Muchas industrias y organizaciones están utilizando modelos de inteligencia artificial y aprendizaje automático para tomar decisiones informadas. Sin embargo, a medida que estas tecnologías avanzan y se hacen más complejas, los humanos se enfrentan al reto de comprender y seguir el proceso de toma de decisiones de esas soluciones de IA. Este reto puede abordarse mediante la IA explicable (abreviado XAI).
A continuación exploraremos qué es la IA explicable, destacaremos su importancia e ilustraremos sus objetivos y ventajas. En la segunda parte, ofreceremos una visión general y la implementación en Python de dos populares modelos sustitutos, LIME y SHAP, que pueden ayudar a interpretar modelos de aprendizaje automático.
¿Qué es la IA explicable (XAI)?
La IA explicable se refiere a un conjunto de procesos y métodos cuyo objetivo es ofrecer una explicación clara y comprensible para el ser humano de las decisiones generadas por la IA y los modelos de aprendizaje automático.
Integrando una capa de explicabilidad en estos modelos, los científicos de datos y los profesionales del aprendizaje automático pueden crear sistemas más fiables y transparentes para ayudar a una amplia gama de partes interesadas, como desarrolladores, reguladores y usuarios finales.
Generar confianza mediante IA explicable
He aquí algunos principios explicables de la IA que pueden contribuir a generar confianza:
- Transparencia. Garantizar que las partes interesadas comprendan el proceso de toma de decisiones de los modelos.
- Equidad. Garantizar que las decisiones de los modelos sean justas para todos, incluidas las personas pertenecientes a grupos protegidos (raza, religión, sexo, discapacidad, etnia).
- Confianza. Evaluación del nivel de confianza de los usuarios humanos que utilizan el sistema de IA.
- Robustness. Ser resistente a los cambios en los datos de entrada o en los parámetros del modelo, manteniendo un rendimiento coherente y fiable incluso ante la incertidumbre o situaciones inesperadas.
- Privacidad. Garantizar la protección de la información sensible de los usuarios.
- Interpretabilidad. Ofrecer explicaciones comprensibles para el ser humano sobre sus predicciones y resultados.
La aplicación de la IA explicable tiene varias ventajas. Para los responsables de la toma de decisiones y otras partes interesadas, ofrece una comprensión clara de los fundamentos de las decisiones basadas en la IA, lo que les permite tomar decisiones mejor informadas. También ayuda a identificar posibles sesgos o errores en los modelos, lo que conduce a resultados más precisos y justos.
Ejemplos explicables de IA
Existen dos grandes categorías de explicabilidad de los modelos: los métodos específicos de los modelos y los métodos agnósticos de los modelos. En esta sección, comprenderemos la diferencia entre ambos, centrándonos específicamente en los métodos agnósticos del modelo.
Ambas técnicas pueden ofrecer información valiosa sobre el funcionamiento interno de los modelos de aprendizaje automático, al tiempo que garantizan que los modelos son eficaces y responsables.
Para ilustrar mejor estas herramientas, utilizaremos el conjunto de datos sobre diabetes de Kaggle. En primer lugar, construiremos un clasificador sencillo y, a continuación, aplicaremos la explicabilidad. El código fuente completo está disponible en este libro de trabajo de DataLab.
Construir clasificador
Se construye un clasificador Random Forest para predecir los resultados de la diabetes utilizando el conjunto de datos de diabetes. El código se divide en varios pasos: (1) importar bibliotecas relevantes, (2) crear conjuntos de datos de entrenamiento y prueba, (3) construir el modelo y (4) informar de las métricas de rendimiento a través del informe de clasificación.
# Load useful libraries
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Separate Features and Target Variables
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Create Train & Test Data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
stratify =y,
random_state = 13)
# Build the model
rf_clf = RandomForestClassifier(max_features=2, n_estimators =100 ,bootstrap = True)
rf_clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = rf_clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))La última sentencia de impresión genera el siguiente informe:
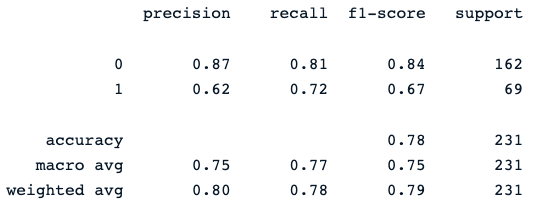
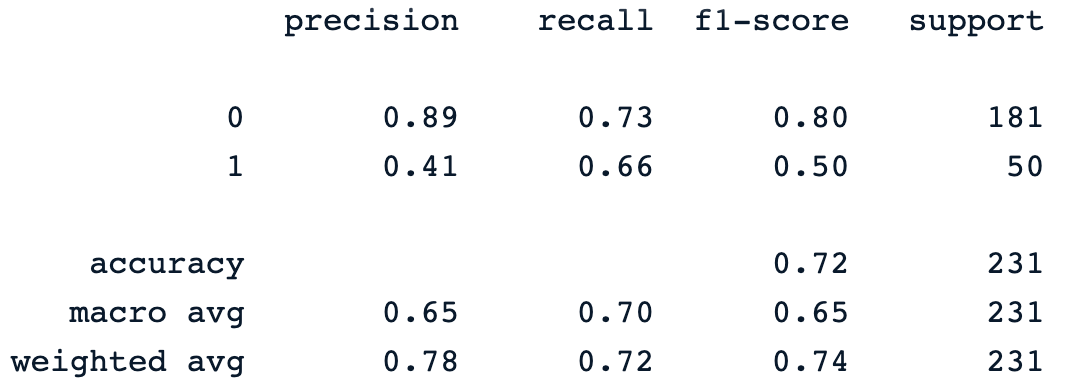
El clasificador de bosque aleatorio ofrece un rendimiento decente en la predicción de los resultados de la diabetes, con un margen obvio de mejora utilizando diferentes modelos.
Ahora podemos integrar la capa de explicabilidad en este modelo para ofrecer más información sobre sus predicciones. La siguiente sección se centrará en las dos grandes categorías de explicabilidad de los modelos: los métodos específicos de los modelos y los métodos agnósticos de los modelos.
Nuestra Clasificación en el aprendizaje automático: Una introducción artículo le ayuda a aprender acerca de la clasificación en el aprendizaje automático, mirando a lo que es, cómo se utiliza, y algunos ejemplos de algoritmos de clasificación.
Métodos de diagnóstico de modelos
Estos métodos pueden aplicarse a cualquier modelo de aprendizaje automático, independientemente de su estructura o tipo. Se centran en analizar el par entrada-salida de las características. En esta sección se presentan y discuten LIME y SHAP, dos modelos sustitutos ampliamente utilizados.
SHAP
Son las siglas de SHapley AdditiveexPlanations. Este método pretende explicar la predicción de una instancia/observación calculando la contribución de cada característica a la predicción, y puede instalarse utilizando el siguiente comando pip.
!pip install shapDespués de la instalación:
- Se importa la biblioteca principal de shap.
- La clase TreeExplainer se utiliza para explicar modelos basados en árboles, junto con la clase initjs.
- shape.initjs() inicializa el código JavaScript necesario para mostrar visualizaciones SHAP en un entorno de cuaderno jupyter.
- Por último, tras instanciar la clase TreeExplainer con el clasificador de bosque aleatorio, se calculan los valores de forma para cada característica de cada instancia del conjunto de datos de prueba.
import shap
import matplotlib.pyplot as plt
# load JS visualization code to notebook
shap.initjs()
# Create the explainer
explainer = shap.TreeExplainer(rf_clf)
shap_values = explainer.shap_values(X_test)SHAP ofrece una serie de herramientas de visualización para mejorar la interpretabilidad del modelo, y en la siguiente sección se analizarán dos de ellas: (1) importancia de la variable con el gráfico de resumen, (2) gráfico de resumen de un objetivo específico y (3) gráfico de dependencia.
Importancia de las variables con gráfico de síntesis
En este gráfico, las características se clasifican por sus valores SHAP medios, mostrando las más importantes en la parte superior y las menos importantes en la inferior mediante la función summary_plot(). Esto ayuda a comprender el impacto de cada característica en las predicciones del modelo.
print("Variable Importance Plot - Global Interpretation")
figure = plt.figure()
shap.summary_plot(shap_values, X_test)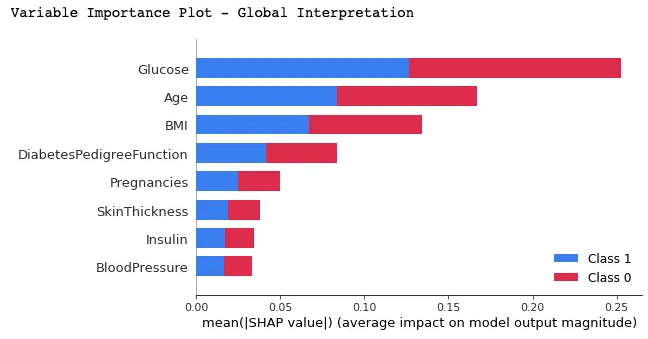
A continuación se expone la interpretación que puede hacerse del gráfico anterior:
- Podemos observar que los colores rojo y azul ocupan la mitad de los rectángulos horizontales para cada clase. Esto significa que cada característica tiene el mismo impacto en la clasificación de los casos de diabetes (etiqueta=1) y de no diabetes (etiqueta=0).
- Sin embargo, la glucosa, la edad y el IMC son las tres primeras características con mayor poder predictivo.
- Por otro lado, Embarazos, Escaras, Insulina y Presión arterial no contribuyen tanto como las tres primeras características.
Parcela resumen en una etiqueta específica
Este enfoque puede proporcionar una visión más detallada del impacto de cada característica en un resultado específico (etiqueta).
En el ejemplo siguiente, shap_values[1] se utiliza para representar los valores SHAP de las instancias clasificadas como etiqueta 1 (padece diabetes).
shap.summary_plot(shap_values[1], X_test)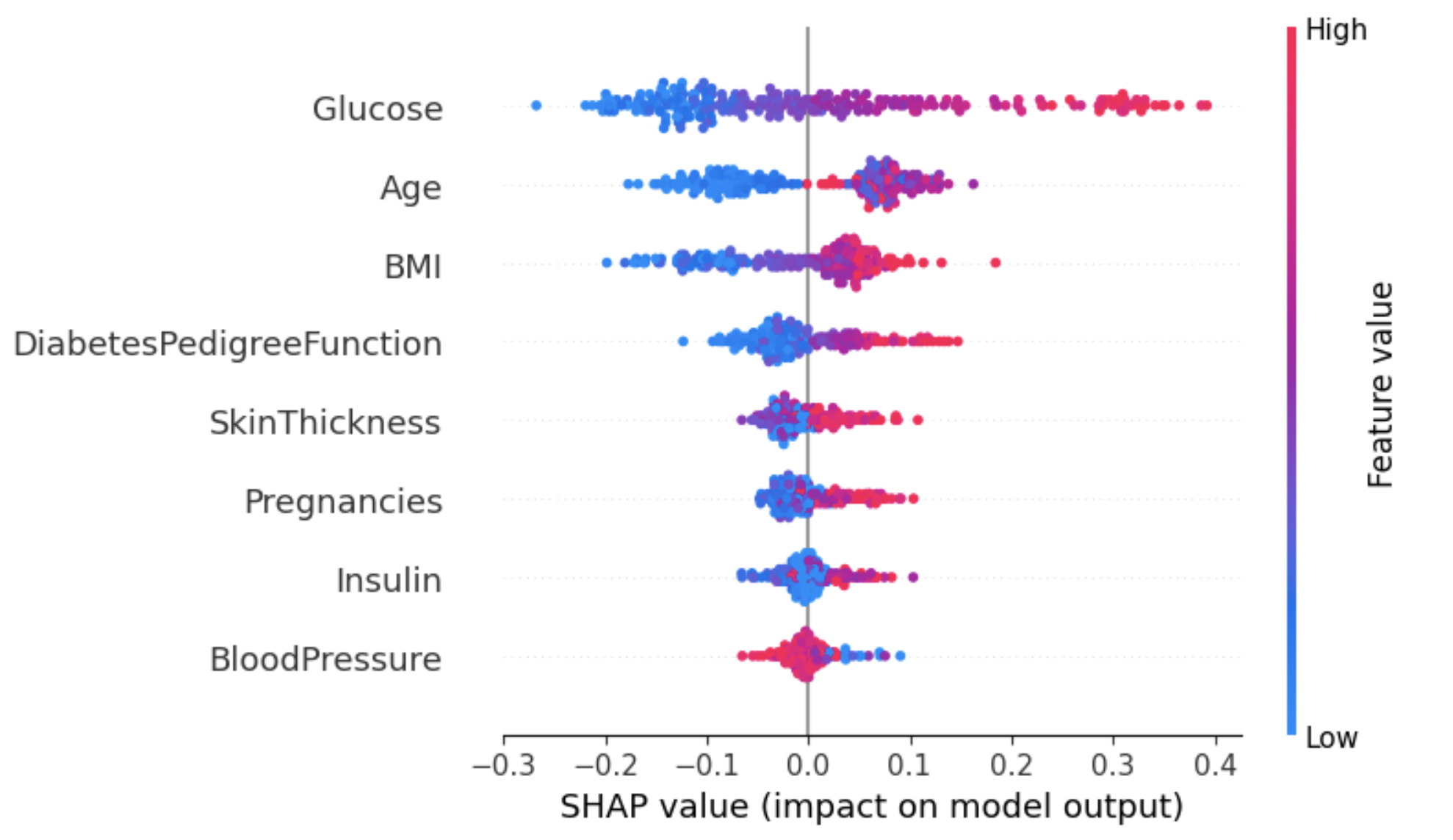
Del gráfico anterior:
- El eje Y representa las características clasificadas por sus valores SHAP absolutos medios, de forma similar al gráfico de la imagen 2.
- El eje X representa los valores SHAP. Los valores positivos de una característica determinada acercan la predicción del modelo a la etiqueta examinada (etiqueta=1). Por el contrario, los valores negativos empujan hacia la clase opuesta (etiqueta=0).
- Un individuo con un nivel alto de glucosa (puntos rojos) tiene probabilidades de que se le diagnostique diabetes (resultado positivo), mientras que un nivel bajo de glucosa conduce a que no se le diagnostique diabetes.
- Del mismo modo, los pacientes que envejecen tienen más probabilidades de que se les diagnostique diabetes. Sin embargo, el modelo parece incierto sobre el diagnóstico para los pacientes más jóvenes.
Una forma de abordar esta ambigüedad para el atributo Edad es utilizar el gráfico de dependencia para obtener más información.
Gráfico de dependencia
A diferencia de los gráficos de resumen, los gráficos de dependencia muestran la relación entre una característica específica y el resultado previsto para cada instancia dentro de los datos. Este análisis se realiza por múltiples razones y no se limita a obtener información más detallada y validar la importancia de la característica analizada confirmando o cuestionando los resultados de los gráficos de resumen u otras medidas de importancia global de la característica.
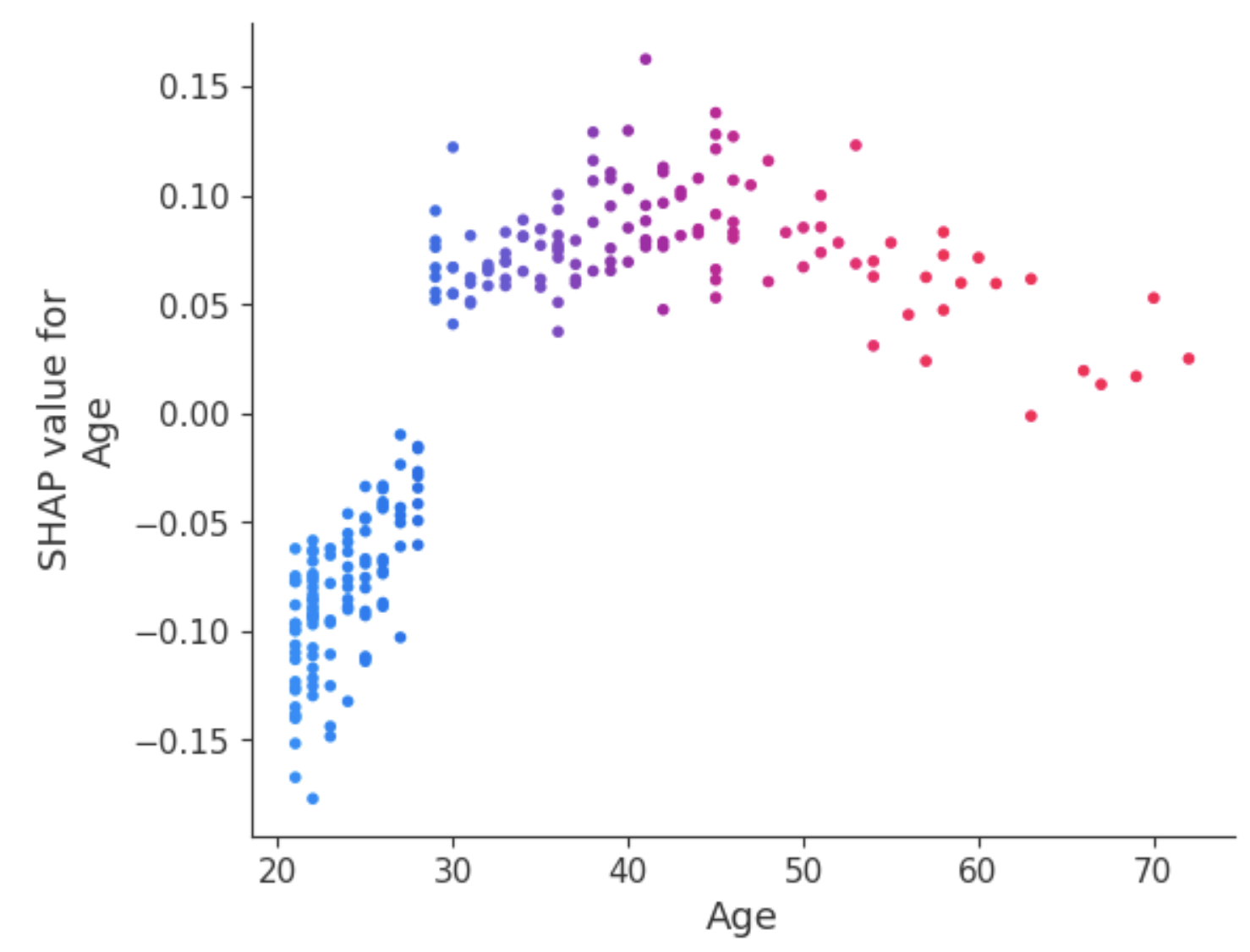
El gráfico de dependencia revela que los pacientes menores de 30 años tienen menos riesgo de ser diagnosticados de diabetes. En cambio, las personas mayores de 30 años tienen más probabilidades de que se les diagnostique diabetes.
CAL
Explicaciones agnósticas de modelos interpretables locales (abreviado LIME). En lugar de proporcionar una comprensión global del modelo en todo el conjunto de datos, LIME se centra en explicar la predicción del modelo para instancias individuales.
LIME explainer puede configurarse siguiendo dos pasos principales: (1) importar el módulo de cal, y (2) ajustar el explicador utilizando los datos de entrenamiento y los objetivos. Durante esta fase, el modo se establece en clasificación, que corresponde a la tarea que se está realizando.
# Import the LimeTabularExplainer module
from lime.lime_tabular import LimeTabularExplainer
# Get the class names
class_names = ['Has diabetes', 'No diabetes']
# Get the feature names
feature_names = list(X_train.columns)
# Fit the Explainer on the training data set using the LimeTabularExplainer
explainer = LimeTabularExplainer(X_train.values, feature_names =
feature_names,
class_names = class_names,
mode = 'classification')El siguiente fragmento de código genera y muestra una explicación LIME para la octava instancia de los datos de prueba utilizando el clasificador de bosque aleatorio y presentando la contribución final de características en un formato tabular.
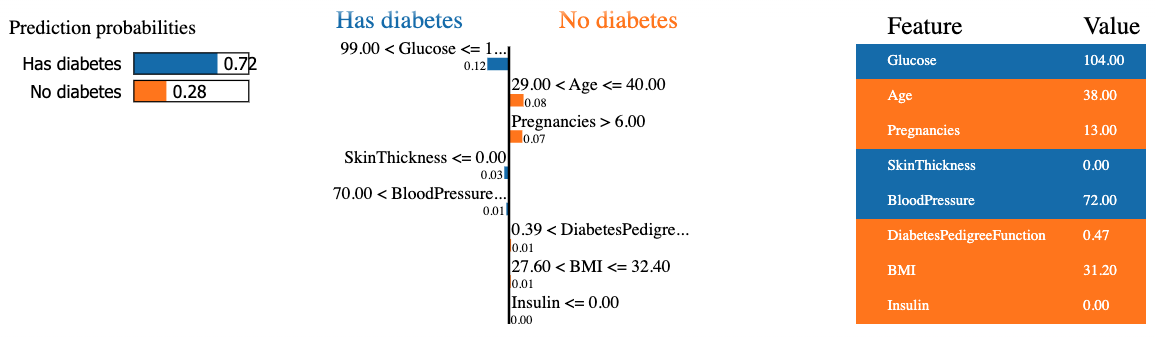
El resultado contiene tres informaciones principales de izquierda a derecha: (1) las predicciones del modelo, (2) las contribuciones de las características y (3) el valor real de cada característica.
Podemos observar que se predice que el octavo paciente tiene diabetes con un 72% de confianza. Las razones que llevaron al modelo a tomar esta decisión se deben a que:
- El nivel de glucosa del paciente es superior a 99.
- La tensión arterial es superior a 70.
Estos valores pueden comprobarse en la tabla de la derecha.
Métodos específicos para cada modelo
A diferencia de los métodos agnósticos, estos métodos sólo pueden aplicarse a una categoría limitada de modelos. Algunos de esos modelos son la regresión lineal, los árboles de decisión y la interpretabilidad de redes neuronales. Diferentes técnicas como DeepLIFT, Grad-CAM o Integrated Gradients pueden aprovecharse para explicar modelos de aprendizaje profundo.
Cuando se utiliza un modelo de árbol de decisión, se puede generar un árbol gráfico con la función plot_tree de scikit-learn para explicar el proceso de toma de decisiones del modelo de arriba abajo, y a continuación se ofrece una ilustración.
El artículo Deep Learning - A Tutorial for Data Scientists responderá a las preguntas más frecuentes sobre el aprendizaje profundo y explora diversos aspectos del aprendizaje profundo con ejemplos de la vida real.
Vamos a entrenar un clasificador de árbol de decisión con hiperparámetros específicos como max_depth, y min_samples_leaf antes de generar el árbol gráfico.
from sklearn.tree import DecisionTreeClassifier, plot_tree
dt_clf = DecisionTreeClassifier(max_depth = 3, min_samples_leaf = 2)
dt_clf.fit(X_train, y_train)
# Predict on the test data and evaluate the model
y_pred = dt_clf.predict(X_test)
print(classification_report(y_pred, y_test))La sentencia print anterior genera el siguiente informe de clasificación del modelo.
Y el proceso de toma de decisiones del modelo puede visualizarse a partir del siguiente código:
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_clf,
feature_names = feature_names,
class_names = class_names,
filled=True)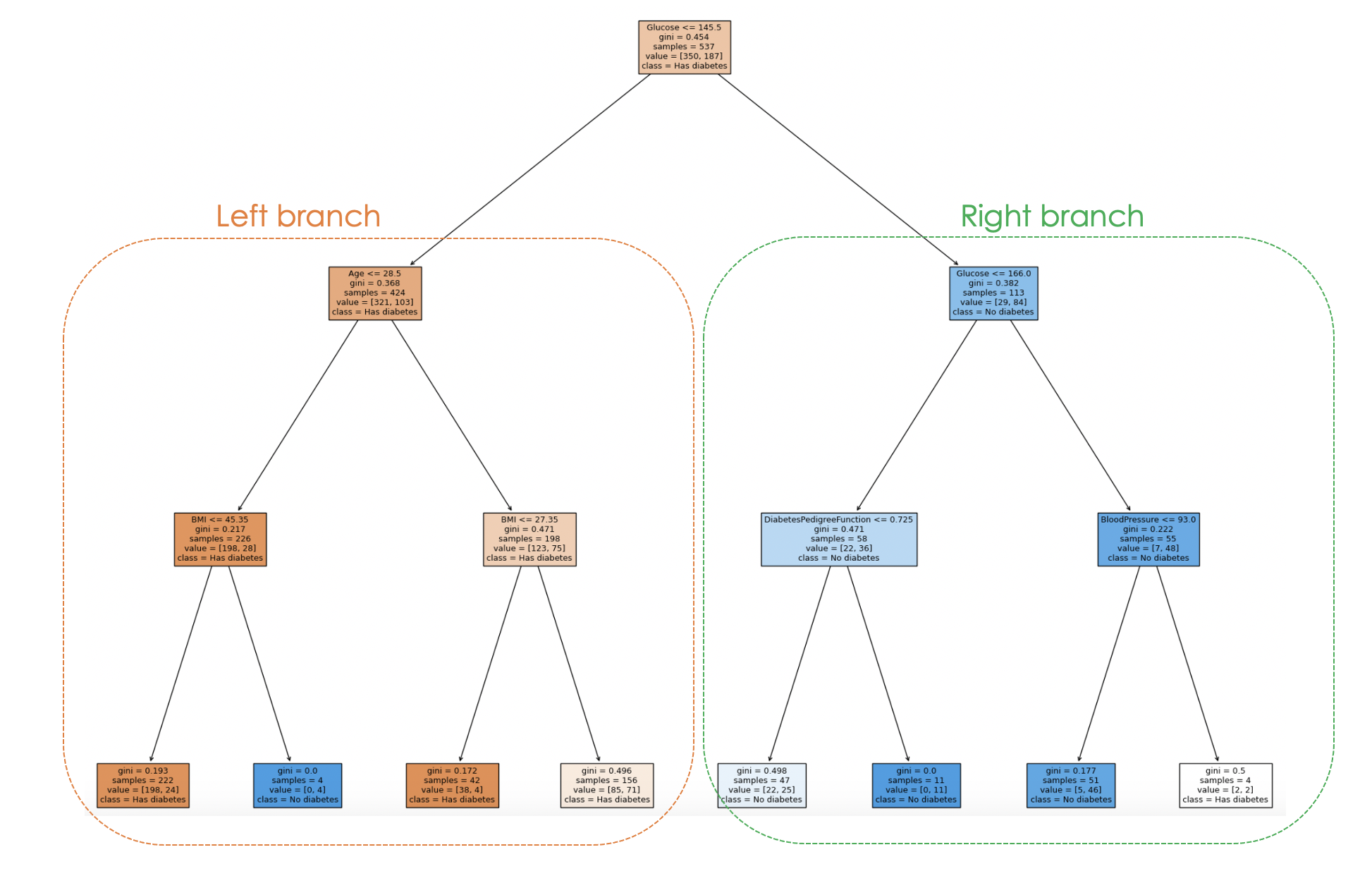
Al examinar la estructura de árbol, se puede seguir el proceso de toma de decisiones de cada muestra, lo que permite comprender el comportamiento del modelo y su interpretabilidad.
En el gráfico anterior, cada nodo representa una decisión o división basada en un valor de característica específico. Para cada nodo interno, el gráfico muestra la característica utilizada para la división, el valor del criterio de división, la impureza de Gini y el número de muestras que llegan a ese nodo.
En los nodos de las hojas aparecen la clase mayoritaria y el número de muestras. Además, los colores de los nodos representan la clase mayoritaria, y la intensidad del color indica la proporción de la clase dominante dentro de ese nodo. Por ejemplo, los nodos naranjas de la rama izquierda corresponden a la etiqueta diabetes, mientras que el azul corresponde a no diabetes.
Retos de la XAI y perspectivas de futuro
A medida que la tecnología de IA avanza y se hace más sofisticada, comprender e interpretar los algoritmos para discernir cómo producen resultados es cada vez más difícil, lo que permite a los investigadores seguir explorando nuevos enfoques y mejorando los existentes.
Muchos modelos de IA explicables requieren simplificar el modelo subyacente, lo que conlleva una pérdida de rendimiento predictivo. Además, es posible que los métodos actuales de explicabilidad no abarquen todos los aspectos del proceso de toma de decisiones, lo que puede limitar el beneficio de la explicación, especialmente cuando se trata de modelos más complejos.
Los nuevos métodos de investigación se centran en mejorar las técnicas explicables de la IA mediante el desarrollo de algoritmos más eficaces para abordar las cuestiones éticas al tiempo que se crean explicaciones fáciles de usar.
Por último, con la investigación en curso, es más probable que dispongamos de métodos más sofisticados que fomenten la transparencia, la fiabilidad y la equidad.
Conclusión
Este artículo ha proporcionado una buena visión general de lo que es la IA explicable y algunos principios que contribuyen a generar confianza y pueden proporcionar a los científicos de datos y a otras partes interesadas los conocimientos necesarios para crear modelos fiables que ayuden a tomar decisiones procesables.
También cubrimos los métodos agnósticos y específicos del modelo, centrándonos especialmente en el primero utilizando LIME y SHAP. Además, se han destacado los retos, las limitaciones y algunas áreas de investigación sobre la IA explicable.
Para obtener más información sobre la ética que hay detrás de esta tecnología, consulte nuestro curso Introducción a la ética de los datos, que abarca los principios de la ética de los datos, su relación con la ética de la IA y sus características en las diferentes etapas del ciclo de vida de los datos.


