
Cours
Concepts Databricks
4 h
22K
Databricks SQL est un outil puissant conçu pour la gestion des données et l'analyse au sein de la plateforme Databricks Lakehouse. Cette plateforme intègre l'ingénierie des données, la science des données et l'analyse commerciale dans une expérience unifiée. Databricks SQL est donc important pour les professionnels des données qui cherchent à rationaliser leurs flux de données, l'exécution des requêtes et les tâches de BI sans la complexité de la gestion traditionnelle de l'infrastructure.
Dans cet article, je vais explorer les composants, les fonctionnalités et les outils de Databricks SQL et montrer des exemples pratiques de création et d'utilisation de l'entrepôt Databricks SQL. Pour commencer, je vous recommande vivement de suivre le cours Introduction à Databricks de DataCamp pour découvrir Databricks en tant que solution d'entreposage de données pour la Business Intelligence (BI), en tirant parti des capacités optimisées de SQL pour créer des requêtes et analyser des données.
Databricks SQL est un outil d'analyse robuste au sein de la plateforme Databricks Lakehouse qui permet aux professionnels des données d'exécuter des requêtes SQL, d'analyser des données et de créer des tableaux de bord interactifs. Conçu avec une architecture sans serveur, Databricks SQL combine la flexibilité des lacs de données avec les capacités de gouvernance et de performance des entrepôts de données.
Les composants clés de Databricks SQL comprennent les entrepôts SQL, les éditeurs SQL et les tableaux de bord SQL. Ne vous inquiétez pas si vous n'êtes pas familier avec chacun d'entre eux, car je vais en expliquer la signification ci-dessous.
Les composants de base de Databricks SQL facilitent l'interrogation efficace, la visualisation des données et la collaboration entre les utilisateurs. Vous trouverez ci-dessous un aperçu des principaux outils et fonctionnalités disponibles dans Databricks SQL.
Les entrepôts SQL servent de ressources informatiques pour l'exécution des requêtes SQL dans Databricks SQL. Ils sont conçus pour gérer des charges de travail variables et pour optimiser les performances en fonction du type d'entrepôt sélectionné. Il existe trois types principaux d'entrepôts SQL :
SQL Warehouse dans Databricks SQL. Image par l'auteur.
L'éditeur SQL est une interface conviviale qui permet aux utilisateurs d'écrire, d'exécuter et de gérer des requêtes SQL. Les principales caractéristiques de l'éditeur SQL sont les suivantes
Éditeur SQL dans Databricks SQL. Image par l'auteur.
Les tableaux de bord permettent de visualiser les données en transformant les résultats des requêtes en diagrammes, graphiques et widgets interactifs. Les tableaux de bord sont idéaux pour surveiller les paramètres clés et communiquer efficacement les informations au sein d'une organisation. Les principales fonctionnalités des tableaux de bord sont les suivantes :
Tableaux de bord dans Databricks SQL. Image par l'auteur.
Les alertes dans Databricks SQL permettent de surveiller les changements de données et de déclencher des notifications lorsque des conditions spécifiques sont remplies. Les alertes sont essentielles pour maintenir la qualité des données et garantir des réponses opportunes aux changements importants. La fonctionnalité d'alerte fonctionne de la manière suivante.
Enfin, je tiens à dire que Databricks SQL offre des outils de suivi de l'historique des requêtes et de profilage :
Historique des requêtes dans Databricks SQL. Image par l'auteur.
Databricks SQL est doté de fonctionnalités et d'outils avancés. Ces fonctionnalités sont conçues pour améliorer les performances, rationaliser les flux de travail et permettre une intégration transparente avec d'autres outils. Examinons quelques-uns des éléments clés qui font de Databricks SQL un excellent choix.
Photon Engine est un moteur de requêtes vectorisé de haute performance développé par Databricks pour accélérer de manière significative l'exécution des requêtes SQL. Les principaux avantages du moteur Photon sont les suivants :
CloudFetch et Async I/O sont des fonctionnalités conçues pour améliorer les vitesses de transfert des données et le traitement des petits fichiers pendant l'exécution des requêtes. Ces fonctionnalités fonctionnent de la manière suivante :
Databricks SQL s'intègre de manière transparente aux outils de Business Intelligence (BI) les plus répandus, ce qui facilite l'analyse et la visualisation des données par les équipes. Les intégrations prises en charge sont les suivantes :
L'architecture sans serveur de Databricks SQL élimine le besoin d'une gestion manuelle de l'infrastructure en provisionnant et en mettant à l'échelle automatiquement les ressources en fonction des demandes de charge de travail. L'architecture sans serveur ajustera automatiquement les ressources pour gérer des charges de requêtes variables sans temps d'arrêt. Cette fonction permet aux utilisateurs de ne pas avoir à configurer ou à maintenir manuellement les grappes. L'architecture sans serveur est également rentable, car les utilisateurs ne paient que pour les ressources utilisées lors de l'exécution des requêtes.
Par exemple, une entreprise de vente au détail est confrontée à un nombre élevé de requêtes pendant les heures de pointe. L'architecture sans serveur augmente automatiquement les ressources pour garantir des performances constantes et les réduit pendant les heures creuses pour économiser des coûts.
Les entrepôts SQL de Databricks sont essentiels à l'exécution efficace des requêtes SQL dans l'environnement Databricks. Dans cette section, je vais vous guider à travers le processus de création d'un entrepôt SQL et de son utilisation avec des carnets de notes. Si vous avez besoin de rafraîchir vos connaissances sur les entrepôts de données, je vous recommande de suivre notre cours Concepts d'entreposage de données pour apprendre les principes fondamentaux de la modélisation et de la transformation des données.
Suivez les étapes suivantes pour créer un SQL Warehouse à l'aide de l'interface web Databricks :
Dans l'espace de travail Databricks, cliquez sur l'icône SQL dans la barre latérale.
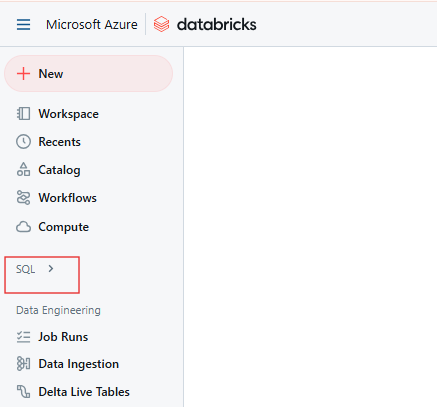
Page SQL de Databricks. Image par l'auteur.
Sur la page SQL, naviguez jusqu'à l'onglet Entrepôts SQL.
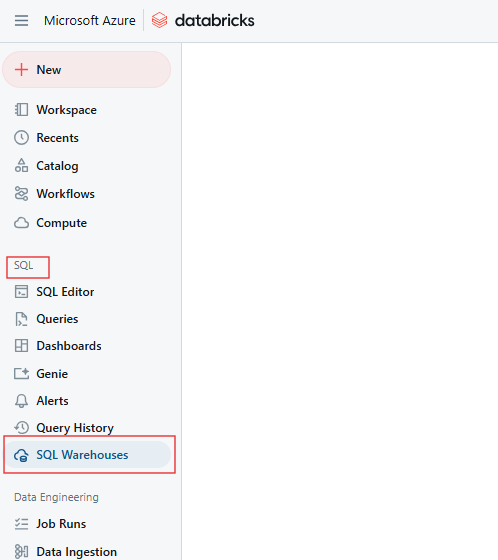
Onglet Databricks SQL Warehouse. Image par l'auteur.
Cliquez sur le bouton Créer un entrepôt pour commencer à configurer votre nouvel entrepôt SQL.
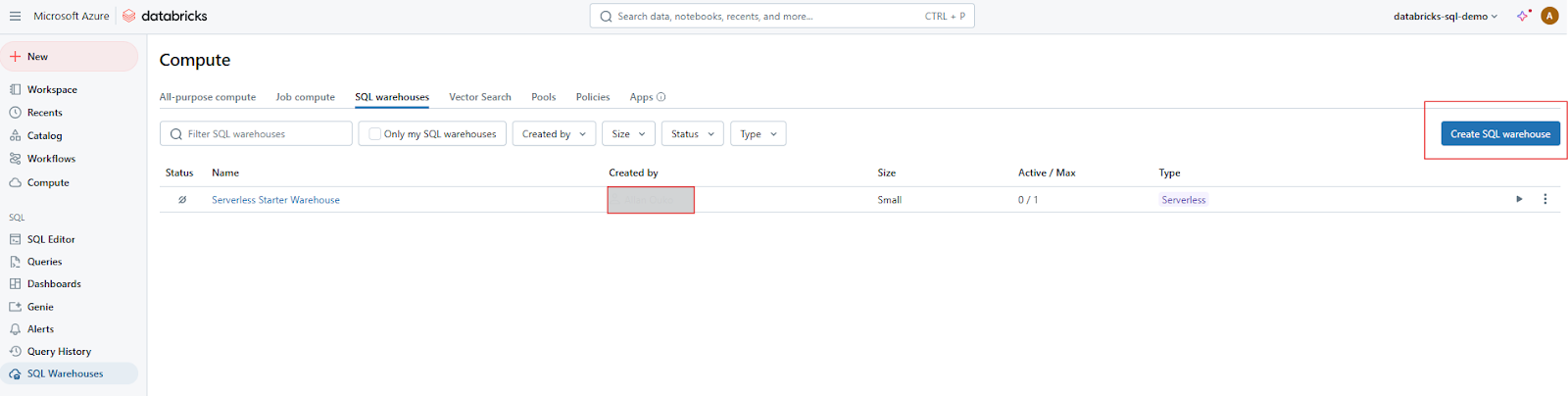
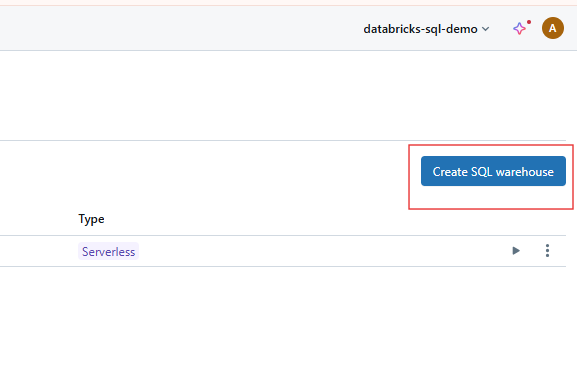
Création de SQL Warehouse sur Databricks SQL. Image par l'auteur.
Configurez les paramètres de l'entrepôt à l'aide des options suivantes.
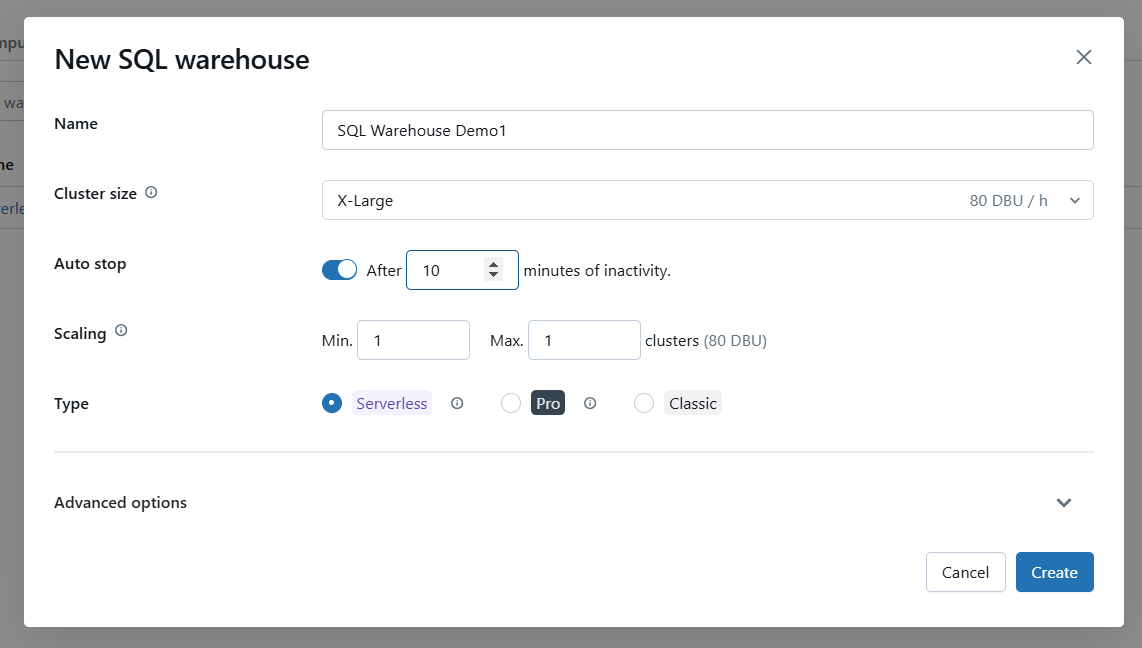
Configurez les paramètres de base de Databricks SQL Warehouse. Image par l'auteur.
Si nécessaire, configurez les options avancées telles que l'activation de Photon ou la définition de configurations SQL spécifiques.
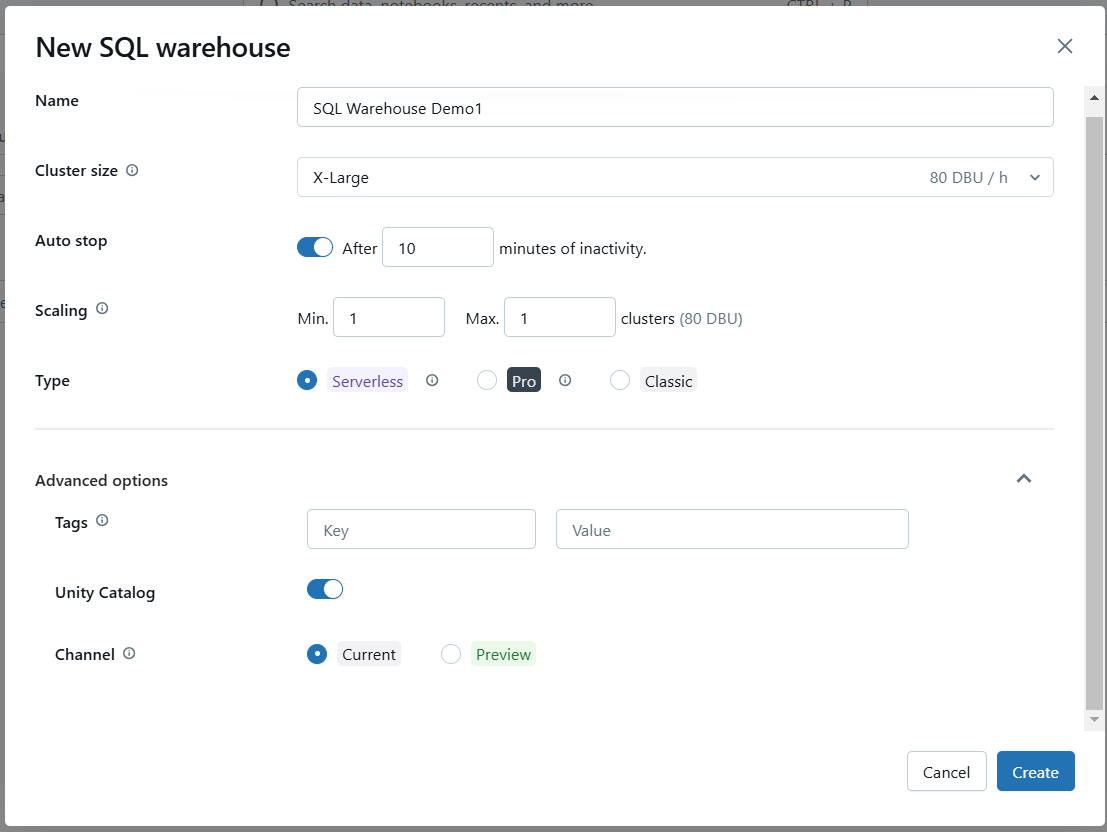
Configurez les paramètres avancés pour Databricks SQL Warehouse. Image par l'auteur.
Cliquez sur Créer pour enregistrer votre configuration. Une fois créé, démarrez l'entrepôt pour le rendre opérationnel.
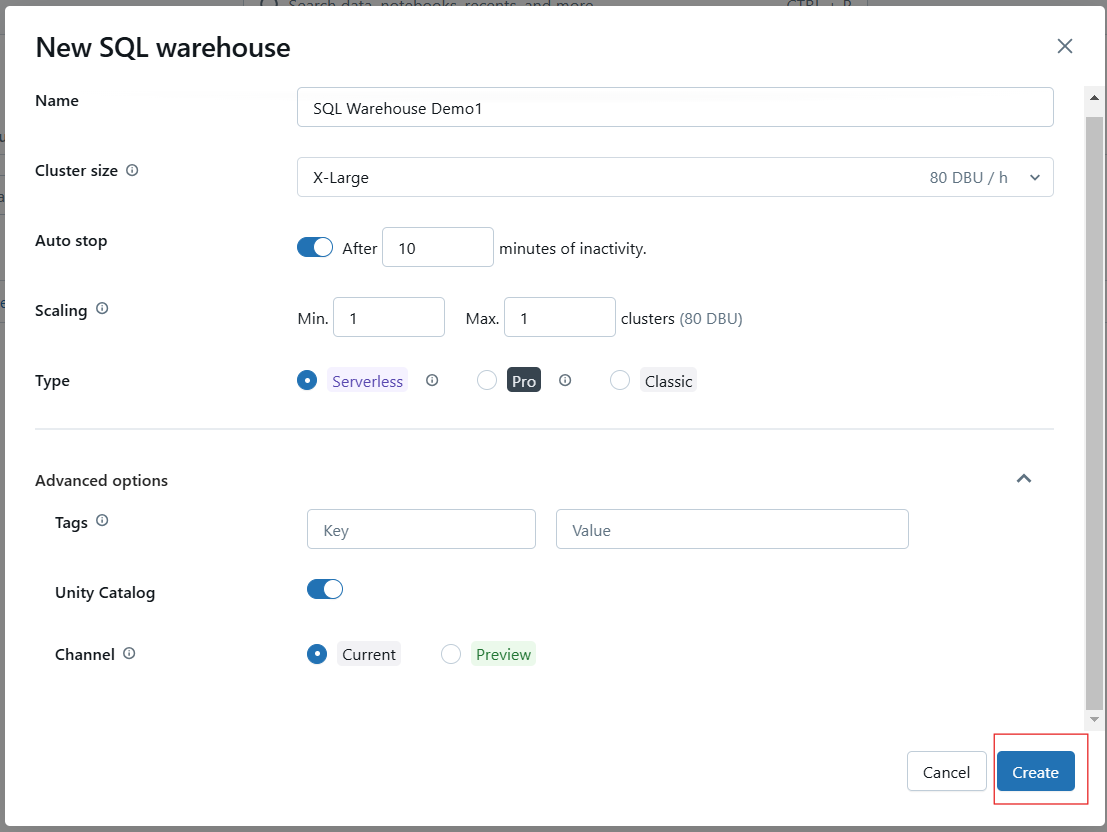
Création de l'entrepôt SQL de Databricks. Image par l'auteur.
Après la création, une fenêtre d'autorisation s'affiche, dans laquelle vous pouvez accorder l'accès à l'entrepôt à des utilisateurs ou à des groupes.
