
Curso
Introducción a Python
4 h
6.9M
Si estás pensando en iniciar una carrera en la ciencia de datos, cuanto antes empieces a codificar, mejor. Aprender a programar es un paso fundamental para todo aspirante a científico de datos. Sin embargo, iniciarse en la programación puede ser desalentador, sobre todo si no tienes experiencia previa en codificación.
Para elegir el lenguaje de programación adecuado, primero debemos fijarnos en lo que hacen los científicos de datos en su trabajo diario. Un científico de datos es un experto técnico que utiliza técnicas matemáticas y estadísticas para manipular, analizar y extraer información de los datos. Hay muchos dominios dentro del ámbito de la ciencia de datos, desde el aprendizaje automático y el aprendizaje profundo, hasta el análisis de redes, el procesamiento del lenguaje natural y el análisis geoespacial. Para realizar sus tareas, los científicos de datos confían en la potencia de los ordenadores. La programación es la técnica que permite a los científicos de datos interactuar con los ordenadores y enviarles instrucciones.
Existen cientos de lenguajes de programación, creados para diversos fines. Algunos de ellos son más adecuados para la ciencia de datos, ya que proporcionan una gran productividad y rendimiento para procesar grandes cantidades de datos. Sin embargo, este grupo sigue comprendiendo un buen número de lenguajes de programación.
En este artículo, analizamos algunos de los principales lenguajes de programación para la ciencia de datos para 2026 y presentamos las ventajas y capacidades de cada uno de ellos.
Todos los datos se han actualizado para reflejar las últimas tendencias para 2026 y años posteriores.

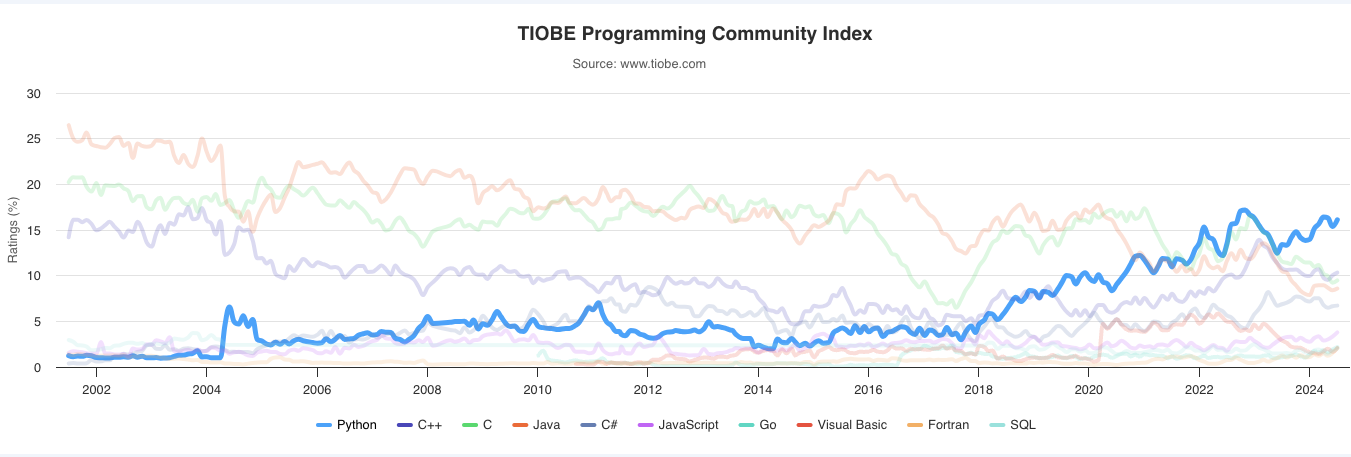
Clasificado en primer lugar en varios índices de popularidad de lenguajes de programación, como el Índice TIOBE y el Índice PYPL, la popularidad de Python ha aumentado en los últimos años y sigue siendo el lenguaje de programación más popular. Python es un lenguaje de programación de código abierto y de propósito general con una amplia aplicabilidad no sólo en la industria de la ciencia de datos, sino también en otros dominios, como el desarrollo web y el desarrollo de videojuegos.
Cualquier tarea de ciencia de datos que se te ocurra se puede hacer con Python. Esto se debe principalmente a su rico ecosistema de bibliotecas. Con miles de potentes paquetes respaldados por su enorme comunidad de usuarios, Python puede realizar todo tipo de operaciones, desde el preprocesamiento de datos, la visualización y el análisis estadístico, hasta el despliegue de modelos de aprendizaje automático y aprendizaje profundo. Éstas son algunas de las bibliotecas más utilizadas para la ciencia de datos y el aprendizaje automático:
Debido a su sintaxis sencilla y legible, se suele decir que Python es uno de los lenguajes de programación más fáciles de aprender y utilizar para principiantes. Si eres nuevo en la ciencia de datos y no sabes qué lenguaje aprender primero, Python es una de las mejores opciones.
Si quieres ser un experto en Python, DataCamp está aquí para ayudarte. Consulta los cursos de Python de nuestro catálogo y comienza tu formación para convertirte en un científico de datos de éxito.

Aunque no está tan de moda como Python en los últimos años, según los índices de popularidad, R es una de las mejores opciones para los aspirantes a científicos de datos. Frecuentemente presentado en los foros de ciencia de datos como el principal competidor de Python, aprender uno de estos dos lenguajes es un paso fundamental para introducirse en este campo.
R es un lenguaje específico de dominio de código abierto, diseñado explícitamente para la ciencia de datos. Muy popular en el mundo financiero y académico, R es un lenguaje perfecto para la manipulación, procesamiento y visualización de datos, así como para la computación estadística y el aprendizaje automático.
Al igual que Python, R tiene una gran comunidad de usuarios y una vasta colección de bibliotecas especializadas para el análisis de datos. Algunos de los más notables pertenecen a la familia Tidyverse, una colección de paquetes de ciencia de datos. Incluye dplyr, para la manipulación de datos, y el potente ggplot2, la biblioteca estándar para la visualización de datos en R. En cuanto a las tareas de machine learning, bibliotecas como caret te facilitarán mucho la vida a la hora de desarrollar tus algoritmos.
Aunque es posible trabajar con R directamente en la línea de comandos, es habitual utilizar Rstudio, una potente interfaz de terceros que integra diversas funciones, como editor de datos, visor de datos y depurador.
Tanto si eres nuevo en la ciencia de datos como si quieres añadir nuevos lenguajes a tu arsenal, aprender R es una opción perfecta. Consulta nuestro rico catálogo de cursos de R para empezar a perfeccionar tus habilidades.

Gran parte de los datos del mundo se almacenan en bases de datos. SQL (Lenguaje de Consulta Estructurado) es un lenguaje específico del dominio que permite a los programadores comunicarse con las bases de datos, editarlas y extraer datos de ellas. Tener conocimientos prácticos de bases de datos y SQL es imprescindible si quieres convertirte en un científico de datos.
Conocer SQL te permitirá trabajar con diferentes bases de datos relacionales, incluidos sistemas populares como SQLite, MySQL y PostgreSQL. A pesar de las pequeñas diferencias entre estas bases de datos relacionales, la sintaxis para las consultas básicas es bastante similar, lo que hace de SQL un lenguaje muy versátil.
Tanto si eliges Python como R para iniciar tu andadura en la ciencia de datos, también deberías plantearte aprender SQL. Debido a su sintaxis declarativa y sencilla, SQL es muy fácil de aprender en comparación con otros lenguajes, y te ayudará mucho en el camino.
¿Quieres iniciarte en SQL? Echa un vistazo a los diferentes cursos de SQL y a los itinerarios de habilidades que ofrece DataCamp y prepárate para convertirte en un maestro de las consultas. Incluso puedes obtener una certificación de asociado SQL a través de DataCamp.

Clasificado en el segundo puesto del índice PYPL y en el cuarto del índice TIOBE, Java es uno de los lenguajes de programación más populares. en el mundo, aunque su popularidad se ha reducido en la última década, mientras que el interés por lenguajes como Python se ha disparado. Java es un lenguaje de código abierto orientado a objetos, conocido por su rendimiento y eficacia de primera clase. Infinidad de tecnologías, aplicaciones de software y sitios web dependen del ecosistema Java.
Aunque Java es la opción preferida cuando se desarrollan sitios web o se crean aplicaciones desde cero, en los últimos años, Java ha adquirido un papel destacado en la industria de la ciencia de datos. Esto se debe principalmente a las Máquinas Virtuales Java, que proporcionan un marco sólido y eficiente para herramientas populares de big data, como Hadoop, Spark y Scala.
Debido a su alto rendimiento, Java es un lenguaje adecuado para desarrollar trabajos ETL y realizar tareas de datos que requieran grandes requisitos de almacenamiento y procesamiento complejo, como los algoritmos de aprendizaje automático.

Julia puede considerarse una estrella emergente de la ciencia de datos. A pesar de ser uno de los lenguajes más jóvenes de esta lista (se lanzó en 2011), Julia ya ha impresionado al mundo de la computación numérica. A veces conocido como el heredero de Python, Julia es una herramienta muy eficaz en comparación con otros lenguajes utilizados para el análisis de datos. Puedes empezar con nuestro programa formativo «Fundamentos de Julia » para obtener más información.
Aunque ha ganado notoriedad gracias a su pronta adopción por parte de varias organizaciones importantes, incluidas muchas del sector financiero, Julia no está tan ampliamente adoptado como lenguajes como Python y R. Tiene una comunidad más pequeña y no dispone de tantas bibliotecas como sus principales competidores. A pesar de ello, Julia es un lenguaje prometedor para la ciencia de datos debido a su velocidad, sintaxis clara y versatilidad, y hay muchos casos de uso en los que destaca.

Aunque no es muy habitual ver a Scala en los primeros puestos de los rankings de lenguajes de programación (actualmente ocupa el puesto 21 en el índice PYPL y el 33 en TIOBE), hablar de este lenguaje de programación es obligatorio en el contexto de la ciencia de datos.
Scala se ha convertido recientemente en uno de los mejores lenguajes para el aprendizaje automático y los grandes datos. Lanzado en 2004, Scala es un lenguaje multiparadigmático diseñado explícitamente para ser una alternativa más clara y menos farragosa a Java.
Scala también se ejecuta en la Máquina Virtual Java, lo que permite la interoperabilidad con Java y lo convierte en un lenguaje perfecto para proyectos distribuidos de big data. Por ejemplo, el marco de computación en clúster Apache Spark está escrito en Scala.


Considerados dos de los lenguajes más optimizados, estar familiarizado con C y su pariente cercano C++ puede ser muy útil cuando se trata de abordar tareas de ciencia de datos computacionalmente intensivas.
 Fuente: Índice TIOBE
Fuente: Índice TIOBE
C y C++ son comparativamente más rápidos que otros lenguajes de programación, lo que los convierte en candidatos idóneos para desarrollar aplicaciones de big data y aprendizaje automático. No es casualidad que algunos de los componentes principales de las bibliotecas de aprendizaje automático más populares, como PyTorch y TensorFlow, estén escritos en C++.
Debido a su naturaleza de bajo nivel, C y C++ se encuentran entre los lenguajes más complicados de aprender. Por lo tanto, aunque puede que no sean las primeras opciones a la hora de embarcarse en el mundo de la ciencia de datos, una vez que adquieras una sólida comprensión de los fundamentos de la programación, dominarlos es un movimiento inteligente que puede marcar una gran diferencia en tu currículum.

JavaScript ocupa el tercer puesto en el índice PYPL y el sexto en TIOBE, lo que lo convierte en uno de los lenguajes de programación más populares del mundo. JavaScript es un lenguaje multiparadigma y versátil, ampliamente conocido por su capacidad para construir páginas web ricas e interactivas.
Aunque la mayoría de los usuarios de JavaScript trabajan en el sector del desarrollo web, en los últimos años el lenguaje ha ganado notoriedad en la industria de la ciencia de datos. Hoy en día, JavaScript admite bibliotecas populares para el aprendizaje automático y el aprendizaje profundo, como TensorFlow y Keras, así como herramientas de visualización increíblemente potentes, como D3.
Gracias a la compatibilidad con bibliotecas populares para el aprendizaje automático, y debido a su amplia popularidad entre los desarrolladores web, es una opción de entrada sin problemas para todos los programadores de front-end y back-end que quieran introducirse en la ciencia de datos.

Uno de los inconvenientes de Python y R es que ninguno de los dos se creó pensando en los dispositivos móviles. En los próximos años, podemos esperar un avance aún mayor de los móviles, los wearables y el IoT (Internet de las Cosas). Swift fue desarrollado por Apple para facilitar la creación de aplicaciones y, con ello, hacer crecer su ecosistema de aplicaciones y aumentar la retención de clientes. Poco después de su lanzamiento en 2014, Apple y Google empezaron a trabajar juntos para convertirlo en una herramienta clave en la interacción entre el móvil y el aprendizaje automático.
Clasificado en el puesto n.º 9 del índice PYPL y en el n.º 17 del TIOBE, Swift ahora es compatible con TensorFlow y es interoperable con Python. Una ventaja adicional de Swift es que ya no se limita al ecosistema iOS y se ha convertido en código abierto para funcionar en Linux.
Por estas razones, si eres desarrollador móvil y sientes curiosidad por la ciencia de datos, Swift es lo que estás buscando.

Go (o GoLang) es un lenguaje cada vez más popular, especialmente para proyectos de aprendizaje automático. Ha subido en las clasificaciones de popularidad tanto en el índice PYPL (puesto n.º 12) como en TIOBE (puesto n.º 7).
Google lo introdujo en 2009 con sintaxis y diseños similares a C. Según muchos desarrolladores, Go es la versión del siglo XXI de C. Más de una década después de su lanzamiento, Go se está haciendo extremadamente popular gracias a su lenguaje flexible y fácil de entender. En el contexto de la ciencia de datos, Go puede ser un buen aliado para las tareas de aprendizaje automático. A pesar de sus perspectivas, la comunidad de ciencia de datos de Go sigue siendo relativamente pequeña.
MATLAB es un lenguaje diseñado principalmente para cálculo numérico. Actualmente ocupa el puesto 14 en el índice PYPL y el 12 en el TIOBE.
Ampliamente adoptado en el mundo académico y la investigación científica desde su lanzamiento en 1984, MATLAB proporciona potentes herramientas para realizar operaciones matemáticas y estadísticas avanzadas, lo que lo convierte en un gran candidato para la ciencia de datos. Sin embargo, MATLAB tiene un inconveniente importante: es propietario. Dependiendo del caso (uso académico, personal o empresarial), puede que tengas que pagar una gran cantidad de dinero para obtener una licencia, lo que lo hace menos atractivo que otros lenguajes de programación que pueden utilizarse gratuitamente.

SAS (Statistical Analytical System) es un entorno de software diseñado para la inteligencia empresarial y la informática numérica avanzada. SAS existe desde hace mucho tiempo, y es ampliamente adoptado por las grandes empresas de muchos sectores, lo que crea un gran mercado para los desarrolladores de SAS.
Sin embargo, SAS está perdiendo popularidad frente a otros lenguajes de programación de ciencia de datos como Python y R. Esto se debe principalmente a que, como ocurrió con MATLAB, necesitas una licencia para utilizar SAS. Esto crea una barrera de entrada para los nuevos usuarios y empresas, que se sentirán propensos a utilizar lenguajes libres y de código abierto.
Esperamos que este post te ayude a navegar por el rico y diverso panorama de los lenguajes de programación de la ciencia de datos. No existe un único lenguaje que sea el mejor en términos absolutos para resolver todos los problemas y situaciones que puedan surgir durante tu trabajo como científico de datos. La elección de un lenguaje de programación preferido es subjetiva y a menudo depende del historial de aprendizaje de un científico de datos o de la pila tecnológica de su trabajo. Por ejemplo, el evangilista de datos de DataCamp, Richie Cotton, opina:
"La ciencia de datos se centra cada vez más en Python y SQL para la programación, aunque R sigue siendo popular y Julia está en alza. Espero que esta tendencia continúe en 2023 y más allá, pero cuidado con las herramientas de inteligencia empresarial de bajo código como Power BI y Tableau."
Si eres un recién llegado a la ciencia de datos, Python o R son un buen punto de partida. Puedes inscribirte en nuestro Tutorial gratuito de Introducción a Python y en el Tutorial de Introducción a R para ver cuál te gusta más. A partir de ahí, la clave del éxito es la paciencia y la práctica. Para adquirir experiencia práctica en programación, DataLabes un entorno en línea en el que puedes escribir código, aplicar tus habilidades, colaborar con otras personas y crear tu portafolio de ciencia de datos.
Una vez que te sientas seguro con el lenguaje elegido, podrías subir de nivel con una sólida formación en SQL. Afortunadamente, DataCamp ofrece una amplia gama de cursos de SQL.
A partir de ahí, el cielo es el límite. Conocer varios lenguajes de programación es una ventaja, y pasar de un lenguaje a otro según las necesidades de tu organización te ayudará a convertirte en un científico de datos versátil y a desarrollar una carrera profesional más exitosa.
Más información:
Cursos para Python
Curso
Curso
Curso
blog
Javier Canales Luna
8 min
blog
Elena Kosourova
14 min
blog
Kevin Babitz
10 min
blog
Javier Canales Luna
7 min
blog
Javier Canales Luna
8 min
Tutorial
Adel Nehme

