




Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
100.3K
¿Quieres ampliar tus conocimientos sobre IA con un proyecto práctico? En este tutorial, exploraremos Cohere Comando R+, incluyendo cómo acceder a él online y localmente. También nos sumergiremos en las características clave de la API Python de Cohere y construiremos un proyecto de IA utilizando LangChain y Tavily.
La parte emocionante comienza con el proyecto. Si ya estás familiarizado con los modelos Cohere y sus características, puedes pasar directamente a la sección de proyectos. Allí aprenderás a construir un agente de IA que utilice varias herramientas en secuencia para completar una tarea.
Si eres nuevo en la IA y quieres aprender más sobre este campo, considera la posibilidad de cursar la asignatura Fundamentos de la IA. Adquirirás conocimientos prácticos sobre temas populares de IA, como ChatGPT, Modelos de Lenguaje Extensos (LLM), IA generativa y mucho más.
Command R+ es el último y más avanzado LLM de Cohere. El modelo destaca en interacciones conversacionales y tareas de contexto largo. Está especialmente optimizado para flujos de trabajo complejos de Generación Aumentada de Recuperación (GAR) y para el uso de herramientas de varios pasos, lo que lo convierte en una potente herramienta para aplicaciones a escala empresarial.
Imagen del autor
Estas son algunas de las características más relevantes del modelo Command R+.
Para comprender mejor los modelos Cohere, no dejes de leer el tutorial de la API Cohere de: Primeros pasos con los modelos Cohere.
Hay distintas formas de acceder a los modelos Cohere, la mayoría gratuitas.
Puedes acceder al campo de juego LLM en línea o descargar el modelo localmente y utilizarlo con una aplicación de chat. Además, también puedes acceder a ella a través de la API Cohere. Repasemos cada uno de estos métodos.
La forma más sencilla de acceder a Cohere Command R+ en línea es a través del HuggingChat. No tiene limitaciones, y además puedes conectarlo con seis herramientas disponibles para diferentes tareas como la generación de imágenes o la búsqueda en Internet.
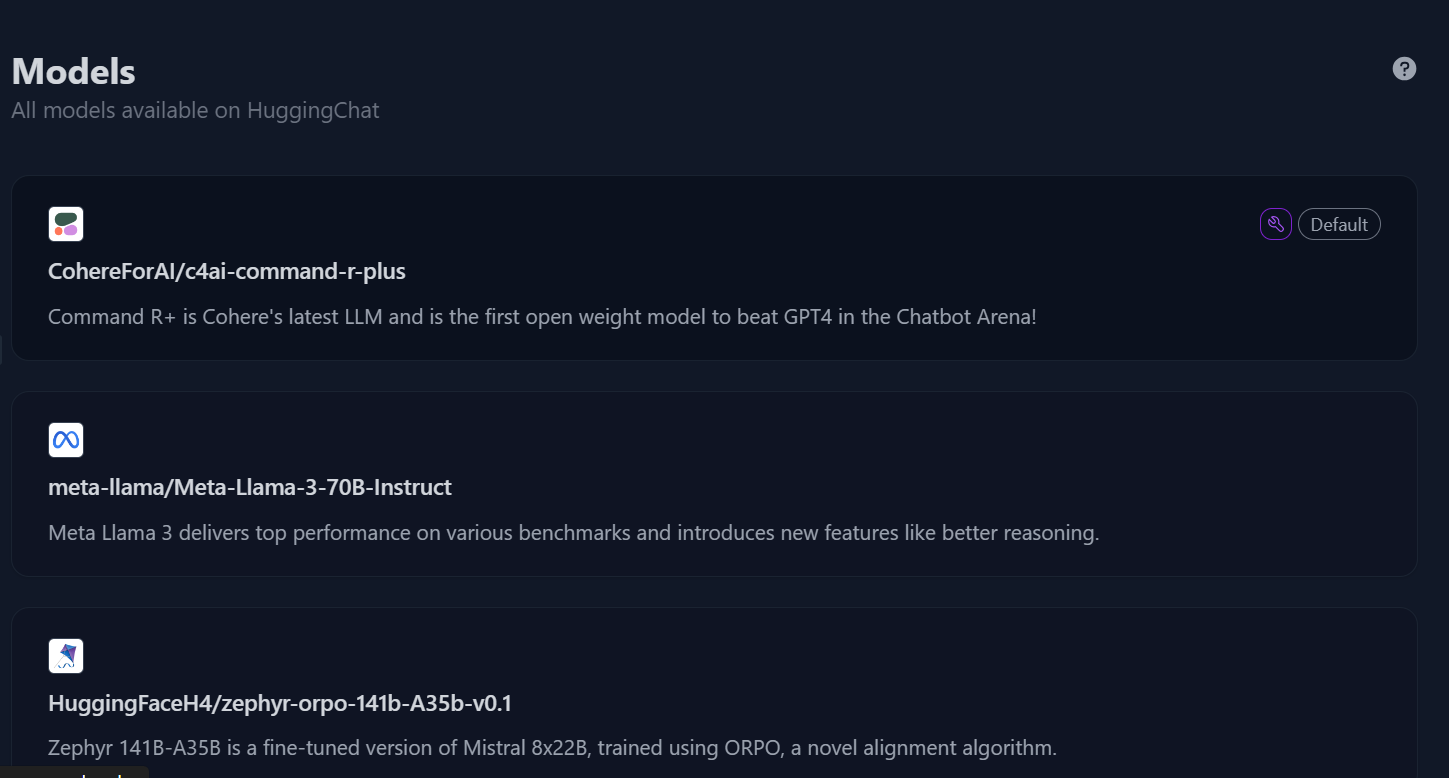
1. Ir a la página https://huggingface.co/chat/ página web.
2. En el panel izquierdo, haz clic en el botón "Modelos" para acceder al menú del modelo y, a continuación, selecciona el modelo "c4ai-command-r-plus".
Directorio de modelos en Chat de abrazos. Fuente de la imagen: HuggingChat
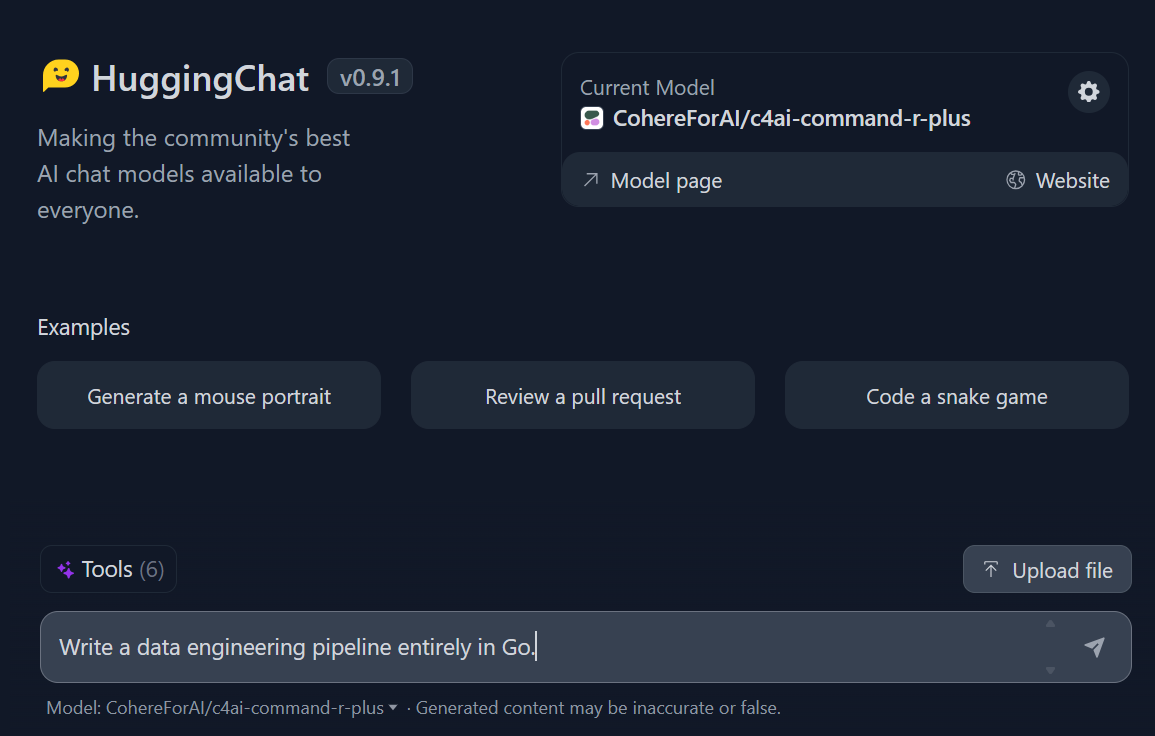
3. Empieza a escribir la consulta, y generará una respuesta rápida y muy precisa.
Prompting en el Chat de Abrazos. Fuente de la imagen: HuggingChat
Puedes utilizar Command R+ localmente de dos formas: descargando el modelo en tu máquina local o proporcionando una clave API a la aplicación de chat de Jan.
Exploremos la segunda opción.
1. Descarga e instala Jan desde https://jan.ai/ sitio web.
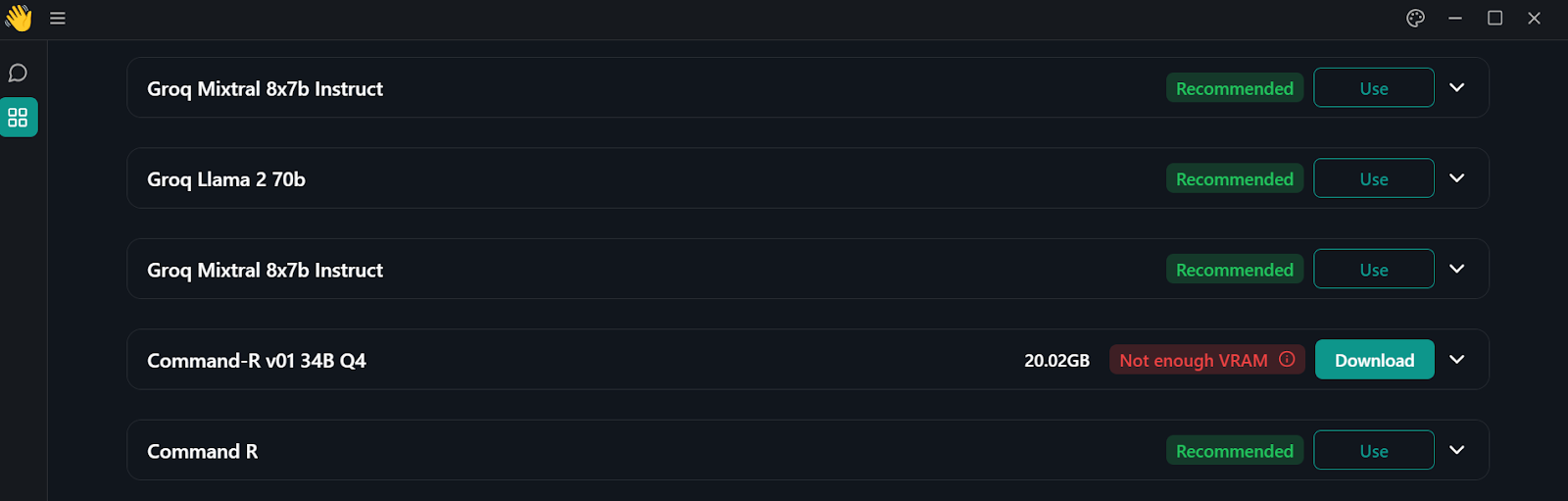
2. Ve al centro de modelos haciendo clic en el botón de ventanas del panel izquierdo.
Directorio de modelos en la aplicación Jan
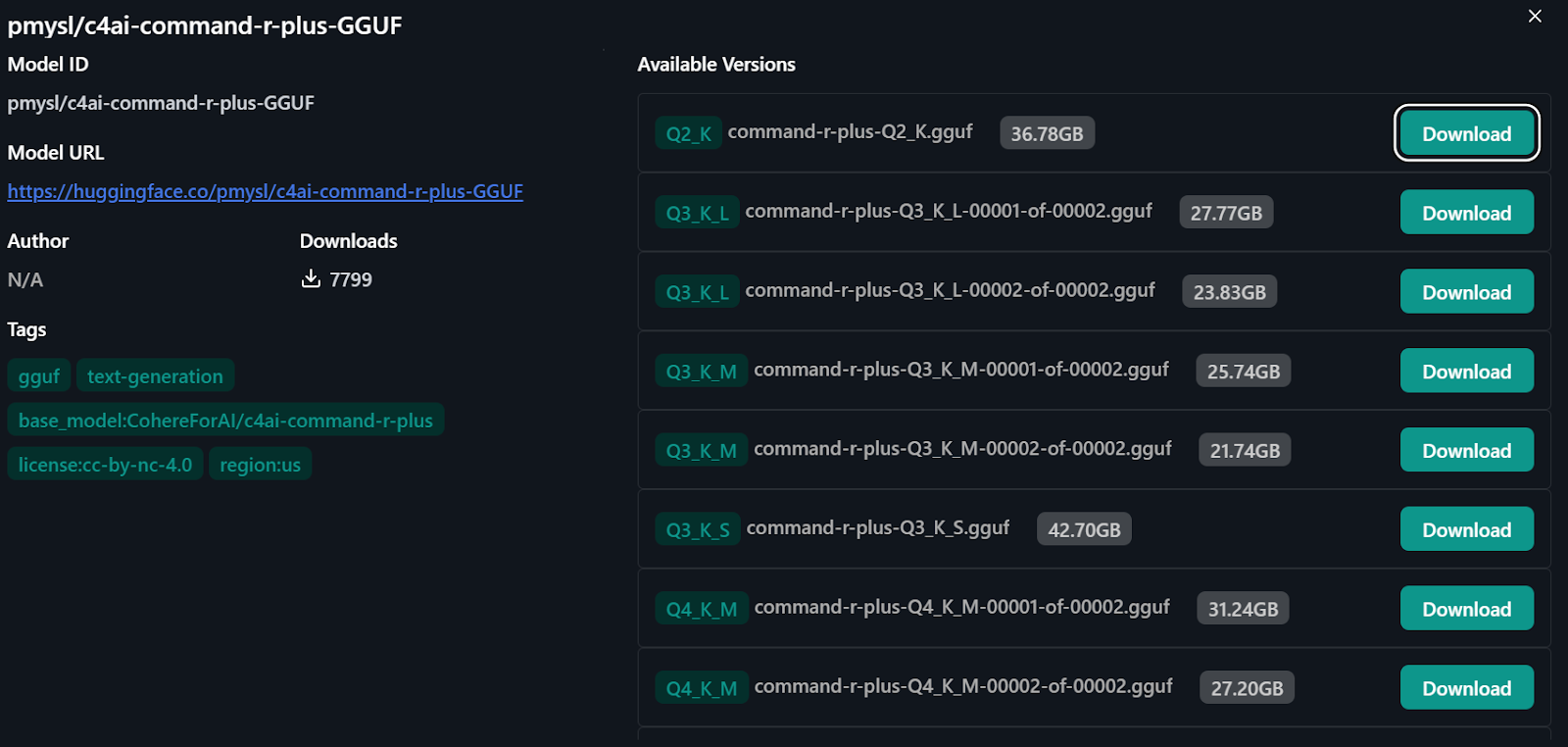
3. Para acceder al modelo Command R+, escribe "pmysl/c4ai-command-r-plus-GGUF " en la barra de búsqueda del centro de modelos.
4. Descarga y empieza a utilizar la "versión Q4_K_M" del modelo, que ocupa unos 31,24 GB.
Importar el modelo de Cara de abrazo
Otra forma de utilizar el modelo Command R+ localmente es conectar la API Cohere con la aplicación Jan.
1. Ir a la página https://coral.cohere.com/ e identifícate.
2. Ve al "Panel de control".
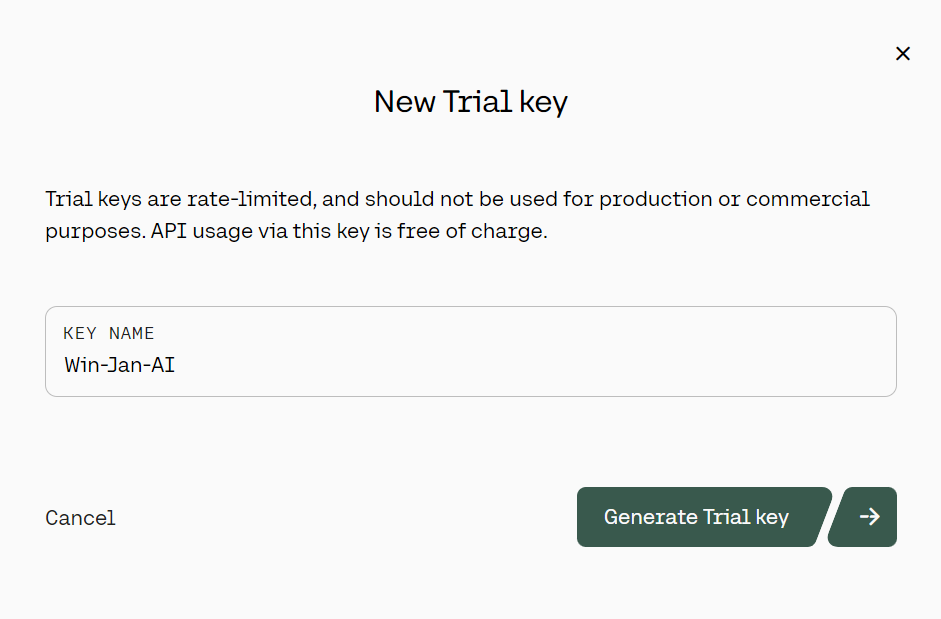
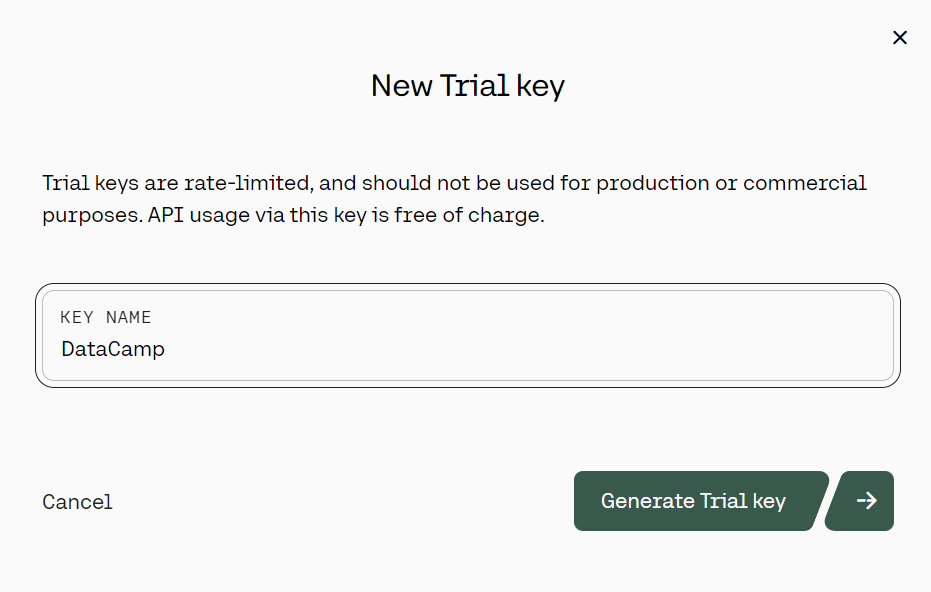
3. En el panel izquierdo, haz clic en el botón "Claves API", luego desplázate hacia abajo y haz clic en "+ Crear clave Trail".
Generar la clave API de prueba de Cohere. Fuente: cohere.com
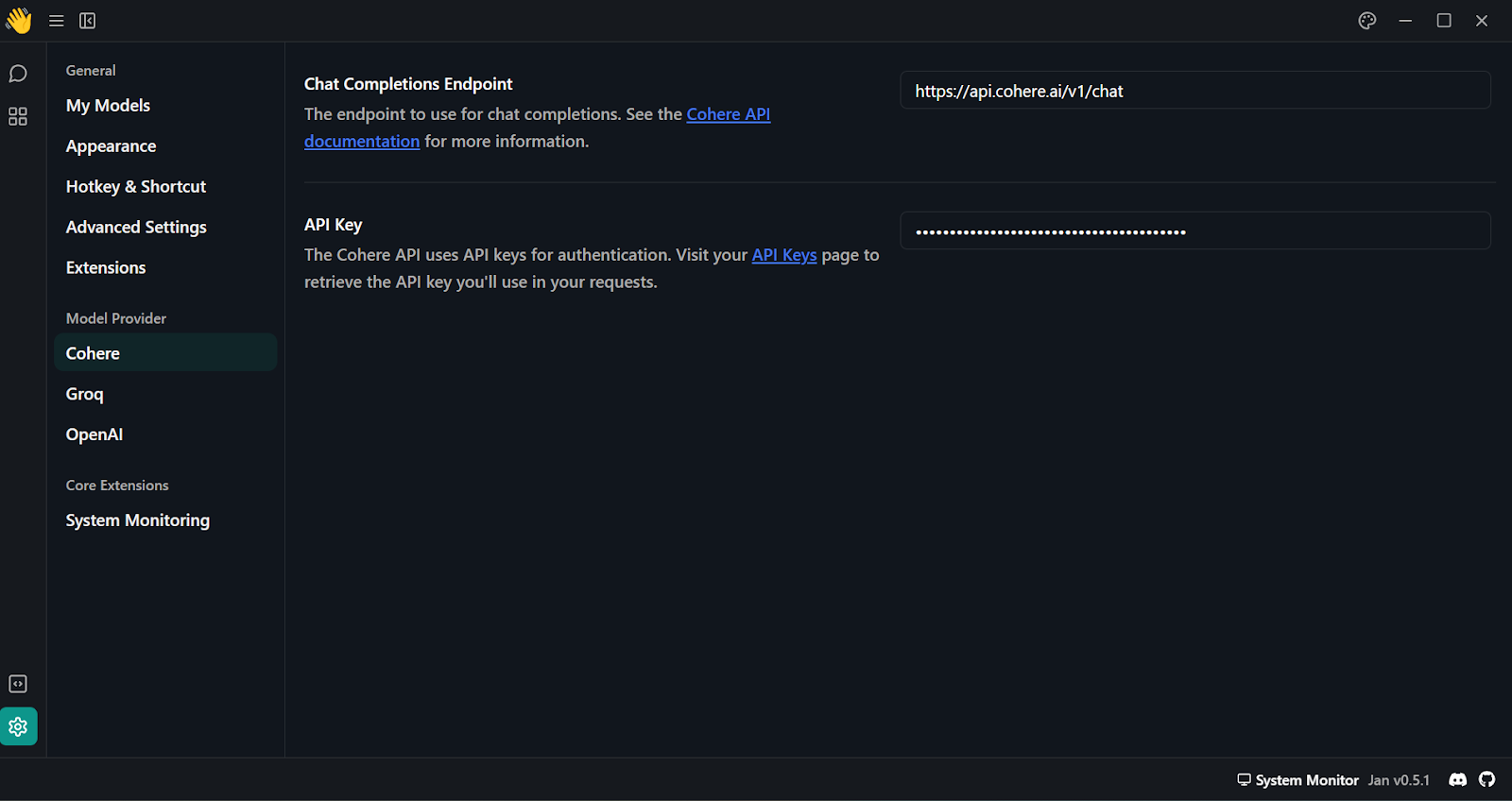
4. Tras generar la clave API de Cohere, pégala en la sección "Proveedor del modelo". Puedes acceder a este menú yendo a "Ajustes" y buscando "Cohere".
Añadir la clave API de Cohere en la aplicación Jan
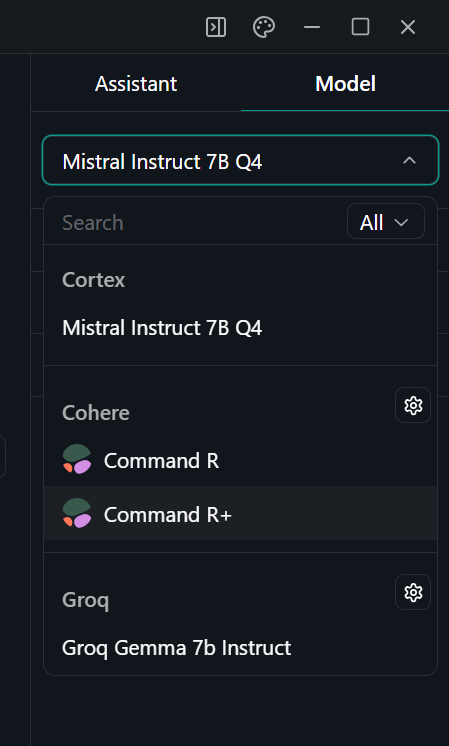
5. Selecciona el modelo Command R+ yendo al menú "Rosca" y, en el panel derecho, selecciona el modelo adecuado.
Seleccionar el modelo en la aplicación Jan
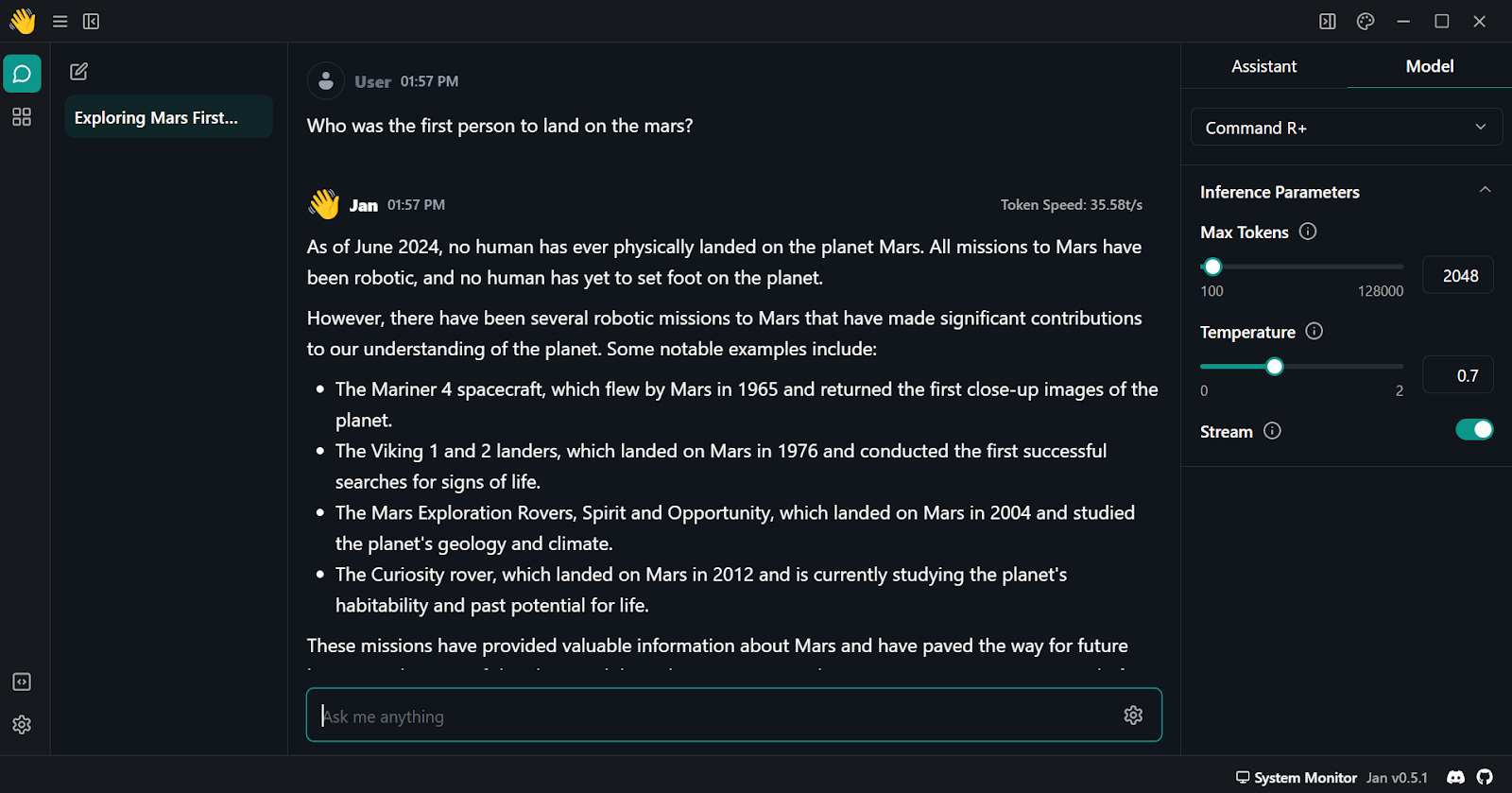
6. Comienza a preguntar y asegúrate de que lo utilizas con la opción "Flujo" activada.
Utilizar Cohere Command R plus en la aplicación Jan
En esta sección, aprenderás a configurar y utilizar la API de Python para generar la respuesta.
1. Instala el paquete Cohere Python con pip.
pip install cohere2. Genera una nueva clave API Cohere. Puedes seguir los pasos de la sección "Utilizar Cohere Command R+ a través de la API".
Generar la clave API de prueba de Cohere. Fuente de la imagen: cohere.com
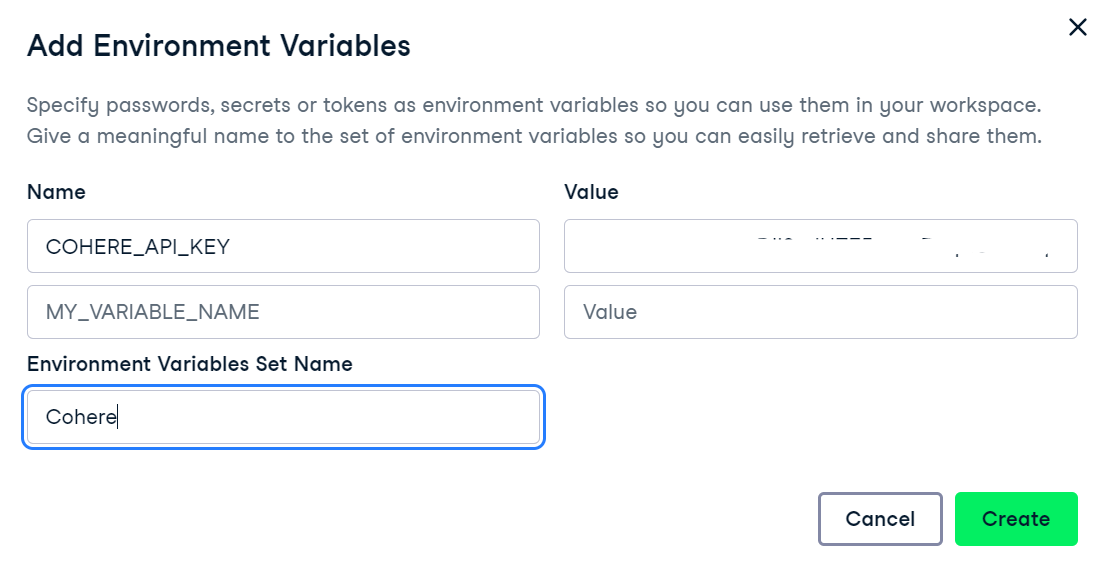
3. Utilizaremos el DataLab de DataCamp como entorno de desarrollo. Para configurar variables de entorno en DataLab, sigue estos pasos:
Añadir variables de entorno en DataLab
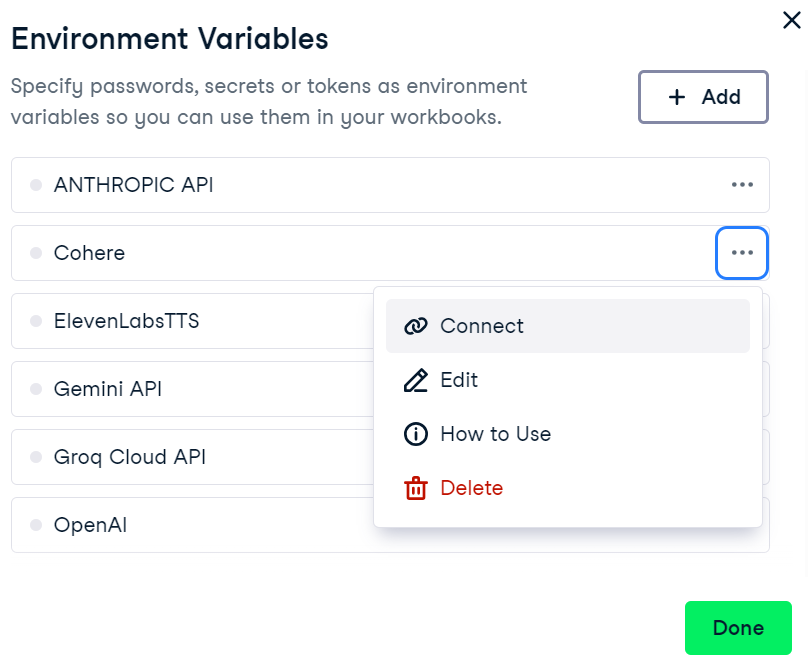
4. Para activar la variable de entorno en el DataLab de DataCamp, ve al menú de variables de entorno, haz clic en los tres puntos que hay junto a "Cohere" y luego haz clic en "Conectar".
Conectar la variable de entorno Cohere en DataLab
5. Ahora, en tu bloc de notas, inicia el cliente Cohere proporcionando la clave API. Para ello, importa la biblioteca Cohere y crea un objeto cliente con tu clave API.
import os
import cohere
cohere_api_key = os.environ["COHERE_API_KEY"]
co = cohere.Client(api_key=cohere_api_key)6. Para generar una respuesta utilizando lafunción .chat() , proporciona el nombre model y la direcciónmessage.
response = co.chat(
model="command-r-plus",
message="Please help me write an email to the angry boss, who thinks I made the changes to the data pipeline but didn't. It was James."
)
print(response.text)
Modelo de respuesta a la consulta proporcionada
¡La generación de respuestas debe ser rápida y muy relevante!
En la siguiente sección, exploraremos varias características de la API Python de Cohere.
Ahora exploraremos la API Python de Cohere para generar respuestas con historial, transmitir respuestas y obtener salidas predecibles. También realizaremos RAG, convertiremos texto en incrustaciones y ajustaremos el modelo en un conjunto de datos personalizado.
En el apartado anterior, aprendimos a generar respuestas utilizando una sencilla función.chat(). Ahora, le proporcionaremos argumentos adicionales como el prompt del sistema (preamble ), chat_history,max_tokens, y temperature.
response = co.chat(
model="command-r-plus",
preamble="You are a happy chatbot that puts a positive spin on everything.",
chat_history=[
{"role": "USER", "text": "Hey, my name is Abid!"},
{"role": "CHATBOT", "text": "Hey Abid! How can I help you today?"},
],
message="I can't swim?",
max_tokens=150,
temperature=0.7
)
print(response.text)
Modelo de respuesta con los argumentos adicionales proporcionados
Basándose en los argumentos adicionales, el modelo ha modificado la respuesta.
También podemos transmitir la respuesta utilizando la función.chat_stream(). Esta función nos permite generar respuestas en tiempo real, produciendo fichas a medida que están disponibles, lo que aumenta la velocidad percibida del modelo.
response = co.chat_stream(
model="command-r-plus",
message="Tell me something interesting about the galaxy?"
)
for event in response:
if event.event_type == "text-generation":
print(event.text, end="")
elif event.event_type == "stream-end":
print(event.finish_reason, end="")
Modelo que devuelve fichas en tiempo real
Los resultados predecibles son una característica exclusiva de Cohere. Fijando el argumento seed, podemos hacer que el modelo genere la misma respuesta a la misma pregunta.
Normalmente, cuando haces dos veces la misma pregunta a un LLM, recibirás una respuesta diferente. Establecer el seed garantiza resultados coherentes y reproducibles, como cualquier modelo de aprendizaje automático.
En el siguiente ejemplo, si estableces el argumento seed a 55, siempre recibirás "Matilda" como respuesta.
res = co.chat(model="command-r", message="say a random name", seed=55)
print(res.text)Sure! I will pick a random name for you. How about "Matilda"?Para probar nuestra teoría, hemos vuelto a plantear al modelo la misma pregunta con el mismo seed.
res = co.chat(model="command-r", message="say a random name", seed=55)
print(res.text)Sure! I will pick a random name for you. How about "Matilda"?¡Y ha dado el mismo resultado!
La API de Cohere ofrece una función integrada para realizar RAG. Sólo tenemos que proporcionar a la función .chat() un argumentodocuments. Al formular una pregunta, realizará una búsqueda de similitudes en los documentos para generar respuestas que tengan en cuenta el contexto.
Utilizaremos como ejemplo los documentos de investigación sobre el anime. El formato de los documentos debe ser similar al del ejemplo siguiente. Cada documento debe contener las claves title y snippet.
anime = [
{
"title": "Naruto Popularity Analysis",
"snippet": "Naruto's global success: massive manga sales, top anime ratings, extensive merchandise, and a dedicated fanbase. The series' impact on anime culture and its influence on subsequent shonen series is undeniable."
},
{
"title": "One Piece Popularity Analysis",
"snippet": "One Piece's record-breaking manga sales and its status as a long-running anime phenomenon highlight its popularity. The series' captivating story and characters have made it a staple in the anime community."
},
{
"title": "Attack on Titan Popularity Analysis",
"snippet": "Attack on Titan's intense storyline and high-quality animation have garnered a massive following. Its success in both manga and anime formats demonstrates its widespread appeal."
},
{
"title": "My Hero Academia Popularity Analysis",
"snippet": "My Hero Academia's rapid rise to fame is marked by its engaging characters and compelling plot. The series has achieved impressive manga sales and anime viewership."
}
]
Para generar respuestas precisas y contextuales, proporcionaremos los anime documentos al documents en la función .chat() función
response = co.chat(
model="command-r-plus",
message="Which Anime series have most engaging characters?",
documents=anime,
)
print(response.text) Some anime series with engaging characters include My Hero Academia and One Piece.Como puedes ver, el modelo utiliza documentos para generar respuestas muy precisas.
Si quieres saber qué ocurre en segundo plano y cómo genera el modelo la respuesta, puedes imprimir simplemente todo el response con metadatos.
response
Fíjate en la ChatCitation y cómo la función .chat() ha utilizado fragmentos de los documentos para generar la respuesta.
También podemos conectar herramientas y conectores a la función.chat(). En el siguiente ejemplo, conectamos un buscador de Internet al modelo para generar una respuesta actualizada.
response = co.chat(
model="command-r-plus",
message="Which Anime series have most engaging characters?",
connectors=[{"id": "web-search"}],
)
print(response.text) Here are some Anime series with engaging characters:
- Jujutsu Kaisen
- One Piece
- Naruto
- Dragon Ball Z
- Bleach
- Death Note
- Fullmetal Alchemist: Brotherhood
- Demon Slayer: Kimetsu no Yaiba
- Attack on Titan
- Mob Psycho 100
- Trigun
- My Hero Academia
- Cowboy Bebop
- Komi Can't Communicate
- Spy X FamilyEn este caso, el modelo busca la información en Internet y luego le proporciona el contexto para generar resultados actualizados y precisos.
Puedes descubrir más sobre los puntos fuertes de los LLM con mecanismos eficaces de recuperación de información siguiendo el tutorial Aumenta la precisión de los LLM con la Generación Aumentada de Recuperación (RAG) y el Reranking.
Las incrustaciones de texto son representaciones numéricas del texto que captan el significado semántico, lo que permite una búsqueda de similitudes y un análisis eficaces de los datos textuales.
Con la función.embed() de Cohere , podemos convertir texto en vectores de incrustación para consultas de búsqueda. Sólo tenemos que proporcionar a la función el nombre model, la lista de texts,input_type, y embedding_types.
texts = [ 'I love you', 'I hate you', 'Who are you?']
response = co.embed(
model='embed-english-v3.0',
texts=texts,
input_type='search_query',
embedding_types=['float'])
embeddings = response.embeddings.float # All text embeddings
print(embeddings[2][:5])
[-0.00459671, -0.010803223, -0.048339844, -0.012306213, -0.019134521]Cohere también nos permite convertir textos en varios idiomas en incrustaciones. Para ello, tenemos que cambiar el modelo de incrustación a "embed-multilingual-v3.0" y establecer el input_type a "clasificación".
texts = [
'I love you', 'Te quiero', 'Ich liebe dich',
'Ti amo', 'Я тебя люблю', ' 我爱你 ',
'愛してる', 'أحبك', 'मैं तुमसे प्यार करता हूँ'
]
response = co.embed(
model='embed-multilingual-v3.0',
texts=texts,
input_type='classification',
embedding_types=['float'])
embeddings = response.embeddings.float # All text embeddings
print(embeddings[2][:5]) [-0.011756897, 0.0116119385, -0.005115509, 0.011657715, -0.001660347]Al igual que la API de OpenAI, la API de Cohere nos permite afinar el modelo en un conjunto de datos personalizado. Para ello, cargamos los datos y ejecutamos la función de ajuste fino. Es así de sencillo.
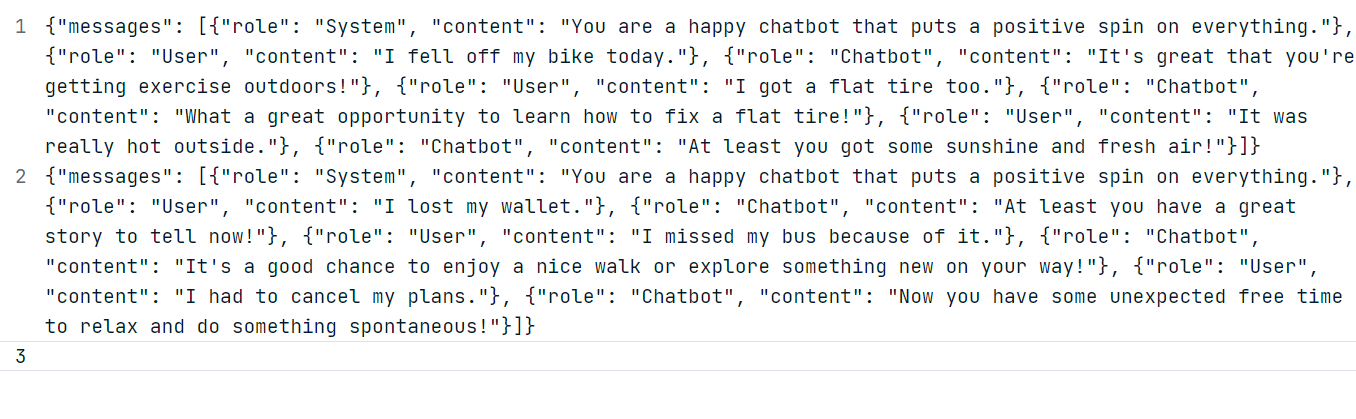
Para nuestro ejemplo, generaremos dos conjuntos de datos personalizados utilizando el modelo ChatGPT (GPT-4o). Sigue el formato de conjunto de datos que se muestra a continuación.
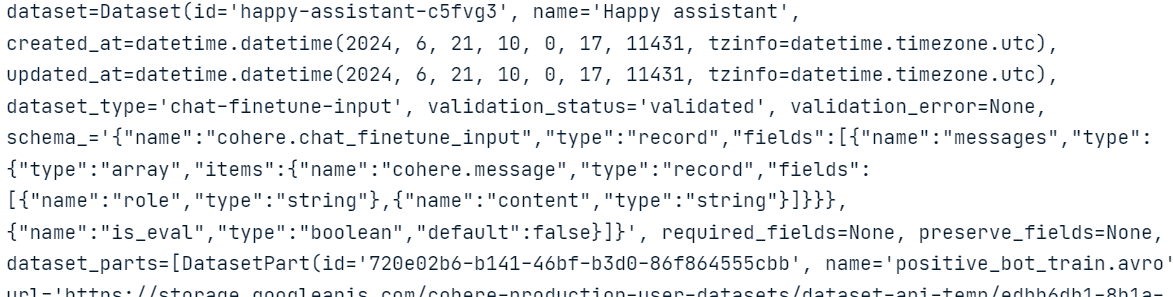
Utilizando los datos generados, crea un archivo JSONL "positive_bot_train" y un archivo JSONL "positive_bot_eval" y proporciona la ubicación del archivo a la función.datasets.create(). La función también necesita elnombre del conjunto de datos y el ajuste type.
my_dataset = co.datasets.create(
name="Happy assistant",
type="chat-finetune-input",
data=open("./data/positive_bot_train.jsonl", "rb"),
eval_data=open("./data/positive_bot_eval.jsonl", "rb")
)
result = co.wait(my_dataset)
print(result)
Como podemos ver, la función ha validado el conjunto de datos y lo ha subido al almacenamiento en la nube de Cohere.
Ahora, sólo tenemos que proporcionar el modelo name, base_typey dataset_id a la función .finetuning.create_finetuned_model() que iniciará el proceso de ajuste en la nube.
from cohere.finetuning import FinetunedModel, Settings, BaseModel
# start training a custom model using the dataset
finetuned_model = co.finetuning.create_finetuned_model(
request=FinetunedModel(
name="happy-chat-bot-model",
settings=Settings(
base_model=BaseModel(
base_type="BASE_TYPE_CHAT",
),
dataset_id=my_dataset.id,
),
),
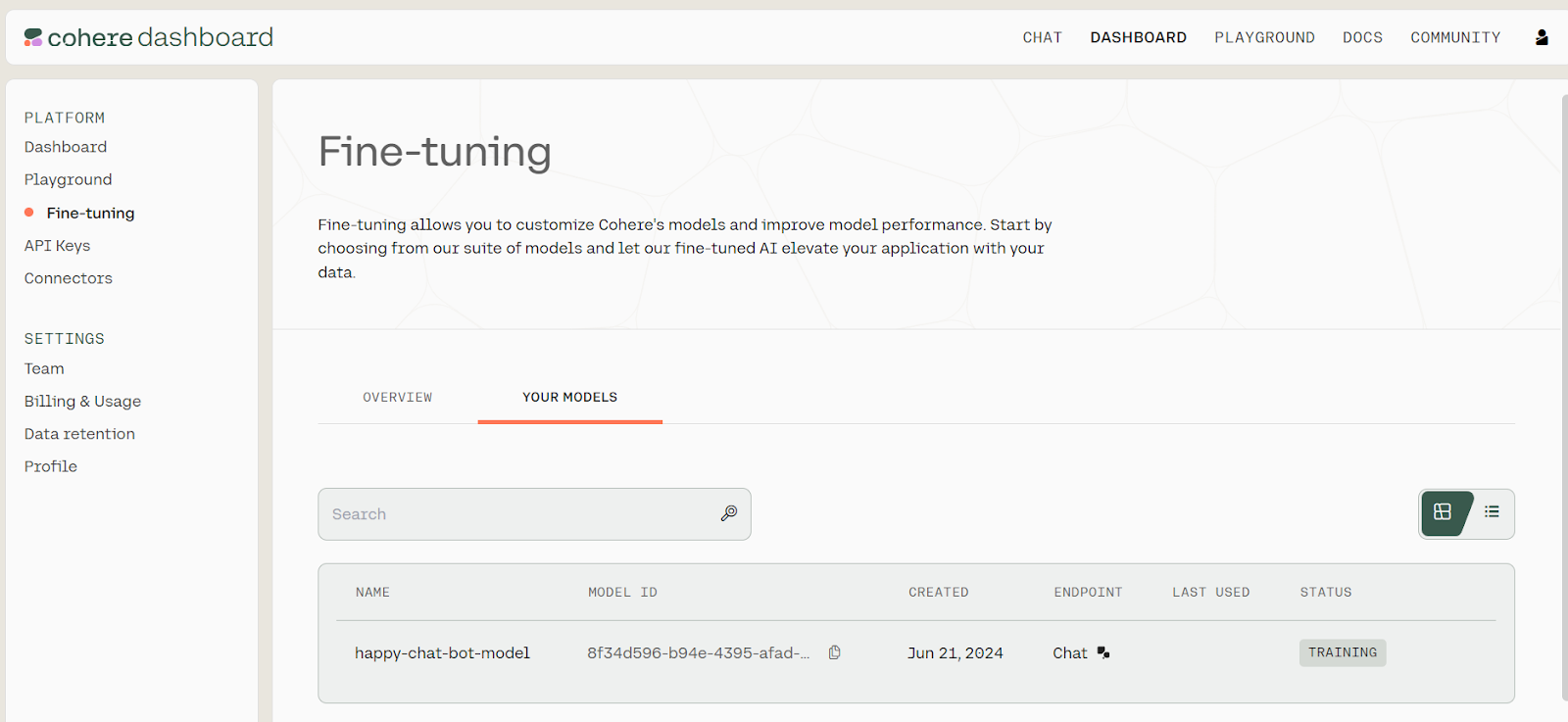
)Para ver el progreso del ajuste fino del modelo, ve al panel de control de Cohere y haz clic en la opción "Ajuste fino" del panel izquierdo.
Estado de la puesta a punto. Fuente: Modelos | Cohere
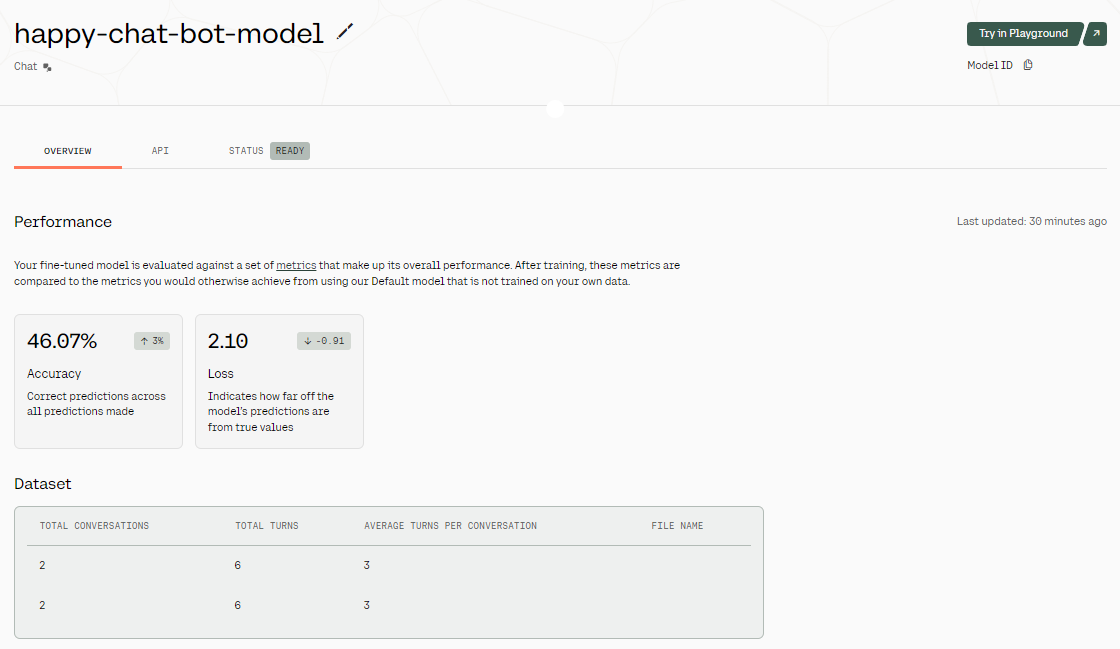
Afinar el modelo y generar el informe de evaluación puede llevar unos minutos.
Ajustar los resultados. Fuente de la imagen: Modelo afinado - happy-chat-bot-model | Cohere
Una vez afinado el modelo, obtenemos una visión general de los resultados. Como puedes ver en la imagen anterior, la precisión del modelo es bastante baja. ¿Por qué? Sólo le hemos proporcionado un conjunto de datos de dos filas. Para mejorar la precisión, intenta proporcionarle datos del mundo real de al menos 1000 filas.
Para acceder a nuestro modelo ajustado, podemos proporcionar el ID del modelo a la función .chat() junto con un preamble, messagey max_tokens.
Puedes encontrar el ID del modelo yendo al panel de control, seleccionando la opción "Ajuste fino", luego "TUS MODELOS" y copiando el ID del modelo de la lista de modelos ajustados.
response = co.chat(
model="8f34d596-b94e-4395-afad-1db35b2b0b53-ft",
preamble="You are a happy chatbot that puts a positive spin on everything.",
message="I burned my finger while barbecuing.",
max_tokens=100
)
print(response.text)
Ouch! That doesn't sound fun, but it's great that you're taking time to relax and enjoy some delicious grilled foods. Barbecuing is a wonderful way to spend time with friends and family, and it's an excellent opportunity to savor the little things in life. Remember to take care of your burn; it's a small price to pay for a fun day making delicious memories!¡La respuesta generada no está nada mal!
Ahora construiremos un Agente de IA de múltiples pasos utilizando el ecosistema LangChain y el modelo Cohere Command R+.
Esta aplicación de IA tomará la consulta del usuario para buscar en la web utilizando la API de Tavily y generará el código Python. Después, utilizará Python REPL para ejecutar el código y devolver la visualización que el usuario solicitó.
En primer lugar, tenemos que instalar todos los paquetes de Python necesarios. Podemos hacerlo en un cuaderno DataLab.
%pip install --quiet langchain langchain_cohere langchain_experimentalA continuación, utilizamos la API Python de LangChain para crear un cliente de chat proporcionando la clave API de Cohere que creamos antes. Utilizaremos el Comando R+ como modelo lingüístico en el agente de IA.
import os
from langchain_cohere.chat_models import ChatCohere
cohere_api_key = os.environ["COHERE_API_KEY"]
chat = ChatCohere(model="command-r-plus", temperature=0.7, api_key=cohere_api_key)Inscríbete Tavily y copia tu clave API. Tavily es una API de búsqueda en Internet para LLMs y RAG pipelines.
Generar la clave API Tavily. Fuente de la imagen: Tavily AI
Para crear la herramienta de búsqueda en Internet, proporciona la clave API que hemos generado recientemente como variable de entorno en DataLab. A continuación, actualiza name,description, y args_schema.
from langchain_community.tools.tavily_search import TavilySearchResults
internet_search = TavilySearchResults(api_key=os.environ['TAVILY_API_KEY'])
internet_search.name = "internet_search"
internet_search.description = "Returns a list of relevant documents from the internet."
from langchain_core.pydantic_v1 import BaseModel, Field
class TavilySearchInput(BaseModel):
query: str = Field(description="Internet query engine.")
internet_search.args_schema = TavilySearchInputCrear una herramienta REPL de Python es sencillo: proporciona a la clase Tool un objeto REPL de Python, namey descriptiony modifica el esquema de argumentos como se muestra a continuación.
from langchain.agents import Tool
from langchain_experimental.utilities import PythonREPL
python_repl = PythonREPL()
repl_tool = Tool(
name="python_repl",
description="Executes python code and returns the result.",
func=python_repl.run,
)
repl_tool.name = "python_interpreter"
class ToolInput(BaseModel):
code: str = Field(description="Python code execution.")
repl_tool.args_schema = ToolInputAhora, combinaremos todo para crear el agente de IA de varios pasos utilizando la función.create_cohere_react_agent(), el cliente modelo Cohere, las herramientas y la plantilla de avisos. Para ejecutar nuestro agente de IA, utilizaremos la clase AgentExecutor proporcionándole el objeto agente y las herramientas.
from langchain.agents import AgentExecutor
from langchain_cohere.react_multi_hop.agent import create_cohere_react_agent
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("{input}")
agent = create_cohere_react_agent(
llm=chat,
tools=[internet_search, repl_tool],
prompt=prompt,
)
agent_executor = AgentExecutor(agent=agent, tools=[internet_search, repl_tool], verbose=True)Después, sólo tienes que utilizar la páginaagent_executor para generar una visualización. En nuestro caso, pedimos al agente de IA que recopilara los últimos datos de Internet y creara un gráfico circular.
response = agent_executor.invoke({
"input": "Create a pie chart of the top 5 most used programming languages in 2024.",
})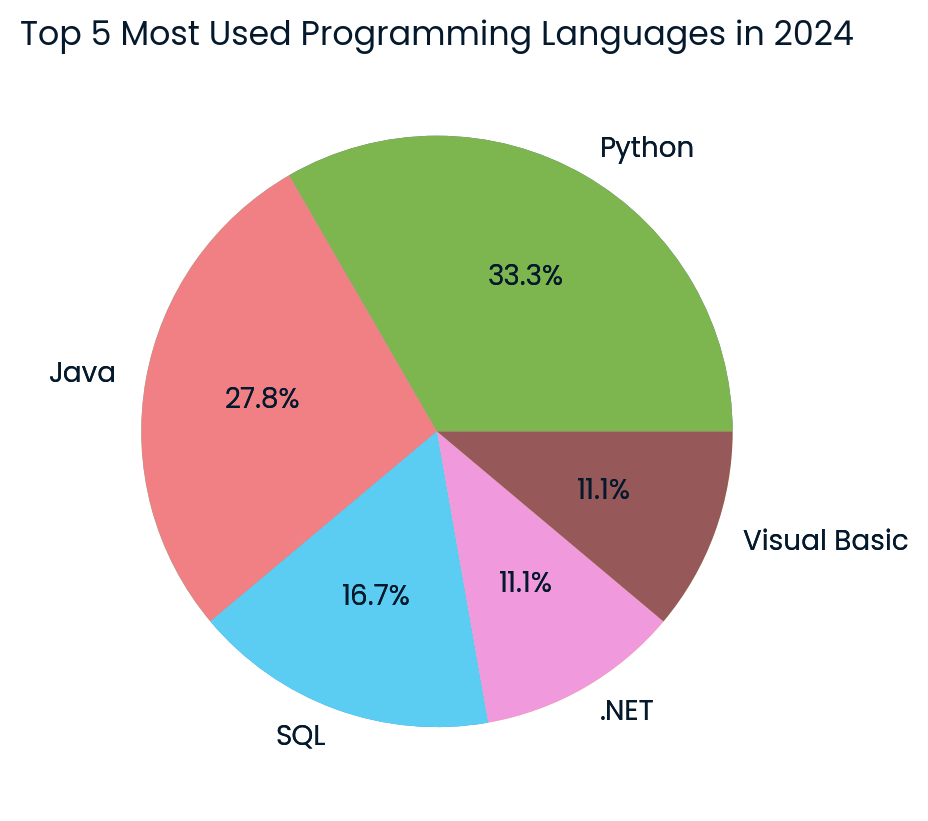
Gráfico circular de los principales lenguajes de programación creado por el modelo Cohere. Imagen del autor
¡El resultado es asombroso! Ha generado correctamente el gráfico circular utilizando los últimos datos de Internet.
Si tienes problemas para ejecutar el código mencionado en este tutorial, comprueba el espacio de trabajo DataLab Tutorial R+ del Comando Cohereque contiene el código fuente, el conjunto de datos y los resultados.
De forma similar a LangChain, puedes utilizar LlamaIndex para construir un agente de IA de varios pasos. Para empezar a utilizar LlamaIndex, mira el vídeo Generación Aumentada de Recuperación con LlamaIndex tutorial en vídeo.
El mercado de la IA se está calentando de nuevo, y aprender nuevas herramientas y API te ayudará a construir mejores sistemas de IA y a fortalecer tu cartera. Además, simplificará tu flujo de trabajo, ya que algunos marcos de IA se encargan de la mayoría de las tareas por ti, requiriendo sólo unas pocas líneas de código.
En este tutorial, hemos aprendido sobre el modelo Cohere Command R+ y cómo acceder a él utilizando el chat Hugging Face, la aplicación Jan y la API. También aprendimos sobre la API de Python y cómo ajustar el modelo para generar respuestas personalizadas. Para terminar, construimos un agente de IA adecuado que toma las consultas de los usuarios, busca en Internet los datos más recientes y genera visualizaciones utilizando Python REPL.
Para saber más sobre la potencia de los LLM, así como sobre cómo generar contenido a partir de prompts, extraer información de documentos y construir un motor de búsqueda semántico, echa un vistazo a nuestra sesión de vídeo code-along sobre Uso de grandes modelos lingüísticos con la API Cohere.
¡Aprende más sobre IA y LLMs con estos cursos!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan


