
Cours
Manipulation de données en SQL
4 h
324.1K
SQL est un outil important pour tous ceux qui gèrent et manipulent des données dans des bases de données relationnelles. Il nous permet d'interagir avec les bases de données et d'effectuer des tâches essentielles de manière efficace. La quantité de données disponibles augmentant chaque jour, nous sommes confrontés au défi d'écrire des requêtes complexes pour récupérer ces données.
Les requêtes lentes peuvent constituer un véritable goulot d'étranglement et avoir un impact sur tous les aspects, des performances de l'application à l'expérience de l'utilisateur. L'optimisation des requêtes SQL permet d'améliorer les performances, de réduire la consommation de ressources et de garantir l'évolutivité.
Dans cet article, nous allons examiner quelques-unes des techniques les plus efficaces pour optimiser nos requêtes SQL. Nous examinerons les avantages et les inconvénients de chaque technique afin de comprendre leur impact sur les performances des requêtes SQL. Commençons !
Imaginez que vous cherchiez un livre dans une bibliothèque sans catalogue. Nous devions vérifier chaque étagère et chaque rangée jusqu'à ce que nous le trouvions enfin. Les index d'une base de données sont similaires aux catalogues. Ils nous aident à localiser rapidement les données dont nous avons besoin sans avoir à parcourir l'ensemble du tableau.
Les index sont des structures de données qui améliorent la vitesse de récupération des données. Ils fonctionnent en créant une copie triée des colonnes indexées, ce qui permet à la base de données de repérer rapidement les lignes qui correspondent à notre requête, nous faisant ainsi gagner beaucoup de temps.
Il existe trois types principaux d'index dans les bases de données :
Comment utiliser les index pour améliorer les performances des requêtes SQL ? Voyons quelques bonnes pratiques :
customer_id ou item_id, l'indexation de ces colonnes aura un impact considérable sur la rapidité de la recherche. Vous trouverez ci-dessous comment créer un index :CREATE INDEX index_customer_id ON customers (customer_id);
SELECT, ils peuvent légèrement ralentir les opérations INSERT, UPDATE et DELETE. En effet, l'index doit être mis à jour chaque fois que vous modifiez des données. Ainsi, un trop grand nombre d'index peut ralentir les choses en augmentant la charge de travail pour les modifications de données. Parfois, nous sommes tentés d'utiliser SELECT * pour récupérer toutes les colonnes, même celles qui ne sont pas pertinentes pour notre analyse. Bien que cela puisse sembler pratique, cela conduit à des requêtes très inefficaces qui peuvent ralentir les performances.
La base de données doit lire et transférer plus de données que nécessaire, ce qui nécessite une utilisation plus importante de la mémoire puisque le serveur doit traiter et stocker plus d'informations que nécessaire.
En règle générale, nous ne devrions sélectionner que les colonnes spécifiques dont nous avons besoin. La réduction des données inutiles permet non seulement de conserver un code propre et facile à comprendre, mais aussi d'optimiser les performances.
Ainsi, au lieu d'écrire :
SELECT *
FROM products;Nous devrions écrire :
SELECT product_id, product_name, product_price
FROM products;Nous venons de voir que le fait de ne sélectionner que les colonnes pertinentes est considéré comme une meilleure pratique pour optimiser les requêtes SQL. Cependant, il est également important de limiter le nombre de lignes que nous récupérons, et pas seulement les colonnes. Les requêtes ralentissent généralement lorsque le nombre de lignes augmente.
Nous pouvons utiliser LIMIT pour réduire le nombre de lignes renvoyées. Cette fonction nous évite d'extraire involontairement des milliers de lignes de données alors que nous n'en avons besoin que de quelques-unes.
La fonction LIMIT est particulièrement utile pour les requêtes de validation ou pour inspecter la sortie d'une transformation sur laquelle nous travaillons. Il est idéal pour expérimenter et comprendre le comportement de notre code. Cependant, elle peut ne pas convenir aux modèles de données automatisés, pour lesquels nous devons renvoyer l'ensemble des données.
Voici un exemple du fonctionnement de LIMIT:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;Lorsque vous travaillez avec des bases de données relationnelles, les données sont souvent organisées en tableaux distincts afin d'éviter les redondances et d'améliorer l'efficacité. Toutefois, cela signifie que nous devons extraire des données de différents endroits et les coller ensemble pour obtenir toutes les informations pertinentes dont nous avons besoin.
Les jointures nous permettent de combiner les lignes de deux tableaux ou plus sur la base d'une colonne liée entre eux dans une seule requête, ce qui permet d'effectuer des analyses plus complexes.
Il existe différents types de jointures, et nous devons comprendre comment les utiliser. L'utilisation d'une mauvaise jointure peut créer des doublons dans notre ensemble de données et le ralentir.
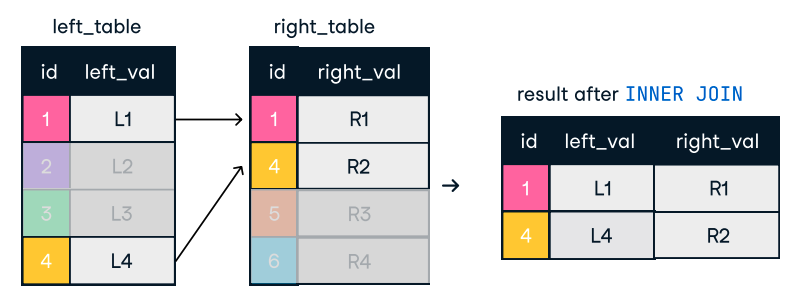
Figure : Jointure intérieure. Source de l'image : L'antisèche SQL-Join de DataCamp.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
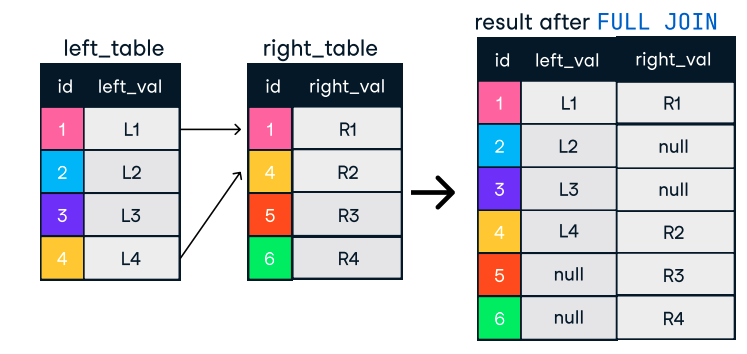
Figure : Jointure externe ou complète. Source de l'image : L'antisèche SQL-Join de DataCamp.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;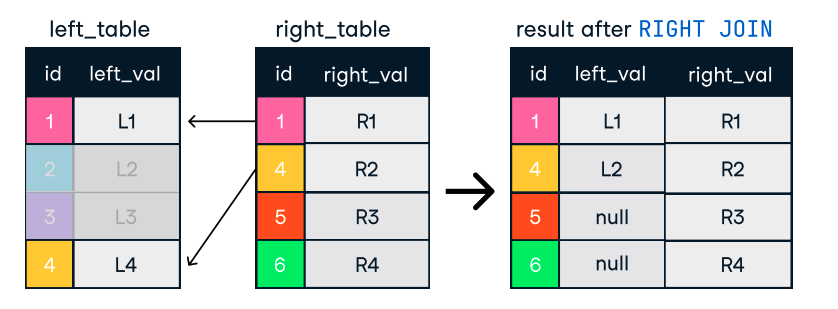
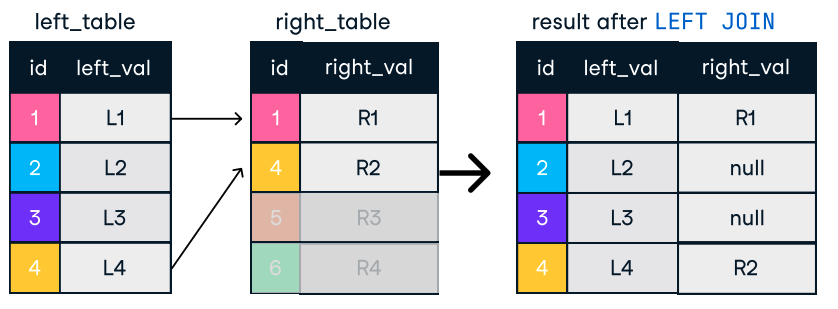
Figure : Gauche et droite. Source de l'image : L'antisèche SQL-Join de DataCamp.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Conseils pour des jonctions efficaces :
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;La plupart du temps, nous exécutons des requêtes SQL et vérifions uniquement si le résultat obtenu correspond à nos attentes. Cependant, nous nous demandons rarement ce qui se passe dans les coulisses lorsque nous exécutons une requête SQL.
La plupart des bases de données proposent des fonctions telles que EXPLAIN ou EXPLAIN PLAN pour visualiser ce processus. Ces plans expliquent, étape par étape, comment la base de données récupérera les données. Nous pouvons utiliser cette fonction pour identifier les goulets d'étranglement en matière de performances et prendre des décisions éclairées pour optimiser nos requêtes.
Voyons comment nous pouvons utiliser EXPLAIN pour identifier les goulets d'étranglement. Nous allons exécuter le code suivant :
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id Nous pouvons ensuite examiner les résultats :
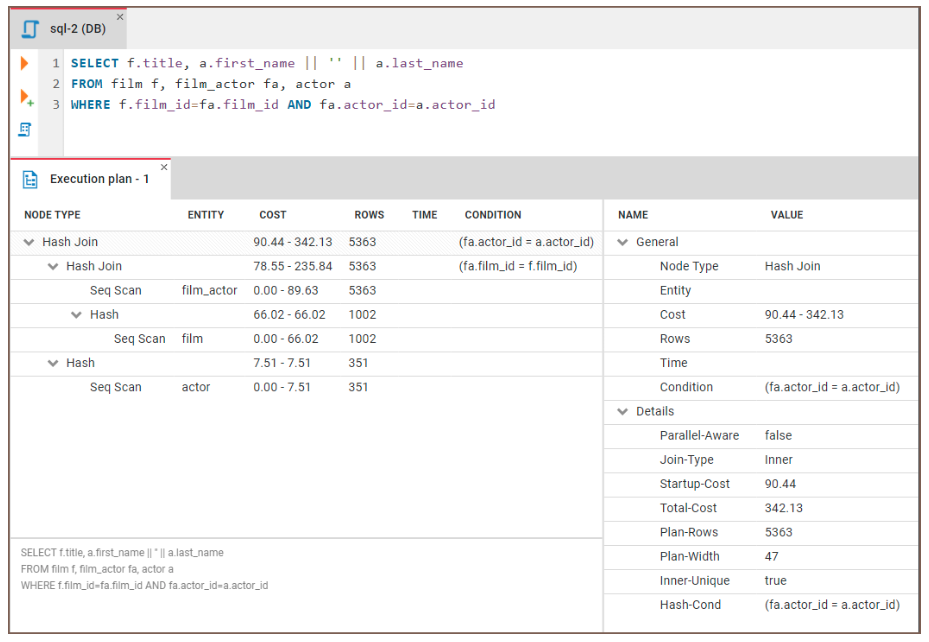
Figure : Exemple de plan d'exécution d'une requête. Source de l'image : Site web de CloudDBeaver.
Voici des conseils généraux sur la manière d'interpréter les résultats :
WHERE inefficace.La clause WHERE est essentielle dans les requêtes SQL car elle permet de filtrer les données sur la base de conditions spécifiques, en veillant à ce que seuls les enregistrements pertinents soient renvoyés. Il améliore l'efficacité des requêtes en réduisant la quantité de données traitées, ce qui est très important pour travailler avec un grand ensemble de données.
Ainsi, une clause WHERE correcte peut être un allié puissant lorsque nous optimisons les performances d'une requête SQL. Voyons comment nous pouvons tirer parti de cette clause :
WHERE est une bonne chose, mais elle n'est pas suffisante. Nous devons faire attention à l'endroit où nous plaçons la clause. Le fait de filtrer autant de lignes que possible au début de la clause WHERE peut nous aider à optimiser la requête.WHERE. Lorsque nous appliquons une fonction à une colonne, la base de données doit appliquer cette fonction à chaque ligne du tableau avant de pouvoir filtrer les résultats. Cela empêche la base de données d'utiliser efficacement les index.Par exemple, au lieu de :
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;Nous devrions utiliser :
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= est généralement plus rapide que LIKE, et l'utilisation de plages de dates spécifiques est plus rapide que l'utilisation de fonctions telles que MONTH(order_date).Ainsi, par exemple, au lieu d'effectuer cette requête :
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;Nous pouvons effectuer les opérations suivantes :
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';Dans certains cas, nous écrivons une requête et ressentons le besoin d'effectuer dynamiquement des opérations de filtrage, d'agrégation ou de jointure de données. Nous ne voulons pas effectuer plusieurs requêtes, mais nous limiter à une seule.
Dans ce cas, nous pouvons utiliser des sous-requêtes. Les sous-requêtes en SQL sont des requêtes imbriquées dans une autre requête, généralement dans les instructions SELECT, INSERT, UPDATE ou DELETE.
Les sous-requêtes peuvent être puissantes et rapides, mais elles peuvent également entraîner des problèmes de performance si elles ne sont pas utilisées avec précaution. En règle générale, nous devrions minimiser l'utilisation des sous-requêtes et suivre un ensemble de bonnes pratiques :
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;Lorsque nous travaillons avec des sous-requêtes, nous devons souvent vérifier si une valeur existe dans un ensemble de résultats. Nous pouvons le faire avec deux IN ou EXISTS, mais EXISTS est généralement plus efficace, en particulier pour les grands ensembles de données.
La clause IN lit l'ensemble des résultats de la sous-requête dans la mémoire avant de les comparer. En revanche, la clause EXISTS arrête le traitement de la sous-requête dès qu'elle trouve une correspondance .
Voici un exemple d'utilisation de cette clause :
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Imaginons que nous travaillions sur une analyse permettant d'envoyer une offre promotionnelle à des clients résidant dans des villes différentes. La base de données contient plusieurs commandes provenant des mêmes clients. La première chose qui nous vient à l'esprit est l'utilisation de la clause DISTINCT.
Cette fonction est pratique dans certains cas, mais peut être gourmande en ressources, en particulier pour les grands ensembles de données. Il existe quelques alternatives à DISTINCT:
GROUP BY au lieu de DISTINCT dans la mesure du possible. GROUP BY peut être plus efficace, en particulier lorsqu'elle est combinée avec des fonctions agrégées. Ainsi, au lieu de se produire :
SELECT DISTINCT city FROM customers;Nous pouvons utiliser :
SELECT city FROM customers GROUP BY city;ROW_NUMBER peuvent nous aider à identifier les doublons et à les filtrer sans utiliser DISTINCT.Lorsque nous travaillons avec des données, nous interagissons avec elles en utilisant le langage SQL par l'intermédiaire d'un système de gestion de base de données (SGBD). Le SGBD traite les commandes SQL, gère la base de données et assure l'intégrité et la sécurité des données. Les différents systèmes de base de données offrent des caractéristiques uniques qui peuvent aider à optimiser les requêtes.
Les astuces de base de données sont des instructions spéciales que nous pouvons ajouter à nos requêtes pour les exécuter plus efficacement. Ils constituent un outil utile, mais doivent être utilisés avec prudence.
Par exemple, dans MySQLl' indice USE INDEX peut forcer l'utilisation d'un index spécifique :
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;Dans SQL Server, l' indice OPTION (LOOP JOIN) spécifie la méthode de jointure :
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); Ces conseils remplacent l'optimisation par défaut de la requête, améliorant ainsi les performances dans des scénarios spécifiques.
D'autre part, le partitionnement et le sharding sont deux techniques de distribution des données dans le cloud.
Il est important de tenir à jour les statistiques de la base de données pour que l'optimiseur de requêtes puisse prendre des décisions éclairées et précises sur la manière la plus efficace d'exécuter les requêtes.
Les statistiques décrivent la distribution des données dans un tableau (par exemple, le nombre de lignes, la fréquence des valeurs et la répartition des valeurs entre les colonnes), et l'optimiseur s'appuie sur ces informations pour estimer les coûts d'exécution des requêtes. Si les statistiques sont obsolètes, l'optimiseur peut choisir des plans d'exécution inefficaces, par exemple en utilisant les mauvais index ou en optant pour un balayage complet du tableau au lieu d'un balayage de l'index plus efficace, ce qui entraîne de mauvaises performances de la requête.
Les bases de données permettent souvent des mises à jour automatiques afin de maintenir des statistiques exactes. Par exemple, dans SQL Server, la configuration par défaut met automatiquement à jour les statistiques lorsqu'une quantité importante de données est modifiée. De même, PostgreSQL dispose d'une fonction d'auto-analyse qui met à jour les statistiques après un seuil spécifié de modification des données.
Toutefois, nous pouvons mettre à jour manuellement les statistiques dans les cas où les mises à jour automatiques sont insuffisantes ou si une intervention manuelle est nécessaire. Dans SQL Server, nous pouvons utiliser la commande UPDATE STATISTICS pour actualiser les statistiques d'un tableau ou d'un index spécifique, tandis que dans PostgreSQL, la commande ANALYZE peut être exécutée pour mettre à jour les statistiques d'un ou de plusieurs tableaux .
-- Update statistics for all tables in the current database
ANALYZE;
-- Update statistics for a specific table
ANALYZE my_table;Une procédure stockée est un ensemble de commandes SQL que nous enregistrons dans notre base de données afin de ne pas avoir à écrire le même code SQL à plusieurs reprises. Nous pouvons considérer qu'il s'agit d'un script réutilisable.
Lorsque nous devons effectuer une certaine tâche, comme la mise à jour d'enregistrements ou le calcul de valeurs, il nous suffit d'appeler la procédure stockée. Il peut recevoir des données, effectuer un travail, tel que l'interrogation ou la modification de données, et même renvoyer un résultat. Les procédures stockées permettent d'accélérer les choses puisque le code SQL est précompilé, ce qui rend votre code plus propre et plus facile à gérer.
Nous pouvons créer une procédure stockée dans PostgreSQL comme suit :
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');En tant que praticiens des données, nous aimons que nos données soient ordonnées et regroupées afin d'obtenir plus facilement des informations. Nous utilisons généralement ORDER BY et GROUP BY dans nos requêtes SQL.
Cependant, ces deux clauses peuvent être coûteuses en termes de calcul, en particulier lorsqu'il s'agit de grands ensembles de données. Lors du tri ou de l'agrégation des données, le moteur de base de données doit souvent effectuer une analyse complète des données, puis les organiser, identifier les groupes et/ou appliquer des fonctions d'agrégation, généralement à l'aide d'algorithmes gourmands en ressources.
Pour optimiser les requêtes, nous pouvons suivre certains des conseils suivants :
ORDER BY qu'en cas de nécessité. Si le tri n'est pas essentiel, l'omission de cette clause peut nous aider à réduire considérablement le temps de traitement. ORDER BY et GROUP BY sont indexées . GROUP BY, nous pourrions pré-agréger les données à un stade antérieur ou dans une vue matérialisée, de sorte que la base de données n'ait pas besoin de calculer les mêmes agrégats à plusieurs reprises. la base de données n'a pas besoin de calculer les mêmes agrégats à plusieurs reprises.Pour combiner les résultats de plusieurs requêtes en une seule liste, vous pouvez utiliser les clauses UNION et UNION ALL. Les deux combinent les résultats de deux ou plusieurs déclarations SELECT lorsqu'elles ont les mêmes noms de colonne. Cependant, ils ne sont pas identiques et leur différence les rend adaptés à des cas d'utilisation différents.
La clause UNION supprime les lignes dupliquées, ce qui nécessite plus de temps de traitement.
Figure : Union en SQL. Image source : L'antisèche SQL-Join de DataCamp.
En revanche, UNION ALL combine les résultats mais conserve toutes les lignes, y compris les doublons. Par conséquent, si nous n'avons pas besoin de supprimer les doublons, nous devrions utiliser UNION ALL pour de meilleures performances.
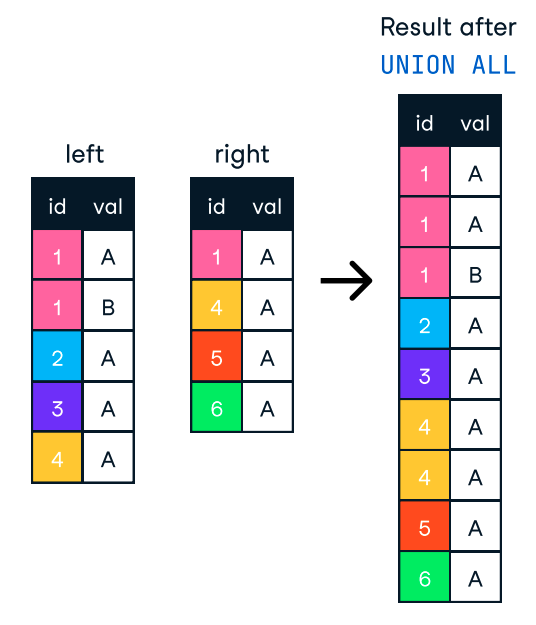
Figure : UNION ALL en SQL. Image source : L'antisèche SQL-Join de DataCamp.
-- Potentially slower
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potentially faster
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Travailler avec de grands ensembles de données implique que nous rencontrons souvent des requêtes complexes qui sont difficiles à comprendre et à optimiser. Nous pouvons essayer de traiter ces cas en les décomposant en requêtes plus petites et plus simples. De cette manière, nous pouvons facilement identifier les goulets d'étranglement et appliquer des techniques d'optimisation.
Les vues matérialisées constituent l'une des stratégies les plus fréquemment utilisées pour décomposer les requêtes. Ces sont des résultats de requête précalculés et stockés auxquels on peut accéder rapidement plutôt que de recalculer la requête à chaque fois qu'elle est référencée. Lorsque les données sous-jacentes changent, la vue matérialisée doit être actualisée manuellement ou automatiquement.
Voici un exemple de création et d'interrogation d'une vue matérialisée :
-- Create a materialized view
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Query the materialized view
SELECT * FROM daily_sales;Dans cet article, nous avons exploré diverses stratégies et meilleures pratiques pour optimiser les requêtes SQL, de l'indexation et des jointures aux sous-requêtes et aux fonctionnalités spécifiques aux bases de données. En appliquant ces techniques, vous pouvez améliorer de manière significative la performance de vos requêtes et rendre nos bases de données plus efficaces.
N'oubliez pas que l'optimisation des requêtes SQL est un processus continu. Au fur et à mesure que vos données augmentent et que votre application évolue, vous devrez continuellement surveiller et optimiser vos requêtes pour vous assurer qu'elles fonctionnent de manière optimale.
Pour approfondir votre compréhension de SQL, nous vous encourageons à explorer les ressources suivantes sur DataCamp :
Apprenez-en plus sur SQL avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Samuel Shaibu
Tutoriel
Sejal Jaiswal
Tutoriel

