Curso
Introducción a la ingeniería de datos
4 h
127.6K
Mantener un servidor físico o virtual no es tarea fácil, ya sea por los elevados costes de mantenimiento o por la necesidad de mano de obra cualificada. La computación sin servidor resuelve estos problemas proporcionando una forma económica de permitir a los desarrolladores crear y ejecutar aplicaciones en la nube.
En este artículo, repasaremos la computación sin servidor, sus aplicaciones y sus ventajas para desarrolladores y empresas. Se trata de un tema importante porque el tamaño del mercado de la informática sin servidor superó los 9 millones de dólares en 2022 y se prevé que crezca otro 25% en los próximos diez años. Vayamos al grano.
Digamos que la luz y el agua que utilizas en tu casa se cobran en función de tu consumo, en lugar de una cuota mensual fija estimada. Así funciona la informática sin servidor: No es más que una forma en que los proveedores de la nube asignan su infraestructura para que puedas crear y ejecutar tus aplicaciones en función del uso, sin preocuparte del mantenimiento de los servidores.
A diferencia de la computación en nube tradicional, en la que se instala un servidor físico o virtualizado, almacenamiento y equipos de red, en la computación sin servidor, el proveedor de la nube gestiona la infraestructura y te asigna recursos automáticamente a medida que tu aplicación escala. En otras palabras, la computación sin servidor es la abstracción del servidor por parte de los desarrolladores, lo que les permite centrarse más en las aplicaciones que están creando en lugar de preocuparse por la infraestructura en la que se aloja la aplicación.
Imagina que estás acostumbrado a tener entre 100 y 200 usuarios diarios en tu aplicación. Si al día siguiente tus usuarios aumentan repentinamente a 1.000.000, el servidor escalará automáticamente sus recursos para satisfacer esa demanda. Esto no es factible con la computación en nube tradicional, ya que los servidores experimentarán tiempos de inactividad debido al aumento del tráfico, y si el servidor tiene poco almacenamiento, hay que comprar un almacenamiento mayor, lo que lleva tiempo.
| Categoría | Computación sin servidor | Informática tradicional |
|---|---|---|
| Escalado | Dinámico | Fijo |
| Facturación | Según el uso | Los costes corrientes, independientemente del uso, también incluyen los costes de mantenimiento y funcionamiento |
| Gestión de infraestructuras | Abstraído de las empresas | Requiere una gestión activa |
Antes de examinar las características clave que distinguen la computación sin servidor de otros modelos tradicionales de nube, veamos las terminologías clave en la computación sin servidor.
La ejecución dirigida por eventos también se conoce como función como servicio (FAAS), en la que la aplicación sin servidor se divide en funciones independientes sin servidor activadas por eventos específicos de fuentes como peticiones HTTP, cambios en una base de datos, consultas de mensajes o cargas de archivos.
Supón que tienes una aplicación sin servidor que procesa automáticamente imágenes cada vez que se suben a un bucket de Amazon S3. Cuando un usuario sube un archivo de imagen, se activa una función para procesar la imagen y guardarla en otro bucket de Amazon S3. Esto garantiza que la función se ejecute sólo cuando sea necesario, haciendo que el sistema sea eficiente y rentable.
