Curso
Machine learning con modelos basados en árboles en Python
5 h
116.4K
El machine learning supervisado es un tipo de machine learning que aprende la relación entre la entrada y la salida. Las entradas se conocen como características o "variables X" y la salida suele denominarse objetivo o "variable Y". El tipo de datos que contiene tanto las características como el objetivo son los datos etiquetados. Es la diferencia clave entre el machine learning supervisado y el no supervisado, dos tipos destacados de machine learning. En este tutorial aprenderás:
El machine learning supervisado aprende patrones y relaciones entre los datos de entrada y de salida. Se define por el uso de datos etiquetados. Los datos etiquetados son un conjunto de datos que contiene muchos ejemplos de características y objetivo. El aprendizaje supervisado utiliza algoritmos que aprenden la relación de las características y el objetivo a partir del conjunto de datos. Este proceso se denomina entrenamiento o ajuste.
Hay dos tipos de algoritmos de aprendizaje supervisado:
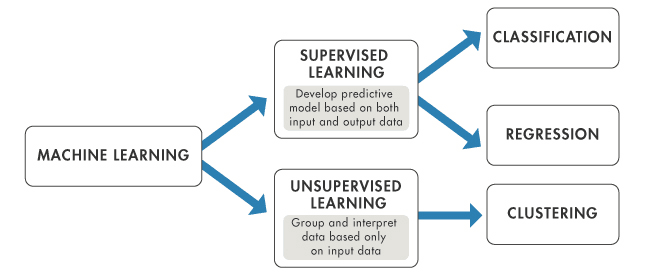
Fuente de la imagen: https://www.mathworks.com/help/stats/machine-learning-in-matlab.html
La clasificación es un tipo de machine learning supervisado en el que los algoritmos aprenden de los datos para prever un resultado o evento en el futuro. Por ejemplo:
Un banco puede tener un conjunto de datos de clientes que contenga su historial crediticio, préstamos, datos de inversión, etc., y puede querer saber si algún cliente no va a pagar. En los datos históricos, tendremos características y objetivo.
Los algoritmos de clasificación se utilizan para prever resultados discretos. Si el resultado tiene dos valores posibles, como verdadero o falso, predeterminado o no predeterminado o sí o no, hablamos de clasificación binaria. Cuando el resultado contiene más de dos valores posibles, hablamos de clasificación multiclase. Hay muchos algoritmos de machine learning que pueden utilizarse para tareas de clasificación. Algunos son:
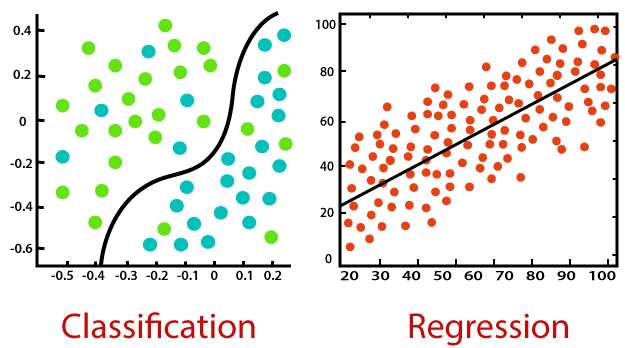
La regresión es un tipo de machine learning supervisado en el que los algoritmos aprenden de los datos para prever valores continuos como las ventas, el salario, el peso o la temperatura. Por ejemplo:
Dado un conjunto de datos que contenga características de la casa como el tamaño del solar, el número de dormitorios, el número de cuartos de baño, el barrio, etc., y el precio de la casa, se puede entrenar un algoritmo de regresión para aprender la relación entre las características y el precio de la casa.
Hay muchos algoritmos de machine learning que pueden utilizarse para tareas de regresión. Algunos son:
Fuente de la imagen: https://static.javatpoint.com/tutorial/machine-learning/images/regression-vs-classification-in-machine-learning.png
La principal diferencia entre el machine learning no supervisado y el supervisado es que el aprendizaje supervisado utiliza datos etiquetados. Los datos etiquetados son datos que contienen tanto las características (variables X) como el objetivo (variable Y).
Cuando se utiliza el aprendizaje supervisado, el algoritmo aprende iterativamente a prever la variable objetivo dadas las características y se modifica para obtener la respuesta adecuada con el fin de "aprender" del conjunto de datos de entrenamiento. Este proceso se denomina entrenamiento o ajuste. Los modelos de aprendizaje supervisado suelen producir resultados más precisos que los del aprendizaje no supervisado, pero requieren interacción humana al principio para identificar correctamente los datos. Si las etiquetas del conjunto de datos no se identifican correctamente, los algoritmos supervisados aprenderán detalles erróneos.
Los modelos de aprendizaje no supervisado, en cambio, trabajan de forma autónoma para identificar la estructura innata de los datos que no se han etiquetado. Es importante tener en cuenta que la validación de las variables de salida sigue requiriendo cierto nivel de participación humana. Por ejemplo, un modelo de aprendizaje no supervisado puede determinar que los clientes que compran por Internet tienden a comprar varios artículos de la misma categoría al mismo tiempo. Sin embargo, un analista humano tendría que comprobar que tiene sentido que un motor de recomendación empareje el artículo X con el artículo Y.
Hay dos casos de uso destacados para el aprendizaje supervisado: la clasificación y la regresión. En ambas tareas, un algoritmo supervisado aprende de los datos de entrenamiento para prever algo. Si la variable prevista es discreta, como "Sí" o "No", 1 o 0, "Fraude" o "No fraude", se requiere un algoritmo de clasificación. Si la variable prevista es continua, como las ventas, el coste, el salario, la temperatura, etc., se requiere el algoritmo de regresión.
El clustering y la detección de anomalías son dos casos de uso destacados en el aprendizaje no supervisado. Para saber más sobre clustering, consulta este artículo. Si quieres profundizar en el machine learning no supervisado, consulta este interesante curso de DataCamp. Aprende a agrupar en clústeres, transformar, visualizar y extraer información de conjuntos de datos no etiquetados utilizando scikit-learn y scipy.
El objetivo del aprendizaje supervisado es prever resultados de nuevos datos en función de un modelo que ha aprendido de un conjunto de datos de entrenamiento etiquetados. El tipo de resultados que puedes esperar se conocen de antemano en forma de datos etiquetados. El objetivo de un algoritmo de aprendizaje no supervisado es obtener información a partir de grandes cantidades de datos sin etiquetas explícitas. Los algoritmos no supervisados también aprenden del conjunto de datos de entrenamiento, pero los datos de entrenamiento no contienen etiquetas.
El machine learning supervisado es más sencillo que el aprendizaje no supervisado. Los modelos de aprendizaje no supervisado suelen requerir un gran conjunto de entrenamiento para producir los resultados deseados, lo que los hace computacionalmente complejos.
