
Programa
Profissional de nuvem da AWS (CLF-C02)
10 h
A IA generativa da AWS é o futuro dos serviços em nuvem, porque permite que as empresas criem conteúdo automatizado e trabalho de conhecimento por meio de modelos básicos que produzem texto, imagens e vídeo em tempo real.
Neste artigo, eu dou uma visão geral completa dos elementos essenciais dos métodos de implantação e estruturas de governança necessários para desenvolver soluções de IA generativa prontas para produção.
A AWS é a líder em nuvem porque oferece o Amazon Bedrock junto com uma infraestrutura de computação especializada e amplos recursos de integração que são melhores que outras plataformas de nuvem.
Se você é novo na AWS, esse curso introdutóriooferece uma base sólida antes de mergulhar nos detalhes da IA generativa.
Nesta seção, vamos ver os blocos que fazem a IA generativa da AWS funcionar.
O Bedrock é tipo o plano de controle gerenciado pra toda a IA generativa na AWS. Ele oferece uma API consistente para implantar, dimensionar e proteger modelos básicos, desde o provisionamento de terminais até o faturamento, para que você possa se concentrar em criar prompts e integrar a IA em vez de gerenciar a infraestrutura.
Um diagrama conceitual que mostra o ecossistema do modelo básico da AWS.
O Bedrock cataloune modelos para texto, imagem, vídeo e incorporações em uma única interface. As principais ofertas incluem:
Ajuste os modelos com os seus dados rotulados ou continue o pré-treinamento em corpora específicos do domínio usando o console Bedrock ou o SDK. Depois que o treinamento estiver concluído, o pacote de avaliação da Bedrock faz comparações lado a lado, mostrando a precisão, a latência e o custo por token, para que você possa escolher de forma objetiva a melhor opção para os SLAs de produção.
Além das famílias Titan e Nova da AWS, o Bedrock te dá acesso a modelos de parceiros como Anthropic, Cohere, Mistral, AI21 Labs e muito mais. Aproveite essa variedade para:
Para saber mais sobre como o Bedrock organiza esses modelos básicos em ambientes de produção, dá uma olhada neste guia completo do Amazon Bedrock.
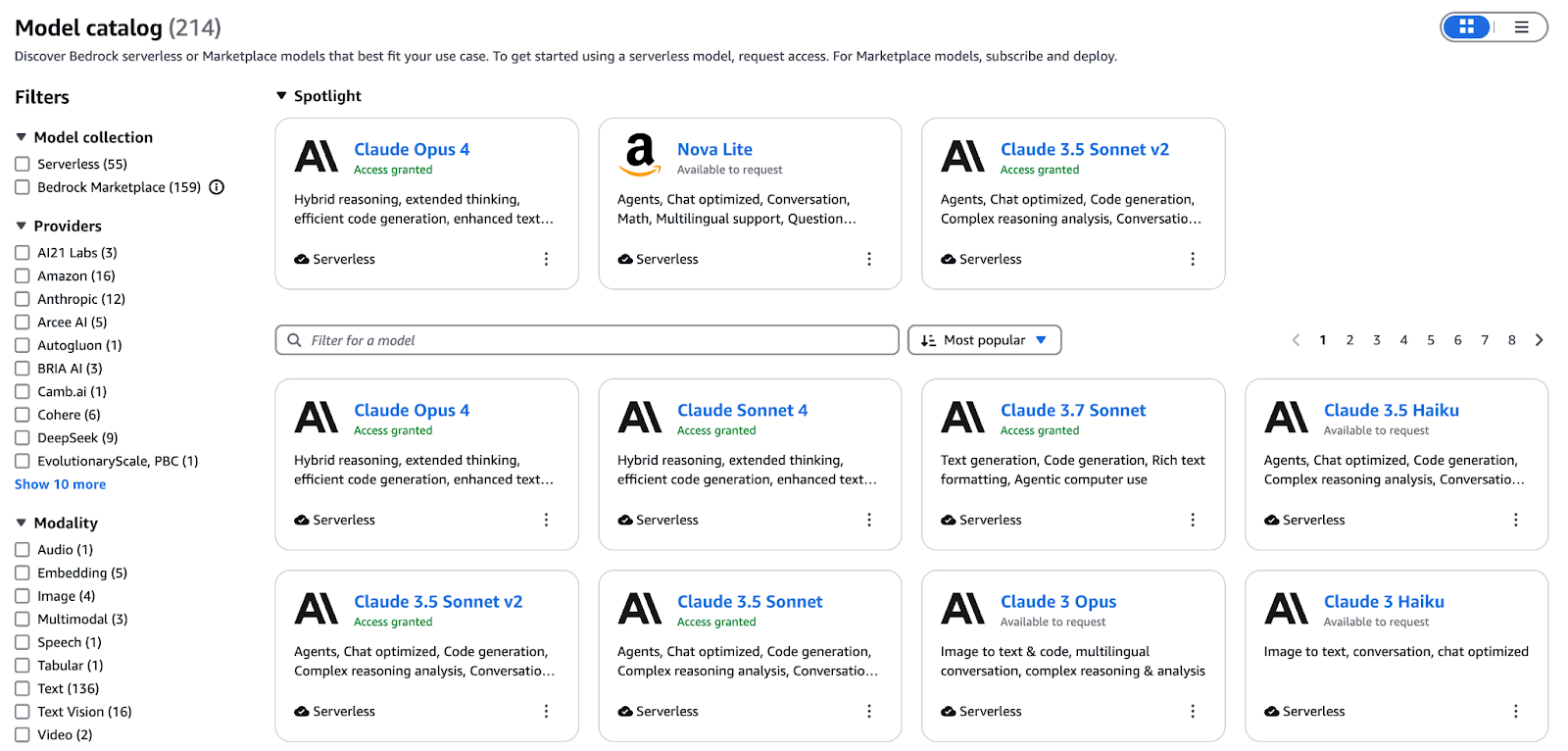
As famílias de instâncias EC2 que a AWS oferece são feitas pra atender às necessidades específicas das operações de treinamento e inferência.
Treinamento:
Conclusão:
Um diagrama que mostra como é a infraestrutura de computação otimizada para IA da AWS.
A AWS consegue uma integração perfeita entre seus componentes de hardware e software personalizados por meio do Trainium para treinamento e do Inferentia para chips de inferência, que funcionam direto com os serviços da AWS. Essa integração vertical traz:
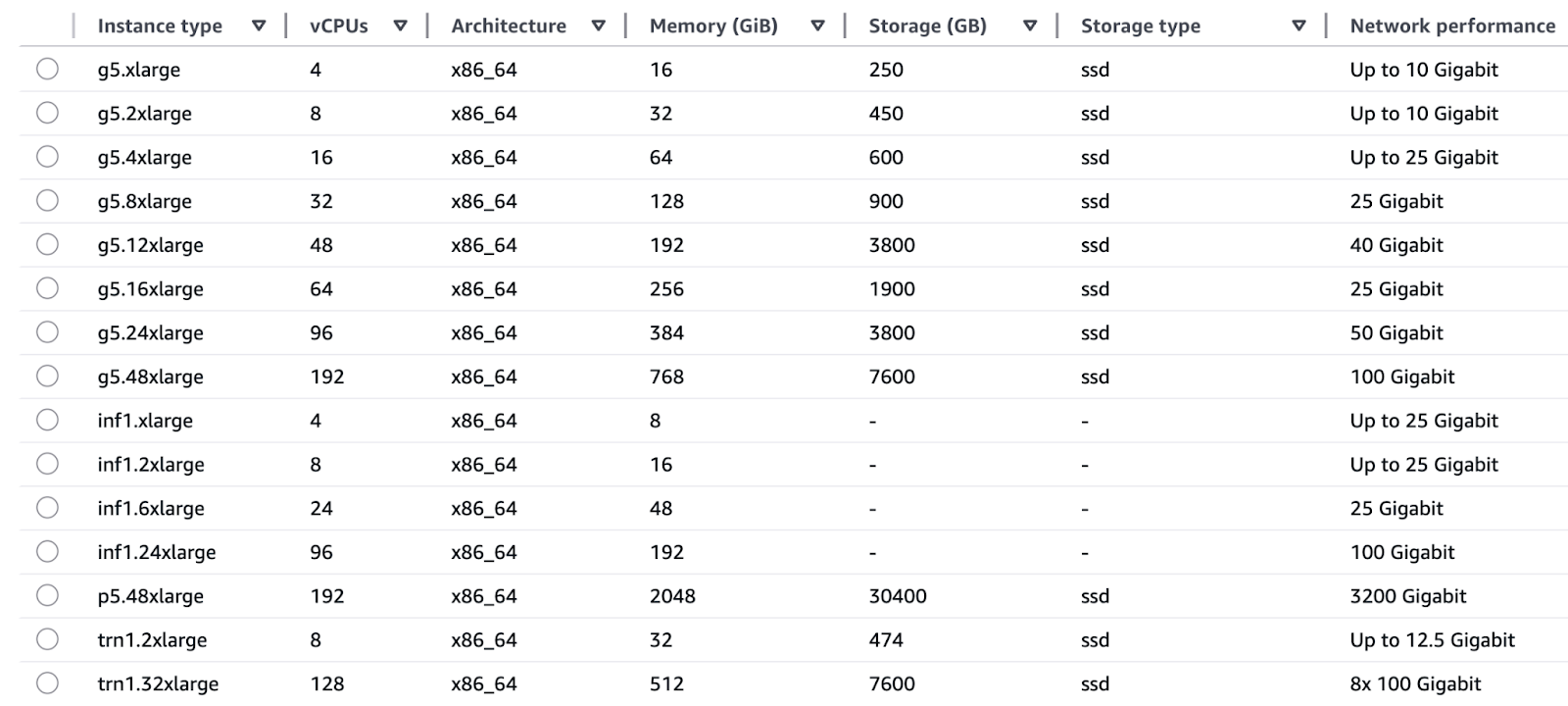
O AWS Nitro System usa placas de hardware dedicadas para fazer as funções de virtualização, dando assim velocidades rápidas de bare metal junto com isolamento seguro:
 Um diagrama ilustrativo do Nitro Hypervisor da AWS Nitro Hypervisor
Um diagrama ilustrativo do Nitro Hypervisor da AWS Nitro Hypervisor
Explore o ecossistema mais amplo de computação, armazenamento e análise neste cursosobre Tecnologia e Serviços em Nuvem da AWS.
O treinamento de modelos em alta velocidade e os pipelines RAG precisam de acesso a dados limpos e bem gerenciados:
Os recursos de IA generativa da AWS se juntam direto com o seu ecossistema mais amplo pra oferecer soluções completas e prontas pra produção. Esta seção fala sobre como juntar o Bedrock com os serviços que o acompanham para criar aplicativos de IA generativa de verdade.
Escolha modelos básicos no hub de modelos do SageMaker JumpStart e comece a usá-los rapidinho. Você pode usar vários modelos de código aberto e proprietários com um único clique antes de registrá-los diretamente no Amazon Bedrock. Os modelos que entram no Bedrock têm acesso a:
A arquitetura integrada permite que os desenvolvedores criem protótiposno SageMaker Studio e depois os aprimorem no Bedrock antes de implantá-los por meio de pipelines de CI/CD sem precisar mexer no código.
Este tutorial do SageMaker mostra como ajustar e usar modelos usando a plataforma de ML da AWS.
 Um diagrama que mostra o ciclo de vida unificado do ML com o SageMaker JumpStart e o Bedrock.
Um diagrama que mostra o ciclo de vida unificado do ML com o SageMaker JumpStart e o Bedrock.
Com o Bedrock Agents, você pode integrar IA generativa nas suas aplicações operacionais, pegando dados automaticamente e transformando-os antes de fazer qualquer coisa. Um Agente só precisa de uma configuração básica pra:
As funções de encanamento dos Agentes permitem que os desenvolvedores se concentrem na lógica de negócios em vez de no código de integração, acelerando assim o tempo de retorno do investimento.
O Amazon Q é um serviço totalmente gerenciado para desenvolver assistentes de negócios com RAG.
O serviço junta a funcionalidade multimodelo do Bedrock com:
Com o Q, as empresas criam chatbots para lidar com os clientes, além de painéis de controle para os chefes e serviços de suporte técnico específicos para cada área, e tudo isso em semanas, não em meses.
A lente de IA generativa bem arquitetada usa as melhores práticas em todas as etapas do desenvolvimento de cargas de trabalho generativas.
A lente de IA generativa da AWS amplia os cinco pilares da estrutura bem arquitetada para cargas de trabalho generativas. A estrutura inclui sistemas automatizados de monitoramento de modelos e mecanismos de detecção de desvios, além de gatilhos de reciclagem com gerenciamento de artefatos de versão e acompanhamento de métricas de inferência.
Aqui estão os pilares:
Pra quem tá querendo se certificar, o programa AWS Cloud Practitionercombina bem com o conhecimento básico que a gente aprendeu aqui.
A Rede de Parceiros da AWS ajuda as empresas a adotarem os serviços da AWS mais rápido com aceleradores de soluções e serviços de parceiros. Cada empresa é diferente das outras, por isso a AWS criou a Rede de Parceiros com aceleradores de IA generativa específicos para diferentes setores e casos de uso.
A capacidade da IA generativa de criar novos conteúdos não combina com o que as aplicações do mundo real precisam, que é processar e entender dados em vários formatos de apresentação.
A AWS oferece um monte de serviços que se juntam com seus pipelines gerativos pra transformar documentos desestruturados em dados estruturados, extrair insights de imagens e permitir conversas naturais e entrega de resultados em qualquer idioma ou voz.
Aqui estão os mais populares:
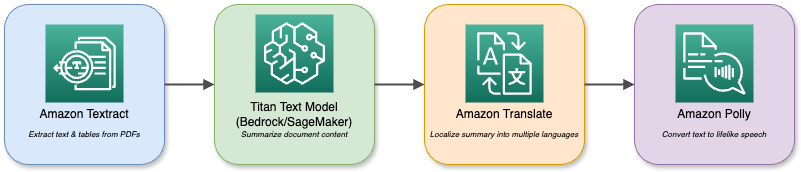
Um diagrama que mostra os vários serviços e interações da AWS.
Os seus modelos básicos no Bedrock ou SageMaker podem ser combinados com esses serviços para criar aplicativos multimodais complexos.
Um assistente de análise de documentos, por exemplo, usa o Textract para pegar PDFs e, depois, usa o Titan Text para resumir tudo antes de traduzir o resumo para vários idiomas e reproduzir com o Polly. O ecossistema modular permite que você combine vários recursos de IA para atender a qualquer necessidade da sua empresa.
A IA generativa dá os melhores resultados quando você usa padrões bem arquitetados para resolver problemas reais de negócios.
Essa seção mostra quatro planos de implementação específicos, incluindo geração aumentada por recuperação e assistentes para desenvolvedores e empresas, além de outros cenários de alto valor que você pode implementar hoje mesmo.
A combinação de recursos de pesquisa com grandes modelos de linguagem na geração aumentada por recuperação gera respostas precisas que permanecem fundamentadas no contexto. O pipeline de quatro etapas funciona assim:
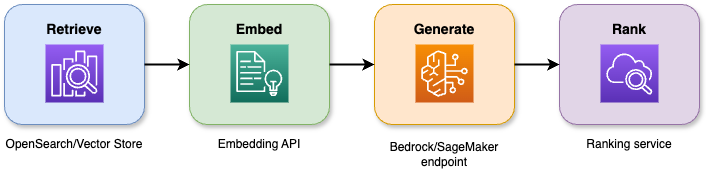
Um diagrama que mostra como funciona a geração aumentada por recuperação (RAG).
Benefícios e ganhos em precisão:
Aplicações comerciais:
O AWS CodeWhisperer oferece IA generativa direto para os desenvolvedores através de seus IDEs e pipelines de CI/CD para automatizar tarefas repetitivas e acelerar os processos de codificação:
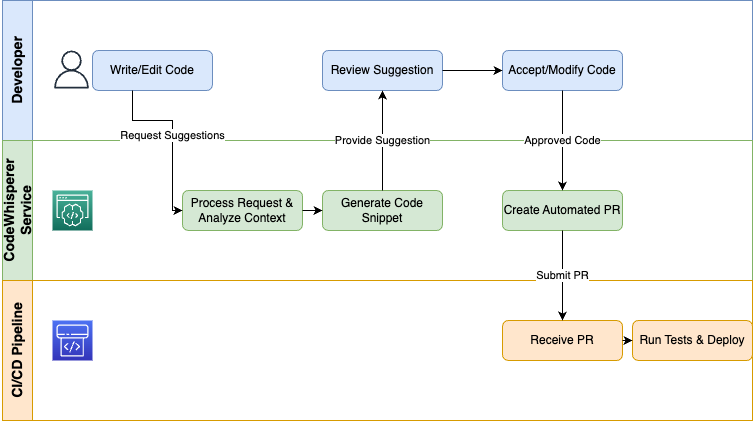
Um diagrama que mostra como funciona a geração de código.
As empresas que usam o CodeWhisperer como assistente de desenvolvedores eliminam o trabalho repetitivo, garantem que os padrões de codificação sejam seguidos e permitem que os engenheiros dediquem seu tempo a atividades importantes, como design e depuração.
Lembre-seque o CodeWhisperer vai passar a fazer parte do Amazon Q Developer.
O Amazon Q Business funciona como uma solução de baixo código com tecnologia RAG, permitindo que os usuários criem assistentes conversacionais que buscam dados da empresa por meio de perguntas.
Arquitetura:
Cenários de implantação:
Os assistentes ajudam as organizações a simplificar o trabalho de conhecimento, reduzir custos operacionais e permitir que os funcionários alcancem níveis mais altos de produtividade.
O valor da IA generativa vai além do RAG, da geração de código e dos assistentes, estendendo-se a vários outros domínios:
Comece com esses padrões para criar projetos-piloto que mostrem um retorno sobre o investimento claro antes de passar para a otimização e a expansão em toda a sua organização.
As empresas precisam implementar controles de segurança e práticas de governança em todas as etapas do ciclo de vida da IA quando adotam a IA generativa.
A AWS oferece uma estrutura completa de segurança e conformidade que vai desde centros de dados físicos até políticas no nível de aplicativos, permitindo inovar com confiança.
A AWS protege as cargas de trabalho de IA generativa com seis camadas de segurança concentricas:
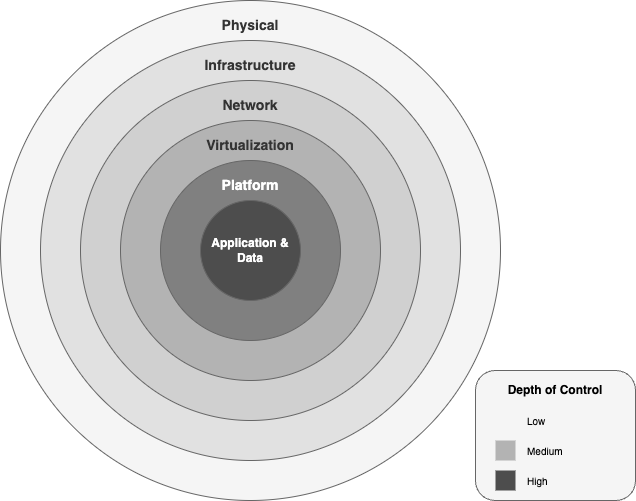
Um diagrama que mostra as camadas de segurança dentro da estrutura de IA generativa da AWS.
Isolamento de dados e conformidade:
A gente precisa criar confiança na IA generativa implementando protocolos éticos e de segurança em cada etapa da invocação do modelo. A AWS faz uma governança responsável da IA usando essa estrutura:
Essas camadas e práticas criam uma postura de defesa em profundidade para a IA generativa empresarial, permitindo que você inove e, ao mesmo tempo, mantenha os mais altos padrões de segurança, conformidade e responsabilidade ética.
O processo de controle dos orçamentos de IA generativa exige tanto um conhecimento completo dos mecanismos de precificação quanto práticas contínuas de gerenciamento de custos. Essa seção explica os preços da AWS para cargas de trabalho de IA, mostrando um exemplo de TCO de implantação de tamanho médio e estratégias para reduzir as despesas.
Os preços da IA generativa da AWS se dividem em quatro dimensões principais:
|
Arquitetura |
Calcular o fator de custo |
Fator determinante do custo do token |
Melhor ajuste |
|
Chatbots em tempo real |
Muitos terminais pequenos funcionando 24 horas por dia, 7 dias por semana |
Alta taxa de solicitação, tokens pequenos |
Suporte ao cliente, Central de ajuda |
|
Geração em lote |
Instâncias grandes de curta duração |
Poucas explosões grandes de tokens |
Geração de relatórios, aumento de dados |
|
Pipelines RAG |
Pesquisa combinada + inferência |
Token de recuperação + token de geração |
Assistentes baseados em conhecimento |
Abaixo tá um exemplo de TCO mensal pra um projetopiloto de IA generativa de tamanho médio:
|
Item de custo |
Custo unitário |
Como usar |
Custo mensal |
|
Pontos finais da inferência (Inf1.xl) |
R$ 0,228 /hora |
3 pontos finais × 24 horas × 30 dias |
$492.48 |
|
Uso de tokens (Titan Express) |
R$ 0,0024 /1 token K |
3 fichas M por dia × 30 dias |
$216.00 |
|
Armazenamento S3 (artefatos do modelo) |
R$ 0,023 /GB por mês |
10 000 GB |
$230 |
|
Saída de dados |
R$ 0,09 /GB |
1 TB |
$90 |
|
Colagem ETL (preparação de recursos) |
R$ 0,44 /DPU-hora |
20 horas após a colheita |
$8.80 |
|
Total |
$1,037.28 |
Principaisalavancas de otimização:
Gerenciamento contínuo de custos:
A combinação de uma arquitetura que leva em conta os preços com otimizações direcionadas e monitoramento contínuo permite que você amplie a IA generativa sem custos excessivos.
O processo de escalonamento da IA generativa, desde o conceito até a produção, precisa de uma metodologia sistemática em fases. O roteiro dá um passo a passo, começando pelas avaliações iniciais, passando por testes de conceito, até chegar a uma plataforma resiliente e pronta para empresas.
A primeira etapa é ver se dá pra fazer e conseguir a aprovação de todo mundo antes de começar a desenvolver a arquitetura toda.
A Prova de Conceito leva ao desenvolvimento da plataforma básica antes que o sistema possa ser usado por todo mundo.
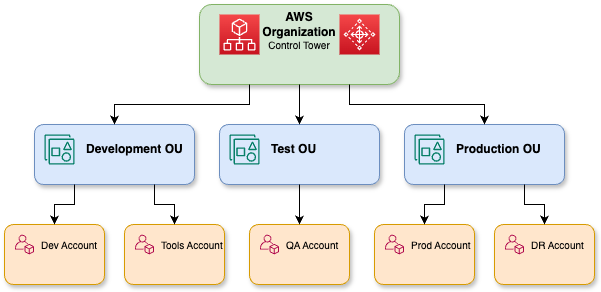
Uma representação detalhada das organizações da AWS.
A abordagem em fases da validação, seguida pela construção de bases e, em seguida, pela expansão com governança e apoio de parceiros, vai ajudar você a transformar seu piloto de IA generativa em uma capacidade robusta em toda a empresa.
O aprimoramento contínuo e práticas sólidas de governança, implementadas depois de expandir sua plataforma de IA generativa, garantem que o sistema funcione bem, mantendo a segurança e a conformidade regulatória.
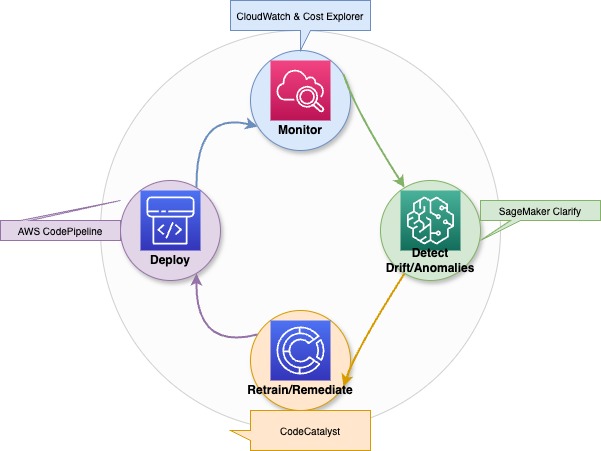
Um diagrama que mostra como funciona a otimização contínua, a deteção de desvios e os processos de retreinamento para modelos de IA generativa.
Ao juntar a otimização contínua e auditorias rigorosas com práticas de aprendizagem organizacional, você pode manter uma capacidade de IA generativa resiliente, confiável e econômica.
A jornada da IA generativa da AWS pode ser acelerada por meio de trilhas de aprendizagem, comunidades e projetos práticos que aumentam a confiança e geram impacto real nos negócios.
A IA generativa da AWS oferece um sistema completo de ponta a ponta, incluindo modelos básicos, computação otimizada, governança, integração e controle de custos, para ajudar as empresas a inovar mais rápido e reduzir as despesas operacionais enquanto criam aplicativos multimodais confiáveis em grande escala.
Com experimentação, aprendizado contínuo e colaboração da comunidade, você vai aproveitar todo o potencial da IA generativa da AWS para gerar um impacto real nos negócios.
Aprenda mais sobre a AWS com esses cursos!
Programa
Curso
Curso
blog
Nahla Davies
15 min
blog
Javier Canales Luna
14 min
blog
Hesam Sheikh Hassani
12 min
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita