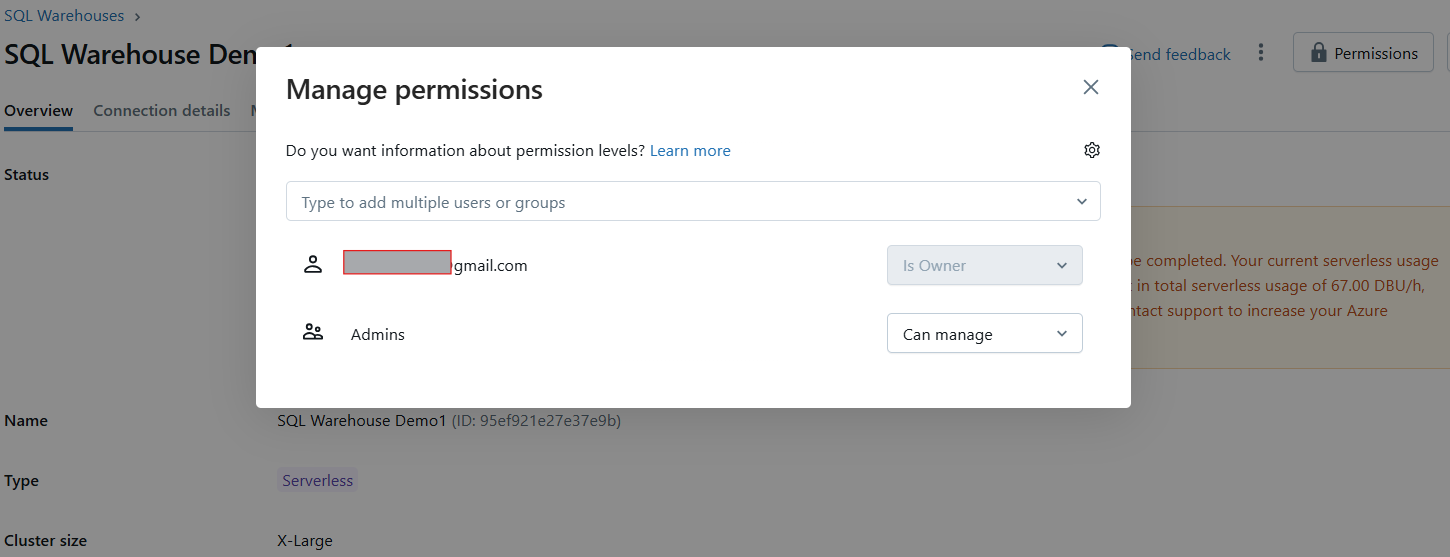
Gestion des autorisations de Databricks SQL Warehouse. Image par l'auteur.
Une fois créé, votre entrepôt SQL démarre automatiquement, ce qui vous permet d'exécuter des requêtes immédiatement.
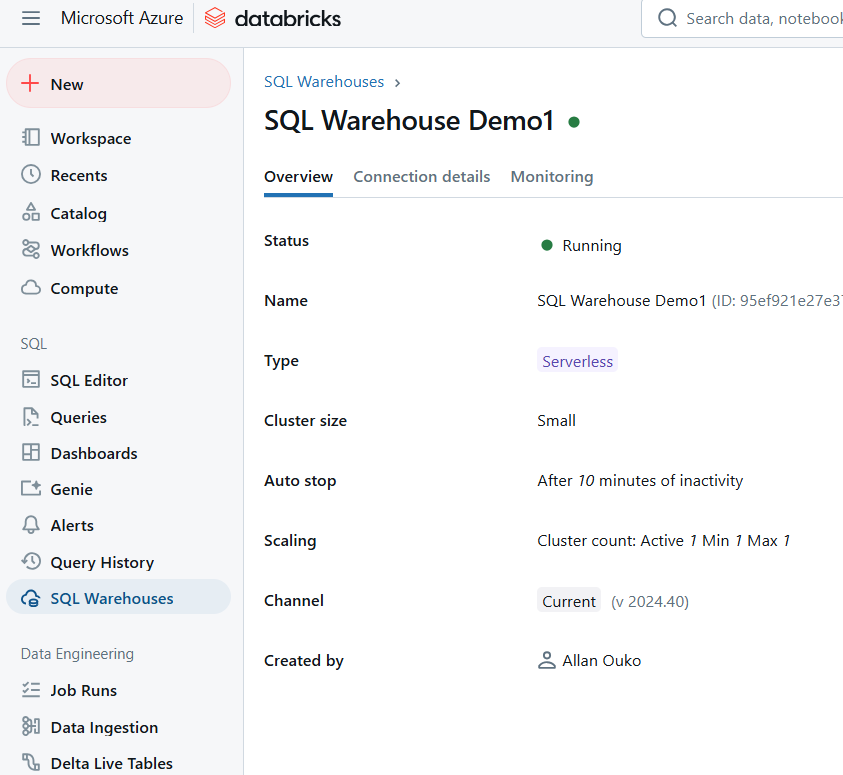
Exemple de Databricks SQL Warehouse. Image par l'auteur.
Pour exécuter des requêtes SQL dans un bloc-notes à l'aide de votre entrepôt SQL nouvellement créé, procédez comme suit :
Dans l'espace de travail Databricks, créez un nouveau carnet ou ouvrez un carnet existant.
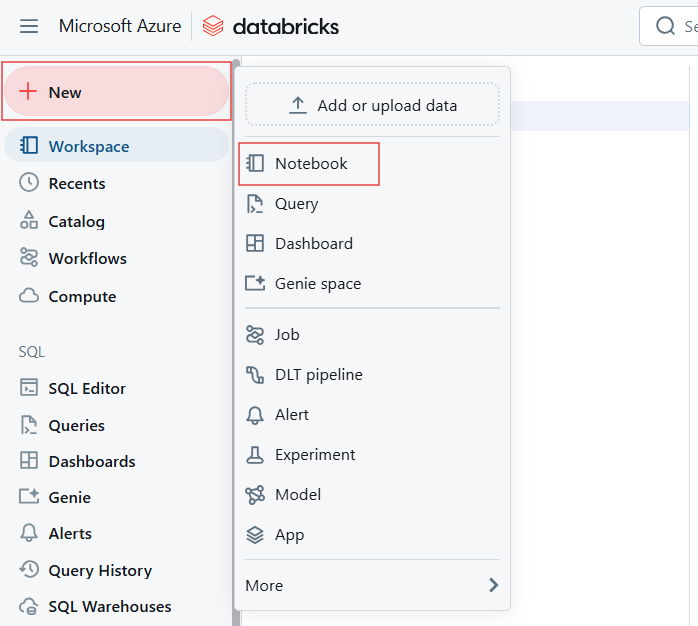
Création d'un nouveau Notebook pour créer Databricks SQL Warehouse. Image par l'auteur.
Dans la barre d'outils du bloc-notes, localisez le sélecteur de calcul ou la connexion (généralement affichée en haut). Cliquez dessus pour ouvrir un menu déroulant affichant les ressources informatiques disponibles. Sélectionnez votre entrepôt SQL dans la liste. S'il n'est pas visible, cliquez sur Plus... pour afficher tous les entrepôts disponibles. Cliquez sur l'entrepôt SQL souhaité, puis sélectionnez Démarrer et attacher.
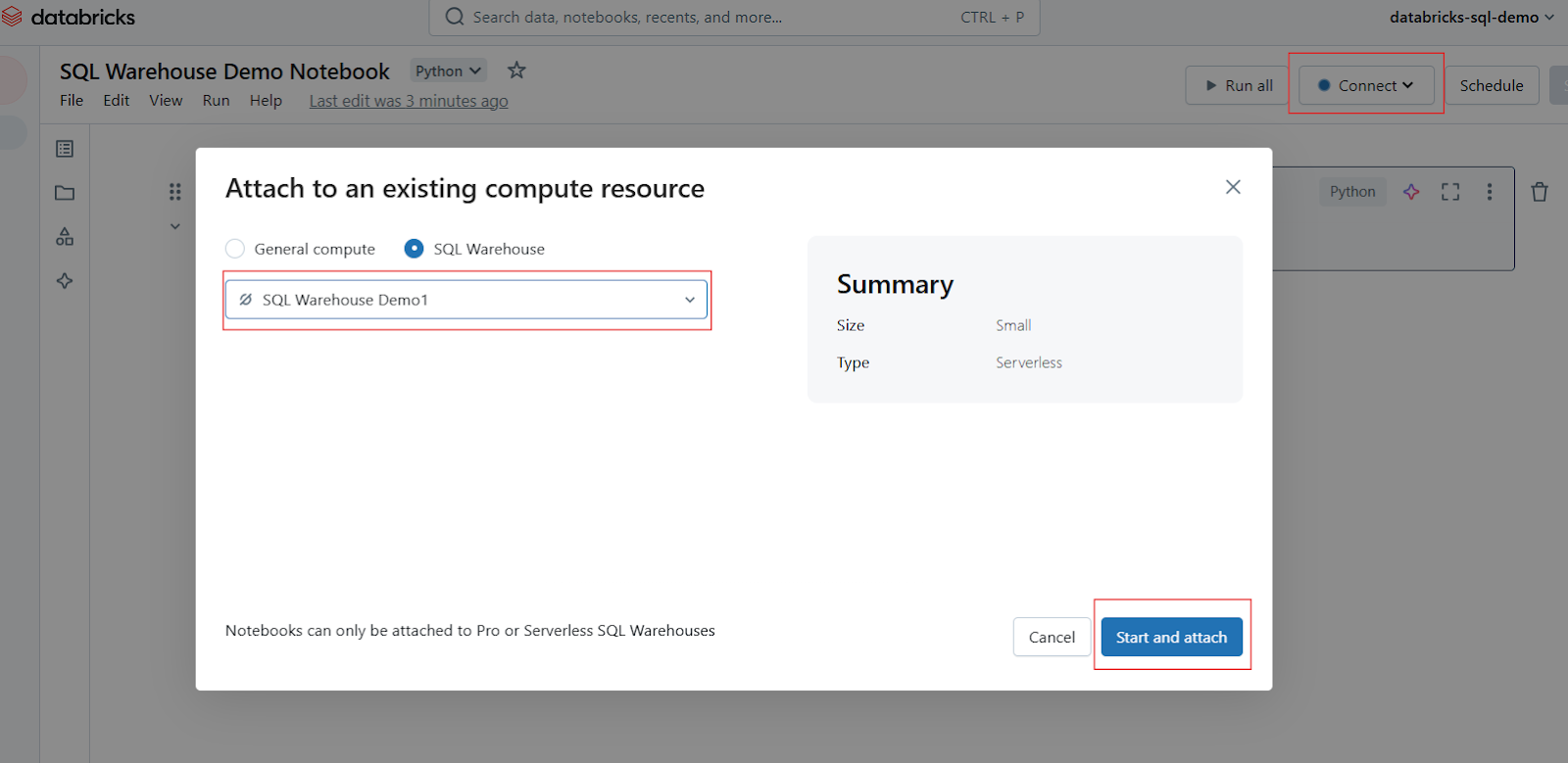
Attachez le carnet de notes dans Databricks SQL Warehouse. Image par l'auteur.
Une fois attaché, vous pouvez créer des cellules dans votre carnet pour les requêtes SQL. Utilisez la commande %sql magic pour exécuter des requêtes SQL dans le carnet.
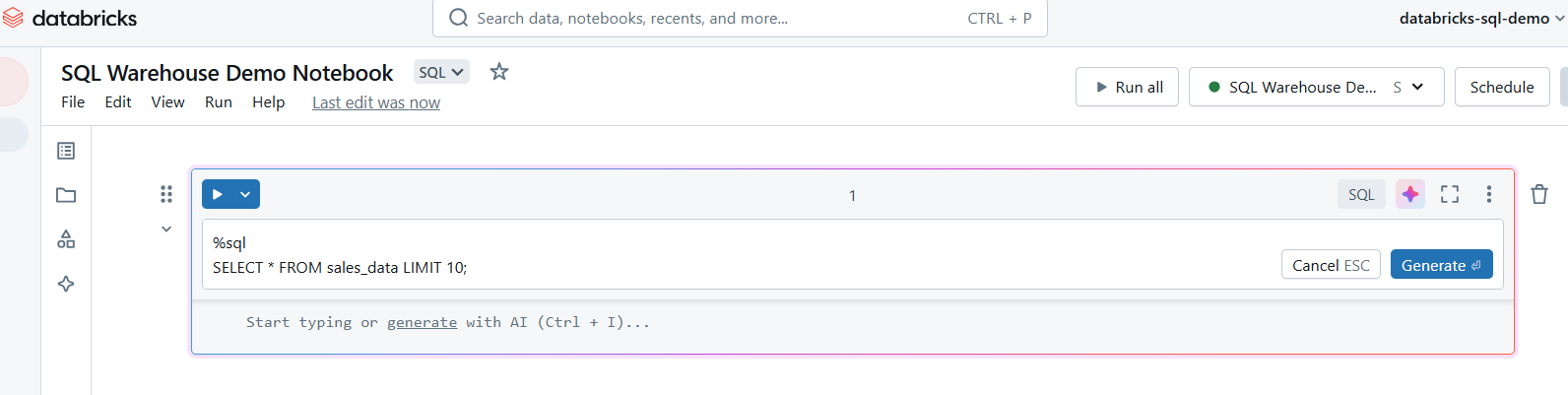
Écrire des requêtes SQL dans Databricks SQL Warehouse. Image par l'auteur.
Lancez la cellule pour exécuter votre requête. Les résultats s'affichent directement sous la cellule, ce qui facilite la prévisualisation des données.
