
Curso
Conceitos de Databricks
4 h
22K
O Databricks SQL é uma ferramenta avançada projetada para o gerenciamento e a análise de dados na plataforma Databricks Lakehouse. Essa plataforma integra engenharia de dados, ciência de dados e análise de negócios em uma experiência unificada. Portanto, o Databricks SQL é importante para os profissionais de dados que desejam otimizar seus fluxos de trabalho de dados, a execução de consultas e as tarefas de BI sem a complexidade do gerenciamento tradicional da infraestrutura.
Neste artigo, explorarei os componentes, os recursos e as ferramentas do Databricks SQL e mostrarei exemplos práticos de criação e uso do Databricks SQL warehouse. Para começar, recomendo que você faça o curso Introduction to Databricks da DataCamp para aprender sobre o Databricks como uma solução de armazenamento de dados para Business Intelligence (BI), aproveitando os recursos otimizados para SQL para criar consultas e analisar dados.
O Databricks SQL é uma ferramenta de análise robusta dentro da plataforma Databricks Lakehouse que permite que os profissionais de dados executem consultas SQL, analisem dados e criem painéis interativos. Projetado com uma arquitetura sem servidor, o Databricks SQL combina a flexibilidade dos data lakes com os recursos de governança e desempenho dos data warehouses.
Os principais componentes do Databricks SQL incluem SQL Warehouses, SQL Editors e SQL Dashboards. Não se preocupe se você não estiver familiarizado com cada uma delas, pois explicarei o significado de cada uma a seguir.
Os componentes principais do Databricks SQL facilitam a consulta eficiente, a visualização de dados e a colaboração entre os usuários. A seguir, você encontrará uma visão geral das principais ferramentas e recursos disponíveis no Databricks SQL.
Os SQL Warehouses servem como recursos computacionais para a execução de consultas SQL no Databricks SQL. Eles são projetados para lidar com cargas de trabalho variadas e oferecer otimizações de desempenho com base no tipo de depósito selecionado. Há três tipos principais de SQL Warehouses:
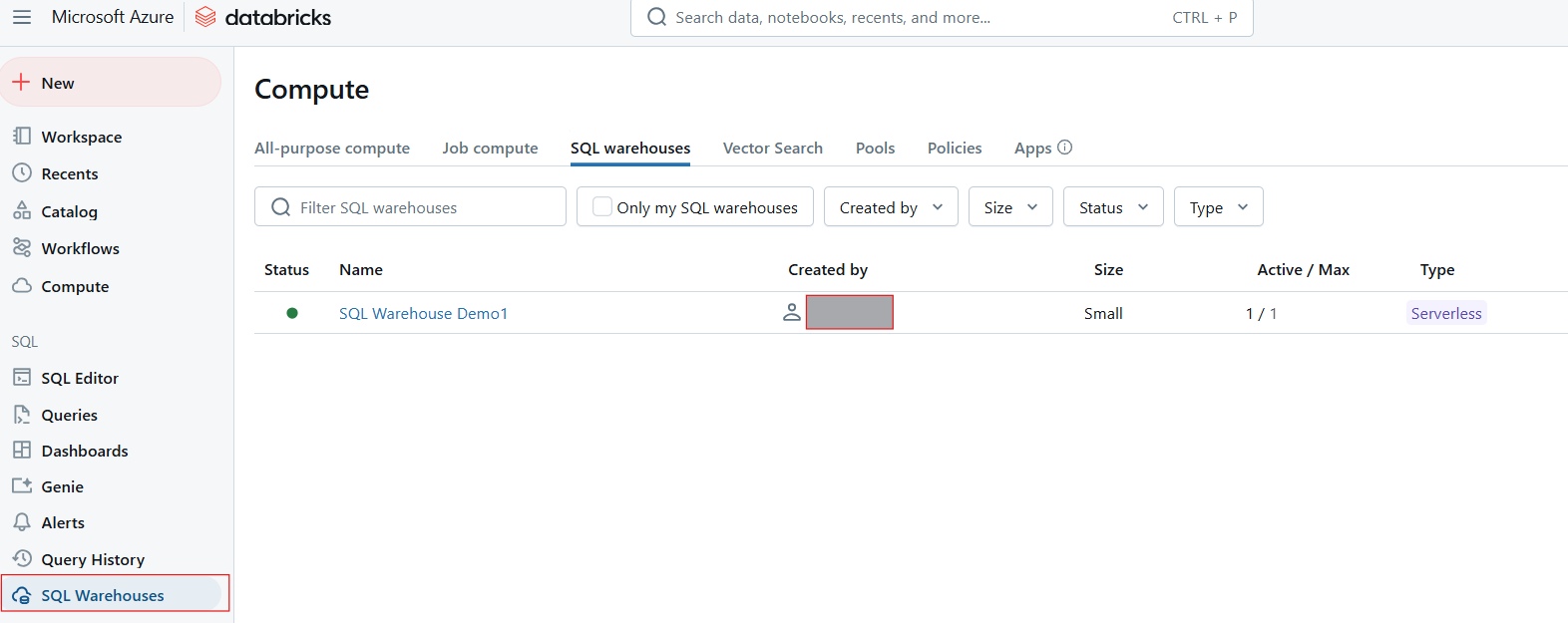
SQL Warehouse no Databricks SQL. Imagem do autor.
