
Kurs
Databricks-Konzepte
4 Std.
22.1K
Databricks SQL ist ein leistungsstarkes Tool für die Datenverwaltung und -analyse innerhalb der Databricks Lakehouse-Plattform. Diese Plattform integriert Data Engineering, Data Science und Business Analytics zu einem einheitlichen Erlebnis. Daher ist Databricks SQL wichtig für Datenexperten, die ihre Daten-Workflows, die Ausführung von Abfragen und BI-Aufgaben ohne die Komplexität des traditionellen Infrastrukturmanagements rationalisieren wollen.
In diesem Artikel gehe ich auf die Komponenten, Funktionen und Werkzeuge von Databricks SQL ein und zeige praktische Beispiele für die Erstellung und Verwendung von Databricks SQL Warehouse. Für den Anfang empfehle ich dir den DataCamp-Kurs "Einführung in Databricks ", um mehr über Databricks als Data-Warehousing-Lösung für Business Intelligence (BI) zu erfahren, die SQL-optimierte Funktionen zum Erstellen von Abfragen und Analysieren von Daten nutzt.
Databricks SQL ist ein robustes Analysetool innerhalb der Databricks Lakehouse-Plattform, mit dem Datenexperten SQL-Abfragen ausführen, Daten analysieren und interaktive Dashboards erstellen können. Databricks SQL wurde mit einer serverlosen Architektur entwickelt und kombiniert die Flexibilität von Data Lakes mit den Governance- und Leistungsfähigkeiten von Data Warehouses.
Zu den wichtigsten Komponenten von Databricks SQL gehören SQL Warehouses, SQL Editors und SQL Dashboards. Mach dir keine Sorgen, wenn du mit diesen Begriffen nicht vertraut bist, denn ich werde weiter unten auf die Bedeutung der einzelnen Begriffe eingehen.
Die SQL-Kernkomponenten von Databricks ermöglichen effiziente Abfragen, Datenvisualisierung und Zusammenarbeit zwischen den Nutzern. Im Folgenden findest du einen Überblick über die wichtigsten Werkzeuge und Funktionen von Databricks SQL.
SQL Warehouses dienen als Rechenressourcen für die Ausführung von SQL-Abfragen in Databricks SQL. Sie sind so konzipiert, dass sie unterschiedliche Arbeitslasten bewältigen können und je nach Art des ausgewählten Lagers Leistungsoptimierungen bieten. Es gibt drei Haupttypen von SQL Warehouses:
SQL Warehouse in Databricks SQL. Bild vom Autor.
Der SQL-Editor ist eine benutzerfreundliche Oberfläche, mit der du SQL-Abfragen schreiben, ausführen und verwalten kannst. Zu den wichtigsten Funktionen des SQL-Editors gehören:
SQL Editor in Databricks SQL. Bild vom Autor.
Dashboards ermöglichen die Visualisierung von Daten, indem sie Abfrageergebnisse in interaktive Diagramme, Grafiken und Widgets umwandeln. Dashboards sind ideal, um wichtige Kennzahlen zu überwachen und Erkenntnisse effektiv im Unternehmen zu kommunizieren. Zu den wichtigsten Funktionen von Dashboards gehören die folgenden:
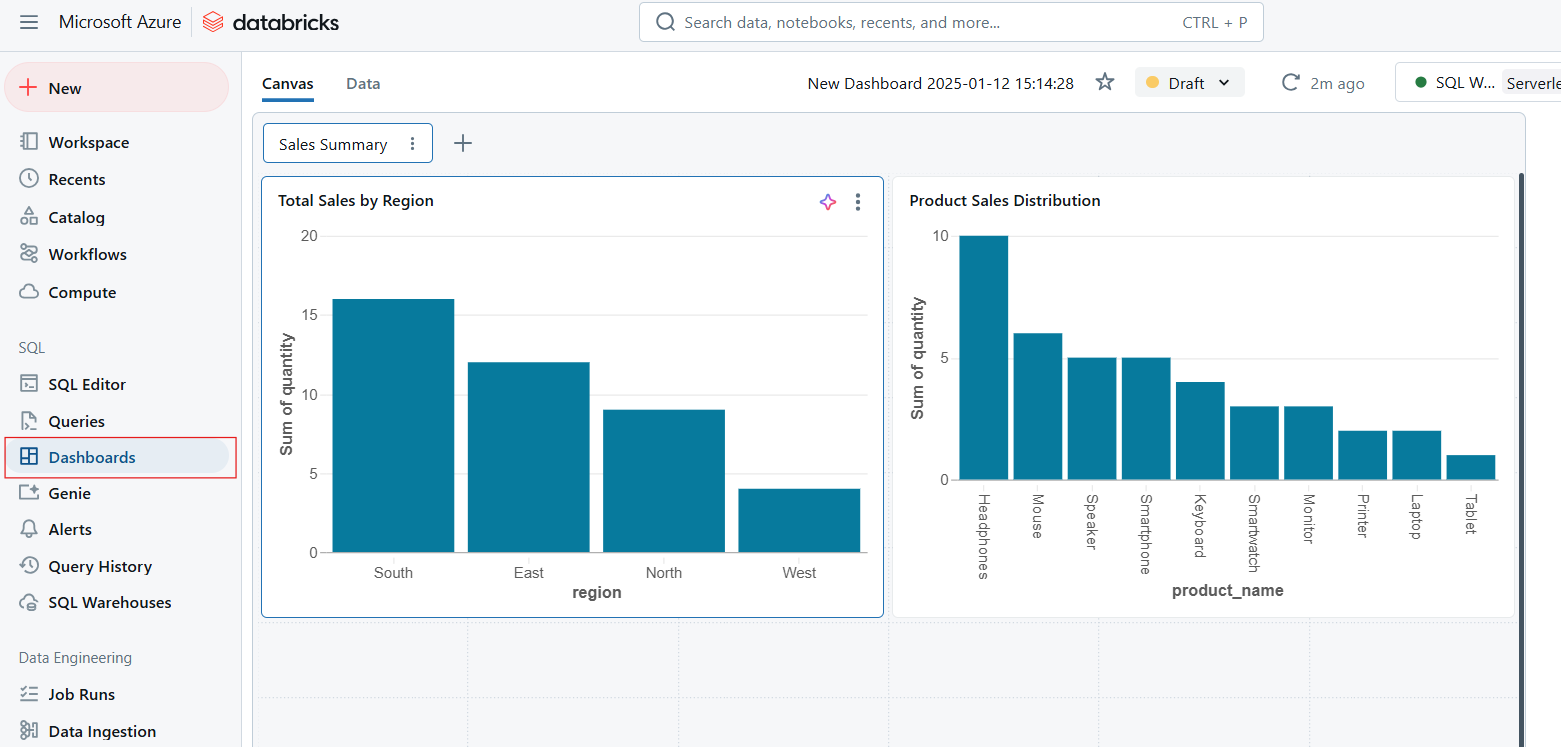
Dashboards in Databricks SQL. Bild vom Autor.
Alerts in Databricks SQL bieten eine Möglichkeit, Datenänderungen zu überwachen und Benachrichtigungen auszulösen, wenn bestimmte Bedingungen erfüllt sind. Warnmeldungen sind wichtig, um die Datenqualität zu erhalten und rechtzeitig auf wichtige Änderungen reagieren zu können. Die Warnfunktion funktioniert folgendermaßen.
Abschließend möchte ich noch erwähnen, dass Databricks SQL Tools zum Verfolgen des Lernpfads und zur Profilerstellung bietet:
Abfrageverlauf in Databricks SQL. Bild vom Autor.
Databricks SQL ist vollgepackt mit fortschrittlichen Funktionen und Tools. Diese Funktionen wurden entwickelt, um die Leistung zu verbessern, Arbeitsabläufe zu optimieren und eine nahtlose Integration mit anderen Tools zu ermöglichen. Sehen wir uns einige der wichtigsten Dinge an, die Databricks SQL zu einer so guten Wahl machen.
Die Photon Engine ist eine leistungsstarke, vektorisierte Abfrage-Engine, die von Databricks entwickelt wurde, um die Ausführung von SQL-Abfragen erheblich zu beschleunigen. Zu den wichtigsten Vorteilen der Photon Engine gehören die folgenden:
CloudFetch und Async I/O sind Funktionen, die die Geschwindigkeit der Datenübertragung und den Umgang mit kleinen Dateien während der Ausführung von Abfragen verbessern. Diese Funktionen funktionieren auf folgende Weise:
Databricks SQL lässt sich nahtlos in gängige Business Intelligence (BI)-Tools integrieren und erleichtert Teams die Analyse und Visualisierung von Daten. Zu den unterstützten Integrationen gehören die folgenden:
Die serverlose Architektur von Databricks SQL macht die manuelle Verwaltung der Infrastruktur überflüssig, da die Ressourcen automatisch entsprechend den Arbeitsanforderungen bereitgestellt und skaliert werden. Die serverlose Architektur passt die Ressourcen automatisch an, um unterschiedliche Abfragelasten ohne Ausfallzeiten zu bewältigen. Diese Funktion sorgt dafür, dass die Nutzer/innen die Cluster nicht manuell konfigurieren oder warten müssen. Die serverlose Architektur ist auch kosteneffizient, da die Nutzer nur für die Ressourcen zahlen, die während der Ausführung der Abfrage genutzt werden.
Ein Einzelhandelsunternehmen hat zum Beispiel während der Hauptgeschäftszeiten ein hohes Anfrageaufkommen. Die serverlose Architektur skaliert automatisch die Ressourcen, um eine gleichbleibende Leistung zu gewährleisten, und reduziert sie außerhalb der Geschäftszeiten, um Kosten zu sparen.
Databricks SQL Warehouses sind für die effiziente Ausführung von SQL-Abfragen innerhalb der Databricks-Umgebung unerlässlich. In diesem Abschnitt werde ich dir zeigen, wie du ein SQL-Warehouse erstellst und es mit Notizbüchern verwendest. Wenn du dein Wissen über Data Warehouses auffrischen möchtest, empfehle ich dir unseren Kurs Data Warehousing Concepts, in dem du die Grundlagen der Datenmodellierung und Datentransformation lernst.
Befolge diese Schritte, um ein SQL Warehouse mit der Databricks Web UI zu erstellen:
Im Databricks-Arbeitsbereich klickst du auf das SQL-Symbol in der Seitenleiste.
