
Course
Databricks Concepts
4 hr
22K
Databricks SQL is a powerful tool designed for data management and analytics within the Databricks Lakehouse platform. This platform integrates data engineering, data science, and business analytics into a unified experience. Therefore, Databricks SQL is important for data professionals looking to streamline their data workflows, query execution, and BI tasks without the complexity of traditional infrastructure management.
In this article, I will explore the components, features, and tools of Databricks SQL and show practical examples of creating and using Databricks SQL warehouse. As we get started, I highly recommend taking DataCamp’s Introduction to Databricks course to learn about Databricks as a data warehousing solution for Business Intelligence (BI), leveraging SQL-optimized capabilities to create queries and analyze data.
Databricks SQL is a robust analytics tool within the Databricks Lakehouse platform that allows data professionals to run SQL queries, analyze data, and create interactive dashboards. Designed with a serverless architecture, Databricks SQL combines the flexibility of data lakes with the governance and performance capabilities of data warehouses.
The key components of Databricks SQL include SQL Warehouses, SQL Editors, and SQL Dashboards. Don't worry if you are not familiar with each of these because I'll go into the meaning of each down below.
Unlike other SQL dialects like MySQL, PostgreSQL, or SQL Server, which are designed for transactional databases, Databricks SQL is optimized for large-scale analytics in a Lakehouse environment. Traditional SQL databases focus on structured data storage, whereas Databricks SQL integrates with data lakes while preserving the performance of a data warehouse. With serverless SQL warehouses, there’s no need to manage infrastructure, as resources are provisioned automatically and scale elastically.
Also, I want to say, in Databricks SQL, query execution is faster because it is accelerated by the Photon engine, which supports vectorized processing. Last thing to say: Databricks SQL is built for BI and collaboration; it offers native support for Power BI, Tableau, and Looker.
Databricks SQL core components facilitate efficient querying, data visualization, and collaboration among users. Below is an overview of the primary tools and features available within Databricks SQL.
SQL Warehouses serve as the computational resources for executing SQL queries in Databricks SQL. They are designed to handle varying workloads and provide performance optimizations based on the type of warehouse selected. There are three main types of SQL Warehouses:
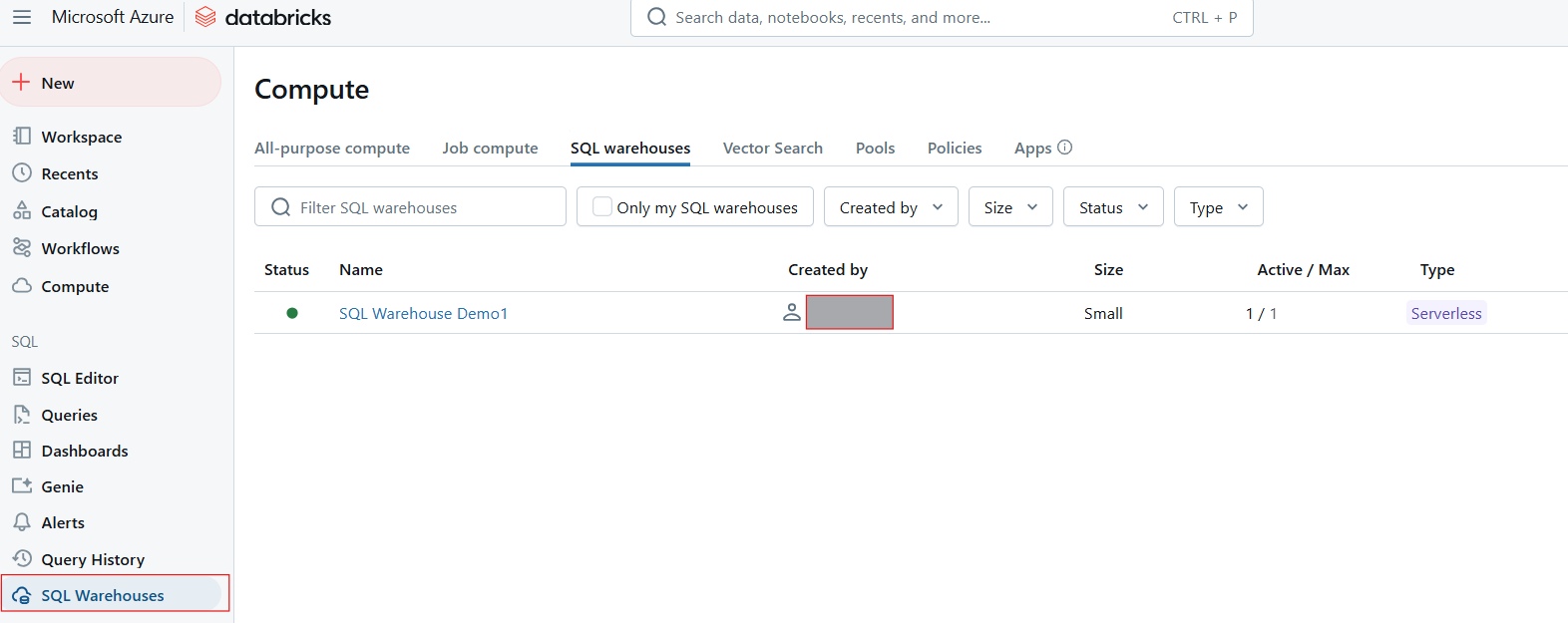
SQL Warehouse in Databricks SQL. Image by Author.
The SQL Editor is a user-friendly interface that enables users to write, execute, and manage SQL queries. Key features of the SQL Editor include:
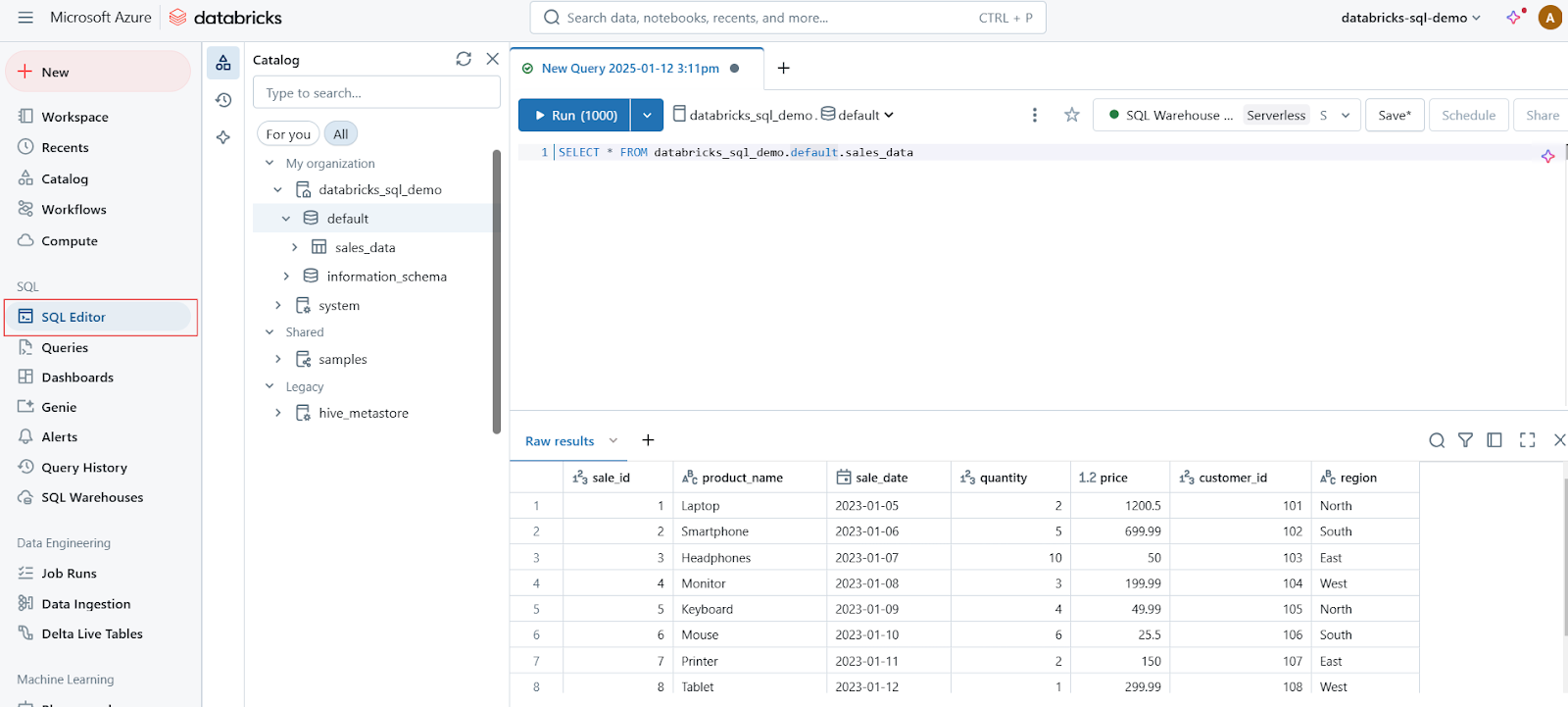
SQL Editor in Databricks SQL. Image by Author.
Dashboards enable data visualization by transforming query results into interactive charts, graphs, and widgets. Dashboards are ideal for monitoring key metrics and communicating insights effectively across an organization. The key capabilities of dashboards include the following:
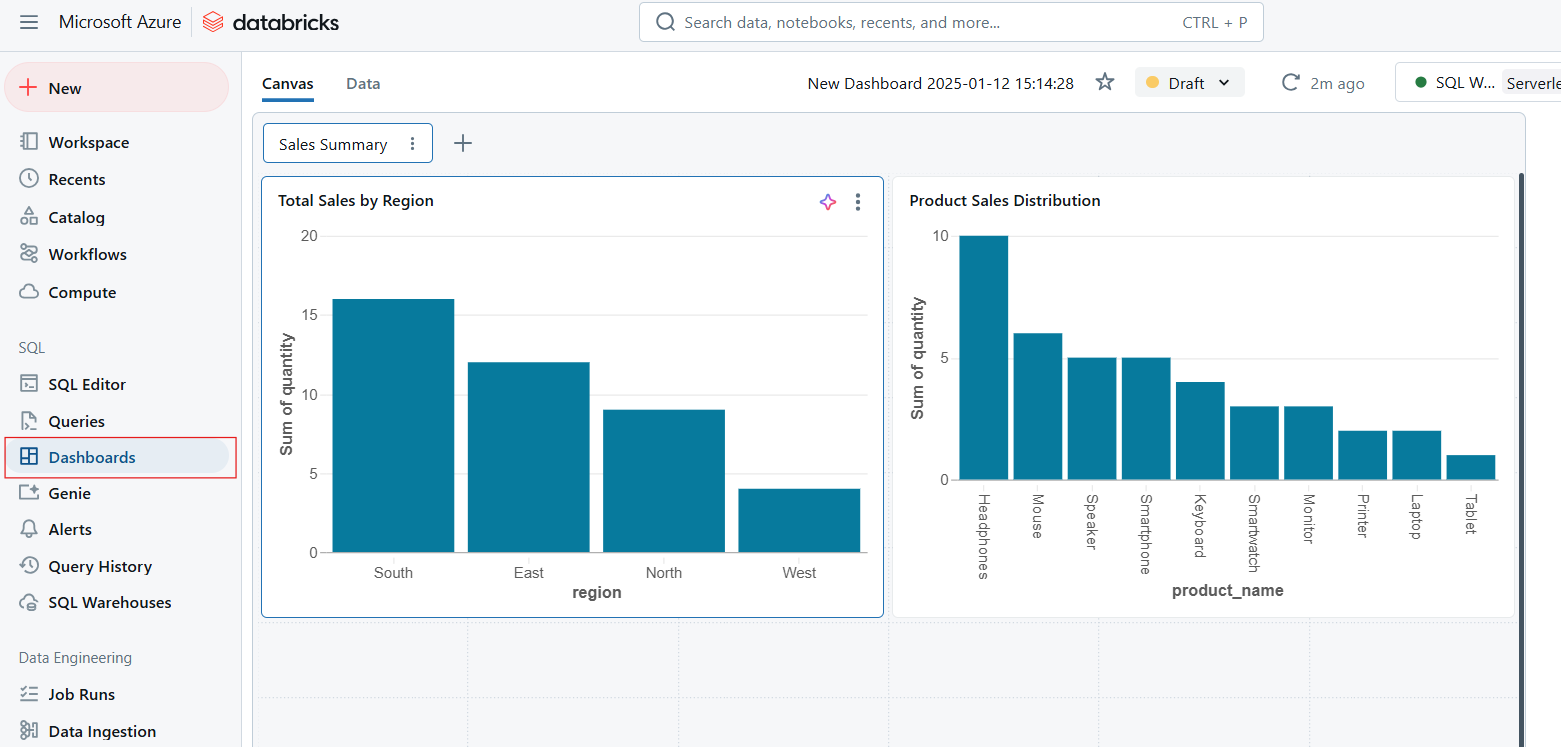
Dashboards in Databricks SQL. Image by Author.