O SQL Editor é uma interface amigável que permite aos usuários escrever, executar e gerenciar consultas SQL. Os principais recursos do SQL Editor incluem:
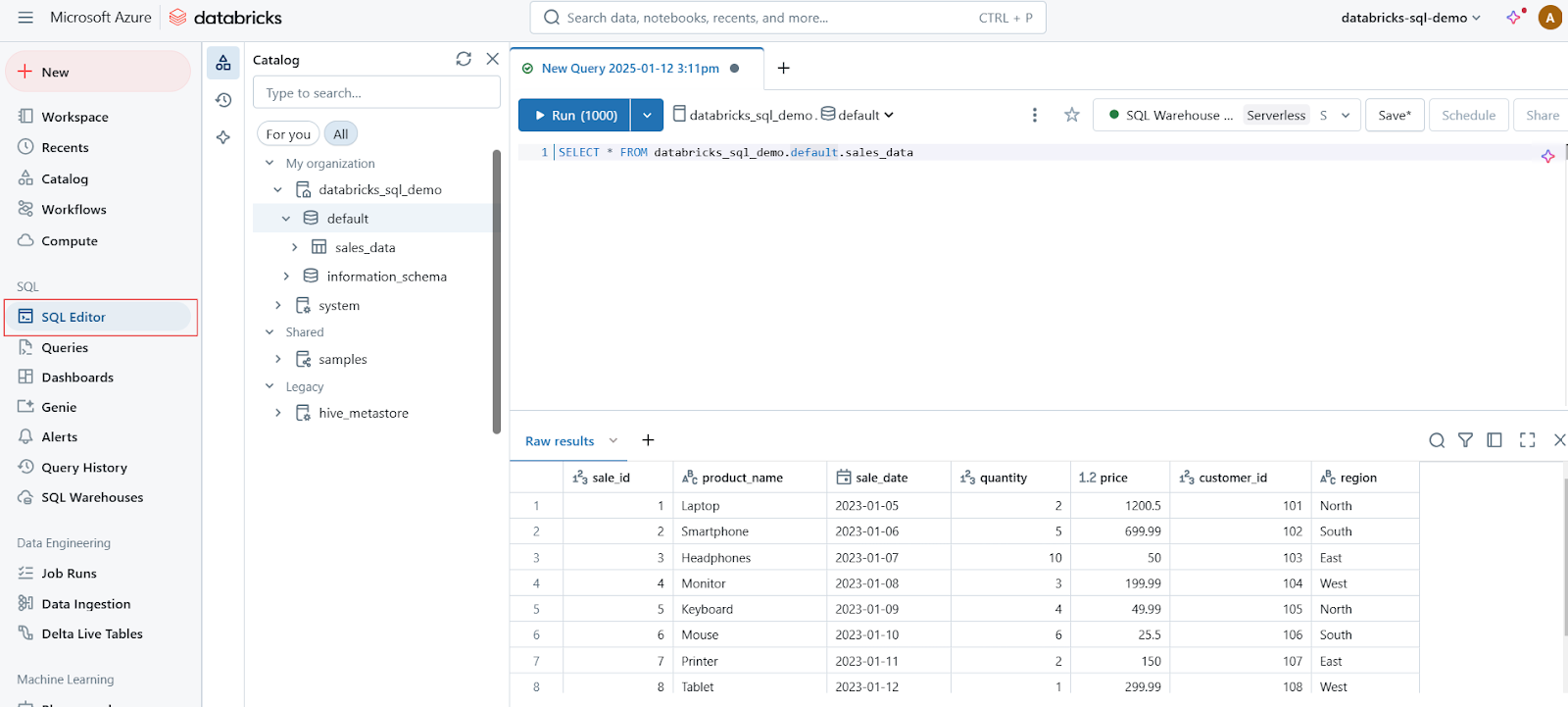
Editor SQL no Databricks SQL. Imagem do autor.
Os painéis permitem a visualização de dados, transformando os resultados da consulta em tabelas, gráficos e widgets interativos. Os painéis são ideais para monitorar as principais métricas e comunicar insights de forma eficaz em uma organização. Os principais recursos dos painéis incluem o seguinte:
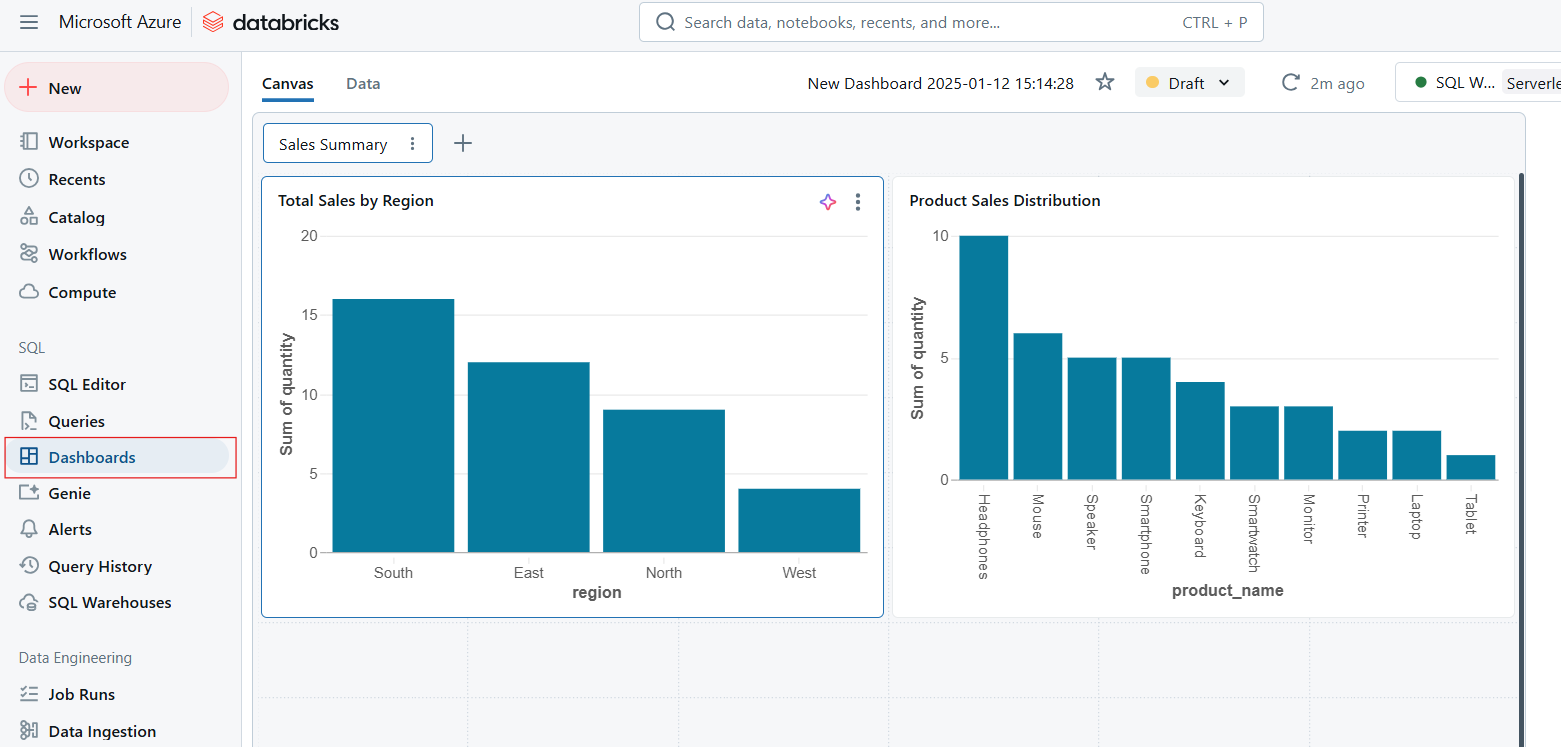
Dashboards no Databricks SQL. Imagem do autor.
Os alertas no Databricks SQL fornecem uma maneira de monitorar as alterações de dados e acionar notificações quando as condições especificadas são atendidas. Os alertas são essenciais para manter a qualidade dos dados e garantir respostas oportunas a mudanças importantes. A funcionalidade de alerta funciona da seguinte maneira.
Por fim, gostaria de dizer que o Databricks SQL oferece ferramentas para rastrear o histórico de consultas e a criação de perfis:
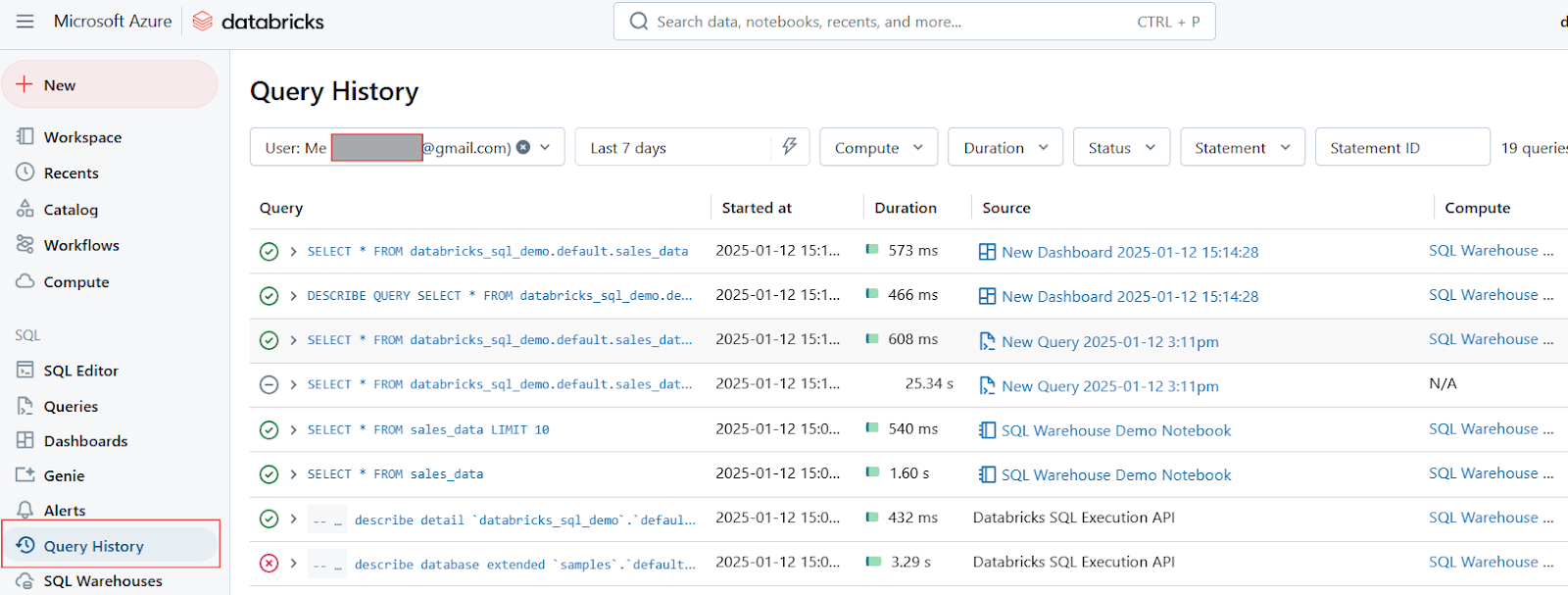
Histórico de consultas no Databricks SQL. Imagem do autor.
O Databricks SQL está repleto de recursos e ferramentas avançados. Esses recursos foram projetados para melhorar o desempenho, otimizar os fluxos de trabalho e permitir a integração perfeita com outras ferramentas. Vamos examinar alguns dos principais aspectos que fazem do Databricks SQL uma excelente opção.
O Photon Engine é um mecanismo de consulta vetorizada de alto desempenho desenvolvido pela Databricks para acelerar significativamente a execução de consultas SQL. Os principais benefícios do Photon Engine incluem o seguinte:
O CloudFetch e o Async I/O são recursos projetados para aumentar a velocidade de transferência de dados e melhorar o manuseio de arquivos pequenos durante a execução de consultas. Esses recursos funcionam das seguintes maneiras:
O Databricks SQL integra-se perfeitamente às ferramentas populares de Business Intelligence (BI), facilitando a análise e a visualização de dados pelas equipes. As integrações compatíveis incluem o seguinte:
A arquitetura sem servidor do Databricks SQL elimina a necessidade de gerenciamento manual da infraestrutura, provisionando e dimensionando automaticamente os recursos com base nas demandas de carga de trabalho. A arquitetura sem servidor ajustará automaticamente os recursos para lidar com cargas de consulta variáveis sem tempo de inatividade. Esse recurso garante que os usuários não precisem configurar ou manter os clusters manualmente. A arquitetura sem servidor também é econômica, pois os usuários pagam apenas pelos recursos usados durante a execução da consulta.
Por exemplo, uma empresa de varejo tem altas cargas de consulta durante o horário comercial de pico. A arquitetura sem servidor dimensiona automaticamente os recursos para garantir um desempenho consistente e reduz os recursos fora do horário comercial para economizar custos.
Os SQL Warehouses da Databricks são essenciais para que você possa executar consultas SQL com eficiência no ambiente da Databricks. Agora, nesta seção, orientarei você no processo de criação de um armazém SQL e seu uso com notebooks. Se você precisar atualizar seus conhecimentos sobre data warehouses, recomendo que faça nosso curso Conceitos de Data Warehousing para aprender os fundamentos da modelagem e transformação de dados.
Siga estas etapas para criar um SQL Warehouse usando a interface do usuário da Web do Databricks:
No espaço de trabalho do Databricks, clique no ícone SQL na barra lateral.
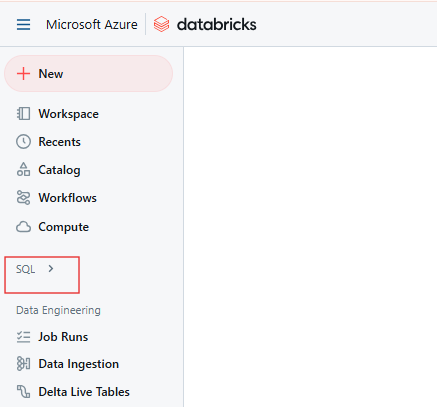
Página SQL do Databricks. Imagem do autor.
Na página SQL, navegue até a guia SQL Warehouses.
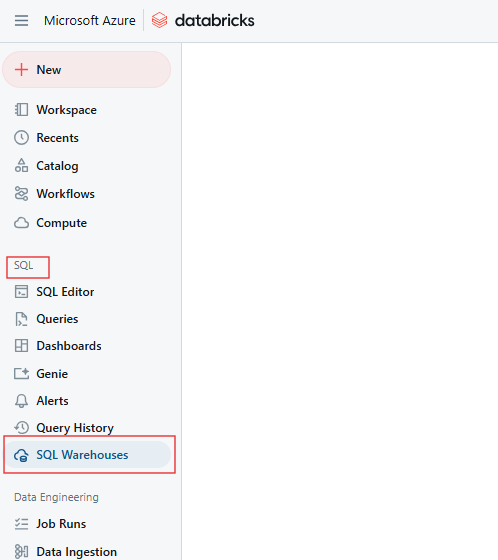
Guia Databricks SQL Warehouse. Imagem do autor.
Clique no botão Create Warehouse para começar a configurar seu novo SQL Warehouse.
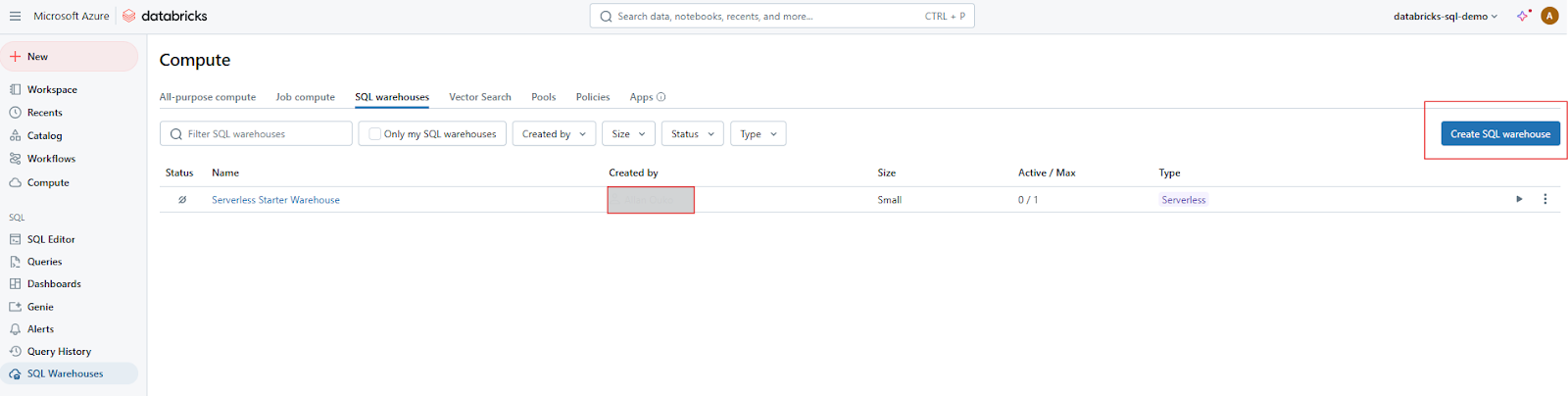
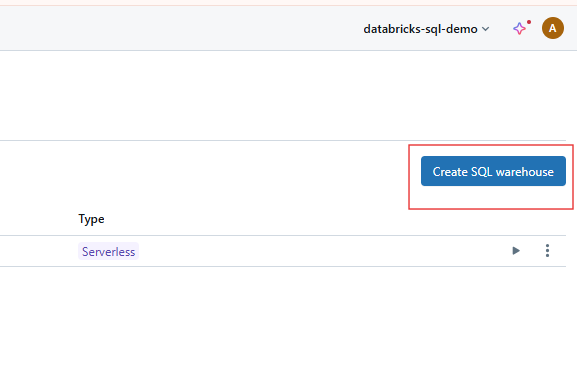
Criando o SQL Warehouse no Databricks SQL. Imagem do autor.
Defina as configurações do depósito usando as seguintes opções.
