
Lernpfad
AWS Cloud Practitioner (CLF-C02)
10 Std.
Die generative KI von AWS ist die Zukunft der Cloud-Services, weil sie Unternehmen ermöglicht, automatisierte Inhalte und Wissensarbeit über Basismodelle zu erstellen, die Texte, Bilder und Videos in Echtzeit produzieren.
In diesem Artikel gebe ich einen umfassenden Überblick über die wichtigsten Elemente von Bereitstellungsmethoden und Governance-Frameworks, die für die Entwicklung produktionsreifer generativer KI-Lösungen erforderlich sind.
AWS ist der führende Cloud-Anbieter, weil es Amazon Bedrock zusammen mit einer speziellen Recheninfrastruktur und umfassenden Integrationsmöglichkeiten anbietet, die andere Cloud-Plattformen übertreffen.
Wenn du noch nicht mit AWS vertraut bist,bekommst du indiesem Einführungskurseine solide Grundlage, bevor du dich mit den Besonderheiten der generativen KI beschäftigst.
In diesem Abschnitt schauen wir uns die Bausteine an, die die generative KI von AWS zum Laufen bringen.
Bedrock ist die verwaltete Steuerungsebene für alle generativen KI-Lösungen auf AWS. Es bietet eine einheitliche API für die Bereitstellung, Skalierung und Sicherung von Basismodellen, von der Endpunktbereitstellung bis zur Abrechnung. So kannst du dich ganz auf die Erstellung von Eingabeaufforderungen und die Integration von KI konzentrieren, anstatt dich um die Verwaltung der Infrastruktur zu kümmern.
Ein Konzeptdiagramm, das das AWS-Foundation-Modell-Ökosystem zeigt
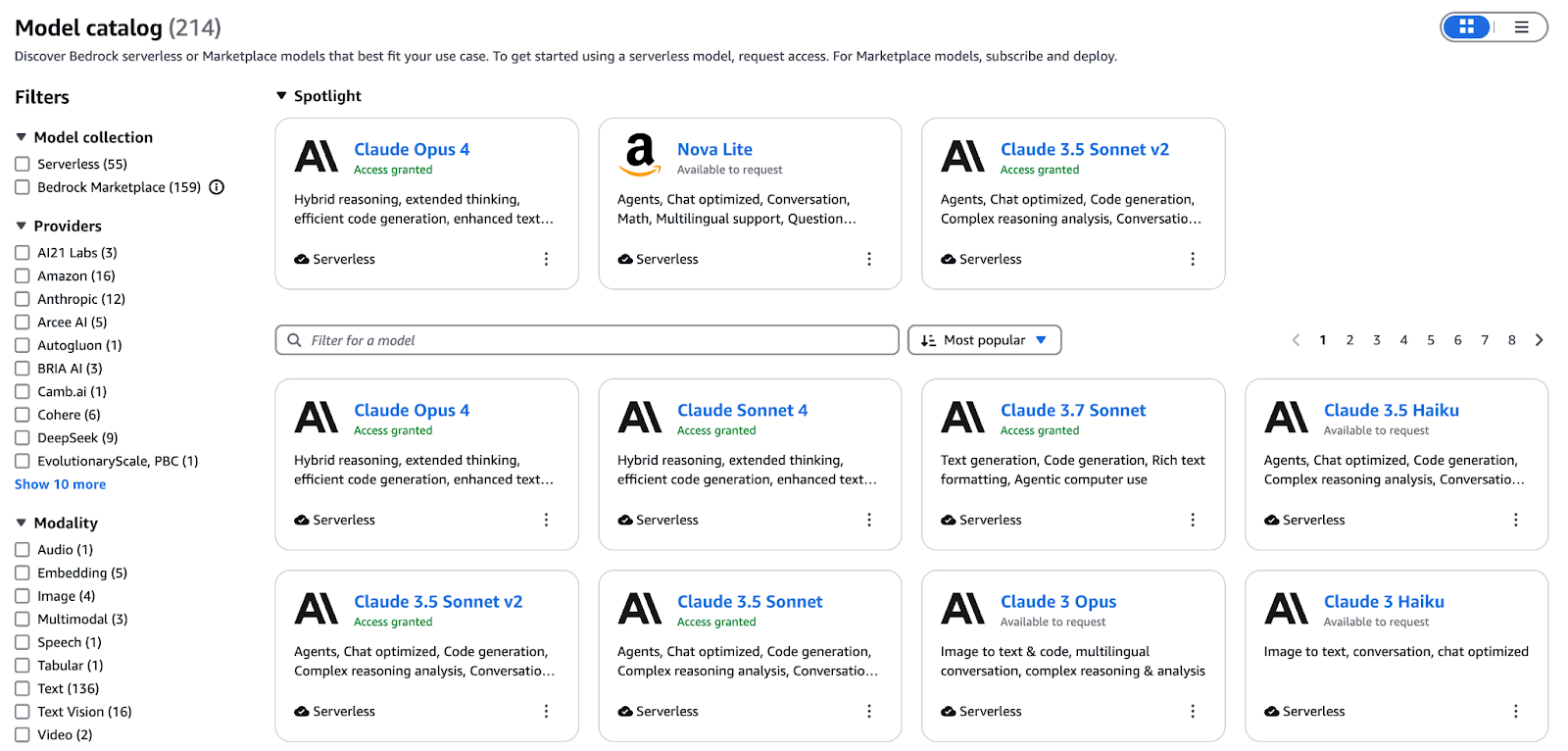
Der Bedrock -Katalog „“ bringt Modelle für Text, Bilder, Videos und Einbettungen unter einer einzigen Oberfläche zusammen. Zu den wichtigsten Angeboten gehören:
Optimiere Modelle anhand deiner beschrifteten Daten oder mach weiter mit dem Vortraining auf domänenspezifischen Korpora über die Bedrock-Konsole oder das SDK. Nach dem Training macht die Bewertungssuite von Bedrock Vergleiche und zeigt dir die Genauigkeit, Latenz und Kosten pro Token, damit du die beste Variante für deine Produktions-SLAs objektiv auswählen kannst.
Neben den Titan- und Nova-Familien von AWS kannst du mit Bedrock auch Modelle von Partnern wie Anthropic, Cohere, Mistral, AI21 Labs und anderen nutzen. Nutzen Sie diese Bandbreite, um:
Wenn du genauer wissen willst, wie Bedrock diese Basismodelle in Produktionsumgebungen zusammenbringt, schau dir diese komplette Anleitung zu Amazon Bedrockan .
Die EC2-Instanzfamilien von AWS sind genau auf die besonderen Anforderungen von Trainings- und Inferenzvorgängen zugeschnitten.
Schulung:
Schlussfolgerung:
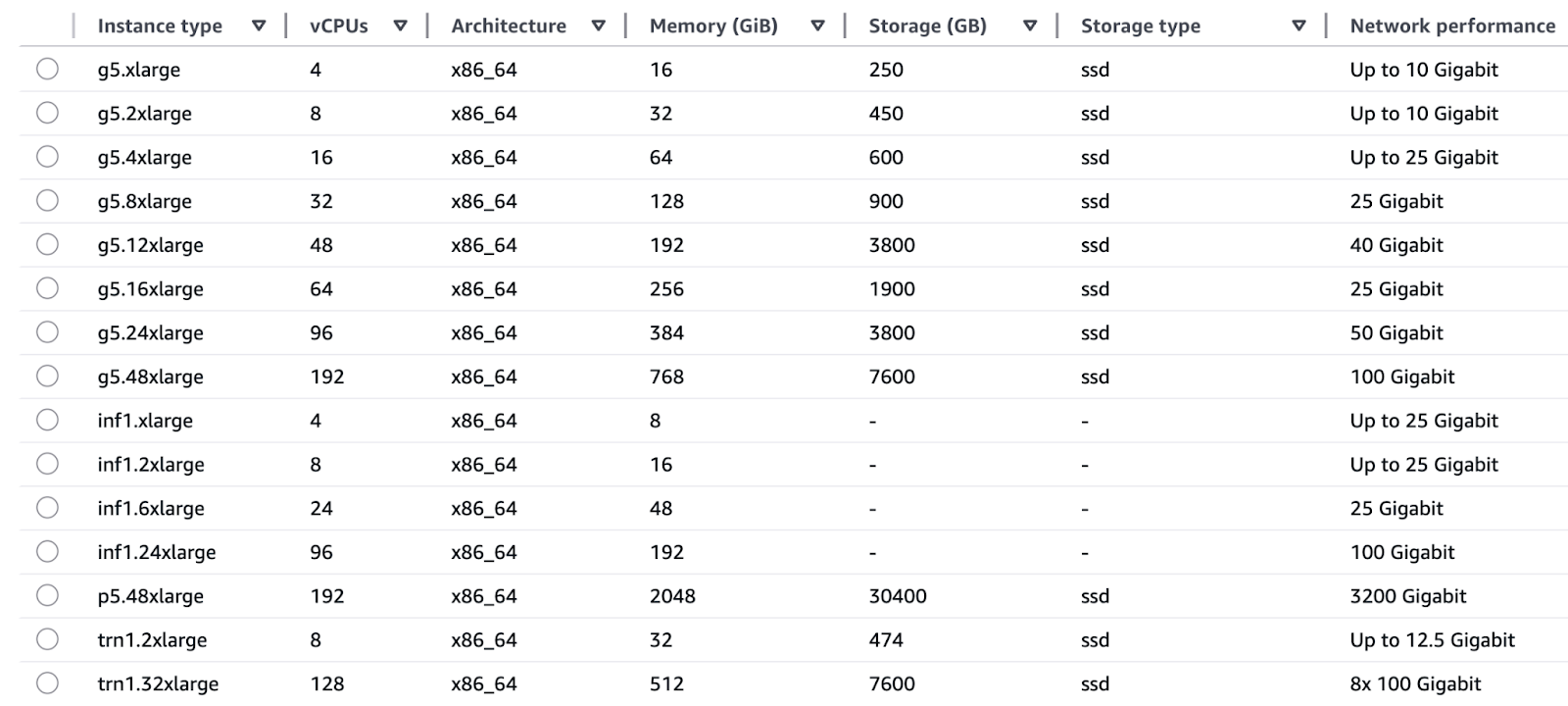
Ein Diagramm, das die KI-optimierte Recheninfrastruktur von AWS zeigt.
AWS schafft eine nahtlose Integration zwischen seiner maßgeschneiderten Hardware und Softwarekomponenten durch Trainium für Schulungen und Inferentia für Inferenzchips, die direkt mit AWS-Diensten zusammenarbeiten. Diese vertikale Integration bringt folgende Vorteile:
Das AWS Nitro System nutzt spezielle Hardwarekarten für die Virtualisierungsfunktionen und bietet so schnelle Bare-Metal-Geschwindigkeiten zusammen mit sicherer Isolierung:
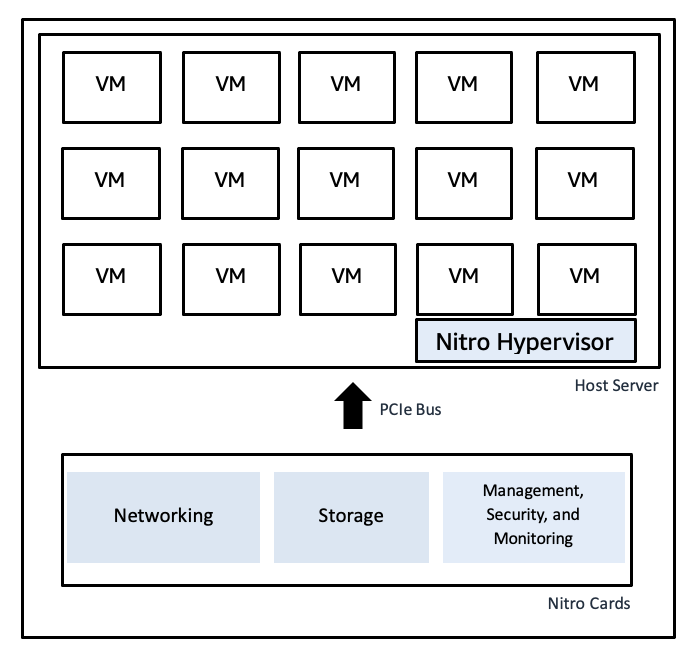 Ein Diagramm, das AWS' Nitro Hypervisor zeigt Nitro Hypervisor
Ein Diagramm, das AWS' Nitro Hypervisor zeigt Nitro Hypervisor
Entdecke in diesem Kursüber AWS Cloud-Technologie und -Servicesdas umfassende Ökosystem aus Rechenleistung, Speicher und Analysen.
Modelltraining mit hoher Geschwindigkeit und RAG-Pipelines brauchen Daten, die sauber und gut verwaltet sind:
Die generativen KI-Funktionen von AWS lassen sich direkt in das umfassende AWS-Ökosystem integrieren und bieten so durchgängige Lösungen für die Produktion. In diesem Abschnitt wird erklärt, wie man Bedrock mit den dazugehörigen Diensten kombiniert, um echte generative KI-Anwendungen zu entwickeln.
Such dir einfach ein paar Basismodelle aus dem Modell-Hub von SageMaker JumpStart aus und leg los. Du kannst ganz einfach mehrere Open-Source- und proprietäre Modelle über einen einzigen Knopf bereitstellen, bevor du sie direkt in Amazon Bedrock registrierst. Die in Bedrock eingegebenen Modelle haben Zugriff auf:
Dank der integrierten Architektur können Entwickler Prototypenin SageMaker Studio erstellen, sie dann in Bedrock verbessern und schließlich über CI/CD-Pipelines ohne Codeänderungen bereitstellen.
Dieses SageMaker-Tutorial zeigt dir Schritt für Schritt, wie du Modelle mit der ML-Plattform von AWS optimierst und bereitstellst.
 Ein Diagramm, das den einheitlichen ML-Lebenszyklus mit SageMaker JumpStart und Bedrock zeigt.
Ein Diagramm, das den einheitlichen ML-Lebenszyklus mit SageMaker JumpStart und Bedrock zeigt.
Mit Bedrock Agents kannst du generative KI in deine operativen Anwendungen einbauen, indem du Daten automatisch abrufst und umwandelst, bevor du Aktionen ausführst. Ein Agent braucht nur ein paar einfache Einstellungen, um:
Dank der pipelinegestützten Funktionen der Agenten können sich Entwickler voll auf die Geschäftslogik konzentrieren, anstatt sich mit dem Integrationscode rumzuschlagen, was die Zeit bis zur Wertschöpfung verkürzt.
Amazon Q ist ein komplett verwalteter Service zum Entwickeln von RAG-basierten Business-Assistenten.
Der Service verbindet die Multimodalfunktionen von Bedrock mit:
Mit Q können Unternehmen Chatbots für den Kundenkontakt zusammen mit Dashboards für Führungskräfte und Helpdesks für bestimmte Bereiche erstellen und diese innerhalb von Wochen statt Monaten bereitstellen.
Die Well-Architected Generative AI Lens setzt in jedem Schritt der Entwicklung generativer Workloads bewährte Verfahren ein.
Die Generative AI Lens von AWS erweitert die fünf Säulen des Well-Architected Frameworks auf generative Workloads. Das Framework umfasst automatisierte Modellüberwachungssysteme und Drift-Erkennungsmechanismen sowie Auslöser für Nachschulungen mit Versionsartefaktmanagement und Lernpfad-Tracking.
Hier sind die Säulen:
Für alle, die eine Zertifizierung anstreben, passtder AWS Cloud Practitioner Lernpfadsuper zu den Grundlagen, die hier behandelt werden.
Das AWS Partner Network hilft Unternehmen dabei, AWS-Services schneller einzusetzen, indem es ihnen Solution Accelerators und Partner-Services zur Verfügung stellt. Jedes Unternehmen ist anders, deshalb hat AWS das Partner Network mit speziellen generativen KI-Beschleunigern für verschiedene Branchen und Anwendungsfälle aufgebaut.
Die Fähigkeit der generativen KI, neue Inhalte zu erstellen, passt nicht zu dem, was man in der Praxis braucht, wo Daten in verschiedenen Formaten verarbeitet und verstanden werden müssen.
AWS hat eine Reihe von Services, die sich in deine generativen Pipelines einbinden lassen, um unstrukturierte Dokumente in strukturierte Daten umzuwandeln, Bildinformationen zu extrahieren und natürliche Gespräche sowie die Ausgabe in jeder Sprache oder Stimme zu ermöglichen.
Hier sind die beliebtesten:
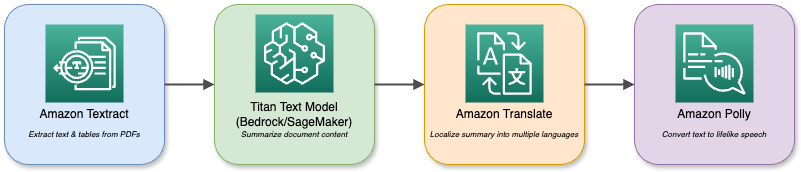
Ein Diagramm, das die verschiedenen Dienste und Interaktionen von AWS zeigt.
Deine Basismodelle in Bedrock oder SageMaker kannst du mit diesen Diensten kombinieren, um komplexe multimodale Anwendungen zu erstellen.
Ein Assistent für die Dokumentenanalyse nutzt zum Beispiel Textract, um PDFs zu lesen, und Titan Text, um sie zusammenzufassen. Dann werden die Zusammenfassungen in verschiedene Sprachen übersetzt und über Polly abgespielt. Mit dem modularen Ökosystem kannst du verschiedene KI-Funktionen kombinieren, um alle Anforderungen deines Unternehmens zu erfüllen.
Generative KI liefert die besten Ergebnisse, wenn du gut durchdachte Muster nutzt, um echte Geschäftsprobleme anzugehen.
In diesem Abschnitt werden vier konkrete Implementierungspläne vorgestellt, darunter die suchgestützte Generierung sowie Entwickler- und Unternehmensassistenten, und es werden weitere nützliche Szenarien vorgestellt, die du schon heute umsetzen kannst.
Die Kombination von Suchfunktionen mit großen Sprachmodellen in der suchgestützten Generierung liefert genaue Antworten, die immer im Kontext bleiben. Die vierstufige Pipeline läuft so ab:
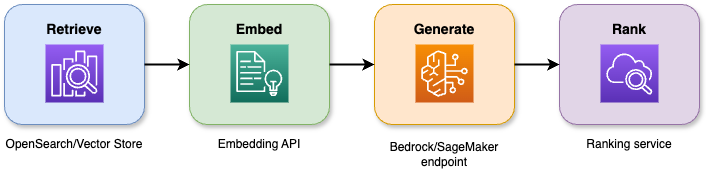
Ein Diagramm, das zeigt, wie die RAG-Architektur funktioniert.
Vorteile und Genauigkeitsgewinne:
Geschäftliche Anwendungen:
AWS CodeWhisperer bringt generative KI direkt über die IDEs und CI/CD-Pipelines zu den Entwicklern, um Routineaufgaben zu automatisieren und das Codieren schneller zu machen:
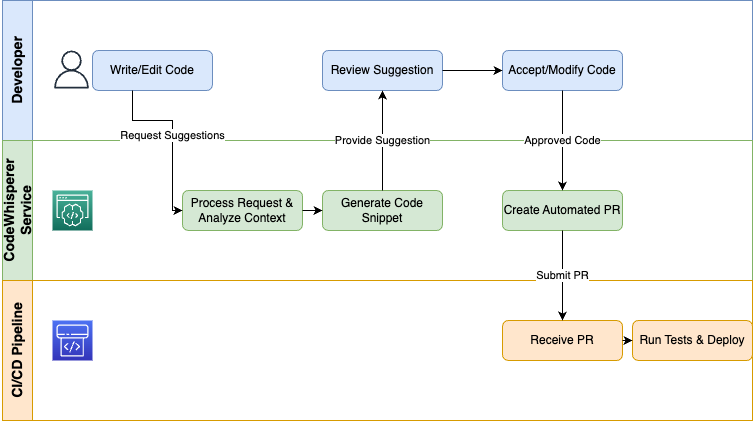
Ein Diagramm, das zeigt, wie Codes erstellt werden.
Firmen, die CodeWhisperer als Entwicklerassistent nutzen, sparen sich langweilige Routineaufgaben, halten sich an Coding-Standards und können sich so voll auf das Design und die Fehlerbehebung konzentrieren.
Denk dran, dass CodeWhisperer Teil von Amazon Q Developer wird.
Amazon Q Business ist eine RAG-basierte Low-Code-Lösung, mit der Leute Chatbots entwickeln können, die Unternehmensdaten über Fragen abrufen.
Architektur:
Einsatzmöglichkeiten:
Die Assistenten helfen Unternehmen dabei, die Arbeit mit Wissen zu optimieren, Betriebskosten zu senken und die Produktivität der Mitarbeiter zu steigern.
Der Wert generativer KI geht über RAG, Codegenerierung und Assistenten hinaus und erstreckt sich auf viele andere Bereiche:
Probier erst mal diese Vorlagen aus, um Pilotprojekte zu starten, die einen klaren ROI zeigen, bevor du mit der Optimierung und Skalierung in deinem Unternehmen weitermachst.
Unternehmen müssen bei der Einführung generativer KI in jeder Phase des KI-Lebenszyklus Sicherheitskontrollen und Governance-Praktiken einführen.
AWS hat ein umfassendes Sicherheits- und Compliance-Framework, das von physischen Rechenzentren bis hin zu Richtlinien auf Anwendungsebene reicht und so Innovationen ohne Bedenken ermöglicht.
AWS schützt generative KI-Workloads mit sechs konzentrischen Sicherheitsebenen:
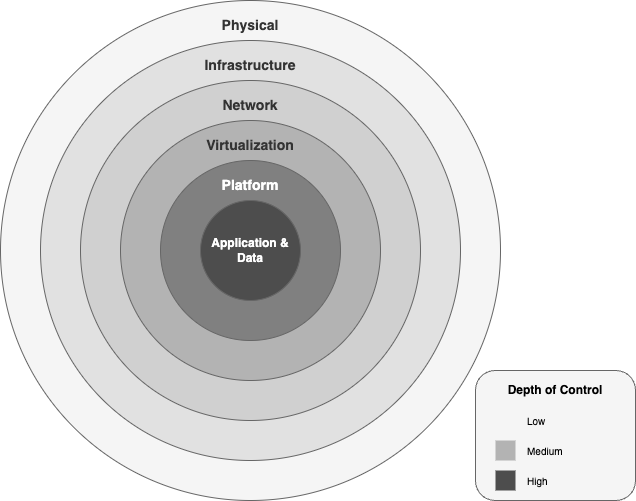
Ein Diagramm, das die Sicherheitsstufen im generativen KI-Framework von AWS zeigt.
Datenisolierung und Compliance:
Um Vertrauen in generative KI aufzubauen, muss man in jeder Phase der Modellanwendung ethische und Sicherheitsprotokolle einhalten. AWS sorgt für eine verantwortungsvolle KI-Governance mit diesem Rahmenwerk:
Diese Schichten und Vorgehensweisen sorgen für eine umfassende Verteidigung für generative KI in Unternehmen, sodass du Innovationen vorantreiben und gleichzeitig die höchsten Standards in Sachen Sicherheit, Compliance und ethischer Verantwortung einhalten kannst.
Um die Budgets für generative KI im Griff zu haben, muss man die Preismechanismen genau kennen und die Kosten ständig im Auge behalten. Hier geht's um die AWS-Preise für KI-Workloads, mit einem Beispiel für die Gesamtbetriebskosten einer mittelgroßen Bereitstellung und Tipps, wie du die Kosten runterhalten kannst.
Die Preise für generative KI von AWS sind in vier Hauptkategorien unterteilt:
|
Architektur |
Kostentreiber berechnen |
Token-Kostenfaktor |
Am besten geeignet |
|
Chatbots in Echtzeit |
Viele kleine Endpunkte, die rund um die Uhr laufen |
Hohe Anfrage-Rate, kleine Tokens |
Kundensupport, Helpdesks |
|
Batch-Erstellung |
Kurzlebige große Instanzen |
Nur wenige große Token-Bursts |
Erstellung von Berichten, Datenanreicherung |
|
RAG-Pipelines |
Kombinierte Suche + Schlussfolgerung |
Abruftoken + Generierungstoken |
Wissensbasierte Assistenten |
Hier ist ein Beispiel für die monatlichen Gesamtbetriebskosten für ein mittelgroßesgeneratives KI-Pilotprojekt:
|
Kostenpunkt |
Stückkosten |
Verwendung |
Monatliche Kosten |
|
Inferenz-Endpunkte (Inf1.xl) |
0,228 $/Stunde |
3 Endpunkte × 24 Stunden × 30 Tage |
$492.48 |
|
Token-Nutzung (Titan Express) |
0,0024 $ / 1 K-Token |
3 M-Token pro Tag × 30 Tage |
$216.00 |
|
S3-Speicher (Modellartefakte) |
0,023 $/GB-Monat |
10.000 GB |
$230 |
|
Datenausgang |
0,09 $/GB |
1 TB |
$90 |
|
Glue ETL (Feature-Vorbereitung) |
0,44 $/DPU-Stunde |
20 DPU-Stunden |
$8.80 |
|
Insgesamt |
$1,037.28 |
WichtigeHebel für die Optimierung:
Laufendes Kostenmanagement:
Durch die Kombination aus einer preisbewussten Architektur mit gezielten Optimierungen und ständiger Überwachung kannst du generative KI skalieren, ohne dass es zu hohen Kosten kommt.
Um generative KI vom Konzept bis zur Produktion zu bringen, braucht man eine systematische Methode in mehreren Schritten. Der Fahrplan zeigt Schritt für Schritt, wie man von ersten Bewertungen über Proof-of-Concept-Pilotprojekte bis hin zu einer robusten Plattform für Unternehmen kommt.
Bevor wir mit der kompletten Entwicklung der Architektur loslegen, checken wir erst mal, ob das Ganze überhaupt machbar ist und alle Beteiligten damit einverstanden sind.
Der Proof of Concept führt zur Entwicklung der grundlegenden Plattform, bevor das System breit eingesetzt werden kann.
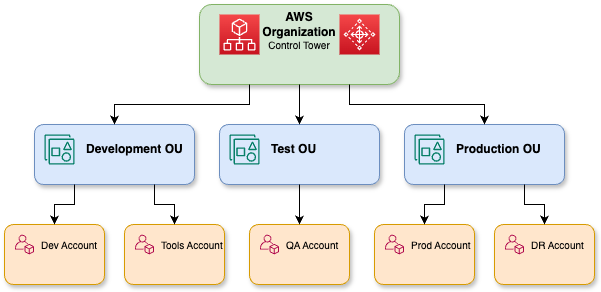
Eine detaillierte Darstellung der AWS-Organisationen.
Der schrittweise Ansatz mit Validierung, Aufbau einer Grundlage und anschließender Skalierung mit Governance und Partnerunterstützung hilft dir dabei, dein generatives KI-Pilotprojekt in eine unternehmensweite, robuste Lösung zu verwandeln.
Ständige Verbesserungen und gute Governance-Praktiken, die nach dem Ausbau deiner generativen KI-Plattform eingeführt werden, sorgen dafür, dass das System gut läuft und gleichzeitig die Sicherheit und die Einhaltung gesetzlicher Vorschriften gewährleistet sind.
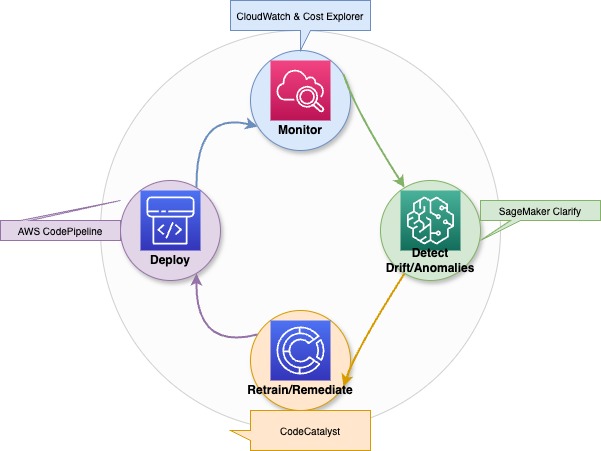
Ein Diagramm, das zeigt, wie generative KI-Modelle immer besser werden, wenn man sie optimiert, Fehler findet und neu trainiert.
Durch die Integration von ständiger Optimierung und strengen Audits in die Lernprozesse deiner Organisation kannst du eine robuste, vertrauenswürdige und kosteneffiziente generative KI-Fähigkeit aufbauen.
Die Reise in die generative KI von AWS kann durch Lernpfade, Communities und praktische Projekte beschleunigt werden, die Vertrauen schaffen und echte geschäftliche Vorteile bringen.
Die generative KI von AWS bietet ein komplettes End-to-End-System, einschließlich Basismodellen, optimierter Rechenleistung, Governance, Integration und Kostenkontrolle, damit Unternehmen schneller innovativ sein können und den Betriebsaufwand reduzieren können, während sie vertrauenswürdige, multimodale Anwendungen in großem Maßstab entwickeln.
Durch Ausprobieren, ständiges Lernen und Zusammenarbeit mit der Community kannst du das volle Potenzial der generativen KI von AWS ausschöpfen, um echte geschäftliche Erfolge zu erzielen.
Lerne mit diesen Kursen mehr über AWS!
Lernpfad
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
