas, pero también pueden causar problemas de rendimiento si no se utilizan con cuidado. Por regla general, debemos minimizar el uso de subconsultas y seguir una serie de buenas prácticas:
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;Cuando trabajamos con subconsultas, a menudo necesitamos comprobar si un valor existe en un conjunto de resultados. Podemos hacerlo con dos IN o EXISTS, pero EXISTS suele ser más eficaz, sobre todo para conjuntos de datos más grandes.
La cláusula IN lee todo el conjunto de resultados de la subconsulta en memoria antes de compararlos. En cambio, la cláusula EXISTS deja de procesar la subconsulta en cuanto encuentra una coincidencia .
Aquí tenemos un ejemplo de cómo utilizar esta cláusula:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Imagina que estamos trabajando en un análisis para enviar una oferta promocional a clientes de ciudades únicas. La base de datos tiene varios pedidos de los mismos clientes. Lo primero que se nos ocurre es utilizar la cláusula DISTINCT.
Esta función es útil para determinados casos, pero puede consumir muchos recursos, especialmente en conjuntos de datos grandes. Hay algunas alternativas a DISTINCT:
GROUP BY en lugar de DISTINCT siempre que sea posible. GROUP BY puede ser más eficaz, sobre todo si se combina con funciones agregadas. Así que, en lugar de actuar:
SELECT DISTINCT city FROM customers;Podemos utilizar:
SELECT city FROM customers GROUP BY city;ROW_NUMBER pueden ayudarnos a identificar duplicados y filtrarlos sin utilizar DISTINCT.Cuando trabajamos con datos, interactuamos con ellos utilizando SQL a través de un Sistema de Gestión de Bases de Datos (SGBD). El SGBD procesa los comandos SQL, gestiona la base de datos y garantiza la integridad y seguridad de los datos. Los distintos sistemas de bases de datos ofrecen características únicas que pueden ayudar a optimizar las consultas.
Las sugerencias de la base de datos son instrucciones especiales que podemos añadir a nuestras consultas para ejecutar una consulta de forma más eficaz. Son una herramienta útil, pero deben utilizarse con precaución.
Por ejemplo, en MySQLla sugerencia USE INDEX puede forzar el uso de un índice concreto:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;En SQL Server, la sugerencia OPTION (LOOP JOIN) especifica el método de unión :
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); Estas sugerencias anulan la optimización de consulta por defecto, mejorando el rendimiento en escenarios específicos.
Por otro lado, la partición y la fragmentación son dos técnicas para distribuir datos en la nube.
Mantener actualizadas las estadísticas de la base de datos es importante para garantizar que el optimizador de consultas pueda tomar decisiones informadas y precisas sobre la forma más eficaz de ejecutar las consultas.
Las estadísticas describen la distribución de los datos en una tabla (por ejemplo, el número de filas, la frecuencia de los valores y la dispersión de los valores entre las columnas), y el optimizador se basa en esta información para estimar los costes de ejecución de la consulta. Si las estadísticas no están actualizadas, el optimizador puede elegir planes de ejecución ineficaces, como utilizar los índices equivocados u optar por un escaneo completo de la tabla en lugar de un escaneo de índices más eficaz, lo que provoca un rendimiento deficiente de la consulta.
Las bases de datos suelen admitir actualizaciones automáticas para mantener estadísticas precisas. Por ejemplo, en SQL Server, la configuración por defecto actualiza automáticamente las estadísticas cuando cambia una cantidad significativa de datos. Del mismo modo, PostgreSQL tiene una función de autoanálisis, que actualiza las estadísticas tras un umbral especificado de modificación de datos.
Sin embargo, podemos actualizar manualmente las estadísticas en los casos en que las actualizaciones automáticas sean insuficientes o si es necesaria la intervención manual. En SQL Server, podemos utilizar el comando UPDATE STATISTICS para actualizar las estadísticas de una tabla o índice concretos, mientras que en PostgreSQL, se puede ejecutar el comando ANALYZE para actualizar las estadísticas de una o varias tablas .
-- Update statistics for all tables in the current database
ANALYZE;
-- Update statistics for a specific table
ANALYZE my_table;Un procedimiento almacenado es un conjunto de comandos SQL que guardamos en nuestra base de datos para no tener que escribir el mismo SQL repetidamente. Podemos considerarlo como un guión reutilizable.
Cuando necesitemos realizar una determinada tarea, como actualizar registros o calcular valores, sólo tenemos que llamar al procedimiento almacenado. Puede recibir datos de entrada, realizar algún trabajo, como consultar o modificar datos, e incluso devolver un resultado. Los procedimientos almacenados ayudan a acelerar las cosas, ya que el SQL está precompilado, lo que hace que tu código sea más limpio y fácil de gestionar.
Podemos crear un procedimiento almacenado en PostgreSQL de la siguiente forma:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');Como profesionales de los datos, nos gusta tenerlos ordenados y agrupados para poder obtener información más fácilmente. Solemos utilizar ORDER BY y GROUP BY en nuestras consultas SQL.
Sin embargo, ambas cláusulas pueden ser costosas desde el punto de vista informático, sobre todo cuando se trata de grandes conjuntos de datos. Al ordenar o agregar datos, el motor de la base de datos debe realizar a menudo un análisis completo de los datos y luego organizarlos, identificar los grupos y/o aplicar funciones de agregación, normalmente utilizando algoritmos que consumen muchos recursos.
Para optimizar las consultas, podemos seguir algunos de estos consejos:
ORDER BY cuando sea necesario. Si la clasificación no es esencial, omitir esta cláusula puede ayudarnos a reducir drásticamente el tiempo de procesamiento. ORDER BY y GROUP BY estén indexadas . GROUP BY, podríamos preagrupar los datos en una fase anterior o en una vista materializada, de modo que la base de datos no tenga que calcular repetidamente los mismos agregados.Cuando queramos combinar los resultados de varias consultas en una sola lista, podemos utilizar las cláusulas UNION y UNION ALL. Ambos combinan los resultados de dos o más sentencias SELECT cuando tienen los mismos nombres de columna. Sin embargo, no son lo mismo, y su diferencia los hace adecuados para casos de uso diferentes.
La cláusula UNION elimina las filas duplicadas, lo que requiere más tiempo de procesamiento .
Figura: Unión en SQL. Imagen agriace: Hoja de trucos SQL-Join del DataCamp.
Por otro lado, UNION ALL combina los resultados pero conserva todas las filas, incluidas las duplicadas. Por tanto, si no necesitamos eliminar duplicados, debemos utilizar UNION ALL para obtener un mejor rendimiento.
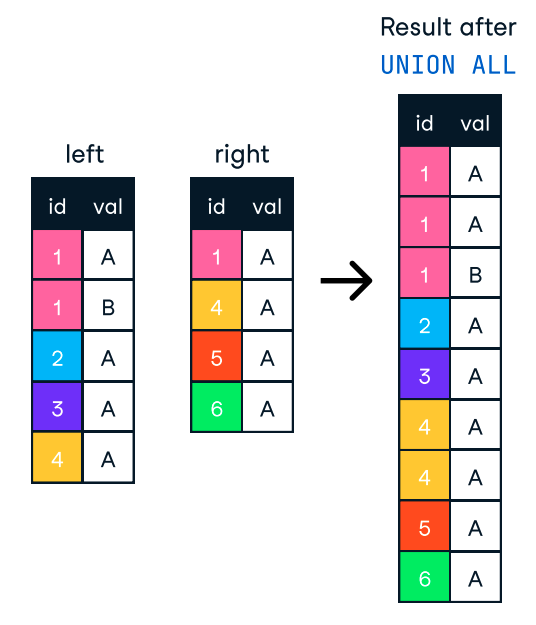
Figura: UNION ALL en SQL. Imagen source: Hoja de trucos SQL-Join del DataCamp.
-- Potentially slower
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potentially faster
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Trabajar con grandes conjuntos de datos implica que a menudo nos encontraremos con consultas complejas difíciles de comprender y optimizar. Podemos intentar abordar estos casos dividiéndolos en consultas más pequeñas y sencillas. De este modo, podemos identificar fácilmente los cuellos de botella de rendimiento y aplicar técnicas de optimización.
Una de las estrategias más utilizadas para descomponer las consultas son las vistas materializadas. Estos son resultados de consulta precalculados y almacenados a los que se puede acceder rápidamente en lugar de recalcular la consulta cada vez que se hace referencia a ella. Cuando cambian los datos subyacentes, la vista materializada debe actualizarse manual o automáticamente.
Aquí tienes un ejemplo de cómo crear y consultar una vista materializada:
-- Create a materialized view
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Query the materialized view
SELECT * FROM daily_sales;En este artículo, hemos explorado varias estrategias y buenas prácticas para optimizar las consultas SQL, desde la indexación y las uniones hasta las subconsultas y las características específicas de las bases de datos. Aplicando estas técnicas, puedes mejorar significativamente el rendimiento de tus consultas y hacer que nuestras bases de datos funcionen con mayor eficacia.
Recuerda que la optimización de las consultas SQL es un proceso continuo. A medida que tus datos crezcan y tu aplicación evolucione, tendrás que supervisar y optimizar continuamente tus consultas para asegurarte de que funcionan con un rendimiento óptimo.
Para mejorar aún más tu comprensión de SQL, te animamos a explorar los siguientes recursos en DataCamp:
Aprende más sobre SQL con estos cursos
Curso
Curso
Curso
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Eugenia Anello