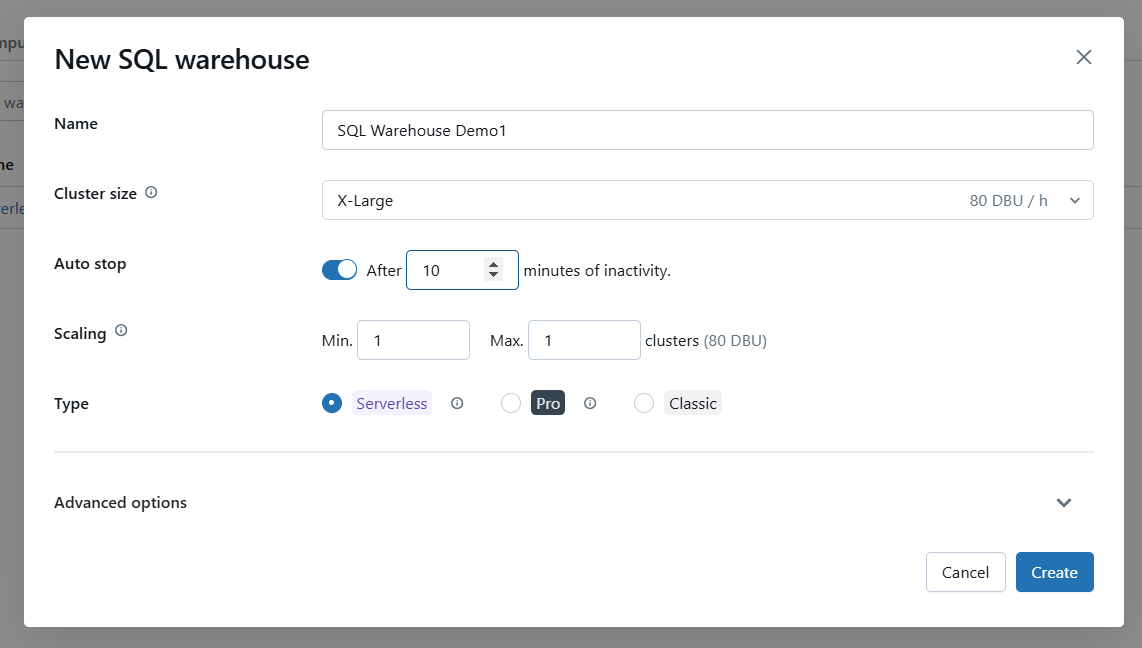
Defina as configurações básicas do Databricks SQL Warehouse. Imagem do autor.
Se necessário, configure opções avançadas, como ativar o Photon ou definir configurações específicas de SQL.
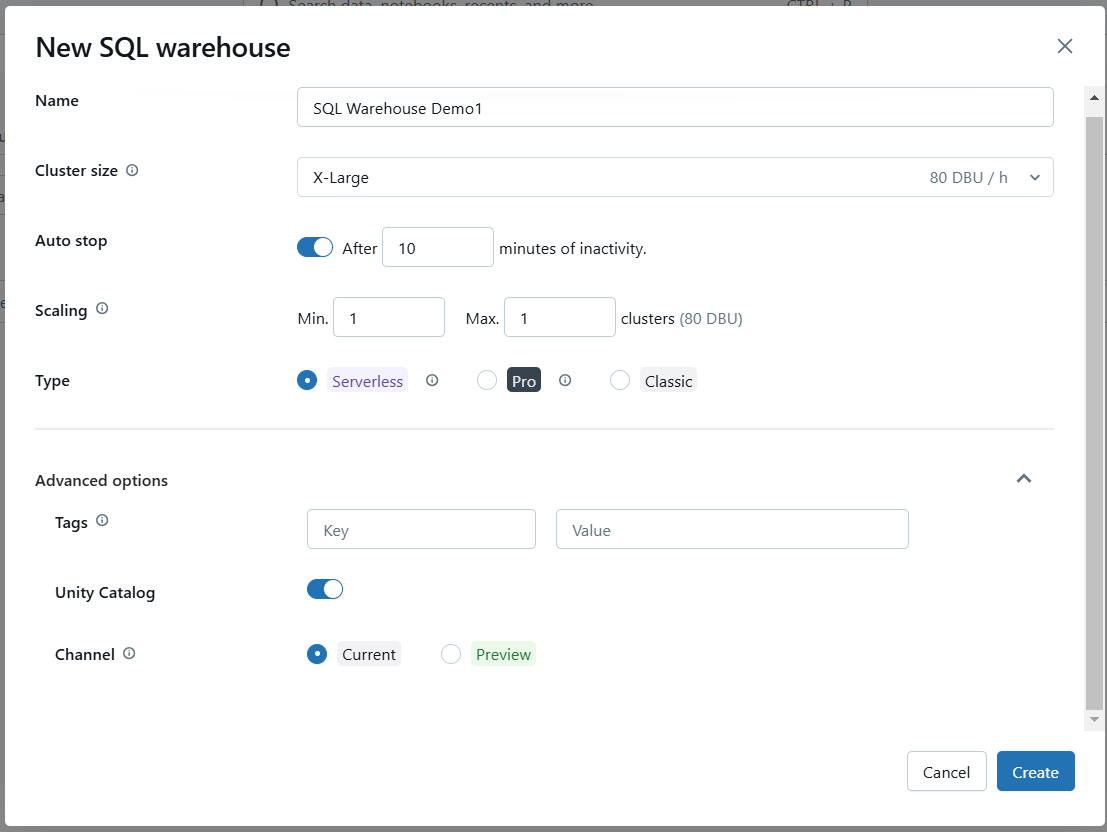
Defina as configurações avançadas do Databricks SQL Warehouse. Imagem do autor.
Clique em Create para salvar sua configuração. Depois de criado, inicie o depósito para torná-lo operacional.
