
Cursus
AWS Cloud Practitioner (CLF-C02)
10 h
L'IA générative AWS représente l'avenir des services cloud, car elle permet aux entreprises de créer du contenu automatisé et des tâches cognitives grâce à des modèles de base qui produisent du texte, des images et des vidéos en temps réel.
Dans cet article, je présente un aperçu complet des éléments essentiels des méthodes de déploiement et des cadres de gouvernance nécessaires pour développer des solutions d'IA générative prêtes à être mises en production.
AWS est le premier fournisseur de services cloud, car il propose Amazon Bedrock ainsi qu'une infrastructure informatique spécialisée et de vastes capacités d'intégration qui surpassent les autres plateformes cloud.
Si vous découvrez AWS, ce cours d'introductionvous permettra d'acquérir des bases solides avant de vous plonger dans les spécificités de l'IA générative.
Dans cette section, nous examinerons les éléments constitutifs qui alimentent l'IA générative d'AWS.
Bedrock sert de plan de contrôle géré pour toute l'IA générative sur AWS. Il fournit une API cohérente pour le déploiement, la mise à l'échelle et la sécurisation des modèles de base, depuis la mise à disposition des terminaux jusqu'à la facturation. Vous pouvez ainsi vous concentrer sur la création d'invites et l'intégration de l'IA plutôt que sur la gestion de l'infrastructure.
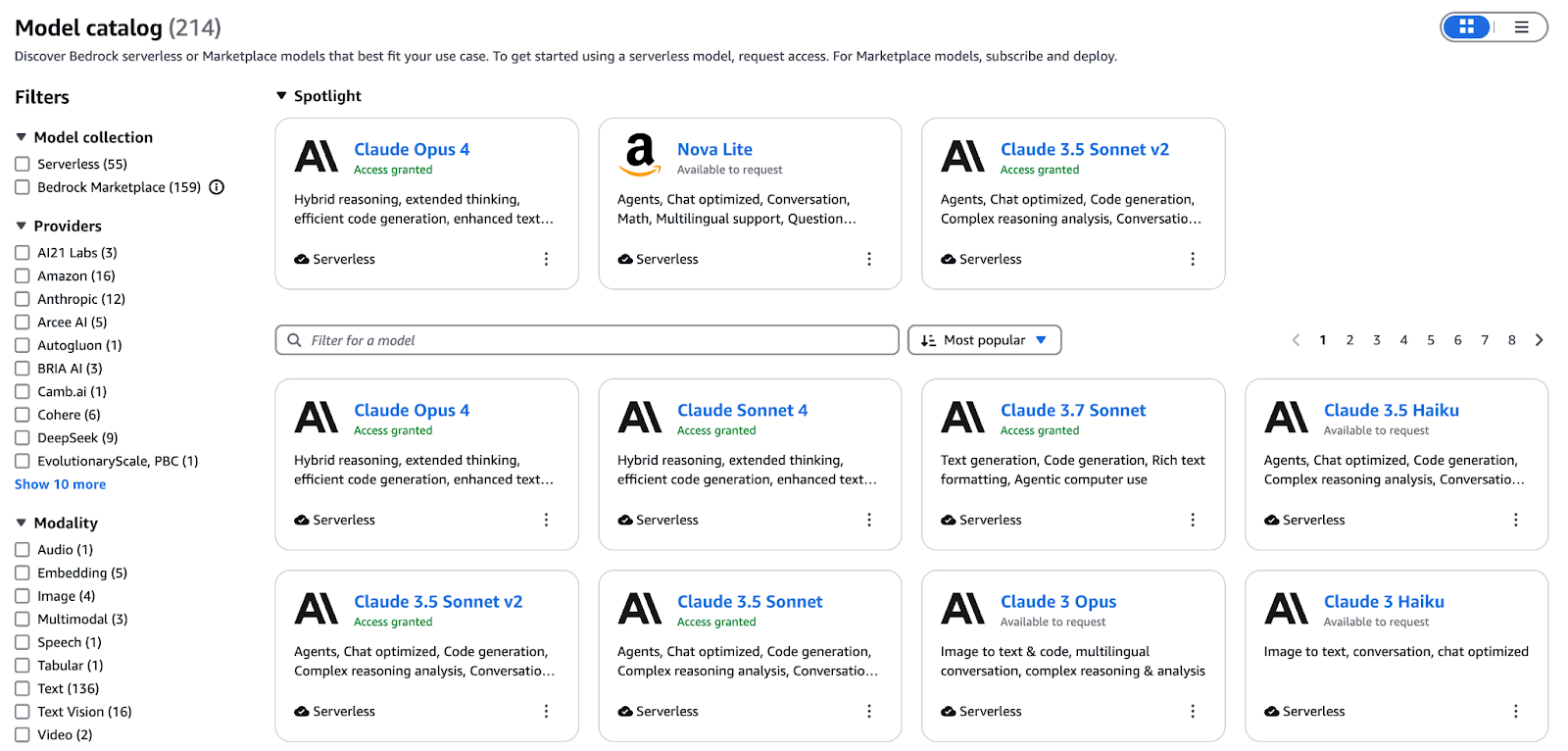
Un diagramme conceptuel illustrant l'écosystème du modèle de base AWS.
Lecatalogue Bedrockunifie les modèles pour le texte, l'image, la vidéo et les intégrations sous une seule interface. Nos principales offres comprennent :
Affinez vos modèles à partir de vos données étiquetées ou poursuivez le pré-entraînement sur des corpus spécifiques à votre domaine via la console Bedrock ou le SDK. Une fois la formation terminée, la suite d'évaluation de Bedrock effectue des comparaisons parallèles et génère des rapports sur la précision, la latence et le coût par jeton, ce qui vous permet de choisir objectivement la variante optimale pour les accords de niveau de service (SLA) de production.
Au-delà des familles Titan et Nova d'AWS, Bedrock vous donne accès à des modèles partenaires d'Anthropic, Cohere, Mistral, AI21 Labs et bien d'autres encore. Tirez parti de cette diversité pour :
Pour en savoir plus sur la manière dont Bedrock orchestre ces modèles de base dans les environnements de production, veuillez consulter ce guide complet sur Amazon Bedrock.
Les familles d'instances EC2 fournies par AWS ont été conçues pour répondre aux besoins spécifiques des opérations de formation et d'inférence.
Formation :
Conclusion :
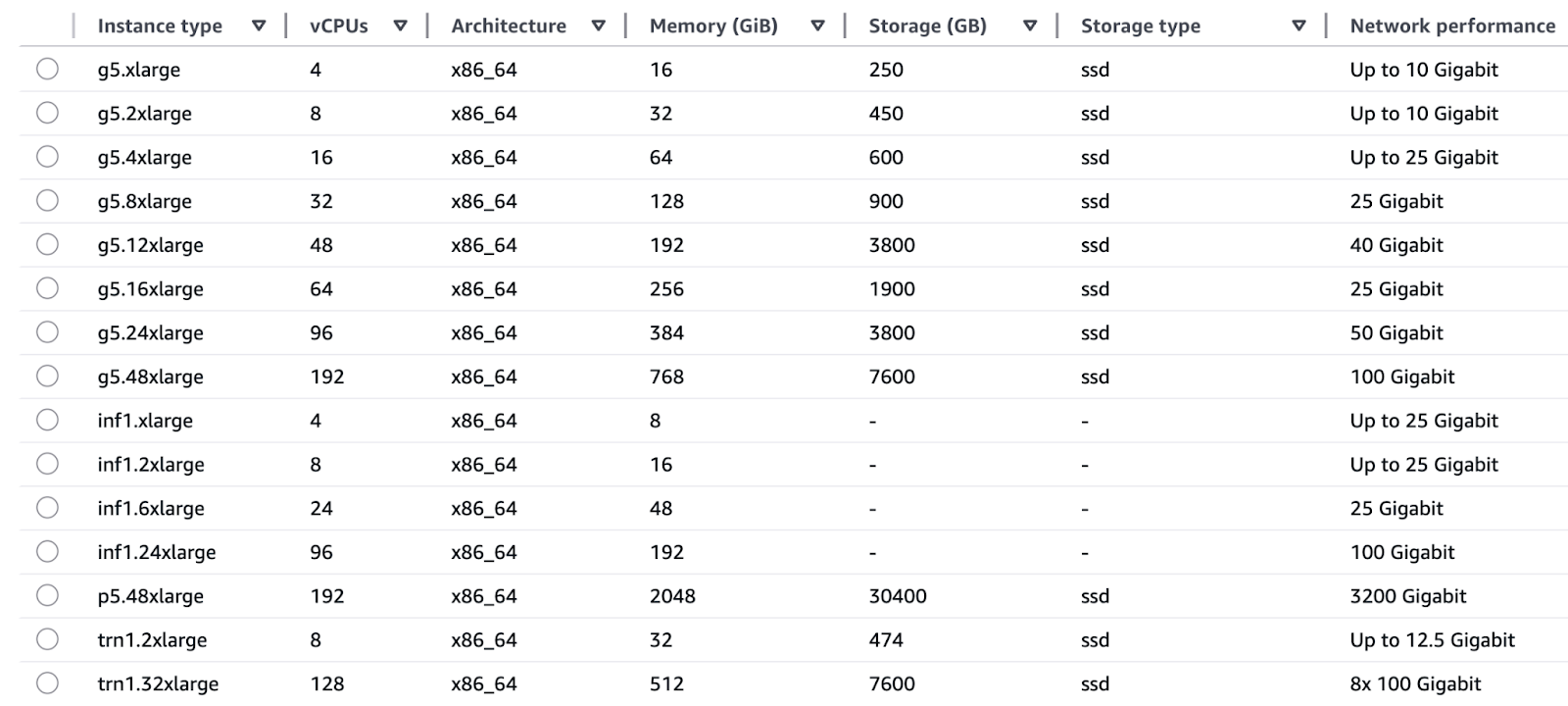
Un schéma illustratif de l'infrastructure informatique optimisée par l'IA d'AWS.
AWS assure une intégration transparente entre ses composants matériels et logiciels conçus sur mesure grâce à Trainium pour la formation et Inferentia pour les puces d'inférence, qui fonctionnent directement avec les services AWS. Cette intégration verticale permet d'obtenir :
Le système AWS Nitro utilise des cartes matérielles dédiées pour exécuter les fonctions de virtualisation, offrant ainsi des vitesses bare metal rapides et une isolation sécurisée :
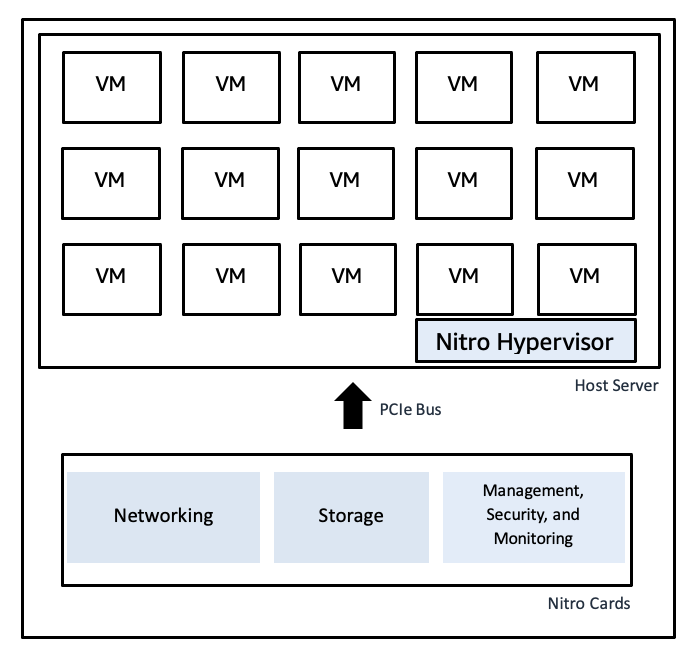 Schéma illustratif du hyperviseur Nitro d'AWS
Schéma illustratif du hyperviseur Nitro d'AWS
Découvrez l'écosystème plus vaste du calcul, du stockage et de l'analyse dans ce courssur la technologie et les services cloud AWS.
La formation de modèles à grande vitesse et les pipelines RAG nécessitent l'accès à des données propres et correctement gérées :
Les capacités d'IA générative d'AWS s'intègrent directement à son écosystème plus large afin de fournir des solutions de bout en bout adaptées à la production. Cette section décrit le processus de combinaison de Bedrock avec ses services associés afin de développer des applications d'IA générative concrètes.
Sélectionnez des modèles de base dans le hub de modèles SageMaker JumpStart et déployez-les immédiatement. Vous pouvez déployer de nombreux modèles open source et propriétaires à l'aide d'un seul bouton avant de les enregistrer directement dans Amazon Bedrock. Les modèles enregistrés dans Bedrock bénéficient des avantages suivants :
L'architecture intégrée permet aux développeurs de créer des prototypesdans SageMaker Studio, puis de les améliorer dans Bedrock avant de les déployer via des pipelines CI/CD sans modification du code.
Ce tutoriel SageMaker vous guide à travers le processus de réglage fin et de déploiement de modèles à l'aide de la plateforme ML phare d'AWS.
 Un diagramme illustratif présentant le cycle de vie unifié du ML avec SageMaker JumpStart et Bedrock.
Un diagramme illustratif présentant le cycle de vie unifié du ML avec SageMaker JumpStart et Bedrock.
Grâce à Bedrock Agents, vous pouvez intégrer l'IA générative à vos applications opérationnelles en récupérant automatiquement les données et en les transformant avant d'exécuter des actions. Un agent ne nécessite qu'une configuration de base pour :
Les fonctionnalités de base des agents permettent aux développeurs de se concentrer sur la logique métier plutôt que sur le code d'intégration, accélérant ainsi la rentabilisation.
Amazon Q est un service entièrement géré permettant de développer des assistants professionnels basés sur la technologie RAG.
Le service intègre la fonctionnalité multimodèle Bedrock avec :
Grâce à Q, les entreprises créent des chatbots destinés à leurs clients, ainsi que des tableaux de bord pour les cadres et des services d'assistance spécifiques à leur domaine, qu'elles déploient en quelques semaines au lieu de plusieurs mois.
La lentille IA générative bien conçue met en œuvre les meilleures pratiques à chaque étape du développement des charges de travail génératives.
La lentille IA générative d'AWS étend les cinq piliers du cadre Well-Architected aux charges de travail génératives. Le cadre comprend des systèmes automatisés de surveillance des modèles et des mécanismes de détection des dérives, ainsi que des déclencheurs de recyclage avec gestion des artefacts de version et suivi des métriques d'inférence.
Voici les piliers :
Pour ceux qui souhaitent obtenir une certification, le cursus AWS Cloud Practitionercorrespond parfaitement aux connaissances fondamentales abordées ici.
Le réseau de partenaires AWS offre un soutien aux entreprises en accélérant leur adoption des services AWS grâce à des accélérateurs de solutions et des services partenaires. Chaque entreprise est unique, c'est pourquoi AWS a mis en place le réseau de partenaires avec des accélérateurs d'IA générative spécifiques pour différents secteurs et cas d'utilisation.
La capacité de l'IA générative à générer de nouveaux contenus ne correspond pas aux exigences des applications du monde réel, qui doivent traiter et comprendre les données sous divers formats de présentation.
AWS fournit un ensemble de services complémentaires qui s'intègrent à vos pipelines génératifs afin de convertir des documents non structurés en données structurées, d'extraire des informations à partir d'images et de permettre des conversations naturelles et la diffusion de résultats dans n'importe quelle langue ou voix.
Voici les plus populaires :
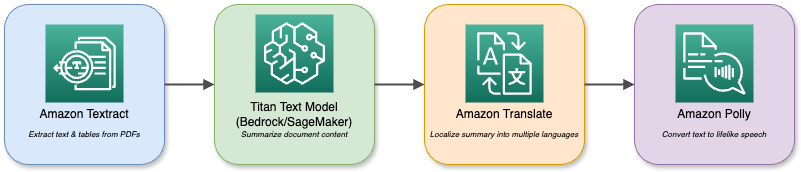
Un diagramme illustratif des différents services AWS et de leurs interactions.
Vos modèles de base dans Bedrock ou SageMaker peuvent être associés à ces services pour créer des applications multimodales complexes.
Un assistant d'analyse de documents, par exemple, utilise Textract pour ingérer des fichiers PDF, puis Titan Text pour les résumer avant de traduire le résumé en plusieurs langues et de le restituer via Polly. L'écosystème modulable vous permet de combiner diverses capacités d'IA afin de répondre à toutes les exigences de votre entreprise.
L'IA générative offre les meilleurs résultats lorsque vous utilisez des modèles bien conçus pour répondre à des problèmes commerciaux concrets.
Cette section présente quatre plans de mise en œuvre spécifiques, notamment la génération augmentée par la récupération et les assistants pour développeurs et entreprises, ainsi que d'autres scénarios à forte valeur ajoutée que vous pouvez mettre en œuvre dès aujourd'hui.
La combinaison des capacités de recherche et des modèles linguistiques volumineux dans la génération augmentée par la récupération produit des réponses précises qui restent ancrées dans le contexte. Le pipeline en quatre étapes fonctionne comme suit :
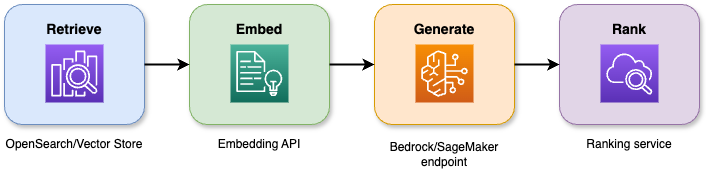
Un diagramme illustratif présentant une architecture de génération augmentée par la récupération (RAG).
Avantages et gains en termes de précision :
Applications commerciales :
AWS CodeWhisperer fournit une IA générative directement aux développeurs via leurs IDE et leurs pipelines CI/CD afin d'automatiser les tâches répétitives et d'accélérer les processus de codage.
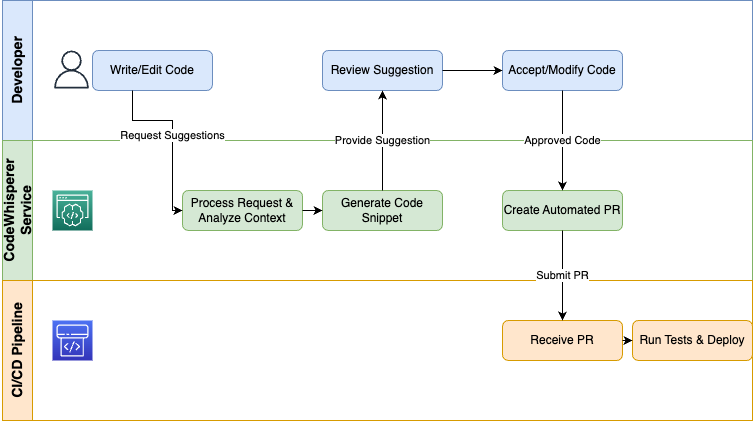
Un diagramme illustratif présentant un processus de génération de code.
Les organisations qui utilisent CodeWhisperer comme assistant de développement éliminent les tâches répétitives, appliquent les normes de codage et permettent aux ingénieurs de consacrer leur temps à des activités de conception et de débogage à forte valeur ajoutée.
Veuillez noterque CodeWhisperer fera désormais partie d'Amazon Q Developer.
Amazon Q Business est une solution low-code basée sur la technologie RAG qui permet aux utilisateurs de développer des assistants conversationnels capables de récupérer des données d'entreprise à partir de questions.
Architecture :
Scénarios de déploiement :
Les assistants aident les organisations à rationaliser le travail intellectuel, à réduire les coûts opérationnels et à permettre aux employés d'atteindre des niveaux de productivité plus élevés.
La valeur de l'IA générative s'étend au-delà du RAG, de la génération de code et des assistants à divers autres domaines :
Commencez par ces modèles pour mettre en place des projets pilotes démontrant un retour sur investissement clair avant de passer à l'optimisation et à la mise à l'échelle dans l'ensemble de votre organisation.
Les entreprises doivent mettre en œuvre des contrôles de sécurité et des pratiques de gouvernance à chaque étape du cycle de vie de l'IA lorsqu'elles adoptent l'IA générative.
AWS fournit un cadre complet de sécurité et de conformité qui s'étend des centres de données physiques aux politiques au niveau des applications, permettant ainsi d'innover en toute confiance.
AWS protège les charges de travail d'IA générative grâce à six couches de sécurité concentriques :
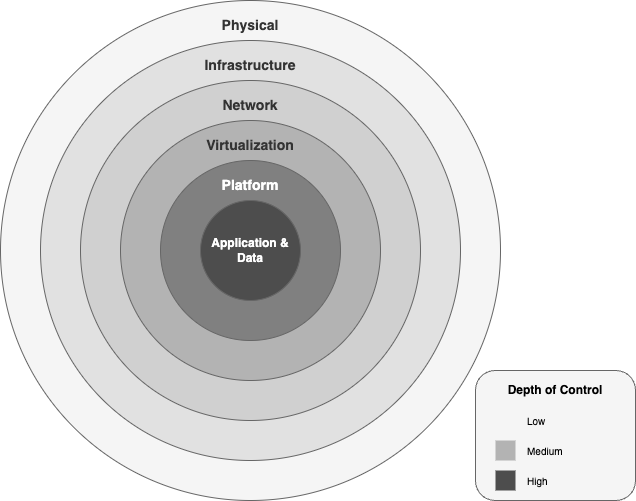
Un diagramme illustratif des couches de sécurité au sein du cadre d'IA générative AWS.
Isolation des données et conformité :
Le développement de la confiance dans l'IA générative nécessite la mise en œuvre de protocoles éthiques et de sécurité à chaque étape de l'invocation du modèle. AWS met en œuvre une gouvernance responsable de l'IA à travers le cadre suivant :
Ces couches et pratiques établissent une posture de défense en profondeur pour l'IA générative d'entreprise, vous permettant d'innover tout en respectant les normes les plus strictes en matière de sécurité, de conformité et de responsabilité éthique.
Le processus de contrôle des budgets consacrés à l'IA générative exige à la fois une connaissance approfondie des mécanismes de tarification et des pratiques de gestion continue des coûts. Cette section explique la tarification AWS pour les charges de travail IA, tout en présentant un exemple de coût total de possession pour un déploiement de taille moyenne et des stratégies pour réduire les dépenses.
La tarification de l'IA générative AWS s'articule autour de quatre dimensions principales :
|
Architecture |
Calculer le facteur de coût |
Facteur de coût des jetons |
Meilleure correspondance |
|
Chatbots en temps réel |
De nombreux petits terminaux fonctionnant 24 heures sur 24, 7 jours sur 7 |
Taux de requêtes élevé, jetons de petite taille |
Assistance clientèle, services d'assistance |
|
Génération par lots |
Instances de grande taille à courte durée de vie |
Peu de pics importants de jetons |
Génération de rapports, augmentation des données |
|
Pipelines RAG |
Recherche combinée + inférence |
Jeton de récupération + jeton de génération |
Assistants basés sur les connaissances |
Vous trouverez ci-dessous un exemple de coût total de possession mensuel pour un projetpilote d'IA générative de taille moyenne:
|
Élément de coût |
Coût unitaire |
Utilisation |
Coût mensuel |
|
Critères d'évaluation de l'inférence (Inf1.xl) |
0,228 $ / heure |
3 critères d'évaluation × 24 heures × 30 jours |
492,48 $ |
|
Utilisation des jetons (Titan Express) |
0,0024 $ / 1 000 jetons |
3 jetons M par jour × 30 jours |
216,00 $ |
|
Stockage S3 (artefacts de modèle) |
0,023 $ / Go par mois |
10 000 GO |
$230 |
|
Sortie des données |
0,09 $ / GO |
1 TO |
$90 |
|
Coller ETL (préparation des fonctionnalités) |
0,44 $ /DPU-heure |
20 heures de travail par jour |
8,80 $ |
|
Total |
1 037,28 $ |
Principauxleviers d'optimisation:
Gestion continue des coûts :
La combinaison d'une architecture sensible aux prix, d'optimisations ciblées et d'une surveillance continue vous permet de faire évoluer l'IA générative sans coûts excessifs.
Le processus de mise à l'échelle de l'IA générative, de la conception à la production, nécessite une méthodologie systématique par étapes. La feuille de route fournit une approche étape par étape, depuis les évaluations initiales jusqu'aux projets pilotes de validation, en passant par la mise en place d'une plateforme résiliente adaptée aux entreprises.
La première étape consiste à vérifier la faisabilité et à obtenir l'accord des parties prenantes avant de procéder au développement complet de l'architecture.
La validation du concept aboutit au développement de la plateforme fondamentale avant que le système puisse être largement adopté.
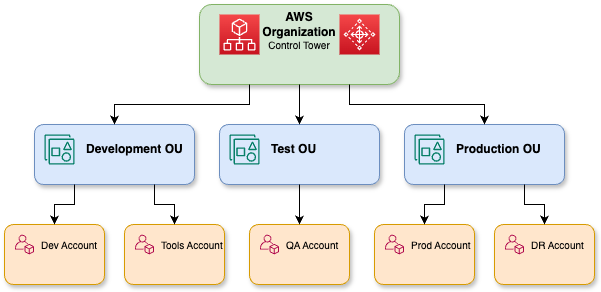
Une représentation détaillée des organisations AWS.
L'approche progressive de la validation, suivie de la mise en place des fondations, puis de la mise à l'échelle avec une gouvernance et le soutien des partenaires, vous aidera à transformer votre projet pilote d'IA générative en une capacité robuste à l'échelle de l'entreprise.
L'amélioration continue et les pratiques de gouvernance rigoureuses, mises en œuvre après la mise à l'échelle de votre plateforme d'IA générative, garantissent les performances du système tout en assurant la sécurité et la conformité réglementaire.
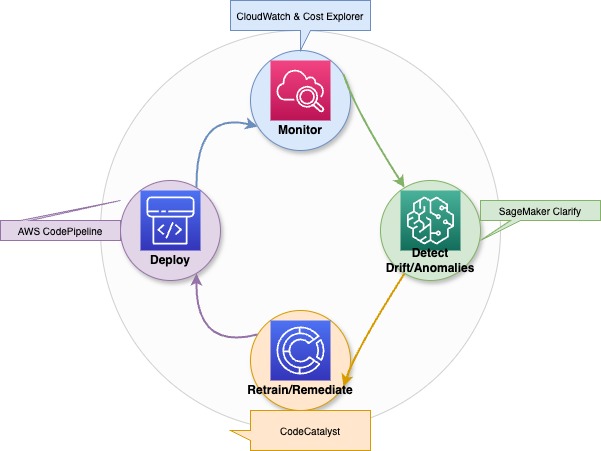
Un diagramme illustratif montrant les processus d'optimisation continue, de détection des dérives et de réentraînement pour les modèles d'IA générative.
En intégrant une optimisation continue et des audits rigoureux à des pratiques d'apprentissage organisationnel, vous pouvez maintenir une capacité d'IA générative résiliente, fiable et rentable.
Le parcours vers l'IA générative AWS peut être accéléré grâce à des parcours d'apprentissage, des communautés et des projets pratiques qui renforcent la confiance et génèrent un impact commercial réel.
L'IA générative AWS fournit un système complet de bout en bout, comprenant des modèles de base, des ressources informatiques optimisées, des fonctions de gouvernance, d'intégration et de contrôle des coûts, afin d'aider les entreprises à innover plus rapidement et à réduire leurs frais généraux tout en créant des applications multimodales fiables à grande échelle.
Grâce à l'expérimentation, à l'apprentissage continu et à la collaboration communautaire, vous exploiterez tout le potentiel de l'IA générative AWS pour générer un impact réel sur votre activité.
Découvrez AWS grâce à ces cours.
Cursus
Cours
Cours