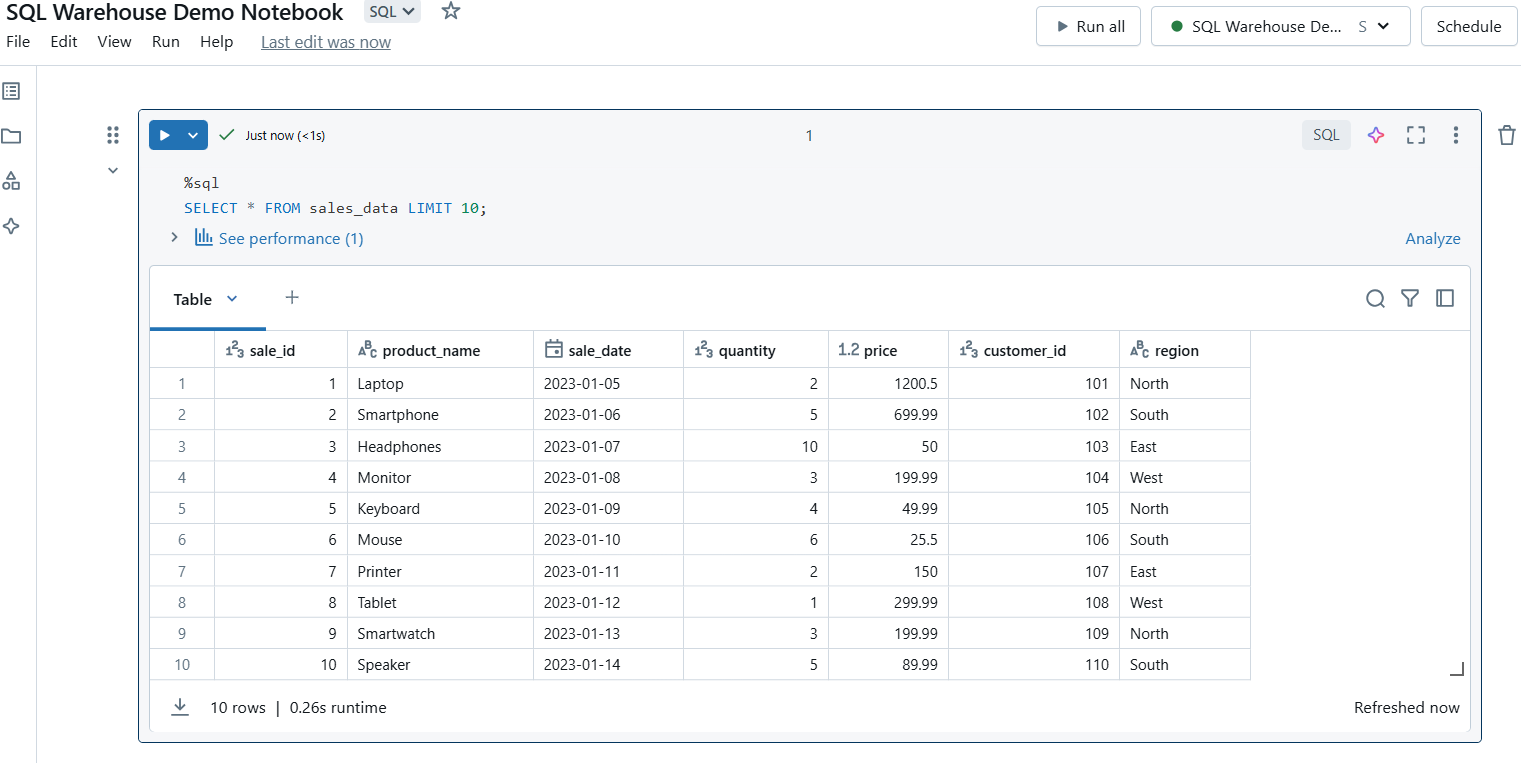
Exécutez des requêtes SQL dans Databricks SQL Warehouse. Image par l'auteur.
Voici quelques considérations à prendre en compte lors de l'utilisation d'ordinateurs portables avec des entrepôts SQL :
Limites de l'interrogation : Les entrepôts SQL sont optimisés pour les requêtes analytiques, et non pour les requêtes transactionnelles fréquentes et à faible latence.
Aperçu des données : Pour les grands ensembles de données, envisagez de limiter les résultats de votre requête, en utilisant par exemple la clause LIMIT pour éviter les goulets d'étranglement.
Mise en cache des requêtes : Tirez parti de la mise en cache des résultats pour accélérer les requêtes répétées.
Utilisation des ressources : Surveillez l'utilisation de SQL Warehouse pour vous assurer que la taille du cluster et les paramètres de mise à l'échelle répondent aux besoins de votre charge de travail.
Databricks SQL est une plateforme puissante qui comble le fossé entre les lacs de données et les entrepôts de données, en fournissant une solution unifiée pour l'analyse moderne des données et l'intelligence économique. Que vous construisiez des tableaux de bord, que vous optimisiez vos requêtes ou que vous surveilliez vos données à l'aide d'alertes, Databricks SQL offre la flexibilité et les performances nécessaires pour relever les défis actuels en matière de données. Je vous encourage à explorer les fonctionnalités et les capacités de Databricks SQL pour améliorer vos flux de données, renforcer la collaboration et favoriser une prise de décision plus intelligente et plus rapide.
Si vous souhaitez devenir un ingénieur de données professionnel, je vous recommande vivement de suivre le cours Understanding Data Engineering de DatacMap pour apprendre comment les ingénieurs de données stockent et traitent les données afin de faciliter la collaboration avec les scientifiques de données. Je vous recommande également de suivre notre cours Data-Driven Decision-Making in SQL pour apprendre à utiliser SQL pour soutenir la prise de décision à l'aide de projets réels. N'oubliez pas non plus de consulter notre vaste assortiment de cours sur le cloud.
Apprenez Databricks avec DataCamp
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach