
Curso
Manipulação de dados em SQL
4 h
324.1K
O SQL é uma ferramenta importante para qualquer pessoa que gerencie e manipule dados em bancos de dados relacionais. Ele nos permite interagir com bancos de dados e executar tarefas essenciais com eficiência. Com a quantidade de dados disponíveis crescendo a cada dia, enfrentamos o desafio de escrever consultas complexas para recuperar esses dados.
As consultas lentas podem ser um verdadeiro gargalo, afetando tudo, desde o desempenho do aplicativo até a experiência do usuário. A otimização das consultas SQL melhora o desempenho, reduz o consumo de recursos e garante o dimensionamento.
Neste artigo, veremos algumas das técnicas mais eficazes para otimizar nossas consultas SQL. Vamos nos aprofundar nas vantagens e desvantagens de cada técnica para entender seu impacto no desempenho das consultas SQL. Vamos começar!
Imagine que estamos procurando um livro em uma biblioteca sem catálogo. Tivemos que verificar todas as prateleiras e todas as fileiras até que finalmente o encontramos. Os índices em um banco de dados são semelhantes aos catálogos. Elas nos ajudam a localizar rapidamente os dados de que precisamos sem precisar examinar toda a tabela.
Os índices são estruturas de dados que aumentam a velocidade de recuperação dos dados. Eles funcionam criando uma cópia ordenada das colunas indexadas, o que permite que o banco de dados identifique rapidamente as linhas que correspondem à nossa consulta, economizando muito tempo.
Há três tipos principais de índices em bancos de dados:
Então, como podemos usar os índices para melhorar o desempenho das consultas SQL? Vamos ver algumas práticas recomendadas:
customer_id ou item_id, a indexação dessas colunas afetará muito a velocidade. Veja abaixo como você pode criar um índice:CREATE INDEX index_customer_id ON customers (customer_id);
SELECT, eles podem tornar as operações em INSERT, UPDATE e DELETE um pouco mais lentas. Isso ocorre porque o índice precisa ser atualizado sempre que você modificar os dados. Portanto, o excesso de índices pode tornar as coisas mais lentas, aumentando a sobrecarga das modificações de dados. Às vezes, ficamos tentados a usar o siteSELECT * para pegar todas as colunas, mesmo aquelas que não são relevantes para nossa análise. Embora isso possa parecer conveniente, leva a consultas muito ineficientes que podem reduzir o desempenho.
O banco de dados precisa ler e transferir mais dados do que o necessário, o que exige maior uso de memória, pois o servidor precisa processar e armazenar mais informações do que o necessário.
Como prática recomendada geral, devemos selecionar apenas as colunas específicas de que precisamos. Minimizar os dados desnecessários não só manterá nosso código limpo e fácil de entender, mas também ajudará a otimizar o desempenho.
Então, em vez de escrever:
SELECT *
FROM products;Devemos escrever:
SELECT product_id, product_name, product_price
FROM products;Acabamos de discutir que selecionar apenas colunas relevantes é considerado uma prática recomendada para otimizar as consultas SQL. No entanto, também é importante limitar o número de linhas que estamos recuperando, e não apenas de colunas. As consultas geralmente ficam mais lentas quando o número de linhas aumenta.
Você pode usar o site LIMIT para reduzir o número de linhas retornadas. Esse recurso evita que recuperemos involuntariamente milhares de linhas de dados quando precisamos trabalhar com apenas algumas.
A função LIMIT é especialmente útil para consultas de validação ou para inspecionar a saída de uma transformação na qual estamos trabalhando. É ideal para fazer experimentos e entender como nosso código se comporta. No entanto, ele pode não ser adequado para modelos de dados automatizados, nos quais precisamos retornar todo o conjunto de dados.
Aqui temos um exemplo de como o LIMIT funciona:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;Ao trabalhar com bancos de dados relacionais, os dados geralmente são organizados em tabelas separadas para evitar redundância e aumentar a eficiência. No entanto, isso significa que precisamos recuperar dados de diferentes lugares e juntá-los para obter todas as informações relevantes de que precisamos.
As uniões nos permitem combinar linhas de duas ou mais tabelas com base em uma coluna relacionada entre elas em uma única consulta, possibilitando a realização de análises mais complexas.
Existem diferentes tipos de junções, e precisamos entender como usá-las. O uso da junção errada pode criar duplicatas em nosso conjunto de dados e torná-lo mais lento.
