programa
Desarrollar grandes modelos lingüísticos
16 h
Imagina un modelo de lenguaje de gran tamaño (LLM) en el que las respuestas que obtienes no sólo son relevantes, sino que están finamente seleccionadas, priorizadas y refinadas para ajustarse exactamente a tus necesidades. Aunque los LLM han revolucionado el ámbito de la IA, no están exentos de limitaciones. Cuestiones como las alucinaciones y la obsolescencia de los datos pueden poner en riesgo la exactitud y pertinencia de sus resultados. Aquí es donde entran en juego la generación mejorada por recuperación (RAG) y la reclasificación, que ofrecen una forma de mejorar los LLM integrándolos con procesos de recuperación de información dinámicos y actualizados. ¿Tienes curiosidad por conocer los pasos de esta receta? Sigue leyendo.
Los LLM han revolucionado el ámbito de la IA y han ampliado los límites de lo que podemos conseguir utilizando la IA. Se han convertido en la herramienta a la que recurre cualquiera que busque soluciones versátiles de PNL en prácticamente cualquier dominio, modelando una serie de tareas de comprensión y generación del lenguaje natural, como se muestra a continuación.
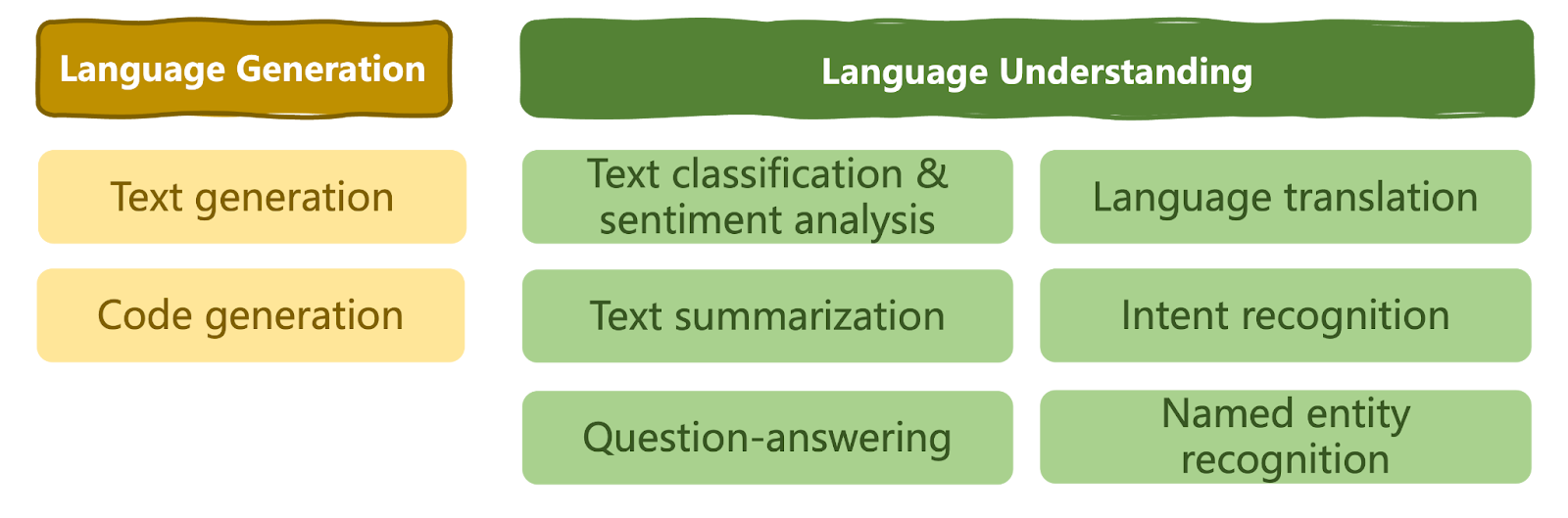
Una taxonomía de tareas lingüísticas resolubles por LLMs | Iván Palomares
A pesar de sus capacidades, los LLM también tienen limitaciones en determinados escenarios. Dependiendo del caso de uso específico y de los conocimientos que hayan aprendido del vasto conjunto de datos en el que se han entrenado, los LLM a veces no consiguen generar un texto coherente, relevante o contextualmente apropiado. A veces, en ausencia de datos relevantes veraces para crear una respuesta a las consultas de los usuarios, pueden incluso generar información incorrecta o sin sentido como si fuera cierta. Este fenómeno se conoce como alucinación.