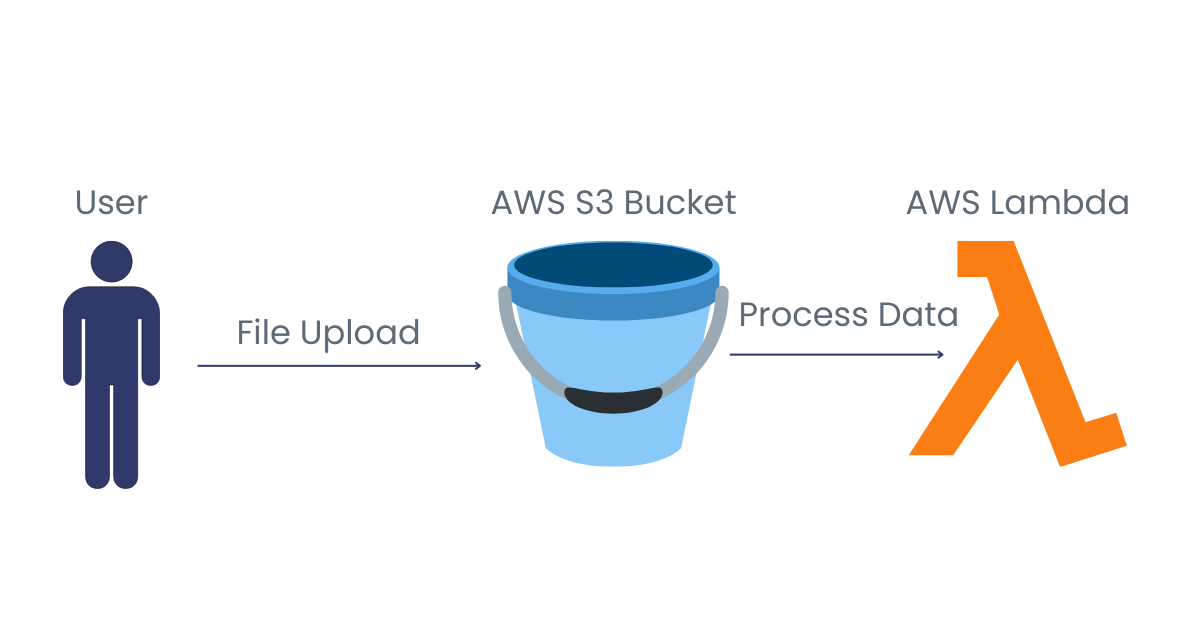
Ejecución basada en eventos, utilizando como ejemplo la carga de archivos. Imagen del autor
Autoescalado es la asignación de recursos informáticos en función de la demanda o del aumento de las cargas de trabajo. Es una característica clave de la computación sin servidor que la hace eficiente y adaptable, garantizando que no se desperdicien recursos si no hay mucha carga de trabajo o demanda en el servidor, y que no se experimente tiempo de inactividad cuando el servidor experimenta una gran demanda.
Por ejemplo, tu aplicación recibe un pico de tráfico. En lugar de experimentar tiempos de inactividad en tu servidor debido al elevado tráfico, la plataforma proporciona automáticamente instancias adicionales para gestionar el aumento de la carga de trabajo. Asimismo, la plataforma reduce los recursos para minimizar los costes cuando el tráfico es bajo. Esto garantiza la eficacia sin intervención manual, haciendo que la aplicación sea rentable y tenga capacidad de respuesta en diversos escenarios.
Las plataformas sin servidor cobran a los usuarios en función de los recursos utilizados y no de los recursos asignados. A diferencia de los modelos de nube tradicionales, en los que puede que no utilices todos los recursos asignados, en las plataformas sin servidor sólo pagas por el tiempo de computación utilizado. Los costes también se miden, lo que significa que pagas por invocación o duración de la ejecución de la función, garantizando que se te facturen exactamente los recursos que utilizas.
Si, por ejemplo, tu aplicación procesa 100 imágenes de usuarios en un mes determinado, en lugar de pagar por el uso 24/7 del servidor, pagas sólo por el tiempo de cálculo utilizado para las 100 imágenes procesadas.
Esta es también una característica clave de la computación sin servidor, en la que los desarrolladores y las empresas no tienen que preocuparse de aprovisionar, escalar y mantener los servidores. Esto les permite centrarse en los problemas centrales del negocio y dejar el mantenimiento del servidor a los proveedores de la nube.
Las plataformas sin servidor pueden ejecutar múltiples funciones simultáneamente. Esto lo hace rápido y eficaz en comparación con los enfoques tradicionales. Si los usuarios quieren subir imágenes a su plataforma y el proveedor sin servidor proporciona un límite de concurrencia por defecto de 100, entonces cualquier petición que supere el límite de concurrencia se pone en cola y se ejecuta en la siguiente ejecución de la función.
A diferencia de la computación en nube tradicional, que requiere servidores dedicados e incurre en costes siempre que el servidor está inactivo, las plataformas sin servidor utilizan un modelo basado en eventos para cobrar a los desarrolladores. Una analogía útil es utilizar un servicio de taxi en lugar de tener un coche. Con un taxi no tienes que preocuparte de los gastos que conlleva, como el aparcamiento, el combustible, etc., pues sólo pagas por la distancia que recorres. En la computación sin servidor, al igual que en el taxi, sólo pagas por los recursos informáticos que utilizas. A diferencia del enfoque tradicional (poseer un coche), eres responsable de cada recurso informático que utilizas, incluso cuando el sistema está inactivo.
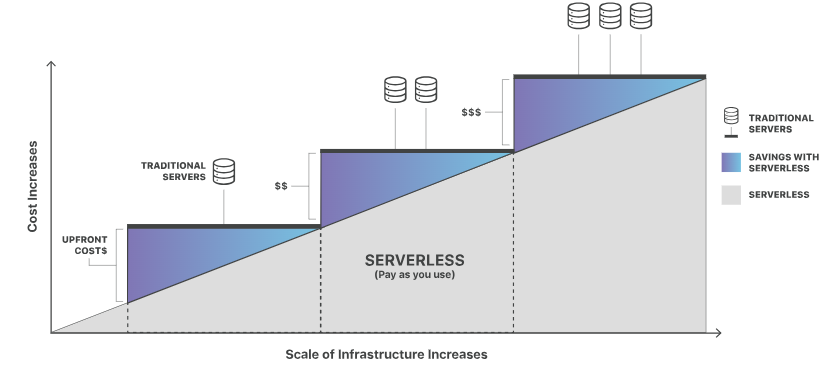
Comparación de rentabilidad entre tipos de servidores. Fuente: Cloudflare
Se ahorra mucho tiempo en la computación sin servidor porque los desarrolladores no necesitan dedicar su tiempo a instalar y mantener servidores; se centran más en construir la aplicación. Dado que las aplicaciones se construyen como funciones independientes en la nube, se puede actualizar una función sin alterar las demás o toda la aplicación.
Esta es una de las ventajas más importantes de una plataforma sin servidor y la razón por la que es popular entre las organizaciones más pequeñas y las startups. Las plataformas sin servidor facilitan a los desarrolladores escalar sus operaciones automáticamente cuando aumenta la demanda. Para las funciones que experimentan fluctuaciones en las peticiones, las plataformas sin servidor escalan para satisfacerlas aumentando o disminuyendo la asignación de recursos, garantizando así la optimización de los recursos informáticos.
Con las aplicaciones sin servidor, puedes lanzar aplicaciones rápidamente y obtener de inmediato los comentarios de los usuarios. Esto es importante para las startups, ya que reduce el tiempo invertido y la mano de obra necesaria para crear aplicaciones.
A diferencia de las aplicaciones alojadas en servidores dedicados, se pueden ejecutar aplicaciones sin servidor desde cualquier lugar. Esto mejora el rendimiento de las aplicaciones y reduce la latencia en comparación con la computación en nube tradicional.
La arquitectura sin servidor es una forma de construir aplicaciones sin instalar ni gestionar la infraestructura que aloja la aplicación. Los desarrolladores pueden crear aplicaciones sin servidor utilizando cualquiera de los dos modelos sin servidor: Backend as a Service (BaaS) o Function as a Service (FaaS).