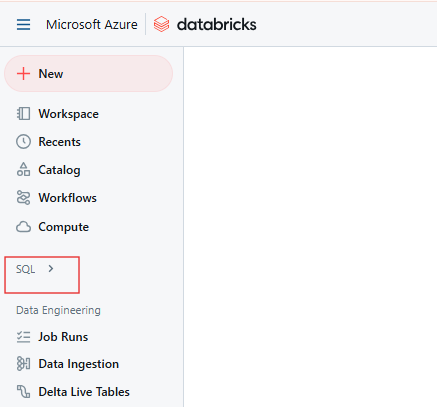
Databricks SQL-Seite. Bild vom Autor.
Navigiere auf der Seite SQL zu der Registerkarte SQL-Warehouses.
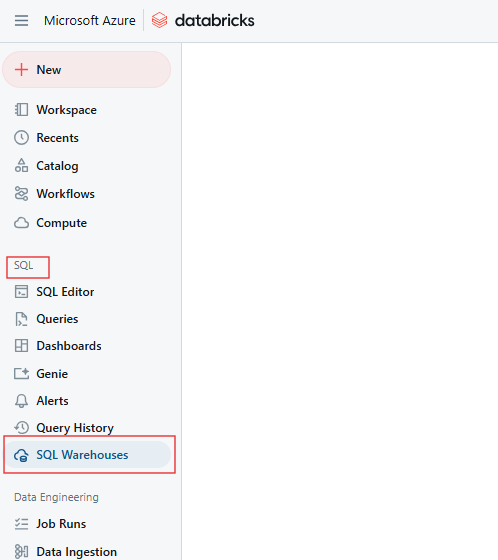
Databricks SQL Warehouse Registerkarte. Bild vom Autor.
Klicke auf die Schaltfläche Warehouse erstellen, um mit der Konfiguration deines neuen SQL Warehouse zu beginnen.
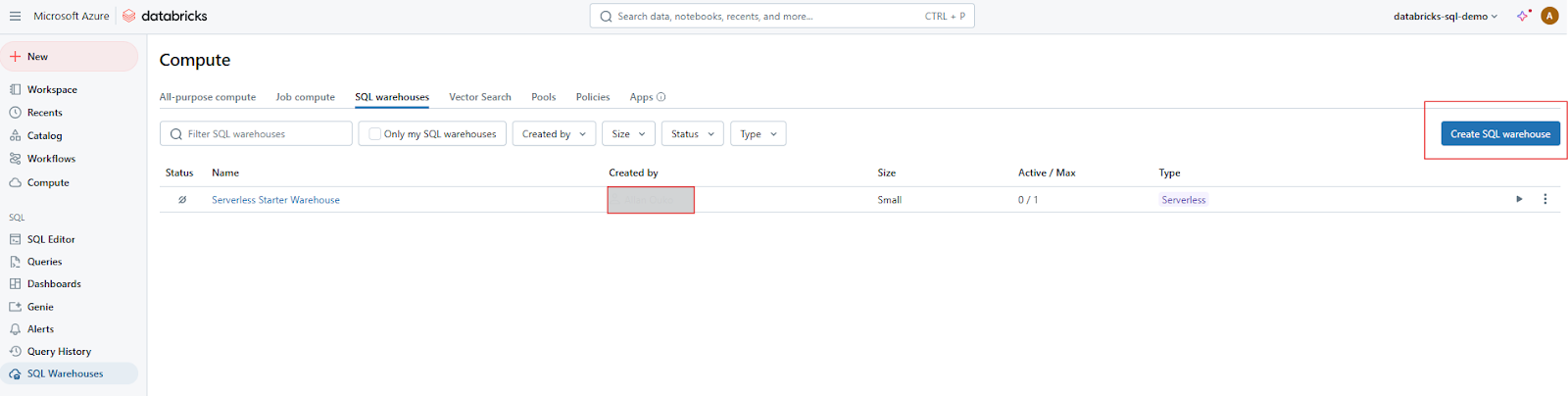
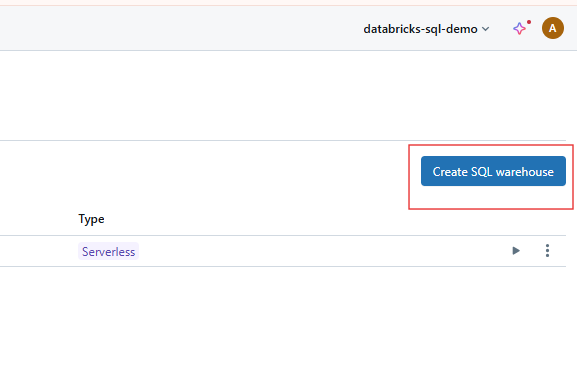
Erstellen von SQL Warehouse auf Databricks SQL. Bild vom Autor.
Konfiguriere die Lagereinstellungen mit den folgenden Optionen.