Considera, por ejemplo, la pregunta: "¿Cuáles son los síntomas comunes de la gripe?"
Un LLM estándar podría generar una respuesta basada en conocimientos generales, enumerando síntomas comunes como fiebre, tos y dolores corporales.
Sin embargo, a menos que hubiera sido entrenado con datos sobre el virus de la gripe muy específicos del dominio, el LLM podría no tener en cuenta las variaciones en la gravedad de los síntomas ni distinguir entre cepas de gripe, proporcionando así respuestas más bien genéricas e incluso algo "automatizadas" a distintos usuarios, independientemente de sus circunstancias o necesidades.
Es más, si, por ejemplo, el modelo se hubiera entrenado con datos clínicos de gripe recogidos hasta diciembre de 2023, y en enero de 2024 aparece una nueva cepa de gripe que se propaga rápidamente entre la población, un LLM autónomo será incapaz de dar respuestas precisas debido a la falta de conocimientos actualizados sobre el dominio del problema.
Este problema de "obsolescencia de datos" se conoce como corte de conocimientos.
En algunos casos, la solución al problema anterior podría consistir en volver a entrenar y afinar frecuentemente el LLM con información nueva y actualizada. Pero, ¿es ésta necesariamente la mejor forma de actuar?
Se sabe que los modelo de lenguaje de gran tamaño LLM (Large Language Models) son difíciles de entrenar y computacionalmente caros. Requieren de millones a miles de millones de instancias de datos de texto y, a menudo, miles de textos específicos del dominio para su ajuste (véase el diagrama siguiente).
La mayoría de los LLM, incluso los de dominio específico, suelen estar ajustados para funcionar en dominios de amplio alcance, como la sanidad. Por tanto, introducir nuevos datos específicos para dar cabida a todos los posibles matices contextuales del dominio puede no ser la solución más eficaz.
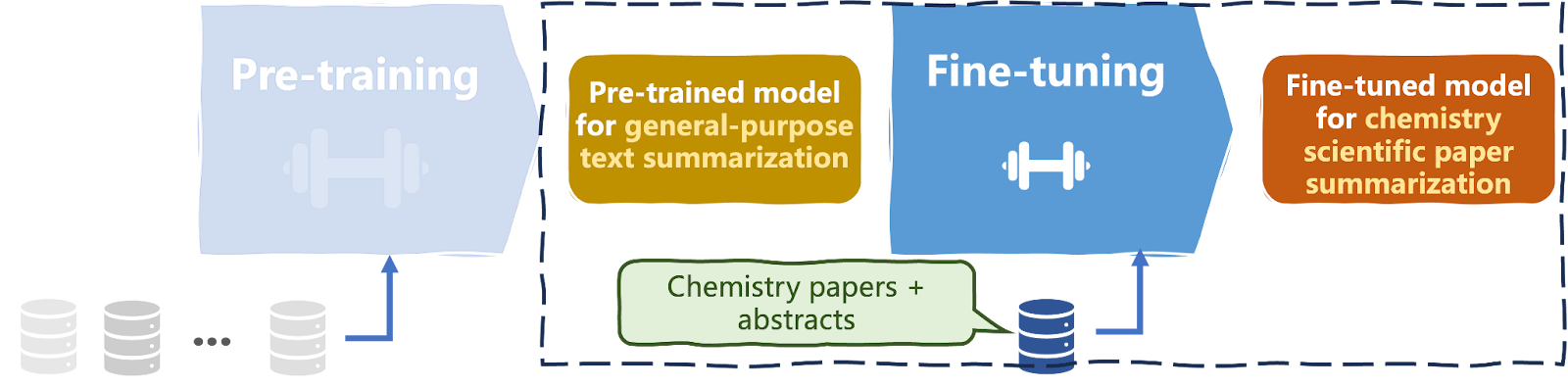
Entrenamiento y puesta a punto de un LLM | Iván Palomares
¡Aquí es donde la RAG (generación mejorada por recuperación) entra en acción!
La generación mejorada por recuperación o RAG es un proceso de recuperación de información mediante el cual se optimizan los resultados producidos por un LLM. Los LLM se basan en los conocimientos adquiridos a partir de los datos sobre los que se han generado para generar respuestas.
Mientras tanto, la generación mejorada por recuperación apunta a una base de conocimientos externa.
Combinando ambas soluciones, la RAG puede utilizarse para mejorar la calidad, la relevancia para el usuario, la coherencia y la veracidad de la salida "en bruto" generada por el LLM, recuperando conocimientos de la base de conocimientos mencionada anteriormente.
Como resultado, desaparece en gran medida la necesidad de reentrenar continuamente el LLM para adaptarlo a los nuevos contextos y situaciones que van surgiendo.
A continuación se describe de forma simplificada el flujo de trabajo general de un sistema de generación mejorada por recuperación:
Volviendo al ejemplo de la gripe, podemos ver que con la generación mejorada por recuperación, el modelo podría recuperar información actualizada y relevante de bases de datos médicas o artículos recientes, lo que le permitiría generar una respuesta más matizada y precisa a la consulta del paciente o médico.
Podría incorporar información sobre las cepas de gripe actuales, las variaciones regionales de los síntomas o los patrones emergentes, proporcionando así una respuesta más pertinente y coherente a la consulta del usuario.
El reordenamiento es un proceso de recuperación de información en el que un conjunto inicial de resultados recuperados se reordena para mejorar su relevancia respecto a la consulta del usuario, sus necesidades y su contexto, mejorando así la calidad general del resultado. Así es como funciona:
El diagrama siguiente ilustra el proceso de reordenación:
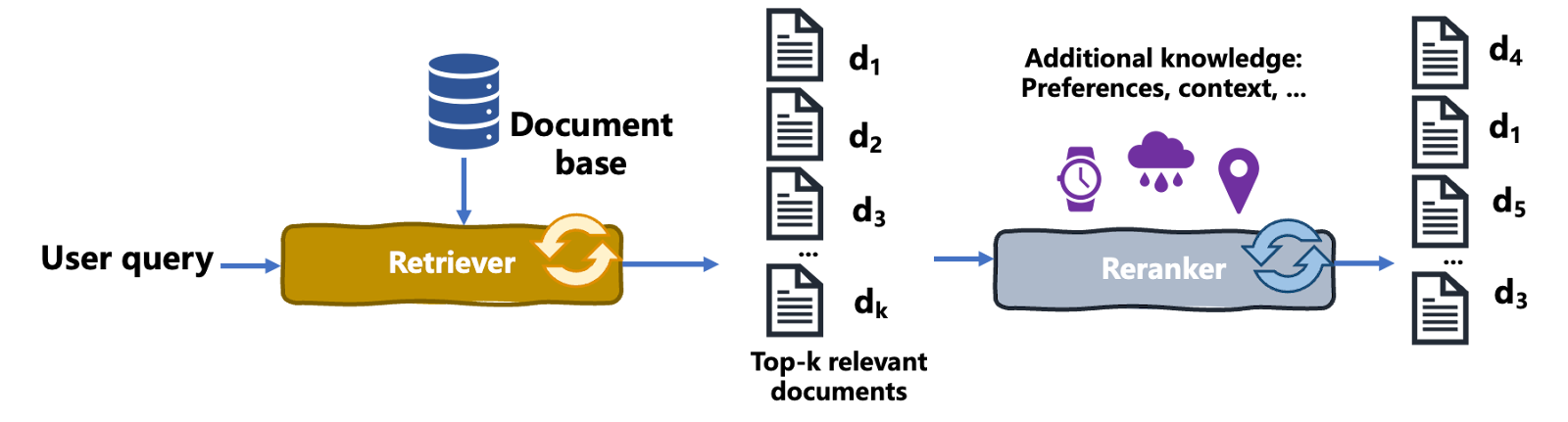
Proceso de reclasificación | Iván Palomares
Aclaremos aquí un punto importante: la reclasificación reordena los documentos recuperados en función de varios criterios, como las preferencias del usuario. Sin embargo, la reclasificación es diferente de los motores de recomendación, como los que sugieren productos relevantes para comprar en los sitios de comercio electrónico.
La reclasificación se utiliza en casos de búsqueda en los que un usuario introduce una consulta en tiempo real.
En cambio, los motores de recomendación crean proactivamente sugerencias personalizadas para los usuarios basadas en sus interacciones y preferencias a lo largo del tiempo.
Volvamos al ejemplo de la gripe.
Considera una situación en la que un profesional sanitario busca "los mejores tratamientos para los síntomas de la gripe". Un sistema de recuperación inicial podría devolver una lista de documentos, incluyendo información general sobre la gripe, pautas de tratamiento y artículos de investigación.
Pero un modelo de reordenación, posiblemente utilizando datos adicionales específicos del paciente e información contextual, puede entonces reordenar estos documentos para dar prioridad a los protocolos de tratamiento más relevantes y recientes, consejos para el cuidado del paciente y estudios de investigación revisados por expertos que aborden directamente los síntomas de la gripe y su tratamiento, dando así prioridad a los resultados que van "directos al grano".
En resumen, la reclasificación reorganiza una lista de documentos recuperados basándose en criterios de relevancia adicionales para mostrar primero los más relevantes para el usuario concreto.
La reordenación es especialmente útil en los modelo de lenguaje de gran tamaño (LLM) equipados con la generación mejorada por recuperación (RAG). RAG combina los LLM con la recuperación externa de documentos para ofrecer respuestas más informadas y precisas.
Tras la recuperación inicial de documentos basada en una consulta, un proceso de reordenación puede refinar la selección, garantizando que el LLM trabaje con la información más relevante y de mayor calidad.
Este proceso aumenta el rendimiento general del LLM, mejorando la precisión y relevancia de las respuestas, sobre todo en ámbitos especializados en los que la información precisa es fundamental.
No existe una receta única para implantar un agente de reclasificación. Se han establecido varios enfoques, algunos de los cuales son:
Ahora que comprendemos las ventajas de incorporar la generación mejorada por recuperación a los LLM, así como los mecanismos de reordenación para la recuperación de conocimientos, ha llegado el momento de integrar estos elementos y verlos en acción.
Este ejemplo utiliza la biblioteca Langchain (versión de la comunidad) para construir una sencilla canalización de generación mejorada por recuperación (RAG) con reclasificación. Descubre mucho más sobre el desarrollo de aplicaciones LLM con Langchain en el curso Cómo desarrollar aplicaciones LLM y en este tutorial sobre cómo crear aplicaciones LLM con Langchain.
El código se ha implementado en un cuaderno Google Colab.
pip install -U langchain-communityEn primer lugar, instalamos langchain-community en nuestro portátil.
A continuación, importa los paquetes, clases y funciones necesarios.
import os
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from sklearn.metrics.pairwise import cosine_similarity
import numpy as npLa siguiente función está definida para cargar una lista de documentos (archivos .txt) de un directorio local del que tu cuaderno de código debería poder leer. Éstos serán los documentos que se recuperarán y se volverán a clasificar para mejorar los resultados del LLM:
# Function to load documents from a directory
def load_documents_from_directory(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith(".txt"):
with open(os.path.join(directory_path, filename), 'r') as file:
documents.append(file.read())
return documents
# Load documents from the specified directory
directory_path = "./sample_data"
documents = load_documents_from_directory(directory_path)
Para optimizar el rendimiento de las representaciones de incrustación de los documentos de texto, limitamos su tamaño a 1000 y dividimos los documentos con extensiones más largas en trozos más pequeños. La clase CharacterTextSplitter ayuda a realizar el trabajo.
El argumento chunk_overlap se fija en 0 para evitar que se superpongan porciones de texto entre trozos.
# Split documents into chunks for better embedding performance
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
Utilizaremos las incrustaciones de OpenAI para construir nuestro almacén de vectores de incrustación. Ten en cuenta que, dependiendo del entorno en el que estés ejecutando tu código, es posible que tengas que obtener una clave de validación de OpenAI definida en OPENAI_API_KEY.
# Initialize OpenAI embeddings
embeddings = OpenAIEmbeddings()
# Build FAISS vector store upong document chunk embeddings
vector_store = FAISS.from_documents(docs, embeddings)
# Load and initialize OpenAI LLM
llm = OpenAI(model="text-davinci-003", temperature=0.7)FAISS crea un almacén vectorial a partir de incrustaciones. Necesitamos pasar dos argumentos a su función from_documents(). El documento se divide, y las incrustaciones inicializadas se instancian con ayuda de OpenAIEmbeddings.
Después, traemos a escena a uno de los actores principales: ¡el LLM! Utilizamos OpenAI para cargar el modelo text-davinci-003, estableciendo una temperatura de modelo moderadamente alta 0,7 para permitir cierto grado de originalidad en la generación de texto.
Demos unos pasos más:
# Define the prompt template for the LLM
prompt_template = PromptTemplate(template="Answer the question based on the context: {context}\n\nQuestion: {question}\nAnswer:")
# Define the RAG chain with reranking using a QA chain
qa_chain = load_qa_with_sources_chain(llm, prompt_template=prompt_template, retriever=vector_store.as_retriever())
# Example question
question = "What are the common symptoms of the flu and how can it be treated?"
# Generate an answer using the QA chain
response = qa_chain(question=question)
print(response)El código anterior define primero una plantilla de pregunta-respuesta. A continuación, llama a la función load_qa_with_sources_chain() para crear una canalización de preguntas y respuestas (o cadena, en la jerga de Langchain). Su argumento recuperador permite incorporar un componente de recuperación en la canalización LLM, permitiendo así la RAG.
Finalmente se formula una pregunta, y ejecutamos la tubería definida qa_chain. ¡Voilà!
Aquí tienes el resultado (depende de los documentos de los que vayas a leer):
"Los síntomas comunes de la gripe incluyen fiebre, tos, dolor de garganta, secreción o congestión nasal, dolores corporales, dolor de cabeza, escalofríos y fatiga. Algunas personas pueden experimentar vómitos y diarrea, sobre todo los niños. La gripe puede tratarse con medicamentos antivirales, que pueden hacer que la enfermedad sea más leve y acortar su duración. Los medicamentos antivirales también pueden prevenir complicaciones graves, como la neumonía. Se recomienda un tratamiento rápido a las personas muy enfermas o con alto riesgo de complicaciones."
El ejemplo anterior era bonito, salvo que no incorporaba la fase de reclasificación. Modificar el código para incorporar la reclasificación es relativamente sencillo.
La lista de importaciones es la misma, pues ya hicimos en la versión anterior todas las importaciones necesarias para la fase de reclasificación, aunque algunas de ellas aún no las habíamos utilizado:
# Previous code here
#...
# Define the prompt template for the LLM
prompt_template = PromptTemplate(template="Answer the question based on the context: {context}\n\nQuestion: {question}\nAnswer:")
# Reranking function
def rerank_documents(question, retrieved_docs, top_n=5):
question_embedding = embeddings.embed_text(question)
doc_embeddings = [doc.embedding for doc in retrieved_docs]
similarities = cosine_similarity([question_embedding], doc_embeddings)[0]
ranked_indices = np.argsort(similarities)[::-1] # Sort by descending similarity
ranked_docs = [retrieved_docs[i] for i in ranked_indices[:top_n]]
return ranked_docsComo vemos, lo que hacemos primero es definir una función rerank_documents que utiliza la similitud del coseno en las incrustaciones para calcular la similitud entre la incrustación de la pregunta y las incrustaciones del documento, devolviendo los n documentos mejor clasificados.
# Custom QA chain with reranking
class CustomQAWithReranking:
def __init__(self, llm, retriever, prompt_template, top_n=5):
self.llm = llm
self.retriever = retriever
self.prompt_template = prompt_template
self.top_n = top_n
def __call__(self, question):
retrieved_docs = self.retriever.retrieve_documents(question)
ranked_docs = rerank_documents(question, retrieved_docs, self.top_n)
context = "\n".join([doc.page_content for doc in ranked_docs])
prompt = self.prompt_template.format(context=context, question=question)
return self.llm(prompt)La clase CustomQAWithReranking integra en el LLM los pasos de recuperación y reclasificación del proceso LLM, que se invocarán llamando a la función call () de esta clase.
# Define the custom QA chain with reranking
qa_chain = CustomQAWithReranking(llm, vector_store.as_retriever(), prompt_template)
# Example question
question = "What are the benefits of using multi-vector rerankers?"
# Generate an answer using the custom QA chain
response = qa_chain(question)Solo queda instanciar again qa_chain. Observa que esta vez lo haremos definiendo un objeto de la clase que acabamos de crear, que encapsula la mayor parte de la lógica de nuestra versión anterior más nuestro mecanismo personalizado de reclasificación.
Por último, formulamos la pregunta e invocamos la cadena para obtener una respuesta.
En el ámbito de los LLM y de la IA en su conjunto, podría decirse que la RAG ha llegado para quedarse. Hacer que un LLM acceda y recupere conocimientos de fuentes externas como parte del proceso para generar respuestas, se ha convertido en una alternativa ampliamente aceptada al constante reciclaje y puesta a punto de los LLM.
En este artículo se analiza la reclasificación como un enfoque útil para incorporar una recuperación eficaz de la información como parte de un proceso LLM. Destacó cómo funciona el proceso de reclasificación, los distintos tipos de agentes de reclasificación, y un ejemplo práctico utilizando Langchain y la API OpenAI.
¿Quieres saber más? Echa un vistazo a estos recursos adicionales:
Más información sobre LLM
programa
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita

