
Track
AWS Cloud Practitioner (CLF-C02)
10 hr
AWS generative AI represents the future of cloud services because it allows businesses to create automated content and knowledge work through foundation models that produce text, images, and video in real time.
In this article, I provide a comprehensive overview of the essential elements of deployment methods and governance frameworks required to develop production-ready generative AI solutions.
AWS is the leading cloud provider because it offers Amazon Bedrock alongside specialized compute infrastructure and broad integration capabilities that surpass other cloud platforms.
If you're new to AWS, this introductory course provides a solid foundation before diving into generative AI specifics.
In this section, we will explore the building blocks that power AWS generative AI.
Bedrock serves as the managed control plane for all generative AI on AWS. It exposes a consistent API for deploying, scaling, and securing foundation models from endpoint provisioning to billing, so you can focus on crafting prompts and integrating AI instead of managing infrastructure.
A conceptual diagram illustrating the AWS foundation model ecosystem
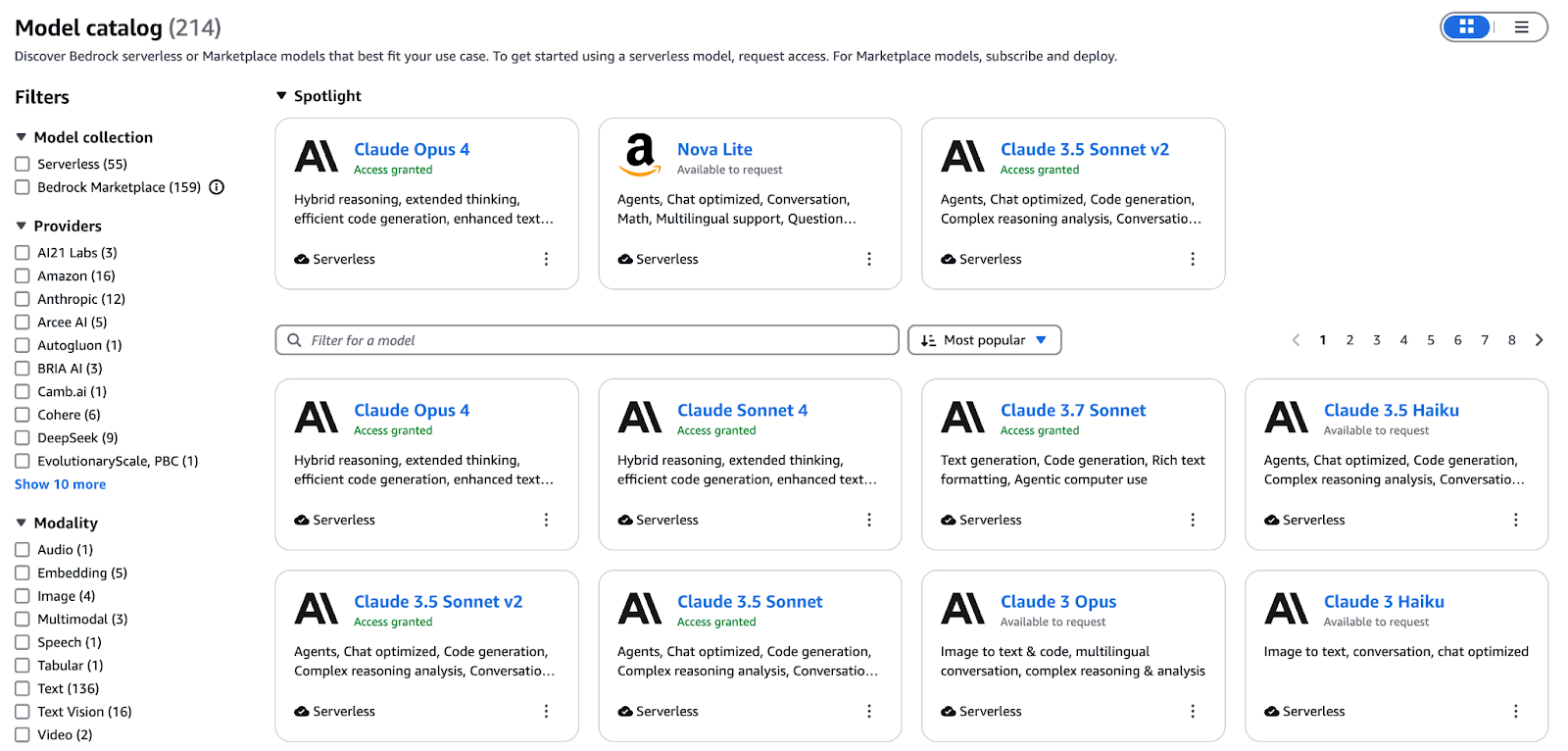
