
Curso
Diseño de sistemas agénticos con LangChain
3 h
12.1K
DeepSeek V3.2 Speciale es un modelo de razonamiento de alta computación optimizado para flujos de trabajo complejos y aumentados con herramientas. En lugar de limitarse a responder preguntas directamente, está diseñado para planificar, razonar y coordinar herramientas para crear sistemas de análisis agenticos.
En este tutorial, utilizaremos DeepSeek V3.2 Speciale para crear un agente de análisis de datos con IA que se sitúa encima de cualquier CSV. El flujo es el siguiente:
Al final, tendrás una aplicación Streamlit con planes explícitos y pasos de análisis reproducibles. Si deseas obtener más información sobre los agentes de IA, te recomiendo que consultes el programa de habilidades Fundamentos de los agentes de IA.
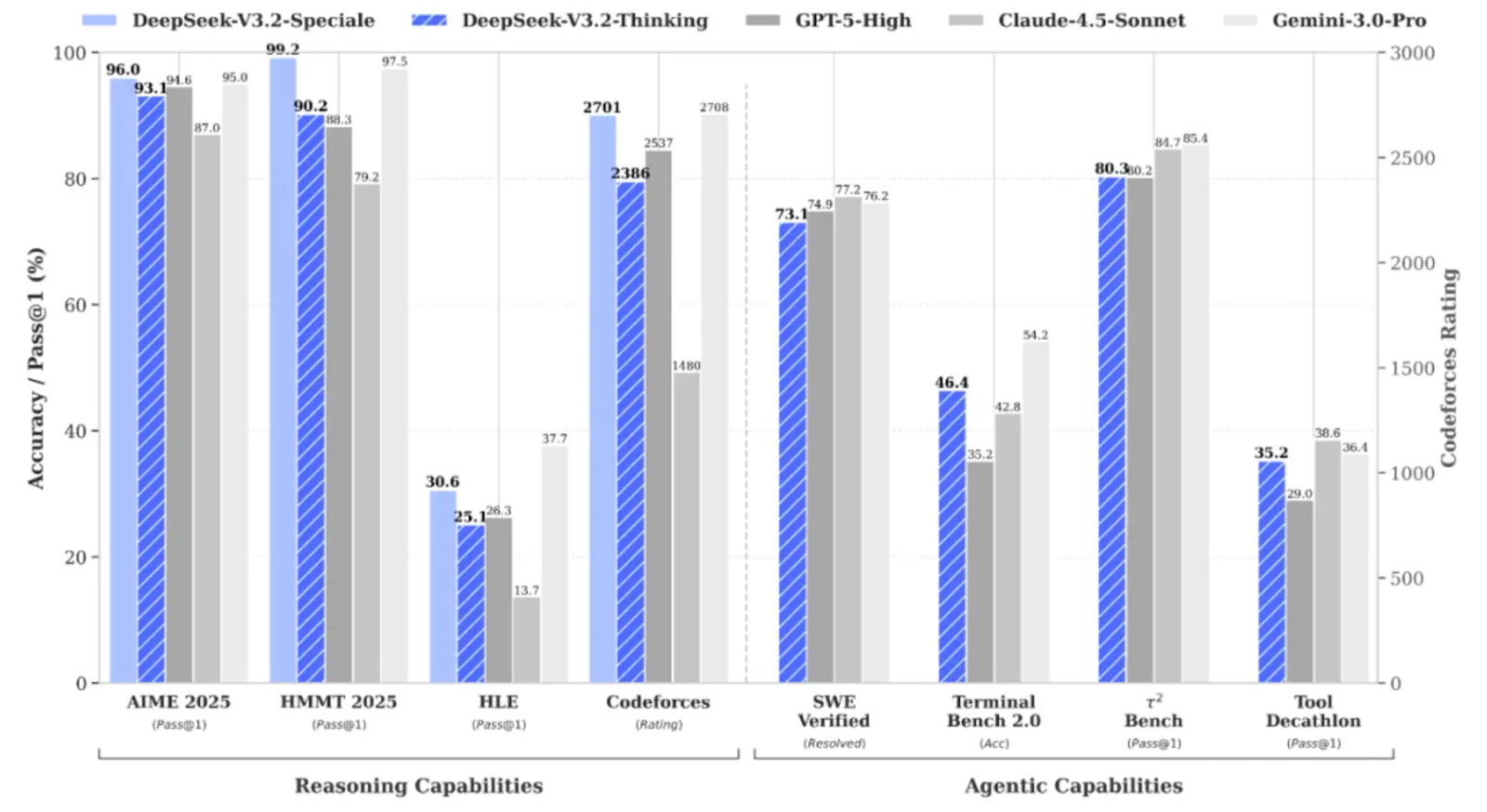
DeepSeek V3.2 Speciale es la variante de la familia DeepSeek V3.2 con alta capacidad de cálculo y aprendizaje reforzado, diseñada específicamente para el razonamiento profundo en lugar de la conversación informal.
Lleva el rendimiento a un nivel tal que rivaliza con modelos como Gemini 3 Pro en tareas complejas, y ha obtenido incluso resultados de medalla de oro en pruebas de rendimiento como IMO, CMO, ICPC World Finals e IOI 2025.
DeepSeek V3.2 Speciale está optimizado para:
La versión 3.2 Speciale solo admite el modo de pensamiento y, actualmente, no admite la llamada de herramientas a través de la API oficial. No basta con modificar el parámetro « temperature » y esperar obtener un JSON limpio a la primera. El modelo Speciale pensará detenidamente y, a menudo, intercalará su razonamiento con la respuesta final.
En esta sección, implementaremos un agente analista de datos de IA con un modelo DeepSeek V3.2 Speciale integrado en una aplicación Streamlit. A grandes rasgos, esto es lo que hace la aplicación final:
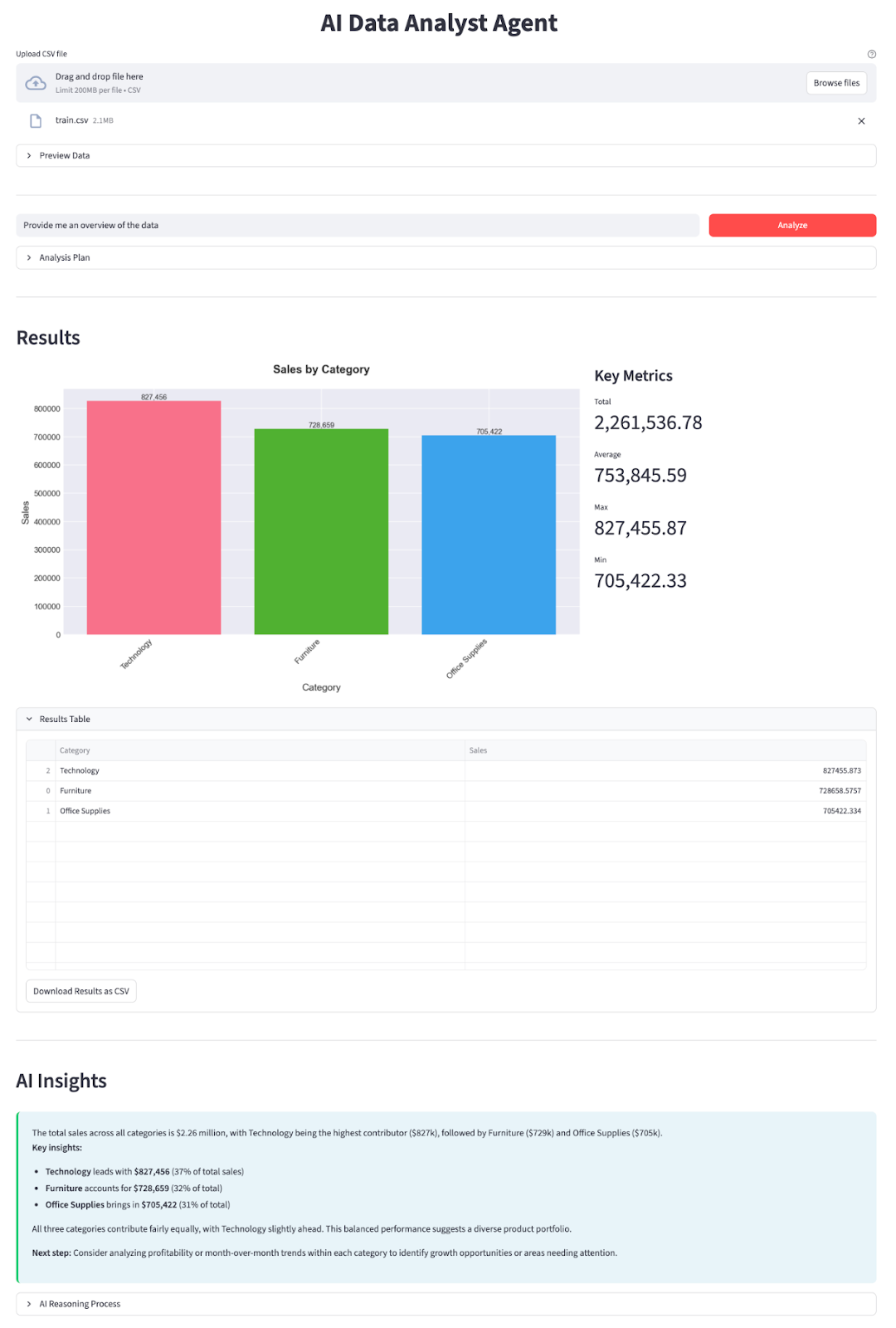
Construyámoslo paso a paso.
En primer lugar, instala las dependencias principales y obtén una clave API de la plataforma API de DeepSeek:
pip install streamlit pandas matplotlib seaborn python-dotenv openaiUtilizaremos algunas bibliotecas básicas como streamlit para impulsar la interfaz de usuario interactiva de la aplicación web, pandas para cargar y manipular datos CSV, matplotlib y seaborn para crear gráficos y visualizaciones. La biblioteca python-dotenv se utiliza para cargar variables de entorno desde un archivo .env, y OpenAI como cliente para comunicarse con la API compatible con OpenAI de DeepSeek.
A continuación, inicia sesión en la plataforma API de DeepSeek, ve a la pestaña Claves API y haz clic en Crear una nueva clave API.
Por último, asigna un nombre a tu clave y copia la clave generada.
Configura tu clave API de DeepSeek como variable de entorno:
export DEEPSEEK_API_KEY="your_api_key_here"Ahora nuestro entorno está listo.
Una vez instaladas las dependencias, el siguiente paso es incorporarlas a nuestro script y conectar el cliente DeepSeek que alimentará nuestros agentes planificadores y explicadores.
import io
import json
import os
import re
from datetime import datetime
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import streamlit as st
from dotenv import load_dotenv
from openai import OpenAI
plt.style.use('seaborn-v0_8-darkgrid')
sns.set_palette("husl")
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
if not DEEPSEEK_API_KEY:
raise RuntimeError("Please set DEEPSEEK_API_KEY env variable.")
DEEPSEEK_BASE_URL = os.getenv(
"DEEPSEEK_BASE_URL",
"https://api.deepseek.com/v3.2_speciale_expires_on_20251215",
)
client = OpenAI(
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)El bloque de código anterior hace tres cosas. Importa nuestras bibliotecas principales, aplica un estilo de gráficando y carga las variables de entorno desde .env. A continuación, lee DEEPSEEK_API_KEY, lo valida y crea un cliente OpenAI dirigido al punto final temporal V3.2 Speciale de DeepSeek, de modo que todas las llamadas LLM posteriores pasen por el modelo correcto.
Ten en cuenta que DeepSeek V3.2 Speciale se ofrece actualmente desde un punto final temporal que caduca el 15 de diciembre de 2025. Después de eso, la URL de implementación puede cambiar, pero el nombre del modelo seguirá siendo deepseek-reasoner. Para conocer los últimos puntos finales y detalles de uso, consulta la documentación oficial de DeepSeek.
Una vez configurado el cliente, definamos nuestros dos agentes: uno para planificar el análisis y otro para explicar los resultados.
Una vez instalado el cliente, podemos crear el agente planificador, que decide qué análisis ejecutar con los datos. En lugar de permitir que el modelo manipule directamente el DataFrame, le pedimos que genere un plan JSON estructurado que nuestro «trabajador de datos» de Python pueda ejecutar de forma segura.
El planificador ve una descripción textual del conjunto de datos junto con la pregunta del usuario y devuelve un objeto JSON que describe la operación, las columnas agrupadas, los filtros, la métrica y el tipo de gráfico.
def call_planner_llm(schema_text: str, question: str) -> tuple[dict, str]:
system_prompt = """
You are a data analysis planner. Convert user questions into JSON plans.
JSON Structure (REQUIRED):
{
"operation": "group_by_summary",
"group_by": ["column_name"],
"filters": [],
"target_column": "column_to_analyze",
"metric": "sum",
"need_chart": true,
"chart_type": "bar"
}
Fields:
- operation: Always use "group_by_summary" (most flexible)
- group_by: Columns to group by (e.g., ["Product Name"] or ["Category", "Region"])
- filters: Optional filters, e.g., [{"column": "Year", "op": "==", "value": "2023"}]
- target_column: Column to aggregate (must exist in schema!)
- metric: One of: sum, mean, count, max, min
- need_chart: true (always show chart)
- chart_type: bar, line, or pie
Quick Rules:
- Use ONLY columns from the provided schema
- For "this year", look for year columns or use the latest year in data
- For "top N", use appropriate group_by and metric
- For comparisons, use filters to split groups
Think briefly, then output the complete JSON.
""".strip()
messages = [
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": f"Dataset:\n{schema_text}\n\nQuestion:\n{question}\n\nReminder: After analyzing, output the complete JSON plan.",
},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
max_tokens=8192,
)
message = resp.choices[0].message
content = message.content or ""
content = content.strip()
reasoning_content = getattr(message, 'reasoning_content', None) or ""
finish_reason = resp.choices[0].finish_reason
def extract_json_from_text(text: str) -> dict | None:
if not text:
return None
try:
return json.loads(text)
except json.JSONDecodeError:
pass
code_block_match = re.search(r'```(?:json)?\s*(\{[\s\S]*?\})\s*```', text, re.DOTALL)
if code_block_match:
try:
return json.loads(code_block_match.group(1))
except json.JSONDecodeError:
pass
def find_all_json_objects(s):
objects = []
depth = 0
start_idx = None
in_string = False
escape_next = False
for i, char in enumerate(s):
if escape_next:
escape_next = False
continue
if char == '\\':
escape_next = True
continue
if char == '"' and not in_string:
in_string = True
elif char == '"' and in_string:
in_string = False
elif not in_string:
if char == '{':
if depth == 0:
start_idx = i
depth += 1
elif char == '}':
depth -= 1
if depth == 0 and start_idx is not None:
objects.append(s[start_idx:i+1])
start_idx = None
return objects
for candidate in find_all_json_objects(text):
try:
parsed = json.loads(candidate)
if isinstance(parsed, dict) and any(k in parsed for k in ['operation', 'target_column', 'metric', 'group_by']):
return parsed
except json.JSONDecodeError:
continue
for i in range(len(text)):
if text[i] == '{':
decoder = json.JSONDecoder()
try:
parsed, _ = decoder.raw_decode(text[i:])
if isinstance(parsed, dict) and any(k in parsed for k in ['operation', 'target_column', 'metric', 'group_by']):
return parsed
except json.JSONDecodeError:
continue
return None
if reasoning_content:
plan = extract_json_from_text(reasoning_content)
if plan is not None:
return plan, reasoning_content
plan = extract_json_from_text(content)
if plan is not None:
return plan, reasoning_content
error_msg = (
f"Planner returned non-JSON content.\n"
f"Finish reason: {finish_reason}\n"
f"Content received: {repr(content[:500]) if content else '(empty)'}\n"
f"Reasoning content length: {len(reasoning_content) if reasoning_content else 0}\n"
f"Reasoning content sample: {reasoning_content[:500] if reasoning_content else '(none)'}"
)
if finish_reason == "length":
error_msg += "\n\nNote: Response was truncated due to token limit. The model didn't finish generating the JSON."
raise ValueError(error_msg)En primer lugar, el archivo « system_prompt » define el contrato para el agente planificador, que convierte la pregunta del usuario en un plan JSON, y especifica exactamente qué campos esperamos, como una lista de columnas « group_by », « filters » opcionales, « target_column », « metric » y « chart_type ».
También añadimos algunas heurísticas (como cómo manejar «este año» o «top N») para que el modelo se comporte más como un analista de datos junior que como un chatbot genérico.
A continuación, creamos el mensaje del sistema que contiene las instrucciones y agrupa dos elementos: una descripción textual del esquema del conjunto de datos (nombres de columnas, tipos de datos, filas de muestra) y la pregunta del usuario. Esto proporciona al modelo suficiente contexto para seleccionar nombres de columnas válidos y elegir una agregación sensata para la pregunta que se plantea.
A continuación, se llama a DeepSeek V3.2 Speciale a través de client.chat.completions.create(). Dado que se trata de un modelo de razonamiento, puede producir dos canales de salida: una cadena de contenido visible y una cadena interna reasoning_content, donde suelen residir la mayor parte del «pensamiento» y la respuesta final. Extraemos ambos de la respuesta y hacemos un seguimiento del finish_reason para poder detectar el truncamiento.
El trabajo pesado se realiza dentro de una función llamad extract_json_from_text(). Dado que los modelos de razonamiento no siempre devuelven JSON limpio, lo envolvemos en un markdown. Para que el planificador sea robusto, esta función auxiliar prueba varias estrategias en secuencia:
json.loadsPara cada candidato, solo se aceptan objetos que parezcan un plan válido, es decir, deben contener al menos uno de los campos operation, target_column, metric o group_by.
Por último, conectamos todo aplicando una función de e extract_json_from_text() o a reasoning_content.
En conjunto, estas piezas convierten cualquier pregunta en lenguaje natural y cualquier instantánea del esquema en un plan de análisis estructurado.
Una vez que el trabajador de datos ha realizado el análisis con Pandas, enviamos la tabla de resultados junto con el plan JSON a DeepSeek y lo convertimos todo en un resumen con información concreta.
def call_explainer_llm(question: str, plan: dict, result_summary: list) -> tuple[str, str]:
system_prompt = """
You are a senior data analyst explaining insights to business stakeholders.
The user asked a question about their CSV data.
Another agent already designed an analysis plan and we executed it in Python.
You will now explain the results in clear, engaging, non-technical language.
Requirements:
- Start with a direct 1-2 sentence answer to their question
- Use bullet points (3-5 points) to highlight key insights, trends, or comparisons
- Include specific numbers and percentages where relevant
- Use business-friendly language (avoid technical jargon like "aggregation", "groupby")
- If the data shows interesting patterns, point them out
- End with a brief recommendation or next step if appropriate
Keep it concise and actionable.
""".strip()
limited_summary = result_summary[:20] if len(result_summary) > 20 else result_summary
user_content = f"""
User question:
{question}
Analysis performed:
{json.dumps(plan, indent=2)}
Results (top rows):
{json.dumps(limited_summary, indent=2)}
Total rows in result: {len(result_summary)}
""".strip()
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
max_tokens=2048,
)
message = resp.choices[0].message
content = message.content or ""
content = content.strip()
reasoning_content = getattr(message, 'reasoning_content', None) or ""
if not content:
if reasoning_content:
content = reasoning_content.strip()
return (content if content else "Unable to generate explanation from the model response.",
reasoning_content)El agente explicador comienza estableciendo el « system_prompt » (enfoque de comunicación), que indica a DeepSeek que se comporte como un analista de datos sénior que habla con las partes interesadas de la empresa. Especificamos la forma exacta de la respuesta que deseamos, junto con otras recomendaciones para redactar la respuesta.
A continuación, preparamos user_content, que proporciona al modelo todo el contexto que necesita. Pasamos la pregunta original, el plan de análisis JSON (para que sepas qué cálculos se han ejecutado) y el número total de filas.
A continuación, recopilamos la lista de mensajes y llamamos a DeepSeek V3.2 Speciale a través de client.chat.completions.create(). Al igual que en el planificador, el modelo puede devolver texto tanto en content como en reasoning_content, por lo que añadimos ambos y recurrimos a reasoning_content si content está vacío.
Por último, la función devuelve una tupla que incluye tanto la explicación como la cadena de razonamiento sin procesar que aparece en el expansor.
Con este agente explicativo en su lugar, el ciclo se completa:
Antes de permitir que DeepSeek planifique algo, es necesario describir los datos con claridad y facilitar su análisis. Esto se consigue utilizando un conjunto de funciones auxiliares.
El agente planificador no puede ver tu DataFrame directamente, por lo que le enviamos un resumen textual compacto del conjunto de datos.
def get_schema_description(df: pd.DataFrame, max_rows: int = 3) -> str:
schema_lines = ["Columns:"]
for col, dtype in df.dtypes.items():
if dtype == 'object' and df[col].nunique() < 20:
unique_vals = df[col].dropna().unique()[:5]
schema_lines.append(f"- {col} ({dtype}) - sample values: {', '.join(map(str, unique_vals))}")
else:
schema_lines.append(f"- {col} ({dtype})")
sample = df.head(max_rows).to_markdown(index=False)
return "\n".join(schema_lines) + "\n\nSample rows:\n" + sampleEste ayudante recorre todas las columnas. También incluye algunos valores de ejemplo para cosas como nombres de productos, regiones o categorías. F
Finalmente, añade una breve tabla con las primeras filas, para que el modelo tenga ejemplos concretos sobre los que razonar.
Esta cadena de esquema es la visión que tiene el planificador de tus datos, lo que le permite seleccionar nombres de columnas y agrupaciones válidos.
Detectamos automáticamente las columnas de fecha y añadimos campos auxiliares como _year y _year_month, lo que facilita a DeepSeek responder a preguntas como «el año pasado» o «por mes».
def preprocess_dates(df: pd.DataFrame) -> pd.DataFrame:
df = df.copy()
date_columns = []
for col in df.columns:
if pd.api.types.is_datetime64_any_dtype(df[col]):
date_columns.append(col)
continue
if any(x in col.lower() for x in ['date', 'time', 'day']):
try:
df[col] = pd.to_datetime(df[col], errors='coerce')
if df[col].notna().sum() > 0:
date_columns.append(col)
except:
pass
for col in date_columns:
if col in df.columns and pd.api.types.is_datetime64_any_dtype(df[col]):
df[f'{col}_year'] = df[col].dt.year
df[f'{col}_month'] = df[col].dt.month
df[f'{col}_year_month'] = df[col].dt.to_period('M').astype(str)
return dfPrimero, escaneamos las columnas y, si una columna ya es de tipo fecha/hora o su nombre hace referencia a una fecha (como order_date o day), intentamos analizarla con pd.to_datetime. Para cada columna de fecha, creamos características como _year, _month y _year_month.
Este preprocesamiento significa que el planificador puede hacer referencia de forma segura a las columnas year y year_month sin que tengas que diseñar manualmente características temporales para cada conjunto de datos.
El planificador puede añadir filtros de fila sencillos al plan, y este asistente los convierte en filtros pandas.
def apply_filters(df: pd.DataFrame, filters: list) -> pd.DataFrame:
if not filters:
return df
filtered = df.copy()
for f in filters:
col = f.get("column")
op = f.get("op")
val = f.get("value")
if col not in filtered.columns:
continue
try:
val_cast = pd.to_numeric(val)
except Exception:
val_cast = val
if op == "==":
filtered = filtered[filtered[col] == val_cast]
elif op == "!=":
filtered = filtered[filtered[col] != val_cast]
elif op == ">":
filtered = filtered[filtered[col] > val_cast]
elif op == "<":
filtered = filtered[filtered[col] < val_cast]
elif op == ">=":
filtered = filtered[filtered[col] >= val_cast]
elif op == "<=":
filtered = filtered[filtered[col] <= val_cast]
elif op == "contains":
filtered = filtered[filtered[col].astype(str).str.contains(str(val_cast), case=False, na=False)]
return filteredPara cada filtro, verificamos que la columna exista y convertimos el valor a un número si es posible, luego aplicamos la comparación adecuada. Todos los filtros se aplican de forma secuencial, por lo que puedes combinar condiciones como «Región contiene Oeste» y «Año >= 2021» de forma natural.
Esta función es la que conecta las restricciones del lenguaje natural del plan con los subconjuntos de filas.
Ahora implementamos el Data Worker, que es una capa delgada que lee el plan JSON y ejecuta las agregaciones de pandas correspondientes.
def run_analysis_plan(df: pd.DataFrame, plan: dict) -> pd.DataFrame:
op = plan.get("operation")
target_col = plan.get("target_column")
group_by = plan.get("group_by") or []
filters = plan.get("filters") or []
metric = plan.get("metric", "sum")
if filters:
df = apply_filters(df, filters)
if not op or not target_col or target_col not in df.columns:
return df.head(20)
if op in ("aggregate_compare", "group_by_summary", "filter_then_aggregate"):
if not group_by:
if metric == "sum":
value = df[target_col].sum()
elif metric == "mean":
value = df[target_col].mean()
elif metric == "count":
value = df[target_col].count()
elif metric == "max":
value = df[target_col].max()
elif metric == "min":
value = df[target_col].min()
else:
raise ValueError(f"Unsupported metric: {metric}")
return pd.DataFrame({f"{metric}_{target_col}": [value]})
if metric == "sum":
agg_df = df.groupby(group_by)[target_col].sum().reset_index()
elif metric == "mean":
agg_df = df.groupby(group_by)[target_col].mean().reset_index()
elif metric == "count":
agg_df = df.groupby(group_by)[target_col].count().reset_index()
elif metric == "max":
agg_df = df.groupby(group_by)[target_col].max().reset_index()
elif metric == "min":
agg_df = df.groupby(group_by)[target_col].min().reset_index()
else:
raise ValueError(f"Unsupported metric: {metric}")
agg_df = agg_df.sort_values(by=target_col, ascending=False)
return agg_df
return df.head(20)Comenzamos desglosando el plan con la operación, la columna de destino, las columnas de agrupación, los filtros y los parámetros métricos. T
A continuación, los filtros se aplican mediante la función « apply_filters() ». Si el plan hace referencia a una columna no válida, volvemos a mostrar una vista previa simple.
De lo contrario, para las operaciones compatibles, agregamos toda la tabla o ejecutamos un agrupamiento seguido de operaciones como suma, media, recuento, máximo o mínimo, y ordenamos el resultado por la columna métrica.
Este es el núcleo de la capa de herramientas: el LLM decide qué calcular, y esta función decide cómo calcularlo de forma segura con pandas.
Por último, convertimos la tabla resultante en un gráfico que coincide con el plan chart_type, de modo que tenemos tanto números como imágenes en el resultado.
def generate_chart(df: pd.DataFrame, plan: dict):
if not plan.get("need_chart") or df.empty:
return None
chart_type = plan.get("chart_type", "bar")
group_by = plan.get("group_by") or []
target_col = plan.get("target_column")
if not target_col or target_col not in df.columns:
return None
fig, ax = plt.subplots(figsize=(10, 6))
if group_by and len(group_by) > 0:
x_col = group_by[0]
if x_col not in df.columns:
return None
plot_df = df.head(15)
if chart_type == "bar":
bars = ax.bar(range(len(plot_df)), plot_df[target_col], color=sns.color_palette("husl", len(plot_df)))
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
ax.set_ylabel(target_col, fontsize=12)
ax.set_xlabel(x_col, fontsize=12)
for i, (bar, val) in enumerate(zip(bars, plot_df[target_col])):
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{val:,.0f}' if abs(val) > 100 else f'{val:.2f}',
ha='center', va='bottom', fontsize=9)
elif chart_type == "line":
ax.plot(range(len(plot_df)), plot_df[target_col], marker='o', linewidth=2, markersize=8)
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
ax.set_ylabel(target_col, fontsize=12)
ax.set_xlabel(x_col, fontsize=12)
ax.grid(True, alpha=0.3)
elif chart_type == "pie" and len(plot_df) <= 10:
ax.pie(plot_df[target_col], labels=plot_df[x_col], autopct='%1.1f%%', startangle=90)
ax.axis('equal')
else:
bars = ax.bar(range(len(plot_df)), plot_df[target_col])
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
title = f"{target_col} by {x_col}"
else:
ax.bar([target_col], [df[target_col].iloc[0]])
title = f"{target_col}"
ax.set_title(title, fontsize=14, fontweight='bold', pad=20)
fig.tight_layout()
buf = io.BytesIO()
fig.savefig(buf, format="png", dpi=150, bbox_inches='tight')
buf.seek(0)
plt.close(fig)
return bufLeemos chart_type, group_by y target_column del plan y creamos una figura Matplotlib. La función anterior generate_chart() devuelve un búfer PNG en memoria que la aplicación Streamlit muestra junto a las métricas clave.
Con estas funciones auxiliares implementadas, el resto del sistema se vuelve mucho más sencillo. El planificador utiliza get_schema_description para diseñar el análisis, el trabajador de datos utiliza las funciones preprocess_dates(), apply_filters() y run_analysis_plan() para procesar los números, y la función generate_chart() convierte la tabla final en un gráfico.
Ahora que ya tenemos las funciones de planificación, procesamiento de datos, explicación y ayuda, podemos integrarlo todo en una aplicación Streamlit.
st.set_page_config(
page_title="AI Data Analyst Agent",
page_icon="📊",
layout="wide",
initial_sidebar_state="expanded"
)
st.markdown("""
<style>
.main-header {
font-weight: 700;
text-align: center;
}
.sub-header {
text-align: center;
}
.metric-card {
background-
border-radius: 0.5rem;
border-left: 4px solid #1f77b4;
}
.insight-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #2ecc71;
}
</style>
""", unsafe_allow_html=True)
st.markdown("<h1 class='main-header'>AI Data Analyst Agent</h1>", unsafe_allow_html=True)
uploaded_file = st.file_uploader("Upload CSV file", type=["csv"], help="Upload any CSV file to get started")
if uploaded_file is not None:
try:
df = pd.read_csv(uploaded_file)
df = preprocess_dates(df)
except Exception as e:
st.error(f"Error loading CSV: {e}")
st.stop()
with st.expander("Preview Data", expanded=False):
col1, col2, col3 = st.columns(3)
col1.metric("Total Rows", f"{len(df):,}")
col2.metric("Total Columns", len(df.columns))
col3.metric("Memory Usage", f"{df.memory_usage(deep=True).sum() / 1024**2:.1f} MB")
st.dataframe(df.head(100), width='stretch', height=300)
st.markdown("**Numeric Columns Summary:**")
numeric_cols = df.select_dtypes(include=['number']).columns
if len(numeric_cols) > 0:
st.dataframe(df[numeric_cols].describe(), width='stretch')
st.markdown("---")
col1, col2 = st.columns([4, 1])
with col1:
question = st.text_input(
" Ask a question about your data",
placeholder="e.g., Which product category had the highest sales last year?",
label_visibility="collapsed"
)
with col2:
analyze_button = st.button("Analyze", type="primary", width='stretch')
if analyze_button and question.strip():
with st.spinner("Analyzing data..."):
schema_text = get_schema_description(df)
try:
plan, planner_reasoning = call_planner_llm(schema_text, question)
except Exception as e:
st.error(f" Planner agent failed: {e}")
st.stop()
with st.expander(" Analysis Plan", expanded=False):
col1, col2 = st.columns(2)
with col1:
st.json(plan)
with col2:
if planner_reasoning:
st.markdown("**AI Reasoning Process:**")
st.text_area("Planner Reasoning", planner_reasoning[:1000] + "..." if len(planner_reasoning) > 1000 else planner_reasoning,
height=200, label_visibility="collapsed")
try:
result_df = run_analysis_plan(df, plan)
except Exception as e:
st.error(f" Error running analysis: {e}")
st.info(" Tip: Try rephrasing your question or be more specific about the columns you want to analyze.")
st.stop()
st.markdown("---")
st.markdown("## Results")
chart_buf = generate_chart(result_df, plan)
if chart_buf is not None:
col1, col2 = st.columns([2, 1])
with col1:
st.image(chart_buf)
with col2:
st.markdown("### Key Metrics")
target_col = plan.get("target_column")
if target_col in result_df.columns:
st.metric("Total", f"{result_df[target_col].sum():,.2f}")
st.metric("Average", f"{result_df[target_col].mean():,.2f}")
st.metric("Max", f"{result_df[target_col].max():,.2f}")
st.metric("Min", f"{result_df[target_col].min():,.2f}")
else:
st.info("Chart generation skipped (not applicable for this query)")
with st.expander("Results Table", expanded=True):
st.dataframe(result_df, width='stretch', height=400)
csv_data = result_df.to_csv(index=False)
st.download_button(
label="Download Results as CSV",
data=csv_data,
file_name=f"analysis_results_{datetime.now().strftime('%Y%m%d_%H%M%S')}.csv",
mime="text/csv"
)
with st.spinner("Generating insights..."):
result_df_serializable = result_df.copy()
for col in result_df_serializable.columns:
if pd.api.types.is_datetime64_any_dtype(result_df_serializable[col]):
result_df_serializable[col] = result_df_serializable[col].astype(str)
elif pd.api.types.is_period_dtype(result_df_serializable[col]):
result_df_serializable[col] = result_df_serializable[col].astype(str)
result_summary = result_df_serializable.to_dict(orient="records")
explanation, explainer_reasoning = call_explainer_llm(
question=question,
plan=plan,
result_summary=result_summary,
)
st.markdown("---")
st.markdown("## AI Insights")
st.markdown(f'<div class="insight-box">{explanation}</div>', unsafe_allow_html=True)
if explainer_reasoning:
with st.expander(" AI Reasoning Process", expanded=False):
st.text_area("Explainer Reasoning", explainer_reasoning[:1500] + "..." if len(explainer_reasoning) > 1500 else explainer_reasoning,
height=300, label_visibility="collapsed")En la parte superior, configuramos la página con st.set_page_config y CSS para dar estilo al panel de control. El usuario primero carga un archivo CSV, que nosotros cargamos en un DataFrame, pasamos por preprocess_dates y mostramos dentro de un expansorde vista previa de datos con recuentos de filas/columnas, uso de memoria y un resumen rápido.
Entre bastidores, creamos un esquema con la función « get_schema_description() », llamamos a « call_planner_llm » para obtener un plan JSON y mostramos tanto el plan como el razonamiento del modelo en un expansor. A continuación, el Data Worker ejecuta el plan con pandas, y la sección« » (Resultados de la exploración de datos) muestra un gráfico de generate_chart junto con las métricas clave.
Por último, llamamos a call_explainer_llm con la pregunta, el plan y el resumen de resultados para generar una explicación para el cuadro AI Insights , con un proceso de razonamiento de IA opcional. expansor del proceso de razonamiento de la IA para cualquiera que quiera echar un vistazo bajo el capó.
Guarda todo como app.py y ejecuta:
streamlit run app.pyEn el siguiente vídeo, puedes ver una versión resumida del flujo de trabajo en acción:
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Nadia mhadhbi
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