Alerts in Databricks SQL provide a way to monitor data changes and trigger notifications when specified conditions are met. Alerts are essential for maintaining data quality and ensuring timely responses to important changes. The alert functionality works in the following way.
Finally, I want to say that Databricks SQL offers tools for tracking query history and profiling:
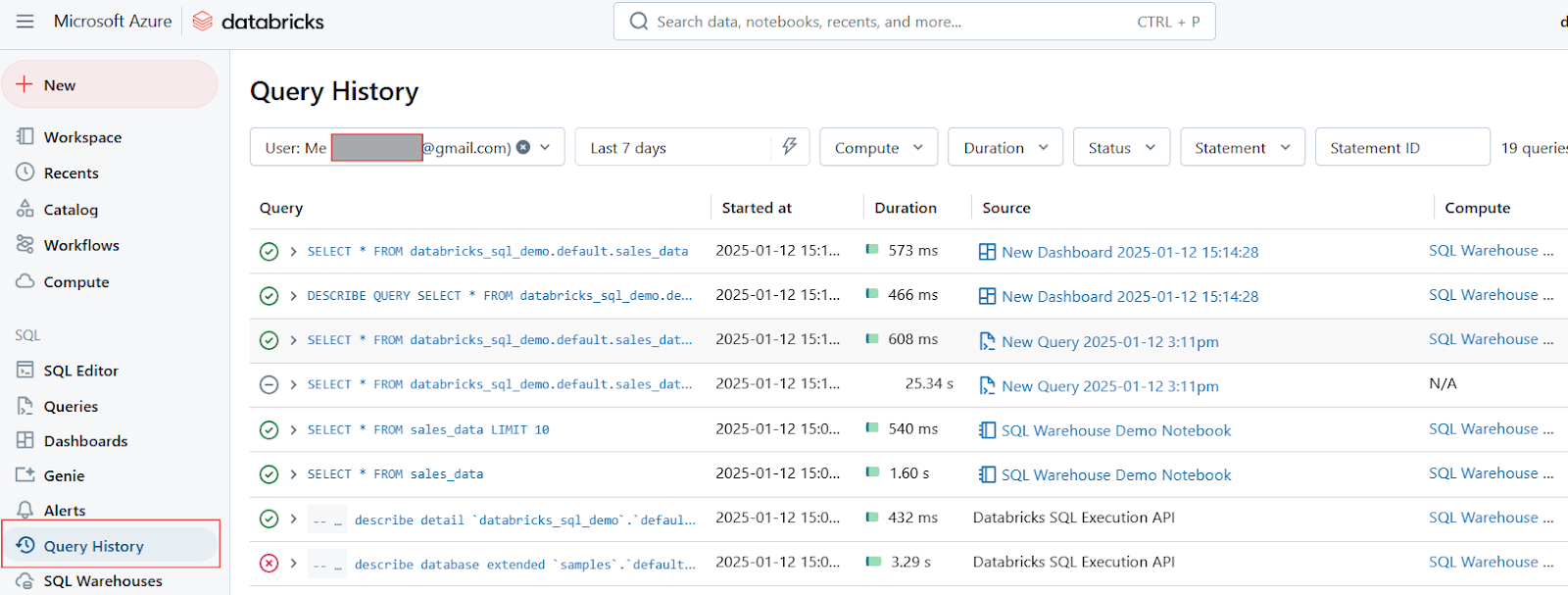
Query History in Databricks SQL. Image by Author.
Databricks SQL is packed with advanced features and tools. These features are designed to enhance performance, streamline workflows, and enable seamless integration with other tools. Let us look at some of the key things that make Databricks SQL such a great choice.
The Photon Engine is a high-performance, vectorized query engine developed by Databricks to accelerate SQL query execution significantly. The key benefits of the Photon Engine include the following:
CloudFetch and Async I/O are features designed to enhance data transfer speeds and improve the handling of small files during query execution. These features work in the following ways:
Databricks SQL integrates seamlessly with popular Business Intelligence (BI) tools, making it easier for teams to analyze and visualize data. The supported integrations include the following:
Databricks SQL’s serverless architecture eliminates the need for manual infrastructure management by automatically provisioning and scaling resources based on workload demands. The serverless architecture will automatically adjust resources to handle varying query loads without downtime. This feature ensures that users do not need to configure or maintain clusters manually. The serverless architecture is also cost-efficient, as users pay only for the resources used during query execution.
For example, a retail company experiences high query loads during peak business hours. The serverless architecture automatically scales up resources to ensure consistent performance and scales down during off-hours to save costs.
Databricks SQL Warehouses are essential for executing SQL queries efficiently within the Databricks environment. Now, in this section, I will walk you through the process of creating SQL warehouse and using it with notebooks. If you need to refresh your knowledge about data warehouses, I recommend taking our Data Warehousing Concepts course to learn the fundamentals of data modeling and data transformation.
Follow these steps to create a SQL Warehouse using the Databricks web UI:
From the Databricks workspace, click on the SQL icon in the sidebar.
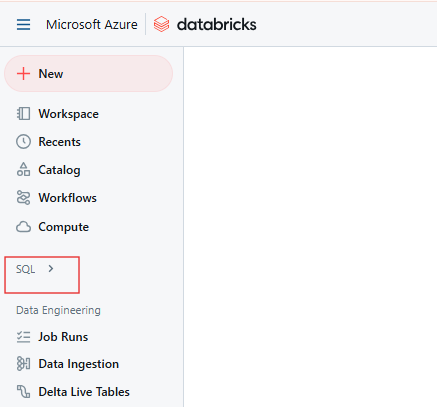
Databricks SQL page. Image by Author.
On the SQL page, navigate to the SQL Warehouses tab.
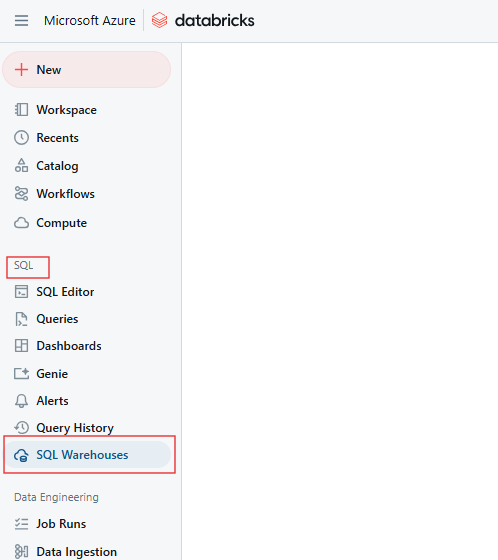
Databricks SQL Warehouse tab. Image by Author.
Click the Create Warehouse button to start configuring your new SQL Warehouse.
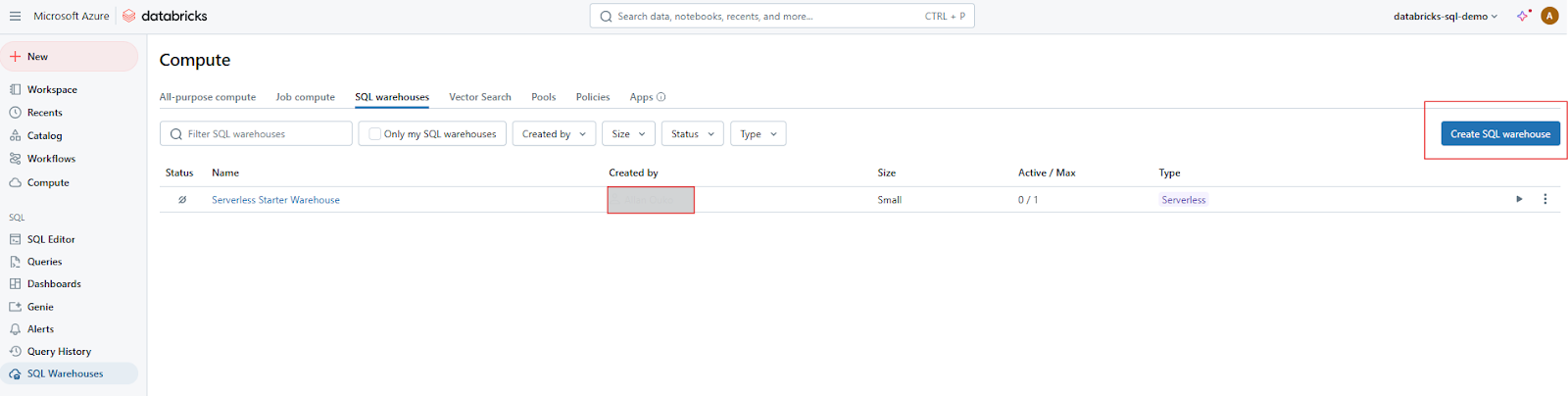
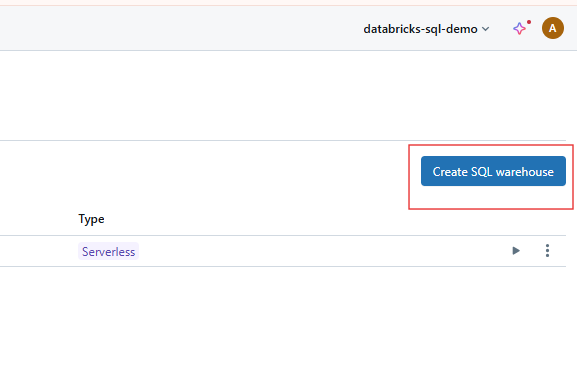
Creating SQL Warehouse on Databricks SQL. Image by Author.
Configure the warehouse settings using the following options.
