
Curso
Projetando Sistemas Agentes com LangChain
3 h
12.1K
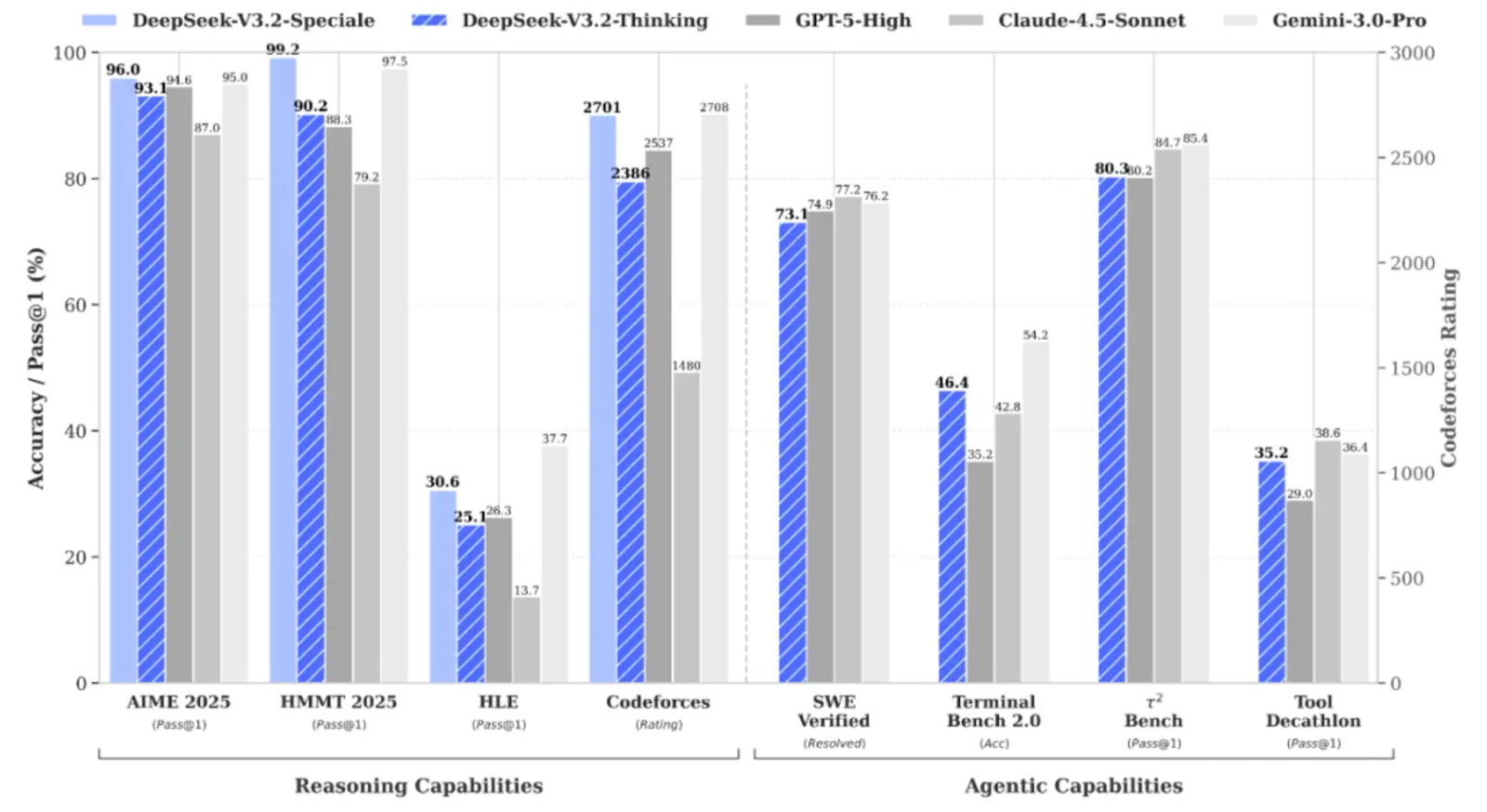
O DeepSeek V3.2 Speciale é um modelo de raciocínio de alta computação ajustado para fluxos de trabalho complexos e aprimorados por ferramentas. Em vez de só responder perguntas direto, ele foi feito pra planejar, raciocinar e coordenar ferramentas pra construir sistemas de análise de agentes.
Neste tutorial, vamos usar o DeepSeek V3.2 Speciale para criar um Agente Analista de Dados de IA que fica em cima de qualquer CSV. O fluxo é assim:
No final, você vai ter um aplicativo Streamlit com planos bem claros e etapas de análise que dá pra repetir. Se você quiser saber mais sobre agentes de IA, recomendo dar uma olhada no programa de habilidades Fundamentos de Agentes de IA.
O DeepSeek V3.2 Speciale é a versão com alta capacidade de computação e reforçada por aprendizado de reforço da família DeepSeek V3.2, projetada especialmente para raciocínio profundo, em vez de conversas casuais.
Ele leva o desempenho a um nível que chega a competir com modelos como o Gemini 3 Pro em tarefas complexas e até conseguiu medalhas de ouro em benchmarks como IMO, CMO, ICPC World Finals e IOI 2025.
O DeepSeek V3.2 Speciale é otimizado para:
A V3.2 Speciale só dá suporte ao modo de pensamento e, por enquanto, não dá suporte à chamada de ferramentas pela API oficial. Não dá pra só mexer no temperature e achar que vai ter um JSON limpo logo de cara. O modelo Speciale vai pensar bastante e, muitas vezes, vai misturar seu raciocínio com a resposta final.
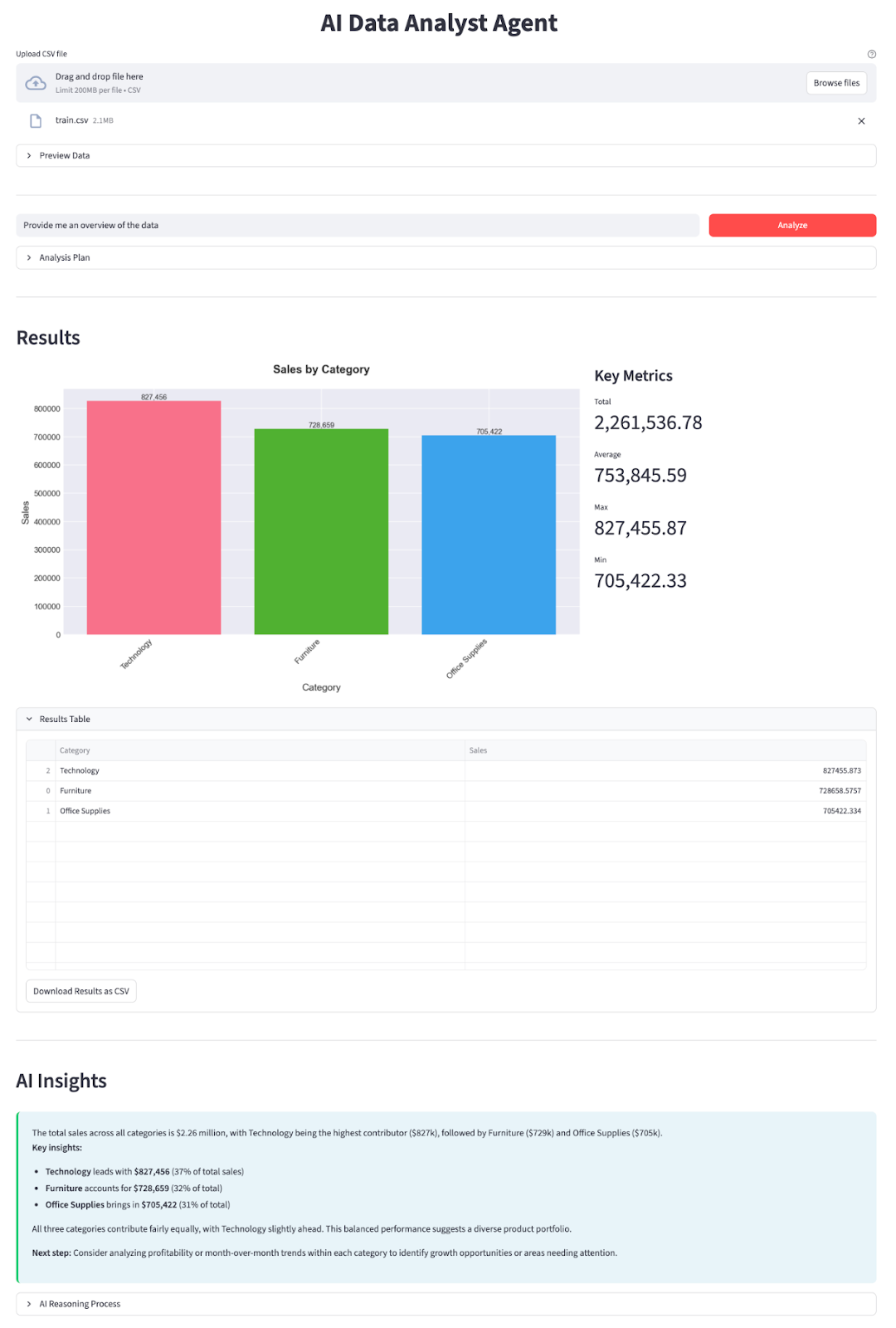
Nesta seção, vamos implementar um Agente Analista de Dados de IA com um modelo DeepSeek V3.2 Speciale integrado a um aplicativo Streamlit. Em resumo, eis o que o aplicativo final faz:
Vamos construir passo a passo.
Primeiro, instale as dependências principais e pegue uma chave API da plataforma API do DeepSeek:
pip install streamlit pandas matplotlib seaborn python-dotenv openaiVamos usar algumas bibliotecas principais, como streamlit, para alimentar a interface interativa do aplicativo web, pandas para carregar e manipular dados CSV, matplotlib e seaborn para criar gráficos e visualizações. A biblioteca python-dotenv é usada para carregar variáveis de ambiente a partir de um arquivo .env, e o OpenAI como cliente para se comunicar com a API compatível com OpenAI do DeepSeek.
Depois, entre na plataforma da API DeepSeek, vá até a aba Chaves da API e clique em Criar uma nova chave da API.
Por fim, dá um nome à tua chave e copia a chave gerada.
Defina sua chave API DeepSeek como uma variável de ambiente:
export DEEPSEEK_API_KEY="your_api_key_here"Agora nosso ambiente está pronto.
Com as dependências instaladas, o próximo passo é colocá-las no nosso script e conectar o cliente DeepSeek que vai alimentar nossos agentes planejadores e explicadores.
import io
import json
import os
import re
from datetime import datetime
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import streamlit as st
from dotenv import load_dotenv
from openai import OpenAI
plt.style.use('seaborn-v0_8-darkgrid')
sns.set_palette("husl")
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
if not DEEPSEEK_API_KEY:
raise RuntimeError("Please set DEEPSEEK_API_KEY env variable.")
DEEPSEEK_BASE_URL = os.getenv(
"DEEPSEEK_BASE_URL",
"https://api.deepseek.com/v3.2_speciale_expires_on_20251215",
)
client = OpenAI(
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)O bloco de código acima faz três coisas. Ele importa nossas bibliotecas principais, aplica um estilo de plotagem e carrega variáveis de ambiente de .env. Em seguida, ele lê DEEPSEEK_API_KEY, valida e constrói um cliente OpenAI apontado para o endpoint temporário V3.2 Speciale do DeepSeek, para que todas as chamadas LLM subsequentes passem pelo modelo correto.
Observe que o DeepSeek V3.2 Speciale está atualmente sendo servido a partir de um endpoint temporário que expira em 15 de dezembro de 2025. Depois disso, o URL de implantação pode mudar, mas o nome do modelo continuará sendo deepseek-reasoner. Para saber os pontos finais mais recentes e detalhes de uso, dá uma olhada na documentação oficial do DeepSeek.
Com o cliente configurado, vamos definir nossos dois agentes: um para planejar a análise e outro para explicar os resultados.
Com o cliente instalado, podemos criar o Planner Agent, que decide quais análises serão executadas com os dados. Em vez de deixar o modelo mexer diretamente no DataFrame, pedimos pra ele criar um plano JSON estruturado que nosso “trabalhador de dados” Python possa executar com segurança.
O planejador vê uma descrição em texto do conjunto de dados junto com a pergunta do usuário e retorna um objeto JSON descrevendo a operação, colunas agrupadas, filtros, métrica e tipo de gráfico.
def call_planner_llm(schema_text: str, question: str) -> tuple[dict, str]:
system_prompt = """
You are a data analysis planner. Convert user questions into JSON plans.
JSON Structure (REQUIRED):
{
"operation": "group_by_summary",
"group_by": ["column_name"],
"filters": [],
"target_column": "column_to_analyze",
"metric": "sum",
"need_chart": true,
"chart_type": "bar"
}
Fields:
- operation: Always use "group_by_summary" (most flexible)
- group_by: Columns to group by (e.g., ["Product Name"] or ["Category", "Region"])
- filters: Optional filters, e.g., [{"column": "Year", "op": "==", "value": "2023"}]
- target_column: Column to aggregate (must exist in schema!)
