
Curso
Conceptos de Databricks
4 h
22K
Databricks SQL es una potente herramienta diseñada para la gestión y el análisis de datos dentro de la plataforma Databricks Lakehouse. Esta plataforma integra la ingeniería de datos, la ciencia de datos y la analítica empresarial en una experiencia unificada. Por lo tanto, Databricks SQL es importante para los profesionales de datos que buscan agilizar sus flujos de trabajo de datos, la ejecución de consultas y las tareas de BI sin la complejidad de la gestión tradicional de infraestructuras.
En este artículo, exploraré los componentes, características y herramientas de Databricks SQL y mostraré ejemplos prácticos de creación y uso del almacén Databricks SQL. Para empezar, recomiendo encarecidamente seguir el curso Introducción a Databricks de DataCamp para conocer Databricks como solución de almacenamiento de datos para Business Intelligence (BI), que aprovecha las capacidades optimizadas de SQL para crear consultas y analizar datos.
Databricks SQL es una robusta herramienta de análisis dentro de la plataforma Databricks Lakehouse que permite a los profesionales de datos ejecutar consultas SQL, analizar datos y crear cuadros de mando interactivos. Diseñado con una arquitectura sin servidor, Databricks SQL combina la flexibilidad de los lagos de datos con las capacidades de gobernanza y rendimiento de los almacenes de datos.
Los componentes clave de Databricks SQL son los Almacenes SQL, los Editores SQL y los Cuadros de Mando SQL. No te preocupes si no estás familiarizado con cada una de ellas, porque a continuación profundizaré en su significado.
Los componentes principales de Databricks SQL facilitan la consulta eficaz, la visualización de datos y la colaboración entre usuarios. A continuación encontrarás un resumen de las principales herramientas y funciones disponibles en Databricks SQL.
Los Almacenes SQL sirven como recursos computacionales para ejecutar consultas SQL en Databricks SQL. Están diseñados para manejar cargas de trabajo variables y proporcionan optimizaciones de rendimiento basadas en el tipo de almacén seleccionado. Hay tres tipos principales de Almacenes SQL:
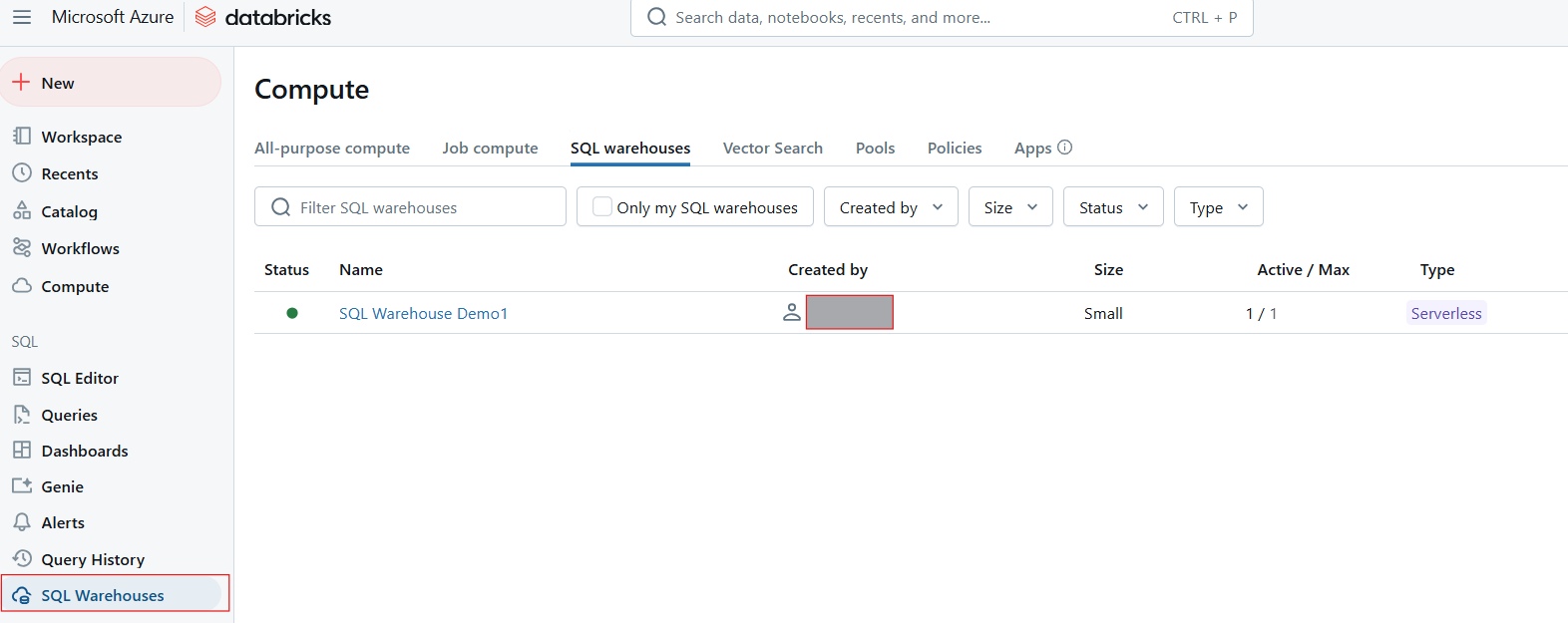
Almacén SQL en Databricks SQL. Imagen del autor.
El Editor SQL es una interfaz fácil de usar que permite a los usuarios escribir, ejecutar y gestionar consultas SQL. Las principales características del Editor SQL son
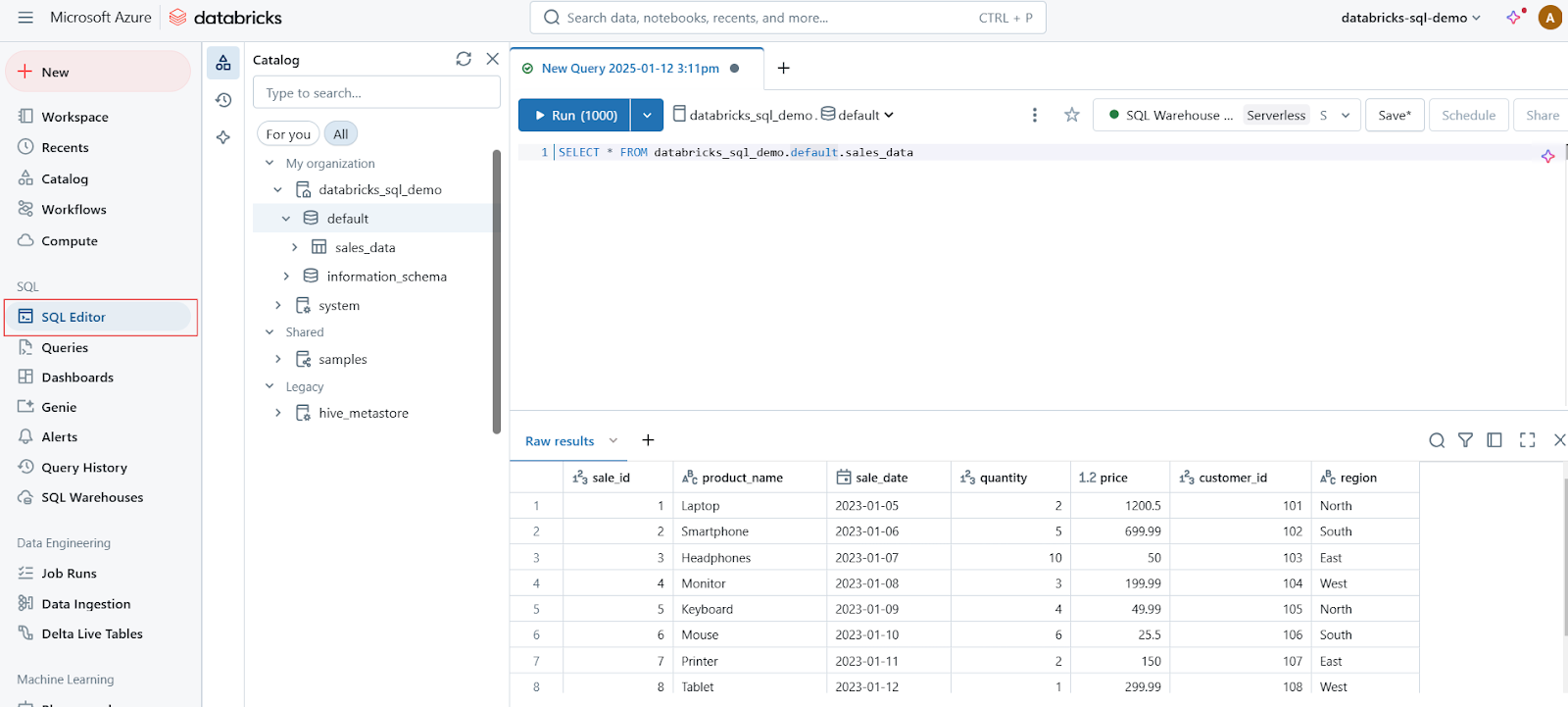
Editor SQL en Databricks SQL. Imagen del autor.
Los cuadros de mando permiten visualizar los datos transformando los resultados de las consultas en tablas, gráficos y widgets interactivos. Los cuadros de mando son ideales para supervisar las métricas clave y comunicar la información de forma eficaz a toda la organización. Las capacidades clave de los cuadros de mando son las siguientes:
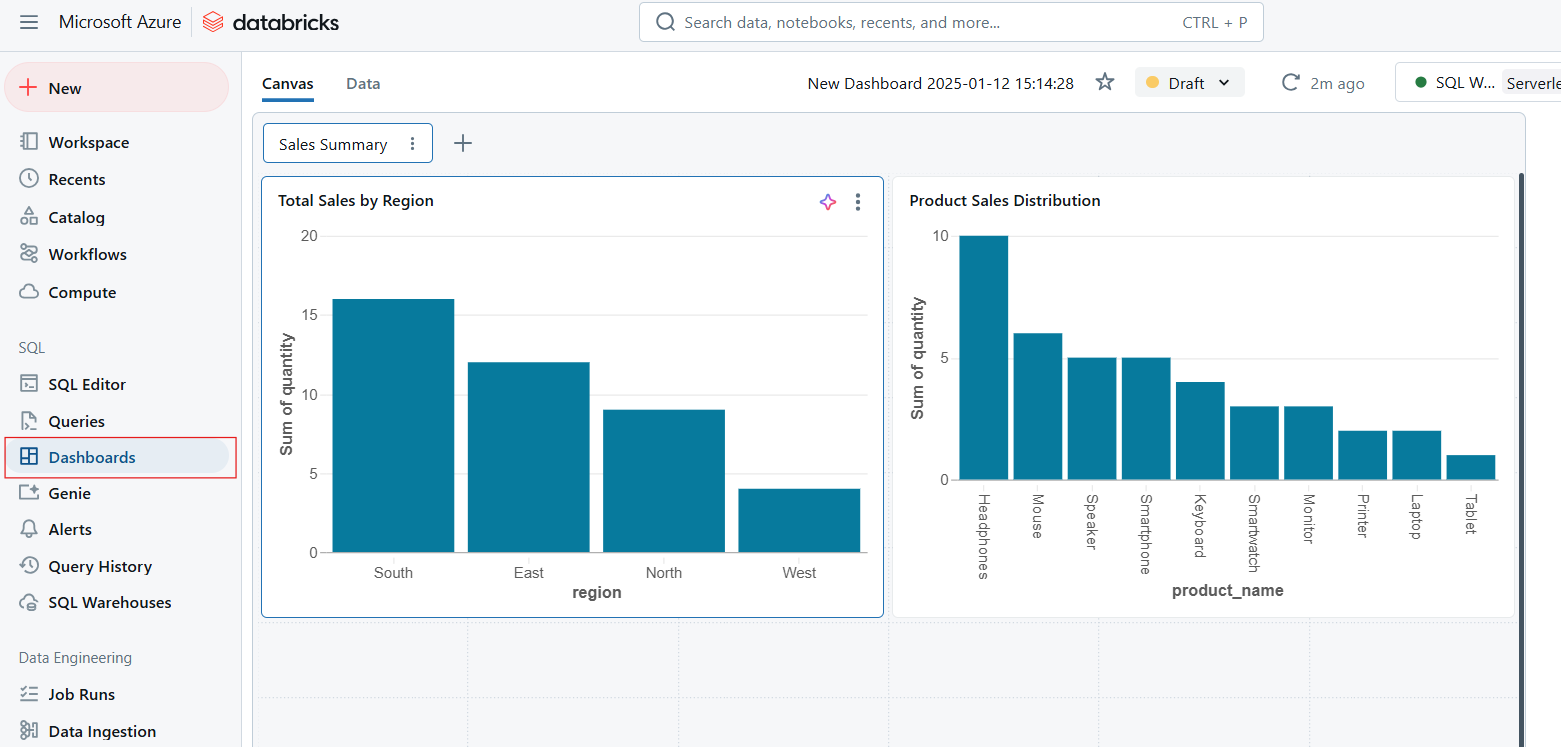
Cuadros de mando en Databricks SQL. Imagen del autor.
Las alertas en Databricks SQL proporcionan una forma de supervisar los cambios en los datos y activar notificaciones cuando se cumplen las condiciones especificadas. Las alertas son esenciales para mantener la calidad de los datos y garantizar respuestas oportunas a cambios importantes. La función de alerta funciona de la siguiente manera
Por último, quiero decir que Databricks SQL ofrece herramientas para el seguimiento del historial de consultas y la elaboración de perfiles:
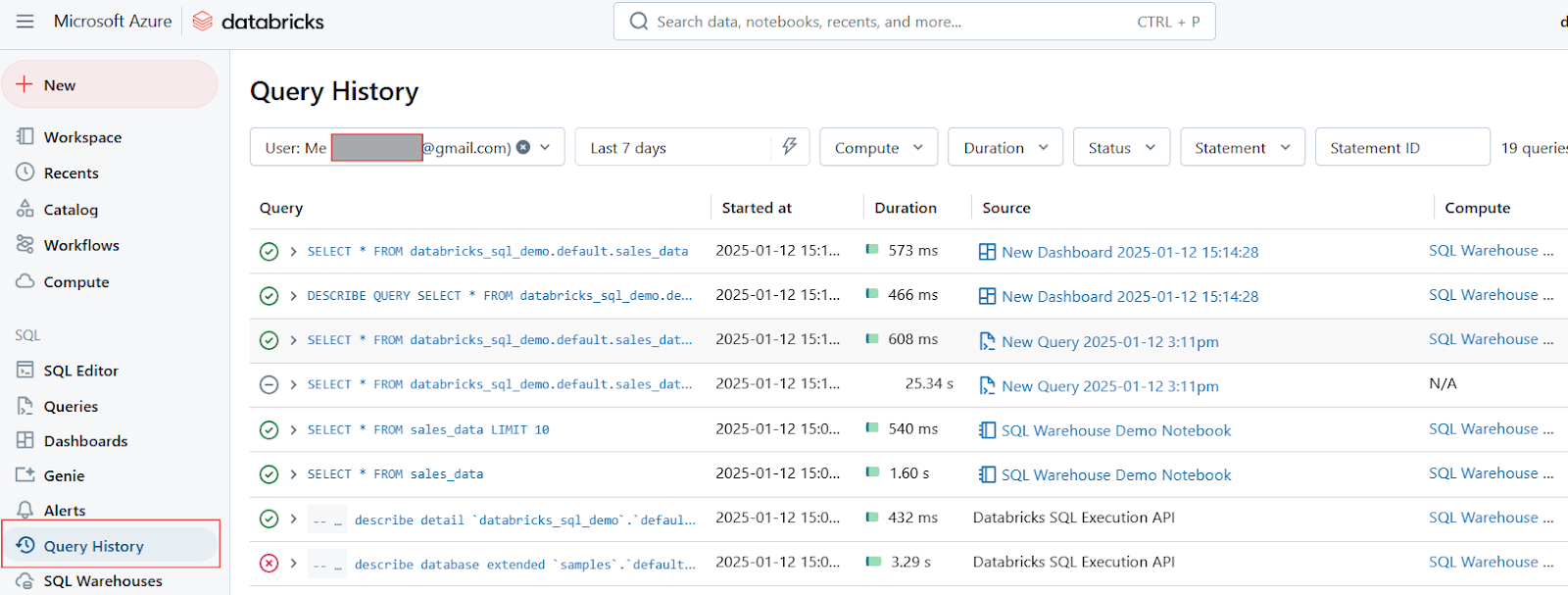
Historial de consultas en Databricks SQL. Imagen del autor.
Databricks SQL está repleto de funciones y herramientas avanzadas. Estas funciones están diseñadas para mejorar el rendimiento, agilizar los flujos de trabajo y permitir una integración perfecta con otras herramientas. Veamos algunos de los aspectos clave que hacen que Databricks SQL sea una gran elección.
El motor Photon es un motor de consulta vectorizado de alto rendimiento desarrollado por Databricks para acelerar significativamente la ejecución de consultas SQL. Las principales ventajas del Motor Fotón son las siguientes:
CloudFetch y Async I/O son funciones diseñadas para aumentar la velocidad de transferencia de datos y mejorar la gestión de archivos pequeños durante la ejecución de consultas. Estas funciones funcionan de las siguientes maneras:
Databricks SQL se integra perfectamente con las herramientas de Business Intelligence (BI) más populares, facilitando a los equipos el análisis y la visualización de los datos. Las integraciones admitidas son las siguientes:
La arquitectura sin servidor de Databricks SQL elimina la necesidad de gestionar manualmente la infraestructura, al aprovisionar y escalar automáticamente los recursos en función de las demandas de la carga de trabajo. La arquitectura sin servidor ajustará automáticamente los recursos para gestionar cargas de consulta variables sin tiempo de inactividad. Esta función evita que los usuarios tengan que configurar o mantener los clusters manualmente. La arquitectura sin servidor también es rentable, ya que los usuarios sólo pagan por los recursos utilizados durante la ejecución de la consulta.
Por ejemplo, una empresa de venta al por menor experimenta grandes cargas de consultas durante las horas punta. La arquitectura sin servidor aumenta automáticamente los recursos para garantizar un rendimiento constante y los reduce durante las horas de menor actividad para ahorrar costes.
Los Almacenes SQL de Databricks son esenciales para ejecutar consultas SQL con eficacia dentro del entorno Databricks. Ahora, en esta sección, te guiaré a través del proceso de creación de almacenes SQL y su uso con cuadernos. Si necesitas refrescar tus conocimientos sobre almacenes de datos, te recomiendo que sigas nuestro curso Conceptos de Almacenamiento de Datos para aprender los fundamentos del modelado de datos y la transformación de datos.
Sigue estos pasos para crear un Almacén SQL utilizando la interfaz web de Databricks:
En el espacio de trabajo Databricks, haz clic en el icono SQL de la barra lateral.
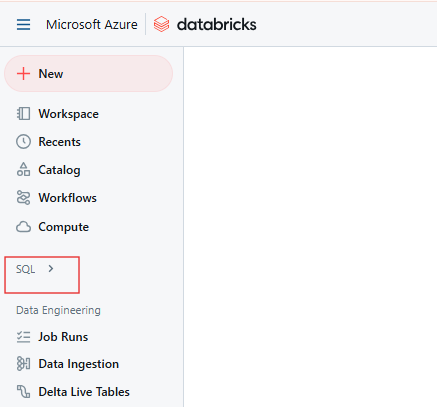
Página SQL de Databricks. Imagen del autor.
En la página SQL, ve a la pestaña Almacenes SQL.
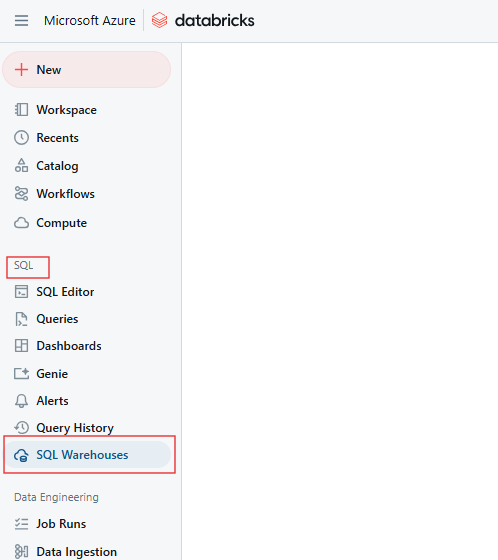
Pestaña Almacén SQL de Databricks. Imagen del autor.
Pulsa el botón Crear Almacén para empezar a configurar tu nuevo Almacén SQL.
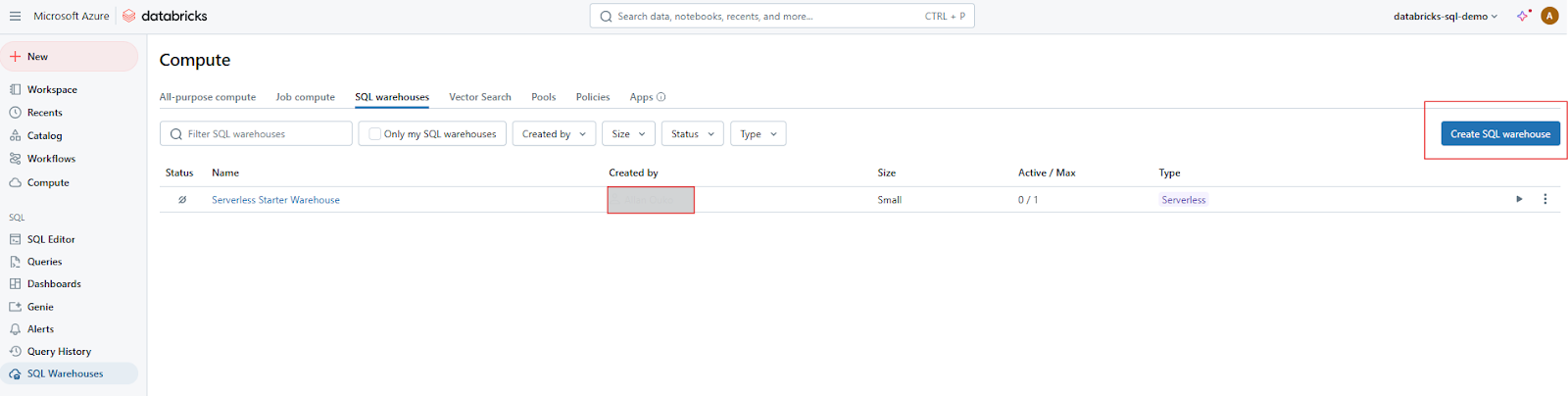
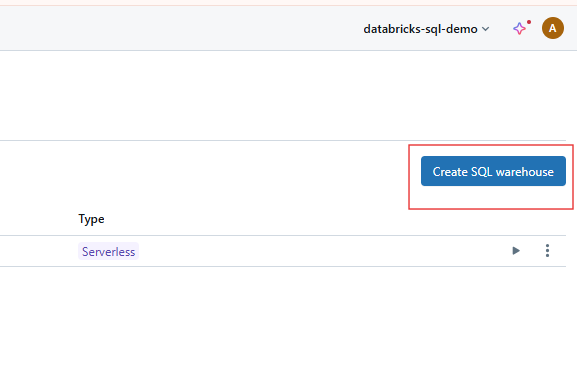
Creación de Almacenes SQL en Databricks SQL. Imagen del autor.
Configura los ajustes del almacén utilizando las siguientes opciones.
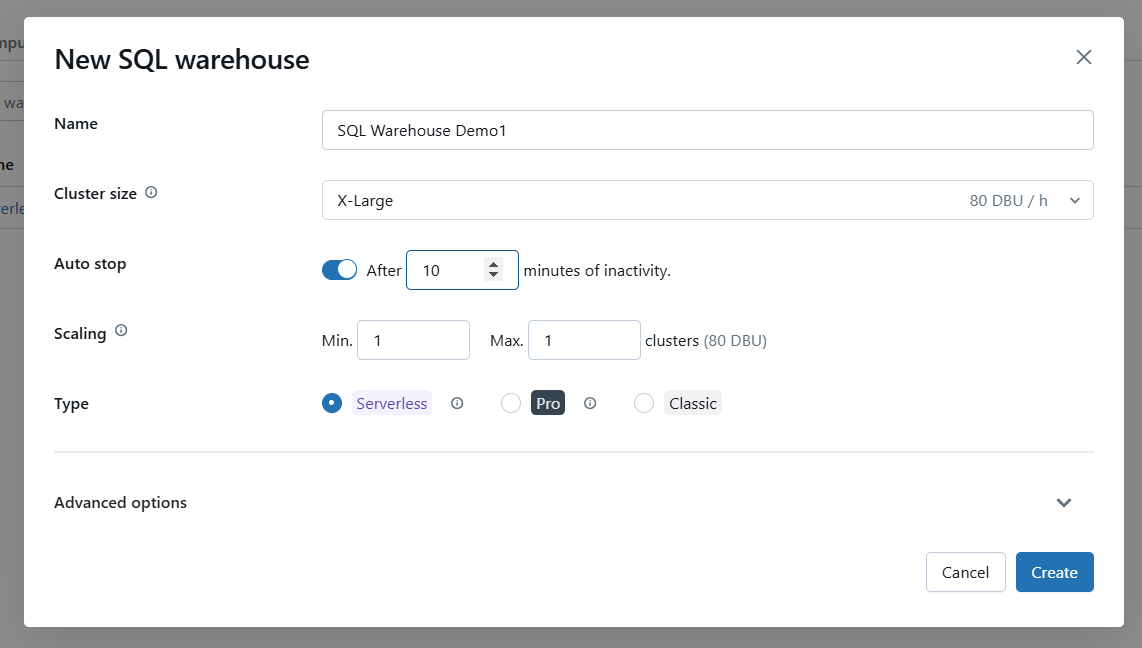
Configura las opciones básicas del Almacén SQL de Databricks. Imagen del autor.
Si es necesario, configura opciones avanzadas como activar Photon o establecer configuraciones SQL específicas.
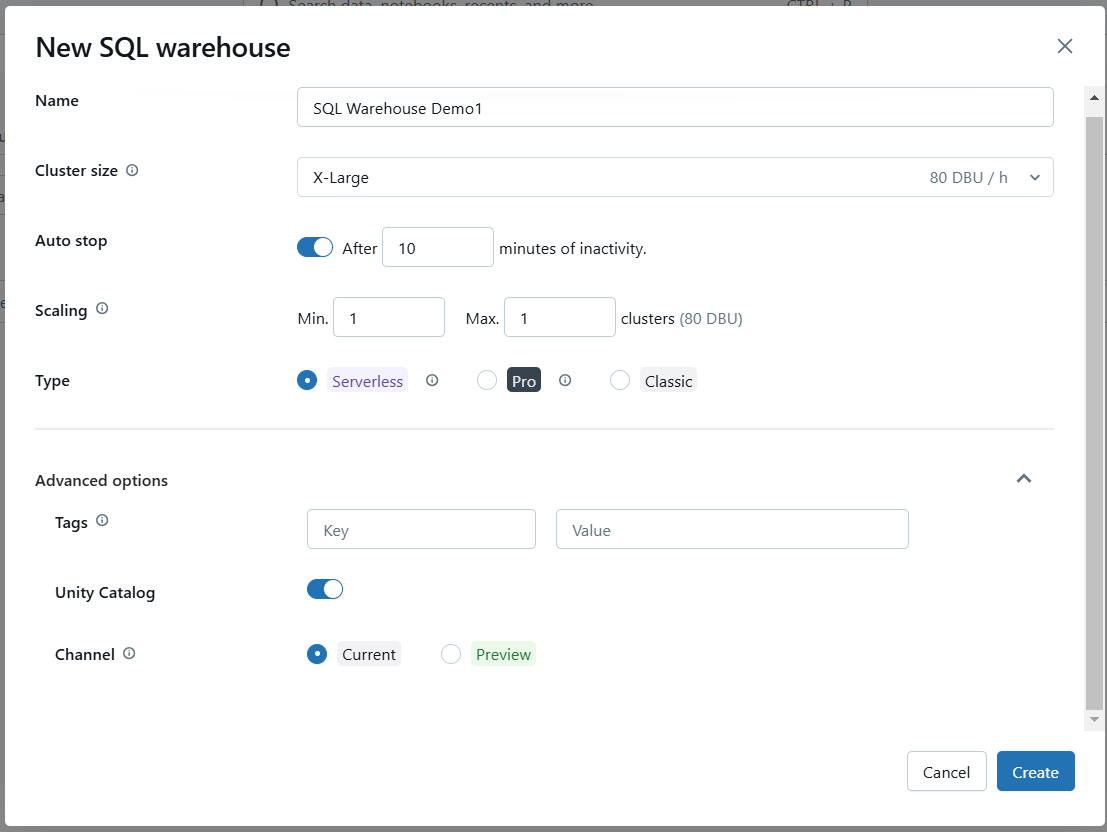
Configura las opciones avanzadas del Almacén SQL de Databricks. Imagen del autor.
Haz clic en Crear para guardar tu configuración. Una vez creado, pon en marcha el almacén para hacerlo operativo.
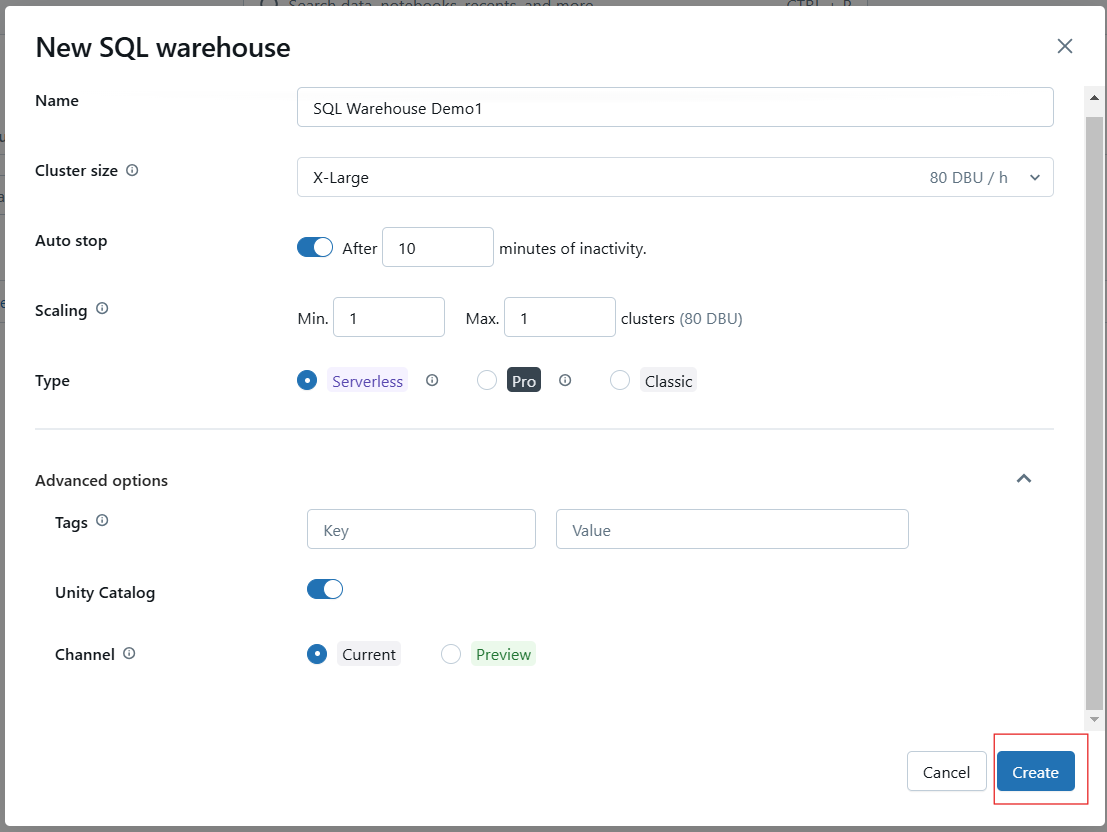
Creación del Almacén SQL de Databricks. Imagen del autor.
Tras la creación, aparecerá un modal de permisos donde podrás conceder a los usuarios o grupos acceso al almacén.
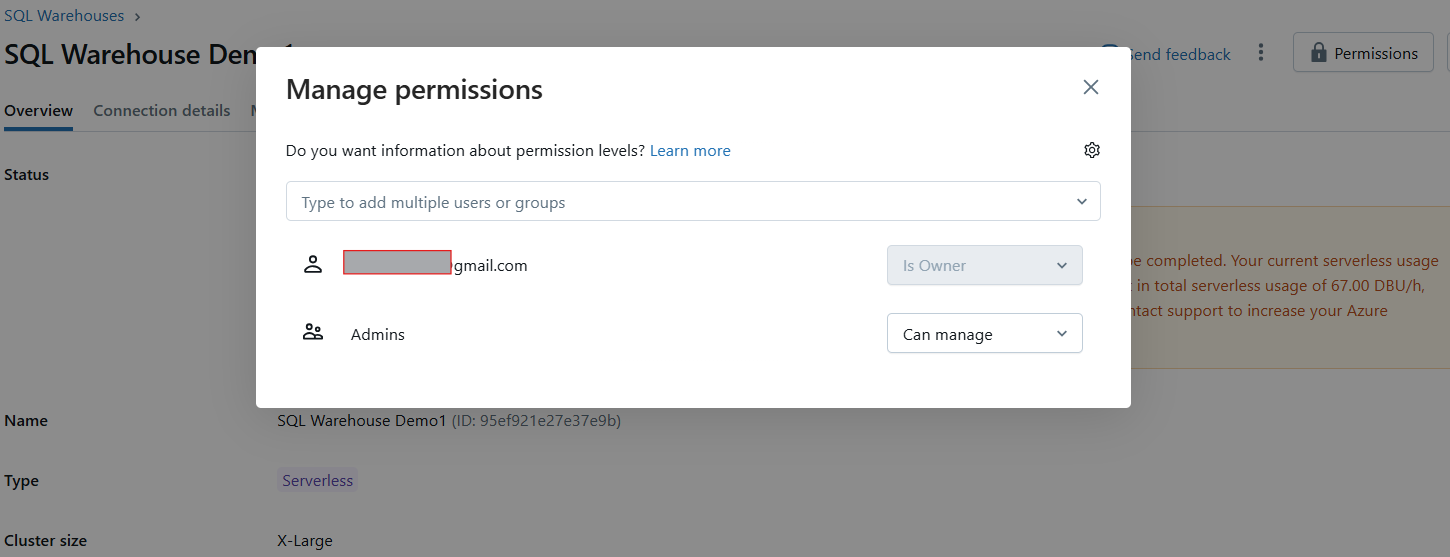
Gestionar los permisos del Almacén SQL de Databricks. Imagen del autor.
Una vez creado, tu almacén SQL se iniciará automáticamente, permitiéndote ejecutar consultas inmediatamente.
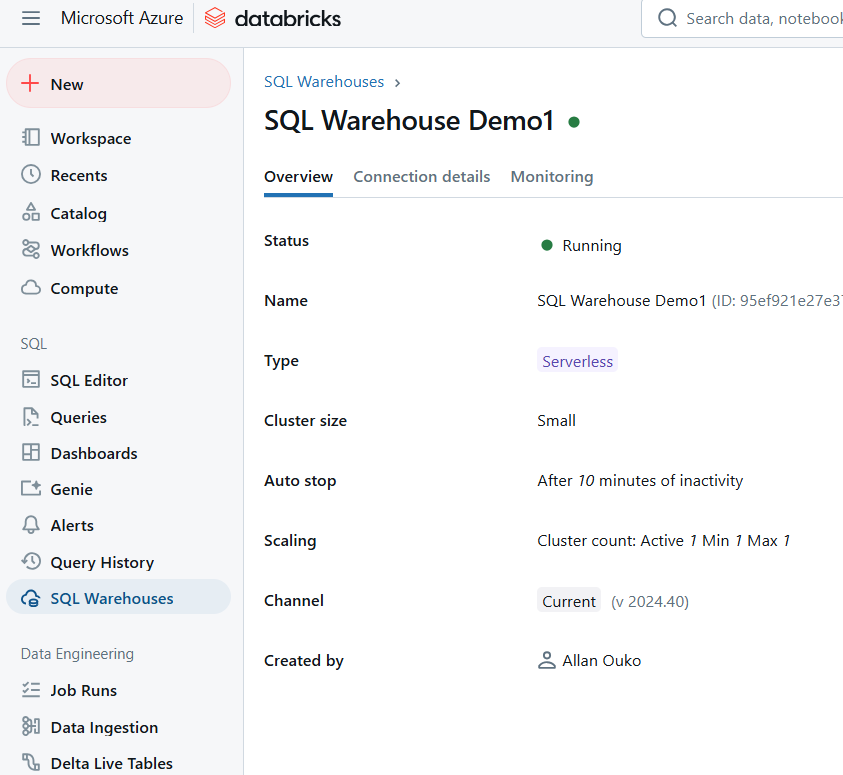
Ejemplo de Almacén SQL Databricks. Imagen del autor.
Para ejecutar consultas SQL en un bloc de notas utilizando tu almacén SQL recién creado, sigue estos pasos:
En el espacio de trabajo de Databricks, crea una libreta nueva o abre una existente.
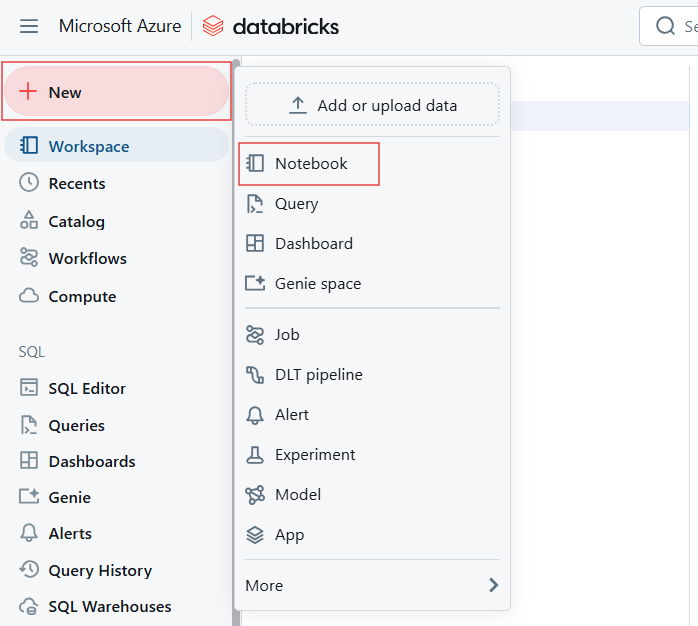
Crear un nuevo Cuaderno para crear Databricks SQL Warehouse. Imagen del autor.
En la barra de herramientas de Libreta, localiza el selector de cálculo o conexión (normalmente aparece en la parte superior). Haz clic en él para abrir un menú desplegable que muestra los recursos informáticos disponibles. Selecciona tu almacén SQL de la lista. Si no está visible, haz clic en Más... para ver todos los almacenes disponibles. Haz clic en el almacén SQL deseado y, a continuación, selecciona Iniciar y adjuntar.
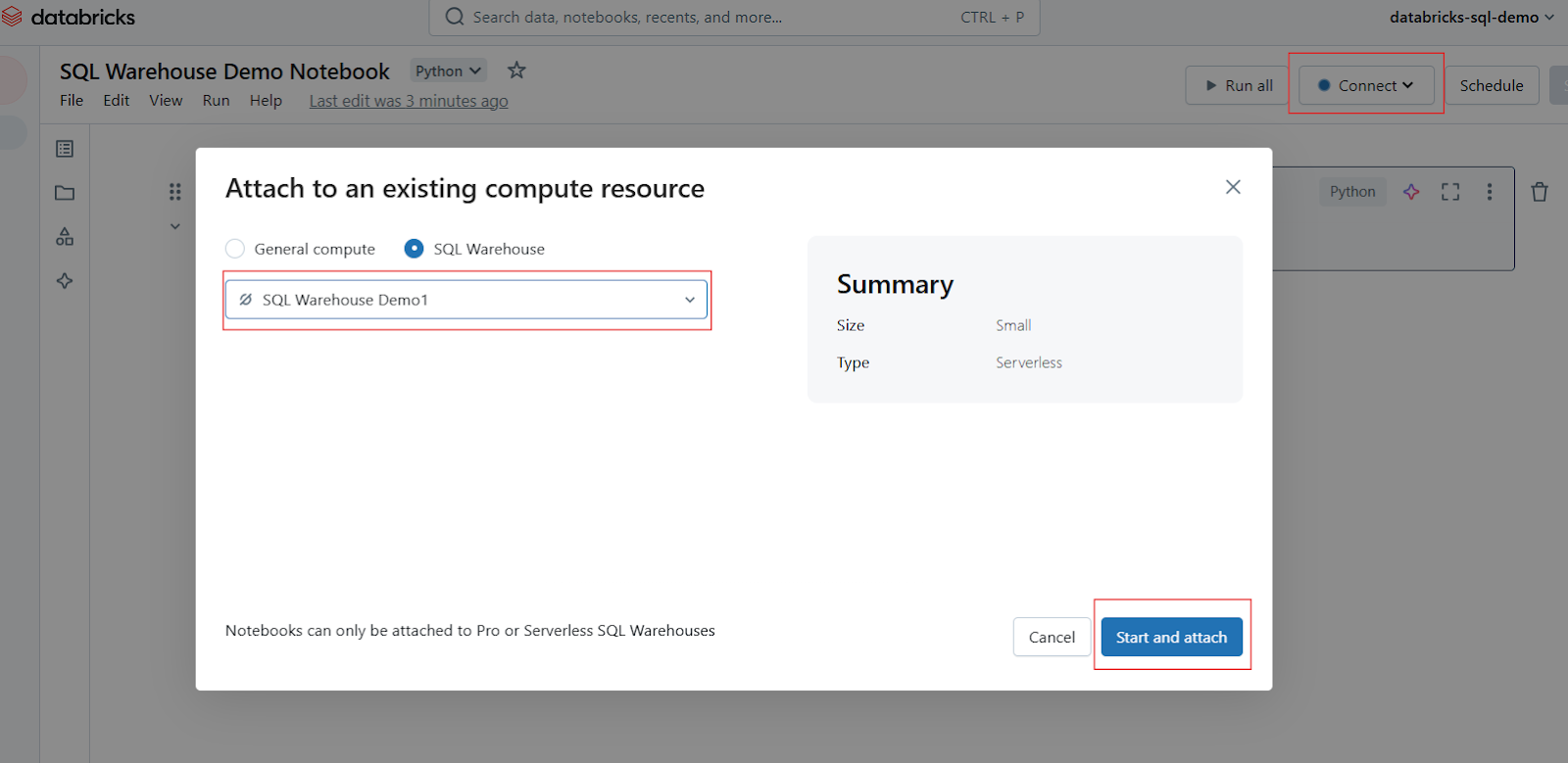
Adjuntar Cuaderno en el Almacén SQL de Databricks. Imagen del autor.
Una vez conectado, puedes crear celdas en tu bloc de notas para consultas SQL. Utiliza el comando %sql magic para ejecutar consultas SQL en el bloc de notas.
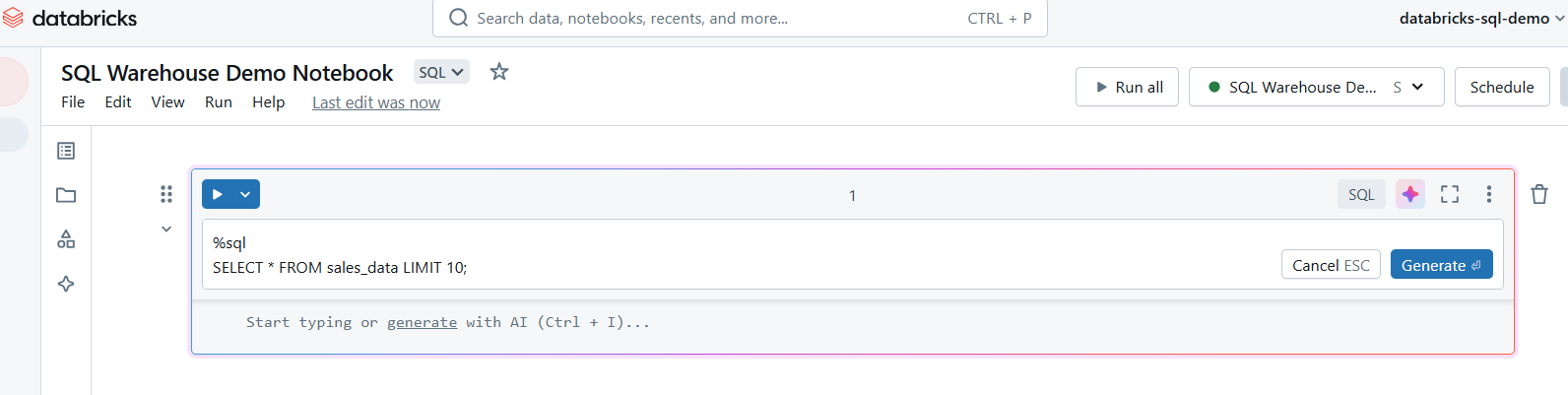
Escribe consultas SQL en el Almacén SQL de Databricks. Imagen del autor.
Ejecuta la celda para ejecutar tu consulta. Los resultados se mostrarán directamente debajo de la celda, facilitando la previsualización de los datos.
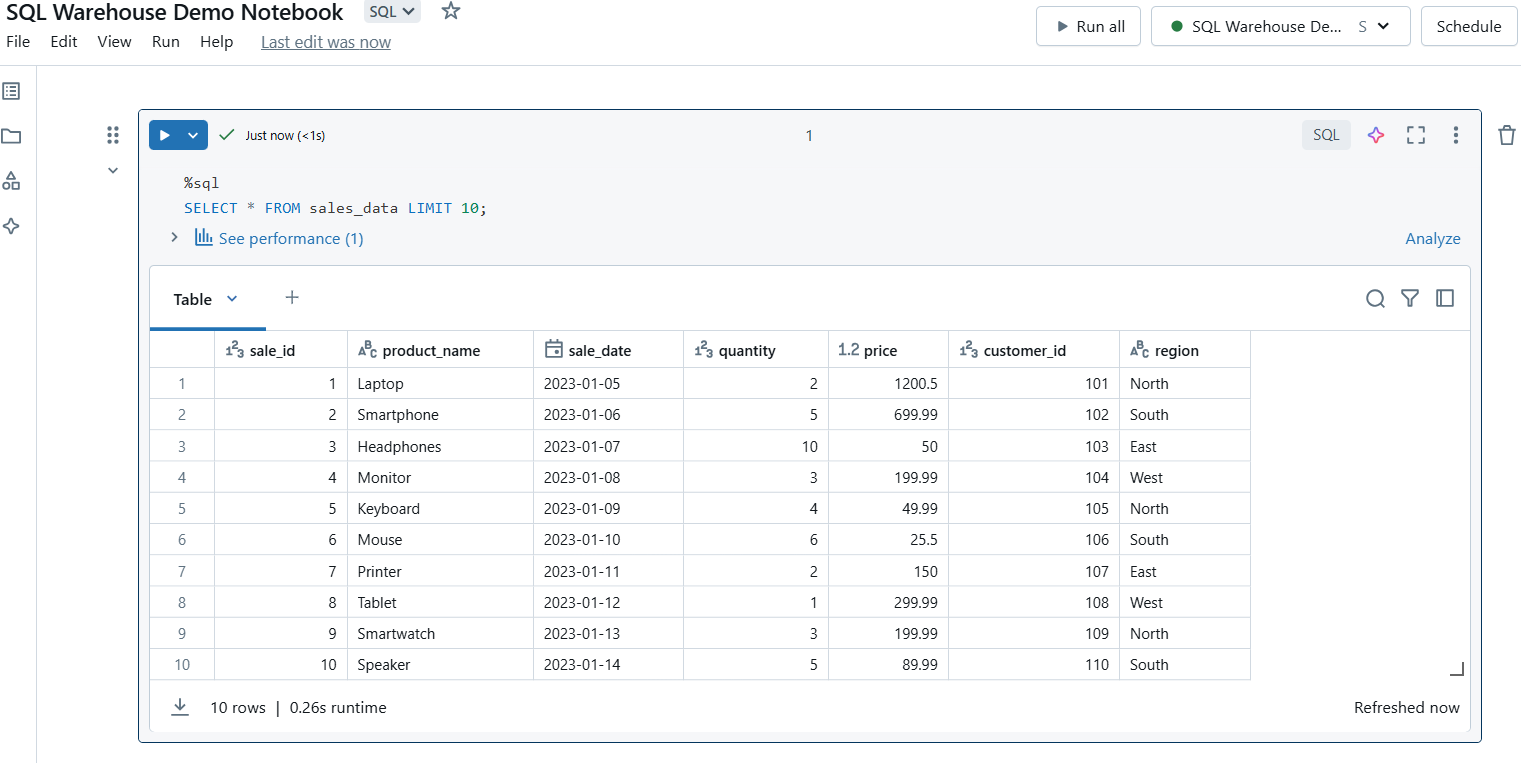
Ejecuta consultas SQL en el Almacén SQL de Databricks. Imagen del autor.
A continuación se exponen algunas consideraciones a tener en cuenta al utilizar cuadernos con Almacenes SQL:
Límites de consulta: Los Almacenes SQL están optimizados para consultas analíticas, no para consultas transaccionales frecuentes y de baja latencia.
Vista previa de los datos: Para conjuntos de datos grandes, considera la posibilidad de limitar los resultados de tu consulta, por ejemplo utilizando la cláusula LIMIT para evitar cuellos de botella en el rendimiento.
Caché de consultas: Aprovecha la caché de resultados para acelerar las consultas repetidas.
Uso de recursos: Supervisa la utilización del Almacén SQL para asegurarte de que el tamaño del clúster y los ajustes de escalado satisfacen tus necesidades de carga de trabajo.
Databricks SQL es una potente plataforma que tiende un puente entre los lagos de datos y los almacenes de datos, proporcionando una solución unificada para la analítica moderna de datos y la inteligencia empresarial. Tanto si estás creando cuadros de mando, optimizando consultas o supervisando datos con alertas, Databricks SQL ofrece la flexibilidad y el rendimiento necesarios para afrontar los retos actuales de los datos. Te animo a explorar las funciones y capacidades de Databricks SQL para mejorar tus flujos de trabajo de datos, potenciar la colaboración e impulsar una toma de decisiones más inteligente y rápida.
Si estás interesado en convertirte en un ingeniero de datos profesional, te recomiendo encarecidamente que sigas el curso de DatacMap Comprender la Ingeniería de Datos para aprender cómo los ingenieros de datos almacenan y procesan los datos para facilitar la colaboración con los científicos de datos. También te recomiendo que sigas nuestro curso Toma de Decisiones Basada en Datos en SQL para aprender a utilizar SQL como apoyo a la toma de decisiones mediante proyectos del mundo real. Además, por supuesto, no olvides echar un vistazo a nuestro gran surtido de cursos sobre la nube.
Aprende Databricks con DataCamp
Curso
Curso
Curso
blog
Gus Frazer
14 min
Tutorial
Anneleen Rummens
Tutorial
Oluseye Jeremiah
Tutorial
Sejal Jaiswal
Tutorial
Joleen Bothma