Course
Data Manipulation in SQL
4 hr
324.1K
SQL is an important tool for anyone managing and manipulating data within relational databases. It enables us to interact with databases and perform essential tasks efficiently. With the amount of available data growing every day, we face the challenge of writing complex queries to retrieve that data.
Slow queries can be a real bottleneck, impacting everything from application performance to user experience. Optimizing SQL queries improves performance, reduces resource consumption, and ensures scalability.
In this article, we’ll look into some of the most effective techniques for optimizing our SQL queries. We will dive into the benefits and drawbacks of each technique to understand their impact on SQL query performance. Let’s start!
Imagine we are searching for a book in a library without a catalog. We'd have to check every shelf and every row until we finally found it. Indexes in a database are similar to catalogs. They help us quickly locate the data we need without scanning the entire table.
Indexes are data structures that improve the speed at which data is retrieved. They work by creating a sorted copy of the indexed columns, which allows the database to quickly pinpoint the rows that match our query, saving us a lot of time.
There are three main types of indexes in databases:
So, how can we use indexes to improve the performance of SQL queries? Let’s see some best practices:
customer_id or item_id, indexing those columns will greatly impact speed. Check below how to create an index:CREATE INDEX index_customer_id ON customers (customer_id);
SELECT queries, they can slightly slow down INSERT, UPDATE, and DELETE operations. This is because the index needs to be updated every time you modify data. So, too many indexes can slow things down by increasing the overhead for data modifications. Sometimes, we are tempted to use SELECT * to grab all columns, even those that aren't relevant to our analysis. Although this could seem convenient, it leads to very inefficient queries that can slow down performance.
The database has to read and transfer more data than necessary, requiring higher memory usage since the server must process and store more information than needed.
As a general best practice, we should only select the specific columns we need. Minimizing unnecessary data not only will keep our code clean and easy to understand but also help optimize the performance.
So, instead of writing:
SELECT *
FROM products;We should write:
SELECT product_id, product_name, product_price
FROM products;We’ve just discussed that selecting only relevant columns is considered a best practice to optimize SQL queries. However, it is also important to limit the number of rows we are retrieving, not just columns. The queries usually slow down when the number of rows increases.
We can use LIMIT to reduce the number of rows returned. This feature prevents us from unintentionally retrieving thousands of rows of data when we only need to work with a few.
The LIMIT function is especially helpful for validation queries or inspecting the output of a transformation we're working on. It’s ideal for experimentation and understanding how our code behaves. However, it may not be suitable for automated data models, where we need to return the entire dataset.
Here we have an example of how LIMIT works:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;When working with relational databases, data is often organized into separate tables to avoid redundancy and improve efficiency. However, this means that we need to retrieve data from different places and glue them together to get all the relevant information we need.
Joins allow us to combine rows from two or more tables based on a related column between them in a single query, making it possible to perform more complex analyses.
There are different types of join, and we need to understand how to use them. Using the wrong join can create duplicates in our dataset and slow it down.
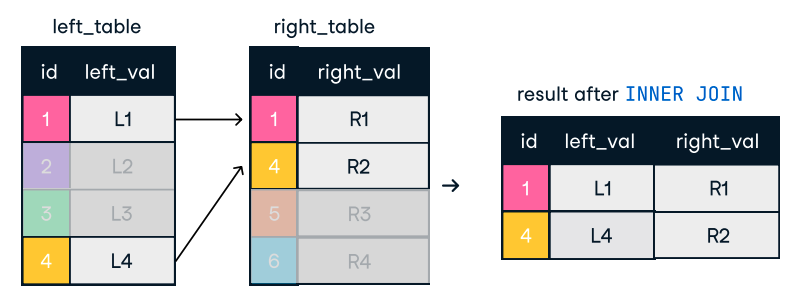
Figure: Inner Join. Image source: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
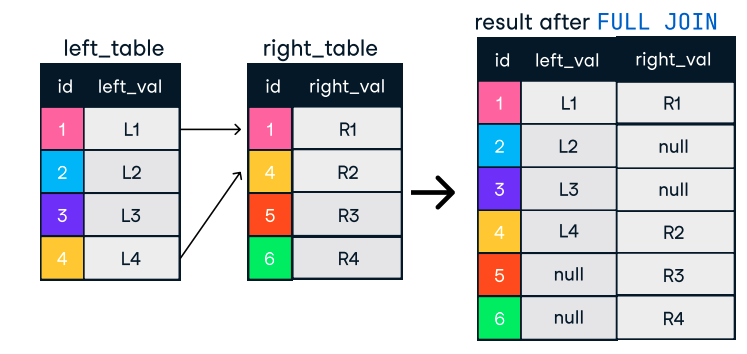
Figure: Outer or Full Join. Image source: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;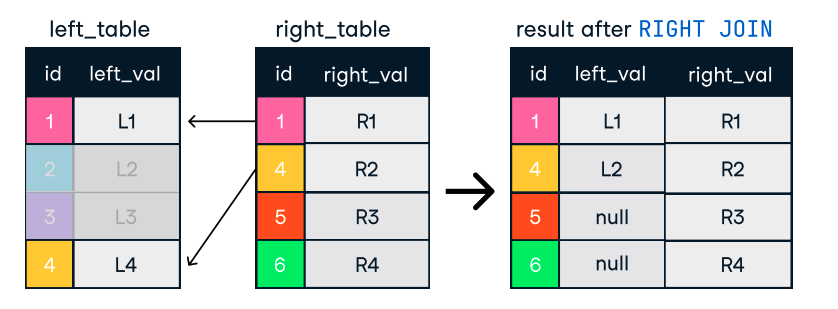
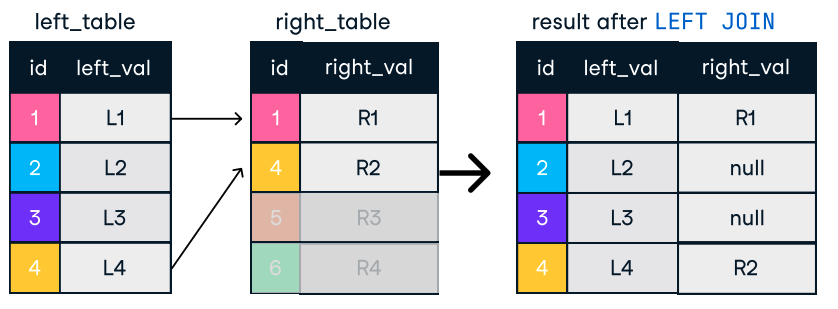
Figure: Left and Right Join. Image source: DataCamp SQL-Join cheat sheet.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Tips for efficient joins:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;Most of the time, we run SQL queries and only check if the output or result retrieved is what we expected. However, we rarely wonder what happens behind the scenes when we execute a SQL query.
Most databases provide functions such as EXPLAIN or EXPLAIN PLAN to visualize this process. These plans provide a step-by-step breakdown of how the database will retrieve the data. We can use this feature to identify where we have the performance bottlenecks and make informed decisions about optimizing our queries.
Let’s see how we can use EXPLAIN to identify bottlenecks. We’ll run the following code:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id We can then examine the results:
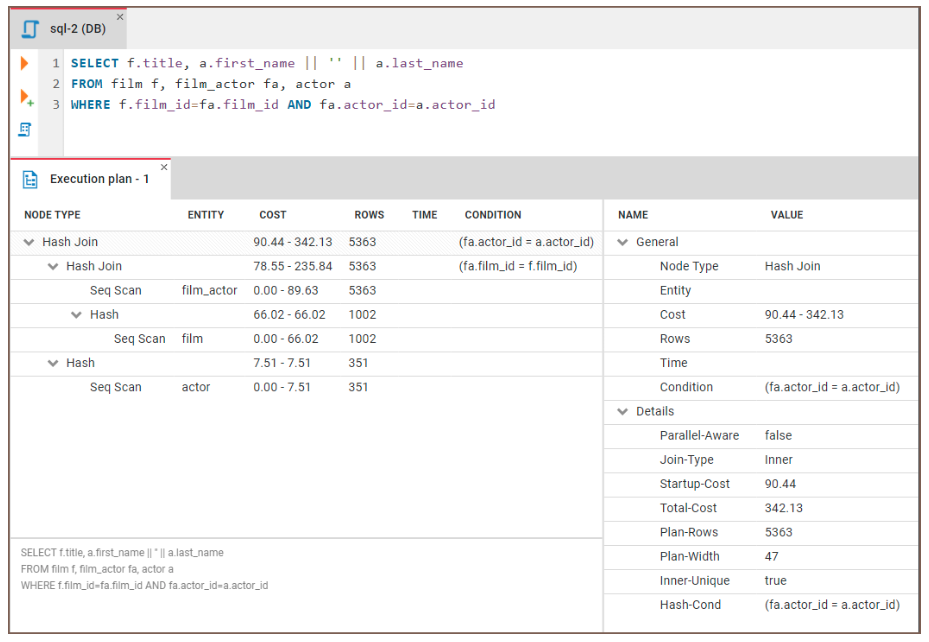
Figure: An example of a query execution plan. Image source: CloudDBeaver website.