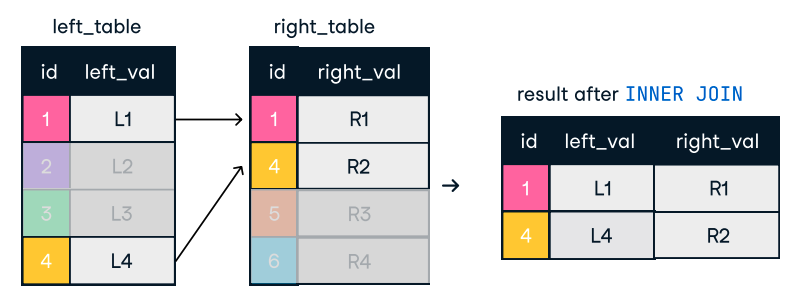
Figura: União interna. Fonte da imagem: Folha de consulta do DataCamp SQL-Join.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
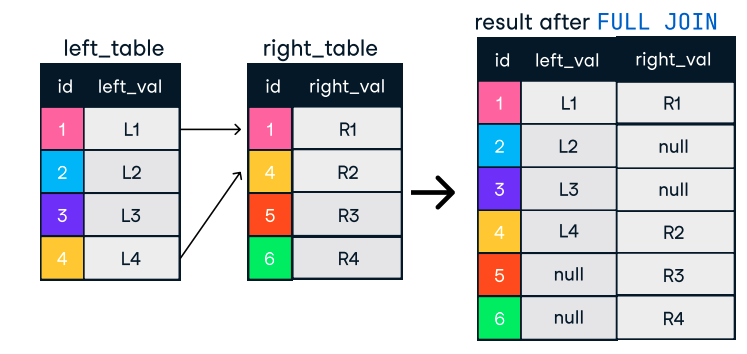
Figura: União externa ou completa. Fonte da imagem: Folha de consulta do DataCamp SQL-Join.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;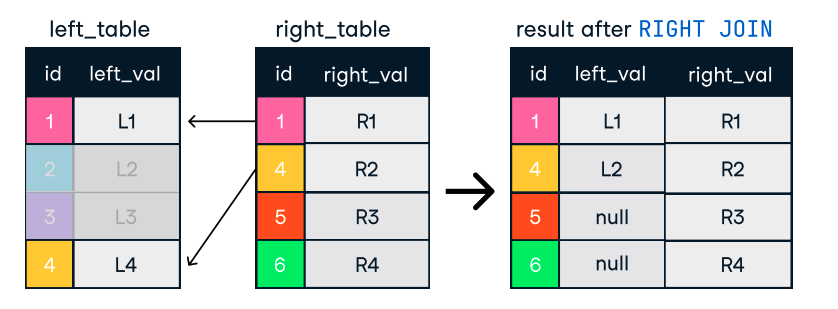
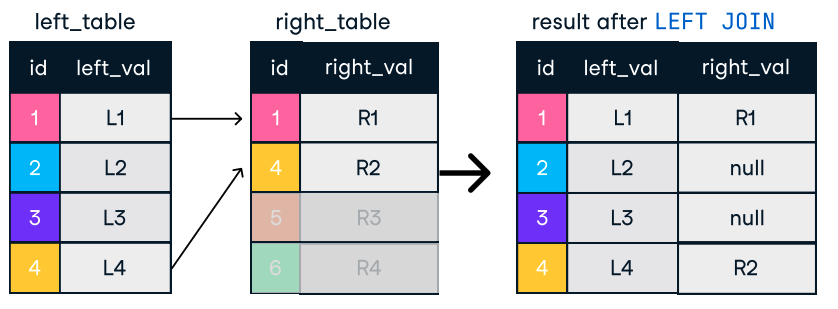
Figura: União esquerda e direita. Fonte da imagem: Folha de consulta do DataCamp SQL-Join.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Dicas para uniões eficientes:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;Na maioria das vezes, executamos consultas SQL e verificamos apenas se a saída ou o resultado recuperado é o esperado. No entanto, raramente nos perguntamos o que acontece nos bastidores quando executamos uma consulta SQL.
A maioria dos bancos de dados oferece funções como EXPLAIN ou EXPLAIN PLAN para que você possa visualizar esse processo. Esses planos fornecem um detalhamento passo a passo de como o banco de dados recuperará os dados. Podemos usar esse recurso para identificar onde estão os gargalos de desempenho e tomar decisões informadas sobre a otimização de nossas consultas.
Vamos ver como podemos usar o site EXPLAIN para identificar gargalos. Executaremos o seguinte código:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id Em seguida, podemos examinar os resultados:
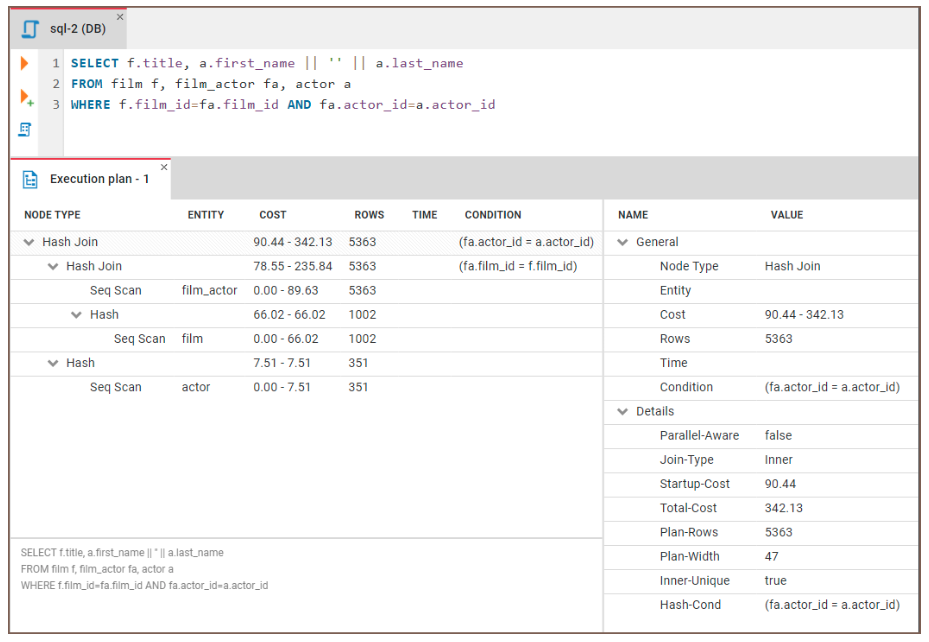
Figura: Um exemplo de um plano de execução de consulta. Fonte da imagem: Site do CloudDBeaver.
Aqui está uma orientação geral sobre como interpretar os resultados:
WHERE ineficiente.A cláusula WHERE é essencial nas consultas SQL porque nos permite filtrar dados com base em condições específicas, garantindo que apenas os registros relevantes sejam retornados. Ele melhora a eficiência da consulta ao reduzir a quantidade de dados processados, o que é muito importante para trabalhar com um grande conjunto de dados.
Portanto, uma cláusula WHERE correta pode ser um aliado poderoso quando estamos otimizando o desempenho de uma consulta SQL. Vejamos algumas maneiras pelas quais podemos aproveitar essa cláusula:
WHERE é bom, mas não é suficiente. Precisamos ter cuidado com o local onde colocamos a cláusula. Filtrar o maior número possível de linhas no início da cláusula WHERE pode nos ajudar a otimizar a consulta.WHERE. Quando aplicamos uma função a uma coluna, o banco de dados precisa aplicar essa função a todas as linhas da tabela antes de poder filtrar os resultados. Isso impede que o banco de dados use os índices de forma eficaz.Por exemplo, em vez de:
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;Devemos usar:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= é geralmente mais rápido do que LIKE, e usar intervalos de datas específicos é mais rápido do que usar funções como MONTH(order_date).Então, por exemplo, em vez de realizar essa consulta, você pode fazer o seguinte:
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;Podemos fazer o seguinte:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';Em alguns casos, estamos escrevendo uma consulta e sentimos que precisamos realizar dinamicamente alguma filtragem, agregação ou junção de dados. Não queremos fazer várias consultas; em vez disso, queremos mantê-las em uma única consulta.
Para esses casos, podemos usar subconsultas. As subconsultas em SQL são consultas aninhadas dentro de outra consulta, normalmente nas instruções SELECT, INSERT, UPDATE ou DELETE.
As subconsultas podem ser eficientes e rápidas, mas também podem causar problemas de desempenho se não forem usadas com cuidado. Como regra, devemos minimizar o uso de subconsultas e seguir um conjunto de práticas recomendadas:
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;Ao trabalhar com subconsultas, muitas vezes precisamos verificar se um valor existe em um conjunto de resultados. Você pode fazer isso com dois IN ou EXISTS, mas o EXISTS é geralmente mais eficiente, especialmente para conjuntos de dados maiores.
A cláusula IN lê todo o conjunto de resultados da subconsulta na memória antes de fazer a comparação. Por outro lado, a cláusula EXISTS interrompe o processamento da subconsulta assim que encontra uma correspondência .
Aqui temos um exemplo de como usar essa cláusula:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Imagine que estamos trabalhando em uma análise para enviar uma oferta promocional a clientes de cidades específicas. O banco de dados tem vários pedidos dos mesmos clientes. A primeira coisa que vem à nossa mente é usar a cláusula DISTINCT.
Essa função é útil em determinados casos, mas pode consumir muitos recursos, especialmente em grandes conjuntos de dados. Há algumas alternativas para DISTINCT:
GROUP BY em vez de DISTINCT quando possível. GROUP BY pode ser mais eficiente, especialmente quando combinado com funções agregadas. Então, em vez de se apresentar:
SELECT DISTINCT city FROM customers;Você pode usar:
SELECT city FROM customers GROUP BY city;ROW_NUMBER podem nos ajudar a identificar duplicatas e filtrá-las sem usar DISTINCT.Ao trabalhar com dados, interagimos com eles usando SQL por meio de um sistema de gerenciamento de banco de dados (DBMS). O DBMS processa os comandos SQL, gerencia o banco de dados e garante a integridade e a segurança dos dados. Diferentes sistemas de banco de dados oferecem recursos exclusivos que podem ajudar a otimizar as consultas.
As dicas de banco de dados são instruções especiais que podemos adicionar às nossas consultas para executá-las com mais eficiência. Eles são uma ferramenta útil, mas devem ser usados com cautela.
Por exemplo, no MySQLa dica USE INDEX pode forçar o uso de um índice específico:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;No SQL Server, a dica OPTION (LOOP JOIN) especifica o método de união :
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); Essas dicas substituem a otimização padrão da consulta, melhorando o desempenho em cenários específicos.
Por outro lado, o particionamento e o sharding são duas técnicas de distribuição de dados na nuvem.
Manter as estatísticas do banco de dados atualizadas é importante para garantir que o otimizador de consultas possa tomar decisões informadas e precisas sobre a maneira mais eficiente de executar consultas.
As estatísticas descrevem a distribuição de dados em uma tabela (por exemplo, o número de linhas, a frequência dos valores e a distribuição dos valores entre as colunas), e o otimizador se baseia nessas informações para estimar os custos de execução da consulta. Se as estatísticas estiverem desatualizadas, o otimizador poderá escolher planos de execução ineficientes, como usar os índices errados ou optar por uma varredura de tabela completa em vez de uma varredura de índice mais eficiente, o que leva a um desempenho ruim da consulta.
Os bancos de dados geralmente aceitam atualizações automáticas para manter estatísticas precisas. Por exemplo, no SQL Server, a configuração padrão atualiza automaticamente as estatísticas quando uma quantidade significativa de dados é alterada. Da mesma forma, o PostgreSQL tem um recurso de análise automática, que atualiza as estatísticas após um limite especificado de modificação de dados.
No entanto, podemos atualizar manualmente as estatísticas nos casos em que as atualizações automáticas forem insuficientes ou se for necessária uma intervenção manual. No SQL Server, podemos usar o comando UPDATE STATISTICS para atualizar as estatísticas de uma tabela ou índice específico, enquanto no PostgreSQL, o comando ANALYZE pode ser executado para atualizar as estatísticas de uma ou mais tabelas .
-- Update statistics for all tables in the current database
ANALYZE;
-- Update statistics for a specific table
ANALYZE my_table;Um procedimento armazenado é um conjunto de comandos SQL que salvamos em nosso banco de dados para não precisarmos escrever o mesmo SQL repetidamente. Podemos pensar nisso como um script reutilizável.
Quando precisamos executar uma determinada tarefa, como atualizar registros ou calcular valores, basta chamar o procedimento armazenado. Ele pode receber entradas, fazer algum trabalho, como consultar ou modificar dados, e até mesmo retornar um resultado. Os procedimentos armazenados ajudam a acelerar as coisas, pois o SQL é pré-compilado, tornando o código mais limpo e fácil de gerenciar.
Você pode criar um procedimento armazenado no PostgreSQL da seguinte forma:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');Como profissionais de dados, gostamos de ter nossos dados ordenados e agrupados para que possamos obter insights mais facilmente. Normalmente, usamos ORDER BY e GROUP BY em nossas consultas SQL.
No entanto, ambas as cláusulas podem ser computacionalmente caras, especialmente ao lidar com grandes conjuntos de dados. Ao classificar ou agregar dados, o mecanismo de banco de dados geralmente precisa executar uma varredura completa dos dados e, em seguida, organizá-los, identificar os grupos e/ou aplicar funções agregadas, normalmente usando algoritmos que consomem muitos recursos.
Para otimizar as consultas, você pode seguir algumas destas dicas:
ORDER BY somente quando necessário. Se a classificação não for essencial, a omissão dessa cláusula pode nos ajudar a reduzir drasticamente o tempo de processamento. ORDER BY e GROUP BY sejam indexadas . GROUP BY, poderíamos pré-agregar os dados em um estágio anterior ou em uma visualização materializada, para que o banco de dados não precise calcular os mesmos agregados repetidamente. banco de dados não precise computar os mesmos agregados repetidamente.Quando quisermos combinar resultados de várias consultas em uma única lista, podemos usar as cláusulas UNION e UNION ALL. Ambos combinam os resultados de dois ou mais comandos SELECT quando eles têm os mesmos nomes de coluna. No entanto, eles não são iguais, e sua diferença os torna adequados para diferentes casos de uso.
A cláusula UNION remove as linhas duplicadas, o que exige mais tempo de processamento .
Figura: União em SQL. Imagem source: Folha de consulta do DataCamp SQL-Join.
Por outro lado, o UNION ALL combina os resultados, mas mantém todas as linhas, inclusive as duplicadas. Portanto, se não precisarmos remover duplicatas, devemos usar UNION ALL para melhorar o desempenho.
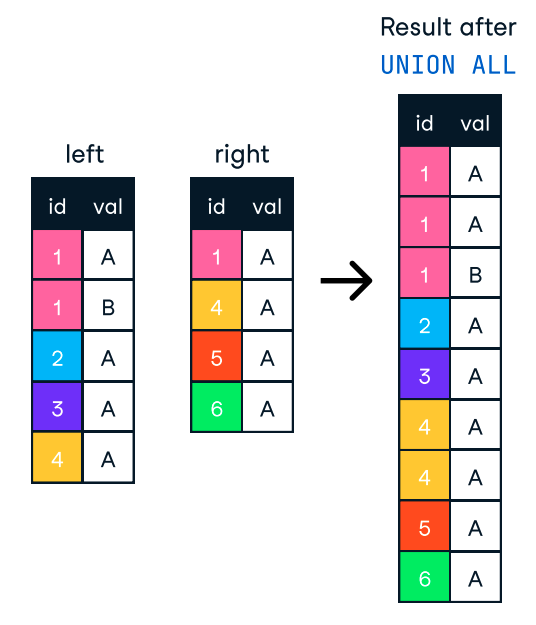
Figura: UNION ALL em SQL. Imagem source: Folha de consulta do DataCamp SQL-Join.
-- Potentially slower
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potentially faster
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Trabalhar com grandes conjuntos de dados implica que, com frequência, encontraremos consultas complexas que são difíceis de entender e otimizar. Podemos tentar lidar com esses casos dividindo-os em consultas menores e mais simples. Dessa forma, podemos identificar facilmente os gargalos de desempenho e aplicar técnicas de otimização.
Uma das estratégias mais usadas para dividir as consultas são as visualizações materializadas. Esses são resultados de consulta pré-computados e armazenados que podem ser acessados rapidamente, em vez de recalcular a consulta sempre que ela for referenciada. Quando os dados subjacentes são alterados, a visualização materializada deve ser atualizada manual ou automaticamente.
Aqui está um exemplo de como criar e consultar uma visualização materializada:
-- Create a materialized view
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Query the materialized view
SELECT * FROM daily_sales;Neste artigo, exploramos várias estratégias e práticas recomendadas para otimizar as consultas SQL, desde indexação e junções até subconsultas e recursos específicos do banco de dados. Ao aplicar essas técnicas, você pode melhorar significativamente o desempenho de suas consultas e fazer com que nossos bancos de dados sejam executados com mais eficiência.
Lembre-se de que a otimização das consultas SQL é um processo contínuo. À medida que seus dados crescem e seu aplicativo evolui, você precisará monitorar e otimizar continuamente suas consultas para garantir que elas estejam sendo executadas com o desempenho ideal.
Para aumentar ainda mais seu conhecimento sobre SQL, recomendamos que você explore os seguintes recursos no DataCamp:
Aprenda mais sobre SQL com estes cursos!
Curso
Curso
Curso
blog
Summer Worsley
13 min
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan