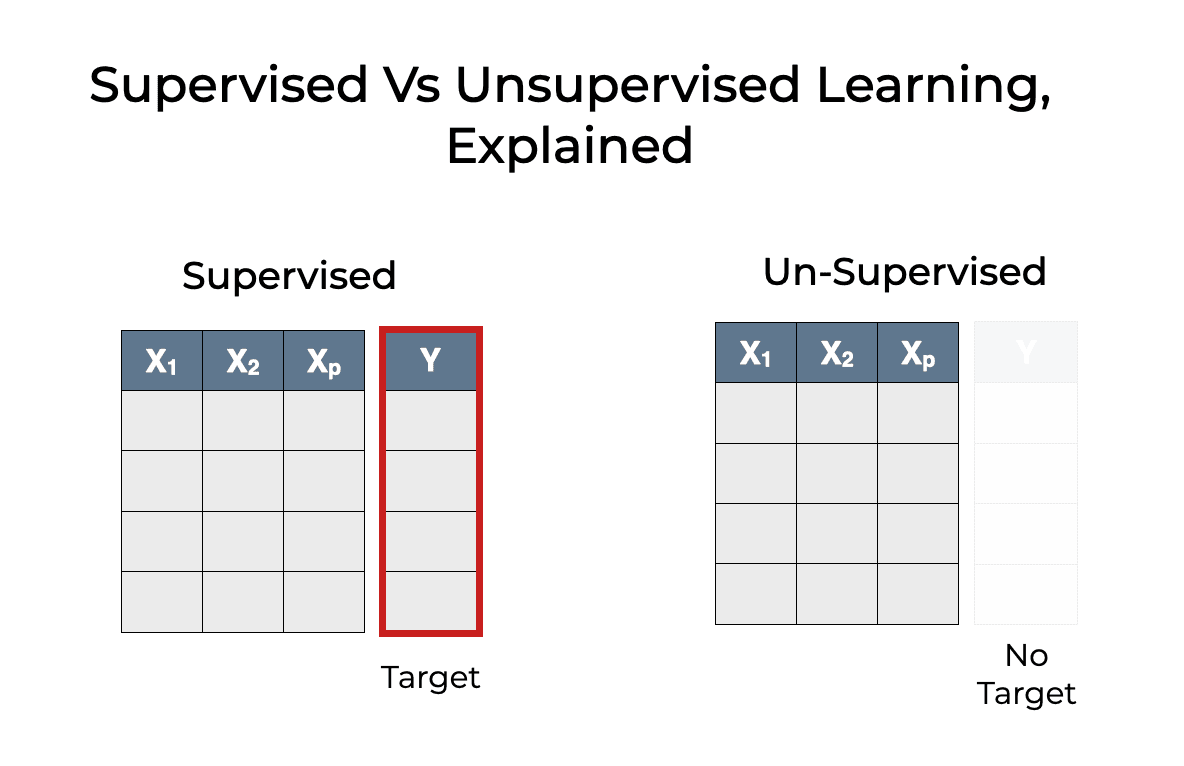
Fuente de la imagen: https://www.sharpsightlabs.com/blog/supervised-vs-unsupervised-learning/
El aprendizaje semisupervisado es un tipo de machine learning relativamente nuevo y menos popular que, durante el entrenamiento, mezcla una cantidad considerable de datos no etiquetados con una pequeña cantidad de datos etiquetados. El aprendizaje semisupervisado está entre el aprendizaje supervisado (con datos de entrenamiento etiquetados) y el aprendizaje no supervisado (datos de entrenamiento no etiquetados).
El aprendizaje semisupervisado ofrece muchas aplicaciones en el mundo real. Hay escasez de datos etiquetados en muchos campos. Debido a que requieren anotadores humanos, equipos especializados o estudios costosos y que requieren mucho tiempo, las etiquetas (variable objetivo) podrían ser difíciles de obtener.
El aprendizaje semisupervisado es de dos tipos:
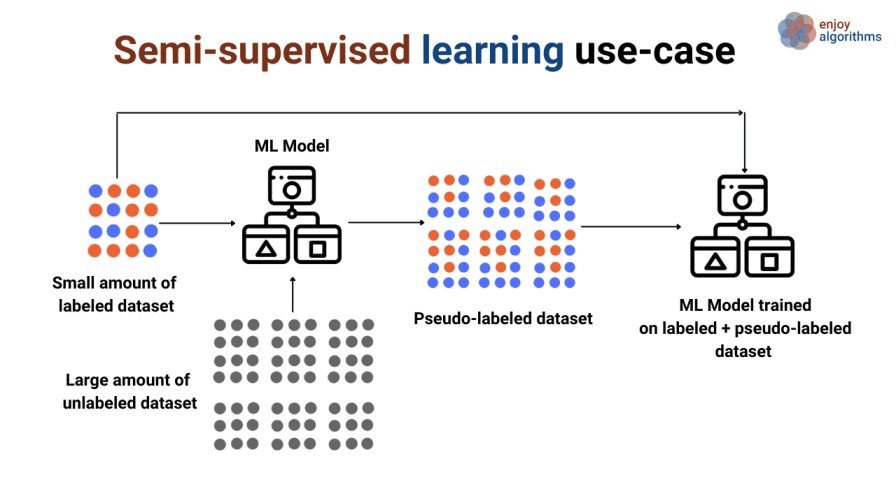
Fuente de la imagen: https://www.enjoyalgorithms.com/blogs/supervised-unsupervised-and-semisupervised-learning
En esta sección trataremos algunos algoritmos comunes para el machine learning supervisado:
La regresión lineal es uno de los algoritmos de machine learning más sencillos que existen, se utiliza para aprender a prever un valor continuo (variable dependiente) en función de las características (variable independiente) del conjunto de datos de entrenamiento. En el valor de la variable dependiente, que representa el efecto, influyen los cambios del valor de la variable independiente.
Si recuerdas la "recta de mejor ajuste" de la escuela, eso es exactamente la regresión lineal. Prever el peso de una persona en función de su altura es un ejemplo sencillo de este concepto.
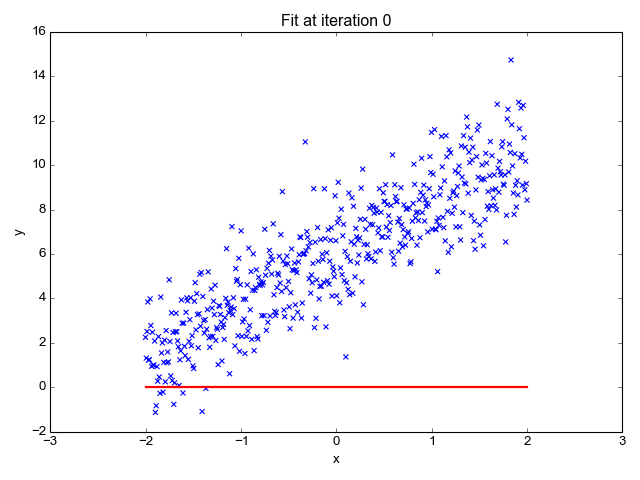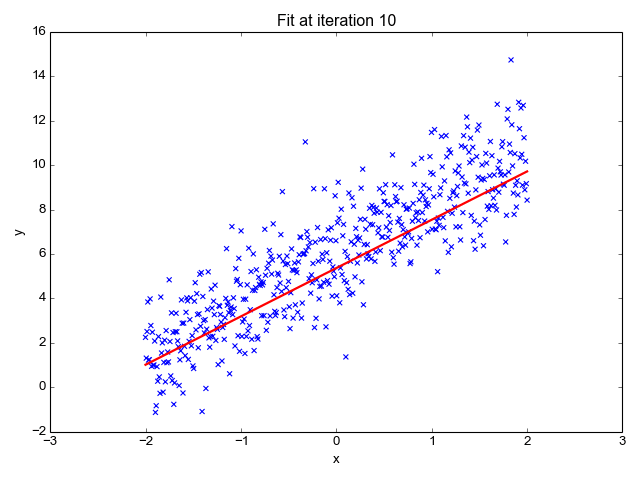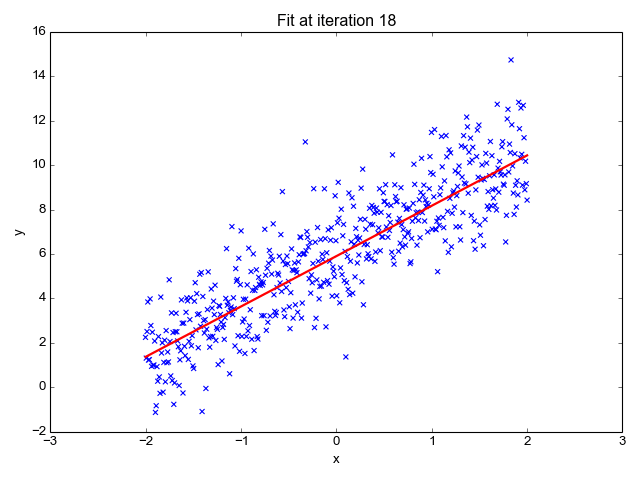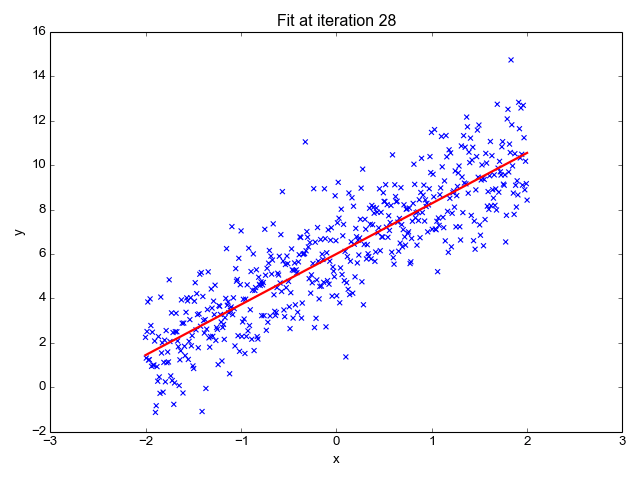
Fuente de la imagen: http://primo.ai/index.php?title=Linear_Regression
|
PROS |
CONTRAS |
|
Sencillo, fácil de entender e interpretar |
Fácil de sobreajustar |
|
Funciona excepcionalmente bien con datos linealmente separables |
Supone linealidad entre las características y la variable objetivo. |
La regresión logística es un caso especial de regresión lineal en el que la variable objetivo (Y) es discreta/categórica, como 1 o 0, verdadero o falso, sí o no o predeterminado o no predeterminado. Como variable dependiente se utiliza un logaritmo de las probabilidades. Utilizando una función logit, la regresión logística hace previsiones sobre la probabilidad de que se produzca un evento binario.
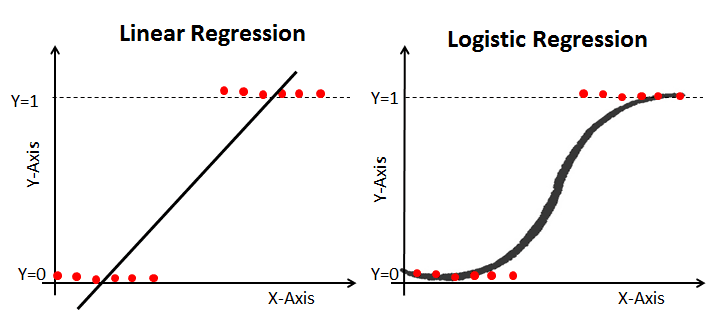
Para saber más sobre este tema, consulta este excelente artículo del tutorial Comprender la regresión logística en Python en DataCamp.
|
PROS |
CONTRAS |
|
Sencillo, fácil de entender e interpretar |
Sobreajuste |
|
Bien calibrado para las probabilidades de salida |
Dificultades para captar relaciones complejas |
Los algoritmos de árbol de decisión son un tipo de modelo estructural similar a un árbol de probabilidad que separa continuamente los datos para categorizarlos o hacer previsiones en función de los resultados del conjunto anterior de preguntas. El modelo analiza los datos y proporciona respuestas a las preguntas para ayudarte a tomar decisiones más informadas.
Podrías, por ejemplo, utilizar un árbol de decisión en el que las respuestas Sí o No se utilizaran para seleccionar una determinada especie de ave en función de elementos de datos como las plumas del ave, su capacidad para volar o nadar, el tipo de pico que tiene, etc.
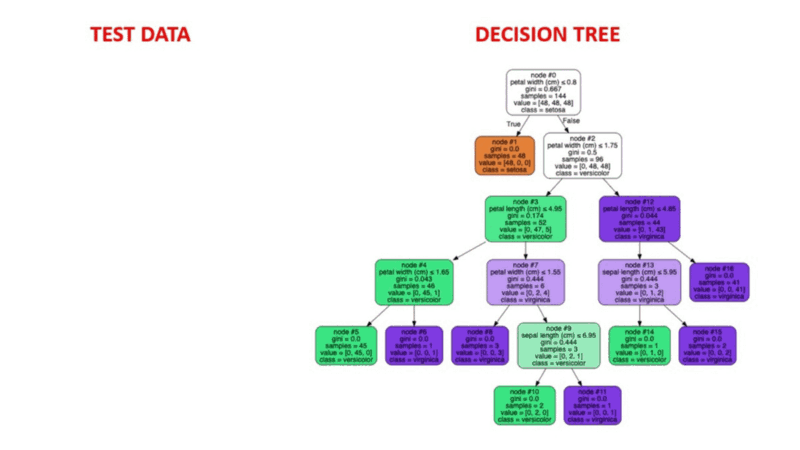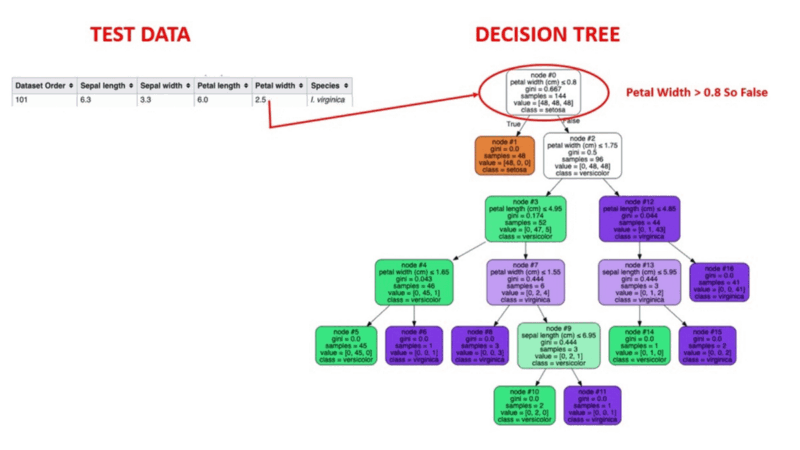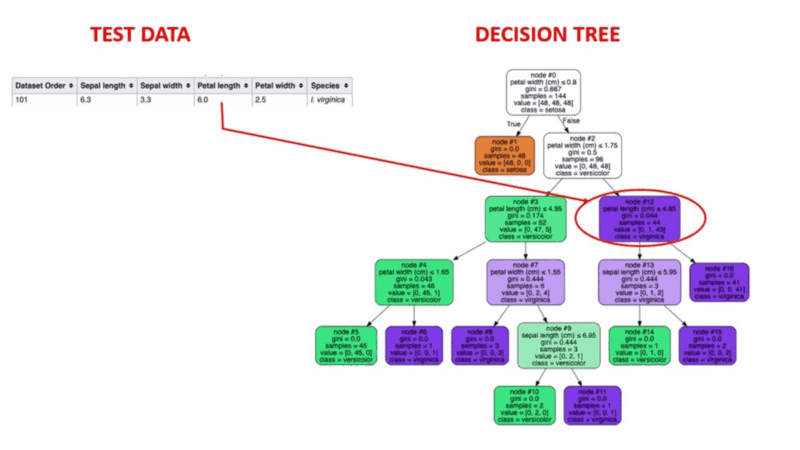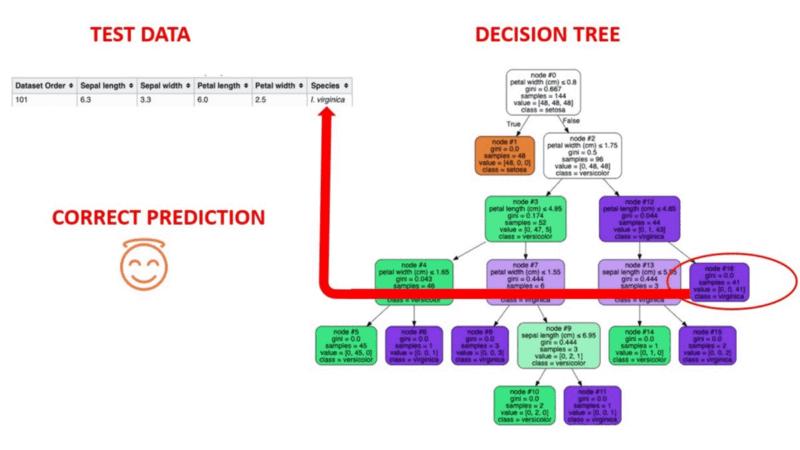
Fuente de la imagen: https://aigraduate.com/decision-tree-visualisation---quick-ml-tutorial-for-beginners/
|
PROS |
CONTRAS |
|
Muy intuitivo y fácil de explicar |
Inestable: un pequeño cambio en los datos de entrenamiento puede provocar enormes diferencias en la previsión. |
|
Los árboles de decisión no requieren mucha preparación de los datos, como algunos modelos lineales. |
Propenso al sobreajuste |
Para aprender más sobre machine learning con modelos basados en árboles en Python, consulta este interesante curso de DataCamp. En este curso, aprenderás a utilizar modelos basados en árboles y combinaciones para regresión y clasificación utilizando scikit-learn.
K vecinos más próximos es un método estadístico que evalúa la proximidad de un punto de datos a otro punto de datos para decidir si los dos puntos de datos pueden agruparse o no. La proximidad de los puntos de datos representa el grado en que son comparables entre sí.
Por ejemplo, supongamos que tenemos un gráfico con dos grupos distintos de puntos de datos muy próximos entre sí y denominados Grupo A y Grupo B, respectivamente. Cada uno de estos grupos de puntos de datos estaría representado por un punto en el gráfico. Cuando añadimos un nuevo punto de datos, el grupo de esa instancia dependerá del grupo al que esté más próximo el nuevo punto.
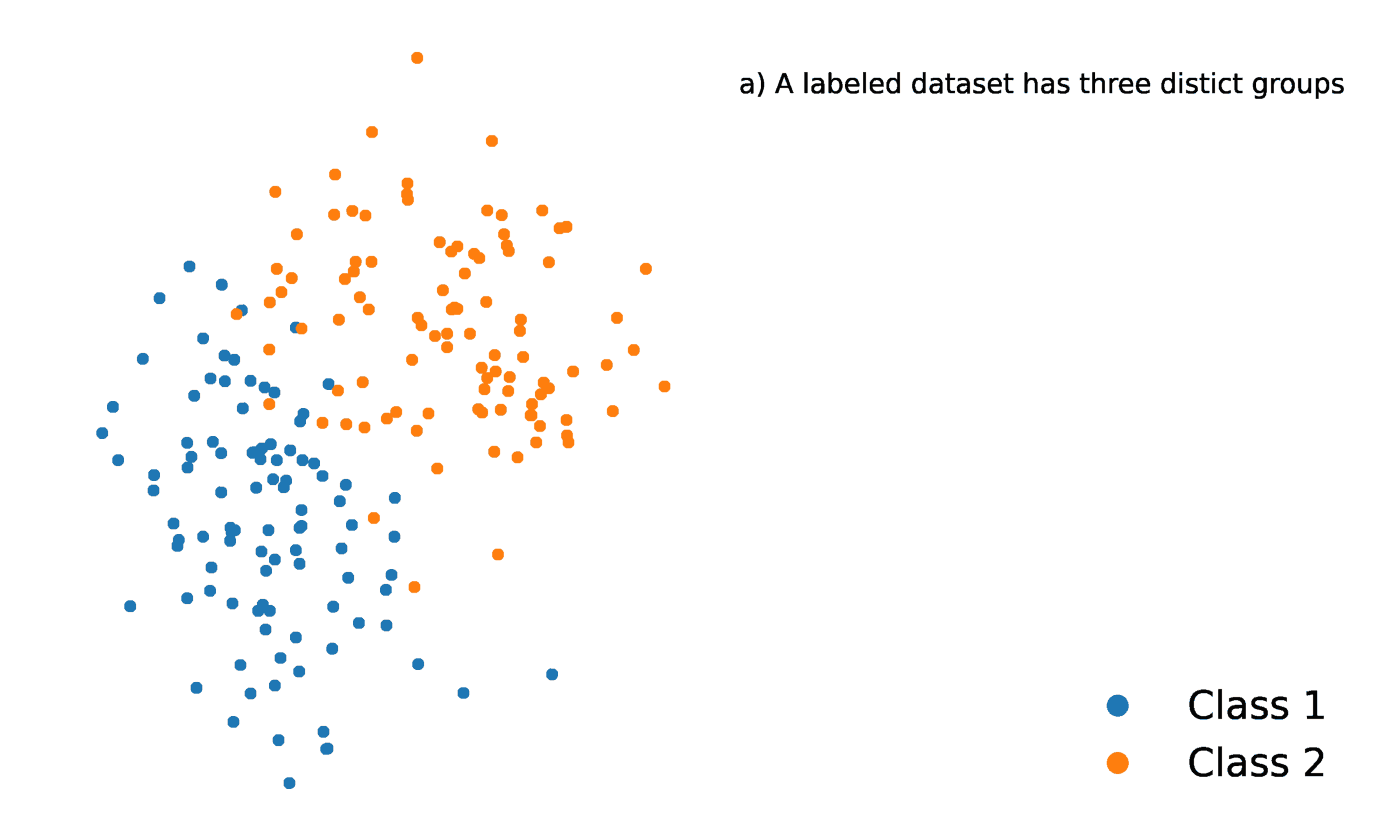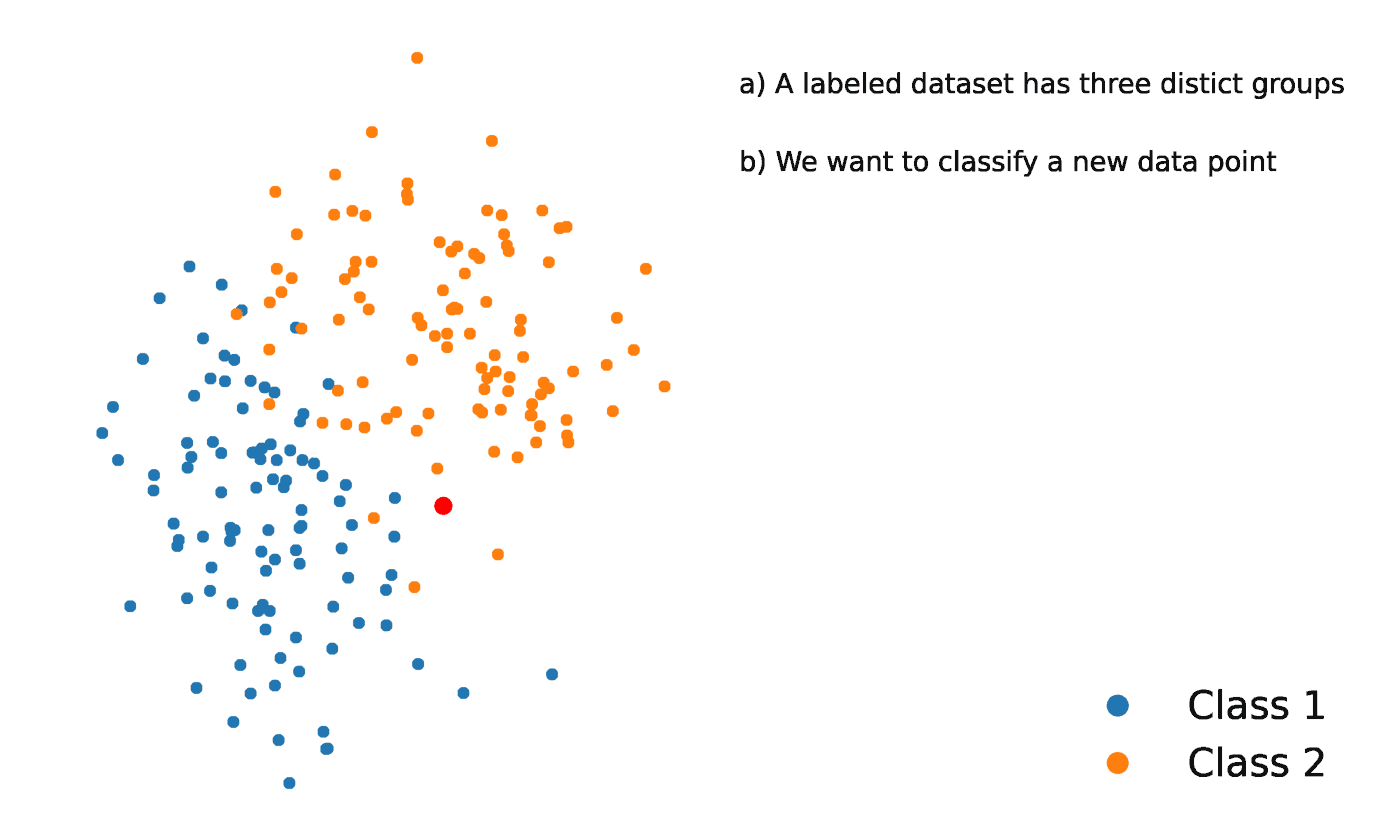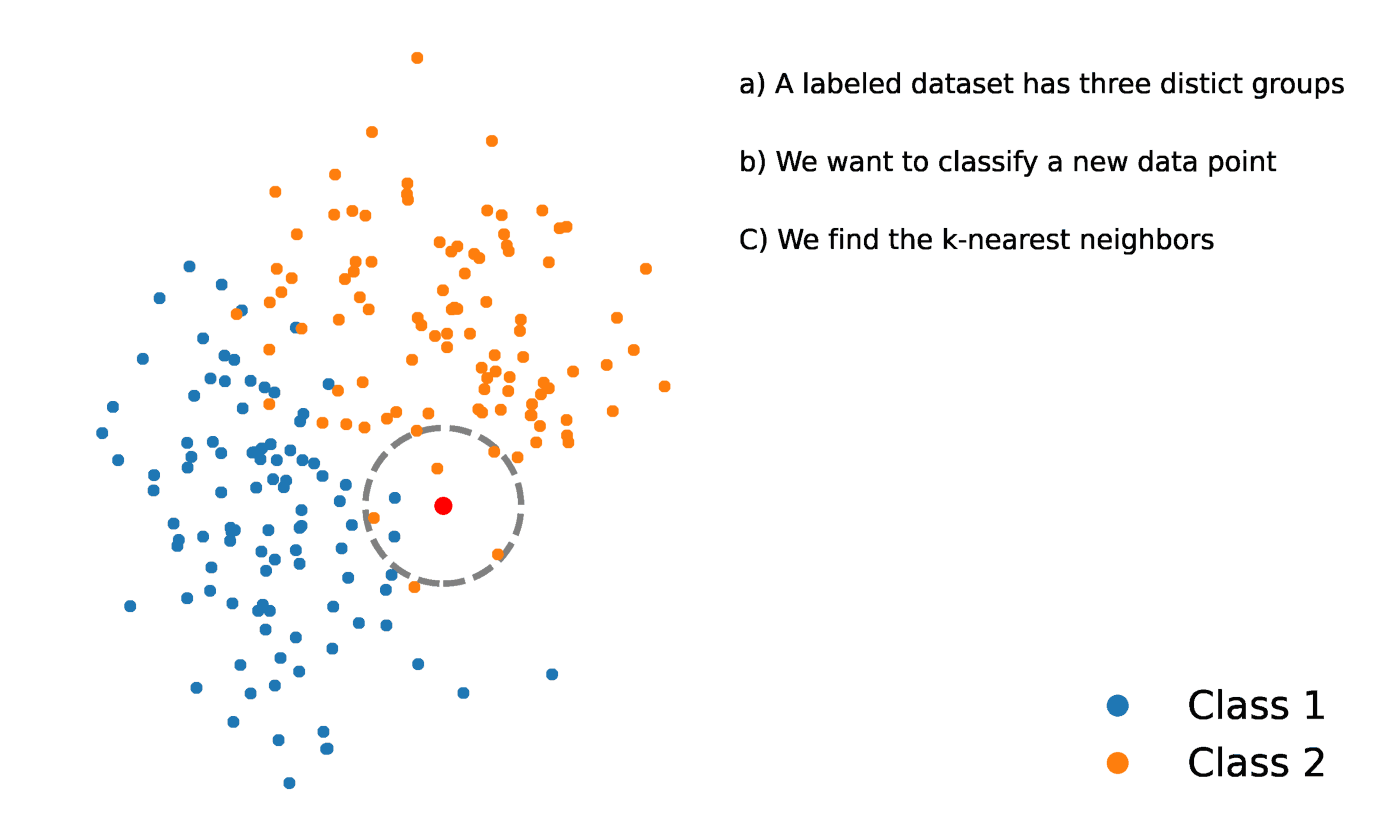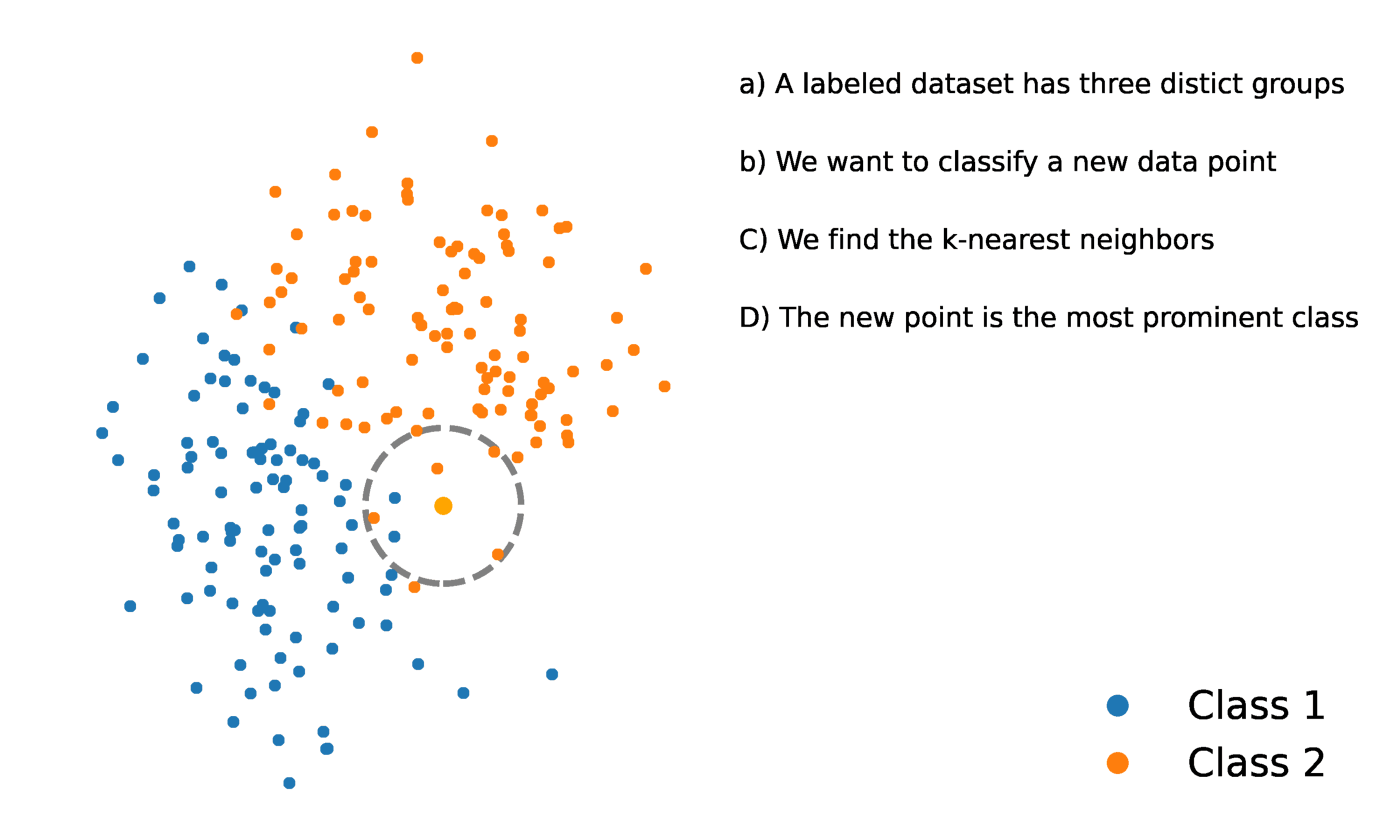
Fuente: https://towardsdatascience.com/getting-acquainted-with-k-nearest-neighbors-ba0a9ecf354f
|
PROS |
CONTRAS |
|
No hace suposiciones sobre los datos |
El entrenamiento lleva mucho tiempo |
|
Intuitivo y sencillo |
KNN funciona bien con un número reducido de características, pero, cuando aumenta el número de características, le cuesta prever con precisión. |
El bosque aleatorio es otro ejemplo de algoritmo basado en árboles, como los árboles de decisión. A diferencia del árbol de decisión, que solo tiene un árbol, el bosque aleatorio usa una serie de árboles de decisión para emitir juicios, creando lo que es esencialmente un bosque de árboles.
Lo hace combinando una serie de modelos diferentes para producir previsiones, y puede utilizarse tanto para la clasificación como para la regresión.
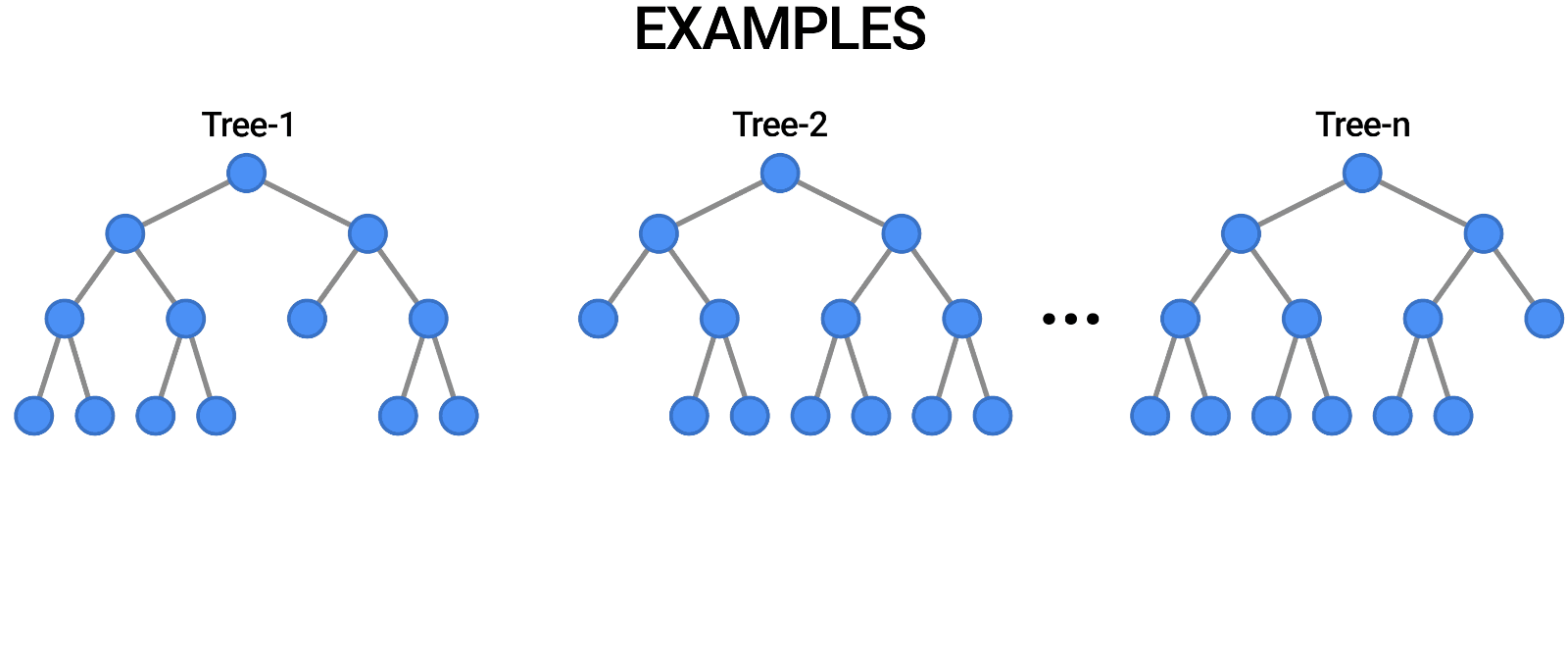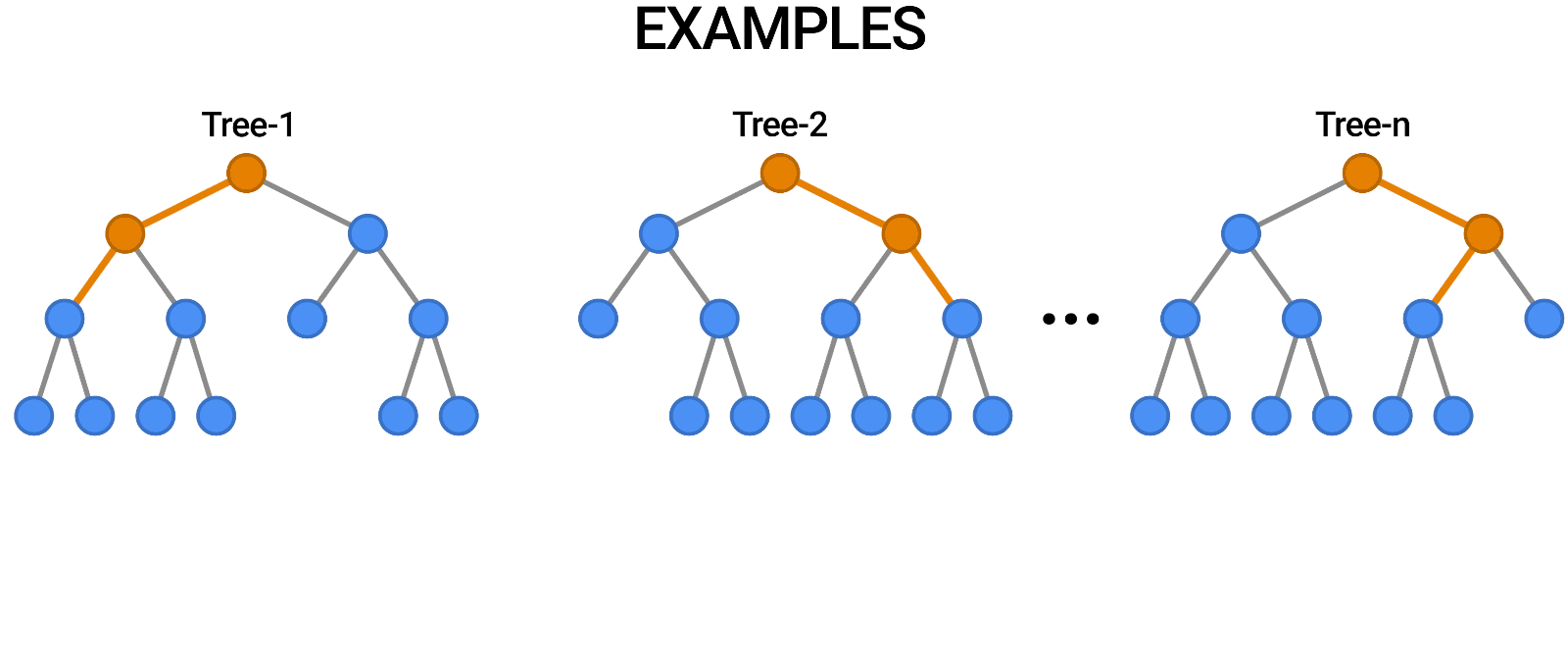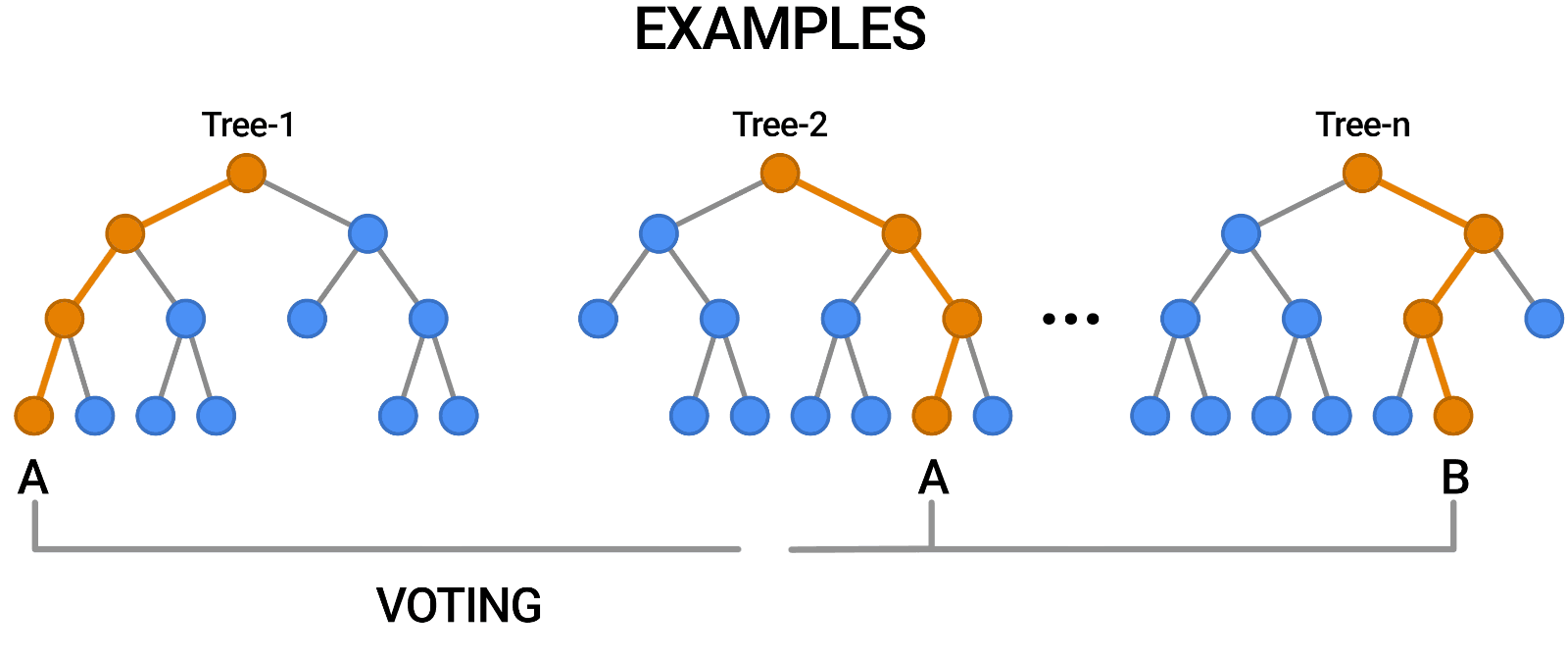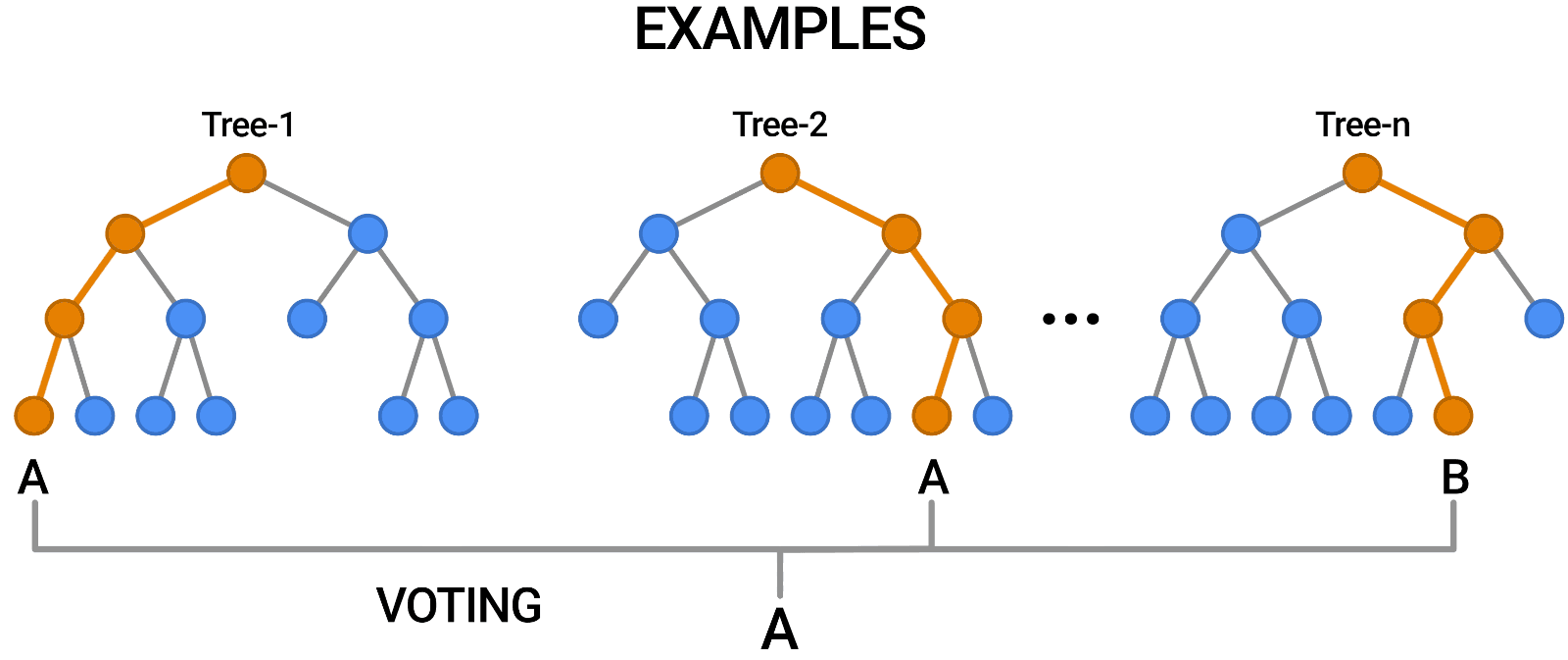
Fuente: https://blog.tensorflow.org/2021/05/introducing-tensorflow-decision-forests.html
|
PROS |
CONTRAS |
|
Los bosques aleatorios pueden manejar fácilmente relaciones no lineales en los datos. |
Difícil de interpretar debido a los múltiples árboles. |
|
Los bosques aleatorios realizan implícitamente la selección de características |
Los bosques aleatorios son costosos computacionalmente para grandes conjuntos de datos. |
El teorema de Bayes es una fórmula matemática que se utiliza para calcular probabilidades condicionales, e Ingenuo Bayes es una aplicación de esa fórmula. La probabilidad de que se produzca un resultado si ya se ha producido otro evento se denomina probabilidad condicionada.
Realiza la previsión de que las probabilidades para cada clase pertenecen a una clase específica y de que la clase con mayor probabilidad es la que se considera la clase que tiene más probabilidades de ocurrir.
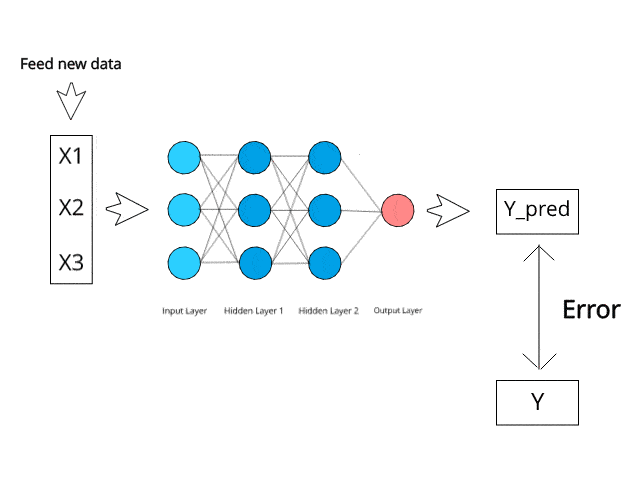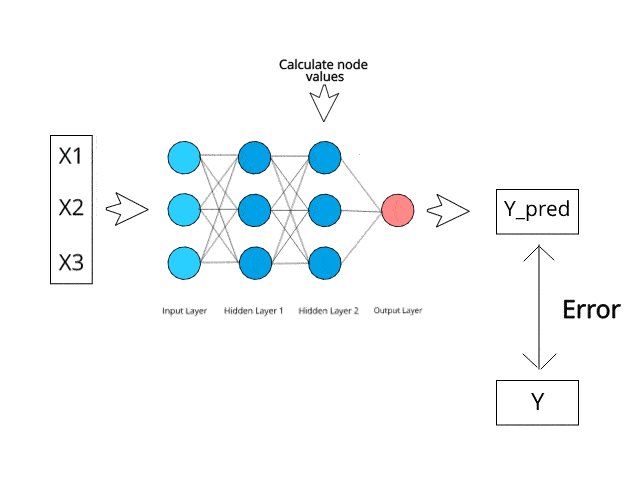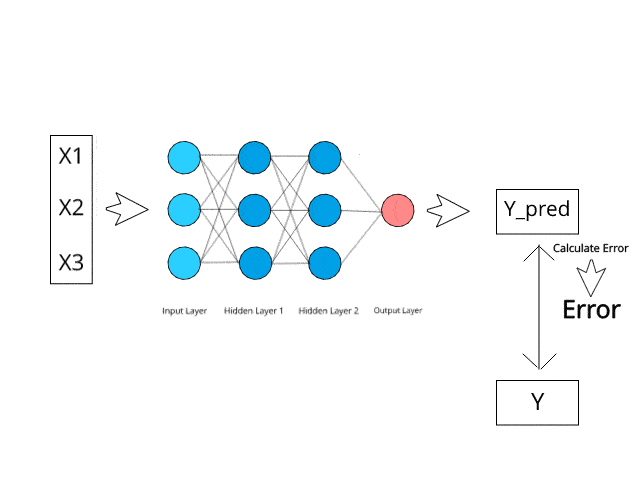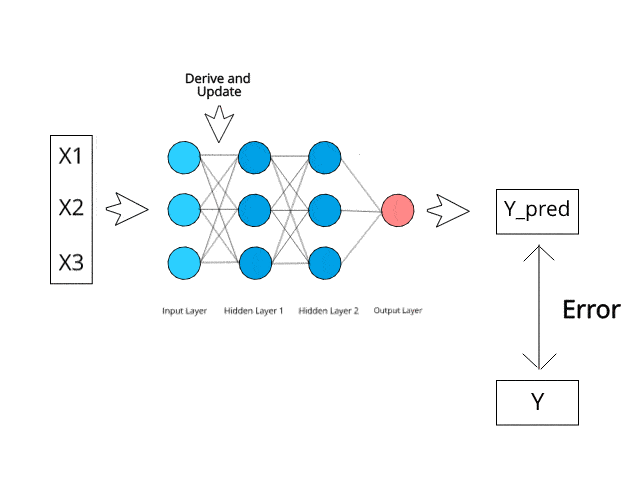
Fuente de la imagen: https://www.kdnuggets.com/2019/10/introduction-artificial-neural-networks.html
|
PROS |
CONTRAS |
|
El algoritmo es muy rápido. |
Supone que todas las características son independientes. |
|
Es sencillo y fácil de implementar |
El algoritmo se encuentra con el "problema de frecuencia cero", en el que da una variable categórica con probabilidad cero si su categoría no estaba presente en el conjunto de datos de entrenamiento. |
En esta parte utilizaremos scikit-learn en Python para entrenar un modelo de regresión logística (clasificación) con un conjunto de datos falso. Consulta el cuaderno completo aquí.
```
# create fake binary classification dataset with 1000 rows and 10 features
from sklearn.datasets import make_classification
X, y = make_classification(n_samples = 1000, n_features = 10, n_classes = 2)
# check shape of X and y
X.shape, y.shape
# train test split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# import and initialize logistic regression model
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
# fit logistic regression model
lr.fit(X_train, y_train)
# generate hard predictions on test set
y_pred = lr.predict(X_test)
y_pred
# evaluate accuracy score of the model
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
```Si quieres aprender machine learning supervisado en R, consulta el curso Aprendizaje supervisado en R de DataCamp. En este curso aprenderás los fundamentos del machine learning para la clasificación en el lenguaje de programación R.
El machine learning ha cambiado por completo nuestra forma de hacer negocios en los últimos años. Una innovación radical que diferencia al machine learning de otras estrategias de automatización es el abandono de la programación basada en reglas. Los ingenieros pueden utilizar datos sin entrenar explícitamente a los equipos para que resuelvan los problemas de una determinada manera, gracias a las técnicas de machine learning supervisado.
En el machine learning supervisado, la solución esperada a un problema puede no conocerse para los datos futuros, pero puede conocerse y capturarse en un conjunto de datos históricos, y el trabajo de los algoritmos de aprendizaje supervisado es aprender esa relación a partir de los datos históricos para prever un resultado, un evento o un valor en el futuro.
En este artículo, hemos explicado los fundamentos del aprendizaje supervisado y su diferencia con el aprendizaje no supervisado. También hemos revisado un par de algoritmos habituales en el aprendizaje supervisado. Sin embargo, hay muchas cosas de las que no hemos hablado, como la evaluación de modelos, la validación cruzada o el ajuste de hiperparámetros. Si quieres profundizar en alguno de estos temas y desarrollar aún más tus habilidades, consulta estos interesantes cursos:
Cursos de machine learning
Curso
Curso
Curso
blog
Zoumana Keita
14 min
blog
Kurtis Pykes
9 min
blog
Matt Crabtree
14 min
blog
Natassha Selvaraj
15 min
blog
DataCamp Team
11 min
Tutorial
Avinash Navlani