Here’s general guidance on how to interpret the results:
WHERE clause.The WHERE clause is essential in SQL queries because it allows us to filter data based on specific conditions, ensuring only relevant records are returned. It improves query efficiency by reducing the amount of data processed, which is very important for working with a large dataset.
So, a correct WHERE clause can be a powerful ally when we are optimizing the performance of a SQL query. Let’s see some ways in which we can take advantage of this clause:
WHERE clause is good but not enough. We have to be careful where we place the clause. Filtering out as many rows as possible early in the WHERE clause can help us optimize the query.WHERE clause. When we apply a function to a column, the database has to apply that function to every row in the table before it can filter the results. This prevents the database from using indexes effectively.For example, instead of:
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;We should use:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= is generally faster than LIKE, and using specific date ranges is faster than using functions like MONTH(order_date).So, for example, instead of performing this query:
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;We can perform the following:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';In some cases, we are writing a query and feel we need to dynamically perform some filtering, aggregation, or joins of data. We don’t want to do several queries; instead, we want to keep it to a single query.
For those cases, we can use subqueries. Subqueries in SQL are queries nested inside another query, typically in the SELECT, INSERT, UPDATE, or DELETE statements.
Subqueries can be powerful and fast, but they can also cause performance issues if they are not used carefully. As a rule, we should minimize the use of subqueries and follow a set of best practices:
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;When working with subqueries, we often need to check if a value exists in a set of results. We can do this with two IN or EXISTS, but EXISTS is generally more efficient, especially for larger datasets.
The IN clause reads the entire subquery result set into memory before comparing. On the other hand, the EXISTS clause stops processing the subquery as soon as it finds a match.
Here we have an example of how to use this clause:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Imagine that we are working on an analysis for sending a promotional offer to customers from unique cities. The database has multiple orders from the same customers. The first thing that pops into our mind is using the DISTINCT clause.
This function is handy for certain cases but can be resource-intensive, especially on large datasets. There are a few alternatives to DISTINCT:
GROUP BY instead of DISTINCT when possible. GROUP BY can be more efficient, especially when combined with aggregate functions. So, instead of performing:
SELECT DISTINCT city FROM customers;We can use:
SELECT city FROM customers GROUP BY city;ROW_NUMBER can help us identify duplicates and filter them out without using DISTINCT.When working with data, we interact with it using SQL through a Database Management System (DBMS). The DBMS processes the SQL commands, manages the database, and ensures data integrity and security. Different database systems offer unique features that can help optimize queries.
Database hints are special instructions we can add to our queries to execute a query more efficiently. They are a helpful tool, but they should be used with caution.
For example, in MySQL, the USE INDEX hint can force the use of a specific index:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;In SQL Server, the OPTION (LOOP JOIN) hint specifies the join method:
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); These hints override the default query optimization, improving performance in specific scenarios.
On the other hand, partitioning and sharding are two techniques for distributing data in the cloud.
Keeping database statistics up to date is important to ensure that the query optimizer can make informed, accurate decisions regarding the most efficient way to execute queries.
Statistics describe the data distribution in a table (e.g., the number of rows, the frequency of values, and the spread of values across columns), and the optimizer relies on this information to estimate query execution costs. If statistics are outdated, the optimizer may choose inefficient execution plans, such as using the wrong indexes or opting for a full table scan instead of a more efficient index scan, leading to poor query performance.
Databases often support automatic updates to maintain accurate statistics. For instance, in SQL Server, the default configuration automatically updates statistics when a significant amount of data changes. Similarly, PostgreSQL has an auto-analyze feature, which updates statistics after a specified threshold of data modification.
However, we can manually update statistics in cases where automatic updates are insufficient or if manual intervention is needed. In SQL Server, we can use the UPDATE STATISTICS command to refresh the statistics for a specific table or index, while in PostgreSQL, the ANALYZE command can be run to update statistics for one or more tables.
-- Update statistics for all tables in the current database
ANALYZE;
-- Update statistics for a specific table
ANALYZE my_table;A stored procedure is a set of SQL commands we save in our database so we don’t have to write the same SQL repeatedly. We can think of it as a reusable script.
When we need to perform a certain task, like updating records or calculating values, we just call the stored procedure. It can take input, do some work, such as querying or modifying data, and even return a result. Stored procedures help speed things up since the SQL is precompiled, making your code cleaner and easier to manage.
We can create a stored procedure in PostgreSQL as follows:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');As data practitioners, we like to have our data ordered and grouped so we can gain insights more easily. We usually use ORDER BY and GROUP BY in our SQL queries.
However, both clauses can be computationally expensive, especially when dealing with large datasets. When sorting or aggregating data, the database engine must often perform a full scan of the data and then organize it, identify the groups, and/or apply aggregate functions, typically using resource-intensive algorithms.
To optimize the queries, we can follow some of these tips:
ORDER BY when necessary. If sorting is not essential, omitting this clause can help us dramatically reduce processing time. ORDER BY and GROUP BY are indexed. GROUP BY, we could pre-aggregate the data at an earlier stage or in a materialized view, so the database doesn’t need to compute the same aggregates repeatedly.When we want to combine results from multiple queries into one list, we can use the UNION and UNION ALL clauses. Both combine the results of two or more SELECT statements when they have the same column names. However, they are not the same, and their difference makes them suitable for different use cases.
The UNION clause removes duplicate rows, which requires more processing time.
Figure: Union in SQL. Image source: DataCamp SQL-Join cheat sheet.
On the other hand, UNION ALL combines the results but keeps all rows, including duplicates. So, if we don't need to remove duplicates, we should use UNION ALL for better performance.
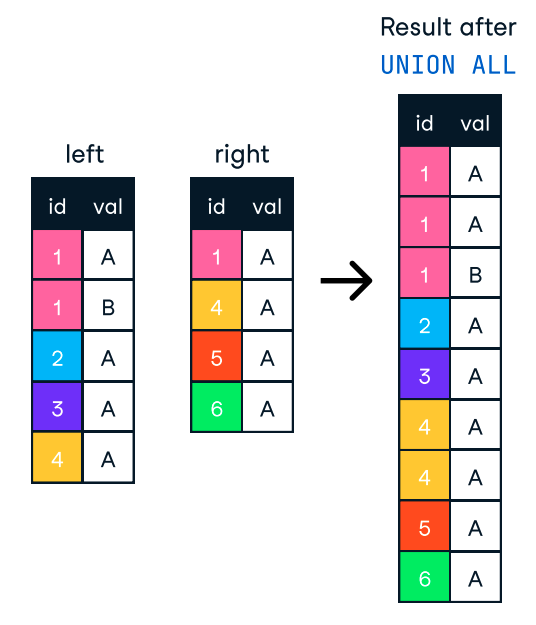
Figure: UNION ALL in SQL. Image source: DataCamp SQL-Join cheat sheet.
-- Potentially slower
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potentially faster
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Working with large datasets implies that we'll often encounter complex queries that are difficult to understand and optimize. We can try to tackle these cases by breaking them down into smaller, simpler queries. In this way, we can easily identify performance bottlenecks and apply optimization techniques.
One of the most frequently used strategies to break down queries is materialized views. These are precomputed and stored query results that can be accessed quickly rather than recalculating the query each time it’s referenced. When the underlying data changes, the materialized view must be manually or automatically refreshed.
Here’s an example of how to create and query a materialized view:
-- Create a materialized view
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Query the materialized view
SELECT * FROM daily_sales;In this article, we have explored various strategies and best practices for optimizing SQL queries, from indexing and joins to subqueries and database-specific features. By applying these techniques, you can significantly improve the performance of your queries and make our databases run more efficiently.
Remember, optimizing SQL queries is an ongoing process. As your data grows and your application evolves, you'll need to continually monitor and optimize your queries to ensure they're running at optimal performance.
To further enhance your understanding of SQL, we encourage you to explore the following resources on DataCamp:
Learn more about SQL with these courses!
Course
Course
Course
Tutorial
Karlijn Willems
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Allan Ouko
code-along
Kelsey McNeillie