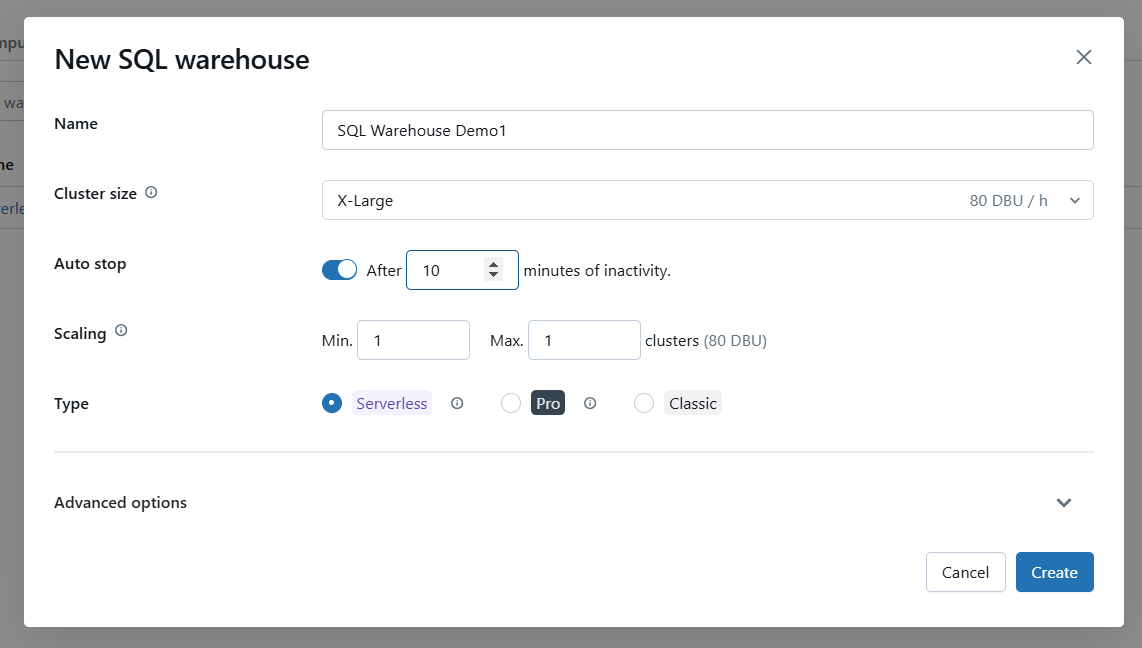
Configure basic settings for Databricks SQL Warehouse. Image by Author.
If needed, configure advanced options such as enabling Photon or setting specific SQL configurations.
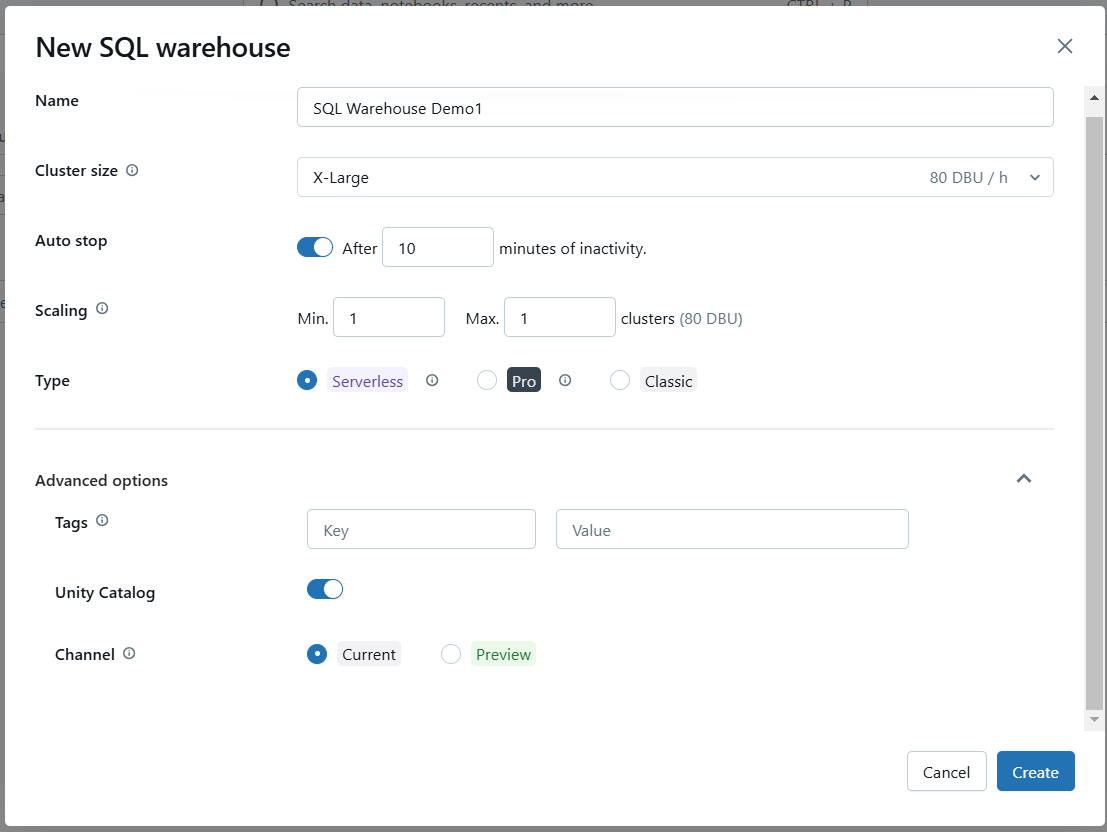
Configure advanced settings for Databricks SQL Warehouse. Image by Author.
Click Create to save your configuration. Once created, start the warehouse to make it operational.
