Course
Machine Learning with Tree-Based Models in Python
5 hr
116.8K
Machine learning is arguably responsible for data science and artificial intelligence’s most prominent and visible use cases. From Tesla’s self-driving cars to DeepMind’s AlphaFold algorithm, machine-learning-based solutions have produced awe-inspiring results and generated considerable hype. In 2026, classic algorithms like gradient boosting and random forests still power most tabular predictions in finance and marketing, while self-supervised deep learning underpins large language models and generative AI. But what exactly is machine learning? How does it work? And most importantly, is it worth the hype? This article provides an intuitive definition of key machine-learning algorithms, outlines their most common use cases, and points you to resources for getting started with machine learning.
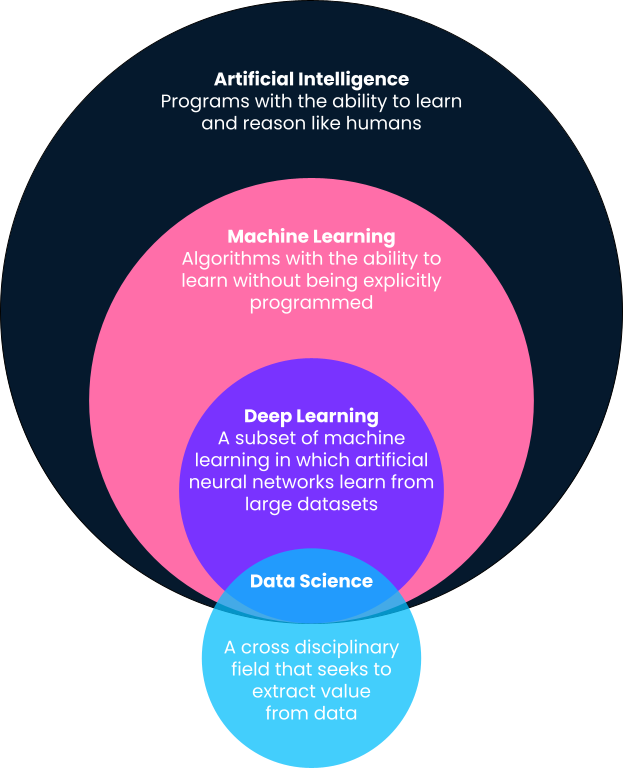
In a nutshell, machine learning is a sub-field of artificial intelligence in which computers provide predictions based on patterns learned directly from data without being explicitly programmed to do so. You’ll notice in this definition that machine learning is a sub-field of artificial intelligence. As such, let’s break definitions down into more detail, as oftentimes, terms such as machine learning, artificial intelligence, deep learning, and even data science are used interchangeably.
One of the best definitions of artificial intelligence comes from Andrew Ng, co-founder of Google Brain and former Chief Scientist at Baidu. According to Andrew, artificial intelligence is a “huge set of tools of making computers behave intelligently.” This can include anything ranging from explicitly defined systems like calculators to machine learning-based solutions like spam email detectors.
As outlined above, machine learning is a subfield of artificial intelligence in which algorithms learn patterns from historical data and provide predictions based on these learned patterns by applying them to new data. Traditionally, simple, intelligent systems like calculators are explicitly programmed by developers as clearly defined steps and procedures (i.e., if this, then that). However, this isn’t scalable or possible for more advanced problems.
Let’s take the example of email spam filters. Developers can try and create spam filters by explicitly defining them. For example, they can define a program that triggers a spam filter if an email has a certain subject line or contains certain links. However, this system will prove ineffective as soon as spammers change tactics.
On the other hand, a machine learning-based solution will take in millions of spam emails as input data, learn the most common characteristics of spammy emails through statistical association, and make predictions on future emails based on the learned characteristics.
Deep learning is a subfield of machine learning and is probably responsible for popular culture's most visible machine learning use cases. Deep learning algorithms are inspired by the structure of the human brain and require incredible amounts of data for training. They are often used for the most complex “cognitive” problems, such as speech detection, language translation, self-driving cars, and more. Check out our comparison of deep learning vs machine learning for more context.
In contrast to machine learning, artificial intelligence, and deep learning, data science has quite a broad definition. In a nutshell, data science is all about extracting value and insights from data. That value could be in the form of predictive models that use machine learning, but it could also mean surfacing insights with a dashboard or report. Read more about the daily tasks of data scientists in this article.
Outside of email spam detection, some commonly known machine learning applications include customer segmentation based on demographic data (sales and marketing), stock price prediction (finance), claims approval automation (insurance), content recommendations based on viewing history (media & entertainment), and much more. Machine learning has become ubiquitous and finds varied applications in our day-to-day lives.
At the end of this article, we will share many resources to get you started with machine learning.
Now that we’ve given an overview of machine learning and where it fits within other buzzwords you may encounter in this space, let’s take a deeper look into the different types of machine learning algorithms. Machine learning algorithms are broadly categorized into supervised, unsupervised, reinforcement, and self-supervised learning. Let us understand them in greater detail and their most common use cases.
Most machine learning use cases revolve around algorithms learning patterns from historical data and applying them to new data in the form of predictions. This is often referred to as supervised learning. Supervised learning algorithms are shown both historical inputs and outputs on a particular problem we’re trying to solve, where inputs are essentially features or dimensions of the observation we’re trying to predict, and where outputs are the outcomes we want to predict. Let’s illustrate this with our spam detection example.
In the spam detection use case, a supervised learning algorithm would be trained on a dataset of spammy emails. The inputs would be features or dimensions about the emails, such as the email subject line, the sender's email address, the contents of the email, whether the email contained dangerous-looking links, and other relevant information that could give clues about whether an email is spammy.
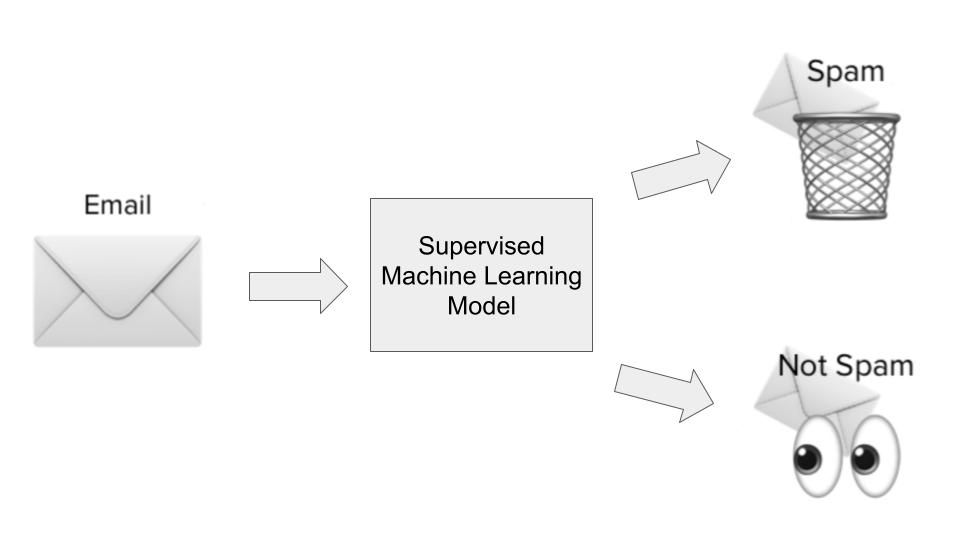
The output would be whether, in fact, that email was spam or not. During the model learning phase, the algorithm learns a function to map the statistical relationship between the set of input variables (the different dimensions of spammy email) and the output variable (whether it was spam or not). This functional mapping is then used to predict the output of the previously unseen data.
There are broadly two types of supervised learning use cases:
In an upcoming section, we’ll look into specific supervised learning algorithms and some of their use cases in more detail.
Instead of learning patterns that map inputs to outputs, unsupervised learning algorithms discover general patterns in data without being explicitly shown outputs. Unsupervised learning algorithms are commonly used to group and cluster different objects and entities. A great example of unsupervised learning is customer segmentation. Companies often have a variety of customer personas that they serve. Organizations often want to have a fact-based approach to identifying their customer segments to serve them better. Enter unsupervised learning.
In this use case, an unsupervised learning algorithm would learn group customers based on various attributes, such as the number of times they used a product, their demographics, how they interact with products, and more. Then, the same algorithm can predict which likely segment new customers belong to based on the same dimensions.
