
programa
Científico de datos asociado en Python
90 h
El panorama de la ciencia de datos está creciendo rápidamente y hay muchas herramientas disponibles para ayudar a los científicos de datos en su trabajo. En esta publicación, analizaremos las 10 mejores herramientas de ciencia de datos que podrás utilizar en 2026. Estas herramientas te ayudarán a recopilar, limpiar, procesar, analizar, visualizar y modelar datos. Además, algunas herramientas también ofrecen ecosistemas de machine learning para el seguimiento, el desarrollo, la implementación y la supervisión de modelos.
Las herramientas de ciencia de datos son esenciales para ayudar a los científicos y analistas de datos a extraer información valiosa de los datos. Estas herramientas son útiles para la limpieza, manipulación, visualización y modelado de datos.
Con la llegada de chatGPT, cada vez más herramientas se están integrando con los modelos GPT-3.5 y GPT-4. La integración de herramientas basadas en inteligencia artificial facilita aún más a los científicos de datos el análisis de datos y la creación de modelos.
Por ejemplo, las capacidades de IA generativa (PandasAI) han llegado a herramientas más sencillas como pandas, lo que permite a los usuarios obtener resultados escribiendo indicaciones en lenguaje natural. Sin embargo, estas nuevas herramientas aún no se utilizan de forma generalizada entre los profesionales de los datos.
Además, las herramientas de ciencia de datos no se limitan a realizar una sola función. Proporcionan capacidades adicionales para realizar tareas avanzadas y, en algunos casos, ofrecen ciencia de datos al ecosistema. Por ejemplo, MLFlow se utiliza principalmente para el seguimiento de modelos. Sin embargo, también se puede utilizar para el registro, la implementación y la inferencia de modelos.
La lista de las 10 mejores herramientas se basa en las siguientes características clave:
En esta reseña, exploraremos herramientas nuevas y consolidadas que se han vuelto esenciales para los científicos de datos en el lugar de trabajo. Estas herramientas comparten varias características comunes: son fácilmente accesibles, fáciles de usar y ofrecen sólidas capacidades para el análisis de datos y machine learning.
Python se utiliza ampliamente para el análisis y procesamiento de datos, así como para machine learning. Su simplicidad y su gran comunidad de programadores lo convierten en una opción muy popular.
Pandas facilita la limpieza, manipulación, análisis y ingeniería de características de datos en Python. Es la biblioteca más utilizada por los profesionales de datos para todo tipo de tareas. Ahora también puedes utilizarlo para la visualización de datos.

Nuestra hoja de referencia sobre pandas te ayudará a dominar esta herramienta de ciencia de datos.
Seaborn es una potente biblioteca de visualización de datos basada en Matplotlib. Incluye una serie de temas predeterminados muy bonitos y bien diseñados, y resulta especialmente útil cuando se trabaja con DataFrame de pandas. Con Seaborn, puedes crear visualizaciones claras y expresivas de forma rápida y sencilla.
Scikit-learn es la biblioteca Python de referencia para machine learning. Esta biblioteca proporciona una interfaz coherente para algoritmos comunes, incluyendo regresión, clasificación, agrupamiento y reducción de dimensionalidad. Está optimizado para ofrecer un gran rendimiento y es muy utilizado por los científicos de datos.
Los proyectos de código abierto han sido fundamentales para el avance del campo de la ciencia de datos. Ofrecen una gran variedad de herramientas y recursos que pueden ayudar a los científicos de datos a trabajar de forma más eficiente y eficaz.
Jupyter Notebooks es una popular aplicación web de código abierto que permite a los científicos de datos crear documentos compartibles que combinan código en vivo, visualizaciones, ecuaciones y explicaciones de texto. Ideal para el análisis exploratorio, la colaboración y la elaboración de informes.
Pytorch es un marco de machine learning muy flexible y de código abierto que se utiliza ampliamente para desarrollar modelos de redes neuronales. Ofrece modularidad y un enorme ecosistema de herramientas para manejar diversos tipos de datos, como texto, audio, visión y datos tabulares. Con la compatibilidad con GPU y TPU, puedes acelerar el entrenamiento de tus modelos hasta 10 veces más rápido.
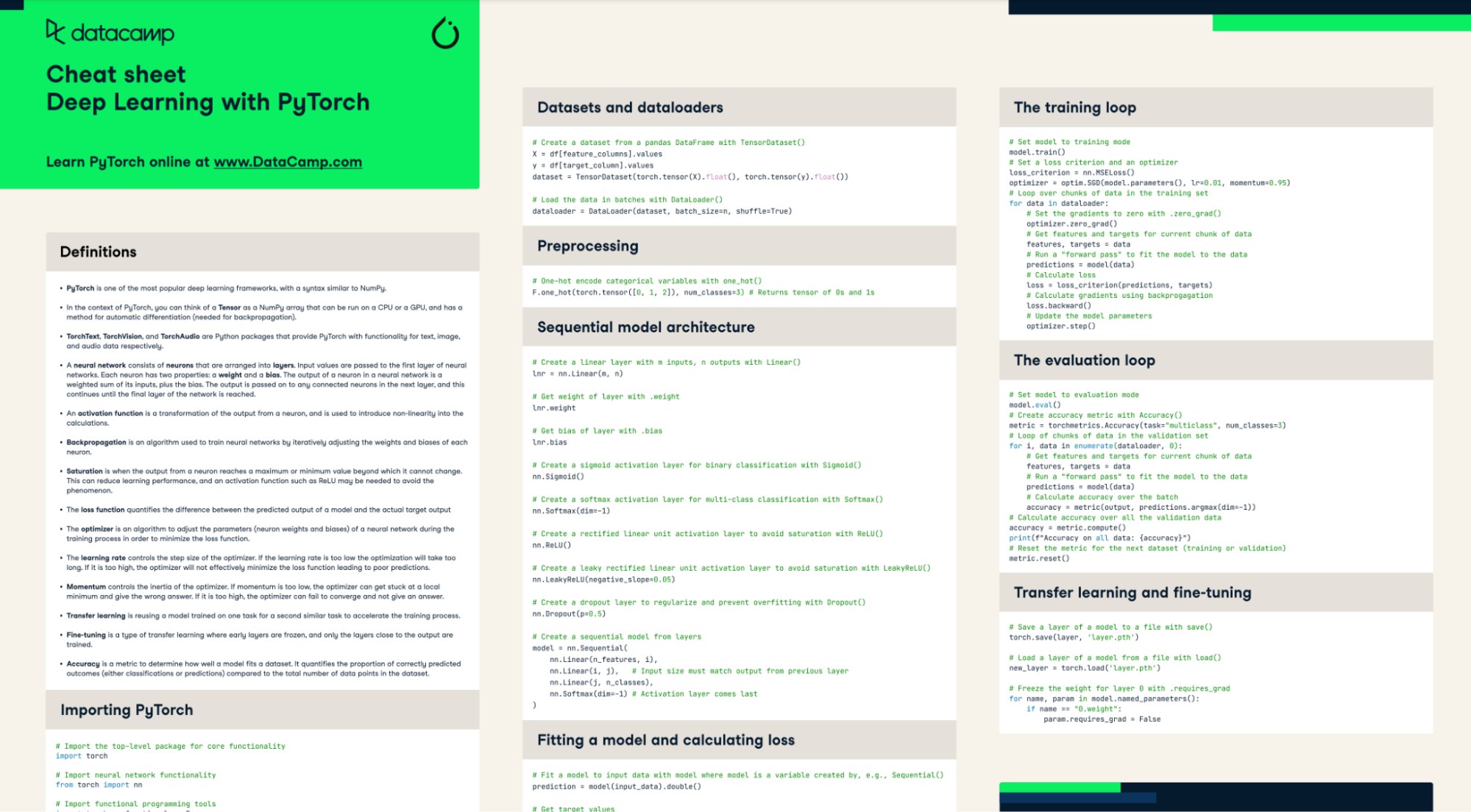
Domina Pytorch con nuestra práctica hoja de referencia
MLFlow es una plataforma de código abierto de Databricks para gestionar el ciclo de vida completo del machine learning. Programa los experimentos, los modelos de paquetes y la implementación en producción, al tiempo que mantiene la reproducibilidad. También es compatible con el programa de LLM y admite tanto la interfaz de línea de comandos como la interfaz gráfica de usuario. También proporciona API para Python, Java, R y Rest.
Hugging Face se ha convertido en una solución integral para el desarrollo de machine learning de código abierto. Proporciona un fácil acceso a conjuntos de datos, modelos de última generación e inferencia, lo que facilita el entrenamiento, la evaluación y la implementación de tus modelos utilizando diversas herramientas del ecosistema Hugging Face. Además, proporciona acceso a GPU de alta gama y soluciones empresariales. Tanto si eres estudiante, investigador o profesional del machine learning, esta es la única plataforma que necesitas para desarrollar soluciones de primera categoría para tus proyectos.
Las robustas plataformas patentadas ofrecen capacidades a escala empresarial, configuración con un solo clic y facilidad de uso. También proporcionan soporte y seguridad para tus datos.
Tableau es líder en software de inteligencia empresarial. Permite visualizaciones de datos y paneles interactivos intuitivos que revelan información valiosa a partir de datos a gran escala. Con Tableau, los usuarios pueden conectarse a una amplia variedad de fuentes de datos, limpiar y preparar los datos para su análisis y, a continuación, generar visualizaciones enriquecidas, como tablas, gráficos y mapas. El software está diseñado para ser fácil de usar, lo que permite a los usuarios sin conocimientos técnicos crear informes y paneles de control con la sencillez de arrastrar y soltar.
RapidMiner es una plataforma de análisis avanzado integral para crear procesos de machine learning y canalizaciones de datos que ofrece un diseñador de flujos de trabajo visual para optimizar el proceso. Desde la preparación de datos hasta la implementación de modelos, RapidMiner proporciona todas las herramientas necesarias para gestionar cada paso del flujo de trabajo de ML. El diseñador visual de flujos de trabajo, elemento central de RapidMiner, permite a los usuarios crear canalizaciones con facilidad, sin necesidad de escribir código.
En el último año, las herramientas de IA se han vuelto esenciales para el análisis de datos. Se utilizan para la generación de código, la validación, la comprensión de resultados, la generación de informes y mucho más.
chatGPT es una herramienta basada en inteligencia artificial que puede ayudarte con diversas tareas relacionadas con la ciencia de datos. Ofrece la posibilidad de generar código Python y ejecutarlo, y también puede generar informes de análisis completos. Pero eso no es todo. chatGPT viene equipado con una variedad de complementos que pueden ser muy útiles para la investigación, la experimentación, las matemáticas, la estadística, la automatización y la revisión de documentos. Algunas de las características más destacadas son DALLE-3 (generación de imágenes), navegador con Bing y chatGPT Vision (reconocimiento de imágenes).
Puedes consultar la Guía para usar chatGPT en proyectos de ciencia de datos para aprender a utilizar chatGPT y crear proyectos de ciencia de datos integrales.
¿Buscas formas de aplicar estas herramientas de datos a conjuntos de datos de la vida real? DataCamp te tiene cubierto. Ofrecen proyectos guiados y no guiados que se pueden cargar en un cuaderno con tecnología de inteligencia artificial llamado DataLab, lo que te permite empezar a trabajar en un proyecto de inmediato. La lista de proyectos de DataCamp es muy amplia y abarca una gran variedad de temas, entre los que se incluyen el procesamiento de datos, machine learning, la ingeniería de datos, MLOps, LLM, NLP y mucho más.
Aquí tienes los enlaces a más proyectos que te ayudarán a aplicar herramientas de vanguardia a tu conjunto de datos:
Se están produciendo avances emocionantes en el dinámico ámbito de la ciencia de datos, donde la innovación es la norma. Esta entrada del blog ofrece una visión general completa de las 10 herramientas de ciencia de datos más populares que probablemente se utilizarán cada vez más en 2026.
Las bibliotecas basadas en Python, como Pandas, Seaborn y Scikit-learn, ofrecen sólidas capacidades para la preparación, el análisis, la visualización y la modelización de datos. Las plataformas de código abierto como MLflow, Pytorch y Hugging Face aceleran la experimentación, el desarrollo y la implementación. Las soluciones patentadas como Tableau y RapidMiner permiten una inteligencia empresarial a escala corporativa y una gestión integral del ciclo de vida del machine learning. Y los nuevos asistentes de IA, como chatGPT, generan código e información, lo que aumenta la productividad.
Si aspiramos a convertirte en un científico de datos competente y adquirir experiencia en el uso de estas herramientas, inscríbete en el programa de Científico de datos con Python. Este programa te proporcionará las habilidades esenciales necesarias para destacar como científico de datos, desde la manipulación de datos hasta machine learning.
¡Comienza hoy mismo tu andadura en la ciencia de datos!
programa
Curso
Curso