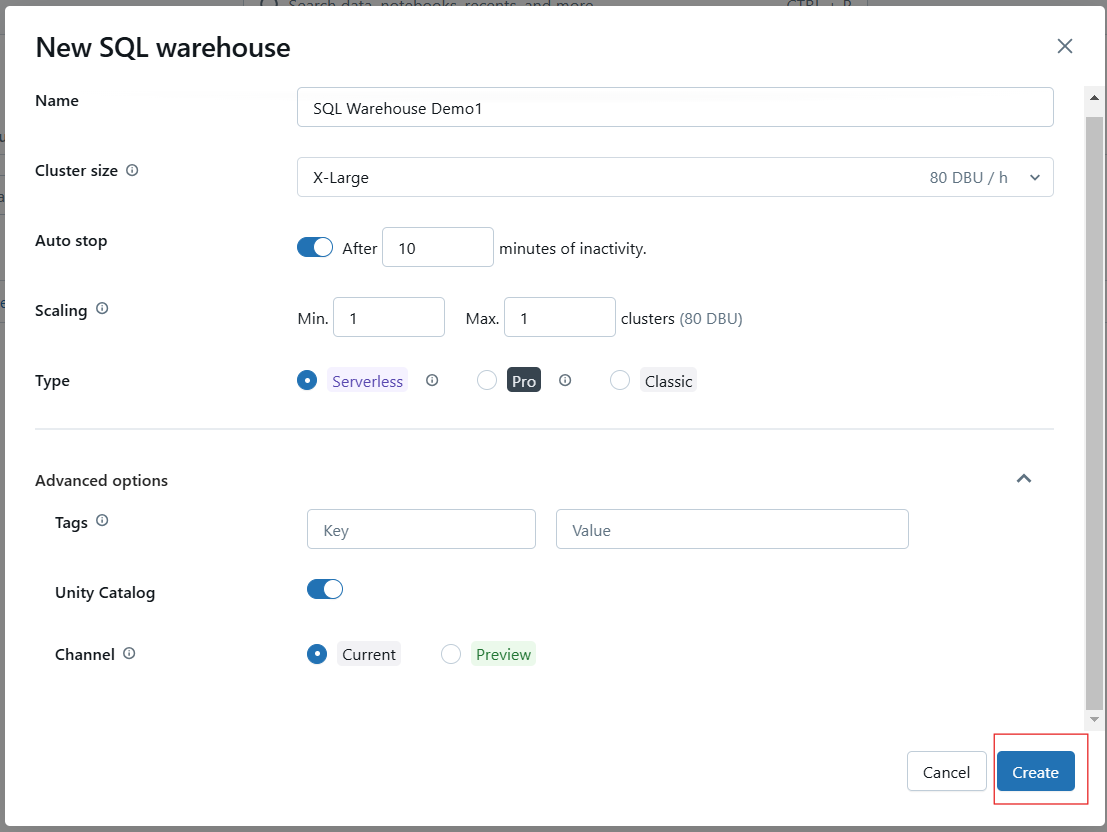
Creating the Databricks SQL Warehouse. Image by Author.
After creation, a permissions modal will appear where you can grant users or groups access to the warehouse.
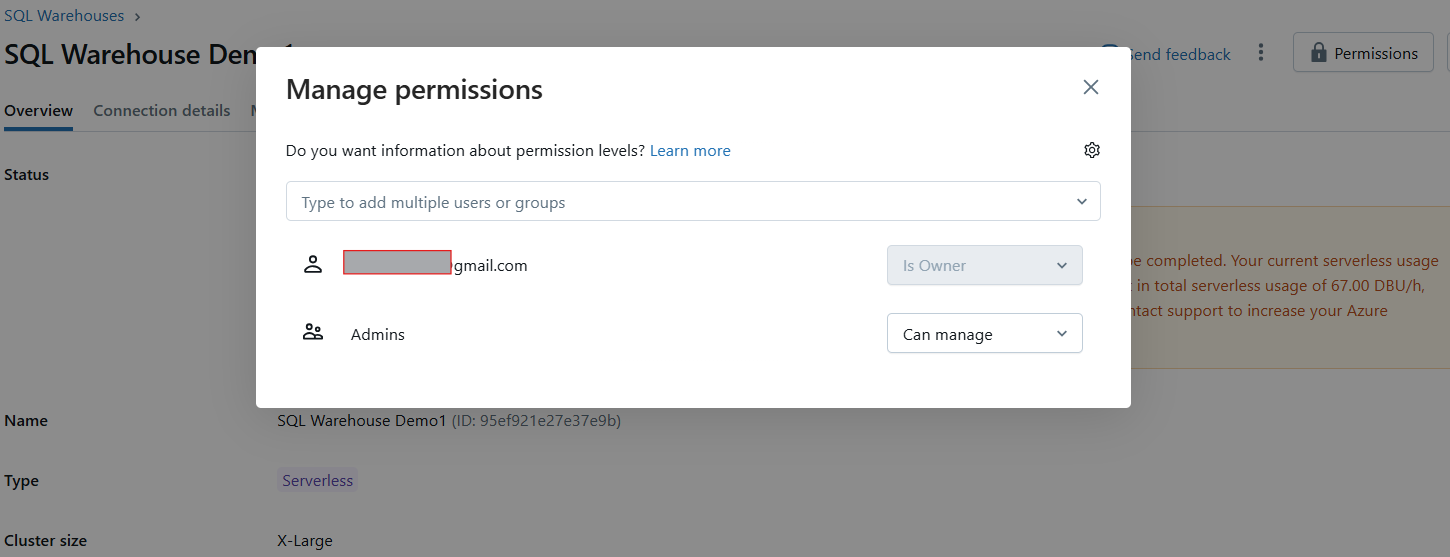
Managing permissions of Databricks SQL Warehouse. Image by Author.
Once created, your SQL warehouse will start automatically, allowing you to execute queries immediately.
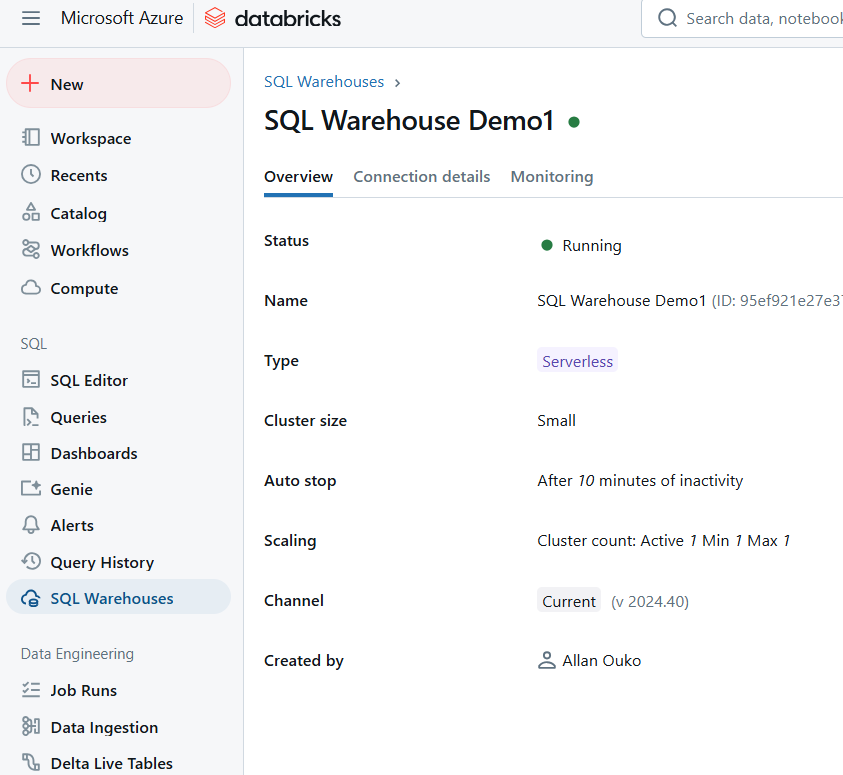
Example of Databricks SQL Warehouse. Image by Author.
To execute SQL queries in a notebook using your newly created SQL warehouse, follow these steps:
From the Databricks workspace, create a new notebook or open an existing one.
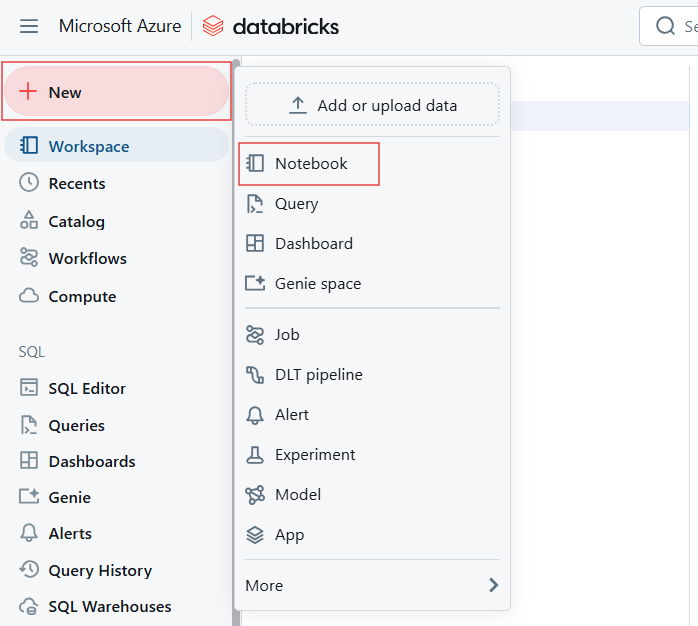
Creating a new Notebook to create Databricks SQL Warehouse. Image by Author.
In the Notebook toolbar, locate the compute selector or connect (usually displayed at the top). Click on it to open a dropdown menu showing available compute resources. Select your SQL warehouse from the list. If it’s not visible, click on More… to view all available warehouses. Click on the desired SQL warehouse and then select Start and attach.
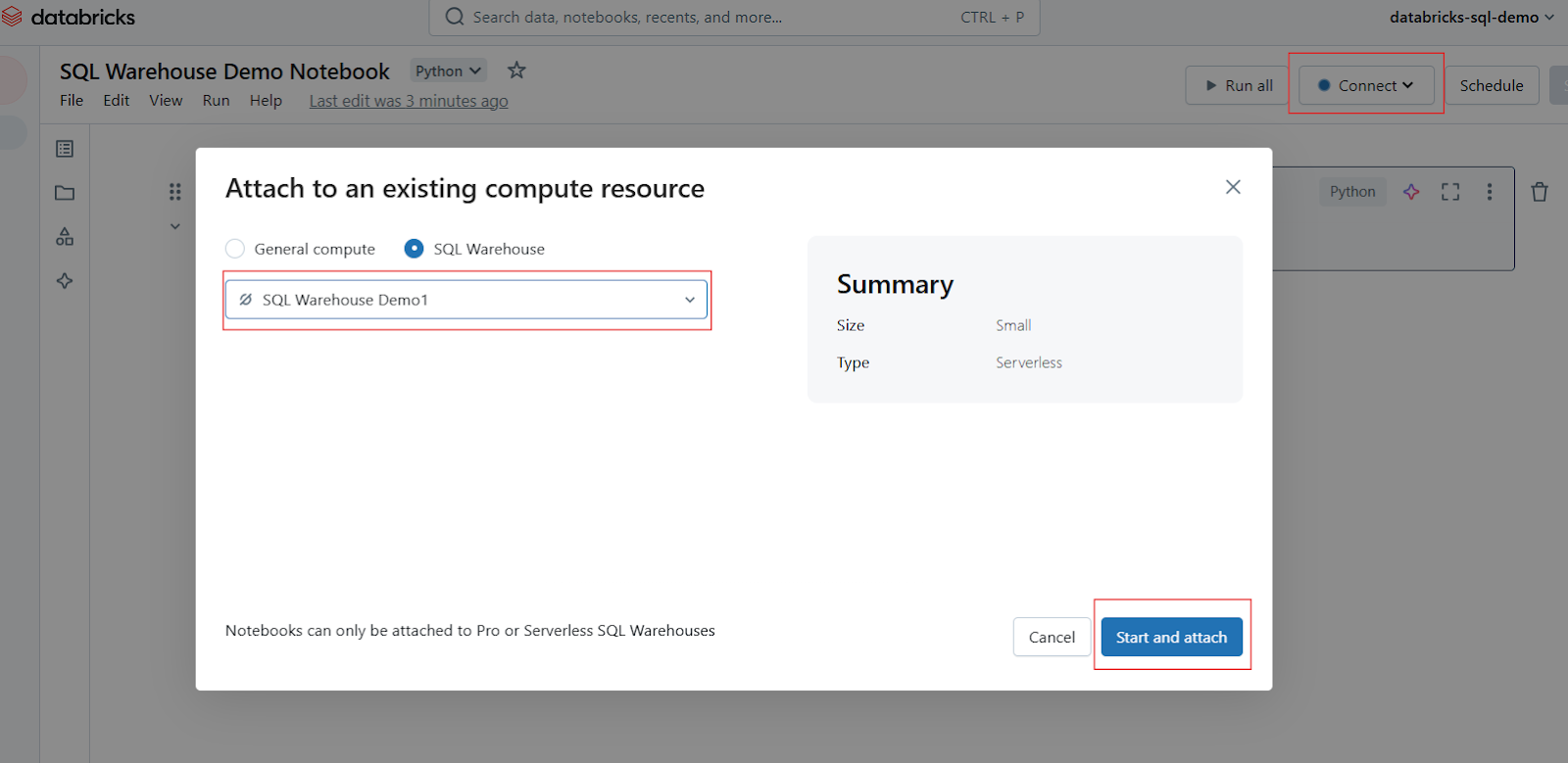
Attach Notebook in Databricks SQL Warehouse. Image by Author.
Once attached, you can create cells in your notebook for SQL queries. Use the %sql magic command to execute SQL queries in the notebook.
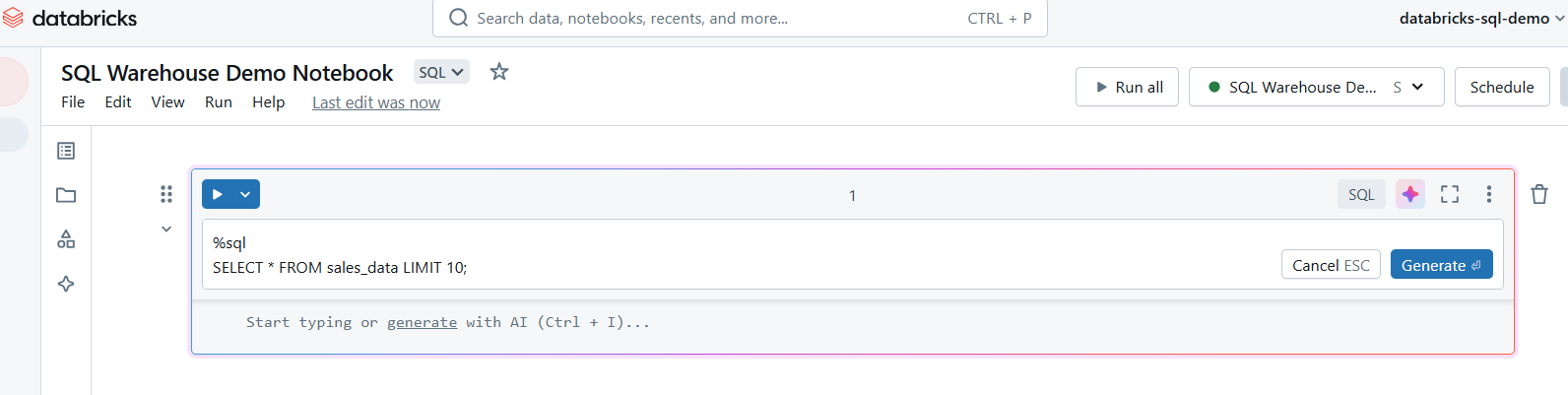
Write SQL queries in Databricks SQL Warehouse. Image by Author.
Run the cell to execute your query. The results will be displayed directly below the cell, making it easy to preview data.
Execute SQL queries in Databricks SQL Warehouse. Image by Author.
The following are some considerations when using notebooks with SQL Warehouses:
Query Limits: SQL Warehouses are optimized for analytical queries, not for frequent, low-latency transactional queries.
Data Preview: For large datasets, consider limiting your query results, such as using the LIMIT clause to avoid performance bottlenecks.
Query Caching: Take advantage of result caching to speed up repeated queries.
Resource Usage: Monitor the SQL Warehouse’s utilization to ensure the cluster size and scaling settings meet your workload needs.
Databricks SQL is a powerful platform that bridges the gap between data lakes and data warehouses, providing a unified solution for modern data analytics and business intelligence. Whether you're building dashboards, optimizing queries, or monitoring data with alerts, Databricks SQL offers the flexibility and performance needed to handle today’s data challenges. I encourage you to explore the features and capabilities of Databricks SQL to enhance your data workflows, empower collaboration, and drive smarter, faster decision-making.
If you are interested in becoming a professional data engineer, I highly recommend taking our Understanding Data Engineering course to learn how data engineers store and process data to facilitate collaboration with data scientists. I also recommend taking our Data-Driven Decision-Making in SQL course to learn how to use SQL to support decision-making using real-world projects. Also, of course, don't forget to look at our great assortment of cloud courses.
Learn Databricks with DataCamp
Course
Course
Course
blog
Josep Ferrer
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Emiko Sano
Tutorial
Richie Cotton
