
programa
Profesional de AWS Cloud (CLF-C02)
10 h
La IA generativa de AWS representa el futuro de los servicios en la nube, ya que permite a las empresas crear contenido automatizado y trabajo basado en el conocimiento a través de modelos básicos que producen texto, imágenes y vídeo en tiempo real.
En este artículo, proporciono una visión general completa de los elementos esenciales de los métodos de implementación y los marcos de gobernanza necesarios para desarrollar soluciones de IA generativa listas para la producción.
AWS es el proveedor líder de servicios en la nube porque ofrece Amazon Bedrock junto con una infraestructura informática especializada y amplias capacidades de integración que superan a otras plataformas en la nube.
Si eres nuevo en AWS, este curso introductoriote proporciona una base sólida antes de sumergirte en los detalles específicos de la IA generativa.
En esta sección, exploraremos los componentes básicos que impulsan la IA generativa de AWS.
Bedrock sirve como plano de control gestionado para toda la IA generativa en AWS. Ofrece una API coherente para implementar, escalar y proteger modelos básicos, desde el aprovisionamiento de terminales hasta la facturación, para que puedas centrarte en crear indicaciones e integrar la IA en lugar de gestionar la infraestructura.
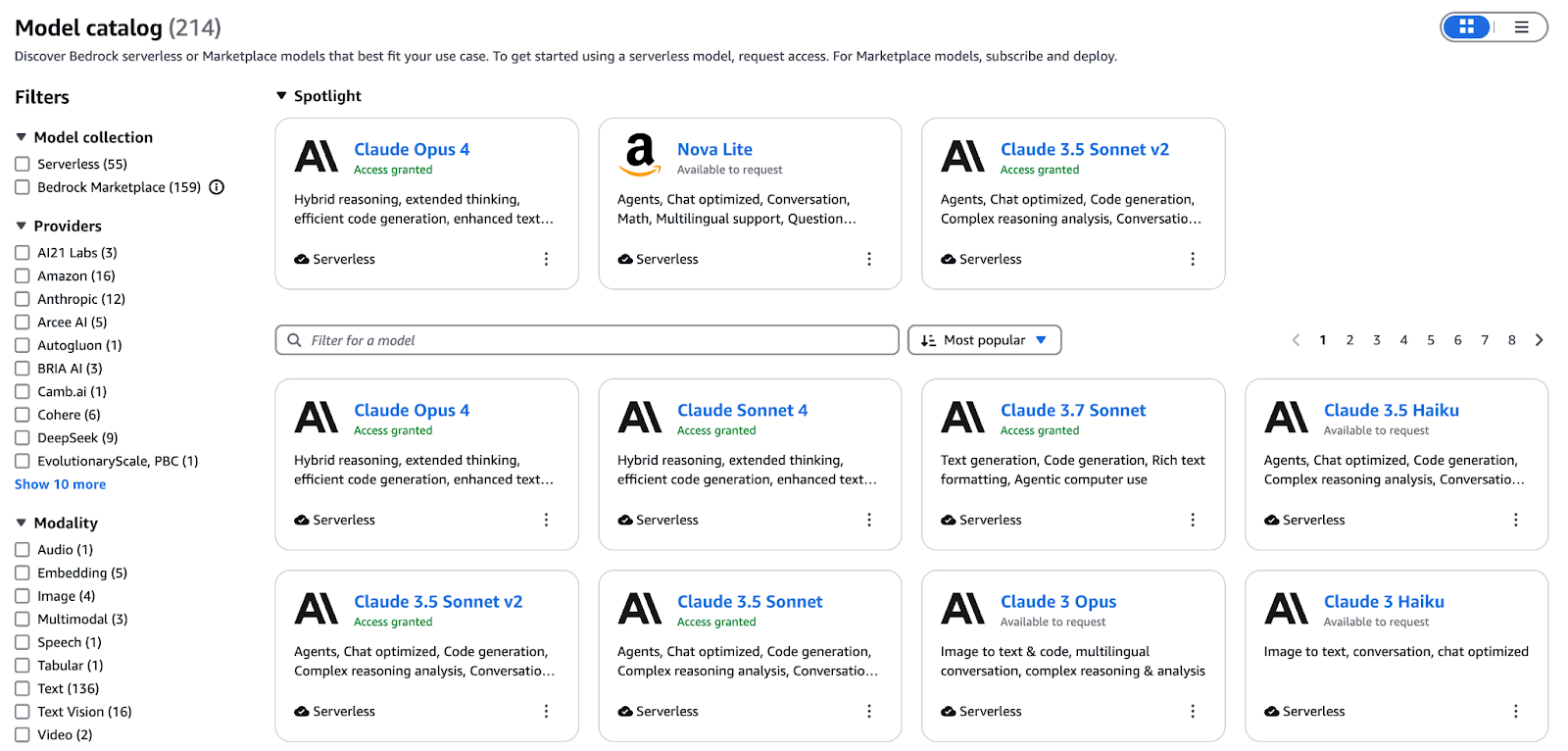
Diagrama conceptual que ilustra el ecosistema del modelo básico de AWS.
Elcatálogo Bedrockunifica modelos para texto, imágenes, vídeo e incrustaciones en una única interfaz. Las ofertas principales incluyen:
Ajusta los modelos con tus datos etiquetados o continúa el preentrenamiento en corpus específicos del dominio a través de la consola Bedrock o el SDK. Una vez completada la formación, el conjunto de herramientas de evaluación de Bedrock realiza comparaciones paralelas e informa sobre la precisión, la latencia y el coste por token, para que puedas elegir de forma objetiva la variante óptima para los SLA de producción.
Además de las familias Titan y Nova de AWS, Bedrock te ofrece acceso a modelos de socios como Anthropic, Cohere, Mistral, AI21 Labs y muchos más. Aprovecha esta amplitud para:
Para profundizar en cómo Bedrock coordina estos modelos básicos en entornos de producción, consulta esta guía completa de Amazon Bedrock.
Las familias de instancias EC2 proporcionadas por AWS existen para satisfacer las necesidades específicas de las operaciones de formación e inferencia.
Formación:
Inferencia:
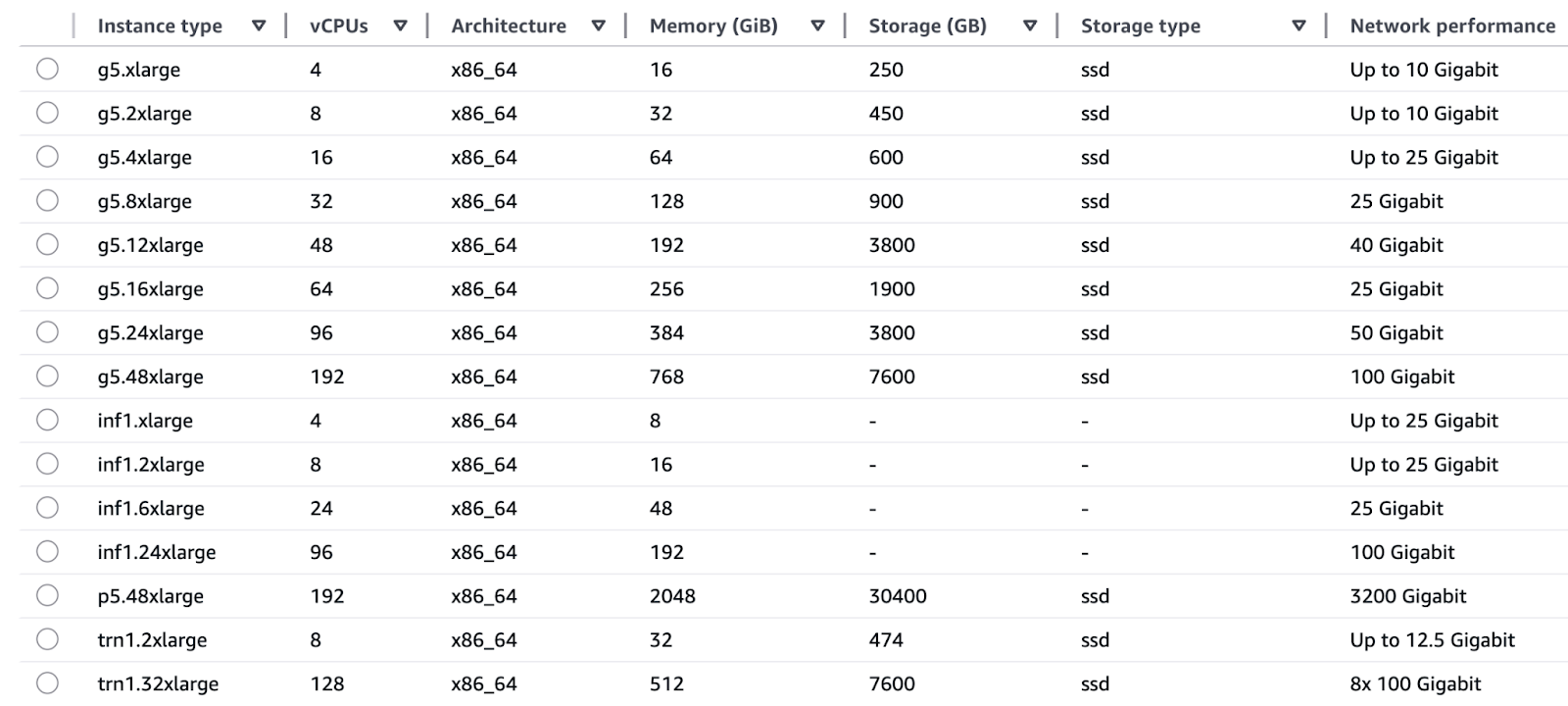
Diagrama ilustrativo de la infraestructura informática optimizada para IA de AWS.
AWS logra una integración perfecta entre sus componentes de hardware y software diseñados a medida a través de Trainium para la formación y Inferentia para los chips de inferencia, que funcionan directamente con los servicios de AWS. Esta integración vertical da como resultado:
El sistema AWS Nitro utiliza tarjetas de hardware dedicadas para realizar funciones de virtualización, lo que proporciona velocidades rápidas de bare metal junto con un aislamiento seguro:
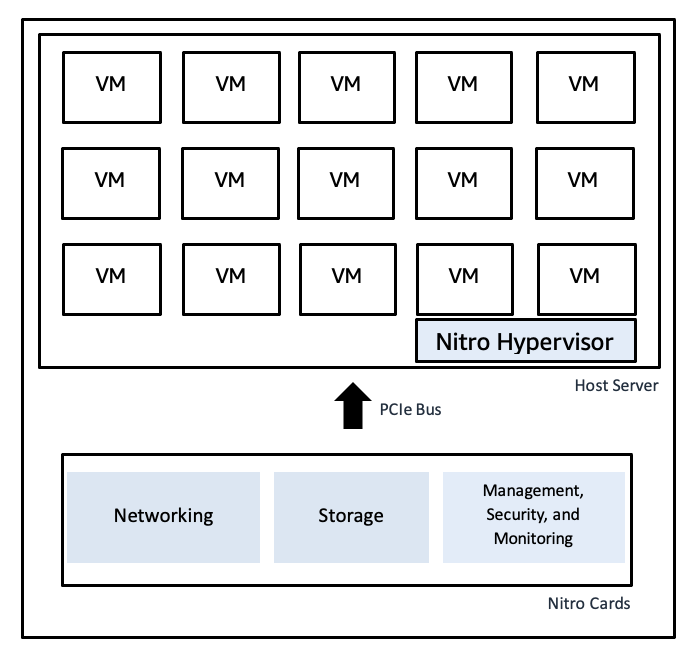 Diagrama ilustrativo del hipervisor Nitro de AWS
Diagrama ilustrativo del hipervisor Nitro de AWS
Explora el amplio ecosistema de computación, almacenamiento y análisis en este cursosobre tecnología y servicios en la nube de AWS.
El entrenamiento de modelos a alta velocidad y los procesos RAG necesitan acceder a datos limpios y correctamente gestionados:
Las capacidades de IA generativa de AWS se integran directamente con su amplio ecosistema para ofrecer soluciones integrales aptas para la producción. En esta sección se describe el proceso de combinación de Bedrock con sus servicios complementarios para desarrollar aplicaciones de IA generativa reales.
Selecciona modelos básicos del centro de modelos de SageMaker JumpStart e impleméntalos de inmediato. Puedes implementar numerosos modelos de código abierto y propietarios con un solo botón antes de registrarlos directamente en Amazon Bedrock. Los modelos introducidos en Bedrock obtienen acceso a:
La arquitectura integrada permite a los programadores crear prototiposen SageMaker Studio y, a continuación, mejorarlos en Bedrock antes de implementarlos a través de canalizaciones de CI/CD sin modificar el código.
Este tutorial de SageMaker te guía a través del proceso de ajuste y despliegue de modelos utilizando la plataforma de ML insignia de AWS.
 Diagrama ilustrativo que muestra el ciclo de vida unificado del ML con SageMaker JumpStart y Bedrock.
Diagrama ilustrativo que muestra el ciclo de vida unificado del ML con SageMaker JumpStart y Bedrock.
A través de Bedrock Agents, puedes integrar la IA generativa en tus aplicaciones operativas mediante la obtención automática de datos y su transformación antes de ejecutar acciones. Un agente solo requiere una configuración básica para:
Las funciones básicas de Agents permiten a los programadores concentrarse en la lógica empresarial en lugar de en el código de integración, lo que acelera la rentabilidad.
Amazon Q es un servicio totalmente gestionado para desarrollar asistentes empresariales basados en RAG.
El servicio integra la funcionalidad multimodelo de Bedrock con:
A través de Q, las organizaciones empresariales crean chatbots orientados al cliente, junto con paneles de control ejecutivos y servicios de asistencia técnica específicos para cada dominio, que se implementan en cuestión de semanas en lugar de meses.
La lente de IA generativa bien diseñada implementa las prácticas recomendadas en cada paso del desarrollo de cargas de trabajo generativas.
La lente de IA generativa de AWS amplía los cinco pilares delmarco Well-Architected Framework a las cargas de trabajo generativas de AWS. El marco incluye sistemas automatizados de supervisión de modelos y mecanismos de detección de desviaciones, junto con activadores de reciclaje con gestión de artefactos de versión y seguimiento de métricas de inferencia.
Estos son los pilares:
Para aquellos que desean obtener la certificación, el programa AWS Cloud Practitionerse ajusta perfectamente a los conocimientos básicos que se tratan aquí.
La red de socios de AWS ofrece asistencia a las empresas acelerando su adopción de los servicios de AWS a través de aceleradores de soluciones y servicios de socios. Cada organización empresarial es diferente, por eso AWS ha creado la red de socios con aceleradores de IA generativa específicos para diferentes sectores y casos de uso.
La capacidad de la IA generativa para crear contenido nuevo no se ajusta a los requisitos de las aplicaciones del mundo real, que necesitan procesar y comprender datos a través de diversos formatos de presentación.
AWS ofrece una colección de servicios de apoyo que se integran con tus procesos generativos para convertir documentos no estructurados en datos estructurados, extraer información de imágenes y permitir conversaciones naturales y la entrega de resultados en cualquier idioma o voz.
Estos son los más populares:
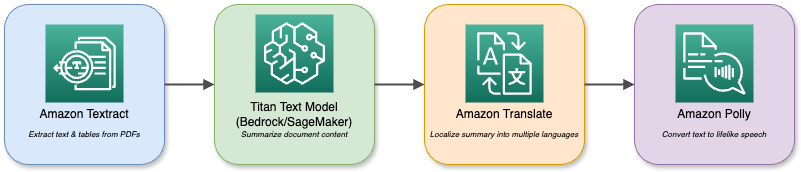
Diagrama ilustrativo de los distintos servicios e interacciones de AWS.
Tus modelos básicos en Bedrock o SageMaker se pueden combinar con estos servicios para crear aplicaciones multimodales complejas.
Un asistente de análisis de documentos, por ejemplo, utiliza Textract para importar archivos PDF y, a continuación, utiliza Titan Text para resumirlos antes de traducir el resumen a varios idiomas y reproducirlo a través de Polly. El ecosistema componible te permite combinar diversas capacidades de IA para satisfacer cualquier requisito empresarial.
La IA generativa ofrece sus mejores resultados cuando utilizas patrones bien diseñados para abordar problemas empresariales reales.
En esta sección se presentan cuatro planes de implementación específicos, que incluyen la generación aumentada con recuperación y los asistentes para programadores y empresas, así como escenarios adicionales de gran valor que puedes implementar hoy mismo.
La combinación de las capacidades de búsqueda con grandes modelos lingüísticos en la generación aumentada por recuperación produce respuestas precisas que se mantienen fieles al contexto. El proceso de cuatro etapas funciona de la siguiente manera:
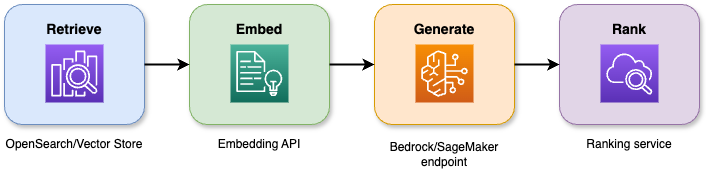
Diagrama ilustrativo que muestra una arquitectura de generación aumentada por recuperación (RAG).
Ventajas y ganancia en precisión:
Aplicaciones empresariales:
AWS CodeWhisperer ofrece IA generativa directamente a los programadores a través de sus IDE y canalizaciones de CI/CD para automatizar las tareas repetitivas y acelerar los procesos de codificación:
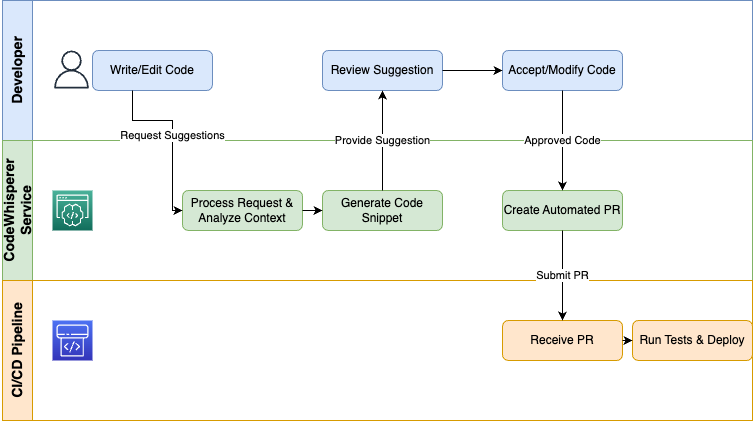
Diagrama ilustrativo que muestra un flujo de trabajo de generación de código.
Las organizaciones que utilizan CodeWhisperer como asistente para programadores eliminan el trabajo repetitivo, aplican normas de codificación y permiten a los ingenieros dedicar su tiempo a actividades valiosas de diseño y depuración.
Ten en cuentaque CodeWhisperer pasará a formar parte de Amazon Q Developer.
Amazon Q Business funciona como una solución de bajo código impulsada por RAG, que permite a los usuarios desarrollar asistentes conversacionales que recuperan datos empresariales a través de preguntas.
Arquitectura:
Escenarios de implementación:
Los asistentes ayudan a las organizaciones a optimizar el trabajo intelectual, reducir los costes operativos y permitir a los empleados alcanzar mayores niveles de productividad.
El valor de la IA generativa va más allá del RAG, la generación de código y los asistentes, y se extiende a otros muchos ámbitos:
Comienza con estos patrones para establecer programas piloto que demuestren un claro retorno de la inversión antes de pasar a la optimización y la ampliación en toda la organización.
Las empresas deben implementar controles de seguridad y prácticas de gobernanza en todas las etapas del ciclo de vida de la IA cuando adoptan la IA generativa.
AWS proporciona un marco integral de seguridad y cumplimiento normativo que abarca desde centros de datos físicos hasta políticas a nivel de aplicaciones, lo que permite innovar con confianza.
AWS protege las cargas de trabajo de IA generativa a través de seis capas de seguridad concéntricas:
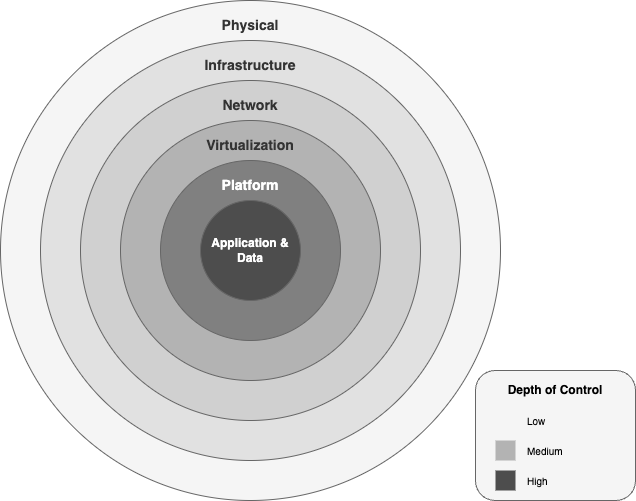
Diagrama ilustrativo de las capas de seguridad dentro del marco de IA generativa de AWS.
Aislamiento de datos y cumplimiento normativo:
El desarrollo de la confianza en la IA generativa requiere la implementación de protocolos éticos y de seguridad en cada etapa de la invocación del modelo. AWS implementa una gobernanza responsable de la IA a través del siguiente marco:
Estas capas y prácticas establecen una postura de defensa en profundidad para la IA generativa empresarial, lo que te permite innovar mientras mantienes los más altos estándares de seguridad, cumplimiento y responsabilidad ética.
El proceso de control de los presupuestos de IA generativa exige tanto un conocimiento completo de los mecanismos de fijación de precios como prácticas continuas de gestión de costes. En esta sección se explica la estructura de precios de AWS para cargas de trabajo de IA, al tiempo que se presenta un ejemplo de TCO para una implementación de tamaño medio y estrategias para reducir los gastos.
Los precios de la IA generativa de AWS se dividen en cuatro dimensiones principales:
|
Arquitectura |
Calcular el factor de coste |
Factor determinante del coste de los tokens |
El más adecuado |
|
Chatbots en tiempo real |
Muchos pequeños terminales que funcionan las 24 horas del día, los 7 días de la semana. |
Alta tasa de solicitudes, tokens pequeños |
Atención al cliente, servicios de asistencia técnica |
|
Generación por lotes |
Instancias grandes de corta duración |
Pocas ráfagas grandes de tokens |
Generación de informes, aumento de datos |
|
Tuberías RAG |
Búsqueda combinada + inferencia |
Token de recuperación + token de generación |
Asistentes basados en el conocimiento |
A continuación se muestra un ejemplo de TCO mensual para un proyectopiloto de IA generativa de tamaño medio:
|
Elemento de coste |
Coste unitario |
Uso |
Coste mensual |
|
Puntos finales de inferencia (Inf1.xl) |
0,228 $/hora |
3 criterios de valoración × 24 horas × 30 días |
$492.48 |
|
Uso de tokens (Titan Express) |
0,0024 $ /1 token K |
3 tokens M al día × 30 días |
216,00 $ |
|
Almacenamiento S3 (artefactos de modelo) |
0,023 $/GB al mes |
10 000 GB |
$230 |
|
Salida de datos |
$0.09 /GB |
1 TB |
$90 |
|
Glue ETL (preparación de características) |
0,44 $/DPU-hora |
20 horas DPU |
$8.80 |
|
Total |
$1,037.28 |
Palanca de optimización clave:
Gestión continua de los costes:
La combinación de una arquitectura consciente de los precios con optimizaciones específicas y una supervisión continua te permite escalar la IA generativa sin incurrir en costes excesivos.
El proceso de escalado de la IA generativa, desde el concepto hasta la producción, requiere una metodología sistemática por fases. La hoja de ruta ofrece un enfoque paso a paso, que comienza con evaluaciones iniciales, pasa por pruebas piloto de concepto y culmina con la creación de una plataforma resistente y apta para empresas.
El primer paso consiste en comprobar la viabilidad y obtener el acuerdo de las partes interesadas antes de proceder al desarrollo completo de la arquitectura.
La prueba de concepto da como resultado el desarrollo de la plataforma fundamental antes de que el sistema pueda adoptarse de forma generalizada.
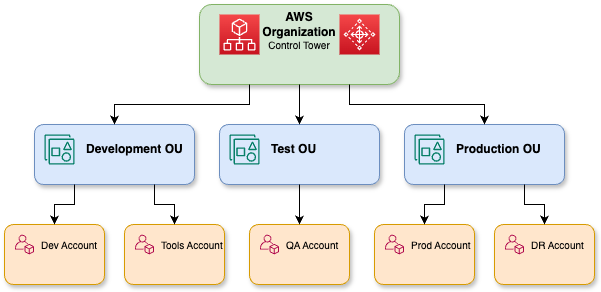
Una representación detallada de las organizaciones de AWS.
El enfoque por fases de la validación, seguido de la creación de bases sólidas y, posteriormente, la ampliación con gobernanza y el apoyo de los socios, te ayudará a transformar tu proyecto piloto de IA generativa en una capacidad sólida para toda la empresa.
El perfeccionamiento continuo y las sólidas prácticas de gobernanza, implementadas tras la ampliación de tu plataforma de IA generativa, garantizan el buen funcionamiento del sistema, al tiempo que mantienen la seguridad y el cumplimiento normativo.
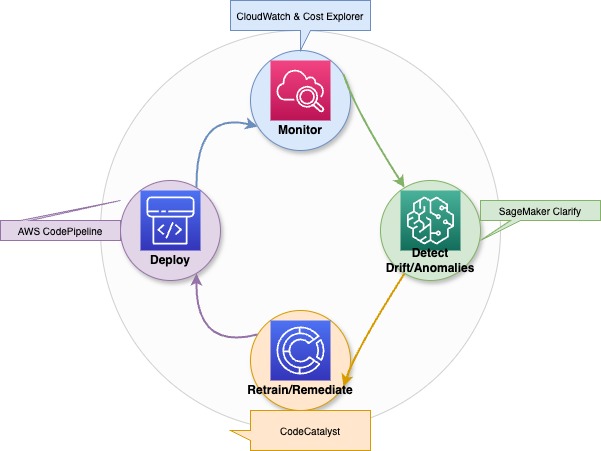
Diagrama ilustrativo que muestra los procesos de optimización continua, detección de desviaciones y reentrenamiento para modelos de IA generativa.
Al integrar la optimización continua y las auditorías estrictas con prácticas de aprendizaje organizacional, puedes mantener una capacidad de IA generativa resistente, fiable y rentable.
El viaje hacia la IA generativa de AWS se puede acelerar mediante itinerarios de aprendizaje, comunidades y proyectos prácticos que generan confianza e impulsan un impacto real en el negocio.
La IA generativa de AWS proporciona un sistema completo de extremo a extremo, que incluye modelos básicos, computación optimizada, gobernanza, integración y controles de costes, para ayudar a las empresas a innovar más rápidamente y reducir los gastos operativos, al tiempo que crean aplicaciones multimodales fiables a gran escala.
A través de la experimentación, el aprendizaje continuo y la colaboración con la comunidad, alcanzarás todo el potencial de la IA generativa de AWS para impulsar un impacto real en tu negocio.
¡Obtén más información sobre AWS con estos cursos!
programa
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Javier Canales Luna
10 min
blog
Javier Canales Luna
14 min
Tutorial
Zoumana Keita