- metric: One of: sum, mean, count, max, min
- need_chart: true (always show chart)
- chart_type: bar, line, or pie
Quick Rules:
- Use ONLY columns from the provided schema
- For "this year", look for year columns or use the latest year in data
- For "top N", use appropriate group_by and metric
- For comparisons, use filters to split groups
Think briefly, then output the complete JSON.
""".strip()
messages = [
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": f"Dataset:\n{schema_text}\n\nQuestion:\n{question}\n\nReminder: After analyzing, output the complete JSON plan.",
},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
max_tokens=8192,
)
message = resp.choices[0].message
content = message.content or ""
content = content.strip()
reasoning_content = getattr(message, 'reasoning_content', None) or ""
finish_reason = resp.choices[0].finish_reason
def extract_json_from_text(text: str) -> dict | None:
if not text:
return None
try:
return json.loads(text)
except json.JSONDecodeError:
pass
code_block_match = re.search(r'```(?:json)?\s*(\{[\s\S]*?\})\s*```', text, re.DOTALL)
if code_block_match:
try:
return json.loads(code_block_match.group(1))
except json.JSONDecodeError:
pass
def find_all_json_objects(s):
objects = []
depth = 0
start_idx = None
in_string = False
escape_next = False
for i, char in enumerate(s):
if escape_next:
escape_next = False
continue
if char == '\\':
escape_next = True
continue
if char == '"' and not in_string:
in_string = True
elif char == '"' and in_string:
in_string = False
elif not in_string:
if char == '{':
if depth == 0:
start_idx = i
depth += 1
elif char == '}':
depth -= 1
if depth == 0 and start_idx is not None:
objects.append(s[start_idx:i+1])
start_idx = None
return objects
for candidate in find_all_json_objects(text):
try:
parsed = json.loads(candidate)
if isinstance(parsed, dict) and any(k in parsed for k in ['operation', 'target_column', 'metric', 'group_by']):
return parsed
except json.JSONDecodeError:
continue
for i in range(len(text)):
if text[i] == '{':
decoder = json.JSONDecoder()
try:
parsed, _ = decoder.raw_decode(text[i:])
if isinstance(parsed, dict) and any(k in parsed for k in ['operation', 'target_column', 'metric', 'group_by']):
return parsed
except json.JSONDecodeError:
continue
return None
if reasoning_content:
plan = extract_json_from_text(reasoning_content)
if plan is not None:
return plan, reasoning_content
plan = extract_json_from_text(content)
if plan is not None:
return plan, reasoning_content
error_msg = (
f"Planner returned non-JSON content.\n"
f"Finish reason: {finish_reason}\n"
f"Content received: {repr(content[:500]) if content else '(empty)'}\n"
f"Reasoning content length: {len(reasoning_content) if reasoning_content else 0}\n"
f"Reasoning content sample: {reasoning_content[:500] if reasoning_content else '(none)'}"
)
if finish_reason == "length":
error_msg += "\n\nNote: Response was truncated due to token limit. The model didn't finish generating the JSON."
raise ValueError(error_msg)Primeiro, o system_prompt define o contrato para o Planner Agent, que transforma a pergunta do usuário em um plano JSON e especifica exatamente quais campos esperamos, como uma lista de colunas group_by, filters opcionais, um target_column, um metric e um chart_type.
Também adicionamos algumas heurísticas (como lidar com “este ano” ou “top N”) para que o modelo se comporte mais como um analista de dados júnior do que como um chatbot genérico.
Depois, criamos a mensagem do sistema que traz as instruções e junta duas coisas: uma descrição textual do esquema do conjunto de dados (nomes das colunas, tipos de dados, linhas de amostra) e a pergunta do usuário. Isso dá ao modelo contexto suficiente para escolher nomes de colunas válidos e uma agregação sensata para a pergunta que está sendo feita.
O DeepSeek V3.2 Speciale é então chamado através de client.chat.completions.create(). Como esse é um modelo de raciocínio, ele pode gerar dois canais de saída: uma sequência de caracteres visível e uma sequência interna de caracteres reasoning_content, onde geralmente fica a maior parte do “pensamento” e a resposta final. A gente pega os dois da resposta e fica de olho no finish_reason pra poder ver se tem algum truncamento.
O trabalho pesado rola dentro de uma função chamad extract_json_from_text(). Como os modelos de raciocínio nem sempre devolvem JSON limpo, a gente coloca isso em um markdown. Para deixar o planejador mais robusto, essa função auxiliar tenta várias estratégias em sequência:
json.loadsPara cada candidato, só aceita objetos que pareçam um plano válido, ou seja, eles precisam ter pelo menos um dos campos operation, target_column, metric ou group_by.
Por fim, conectamos tudo aplicando uma função de extract_json_from_text() e a reasoning_content.
Juntas, essas peças transformam qualquer pergunta em linguagem natural e instantâneo de esquema em um plano de análise estruturado.
Depois que o Data Worker faz a análise com o Pandas, mandamos a tabela de resultados junto com o plano JSON de volta para o DeepSeek e transformamos tudo em um resumo com insights concretos.
def call_explainer_llm(question: str, plan: dict, result_summary: list) -> tuple[str, str]:
system_prompt = """
You are a senior data analyst explaining insights to business stakeholders.
The user asked a question about their CSV data.
Another agent already designed an analysis plan and we executed it in Python.
You will now explain the results in clear, engaging, non-technical language.
Requirements:
- Start with a direct 1-2 sentence answer to their question
- Use bullet points (3-5 points) to highlight key insights, trends, or comparisons
- Include specific numbers and percentages where relevant
- Use business-friendly language (avoid technical jargon like "aggregation", "groupby")
- If the data shows interesting patterns, point them out
- End with a brief recommendation or next step if appropriate
Keep it concise and actionable.
""".strip()
limited_summary = result_summary[:20] if len(result_summary) > 20 else result_summary
user_content = f"""
User question:
{question}
Analysis performed:
{json.dumps(plan, indent=2)}
Results (top rows):
{json.dumps(limited_summary, indent=2)}
Total rows in result: {len(result_summary)}
""".strip()
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
max_tokens=2048,
)
message = resp.choices[0].message
content = message.content or ""
content = content.strip()
reasoning_content = getattr(message, 'reasoning_content', None) or ""
if not content:
if reasoning_content:
content = reasoning_content.strip()
return (content if content else "Unable to generate explanation from the model response.",
reasoning_content)O agente explicador começa definindo o system_prompt, que diz ao DeepSeek para agir como um analista de dados sênior conversando com os stakeholders do negócio. A gente especifica exatamente como a gente quer que a resposta seja, junto com outras dicas para escrever a resposta.
Depois, a gente prepara um user_content, que dá ao modelo todo o contexto que ele precisa. Passamos a pergunta original, o plano de análise JSON (para que ele saiba quais cálculos foram executados) e o número total de linhas.
Depois, montamos a lista de mensagens e chamamos o DeepSeek V3.2 Speciale pelo client.chat.completions.create(). Assim como no planejador, o modelo pode retornar texto tanto em content quanto em reasoning_content, então adicionamos ambos e voltamos para reasoning_content se content estiver vazio.
Por fim, a função retorna uma tupla que inclui tanto a explicação quanto a string de raciocínio bruto que aparece no expansor.
Com esse Agente Explicador instalado, o ciclo está completo:
Antes de deixarmos o DeepSeek planejar qualquer coisa, precisamos descrever os dados de forma clara e torná-los fáceis de analisar. Isso é feito usando um monte de funções auxiliares.
O Planner Agent não consegue ver seu DataFrame diretamente, então a gente manda um resumo textual compacto do conjunto de dados.
def get_schema_description(df: pd.DataFrame, max_rows: int = 3) -> str:
schema_lines = ["Columns:"]
for col, dtype in df.dtypes.items():
if dtype == 'object' and df[col].nunique() < 20:
unique_vals = df[col].dropna().unique()[:5]
schema_lines.append(f"- {col} ({dtype}) - sample values: {', '.join(map(str, unique_vals))}")
else:
schema_lines.append(f"- {col} ({dtype})")
sample = df.head(max_rows).to_markdown(index=False)
return "\n".join(schema_lines) + "\n\nSample rows:\n" + sampleEsse auxiliar faz um loop em todas as colunas. Também inclui alguns exemplos de valores para coisas como nomes de produtos, regiões ou categorias. F
Por fim, ele adiciona uma pequena tabela de marcação das primeiras linhas, para que o modelo tenha exemplos concretos para raciocinar.
Essa sequência de caracteres do esquema é como o planejador vê seus dados, permitindo que ele escolha nomes de colunas e agrupamentos válidos.
A gente detecta automaticamente as colunas de data e adiciona campos auxiliares como _year e _year_month, o que facilita para o DeepSeek responder a perguntas como “no ano passado” ou “por mês”.
def preprocess_dates(df: pd.DataFrame) -> pd.DataFrame:
df = df.copy()
date_columns = []
for col in df.columns:
if pd.api.types.is_datetime64_any_dtype(df[col]):
date_columns.append(col)
continue
if any(x in col.lower() for x in ['date', 'time', 'day']):
try:
df[col] = pd.to_datetime(df[col], errors='coerce')
if df[col].notna().sum() > 0:
date_columns.append(col)
except:
pass
for col in date_columns:
if col in df.columns and pd.api.types.is_datetime64_any_dtype(df[col]):
df[f'{col}_year'] = df[col].dt.year
df[f'{col}_month'] = df[col].dt.month
df[f'{col}_year_month'] = df[col].dt.to_period('M').astype(str)
return dfPrimeiro, a gente dá uma olhada nas colunas e, se uma coluna já for datetime ou o nome dela der a entender que é uma data (tipo order_date ou day), a gente tenta analisá-la com pd.to_datetime. Para cada coluna de data, criamos recursos como _year, _month e _year_month.
Esse pré-processamento significa que o planejador pode consultar com segurança as colunas year e year_month sem que você precise criar manualmente recursos de tempo para cada conjunto de dados.
O planejador pode adicionar filtros de linha simples ao plano, e esse auxiliar transforma esses filtros em filtros pandas.
def apply_filters(df: pd.DataFrame, filters: list) -> pd.DataFrame:
if not filters:
return df
filtered = df.copy()
for f in filters:
col = f.get("column")
op = f.get("op")
val = f.get("value")
if col not in filtered.columns:
continue
try:
val_cast = pd.to_numeric(val)
except Exception:
val_cast = val
if op == "==":
filtered = filtered[filtered[col] == val_cast]
elif op == "!=":
filtered = filtered[filtered[col] != val_cast]
elif op == ">":
filtered = filtered[filtered[col] > val_cast]
elif op == "<":
filtered = filtered[filtered[col] < val_cast]
elif op == ">=":
filtered = filtered[filtered[col] >= val_cast]
elif op == "<=":
filtered = filtered[filtered[col] <= val_cast]
elif op == "contains":
filtered = filtered[filtered[col].astype(str).str.contains(str(val_cast), case=False, na=False)]
return filteredPara cada filtro, a gente verifica se a coluna existe e, se possível, transforma o valor em um número. Depois, faz a comparação certa. Todos os filtros são aplicados um atrás do outro, então você pode juntar condições como “Região contém Oeste” e “Ano >= 2021”.
Essa função é o que conecta as restrições de linguagem natural do plano aos subconjuntos de linhas.
Agora vamos implementar o Data Worker, que é uma camada fina que lê o plano JSON e executa as agregações pandas correspondentes.
def run_analysis_plan(df: pd.DataFrame, plan: dict) -> pd.DataFrame:
op = plan.get("operation")
target_col = plan.get("target_column")
group_by = plan.get("group_by") or []
filters = plan.get("filters") or []
metric = plan.get("metric", "sum")
if filters:
df = apply_filters(df, filters)
if not op or not target_col or target_col not in df.columns:
return df.head(20)
if op in ("aggregate_compare", "group_by_summary", "filter_then_aggregate"):
if not group_by:
if metric == "sum":
value = df[target_col].sum()
elif metric == "mean":
value = df[target_col].mean()
elif metric == "count":
value = df[target_col].count()
elif metric == "max":
value = df[target_col].max()
elif metric == "min":
value = df[target_col].min()
else:
raise ValueError(f"Unsupported metric: {metric}")
return pd.DataFrame({f"{metric}_{target_col}": [value]})
if metric == "sum":
agg_df = df.groupby(group_by)[target_col].sum().reset_index()
elif metric == "mean":
agg_df = df.groupby(group_by)[target_col].mean().reset_index()
elif metric == "count":
agg_df = df.groupby(group_by)[target_col].count().reset_index()
elif metric == "max":
agg_df = df.groupby(group_by)[target_col].max().reset_index()
elif metric == "min":
agg_df = df.groupby(group_by)[target_col].min().reset_index()
else:
raise ValueError(f"Unsupported metric: {metric}")
agg_df = agg_df.sort_values(by=target_col, ascending=False)
return agg_df
return df.head(20)Começamos desmembrando o plano com operação, coluna de destino, colunas de agrupamento, filtros e parâmetros métricos. T
Então, os filtros são aplicados através da função ` apply_filters() `. Se o plano fizer referência a uma coluna inválida, voltaremos a retornar uma pré-visualização simples.
Caso contrário, para operações suportadas, agregamos toda a tabela ou executamos um agrupamento seguido de operações como soma, média, contagem, máximo ou mínimo, e classificamos o resultado pela coluna de métrica.
Esse é o ponto principal da camada de ferramentas: o LLM decide o que calcular, e essa função decide como fazer isso de forma segura com o pandas.
Por fim, transformamos a tabela resultante em um gráfico que combina com o plano chart_type, para que tenhamos números e recursos visuais na saída.
def generate_chart(df: pd.DataFrame, plan: dict):
if not plan.get("need_chart") or df.empty:
return None
chart_type = plan.get("chart_type", "bar")
group_by = plan.get("group_by") or []
target_col = plan.get("target_column")
if not target_col or target_col not in df.columns:
return None
fig, ax = plt.subplots(figsize=(10, 6))
if group_by and len(group_by) > 0:
x_col = group_by[0]
if x_col not in df.columns:
return None
plot_df = df.head(15)
if chart_type == "bar":
bars = ax.bar(range(len(plot_df)), plot_df[target_col], color=sns.color_palette("husl", len(plot_df)))
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
ax.set_ylabel(target_col, fontsize=12)
ax.set_xlabel(x_col, fontsize=12)
for i, (bar, val) in enumerate(zip(bars, plot_df[target_col])):
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{val:,.0f}' if abs(val) > 100 else f'{val:.2f}',
ha='center', va='bottom', fontsize=9)
elif chart_type == "line":
ax.plot(range(len(plot_df)), plot_df[target_col], marker='o', linewidth=2, markersize=8)
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
ax.set_ylabel(target_col, fontsize=12)
ax.set_xlabel(x_col, fontsize=12)
ax.grid(True, alpha=0.3)
elif chart_type == "pie" and len(plot_df) <= 10:
ax.pie(plot_df[target_col], labels=plot_df[x_col], autopct='%1.1f%%', startangle=90)
ax.axis('equal')
else:
bars = ax.bar(range(len(plot_df)), plot_df[target_col])
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
title = f"{target_col} by {x_col}"
else:
ax.bar([target_col], [df[target_col].iloc[0]])
title = f"{target_col}"
ax.set_title(title, fontsize=14, fontweight='bold', pad=20)
fig.tight_layout()
buf = io.BytesIO()
fig.savefig(buf, format="png", dpi=150, bbox_inches='tight')
buf.seek(0)
plt.close(fig)
return bufLemos chart_type, group_by e target_column a partir do plano e criamos uma figura Matplotlib. A função generate_chart() acima retorna um buffer PNG na memória que o aplicativo Streamlit exibe ao lado das principais métricas.
Com essas funções auxiliares em funcionamento, o resto do sistema fica bem mais simples. O Planner usa get_schema_description para projetar a análise, o Data Worker usa as funções preprocess_dates(), apply_filters() e run_analysis_plan() para processar os números, e a função generate_chart() transforma a tabela final em um gráfico.
Agora que temos as funções planejador, trabalhador de dados, explicador e auxiliar em funcionamento, podemos reunir tudo em um aplicativo Streamlit.
st.set_page_config(
page_title="AI Data Analyst Agent",
page_icon="📊",
layout="wide",
initial_sidebar_state="expanded"
)
st.markdown("""
<style>
.main-header {
font-weight: 700;
text-align: center;
}
.sub-header {
text-align: center;
}
.metric-card {
background-
border-radius: 0.5rem;
border-left: 4px solid #1f77b4;
}
.insight-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #2ecc71;
}
</style>
""", unsafe_allow_html=True)
st.markdown("<h1 class='main-header'>AI Data Analyst Agent</h1>", unsafe_allow_html=True)
uploaded_file = st.file_uploader("Upload CSV file", type=["csv"], help="Upload any CSV file to get started")
if uploaded_file is not None:
try:
df = pd.read_csv(uploaded_file)
df = preprocess_dates(df)
except Exception as e:
st.error(f"Error loading CSV: {e}")
st.stop()
with st.expander("Preview Data", expanded=False):
col1, col2, col3 = st.columns(3)
col1.metric("Total Rows", f"{len(df):,}")
col2.metric("Total Columns", len(df.columns))
col3.metric("Memory Usage", f"{df.memory_usage(deep=True).sum() / 1024**2:.1f} MB")
st.dataframe(df.head(100), width='stretch', height=300)
st.markdown("**Numeric Columns Summary:**")
numeric_cols = df.select_dtypes(include=['number']).columns
if len(numeric_cols) > 0:
st.dataframe(df[numeric_cols].describe(), width='stretch')
st.markdown("---")
col1, col2 = st.columns([4, 1])
with col1:
question = st.text_input(
" Ask a question about your data",
placeholder="e.g., Which product category had the highest sales last year?",
label_visibility="collapsed"
)
with col2:
analyze_button = st.button("Analyze", type="primary", width='stretch')
if analyze_button and question.strip():
with st.spinner("Analyzing data..."):
schema_text = get_schema_description(df)
try:
plan, planner_reasoning = call_planner_llm(schema_text, question)
except Exception as e:
st.error(f" Planner agent failed: {e}")
st.stop()
with st.expander(" Analysis Plan", expanded=False):
col1, col2 = st.columns(2)
with col1:
st.json(plan)
with col2:
if planner_reasoning:
st.markdown("**AI Reasoning Process:**")
st.text_area("Planner Reasoning", planner_reasoning[:1000] + "..." if len(planner_reasoning) > 1000 else planner_reasoning,
height=200, label_visibility="collapsed")
try:
result_df = run_analysis_plan(df, plan)
except Exception as e:
st.error(f" Error running analysis: {e}")
st.info(" Tip: Try rephrasing your question or be more specific about the columns you want to analyze.")
st.stop()
st.markdown("---")
st.markdown("## Results")
chart_buf = generate_chart(result_df, plan)
if chart_buf is not None:
col1, col2 = st.columns([2, 1])
with col1:
st.image(chart_buf)
with col2:
st.markdown("### Key Metrics")
target_col = plan.get("target_column")
if target_col in result_df.columns:
st.metric("Total", f"{result_df[target_col].sum():,.2f}")
st.metric("Average", f"{result_df[target_col].mean():,.2f}")
st.metric("Max", f"{result_df[target_col].max():,.2f}")
st.metric("Min", f"{result_df[target_col].min():,.2f}")
else:
st.info("Chart generation skipped (not applicable for this query)")
with st.expander("Results Table", expanded=True):
st.dataframe(result_df, width='stretch', height=400)
csv_data = result_df.to_csv(index=False)
st.download_button(
label="Download Results as CSV",
data=csv_data,
file_name=f"analysis_results_{datetime.now().strftime('%Y%m%d_%H%M%S')}.csv",
mime="text/csv"
)
with st.spinner("Generating insights..."):
result_df_serializable = result_df.copy()
for col in result_df_serializable.columns:
if pd.api.types.is_datetime64_any_dtype(result_df_serializable[col]):
result_df_serializable[col] = result_df_serializable[col].astype(str)
elif pd.api.types.is_period_dtype(result_df_serializable[col]):
result_df_serializable[col] = result_df_serializable[col].astype(str)
result_summary = result_df_serializable.to_dict(orient="records")
explanation, explainer_reasoning = call_explainer_llm(
question=question,
plan=plan,
result_summary=result_summary,
)
st.markdown("---")
st.markdown("## AI Insights")
st.markdown(f'<div class="insight-box">{explanation}</div>', unsafe_allow_html=True)
if explainer_reasoning:
with st.expander(" AI Reasoning Process", expanded=False):
st.text_area("Explainer Reasoning", explainer_reasoning[:1500] + "..." if len(explainer_reasoning) > 1500 else explainer_reasoning,
height=300, label_visibility="collapsed")Na parte superior, a gente configura a página com st.set_page_config e CSS para estilizar o painel. Primeiro, o usuário faz o upload de um CSV, que a gente carrega em um DataFrame, passa por um preprocess_dates e mostra dentro de um expansorde dados Preview Data com contagem de linhas/colunas, uso de memória e um resumo rápido.
Nos bastidores, criamos um esquema com a função get_schema_description(), chamamos call_planner_llm para obter um plano JSON e mostramos tanto o plano quanto o raciocínio do modelo em um expansor. O Data Worker então executa o plano com o pandas, e a seçãoResultados do mostra um gráfico do generate_chart junto com as principais métricas.
Por fim, chamamos call_explainer_llm com a pergunta, o plano e o resumo dos resultados para gerar uma explicação para o caixa AI Insights , com um Expansor do Processo de Raciocínio da IA para quem quiser dar uma olhada nos bastidores.
Salve tudo como app.py e execute:
streamlit run app.pyNo vídeo abaixo, você pode ver uma versão resumida do fluxo de trabalho em ação:
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Matt Crabtree
9 min
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Nadia mhadhbi
Tutorial
Joleen Bothma