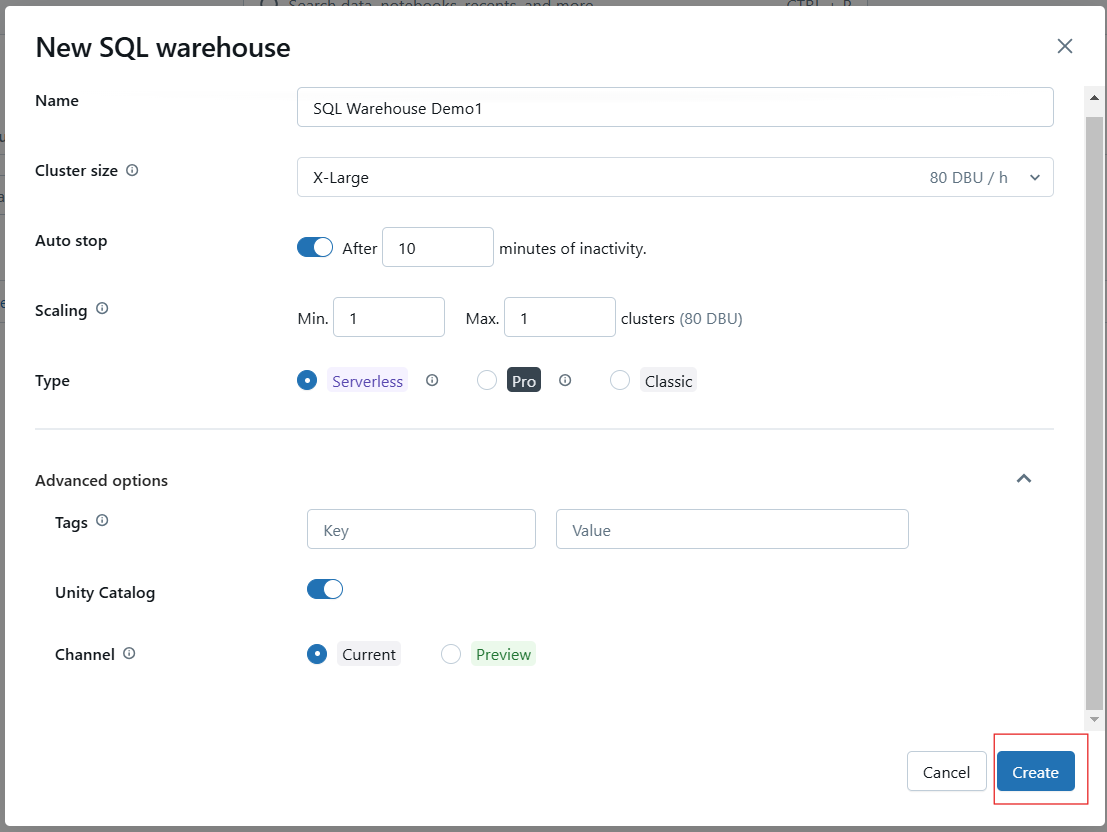
Criando o Databricks SQL Warehouse. Imagem do autor.
Após a criação, será exibido um modal de permissões no qual você pode conceder aos usuários ou grupos acesso ao depósito.
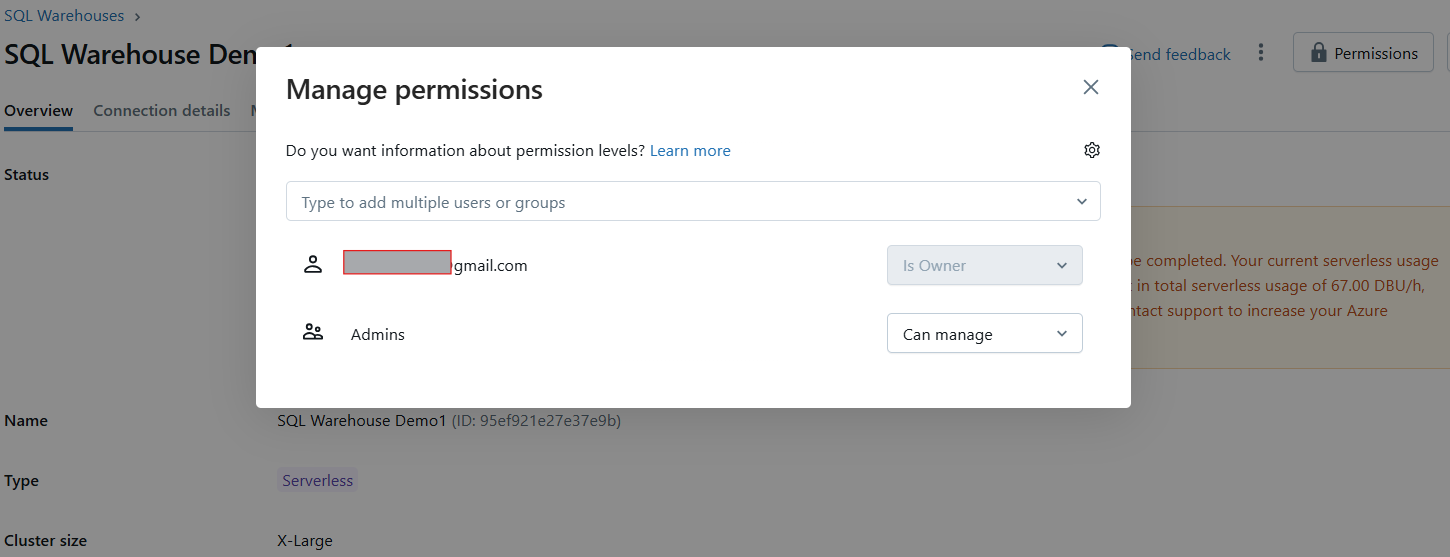
Gerenciar permissões do Databricks SQL Warehouse. Imagem do autor.
Depois de criado, o armazém SQL será iniciado automaticamente, permitindo que você execute consultas imediatamente.
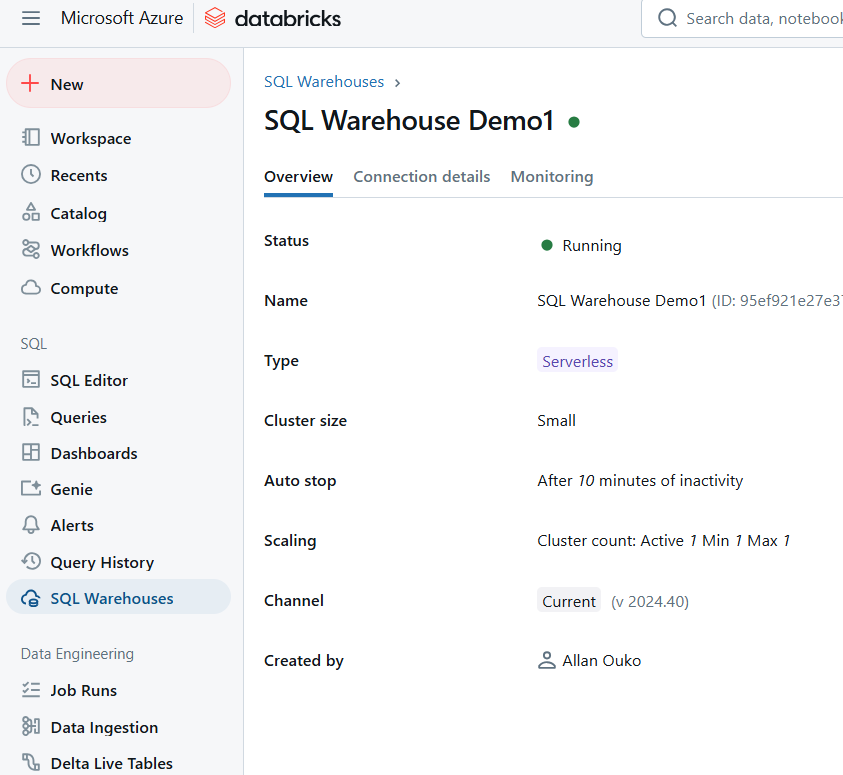
Exemplo de Databricks SQL Warehouse. Imagem do autor.
Para executar consultas SQL em um notebook usando o armazém SQL recém-criado, siga estas etapas:
No espaço de trabalho do Databricks, crie um novo notebook ou abra um já existente.
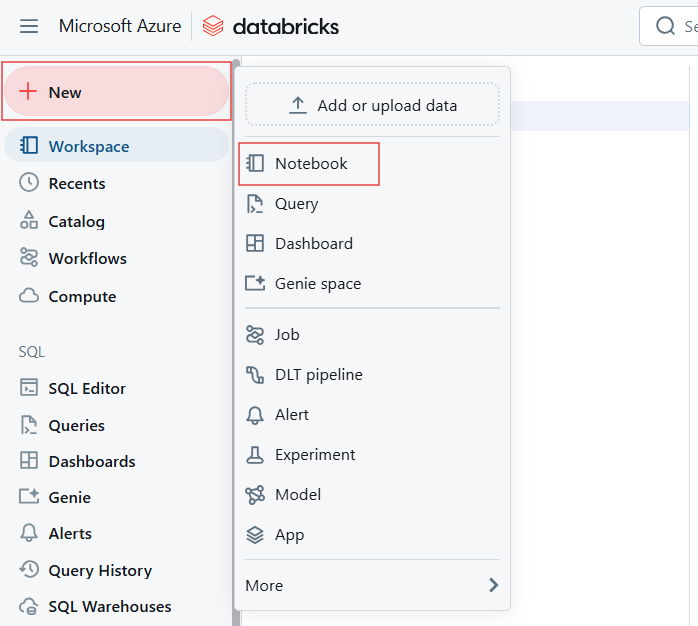
Criando um novo Notebook para criar o Databricks SQL Warehouse. Imagem do autor.
Na barra de ferramentas do Notebook, localize o seletor de computação ou conexão (geralmente exibido na parte superior). Clique nele para abrir um menu suspenso que mostra os recursos de computação disponíveis. Selecione seu depósito SQL na lista. Se não estiver visível, clique em More... (Mais... ) para visualizar todos os depósitos disponíveis. Clique no depósito SQL desejado e selecione Iniciar e anexar.
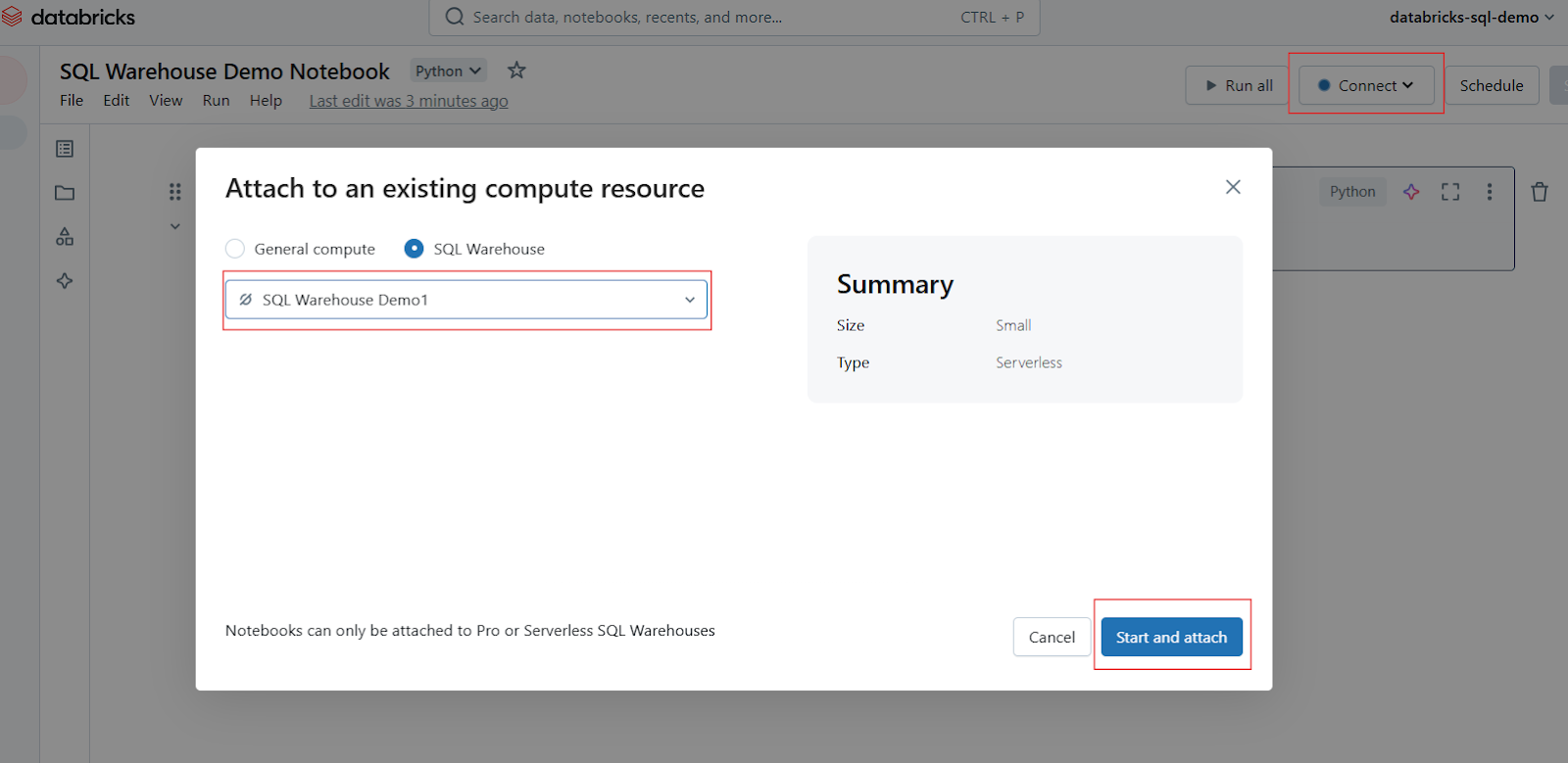
Anexe o Notebook no Databricks SQL Warehouse. Imagem do autor.
Uma vez anexado, você pode criar células em seu notebook para consultas SQL. Use o comando mágico %sql para executar consultas SQL no notebook.
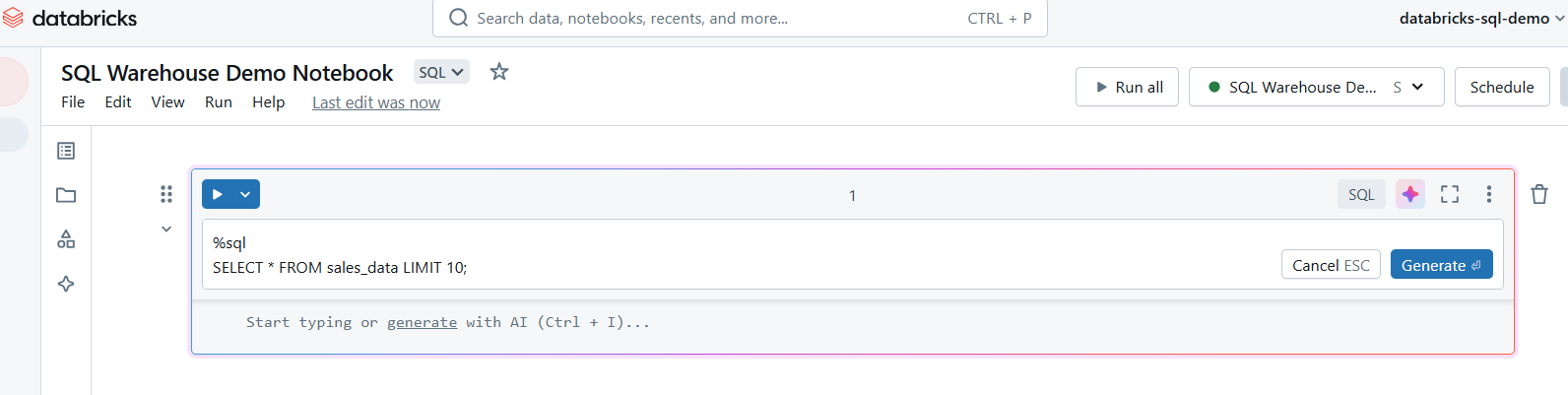
Escreva consultas SQL no Databricks SQL Warehouse. Imagem do autor.
Execute a célula para executar sua consulta. Os resultados serão exibidos diretamente abaixo da célula, facilitando a visualização dos dados.
Executar consultas SQL no Databricks SQL Warehouse. Imagem do autor.
A seguir, você encontrará algumas considerações ao usar notebooks com SQL Warehouses:
Limites de consulta: Os SQL Warehouses são otimizados para consultas analíticas, não para consultas transacionais frequentes e de baixa latência.
Visualização de dados: Para conjuntos de dados grandes, considere a possibilidade de limitar os resultados da consulta, como o uso da cláusula LIMIT para evitar gargalos de desempenho.
Cache de consulta: Aproveite o cache de resultados para acelerar as consultas repetidas.
Utilização de recursos: Monitore a utilização do SQL Warehouse para garantir que o tamanho do cluster e as configurações de dimensionamento atendam às suas necessidades de carga de trabalho.
O Databricks SQL é uma plataforma avançada que preenche a lacuna entre os data lakes e os data warehouses, fornecendo uma solução unificada para análise de dados e business intelligence modernos. Quer você esteja criando painéis, otimizando consultas ou monitorando dados com alertas, o Databricks SQL oferece a flexibilidade e o desempenho necessários para lidar com os desafios de dados atuais. Incentivo você a explorar os recursos e as funcionalidades do Databricks SQL para aprimorar seus fluxos de trabalho de dados, capacitar a colaboração e promover uma tomada de decisão mais inteligente e rápida.
Se você estiver interessado em se tornar um engenheiro de dados profissional, recomendo enfaticamente que faça o curso Understanding Data Engineering da DatacMap para saber como os engenheiros de dados armazenam e processam dados para facilitar a colaboração com os cientistas de dados. Também recomendo que você faça nosso curso Data-Driven Decision-Making in SQL para aprender a usar o SQL para apoiar a tomada de decisões usando projetos do mundo real. Além disso, é claro, não se esqueça de dar uma olhada em nossa grande variedade de cursos sobre nuvem.
Aprenda Databricks com o DataCamp
Curso
Curso
Curso
blog
Matt Crabtree
8 min
Tutorial
Sejal Jaiswal
Tutorial
Abid Ali Awan
Tutorial
Eugenia Anello
Tutorial
Natassha Selvaraj