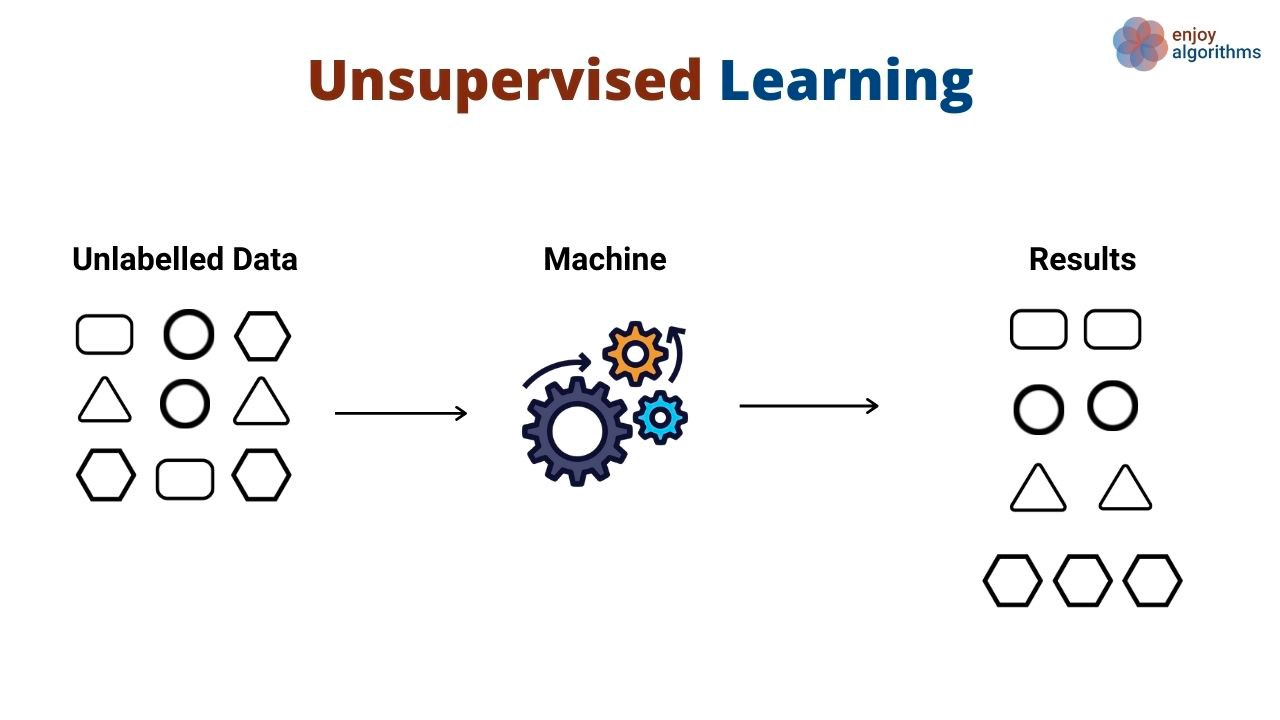
Unsupervised algorithms are also used to reduce the dimensions in a dataset (i.e., the number of features) by using dimensionality reduction techniques. These algorithms are often used as an intermediary step in training a supervised learning algorithm.
A big tradeoff data scientists often face when training machine learning algorithms is performance vs. predictive accuracy. Generally, the more information they have about a particular problem, the better. However, that could also lead to slow training times and performance. Dimensionality reduction techniques help reduce the number of features present within a dataset without sacrificing predictive value.
Reinforcement learning is a subset of machine learning algorithms that utilize rewards to promote a desired behavior or prediction and a penalty otherwise. Once confined to research labs, reinforcement learning now powers production systems, from game-playing agents that exceed human-level performance in Chess and Go to recommendation engines, robotics, and LLM alignment techniques like RLHF (reinforcement learning from human feedback).
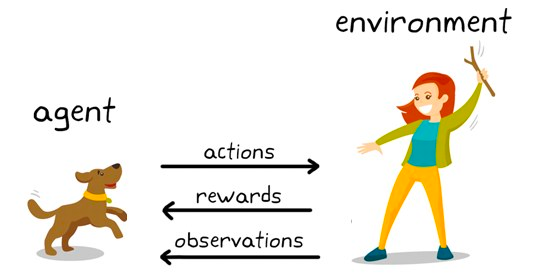
It is a behavioral modeling technique where the model learns through a trial-and-error mechanism as it keeps interacting with the environment. Let’s illustrate that with the chess example. At a high level, a reinforcement learning algorithm (often named agent) is provided an environment (chess board) where it can make a variety of decisions (play moves).
Each move has a set of associated scores, a reward for actions that lead the agent to win, and a penalty for moves that lead the agent to lose.
The agent keeps interacting with the environment to learn the actions that reap the most rewards and keeps repeating those actions. This repetition of promoted behavior is called the exploitation phase. When the agent looks for new avenues to earn rewards, this is called the exploration phase. More generally, this is referred to as the exploration-exploitation paradigm.
Self-supervised learning is a data-efficient machine learning technique where the model learns from an unlabeled sample dataset. As shown in the example below, the first model is fed some unlabelled input images, which are clustered by it using features generated from these images.
Some of these examples would have a high confidence of belonging to the clusters while others don’t. The second step uses the high-confidence labeled data from the first step to train a classifier that tends to be more powerful than a one-step clustering approach.
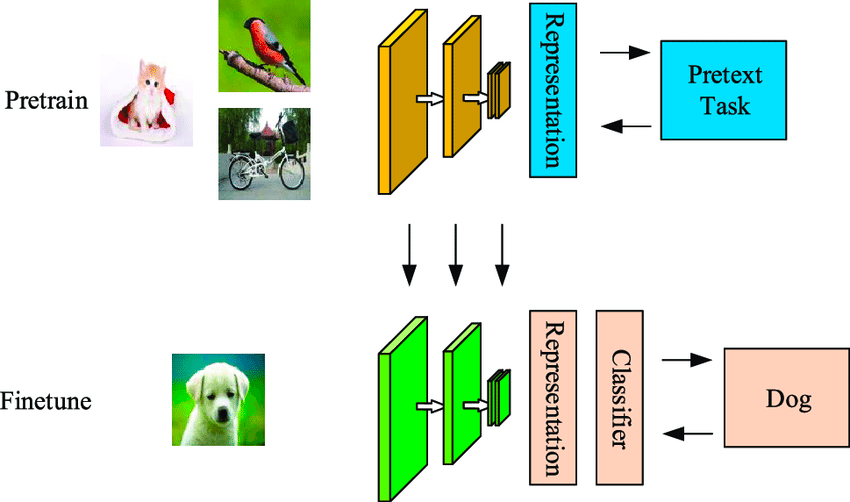
The difference between self-supervised and supervised algorithms is that the classified output in the former still won’t have the classes mapped to real objects. It differs from supervised learning as it does not depend on the manually labeled set and generates labels by itself, hence the name self-learning.
Self-supervised learning is also the foundation of modern large language models (LLMs). Models like GPT and Llama are pre-trained on vast unlabeled text by predicting masked tokens or next words—a self-supervised objective that learns rich language representations before fine-tuning on labeled tasks.
Below, we’ve outlined some of the top machine learning algorithms and their most common use cases.
A simple algorithm models a linear relationship between one or more explanatory variables and a continuous numerical output variable. It is faster to train as compared to other machine learning algorithms. Its biggest advantage lies in its ability to explain and interpret the model predictions. It is a regression algorithm used to predict outcomes like customer lifecycle value, housing prices, and stock prices.
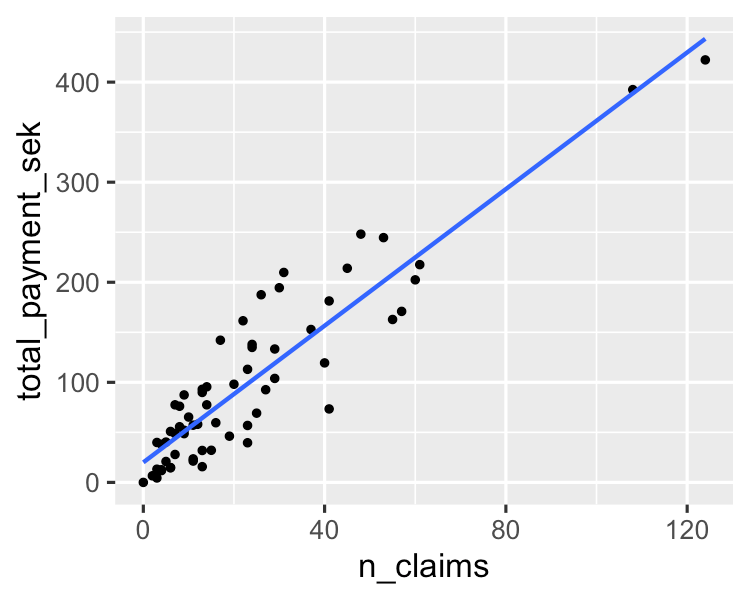
You can learn more about it in this essentials of linear regression in Python tutorial. If you are interested in getting hands-on with regression analysis, this much sought-after course on DataCamp is the right resource for you.
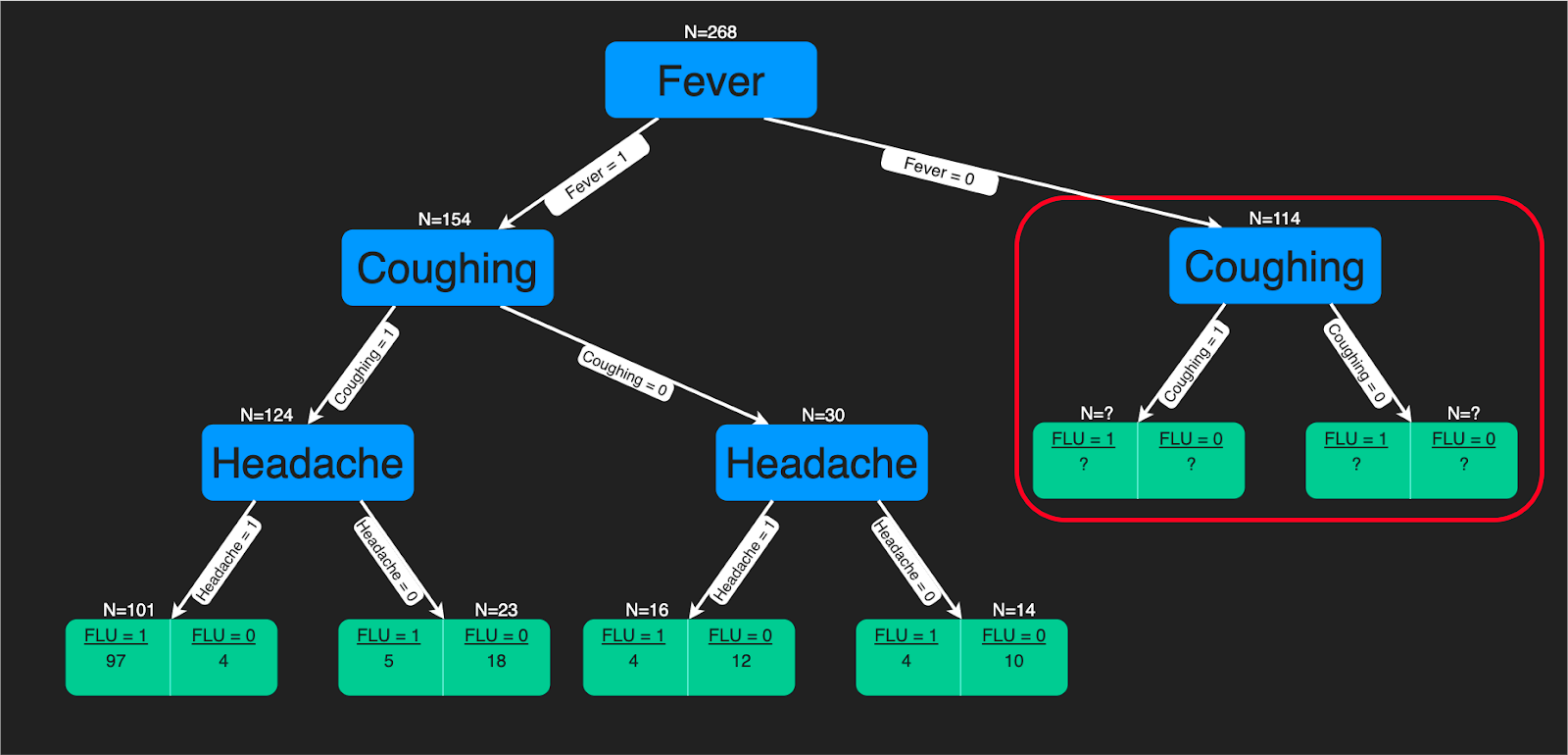
A decision tree algorithm is a tree-like structure of decision rules that are applied to the input features to predict the possible outcomes. It can be used for classification or regression. Decision tree predictions provide a good aid for healthcare experts as it is straightforward to interpret how those predictions are made.
You can refer to this tutorial if you are interested in learning how to build a decision tree classifier using Python. Further, if you are more comfortable using R, then you will benefit from this tutorial. There is also a comprehensive decision trees course on DataCamp.
It is arguably one of the most popular algorithms and builds upon the drawbacks of overfitting prominently seen in the decision tree models. Overfitting is when algorithms are trained on the training data a bit too well, and where they fail to generalize or provide accurate predictions on unseen data. Random forest solves the problem of overfitting by building multiple decision trees on randomly selected samples from the data. The final outcome in the form of the best prediction is derived from the majority voting of all the trees in the forest.
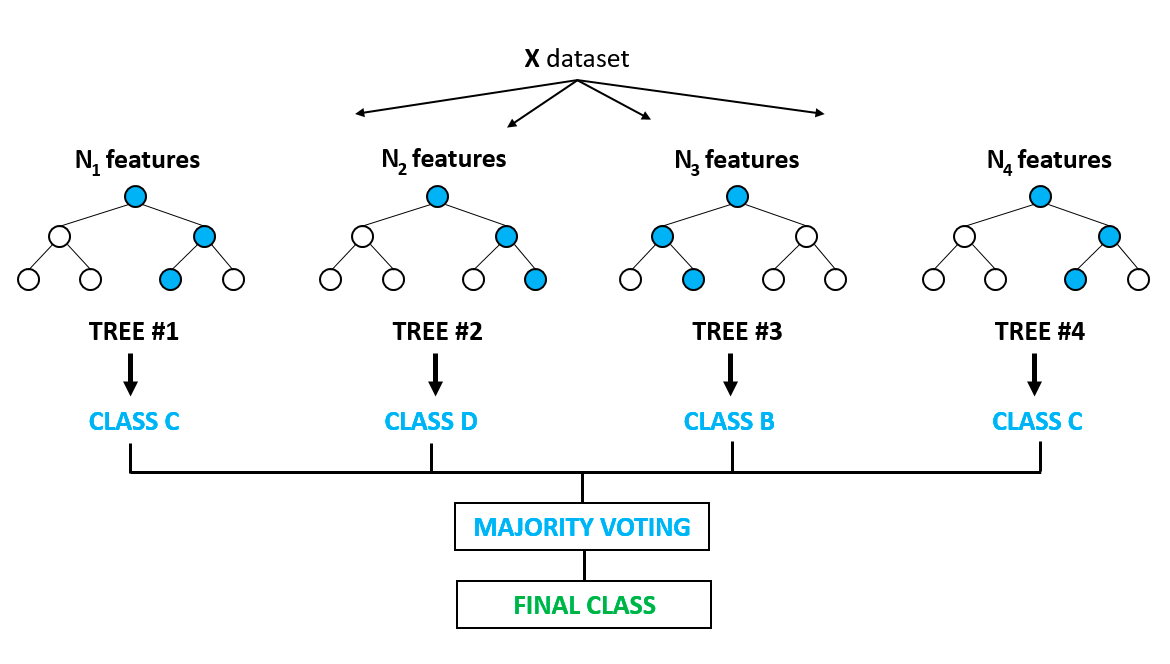
It is used for classification and regression problems both. It finds application in feature selection, disease detection, etc. You can learn more about tree-based models and ensembles (combining different individual models) from this very popular course on DataCamp. You can also learn more in this Python-based tutorial on implementing the random forest model.
Support Vector Machines, commonly known as SVM, are generally used for classification problems. As shown in the example below, an SVM finds a hyperplane (line in this case), which segregates the two classes (red and green) and maximizes the margin (distance between the dotted lines) between them.
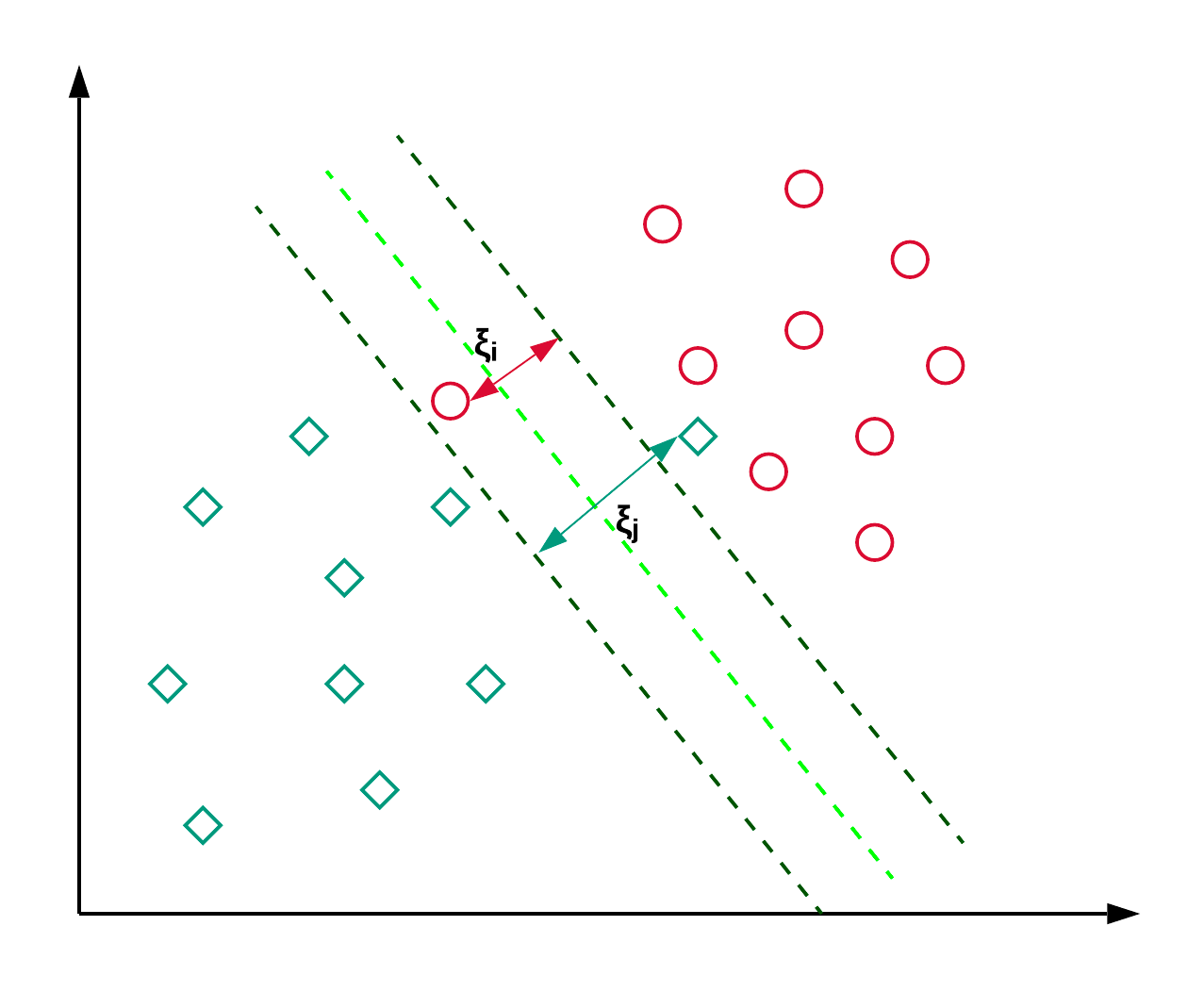
SVM is generally used for classification problems but can also be employed in regression problems. It is used to classify news articles and handwriting recognition. You can read more about the different types of kernel tricks along with the python implementation in this scikit-learn SVM tutorial. You can also follow this tutorial, where you’ll replicate the SVM implementation in R
Gradient Boosting Regression is an ensemble model that combines several weak learners to make a robust predictive model. It is good at handling non-linearities in the data and multicollinearity issues.
While the core idea is gradient boosting, modern implementations have largely superseded the generic regressor in practice:</i
These algorithms consistently rank among the top performers for tabular prediction tasks in 2026. Learn the fundamentals in our gradient boosting guide and get hands-on with XGBoost in Python.

If you are in a ride sharing business and need to predict the ride fare amount, then you can use a gradient boosting regressor. If you want to understand the different flavors of gradient boosting, then you can watchthis video on DataCamp.
K-Means is the most widely used clustering approach—it determines K clusters based on Euclidean distance. It is a very popular algorithm for customer segmentation and recommendation systems.
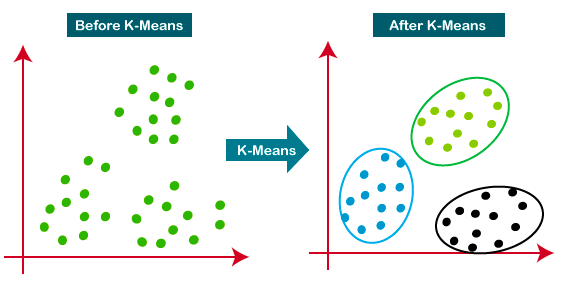
This tutorial is a great resource for learning more about K-means clustering.
Principal component analysis (PCA) is a statistical procedure that is used to summarize the information from a large data set by projecting it to a lower dimensional subspace. It is also called a dimensionality reduction technique that ensures retaining the essential parts of the data with higher information.
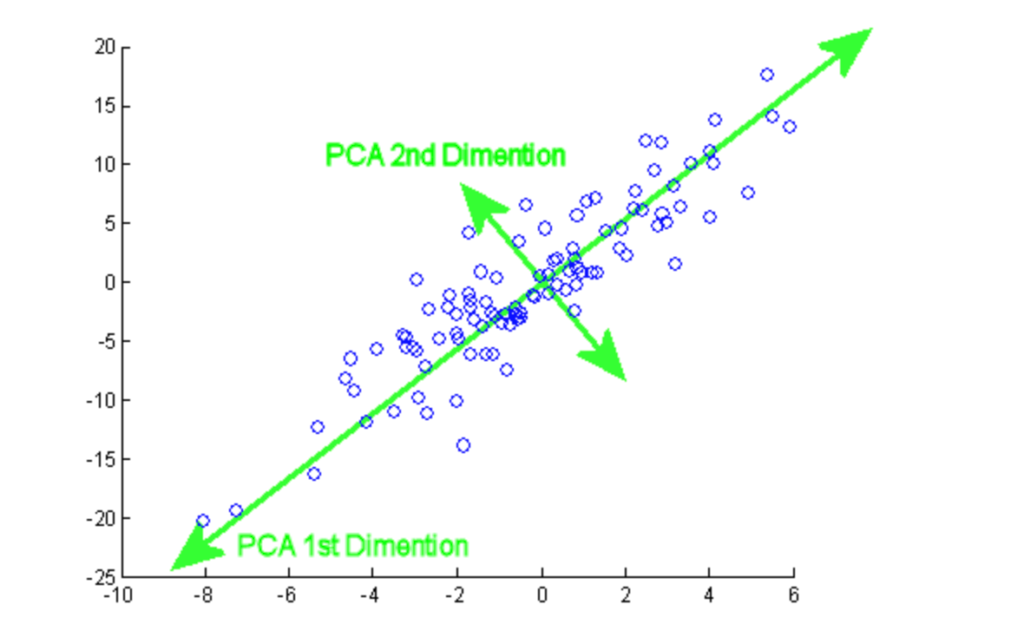
From this tutorial, you can practice hands-on PCA implementation on two popular datasets, Breast Cancer and CIFAR-10.
It is a bottom-up approach where each data point is treated as its own cluster, and then the closest two clusters are merged together iteratively. Its biggest advantage over K-means clustering is that it does not require the user to specify the expected number of clusters at the onset. It finds application in document clustering based on similarity.
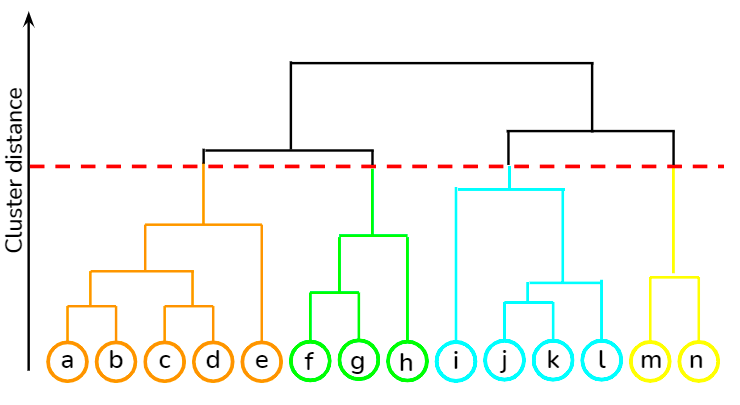
You can learn various unsupervised learning techniques, such as hierarchical clustering and K-means clustering, using the scipy library from this course at DataCamp. Besides, you can also learn how to apply clustering techniques to generate insights from unlabeled data using R from this course.
It is a probabilistic model for modeling normally distributed clusters within a dataset. It is different from the standard clustering algorithms in the sense that it estimates the probability of an observation belonging to a particular cluster and then dives into making inferences about its sub-population.
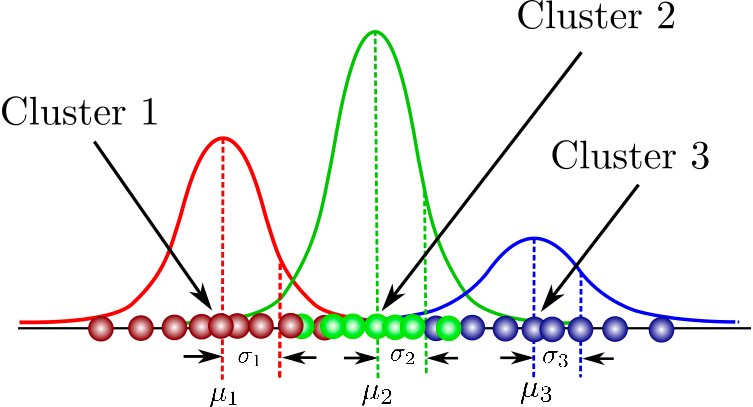
You can find a one-stop collation of courses here that covers fundamental concepts in model-based clustering, the structure of Mixture Models, and beyond. You will also get to practice hands-on gaussian mixture modeling using flexmix package.
A rule-based approach that identifies the most frequent itemset in a given dataset where prior knowledge of frequent itemset properties is used. Market basket analysis employs this algorithm to help behemoths like Amazon and Netflix in translating the heaps of information about their users into simple rules of product recommendations. It analyses the associations between millions of products and uncovers insightful rules.
DataCamp provides a comprehensive course in both the languages—Python and R.
Generative AI and LLMs dominate headlines, but the algorithms in this article remain essential. Here is how they fit together:
| Use case | Best-fit algorithms | Example |
| Tabular prediction (fraud, churn, pricing) | XGBoost, random forests, logistic regression | Credit scoring, customer churn |
| Customer segmentation & clustering | K-means, hierarchical clustering, GMM | Marketing personas, product recommendations |
| Text, image, and speech generation | Deep learning, transformers, self-supervised pre-training | ChatGPT, image generators, speech synthesis |
| Sequential decision-making | Reinforcement learning (Q-learning, PPO, RLHF) | Robotics, game AI, LLM fine-tuning |
Most data teams use both stacks: gradient boosting and random forests for structured business data, and deep learning for unstructured content. Read our guide on deep learning vs. machine learning for a deeper comparison.
Machine learning is not just a buzzword anymore. Many organizations are deploying machine learning models and are already realizing gains from predictive insights. Needless to say, there is a lot of demand for highly-skilled machine learning practitioners in the market.Below, you will find a list of resources to help you upskill in machine learning:
Get started with machine learning
Course
Course
blog
Kurtis Pykes
12 min
blog
Matt Crabtree
14 min
blog
Joyce Chiu
5 min
blog
Javier Canales Luna
9 min
cheat-sheet
Richie Cotton
cheat-sheet
Richie Cotton