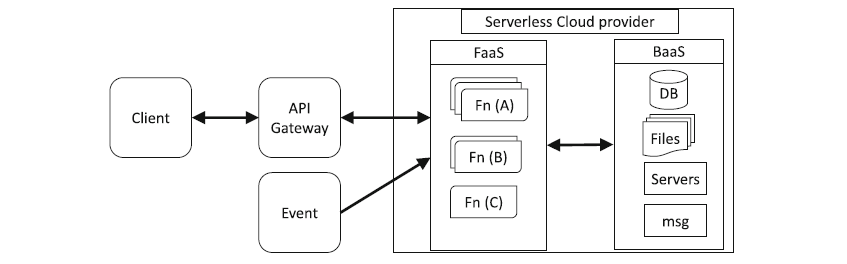
Arquitecturas de nube sin servidor FAAS y BAAS. Fuente: Revista de Computación en la Nube
El principal objetivo de la arquitectura sin servidor es abstraer la gestión del servidor de los desarrolladores. Aquí tienes un desglose de cómo funcionan las plataformas sin servidor en su infraestructura.
Cabe preguntarse: ¿No es la arquitectura sin servidor lo mismo que la arquitectura de contenedores, ya que ambas abstraen el servidor de los desarrolladores? Esto es cierto, pero a diferencia de las funciones sin servidor, que abstraen completamente el servidor al construir y enviar aplicaciones en contenedores, cuando una aplicación experimenta un tráfico elevado, es necesario escalar los contenedores utilizando herramientas como Kubernetes. Esto contradice el objetivo de FaaS, donde todas las acciones relacionadas con el servidor son gestionadas automáticamente por la plataforma sin servidor.
En una arquitectura de contenedor, puedes tener instancias de contenedor que pueden ejecutarse durante un largo periodo, lo que puede generar costes, a diferencia de las funciones sin servidor, en las que se factura por el tiempo que tu función pasa ejecutándose. Para aplicaciones más pequeñas, utilizar una arquitectura sin servidor facilita su desacoplamiento en partes que las plataformas sin servidor pueden ejecutar como funciones independientes.
Antes de la llegada de Google App Engine en 2008, Zimki ofrecía la primera plataforma de "pago por uso" para la ejecución de código, pero más tarde se cerró. En su fase inicial, Google App Engine sólo admitía Python y ofrecía facturación por contador para aplicaciones, entre las que se encontraba SnapChat. Hacia 2010, otra plataforma llamada PiCloud también ofrecía soporte FaaS para aplicaciones Python.
En 2014, AWS popularizó el modelo sin servidor lanzando herramientas como AWS Serverless Application Model (AWS SAM) y Amazon CloudWatch. Google lanzó entonces su segunda oferta sin servidor, Google Cloud functions, junto con Azure functions, en 2016. Desde entonces se han lanzado varias plataformas sin servidor, como Function Compute de Ali Baba Cloud e IBM Cloud Functions de IBM Cloud.
Para eliminar la necesidad de una base de datos virtualizada o física, también se han desarrollado bases de datos sin servidor. AWS ofrece Amazon Aurora, una versión sin servidor basada en MySQL y PostgreSQL. Azure ofrece Azure Data Lake, y Google proporciona Firestore.

Plataformas en la nube sin servidor. Fuente: Entrevista en red
La computación sin servidor se utiliza para crear aplicaciones web y API REST. Lo interesante es que las aplicaciones se construyen utilizando una infraestructura sin servidor autoescalable en función de las demandas de los usuarios, lo que mejora su experiencia.
La arquitectura sin servidor facilita el procesamiento de los medios. Los usuarios pueden cargar contenido multimedia desde distintos dispositivos y tamaños, y la plataforma procesa una única función que satisface la demanda de cada usuario sin reducir el rendimiento de la aplicación. Por ejemplo, un usuario puede subir una imagen a través de un bucket de S3 que activa una función de AWS Lambda para añadir una marca de agua o una miniatura a la imagen.
Los desarrolladores pueden implementar un chatbot para responder a las preguntas de los clientes utilizando una arquitectura sin servidor y pagar sólo por los recursos que utilice el Chatbot. Por ejemplo, Slack utiliza una arquitectura sin servidor para gestionar las solicitudes variables de los bots, con el fin de evitar la infrautilización del ancho de banda debido a la fluctuación diaria de las necesidades de los clientes.
Puedes utilizar una plataforma sin servidor para interactuar con los proveedores de SaaS a través de un punto final HTTP webhook, que recibe notificaciones y realiza tareas. Esto ofrece un mantenimiento mínimo, bajos costes y escalado automático para el webhook incorporado.
Coca-Cola utiliza arquitecturas sin servidor en su máquina expendedora Freestyle para permitir a los clientes pedir, pagar y recibir notificaciones de pago por sus bebidas. Coca-Cola afirmó que gastaba unos 13.000 $/año en el funcionamiento de sus máquinas expendedoras, cantidad que se redujo a 4.500 $/año tras implantar arquitecturas sin servidor en las máquinas expendedoras.
Major League Baseball Advanced Media construyó su producto Statcast con arquitectura sin servidor para proporcionar a los usuarios métricas deportivas precisas y en tiempo real. Utiliza la informática sin servidor para procesar datos y ofrecer a los usuarios información sobre los partidos de béisbol.
La arquitectura sin servidor se utiliza para aplicaciones basadas en eventos, de forma que cuando un evento o un estado cambia, activa un servicio. Se pueden utilizar plataformas sin servidor para vigilar los cambios en una base de datos y compararlos con las normas de calidad.
Debido al viaje de larga distancia de los datos, las aplicaciones tardan en procesar las peticiones y entregar el contenido desde los servidores centralizados, lo que introduce problemas de latencia y cuellos de botella.
La computación de borde sin servidor resuelve este problema distribuyendo los recursos informáticos a múltiples ubicaciones para reducir la carga de trabajo del servidor central. La computación de borde sin servidor es la ubicación de recursos informáticos que ejecutan funciones sin servidor más cerca de los usuarios finales (borde). Esto permite que la aplicación sin servidor funcione en más dispositivos, disminuya la congestión y reduzca la latencia.
En la computación de borde sin servidor, la infraestructura se dedica a cada dispositivo, permitiéndole realizar tareas complejas sin enviar los datos de vuelta a la ubicación central para su procesamiento. He aquí algunos casos de uso que optimizan la experiencia del usuario utilizando funciones edge sin servidor:
A pesar de las ventajas que aporta la computación sin servidor, se enfrenta a algunos de los siguientes inconvenientes.
Para las empresas interesadas en crear aplicaciones ligeras, la computación sin servidor es el camino a seguir. Para aplicaciones compuestas por un gran número de servicios con interacciones complejas, se recomienda una infraestructura híbrida formada por máquinas virtuales para grandes procesos; en este caso, los contenedores sin servidor se utilizan sólo para tareas cortas. También se pueden considerar las funciones de borde sin servidor porque minimizan la latencia procesando los datos localmente sin poner mucha carga de trabajo en el servidor central.
Ten en cuenta que aún se están realizando diversos avances y desarrollos para ampliar las capacidades de la informática sin servidor. Por ejemplo, se puede utilizar un enfoque multi-nube para construir aplicaciones sin servidor, donde se puede construir una aplicación sin servidor utilizando servicios de más de un proveedor de nubes. También se han realizado más desarrollos para garantizar el arranque en frío cero de las funciones sin servidor, como se implementa en Cloudflare Workers.
Gracias por sintonizarnos. Para saber más sobre la computación sin servidor y desarrollar tus habilidades en este campo, consulta los siguientes recursos de DataCamp:
Para una lectura más breve, consulta nuestra entrada de blog con ideas de proyectos para todos los niveles de habilidad.
Aprende con DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
11 min
blog
Kurtis Pykes
10 min
blog
Kurtis Pykes
6 min
Tutorial
Abid Ali Awan