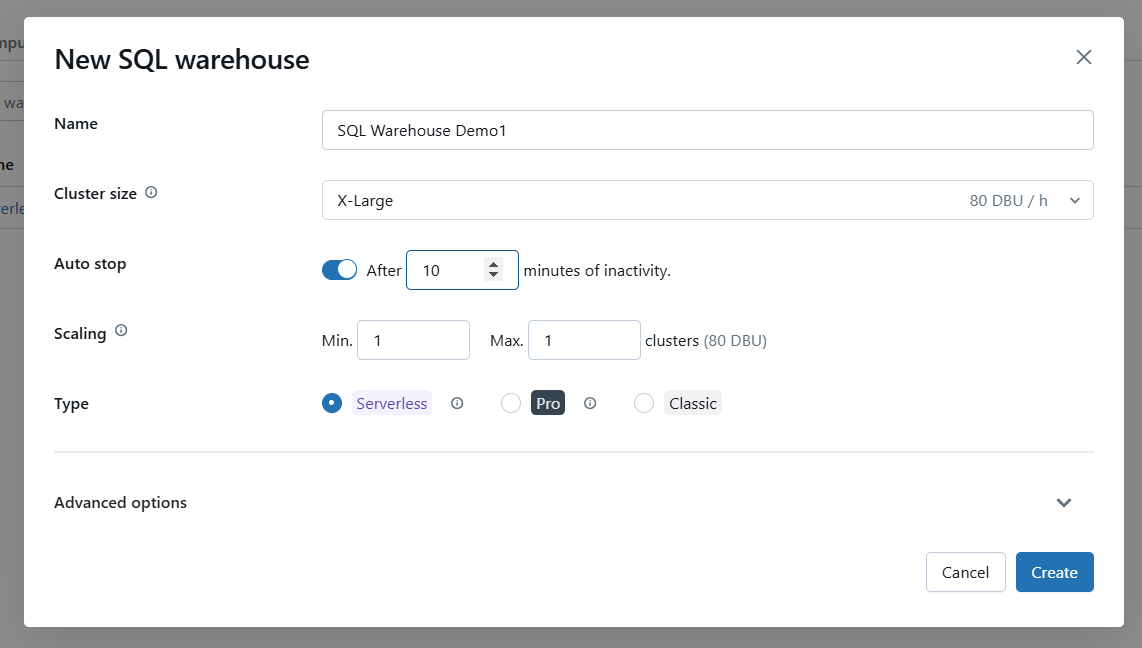
Konfiguriere die Grundeinstellungen für Databricks SQL Warehouse. Bild vom Autor.
Konfiguriere bei Bedarf erweiterte Optionen wie die Aktivierung von Photon oder bestimmte SQL-Konfigurationen.
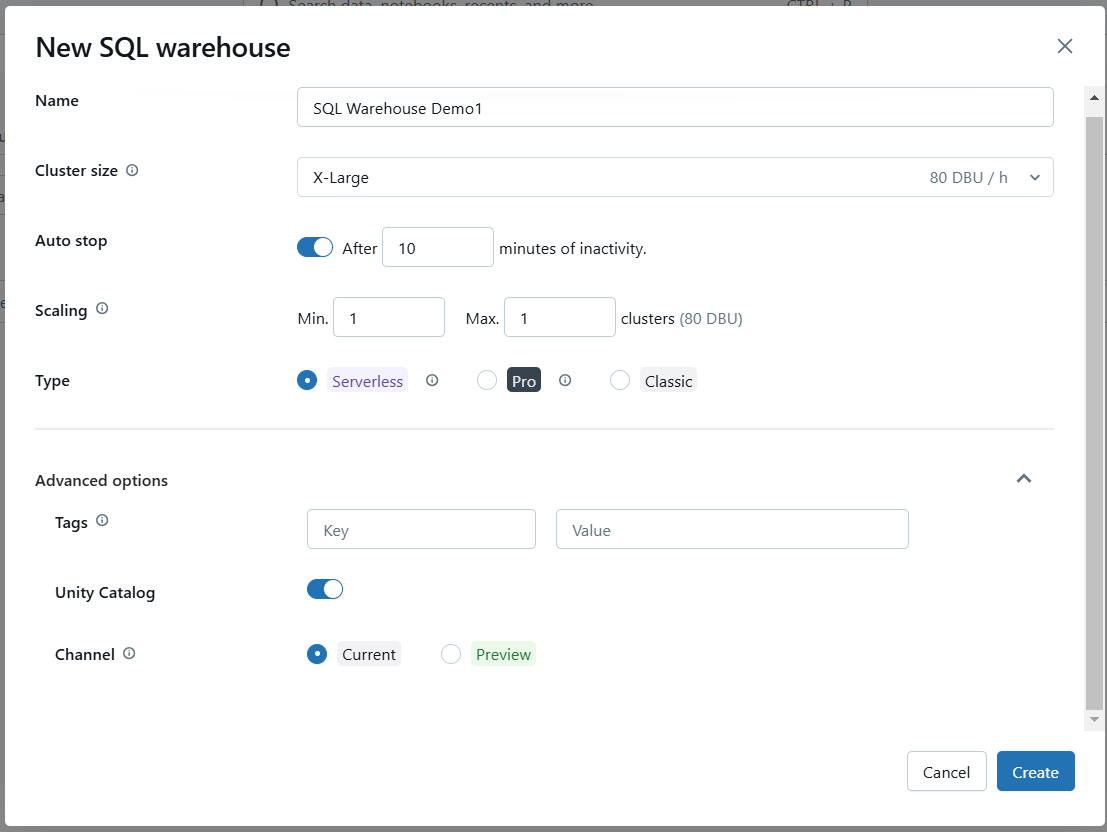
Konfiguriere die erweiterten Einstellungen für Databricks SQL Warehouse. Bild vom Autor.
Klicke auf Erstellen, um deine Konfiguration zu speichern. Wenn du das Lager erstellt hast, starte es, um es betriebsbereit zu machen.
Erstellen des Databricks SQL Warehouse. Bild vom Autor.
Nach der Erstellung erscheint ein Berechtigungsmodal, in dem du Benutzern oder Gruppen Zugriff auf das Lager gewähren kannst.
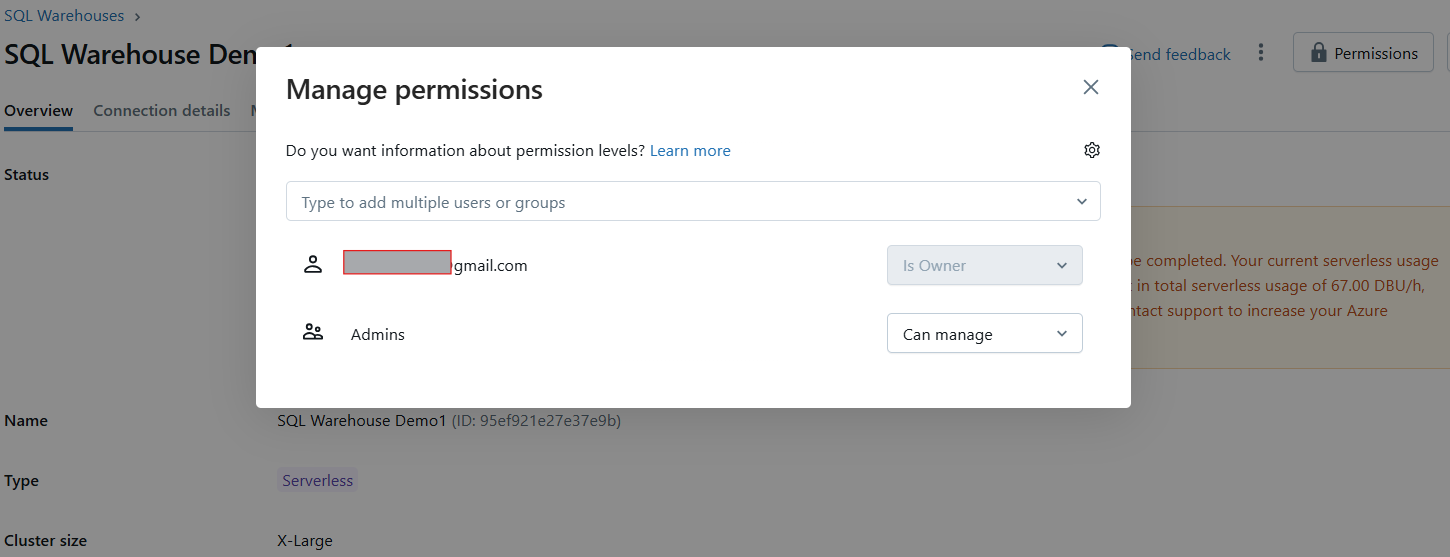
Verwalten von Berechtigungen für Databricks SQL Warehouse. Bild vom Autor.
Sobald es erstellt ist, wird dein SQL-Warehouse automatisch gestartet, sodass du sofort Abfragen ausführen kannst.
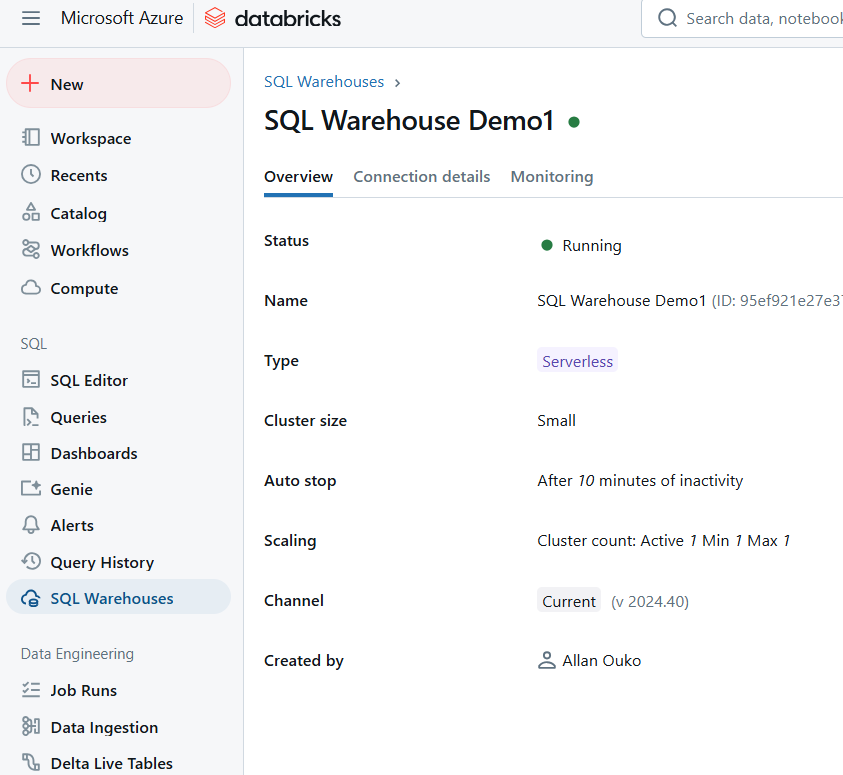
Beispiel für Databricks SQL Warehouse. Bild vom Autor.
Um SQL-Abfragen in einem Notizbuch mit deinem neu erstellten SQL-Warehouse auszuführen, befolge diese Schritte:
Erstelle im Databricks-Arbeitsbereich ein neues Notizbuch oder öffne ein bestehendes.
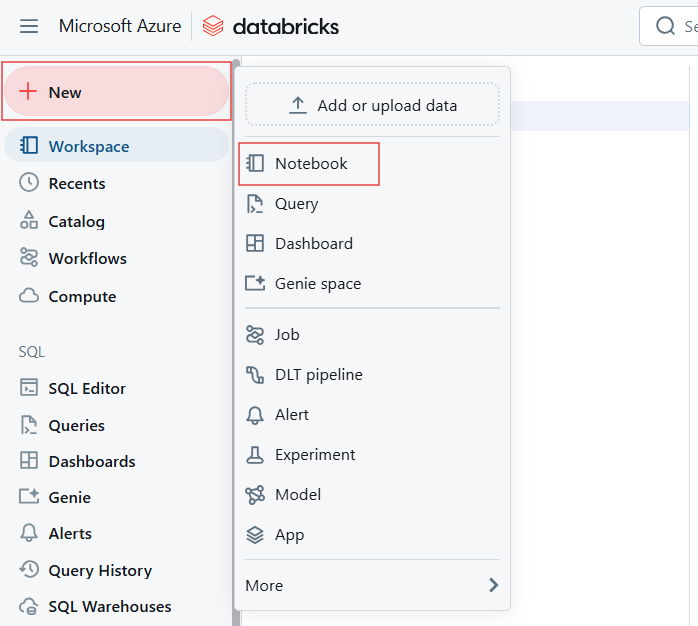
Ein neues Notebook erstellen, um Databricks SQL Warehouse zu erstellen. Bild vom Autor.
Suche in der Notebook-Symbolleiste nach dem Compute Selector oder Connect (wird normalerweise oben angezeigt). Klicke darauf, um ein Dropdown-Menü mit den verfügbaren Rechenressourcen zu öffnen. Wähle dein SQL-Lagerhaus aus der Liste aus. Wenn es nicht sichtbar ist, klicke auf Mehr..., um alle verfügbaren Lagerhäuser anzuzeigen. Klicke auf das gewünschte SQL-Lagerhaus und wähle dann Starten und Anhängen.
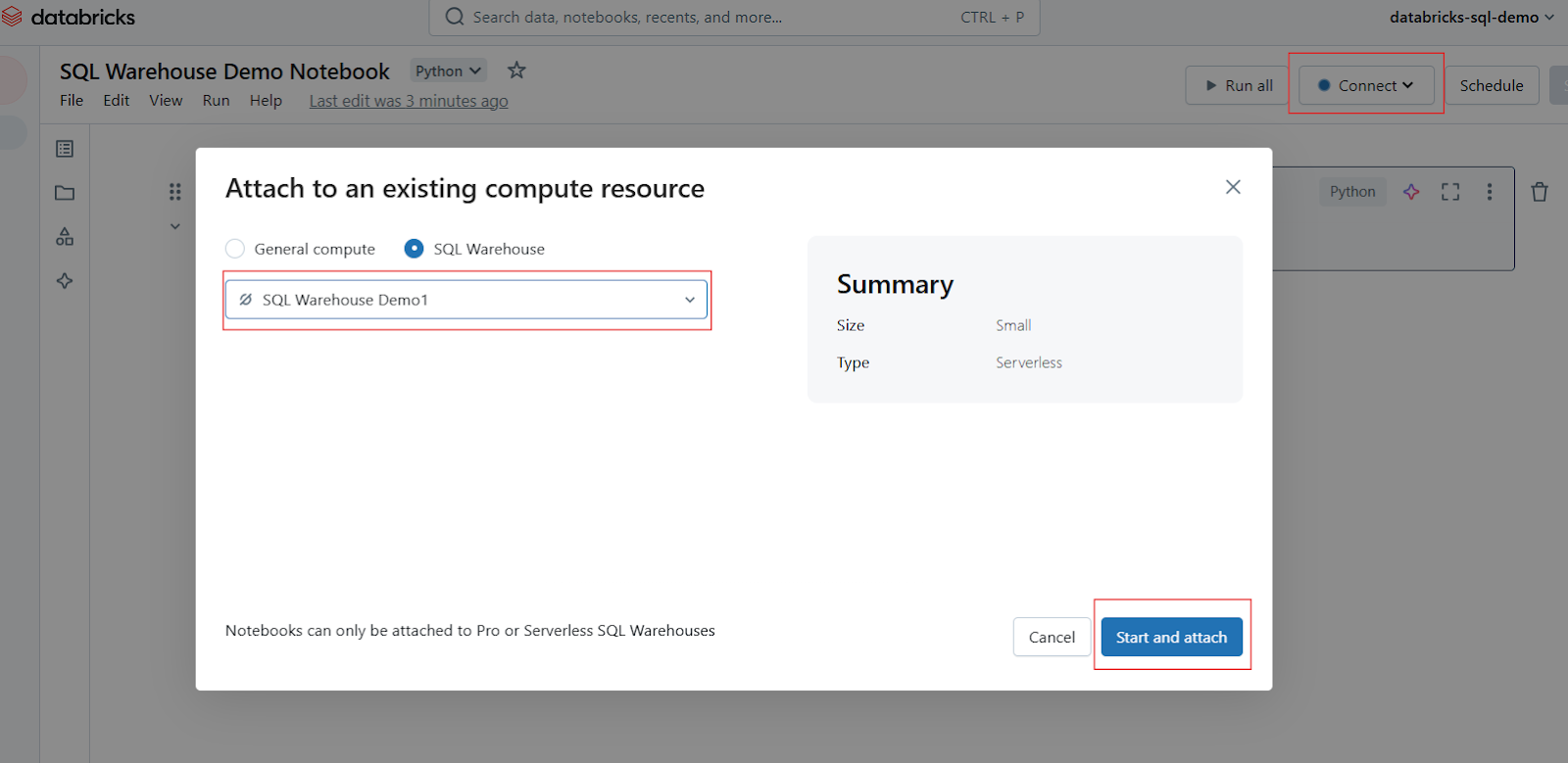
Notebook in Databricks SQL Warehouse anhängen. Bild vom Autor.
Sobald sie angehängt ist, kannst du in deinem Notizbuch Zellen für SQL-Abfragen erstellen. Verwende den Befehl %sql magic, um SQL-Abfragen im Notizbuch auszuführen.
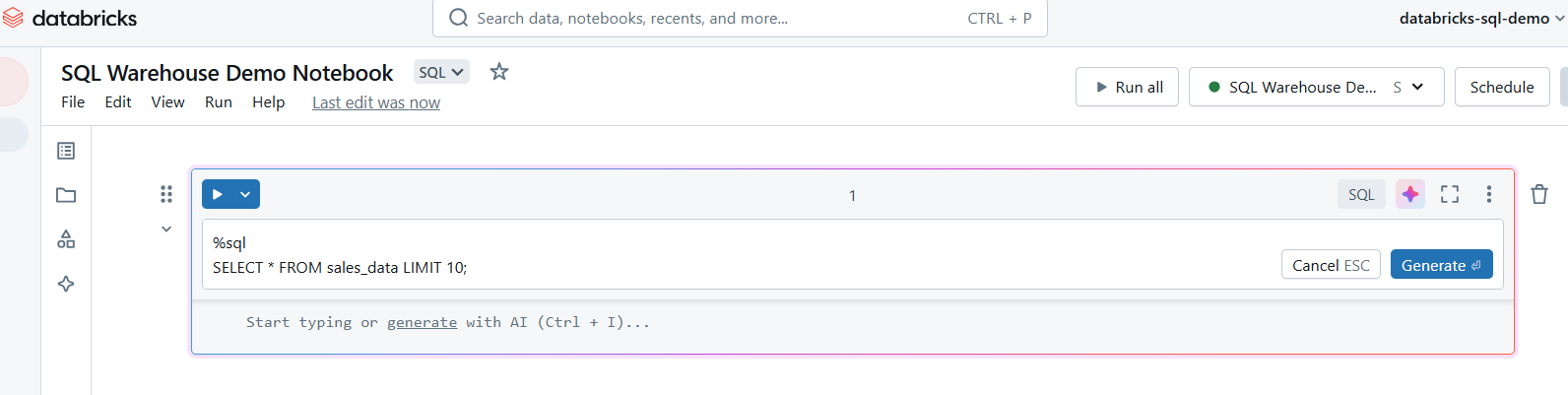
Schreibe SQL-Abfragen in Databricks SQL Warehouse. Bild vom Autor.
Führe die Zelle aus, um deine Abfrage auszuführen. Die Ergebnisse werden direkt unter der Zelle angezeigt, so dass du die Daten leicht einsehen kannst.
