
Kurs
Datenbearbeitung in SQL
4 Std.
324.1K
SQL ist ein wichtiges Werkzeug für alle, die Daten in relationalen Datenbanken verwalten und manipulieren. Sie ermöglicht es uns, mit Datenbanken zu interagieren und wichtige Aufgaben effizient zu erledigen. Da die Menge der verfügbaren Daten jeden Tag wächst, stehen wir vor der Herausforderung, komplexe Abfragen zu schreiben, um diese Daten abzurufen.
Langsame Abfragen können ein echter Engpass sein, der sich auf alles auswirkt, von der Anwendungsleistung bis zur Benutzerfreundlichkeit. Die Optimierung von SQL-Abfragen verbessert die Leistung, reduziert den Ressourcenverbrauch und sorgt für Skalierbarkeit.
In diesem Artikel werden wir uns einige der effektivsten Techniken zur Optimierung unserer SQL-Abfragen ansehen. Wir werden uns mit den Vor- und Nachteilen der einzelnen Techniken beschäftigen, um ihre Auswirkungen auf die Leistung von SQL-Abfragen zu verstehen. Fangen wir an!
Stell dir vor, wir suchen in einer Bibliothek ohne Katalog nach einem Buch. Wir mussten jedes Regal und jede Reihe durchsuchen, bis wir es endlich fanden. Indizes in einer Datenbank sind ähnlich wie Kataloge. Sie helfen uns, die benötigten Daten schnell zu finden, ohne die gesamte Tabelle zu durchsuchen.
Indizes sind Datenstrukturen, die die Geschwindigkeit beim Abrufen von Daten verbessern. Sie erstellen eine sortierte Kopie der indizierten Spalten, so dass die Datenbank schnell die Zeilen finden kann, die unserer Abfrage entsprechen, was uns viel Zeit spart.
Es gibt drei Hauptarten von Indizes in Datenbanken:
Wie können wir also Indizes nutzen, um die Leistung von SQL-Abfragen zu verbessern? Hier sind einige Best Practices:
customer_id oder item_id durchsuchen, hat die Indizierung dieser Spalten einen großen Einfluss auf die Geschwindigkeit. Hier erfährst du, wie du einen Index erstellen kannst:CREATE INDEX index_customer_id ON customers (customer_id);
SELECT Abfragen zu beschleunigen, können sie INSERT, UPDATE und DELETE leicht verlangsamen. Das liegt daran, dass der Index jedes Mal aktualisiert werden muss, wenn du Daten änderst. Zu viele Indizes können also die Arbeit verlangsamen, weil sie den Overhead für Datenänderungen erhöhen. Manchmal sind wir versucht, SELECT * zu verwenden , um alle Spalten zu erfassen, auch die, die für unsere Analyse nicht relevant sind. Das mag zwar bequem erscheinen, führt aber zu sehr ineffizienten Abfragen, die die Leistung beeinträchtigen können.
Die Datenbank muss mehr Daten als nötig lesen und übertragen, was eine höhere Speichernutzung erfordert, da der Server mehr Informationen als nötig verarbeiten und speichern muss.
Generell sollten wir nur die Spalten auswählen, die wir brauchen. Die Minimierung unnötiger Daten sorgt nicht nur dafür, dass unser Code sauber und leicht verständlich bleibt, sondern hilft auch, die Leistung zu optimieren.
Anstatt also zu schreiben:
SELECT *
FROM products;Wir sollten schreiben:
SELECT product_id, product_name, product_price
FROM products;Wir haben gerade besprochen, dass die Auswahl nur relevanter Spalten als Best Practice zur Optimierung von SQL-Abfragen gilt. Es ist aber auch wichtig, die Anzahl der Zeilen zu begrenzen, die wir abrufen, nicht nur die Spalten. Die Abfragen werden normalerweise langsamer, wenn die Anzahl der Zeilen steigt.
Wir können LIMIT verwenden, um die Anzahl der zurückgegebenen Zeilen zu reduzieren. Diese Funktion verhindert, dass wir ungewollt Tausende von Datenzeilen abrufen, obwohl wir nur mit einigen wenigen arbeiten müssen.
Die Funktion LIMIT ist besonders hilfreich für Validierungsabfragen oder die Überprüfung der Ausgabe einer Transformation, an der wir gerade arbeiten. Es ist ideal, um zu experimentieren und zu verstehen, wie sich unser Code verhält. Für automatisierte Datenmodelle, bei denen wir den gesamten Datensatz zurückgeben müssen, ist sie jedoch möglicherweise nicht geeignet.
Hier haben wir ein Beispiel dafür, wie LIMIT funktioniert:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;Bei der Arbeit mit relationalen Datenbanken werden die Daten oft in separaten Tabellen organisiert, um Redundanzen zu vermeiden und die Effizienz zu verbessern. Das bedeutet jedoch, dass wir Daten von verschiedenen Stellen abrufen und sie zusammenfügen müssen, um alle relevanten Informationen zu erhalten, die wir brauchen.
Mit Joins können wir Zeilen aus zwei oder mehr Tabellen auf der Grundlage einer verwandten Spalte zwischen ihnen in einer einzigen Abfrage kombinieren und so komplexere Analysen durchführen.
Es gibt verschiedene Arten von Verbindungen, und wir müssen wissen, wie wir sie nutzen können. Wenn du die falsche Verknüpfung verwendest, können Duplikate in unserem Datensatz entstehen und ihn verlangsamen.
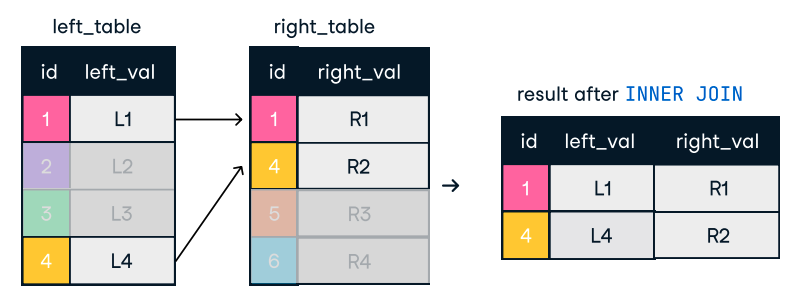
Abbildung: Innere Verbindung. Bildquelle: DataCamp SQL-Join Spickzettel.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
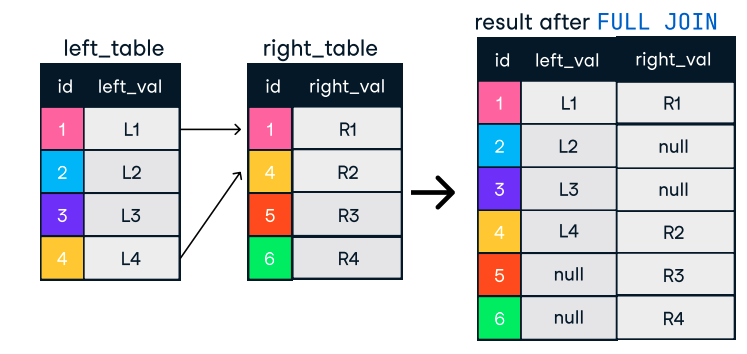
Abbildung: Outer oder Full Join. Bildquelle: DataCamp SQL-Join Spickzettel.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;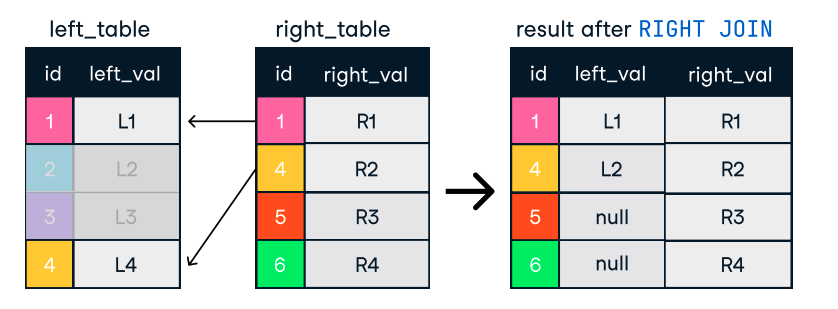
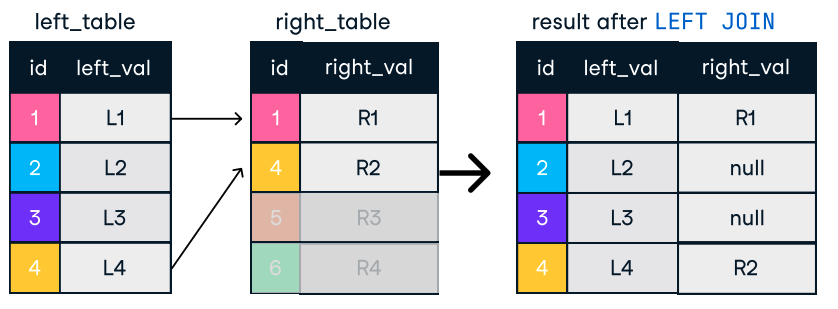
Abbildung: Links und rechts verbinden. Bildquelle: DataCamp SQL-Join Spickzettel.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Tipps für effizientes Verbinden:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;Meistens führen wir SQL-Abfragen aus und prüfen nur, ob die Ausgabe oder das Ergebnis unseren Erwartungen entspricht. Wir fragen uns jedoch selten, was hinter den Kulissen passiert, wenn wir eine SQL-Abfrage ausführen.
Die meisten Datenbanken bieten Funktionen wie EXPLAIN oder EXPLAIN PLAN, um diesen Prozess zu visualisieren. In diesen Plänen wird Schritt für Schritt beschrieben, wie die Datenbank die Daten abrufen wird. Mit dieser Funktion können wir herausfinden, wo wir Leistungsengpässe haben und fundierte Entscheidungen zur Optimierung unserer Abfragen treffen.
Sehen wir uns an, wie wir EXPLAIN nutzen können, um Engpässe zu identifizieren. Wir werden den folgenden Code ausführen:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id Dann können wir die Ergebnisse untersuchen:
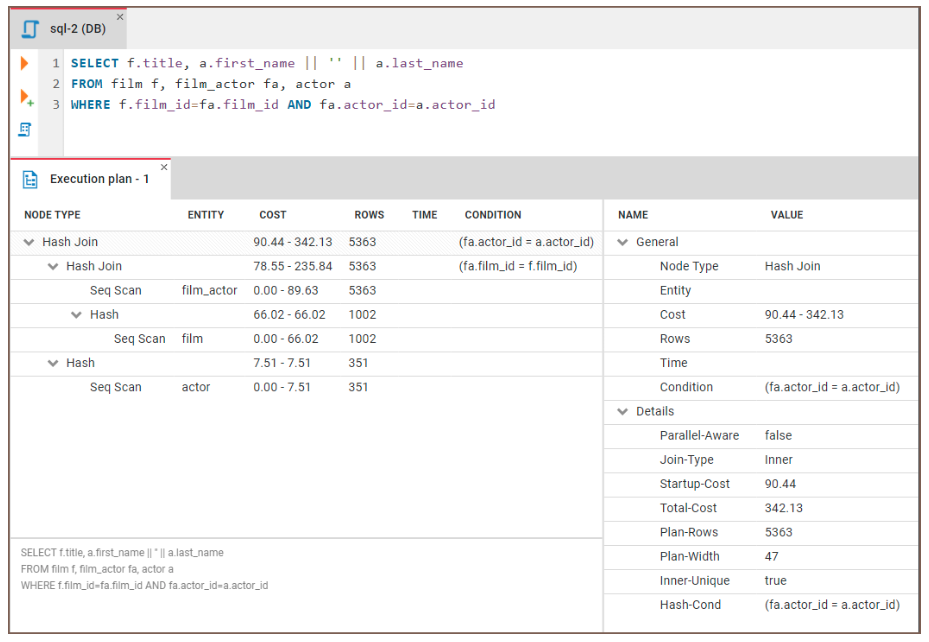
Abbildung: Ein Beispiel für einen Abfrageausführungsplan. Bildquelle: CloudDBeaver website.
Hier findest du allgemeine Hinweise zur Interpretation der Ergebnisse:
WHERE Klausel hin.Die WHERE Klausel ist in SQL-Abfragen unverzichtbar, da sie es uns ermöglicht, Daten nach bestimmten Bedingungen zu filtern und sicherzustellen, dass nur relevante Datensätze zurückgegeben werden. Sie verbessert die Abfrageeffizienz, indem sie die Menge der zu verarbeitenden Daten reduziert, was bei der Arbeit mit einem großen Datensatz sehr wichtig ist.
Eine korrekte WHERE Klausel kann also ein mächtiger Verbündeter sein, wenn wir die Leistung einer SQL-Abfrage optimieren wollen. Sehen wir uns einige Möglichkeiten an, wie wir diese Klausel nutzen können:
WHERE Klausel gut, aber nicht genug. Wir müssen aufpassen, wo wir die Klausel platzieren. Das Herausfiltern möglichst vieler Zeilen zu Beginn der WHERE Klausel kann uns helfen, die Abfrage zu optimieren.WHERE Klausel. Wenn wir eine Funktion auf eine Spalte anwenden, muss die Datenbank diese Funktion auf jede Zeile der Tabelle anwenden, bevor sie die Ergebnisse filtern kann. Dies verhindert, dass die Datenbank Indizes effektiv nutzen kann.Zum Beispiel, statt:
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;Wir sollten sie benutzen:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= in der Regel schneller als LIKE, und die Verwendung bestimmter Datumsbereiche ist schneller als die Verwendung von Funktionen wie MONTH(order_date).Anstatt also zum Beispiel diese Abfrage durchzuführen:
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;Wir können die folgenden Aufgaben übernehmen:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';In manchen Fällen schreiben wir eine Abfrage und haben das Gefühl, dass wir Daten dynamisch filtern, aggregieren oder verknüpfen müssen. Wir wollen nicht mehrere Abfragen machen, sondern es bei einer einzigen Abfrage belassen.
Für diese Fälle können wir Unterabfragen verwenden. Unterabfragen in SQL sind Abfragen, die innerhalb einer anderen Abfrage verschachtelt sind, normalerweise in den Anweisungen SELECT, INSERT, UPDATE oder DELETE.
Unterabfragen können leistungsstark und schnell sein, aber sie können auch Leistungsprobleme verursachen, wenn sie nicht sorgfältig eingesetzt werden. In der Regel sollten wir die Verwendung von Unterabfragen minimieren und eine Reihe von Best Practices befolgen:
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;Wenn wir mit Unterabfragen arbeiten, müssen wir oft prüfen, ob ein Wert in einer Ergebnismenge vorhanden ist. Wir können dies mit zwei IN oder EXISTS tun, aber EXISTS ist im Allgemeinen effizienter, besonders bei größeren Datensätzen.
Die IN Klausel liest die gesamte Ergebnismenge der Subquery in den Speicher, bevor sie verglichen wird. Die EXISTS Klausel hingegen bricht die Verarbeitung der Unterabfrage ab, sobald sie eine Übereinstimmung findet .
Hier haben wir ein Beispiel dafür, wie du diese Klausel verwenden kannst:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Stell dir vor, wir arbeiten an einer Analyse für den Versand eines Werbeangebots an Kunden aus bestimmten Städten. Die Datenbank enthält mehrere Bestellungen von denselben Kunden. Das erste, was uns in den Sinn kommt, ist die Verwendung der DISTINCT Klausel.
Diese Funktion ist in bestimmten Fällen praktisch, kann aber ressourcenintensiv sein, besonders bei großen Datensätzen. Es gibt ein paar Alternativen zu DISTINCT:
GROUP BY anstelle von DISTINCT, wenn möglich. GROUP BY kann effizienter sein, vor allem in Kombination mit Aggregatfunktionen. Anstatt also aufzutreten:
SELECT DISTINCT city FROM customers;Wir können verwenden:
SELECT city FROM customers GROUP BY city;ROW_NUMBER können uns helfen, Duplikate zu erkennen und herauszufiltern, ohne DISTINCT zu verwenden.Wenn wir mit Daten arbeiten, interagieren wir mit ihnen mithilfe von SQL über ein Datenbankmanagementsystem (DBMS). Das DBMS verarbeitet die SQL-Befehle, verwaltet die Datenbank und sorgt für Datenintegrität und Sicherheit. Verschiedene Datenbanksysteme bieten einzigartige Funktionen, mit denen Abfragen optimiert werden können.
Datenbank-Hinweise sind spezielle Anweisungen, die wir zu unseren Abfragen hinzufügen können, um eine Abfrage effizienter auszuführen. Sie sind ein hilfreiches Instrument, aber sie sollten mit Vorsicht eingesetzt werden.
Zum Beispiel in MySQL kann der USE INDEX hint die Verwendung eines bestimmten Index erzwingen:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;In SQL Server gibt der Hinweis OPTION (LOOP JOIN) die Verknüpfungsmethode an :
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); Diese Hinweise setzen die Standardabfrageoptimierung außer Kraft und verbessern die Leistung in bestimmten Szenarien.
Auf der anderen Seite sind Partitionierung und Sharding zwei Techniken zur Verteilung von Daten in der Cloud.
Es ist wichtig, die Datenbankstatistiken auf dem neuesten Stand zu halten, um sicherzustellen, dass der Query Optimizer fundierte und genaue Entscheidungen über die effizienteste Art der Ausführung von Abfragen treffen kann.
Statistiken beschreiben die Datenverteilung in einer Tabelle (z. B. die Anzahl der Zeilen, die Häufigkeit der Werte und die Verteilung der Werte auf die Spalten). Der Optimierer stützt sich auf diese Informationen, um die Kosten für die Abfrageausführung zu schätzen. Wenn die Statistiken veraltet sind, kann der Optimierer ineffiziente Ausführungspläne wählen, z. B. die falschen Indizes verwenden oder sich für einen vollständigen Tabellenscan anstelle eines effizienteren Indexscans entscheiden, was zu einer schlechten Abfrageleistung führt.
Datenbanken unterstützen oft automatische Aktualisierungen, um genaue Statistiken zu erhalten. In der Standardkonfiguration von SQL Server werden die Statistiken zum Beispiel automatisch aktualisiert, wenn sich eine größere Menge an Daten ändert. Auch PostgreSQL verfügt über eine automatische Analysefunktion, die die Statistiken nach einem bestimmten Schwellenwert für Datenänderungen aktualisiert.
Wir können die Statistiken jedoch manuell aktualisieren, wenn die automatische Aktualisierung nicht ausreicht oder ein manuelles Eingreifen erforderlich ist. In SQL Server können wir den Befehl UPDATE STATISTICS verwenden, um die Statistiken für eine bestimmte Tabelle oder einen Index zu aktualisieren, während in PostgreSQL der Befehl ANALYZE ausgeführt werden kann, um die Statistiken für eine oder mehrere Tabellen zu aktualisieren.
-- Update statistics for all tables in the current database
ANALYZE;
-- Update statistics for a specific table
ANALYZE my_table;Eine gespeicherte Prozedur ist eine Reihe von SQL-Befehlen, die wir in unserer Datenbank speichern, damit wir nicht immer wieder dieselben SQL-Befehle schreiben müssen. Wir können uns das wie ein wiederverwendbares Skript vorstellen.
Wenn wir eine bestimmte Aufgabe ausführen müssen, wie das Aktualisieren von Datensätzen oder das Berechnen von Werten, rufen wir einfach die gespeicherte Prozedur auf. Sie kann Eingaben entgegennehmen, Arbeit verrichten, z. B. Daten abfragen oder ändern, und sogar ein Ergebnis zurückgeben. Stored Procedures beschleunigen die Arbeit, da das SQL vorkompiliert ist und dein Code dadurch sauberer und einfacher zu verwalten ist.
Wir können eine Stored Procedure in PostgreSQL wie folgt erstellen:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');Als Datenexperten haben wir unsere Daten gerne geordnet und gruppiert, damit wir leichter Erkenntnisse gewinnen können. Normalerweise verwenden wir ORDER BY und GROUP BY in unseren SQL-Abfragen.
Beide Klauseln können jedoch sehr rechenintensiv sein, vor allem bei großen Datensätzen. Beim Sortieren oder Aggregieren von Daten muss die Datenbank-Engine oft einen vollständigen Scan der Daten durchführen und sie dann ordnen, die Gruppen identifizieren und/oder Aggregatfunktionen anwenden, wobei in der Regel ressourcenintensive Algorithmen verwendet werden.
Um die Abfragen zu optimieren, können wir einige dieser Tipps befolgen:
ORDER BY nur nutzen, wenn es nötig ist. Wenn das Sortieren nicht unbedingt notwendig ist, kann das Weglassen dieser Klausel die Bearbeitungszeit drastisch reduzieren. ORDER BY und GROUP BY beteiligten Spalten indiziert sind . GROUP BY können wir die Daten zu einem früheren Zeitpunkt voraggregieren oder in einer materialisierten Ansicht, so dass die Datenbank nicht immer wieder die gleichen Aggregate berechnen muss.Wenn wir Ergebnisse aus mehreren Abfragen in einer Liste zusammenfassen wollen, können wir die Klauseln UNION und UNION ALL verwenden. Beide kombinieren die Ergebnisse von zwei oder mehr SELECT Anweisungen, wenn sie die gleichen Spaltennamen haben. Sie sind jedoch nicht dasselbe und eignen sich aufgrund ihrer Unterschiede für unterschiedliche Anwendungsfälle.
Die UNION Klausel entfernt doppelte Zeilen, was mehr Verarbeitungszeit erfordert .
Abbildung: Union in SQL. Bild sauerce: DataCamp SQL-Join Spickzettel.
UNION ALL hingegen kombiniert die Ergebnisse, behält aber alle Zeilen, auch die doppelten. Wenn wir also keine Duplikate entfernen müssen, sollten wir UNION ALL verwenden, um die Leistung zu verbessern.
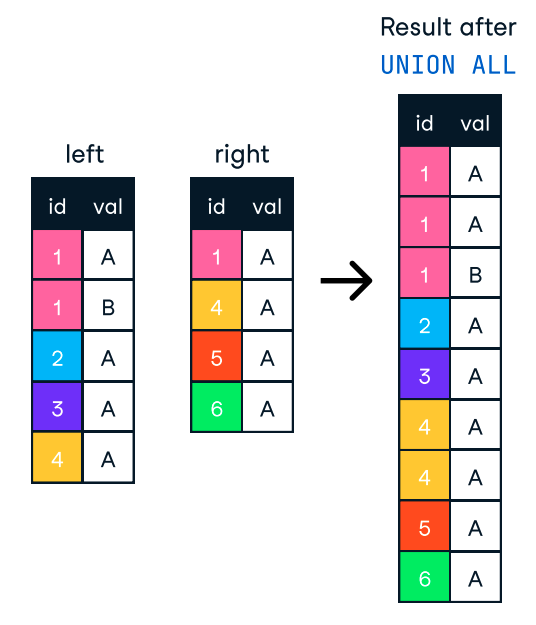
Abbildung: UNION ALL in SQL. Bild source: DataCamp SQL-Join Spickzettel.
-- Potentially slower
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potentially faster
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Die Arbeit mit großen Datensätzen bringt es mit sich, dass wir oft auf komplexe Abfragen stoßen, die schwer zu verstehen und zu optimieren sind. Wir können versuchen, diese Fälle zu lösen, indem wir sie in kleinere, einfachere Abfragen zerlegen. Auf diese Weise können wir Leistungsengpässe leicht erkennen und Optimierungstechniken anwenden.
Eine der am häufigsten verwendeten Strategien zur Aufschlüsselung von Abfragen sind materialisierte Ansichten. Diese sind vorberechnete und gespeicherte Abfrageergebnisse, auf die schnell zugegriffen werden kann, anstatt die Abfrage jedes Mal neu zu berechnen. Wenn sich die zugrunde liegenden Daten ändern, muss die materialisierte Ansicht manuell oder automatisch aktualisiert werden.
Hier ist ein Beispiel dafür, wie du eine materialisierte Ansicht erstellst und abfragst:
-- Create a materialized view
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Query the materialized view
SELECT * FROM daily_sales;In diesem Artikel haben wir verschiedene Strategien und Best Practices für die Optimierung von SQL-Abfragen untersucht, von Indizierung und Joins bis hin zu Unterabfragen und datenbankspezifischen Funktionen. Wenn du diese Techniken anwendest, kannst du die Leistung deiner Abfragen deutlich verbessern und dafür sorgen, dass unsere Datenbanken effizienter laufen.
Denk daran, dass die Optimierung von SQL-Abfragen ein fortlaufender Prozess ist. Wenn deine Daten wachsen und deine Anwendung sich weiterentwickelt, musst du deine Abfragen ständig überwachen und optimieren, um sicherzustellen, dass sie mit optimaler Leistung laufen.
Um dein Verständnis von SQL zu vertiefen, empfehlen wir dir, die folgenden Ressourcen auf DataCamp zu nutzen:
Lerne mehr über SQL mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Laiba Siddiqui
Tutorial
Sejal Jaiswal
Tutorial
Mark Pedigo