The Bedrock catalogue unifies models for text, image, video, and embeddings under a single interface. Key offerings include:
Fine-tune models on your labelled data or continue pre-training on domain-specific corpora via the Bedrock console or SDK. Once training is completed, Bedrock’s evaluation suite runs side-by-side comparisons reporting on the accuracy, latency, and cost per token so you can objectively choose the optimal variant for production SLAs.
Beyond AWS’ Titan and Nova families, Bedrock gives you access to partner models from Anthropic, Cohere, Mistral, AI21 Labs, and more. Leverage this breadth to:
To dive deeper into how Bedrock orchestrates these foundation models in production environments, check out this complete guide to Amazon Bedrock.
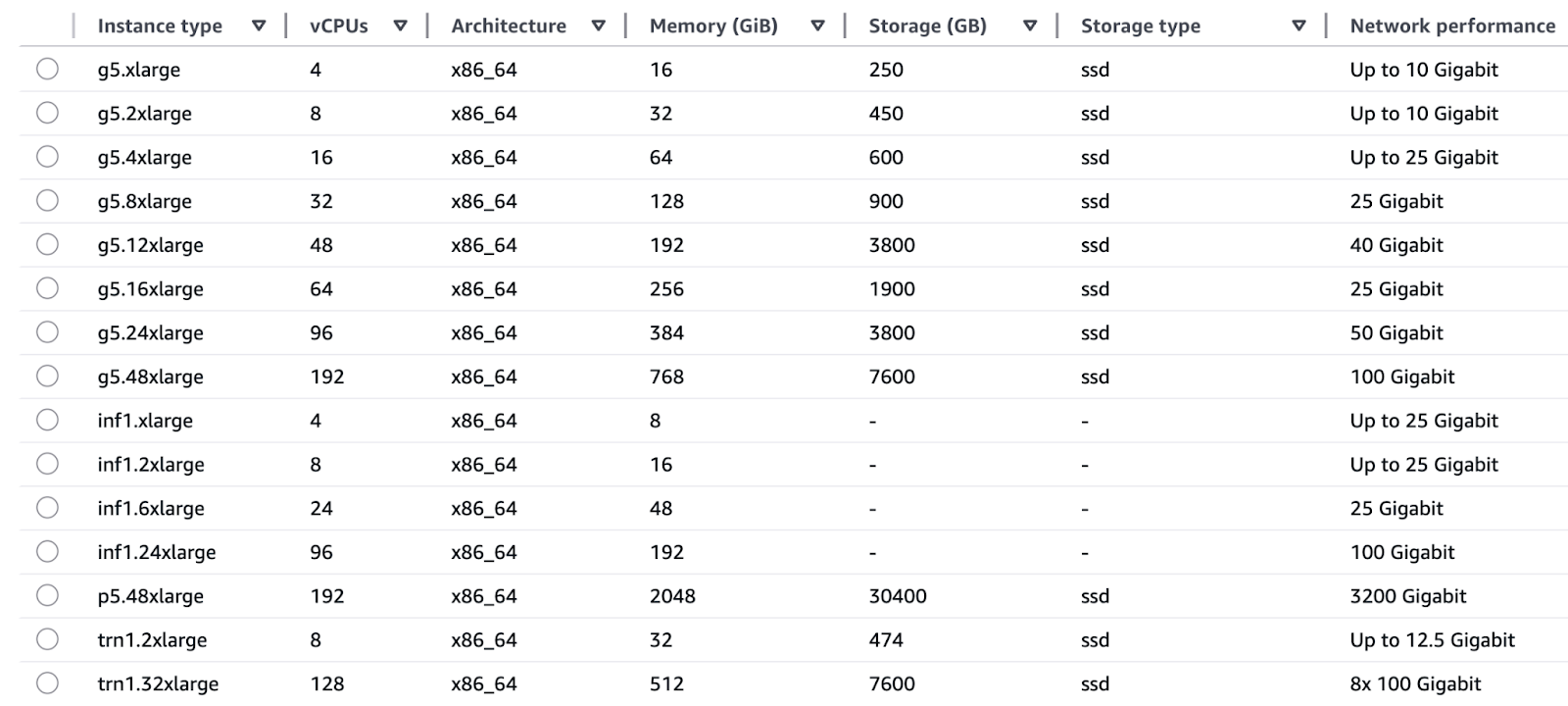
The EC2 instance families provided by AWS exist to meet the distinct needs of training and inference operations.
Training:
Inference:
An illustrative diagram of AWS's AI-optimized compute infrastructure.
AWS achieves seamless integration between its custom-designed hardware and software components through Trainium for training and Inferentia for inference chips, which work directly with AWS services. This vertical integration yields:
The AWS Nitro System uses dedicated hardware cards to perform virtualization functions, thus providing fast bare-metal speeds together with secure isolation:
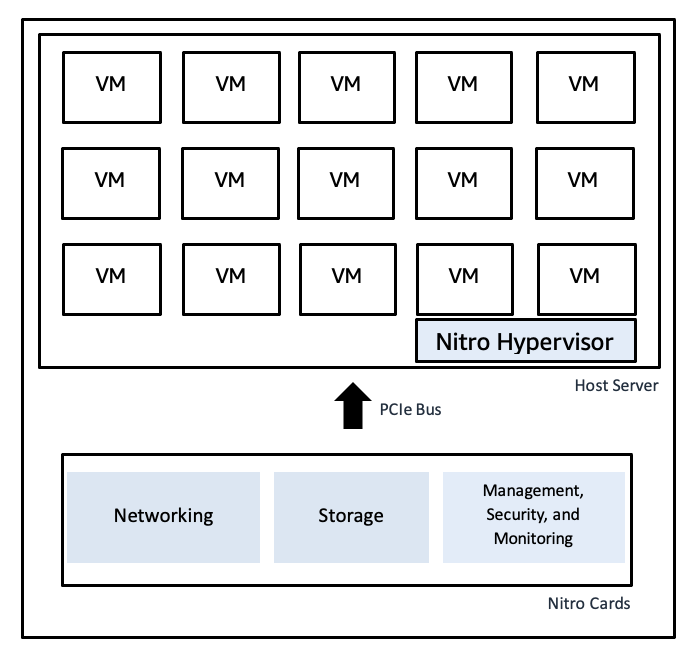 An illustrative diagram of AWS's Nitro Hypervisor
An illustrative diagram of AWS's Nitro Hypervisor
Explore the broader ecosystem of compute, storage, and analytics in this course on AWS Cloud Technology and Services.
Model training at high velocity and RAG pipelines need access to data that is clean and properly governed:
AWS generative AI capabilities directly integrate with its broader ecosystem to deliver end-to-end production-grade solutions. This section describes the process of combining Bedrock with its companion services to develop actual generative AI applications.
Select foundation models from SageMaker JumpStart’s model hub and immediately deploy them. You can deploy numerous open-source and proprietary models through a single button before registering them directly into Amazon Bedrock. The models entered into Bedrock gain access to:
The integrated architecture allows developers to create prototypes in SageMaker Studio and then enhance them in Bedrock before deploying them through CI/CD pipelines without code modification.
This SageMaker tutorial walks through the process of fine-tuning and deploying models using AWS’s flagship ML platform.
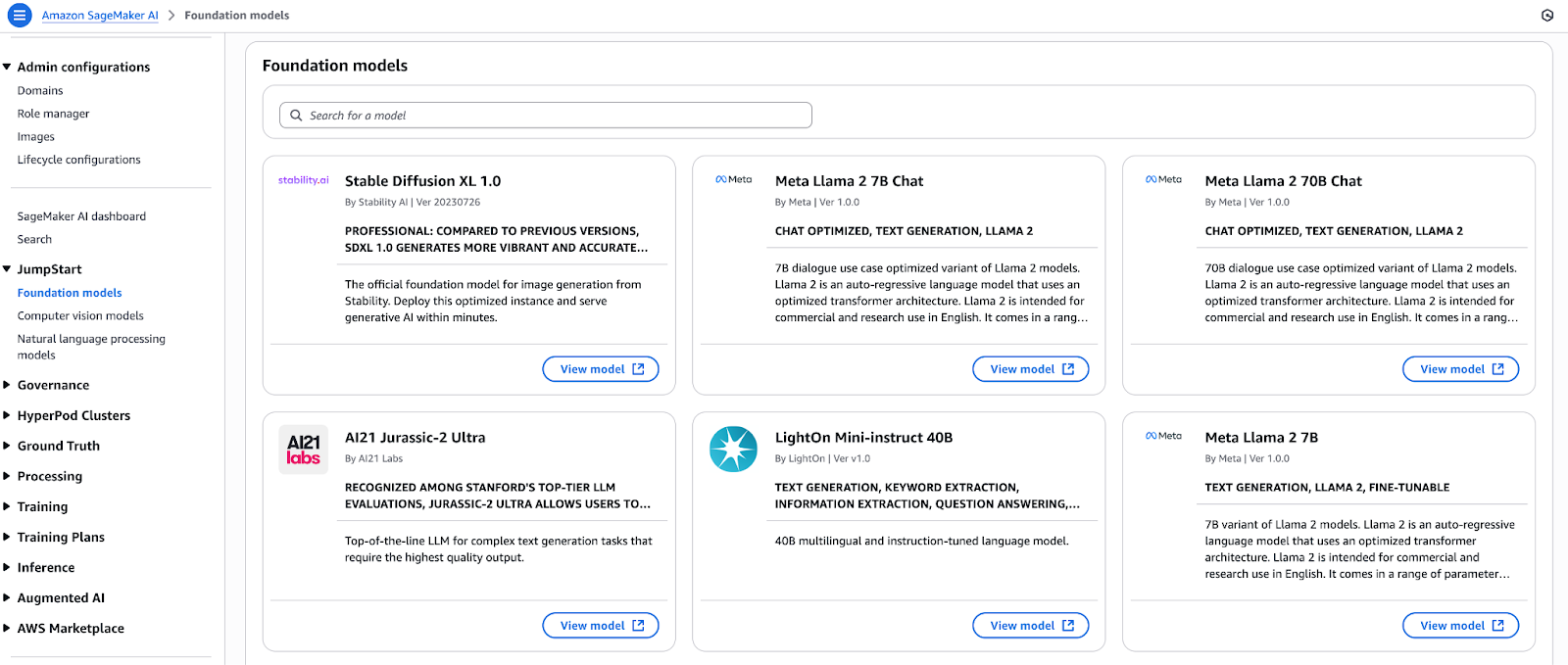 An illustrative diagram showing the unified ML lifecycle with SageMaker JumpStart and Bedrock.
An illustrative diagram showing the unified ML lifecycle with SageMaker JumpStart and Bedrock.
Through Bedrock Agents, you can integrate generative AI into your operational applications by automatically fetching data and transforming it before executing actions. An Agent requires only basic configuration to:
The plumbing functions of Agents enable developers to concentrate on business logic instead of integration code, thus speeding up time-to-value.
Amazon Q serves as a fully managed service to develop RAG-powered business assistants.
The service integrates Bedrock multi-model functionality with:
Through Q, enterprise organizations create customer-facing chatbots along with executive dashboards and domain-specific help desks, which they deploy within weeks instead of months.
The Well-Architected Generative AI Lens implements best practices throughout every step of generative workload development.
The Generative AI Lens of AWS extends the five pillars of the Well-Architected Framework to generative workloads. The framework includes automated model monitoring systems and drift detection mechanisms alongside retraining triggers with version artifact management and inference metric tracking.
Here are the pillars:
For those pursuing certification, the AWS Cloud Practitioner track aligns well with the foundational knowledge covered here.
The AWS Partner Network provides support for businesses by accelerating their adoption of AWS services through solution accelerators and partner services. Every enterprise organization differs from others because AWS has established the Partner Network with specific generative AI accelerators for different industries and use cases.
The ability of Generative AI to generate new content does not align with the requirements of real-world applications, which need to process and understand data through various presentation formats.
AWS provides a collection of supporting services that integrate with your generative pipelines to convert unstructured documents into structured data, extract image insights, and enable natural conversations and output delivery in any language or voice.
Here are the most popular ones:
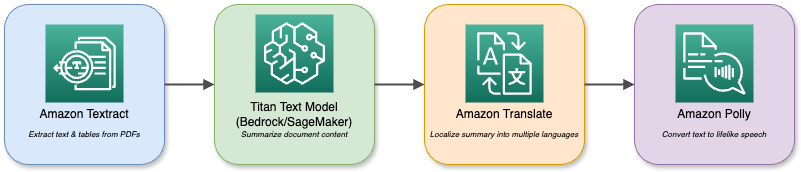
An illustrative diagram of AWS's various services and interactions
Your foundation models in Bedrock or SageMaker can be combined with these services to build complex multi-modal applications.
A document-analysis assistant, for example, uses Textract to ingest PDFs and then uses Titan Text to summarize them before translating the summary into multiple languages and playing it back through Polly. The composable ecosystem enables you to combine various AI capabilities to meet any enterprise requirement.
Generative AI delivers its best results when you use well-architected patterns to address actual business problems.
This section presents four specific implementation blueprints, including retrieval-augmented generation and developer and enterprise assistants, as well as additional high-value scenarios that you can implement today.
The combination of search capabilities with large language models in retrieval-augmented generation produces accurate responses that remain grounded in context. The four-stage pipeline operates as follows:
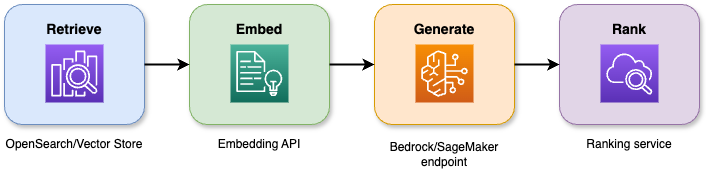
An illustrative diagram showing a retrieval-augmented generation (RAG) architecture.
Benefits and accuracy gains:
Business applications:
AWS CodeWhisperer delivers generative AI directly to developers through their IDEs and CI/CD pipelines to perform boilerplate automation and speed up coding processes:
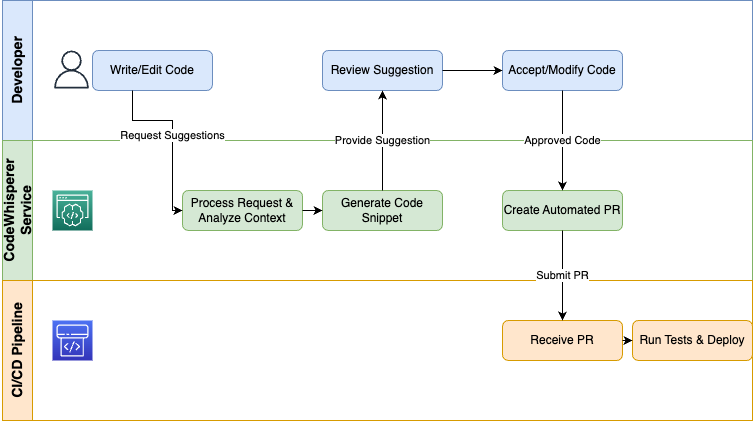
An illustrative diagram showing a code generation workflow.
Organizations that use CodeWhisperer as a developer assistant eliminate repetitive work, enforce coding standards, and enable engineers to dedicate their time to valuable design and debugging activities.
Take into account that CodeWhisperer will become part of Amazon Q Developer.
Amazon Q Business operates as a RAG-powered low-code solution, enabling users to develop conversational assistants that retrieve enterprise data through questions.
Architecture:
Deployment scenarios:
The assistants help organizations streamline knowledge work, reduce operational costs, and enable employees to achieve higher productivity levels.
The value of generative AI extends beyond RAG, code generation, and assistants to various other domains:
Start with these patterns to establish pilots that demonstrate clear ROI before moving on to optimization and scaling across your organization.
Enterprises need to implement security controls and governance practices at every stage of the AI lifecycle when they adopt generative AI.
AWS provides a comprehensive security and compliance framework that spans from physical data centers to application-level policies, enabling confident innovation.
AWS protects generative AI workloads through six concentric security layers:
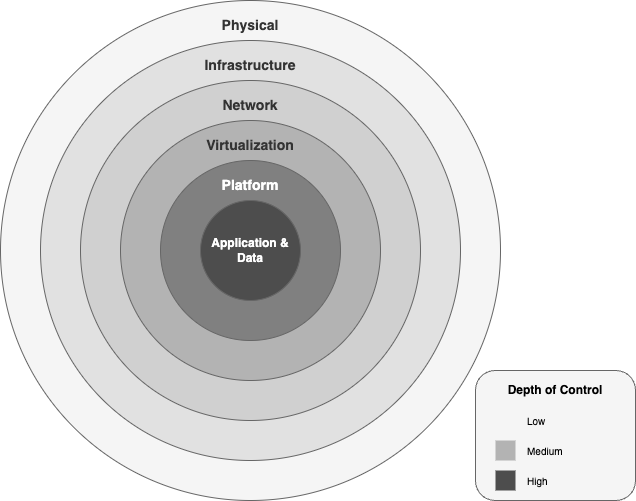
An illustrative diagram of the security layers within the AWS generative AI framework.
Data isolation and compliance:
The development of trust in generative AI requires implementing ethical and safety protocols at each stage of model invocation. AWS implements responsible AI governance through the following framework:
These layers and practices establish a defense-in-depth posture for enterprise generative AI, enabling you to achieve innovation while maintaining the highest standards of security, compliance, and ethical responsibility.
The process of controlling generative AI budgets demands both complete knowledge of pricing mechanisms and continuous cost management practices. This section explains AWS pricing for AI workloads while presenting a mid-sized deployment TCO example and strategies to reduce expenses.
AWS generative AI pricing falls into four main dimensions:
|
Architecture |
Compute cost driver |
Token cost driver |
Best fit |
|
Real-time chatbots |
Many small endpoints running 24×7 |
High request rate, small tokens |
Customer support, Help desks |
|
Batch generation |
Short-lived large instances |
Few large token bursts |
Report generation, Data augmentation |
|
RAG pipelines |
Combined search + inference |
Retrieval token + generation token |
Knowledge-grounded assistants |
Below is a sample monthly TCO for a mid-sized generative AI pilot:
|
Cost item |
Unit cost |
Usage |
Monthly cost |
|
Inference endpoints (Inf1.xl) |
$0.228 /hr |
3 endpoints × 24 hr × 30 days |
$492.48 |
|
Token usage (Titan Express) |
$0.0024 /1 K tokens |
3 M tokens/day × 30 days |
$216.00 |
|
S3 storage (model artifacts) |
$0.023 /GB-month |
10 000 GB |
$230 |
|
Data egress |
$0.09 /GB |
1 TB |
$90 |
|
Glue ETL (feature prep) |
$0.44 /DPU-hour |
20 DPU-hrs |
$8.80 |
|
Total |
$1,037.28 |
Key optimization levers:
Ongoing cost management:
The combination of pricing-aware architecture with targeted optimizations and continuous monitoring enables you to scale generative AI without experiencing excessive costs.
The process of scaling generative AI from concept to production requires a systematic phased methodology. The roadmap provides a step-by-step approach, starting from initial assessments through proof-of-concept pilots to building an enterprise-grade platform that is resilient.
The first step involves checking the feasibility and obtaining stakeholder agreement before proceeding with the full development of the architecture.
The Proof of Concept results in the development of the fundamental platform before the system can be widely adopted.
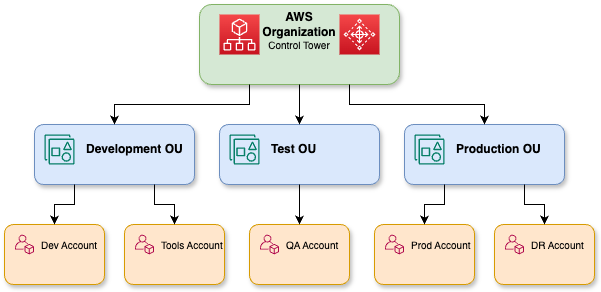
A detailed representation of the AWS organizations.
The phased approach of validation, followed by foundation building and then scaling with governance and partner support, will help you transform your generative AI pilot into an enterprise-wide, robust capability.
Continuous refinement and strong governance practices, implemented after scaling your generative AI platform, ensure the system performs well while maintaining security and regulatory compliance.
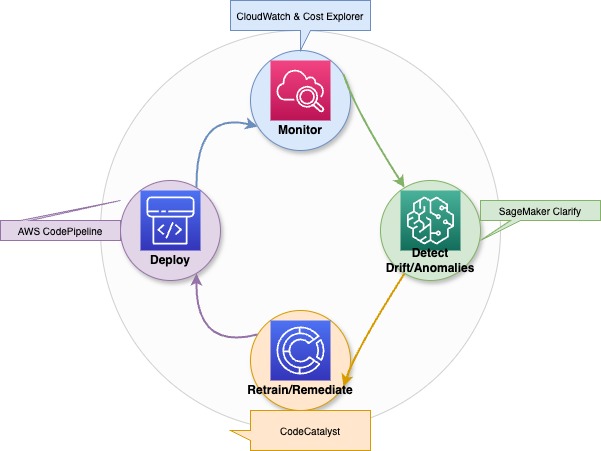
An illustrative diagram showing continuous optimization, drift detection, and retraining processes for generative AI models.
By integrating ongoing optimization and strict audits with organizational learning practices, you can sustain a resilient, trustworthy, and cost-effective generative AI capability.
The AWS generative AI journey can be accelerated through learning paths, communities, and hands-on projects that build confidence and drive real business impact.
AWS generative AI provides a complete end-to-end system, including foundation models, optimized compute, governance, integration, and cost controls, to help enterprises innovate faster and reduce operational overhead while building trusted, multimodal applications at scale.
Through experimentation, continuous learning, and community collaboration, you will achieve the full potential of AWS generative AI to drive real business impact.
Learn more about AWS with these courses!
Track
Course
Course
blog
Kurtis Pykes
14 min
blog
Abid Ali Awan
9 min
blog
Hesam Sheikh Hassani
12 min
blog
Abid Ali Awan
10 min
Tutorial
Rahul Sharma
code-along
Dave Wentzel