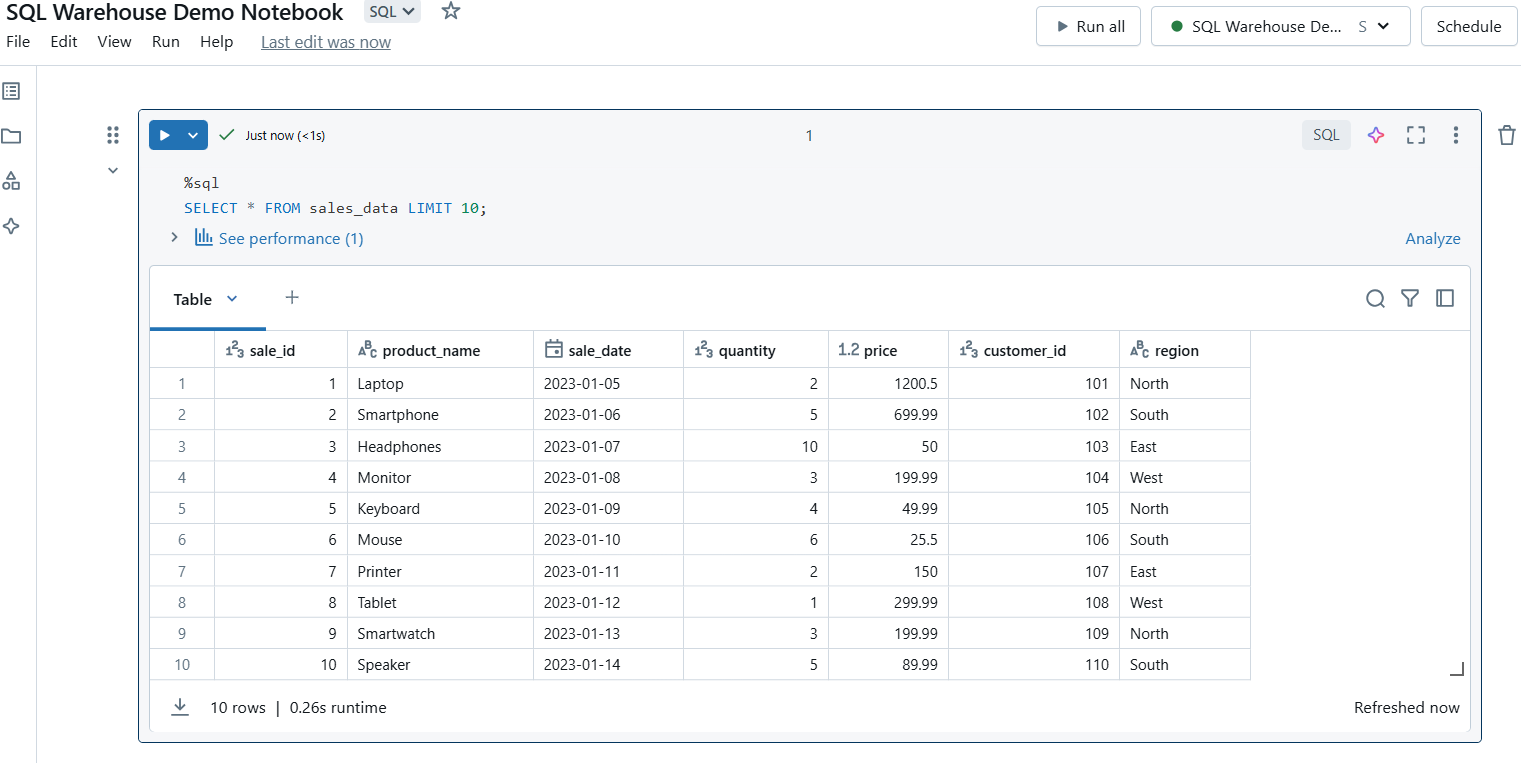
Führe SQL-Abfragen in Databricks SQL Warehouse aus. Bild vom Autor.
Im Folgenden findest du einige Überlegungen zur Verwendung von Notebooks mit SQL Warehouses:
Abfrage-Grenzwerte: SQL Warehouses sind für analytische Abfragen optimiert, nicht für häufige Transaktionsabfragen mit niedriger Latenz.
Datenvorschau: Bei großen Datensätzen solltest du deine Abfrageergebnisse einschränken, z. B. mit der LIMIT Klausel, um Leistungsengpässe zu vermeiden.
Abfrage-Caching: Nutze das Ergebnis-Caching, um wiederholte Abfragen zu beschleunigen.
Ressourcenverwendung: Überwache die Auslastung des SQL Warehouse, um sicherzustellen, dass die Größe des Clusters und die Skalierungseinstellungen den Anforderungen deiner Arbeitslast entsprechen.
Databricks SQL ist eine leistungsstarke Plattform, die die Lücke zwischen Data Lakes und Data Warehouses schließt und eine einheitliche Lösung für moderne Datenanalysen und Business Intelligence bietet. Egal, ob du Dashboards erstellst, Abfragen optimierst oder Daten mit Warnmeldungen überwachst, Databricks SQL bietet die Flexibilität und Leistung, die du brauchst, um die Datenherausforderungen von heute zu bewältigen. Ich möchte dich ermutigen, die Funktionen und Möglichkeiten von Databricks SQL zu erkunden, um deine Daten-Workflows zu verbessern, die Zusammenarbeit zu fördern und intelligentere, schnellere Entscheidungen zu treffen.
Wenn du daran interessiert bist, ein professioneller Data Engineer zu werden, empfehle ich dir den Kurs Understanding Data Engineering von DatacMap, um zu lernen, wie Data Engineers Daten speichern und verarbeiten, um die Zusammenarbeit mit Data Scientists zu erleichtern. Ich empfehle dir auch unseren Kurs "Datengestützte Entscheidungsfindung in SQL", in dem du lernst, wie du SQL zur Entscheidungsfindung in realen Projekten einsetzen kannst. Vergiss auch nicht, dir unsere große Auswahl an Cloud-Kursen anzusehen.
Databricks lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
