




Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
100K
Você deseja expandir seu conhecimento sobre IA com um projeto prático? Neste tutorial, exploraremos o Cohere Command R+, inclusive como acessá-lo on-line e localmente. Você também conhecerá os principais recursos da API Cohere Python e criará um projeto de IA usando LangChain e Tavily.
A parte interessante começa com o projeto. Se você já estiver familiarizado com os modelos Cohere e seus recursos, fique à vontade para pular diretamente para a seção do projeto. Lá, você aprenderá a criar um agente de IA que usa várias ferramentas em sequência para concluir uma tarefa.
Se você é novo em IA e deseja saber mais sobre o campo, considere fazer o programa AI Fundamentals. Você obterá conhecimento prático sobre tópicos populares de IA, como ChatGPT, modelos de linguagem grandes (LLMs), IA generativa e muito mais.
O Command R+ é o LLM mais recente e de última geração da Cohere. O modelo é excelente em interações de conversação e tarefas de contexto longo. Ele é especialmente otimizado para fluxos de trabalho complexos do Retrieval Augmented Generation (RAG) e para o uso de ferramentas em várias etapas, o que o torna uma ferramenta poderosa para aplicativos de escala empresarial.
Imagem do autor
Esses são alguns dos recursos mais relevantes do modelo Command R+.
Para que você entenda melhor os modelos do Cohere, leia o tutorial da API do Cohere em: Primeiros passos com os modelos Cohere.
Há várias maneiras de acessar os modelos Cohere, a maioria das quais é gratuita.
Você pode acessar o playground on-line do LLM ou fazer o download do modelo localmente e usá-lo com um aplicativo de bate-papo. Além disso, você também pode acessá-lo por meio da API Cohere. Vamos analisar cada um desses métodos.
A maneira mais direta de acessar o Cohere Command R+ on-line é por meio do HuggingChat para você. Ele não tem limitações, e você também pode conectá-lo a seis ferramentas disponíveis para diferentes tarefas, como geração de imagens ou pesquisa na Internet.
1. Vá para o site https://huggingface.co/chat/ site.
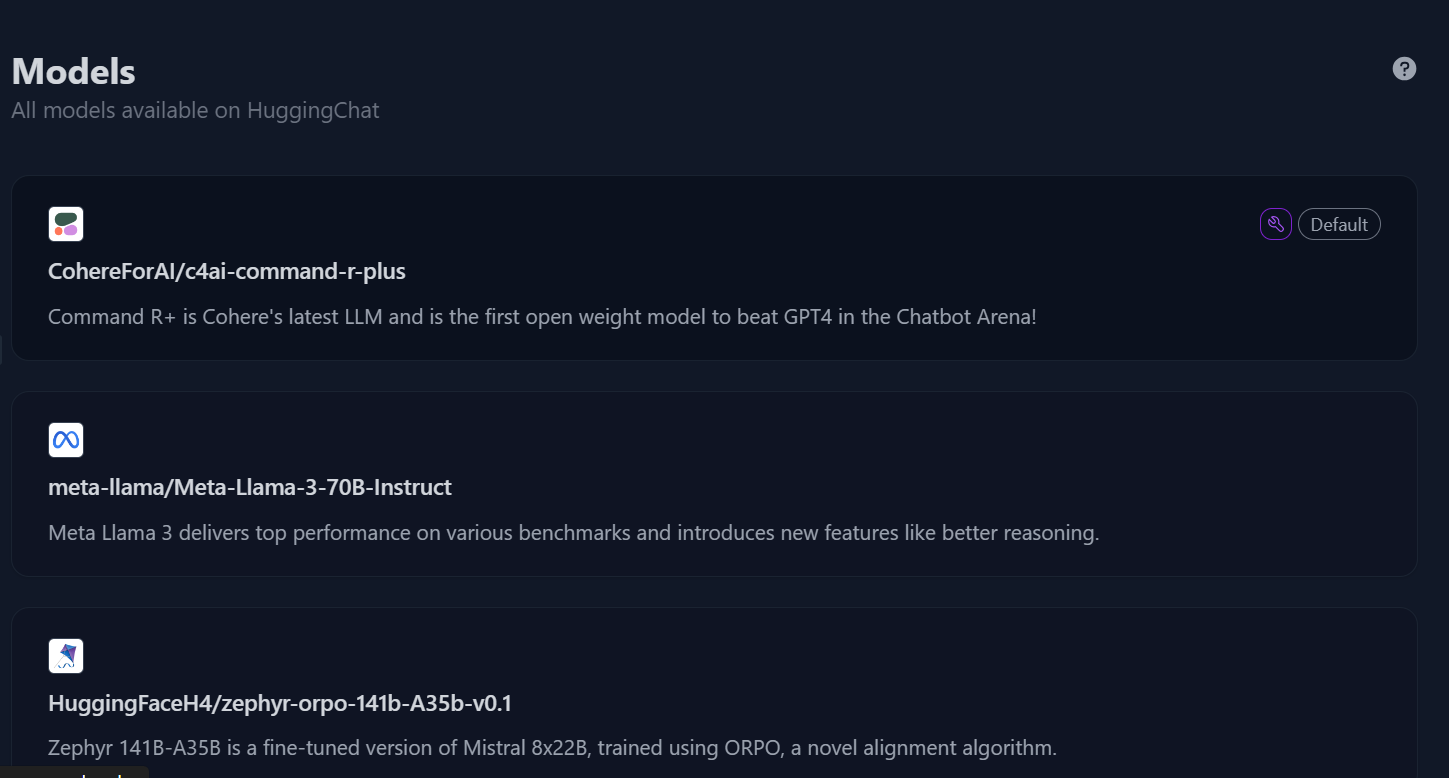
2. No painel esquerdo, clique no botão "Models" (Modelos) para acessar o menu do modelo e, em seguida, selecione o modelo "c4ai-command-r-plus".
Diretório de modelos no Hugging Chat. Fonte da imagem: HuggingChat
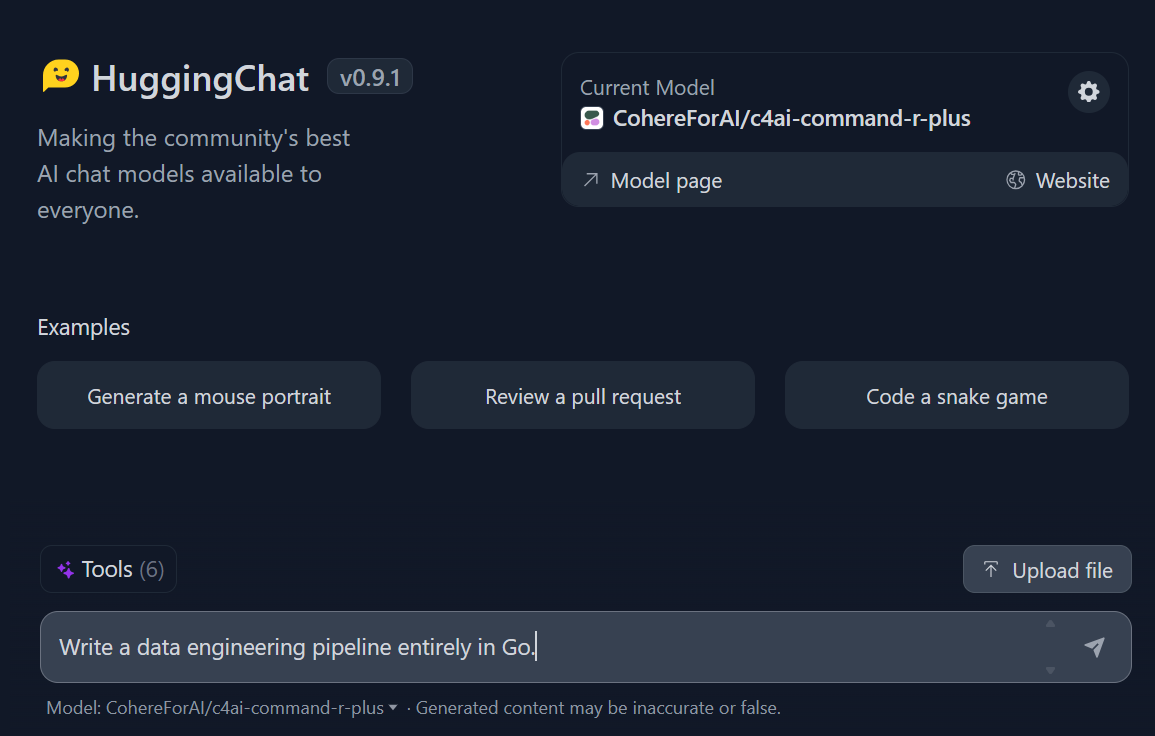
3. Comece a escrever a consulta e ela gerará uma resposta rápida e altamente precisa.
Prompting no Hugging Chat. Fonte da imagem: HuggingChat
Você pode usar o Command R+ localmente de duas maneiras: fazendo o download do modelo em seu computador local ou fornecendo uma chave de API ao aplicativo de bate-papo Jan.
Vamos explorar a segunda opção.
1. Faça o download e instale o Jan em https://jan.ai/ site.
2. Acesse o hub do modelo clicando no botão de janelas no painel esquerdo.
Diretório de modelos no aplicativo Jan
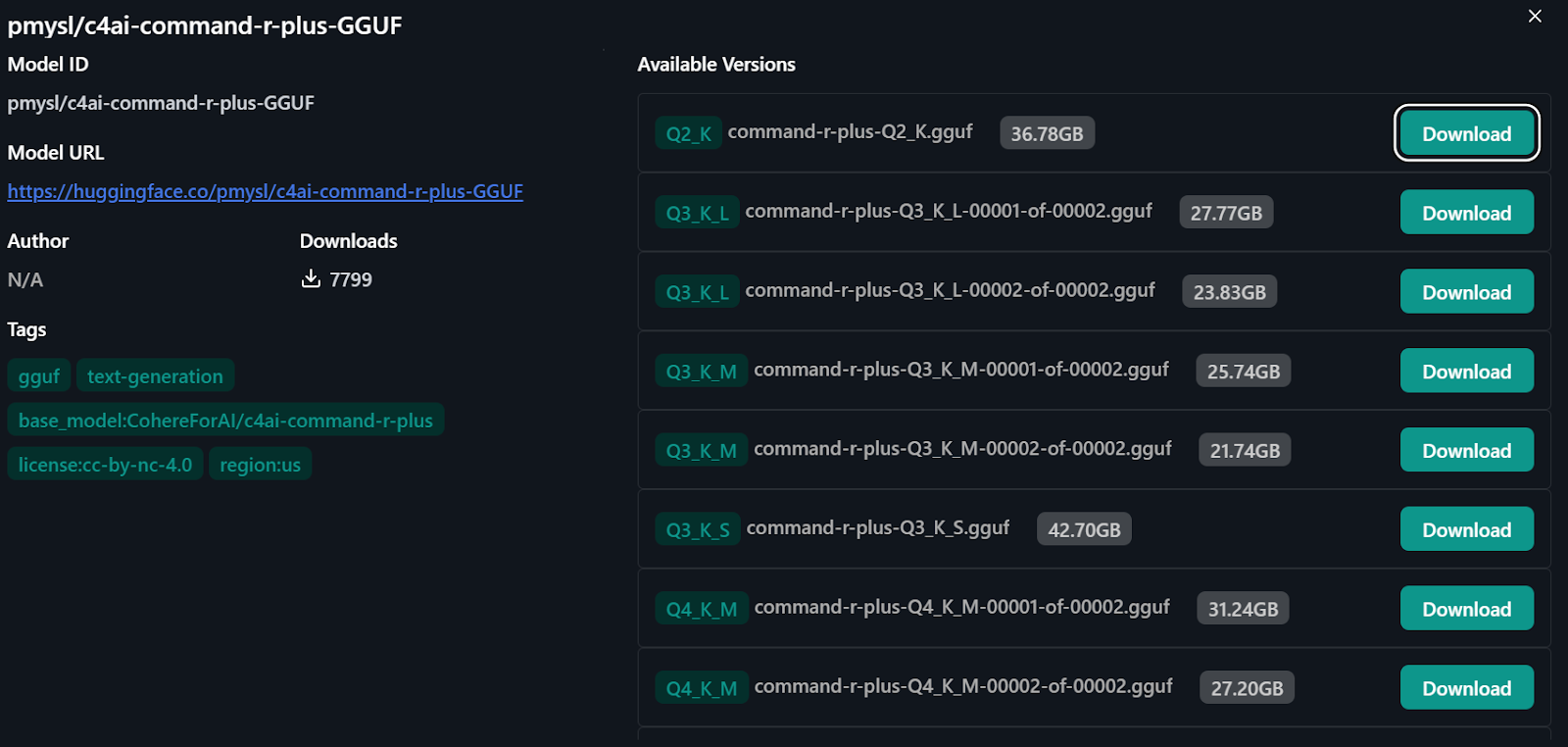
3. Para acessar o modelo Command R+, digite "pmysl/c4ai-command-r-plus-GGUF" na barra de pesquisa do hub de modelos.
4. Faça o download e comece a usar a "versão Q4_K_M" do modelo, que tem cerca de 31,24 GB.
Importando o modelo do Hugging Face
Outra maneira de usar o modelo Command R+ localmente é conectar a API Cohere ao aplicativo Jan.
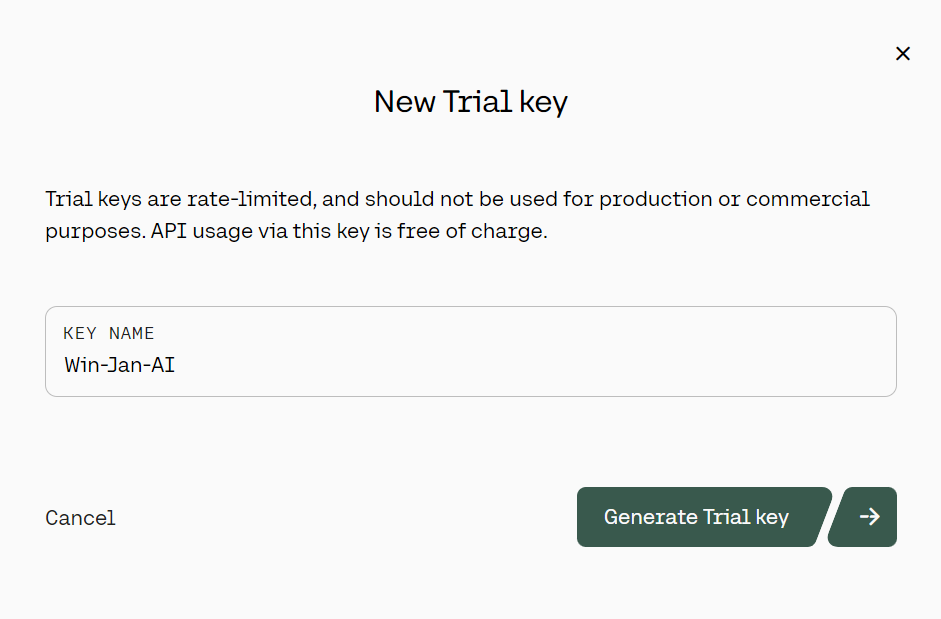
1. Vá para o site https://coral.cohere.com/ e faça login.
2. Vá para o "Painel de controle".
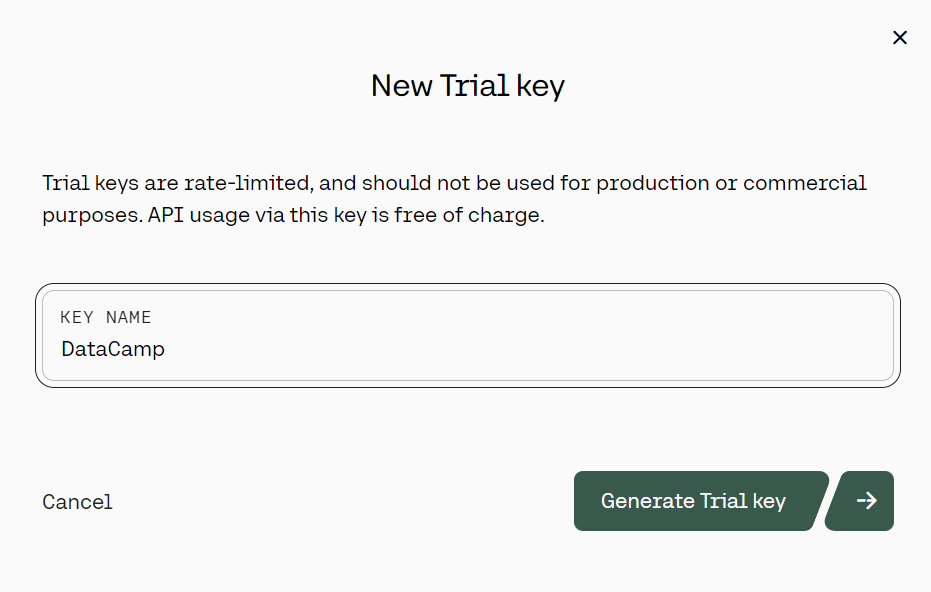
3. No painel esquerdo, clique no botão "Chaves de API", role para baixo e clique em "+ Criar chave de trilha".
Geração da chave da API de avaliação do Cohere. Fonte: cohere.com
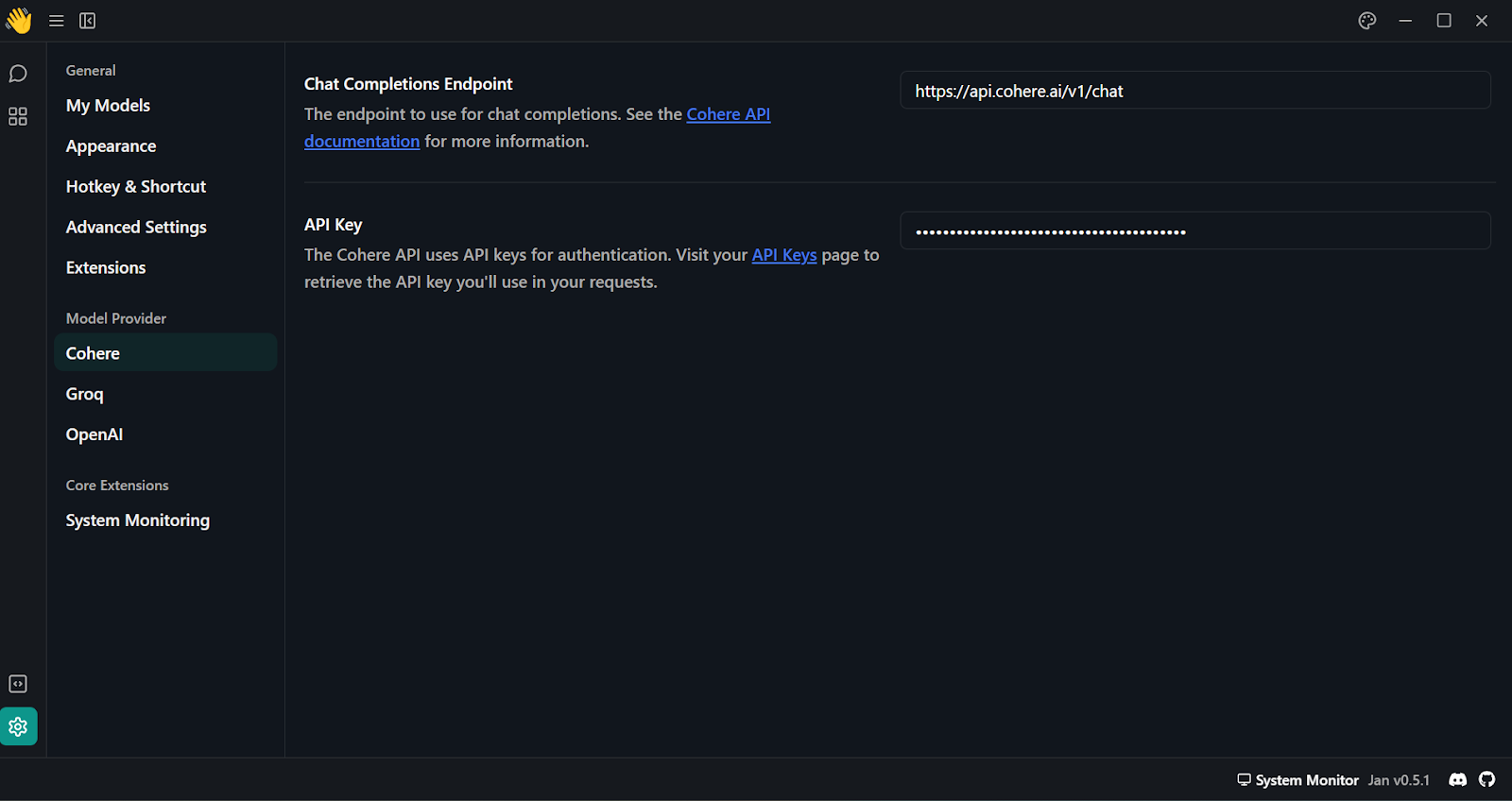
4. Depois de gerar a chave da API do Cohere, cole-a na seção "Model Provider" (Provedor de modelo). Você pode acessar esse menu em "Configurações" e procurar por "Cohere".
Adicionando a chave da API Cohere no aplicativo Jan
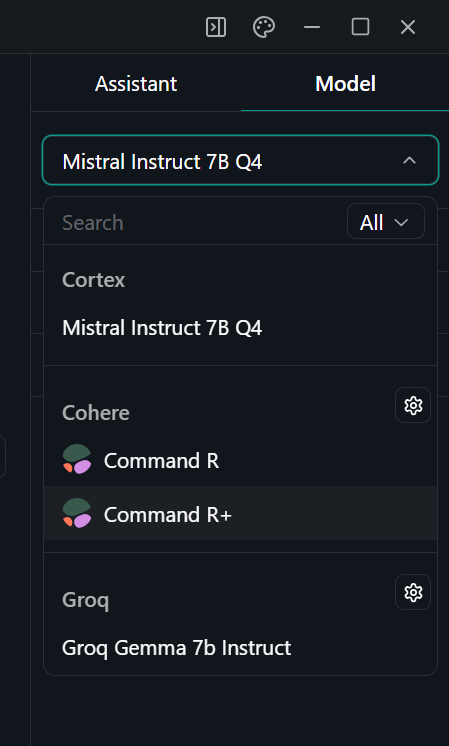
5. Selecione o modelo Command R+ acessando o menu "Thread" e, no painel direito, selecione o modelo adequado.
Selecionando o modelo no aplicativo Jan
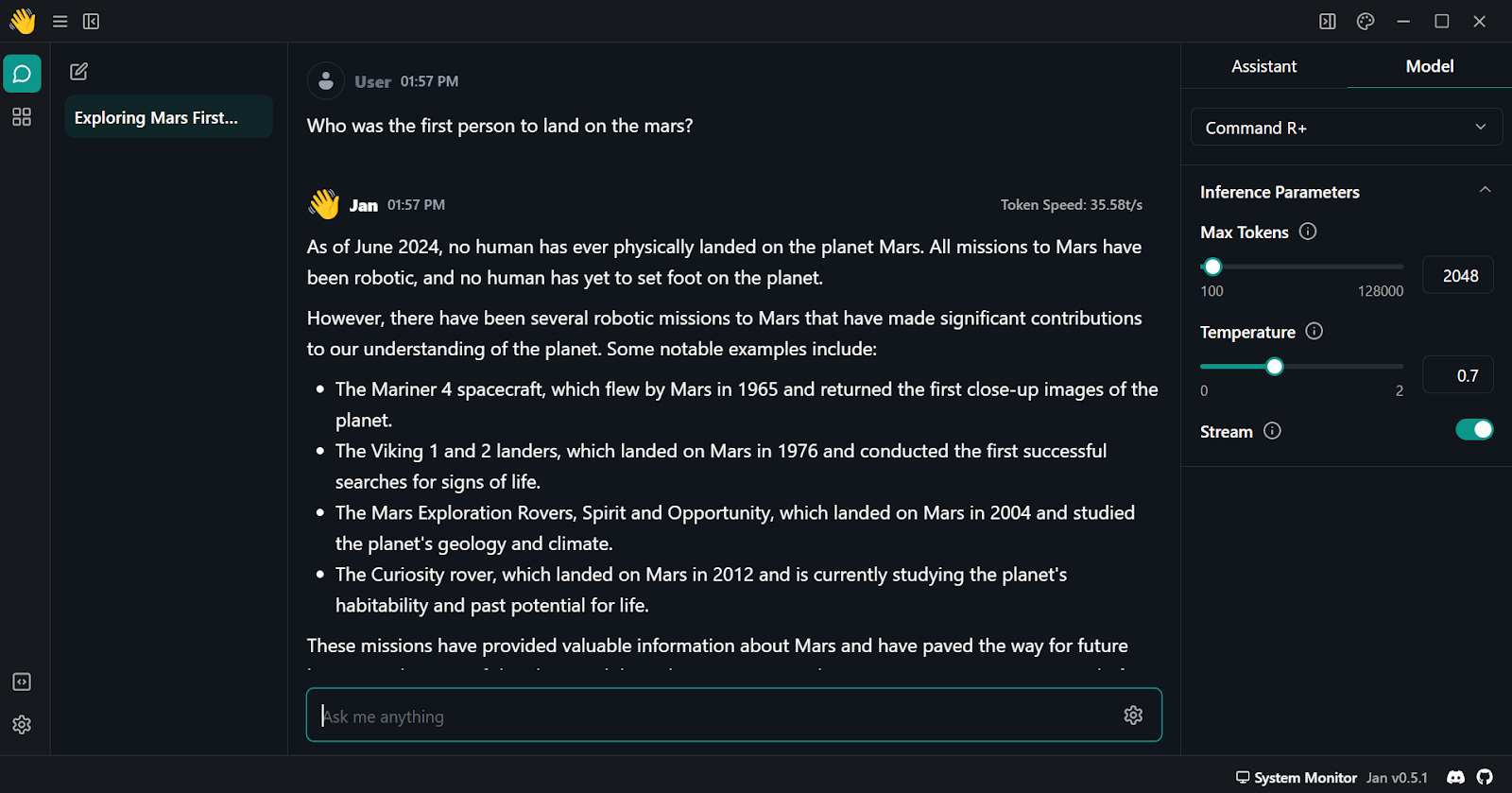
6. Inicie o prompt e verifique se você está usando-o com a opção "Stream" ativada.
Usando o Cohere Command R plus no aplicativo Jan
Nesta seção, você aprenderá a configurar e usar a API do Python para gerar a resposta.
1. Instale o pacote Python do Cohere usando o pip.
pip install cohere2. Gerar uma nova chave de API Cohere. Você pode seguir as etapas da seção "Usando o Cohere Command R+ por meio da API".
Geração da chave da API de avaliação do Cohere. Fonte da imagem: cohere.com
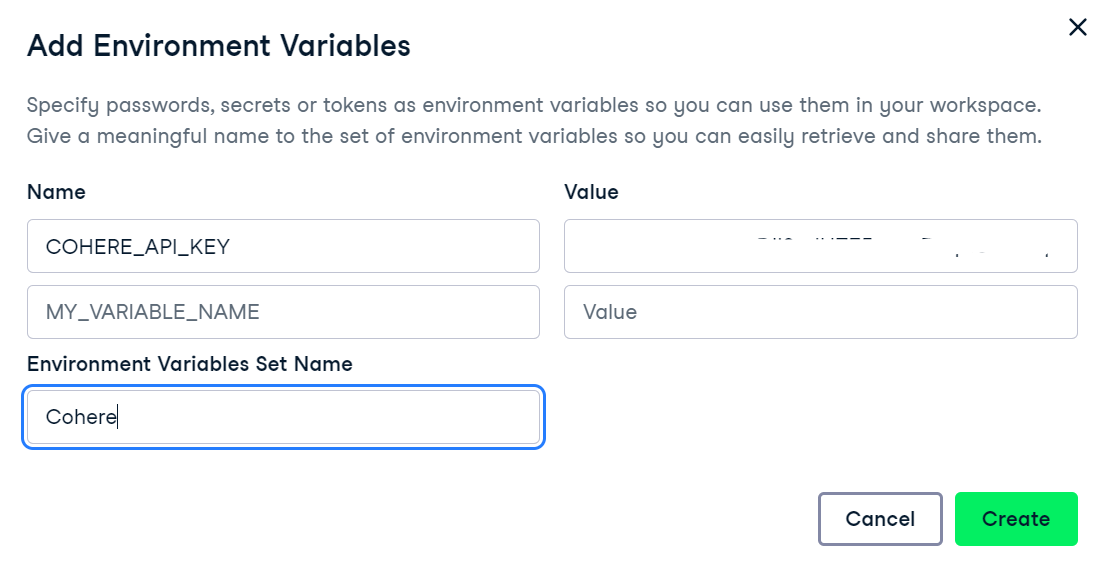
3. Usaremos o DataLab da DataCamp como nosso ambiente de desenvolvimento. Para configurar variáveis de ambiente no DataLab, siga estas etapas:
Adição de variáveis de ambiente no DataLab
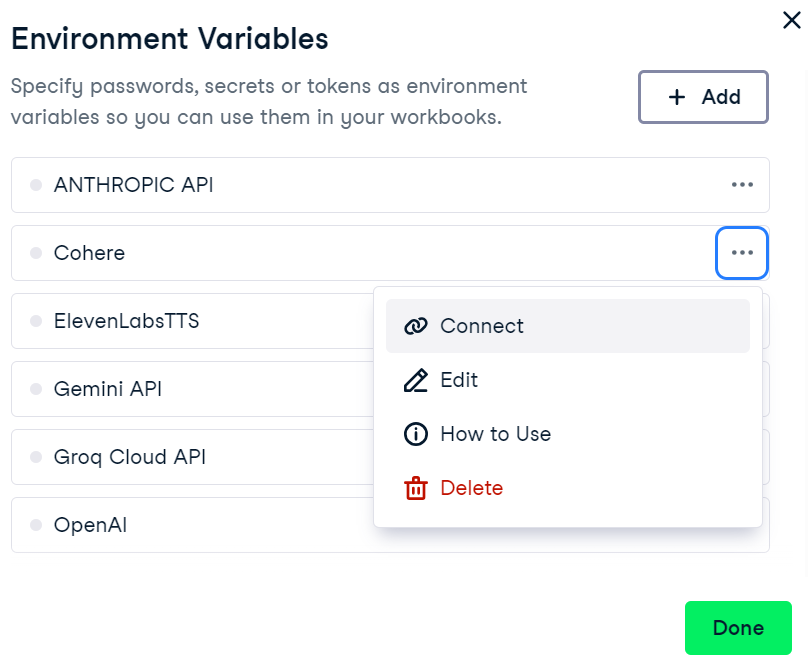
4. Para ativar a variável de ambiente no DataCamp's DataLab, acesse o menu de variáveis de ambiente, clique nos três pontos ao lado de "Cohere" e, em seguida, clique em "Connect".
Conectando a variável de ambiente Cohere no DataLab
5. Agora, em seu notebook, inicie o cliente Cohere fornecendo a chave da API. Isso pode ser feito importando a biblioteca Cohere e criando um objeto cliente com sua chave de API.
import os
import cohere
cohere_api_key = os.environ["COHERE_API_KEY"]
co = cohere.Client(api_key=cohere_api_key)6. Para gerar uma resposta usando afunção .chat() , forneça o nome model e o endereçomessage.
response = co.chat(
model="command-r-plus",
message="Please help me write an email to the angry boss, who thinks I made the changes to the data pipeline but didn't. It was James."
)
print(response.text)
Resposta do modelo à consulta fornecida
A geração de respostas deve ser rápida e altamente relevante!
Na próxima seção, exploraremos vários recursos da API do Cohere Python.
Agora, exploraremos a API Cohere Python para gerar respostas com histórico, transmitir respostas e obter resultados previsíveis. Também executaremos o RAG, converteremos o texto em embeddings e faremos o ajuste fino do modelo em um conjunto de dados personalizado.
Na seção anterior, aprendemos a gerar respostas usando uma função.chat() simples . Agora, forneceremos a ele argumentos adicionais, como prompt do sistema (preamble ), chat_history,max_tokens, e temperature.
response = co.chat(
model="command-r-plus",
preamble="You are a happy chatbot that puts a positive spin on everything.",
chat_history=[
{"role": "USER", "text": "Hey, my name is Abid!"},
{"role": "CHATBOT", "text": "Hey Abid! How can I help you today?"},
],
message="I can't swim?",
max_tokens=150,
temperature=0.7
)
print(response.text)
Modelo de resposta com os argumentos adicionais fornecidos
Com base nos argumentos adicionais, o modelo modificou a resposta.
Também podemos transmitir a resposta usando a função.chat_stream(). Essa função nos permite gerar respostas em tempo real, produzindo tokens à medida que eles se tornam disponíveis, o que aumenta a velocidade percebida do modelo.
response = co.chat_stream(
model="command-r-plus",
message="Tell me something interesting about the galaxy?"
)
for event in response:
if event.event_type == "text-generation":
print(event.text, end="")
elif event.event_type == "stream-end":
print(event.finish_reason, end="")
Modelo de retorno de tokens em tempo real
O resultado previsível é um recurso exclusivo do Cohere. Ao definir o argumento seed, podemos fazer com que o modelo gere a mesma resposta para o mesmo prompt.
Normalmente, quando você faz a mesma pergunta a um LLM duas vezes, recebe uma resposta diferente. Ao definir o endereço seed, você garante resultados consistentes e reproduzíveis, como qualquer modelo de machine learning.
No exemplo a seguir, ao definir o argumento seed para 55, você sempre receberá "Matilda" como resposta.
res = co.chat(model="command-r", message="say a random name", seed=55)
print(res.text)Sure! I will pick a random name for you. How about "Matilda"?Para testar nossa teoria, fizemos novamente a mesma pergunta ao modelo com o mesmo seed.
res = co.chat(model="command-r", message="say a random name", seed=55)
print(res.text)Sure! I will pick a random name for you. How about "Matilda"?E o resultado foi o mesmo!
A API do Cohere oferece uma função integrada para executar o RAG. Você só precisa fornecer à função .chat() um argumentodocuments. Ao fazer uma pergunta, ele executará uma pesquisa de similaridade nos documentos para gerar respostas com reconhecimento de contexto.
Usaremos documentos de pesquisa de anime como exemplo. O formato dos documentos deve ser semelhante ao exemplo abaixo. Cada documento deve conter as chaves title e snippet.
anime = [
{
"title": "Naruto Popularity Analysis",
"snippet": "Naruto's global success: massive manga sales, top anime ratings, extensive merchandise, and a dedicated fanbase. The series' impact on anime culture and its influence on subsequent shonen series is undeniable."
},
{
"title": "One Piece Popularity Analysis",
"snippet": "One Piece's record-breaking manga sales and its status as a long-running anime phenomenon highlight its popularity. The series' captivating story and characters have made it a staple in the anime community."
},
{
"title": "Attack on Titan Popularity Analysis",
"snippet": "Attack on Titan's intense storyline and high-quality animation have garnered a massive following. Its success in both manga and anime formats demonstrates its widespread appeal."
},
{
"title": "My Hero Academia Popularity Analysis",
"snippet": "My Hero Academia's rapid rise to fame is marked by its engaging characters and compelling plot. The series has achieved impressive manga sales and anime viewership."
}
]
Para gerar respostas precisas e contextuais, forneceremos os anime documentos para o argumento documents na função .chat() função.
response = co.chat(
model="command-r-plus",
message="Which Anime series have most engaging characters?",
documents=anime,
)
print(response.text) Some anime series with engaging characters include My Hero Academia and One Piece.Como você pode ver, o modelo usa documentos para gerar respostas altamente precisas.
Se quiser saber o que está acontecendo em segundo plano e como o modelo gera a resposta, você pode simplesmente imprimir todo o response com metadados.
response
Observe a parte ChatCitation e como a função Cohere's .chat() usou trechos dos documentos para gerar a resposta.
Também podemos conectar ferramentas e conectores à função.chat(). No exemplo a seguir, conectamos um mecanismo de pesquisa da Internet ao modelo para gerar uma resposta atualizada.
response = co.chat(
model="command-r-plus",
message="Which Anime series have most engaging characters?",
connectors=[{"id": "web-search"}],
)
print(response.text) Here are some Anime series with engaging characters:
- Jujutsu Kaisen
- One Piece
- Naruto
- Dragon Ball Z
- Bleach
- Death Note
- Fullmetal Alchemist: Brotherhood
- Demon Slayer: Kimetsu no Yaiba
- Attack on Titan
- Mob Psycho 100
- Trigun
- My Hero Academia
- Cowboy Bebop
- Komi Can't Communicate
- Spy X FamilyNesse caso, o modelo procura as informações na Internet e, em seguida, fornece ao modelo o contexto para gerar resultados atualizados e precisos.
Você pode descobrir mais sobre os pontos fortes dos LLMs com mecanismos eficazes de recuperação de informações seguindo o tutorial Aumente a precisão do LLM com Retrieval Augmented Generation (RAG) e Reranking.
As incorporações de texto são representações numéricas de texto que capturam o significado semântico, permitindo a pesquisa de similaridade eficiente e a análise de dados textuais.
Com a função.embed() do Cohere , podemos converter texto em vetores de incorporação para consultas de pesquisa. Você só precisa fornecer à função o nome model, a lista de texts,input_type e embedding_types.
texts = [ 'I love you', 'I hate you', 'Who are you?']
response = co.embed(
model='embed-english-v3.0',
texts=texts,
input_type='search_query',
embedding_types=['float'])
embeddings = response.embeddings.float # All text embeddings
print(embeddings[2][:5])
[-0.00459671, -0.010803223, -0.048339844, -0.012306213, -0.019134521]O Cohere também nos permite converter textos em vários idiomas em embeddings. Para isso, precisamos alterar o modelo de incorporação para "embed-multilingual-v3.0" e definir input_type como "classification".
texts = [
'I love you', 'Te quiero', 'Ich liebe dich',
'Ti amo', 'Я тебя люблю', ' 我爱你 ',
'愛してる', 'أحبك', 'मैं तुमसे प्यार करता हूँ'
]
response = co.embed(
model='embed-multilingual-v3.0',
texts=texts,
input_type='classification',
embedding_types=['float'])
embeddings = response.embeddings.float # All text embeddings
print(embeddings[2][:5]) [-0.011756897, 0.0116119385, -0.005115509, 0.011657715, -0.001660347]Assim como a API OpenAI, a API Cohere permite que você faça o ajuste fino do modelo em um conjunto de dados personalizado. Para isso, carregamos os dados e executamos a função de ajuste fino. É simples assim.
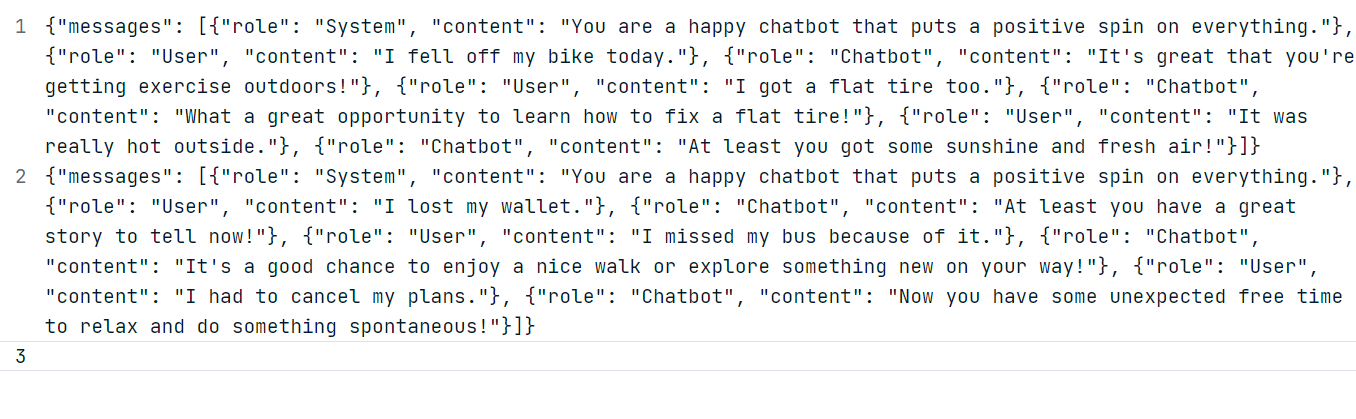
Para o nosso exemplo, vamos gerar dois conjuntos de dados personalizados usando o modelo ChatGPT (GPT-4o). Siga o formato do conjunto de dados mostrado abaixo.
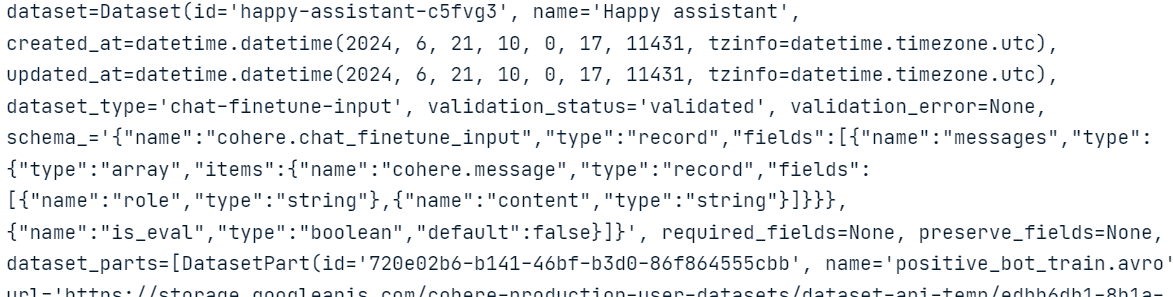
Usando os dados gerados, crie um arquivo JSONL "positive_bot_train" e um "positive_bot_eval" e forneça o local do arquivo para a função.datasets.create(). A função também requer onome do conjunto de dados e o ajuste fino type.
my_dataset = co.datasets.create(
name="Happy assistant",
type="chat-finetune-input",
data=open("./data/positive_bot_train.jsonl", "rb"),
eval_data=open("./data/positive_bot_eval.jsonl", "rb")
)
result = co.wait(my_dataset)
print(result)
Como podemos ver, a função validou o conjunto de dados e o carregou no armazenamento em nuvem do Cohere.
Agora, só precisamos fornecer o modelo name, base_type, e dataset_id para a função .finetuning.create_finetuned_model() que iniciará o processo de ajuste fino na nuvem.
from cohere.finetuning import FinetunedModel, Settings, BaseModel
# start training a custom model using the dataset
finetuned_model = co.finetuning.create_finetuned_model(
request=FinetunedModel(
name="happy-chat-bot-model",
settings=Settings(
base_model=BaseModel(
base_type="BASE_TYPE_CHAT",
),
dataset_id=my_dataset.id,
),
),
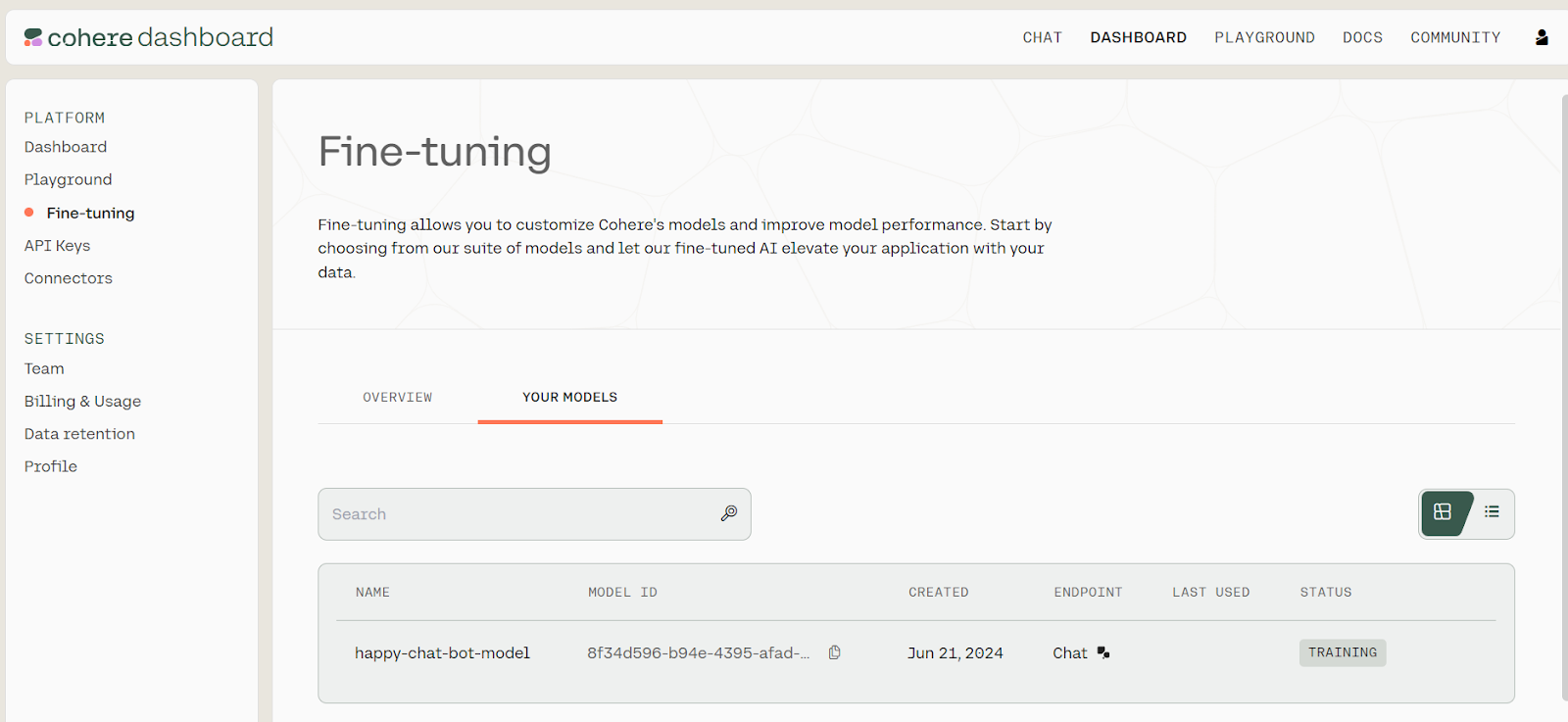
)Para visualizar o progresso do ajuste fino do modelo, acesse o painel do Cohere e clique na opção "Fine-tuning" (Ajuste fino) no painel esquerdo.
Status de ajuste fino. Fonte: Modelos | Cohere
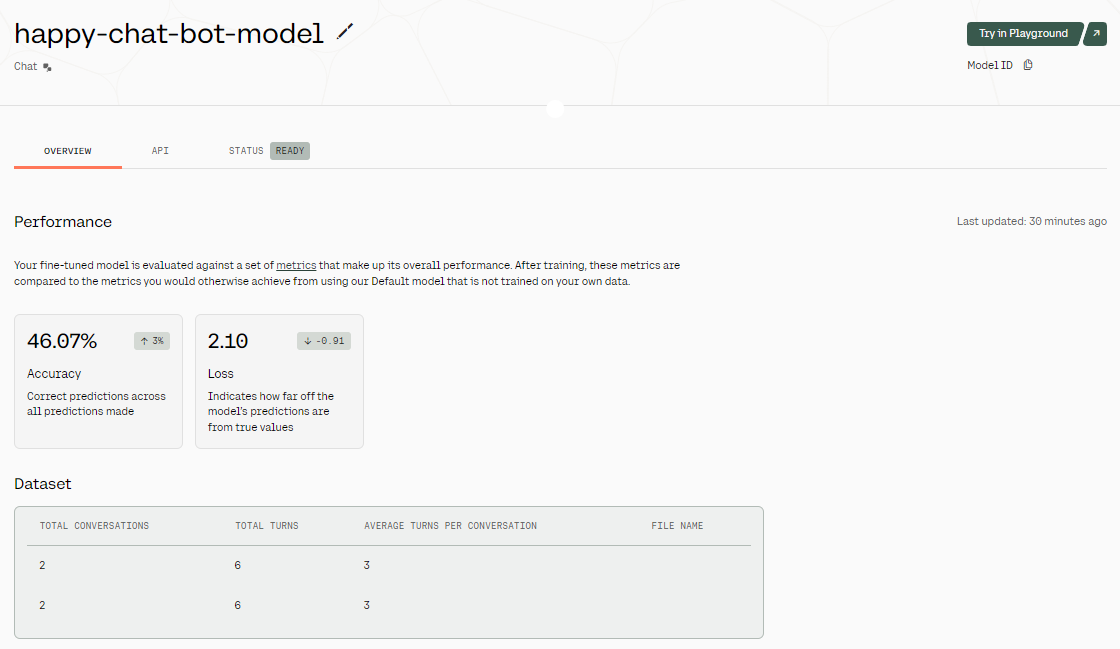
Você pode levar alguns minutos para fazer o ajuste fino do modelo e gerar o relatório de avaliação.
Resultados de ajuste fino. Fonte da imagem: Modelo ajustado - happy-chat-bot-model | Cohere
Depois que o modelo é ajustado, temos uma visão geral dos resultados. Como você pode ver na imagem acima, a precisão do modelo é bastante baixa. Por quê? Fornecemos a ele apenas um conjunto de dados de duas linhas. Para aumentar a precisão, tente fornecer a ele dados do mundo real de pelo menos 1.000 linhas.
Para acessar nosso modelo ajustado, podemos fornecer o ID do modelo para a função .chat() juntamente com um preamble, message, e max_tokens.
Você pode encontrar o ID do modelo acessando o painel, selecionando a opção "Ajuste fino", depois "SEUS MODELOS" e copiando o ID do modelo da lista de modelos ajustados.
response = co.chat(
model="8f34d596-b94e-4395-afad-1db35b2b0b53-ft",
preamble="You are a happy chatbot that puts a positive spin on everything.",
message="I burned my finger while barbecuing.",
max_tokens=100
)
print(response.text)
Ouch! That doesn't sound fun, but it's great that you're taking time to relax and enjoy some delicious grilled foods. Barbecuing is a wonderful way to spend time with friends and family, and it's an excellent opportunity to savor the little things in life. Remember to take care of your burn; it's a small price to pay for a fun day making delicious memories!A resposta gerada não é de todo ruim!
Agora, criaremos um agente de IA de várias etapas usando o ecossistema LangChain e o modelo Cohere Command R+.
Esse aplicativo de IA receberá a consulta do usuário para pesquisar na Web usando a API da Tavily e gerará o código Python. Em seguida, ele usará o Python REPL para executar o código e retornar a visualização que o usuário solicitou.
Primeiro, precisamos instalar todos os pacotes Python necessários. Você pode fazer isso em um notebook do DataLab.
%pip install --quiet langchain langchain_cohere langchain_experimentalEm seguida, usamos a API Python da LangChain para criar um cliente de bate-papo, fornecendo a chave da API Cohere que criamos anteriormente. Usaremos o Command R+ como modelo de linguagem no agente de IA.
import os
from langchain_cohere.chat_models import ChatCohere
cohere_api_key = os.environ["COHERE_API_KEY"]
chat = ChatCohere(model="command-r-plus", temperature=0.7, api_key=cohere_api_key)Inscreva-se para Tavily e copie sua chave de API. Tavily é uma API de pesquisa na Internet para LLMs e pipelines RAG.
Geração da chave da API da Tavily. Fonte da imagem: IA de Tavily
Para criar a ferramenta de pesquisa na Internet, forneça a chave de API que geramos recentemente como uma variável de ambiente no DataLab. Em seguida, atualize os sites name,description e args_schema.
from langchain_community.tools.tavily_search import TavilySearchResults
internet_search = TavilySearchResults(api_key=os.environ['TAVILY_API_KEY'])
internet_search.name = "internet_search"
internet_search.description = "Returns a list of relevant documents from the internet."
from langchain_core.pydantic_v1 import BaseModel, Field
class TavilySearchInput(BaseModel):
query: str = Field(description="Internet query engine.")
internet_search.args_schema = TavilySearchInputCriar uma ferramenta Python REPL é simples: forneça à classe Tool com um objeto Python REPL, name, e descriptione modifique o esquema de argumentos conforme mostrado abaixo.
from langchain.agents import Tool
from langchain_experimental.utilities import PythonREPL
python_repl = PythonREPL()
repl_tool = Tool(
name="python_repl",
description="Executes python code and returns the result.",
func=python_repl.run,
)
repl_tool.name = "python_interpreter"
class ToolInput(BaseModel):
code: str = Field(description="Python code execution.")
repl_tool.args_schema = ToolInputAgora, combinaremos tudo para criar o agente de IA de várias etapas usando a função.create_cohere_react_agent(), o cliente de modelo Cohere, as ferramentas e o modelo de prompt. Para executar nosso agente de IA, usaremos a classe AgentExecutor fornecendo a ela o objeto e as ferramentas do agente.
from langchain.agents import AgentExecutor
from langchain_cohere.react_multi_hop.agent import create_cohere_react_agent
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("{input}")
agent = create_cohere_react_agent(
llm=chat,
tools=[internet_search, repl_tool],
prompt=prompt,
)
agent_executor = AgentExecutor(agent=agent, tools=[internet_search, repl_tool], verbose=True)Em seguida, basta usar o site agent_executor para gerar uma visualização. Em nosso caso, pedimos ao agente de IA para coletar os dados mais recentes da Internet e criar um gráfico de pizza.
response = agent_executor.invoke({
"input": "Create a pie chart of the top 5 most used programming languages in 2024.",
})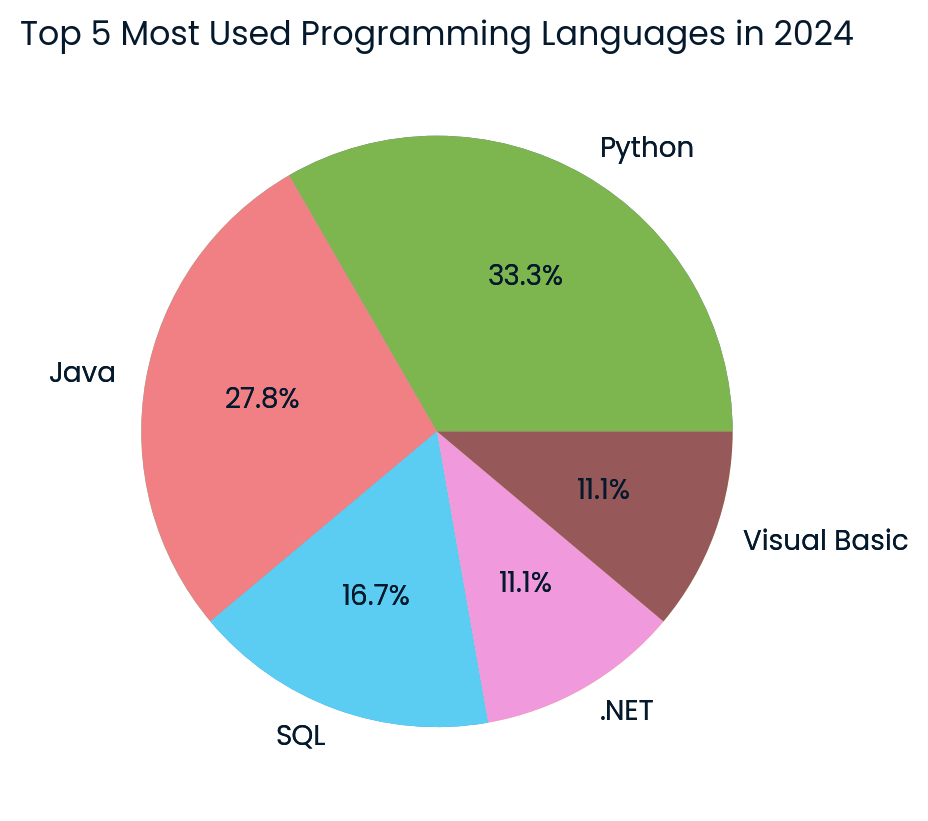
Gráfico de pizza das principais linguagens de programação criado pelo modelo Cohere. Imagem do autor
O resultado é incrível! Ele gerou com sucesso o gráfico de pizza usando os dados mais recentes da Internet.
Se você estiver enfrentando problemas para executar o código mencionado neste tutorial, verifique o espaço de trabalho do DataLab Tutorial do Cohere Command R+que contém a fonte do código, o conjunto de dados e os resultados.
Semelhante ao LangChain, você pode usar o LlamaIndex para criar um agente de IA de várias etapas. Para começar a usar o LlamaIndex, assista ao vídeo Geração Aumentada de Recuperação com o LlamaIndex em vídeo.
O mercado de IA está aquecendo novamente, e aprender novas ferramentas e APIs ajudará você a criar sistemas de IA melhores e a fortalecer seu portfólio. Além disso, ele simplificará seu fluxo de trabalho, pois algumas estruturas de IA lidam com a maioria das tarefas para você, exigindo apenas algumas linhas de código.
Neste tutorial, aprendemos sobre o modelo Cohere Command R+ e como acessá-lo usando o Hugging Face chat, o aplicativo Jan e a API. Também aprendemos sobre a API do Python e como ajustar o modelo para gerar respostas personalizadas. Para concluir, criamos um agente de IA adequado que recebe consultas do usuário, pesquisa na Internet os dados mais recentes e gera visualizações usando o Python REPL.
Para saber mais sobre o poder dos LLMs, bem como sobre como gerar conteúdo a partir de prompts, extrair informações de documentos e criar um mecanismo de pesquisa semântica, confira nossa sessão de vídeo de código-along sobre Usando modelos de linguagem grandes com a API Cohere.
Saiba mais sobre IA e LLMs com estes cursos!
Curso
Curso
Curso