
Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.1K
DeepSeek V3.2 Speciale est un modèle de raisonnement à haute puissance de calcul optimisé pour les flux de travail complexes et assistés par des outils. Au lieu de simplement répondre directement aux questions, il est conçu pour planifier, raisonner et coordonner des outils permettant de créer des systèmes d'analyse agentique.
Dans ce tutoriel, nous utiliserons DeepSeek V3.2 Speciale pour créer un agent d'analyse de données IA qui s'appuie sur n'importe quel fichier CSV. Le flux se présente comme suit :
À la fin, vous disposerez d'une application Streamlit avec des plans explicites et des étapes d'analyse reproductibles. Si vous souhaitez en savoir plus sur les agents IA, je vous recommande de consulter le cursus de compétences « Principes fondamentaux des agents IA ».
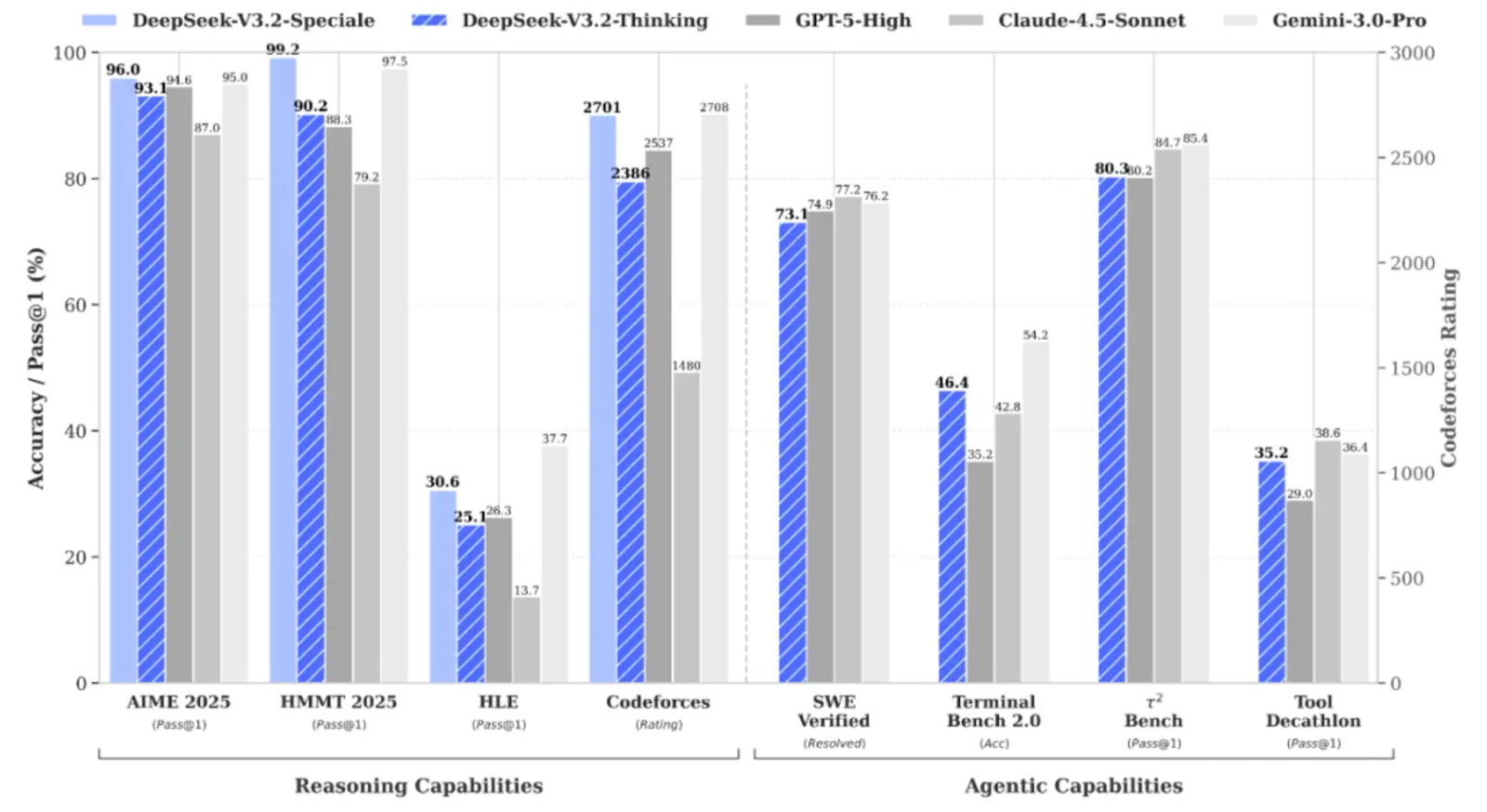
DeepSeek V3.2 Speciale est la variante haute performance et optimisée par apprentissage renforcé de la famille DeepSeek V3.2, spécialement conçue pour le raisonnement approfondi plutôt que pour les conversations informelles.
Il optimise les performances à un niveau tel qu'il rivalise avec des modèles tels que Gemini 3 Pro sur des tâches complexes, et a même obtenu des résultats médaillés d'or lors de benchmarks tels que IMO, CMO, ICPC World Finals et IOI 2025.
DeepSeek V3.2 Speciale est optimisé pour :
La version 3.2 Speciale prend uniquement en charge le mode réflexion et ne prend actuellement pas en charge l'appel d'outils via l'API officielle. Il n'est pas possible de simplement modifier l'temperature e et d'espérer obtenir un JSON propre dès le premier essai. Le modèle Speciale réfléchira longuement et entrecoupait souvent son raisonnement avec la réponse finale.
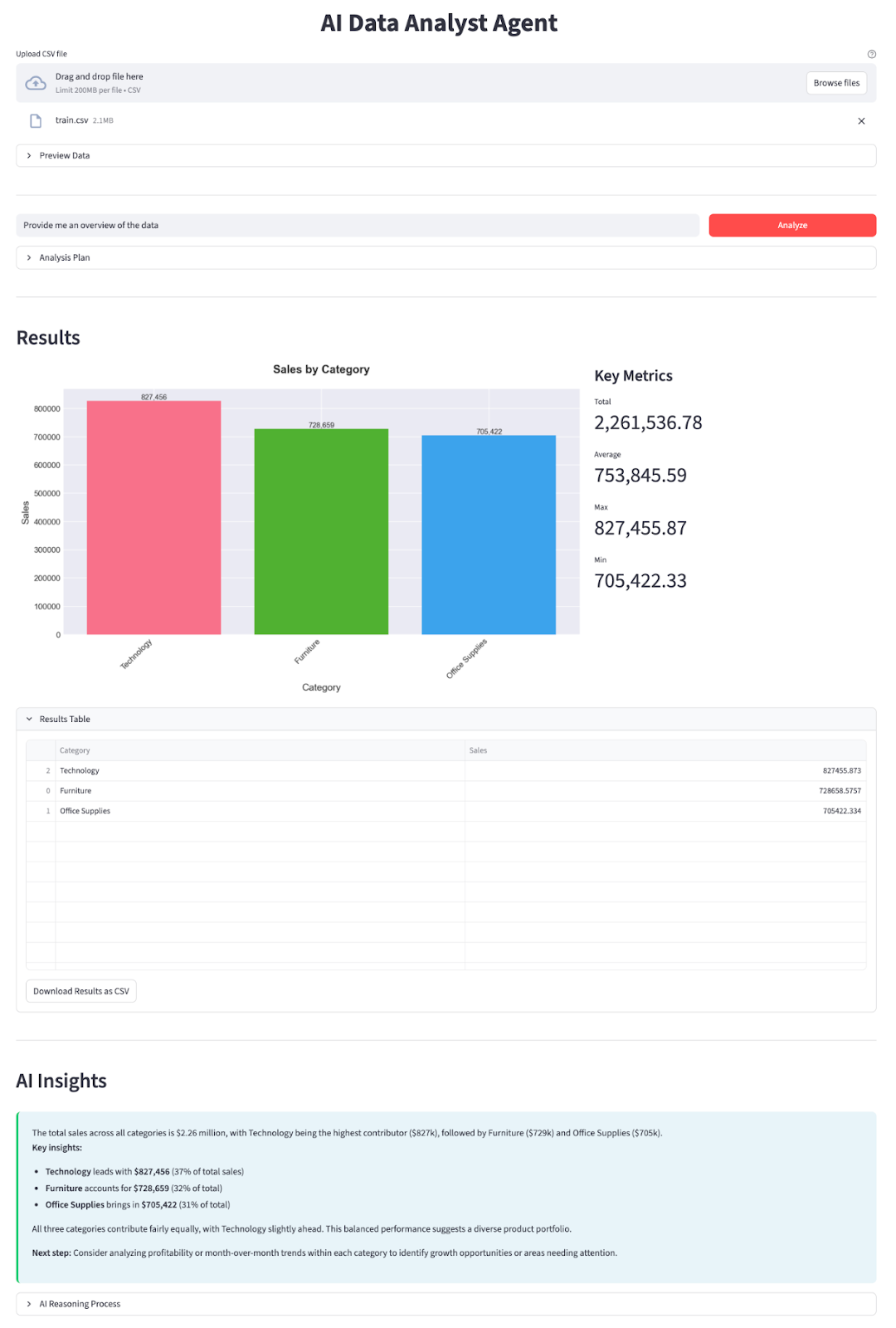
Dans cette section, nous allons mettre en œuvre un agent d'analyse de données IA avec un modèle DeepSeek V3.2 Speciale intégré dans une application Streamlit. À un niveau élevé, voici ce que fait l'application finale :
Construisons-le étape par étape.
Tout d'abord, veuillez installer les dépendances principales et obtenir une clé API à partir de la plateforme API de DeepSeek :
pip install streamlit pandas matplotlib seaborn python-dotenv openaiNous utiliserons quelques bibliothèques essentielles telles que streamlit pour alimenter l'interface utilisateur interactive de l'application web, pandas pour charger et manipuler les données CSV, matplotlib et seaborn pour créer des graphiques et des visualisations. La bibliothèque python-dotenv est utilisée pour charger les variables d'environnement à partir d'un fichier .env, et OpenAI est utilisé comme client pour communiquer avec l'API compatible OpenAI de DeepSeek.
Ensuite, veuillez vous connecter à la plateforme API DeepSeek, accédez à l'onglet Clés API et cliquez sur Créer une nouvelle clé API.
Enfin, veuillez attribuer un nom à votre clé et copier la clé générée.
Veuillez définir votre clé API DeepSeek en tant que variable d'environnement :
export DEEPSEEK_API_KEY="your_api_key_here"Notre environnement est désormais prêt.
Une fois les dépendances installées, l'étape suivante consiste à les intégrer à notre script et à connecter le client DeepSeek qui alimentera nos agents planificateurs et explicateurs.
import io
import json
import os
import re
from datetime import datetime
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import streamlit as st
from dotenv import load_dotenv
from openai import OpenAI
plt.style.use('seaborn-v0_8-darkgrid')
sns.set_palette("husl")
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
if not DEEPSEEK_API_KEY:
raise RuntimeError("Please set DEEPSEEK_API_KEY env variable.")
DEEPSEEK_BASE_URL = os.getenv(
"DEEPSEEK_BASE_URL",
"https://api.deepseek.com/v3.2_speciale_expires_on_20251215",
)
client = OpenAI(
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)Le bloc de code ci-dessus effectue trois opérations. Il importe nos bibliothèques principales, applique un style de graphique et charge les variables d'environnement à partir de .env. Ensuite, il lit DEEPSEEK_API_KEY, le valide et construit un client OpenAI pointant vers le point de terminaison temporaire V3.2 Speciale de DeepSeek afin que chaque appel LLM ultérieur passe par le modèle approprié.
Veuillez noter que DeepSeek V3.2 Speciale est actuellement hébergé sur un point de terminaison temporaire qui expirera le 15 décembre 2025. Par la suite, l'URL de déploiement peut être modifiée, mais le nom du modèle restera deepseek-reasoner. Pour obtenir les derniers points de terminaison et détails d'utilisation, veuillez vous référer à la documentation officielle DeepSeek.
Une fois le client configuré, définissons nos deux agents : l'un pour planifier l'analyse, l'autre pour expliquer les résultats.
Une fois le client en place, nous pouvons créer l'agent Planner, qui détermine les analyses à effectuer sur les données. Au lieu de permettre au modèle de manipuler directement le DataFrame, nous lui demandons de produire un plan JSON structuré que notre « data worker » Python peut exécuter en toute sécurité.
Le planificateur affiche une description textuelle de l'ensemble de données ainsi que la question de l'utilisateur, puis renvoie un objet JSON décrivant l'opération, les colonnes de regroupement, les filtres, la métrique et le type de graphique.
def call_planner_llm(schema_text: str, question: str) -> tuple[dict, str]:
system_prompt = """
You are a data analysis planner. Convert user questions into JSON plans.
JSON Structure (REQUIRED):
{
"operation": "group_by_summary",
"group_by": ["column_name"],
"filters": [],
"target_column": "column_to_analyze",
"metric": "sum",
"need_chart": true,
"chart_type": "bar"
}
Fields:
- operation: Always use "group_by_summary" (most flexible)
- group_by: Columns to group by (e.g., ["Product Name"] or ["Category", "Region"])
- filters: Optional filters, e.g., [{"column": "Year", "op": "==", "value": "2023"}]
- target_column: Column to aggregate (must exist in schema!)
- metric: One of: sum, mean, count, max, min
- need_chart: true (always show chart)
- chart_type: bar, line, or pie
Quick Rules:
- Use ONLY columns from the provided schema
- For "this year", look for year columns or use the latest year in data
- For "top N", use appropriate group_by and metric
- For comparisons, use filters to split groups
Think briefly, then output the complete JSON.
""".strip()
messages = [
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": f"Dataset:\n{schema_text}\n\nQuestion:\n{question}\n\nReminder: After analyzing, output the complete JSON plan.",
},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
max_tokens=8192,
)
message = resp.choices[0].message
content = message.content or ""
content = content.strip()
reasoning_content = getattr(message, 'reasoning_content', None) or ""
finish_reason = resp.choices[0].finish_reason
def extract_json_from_text(text: str) -> dict | None:
if not text:
return None
try:
return json.loads(text)
except json.JSONDecodeError:
pass
code_block_match = re.search(r'```(?:json)?\s*(\{[\s\S]*?\})\s*```', text, re.DOTALL)
if code_block_match:
try:
return json.loads(code_block_match.group(1))
except json.JSONDecodeError:
pass
def find_all_json_objects(s):
objects = []
depth = 0
start_idx = None
in_string = False
escape_next = False
for i, char in enumerate(s):
if escape_next:
escape_next = False
continue
if char == '\\':
escape_next = True
continue
if char == '"' and not in_string:
in_string = True
elif char == '"' and in_string:
in_string = False
elif not in_string:
if char == '{':
if depth == 0:
start_idx = i
depth += 1
elif char == '}':
depth -= 1
if depth == 0 and start_idx is not None:
objects.append(s[start_idx:i+1])
start_idx = None
return objects
for candidate in find_all_json_objects(text):
try:
parsed = json.loads(candidate)
if isinstance(parsed, dict) and any(k in parsed for k in ['operation', 'target_column', 'metric', 'group_by']):
return parsed
except json.JSONDecodeError:
continue
for i in range(len(text)):
if text[i] == '{':
decoder = json.JSONDecoder()
try:
parsed, _ = decoder.raw_decode(text[i:])
if isinstance(parsed, dict) and any(k in parsed for k in ['operation', 'target_column', 'metric', 'group_by']):
return parsed
except json.JSONDecodeError:
continue
return None
if reasoning_content:
plan = extract_json_from_text(reasoning_content)
if plan is not None:
return plan, reasoning_content
plan = extract_json_from_text(content)
if plan is not None:
return plan, reasoning_content
error_msg = (
f"Planner returned non-JSON content.\n"
f"Finish reason: {finish_reason}\n"
f"Content received: {repr(content[:500]) if content else '(empty)'}\n"
f"Reasoning content length: {len(reasoning_content) if reasoning_content else 0}\n"
f"Reasoning content sample: {reasoning_content[:500] if reasoning_content else '(none)'}"
)
if finish_reason == "length":
error_msg += "\n\nNote: Response was truncated due to token limit. The model didn't finish generating the JSON."
raise ValueError(error_msg)Tout d'abord, l'interface system_prompt définit le contrat pour l'agent de planification, qui convertit la requête utilisateur en un plan JSON, et spécifie exactement les champs attendus, tels qu'une liste de colonnes d'group_by, des filters facultatives, un target_column, un metric et un chart_type.
Nous ajoutons également quelques heuristiques (telles que la manière de traiter « cette année » ou « top N ») afin que le modèle se comporte davantage comme un analyste de données junior que comme un chatbot générique.
Ensuite, nous élaborons le message système qui contient les instructions et regroupe deux éléments, à savoir une description textuelle du schéma de l'ensemble de données (noms de colonnes, types de données, exemples de lignes) et la question de l'utilisateur. Cela fournit au modèle suffisamment de contexte pour sélectionner des noms de colonnes valides et choisir une agrégation pertinente pour la question posée.
DeepSeek V3.2 Speciale est ensuite appelé via client.chat.completions.create(). Comme il s'agit d'un modèle de raisonnement, il peut produire deux canaux de sortie : une chaîne de contenu visible et une chaîne d'reasoning_content s interne où se trouvent souvent la plupart des « réflexions » et la réponse finale. Nous extrayons les deux éléments de la réponse et conservons une trace de l'finish_reason afin de pouvoir détecter toute troncature.
Le travail le plus complexe est effectué dans la fonction « extract_json_from_text() ». Étant donné que les modèles de raisonnement ne renvoient pas toujours un JSON propre, nous l'intégrons dans un markdown. Afin de garantir la fiabilité du planificateur, cette fonction d'aide applique plusieurs stratégies successivement :
json.loadsPour chaque candidat, seuls les objets qui semblent constituer un plan valide sont acceptés, c'est-à-dire qu'ils doivent contenir au moins l'un des champs suivants : operation, target_column, metric ou group_by.
Enfin, nous relions tous ces éléments en appliquant la fonction extract_json_from_text() à reasoning_content.
Ensemble, ces éléments transforment toute question en langage naturel et tout instantané de schéma en un plan d'analyse structuré.
Une fois que le Data Worker a effectué l'analyse avec Pandas, nous renvoyons le tableau des résultats ainsi que le plan JSON à DeepSeek et transformons le tout en un résumé contenant des informations concrètes.
def call_explainer_llm(question: str, plan: dict, result_summary: list) -> tuple[str, str]:
system_prompt = """
You are a senior data analyst explaining insights to business stakeholders.
The user asked a question about their CSV data.
Another agent already designed an analysis plan and we executed it in Python.
You will now explain the results in clear, engaging, non-technical language.
Requirements:
- Start with a direct 1-2 sentence answer to their question
- Use bullet points (3-5 points) to highlight key insights, trends, or comparisons
- Include specific numbers and percentages where relevant
- Use business-friendly language (avoid technical jargon like "aggregation", "groupby")
- If the data shows interesting patterns, point them out
- End with a brief recommendation or next step if appropriate
Keep it concise and actionable.
""".strip()
limited_summary = result_summary[:20] if len(result_summary) > 20 else result_summary
user_content = f"""
User question:
{question}
Analysis performed:
{json.dumps(plan, indent=2)}
Results (top rows):
{json.dumps(limited_summary, indent=2)}
Total rows in result: {len(result_summary)}
""".strip()
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
max_tokens=2048,
)
message = resp.choices[0].message
content = message.content or ""
content = content.strip()
reasoning_content = getattr(message, 'reasoning_content', None) or ""
if not content:
if reasoning_content:
content = reasoning_content.strip()
return (content if content else "Unable to generate explanation from the model response.",
reasoning_content)L'agent explicatif commence par définir l'system_prompt, qui indique à DeepSeek de se comporter comme un analyste de données expérimenté s'adressant à des parties prenantes commerciales. Nous précisons la forme exacte de la réponse souhaitée, ainsi que d'autres recommandations pour la rédaction de la réponse.
Ensuite, nous préparons user_content, qui fournit au modèle tout le contexte dont il a besoin. Nous transmettons la requête d'origine, le plan d'analyse JSON (afin qu'il sache quels calculs ont été effectués) et le nombre total de lignes.
Nous assemblons ensuite la liste des messages et appelons DeepSeek V3.2 Speciale via client.chat.completions.create(). Tout comme dans le planificateur, le modèle peut renvoyer du texte à la fois dans content et reasoning_content. Nous ajoutons donc les deux et nous nous rabattons sur reasoning_content si content est vide.
Enfin, la fonction renvoie un tuple comprenant à la fois l'explication et la chaîne de raisonnement brute qui s'affiche dans l'expandeur.
Avec cet agent explicatif en place, la boucle est bouclée :
Avant de permettre à DeepSeek de planifier quoi que ce soit, il est nécessaire de décrire clairement les données et de les rendre faciles à analyser. Ceci est réalisé à l'aide d'un ensemble de fonctions d'assistance.
L'agent Planner ne peut pas visualiser directement votre DataFrame, c'est pourquoi nous lui envoyons un résumé textuel compact de l'ensemble de données.
def get_schema_description(df: pd.DataFrame, max_rows: int = 3) -> str:
schema_lines = ["Columns:"]
for col, dtype in df.dtypes.items():
if dtype == 'object' and df[col].nunique() < 20:
unique_vals = df[col].dropna().unique()[:5]
schema_lines.append(f"- {col} ({dtype}) - sample values: {', '.join(map(str, unique_vals))}")
else:
schema_lines.append(f"- {col} ({dtype})")
sample = df.head(max_rows).to_markdown(index=False)
return "\n".join(schema_lines) + "\n\nSample rows:\n" + sampleCette fonction parcourt toutes les colonnes. Il comprend également quelques exemples de valeurs pour des éléments tels que les noms de produits, les régions ou les catégories. F
Enfin, il ajoute un bref tableau récapitulatif des premières lignes, afin que le modèle dispose d'exemples concrets sur lesquels s'appuyer.
Cette chaîne de schéma représente la vision du planificateur sur vos données, lui permettant de sélectionner des noms de colonnes et des regroupements valides.
Nous détectons automatiquement les colonnes de dates et ajoutons des champs d'aide tels que _year et _year_month, ce qui facilite la réponse de DeepSeek à des questions telles que « l'année dernière » ou « par mois ».
def preprocess_dates(df: pd.DataFrame) -> pd.DataFrame:
df = df.copy()
date_columns = []
for col in df.columns:
if pd.api.types.is_datetime64_any_dtype(df[col]):
date_columns.append(col)
continue
if any(x in col.lower() for x in ['date', 'time', 'day']):
try:
df[col] = pd.to_datetime(df[col], errors='coerce')
if df[col].notna().sum() > 0:
date_columns.append(col)
except:
pass
for col in date_columns:
if col in df.columns and pd.api.types.is_datetime64_any_dtype(df[col]):
df[f'{col}_year'] = df[col].dt.year
df[f'{col}_month'] = df[col].dt.month
df[f'{col}_year_month'] = df[col].dt.to_period('M').astype(str)
return dfTout d'abord, nous analysons les colonnes, et si une colonne est déjà de type date/heure ou si son nom fait référence à une date (comme order_date ou day), nous essayons de l'analyser avec pd.to_datetime. Pour chaque colonne de date, nous créons des caractéristiques telles que _year, _month et _year_month.
Ce prétraitement permet au planificateur de référencer en toute sécurité les colonnes year et year_month sans que vous ayez à créer manuellement des caractéristiques temporelles pour chaque ensemble de données.
Le planificateur peut ajouter des filtres de ligne simples au plan, et cet assistant les transforme en filtres pandas.
def apply_filters(df: pd.DataFrame, filters: list) -> pd.DataFrame:
if not filters:
return df
filtered = df.copy()
for f in filters:
col = f.get("column")
op = f.get("op")
val = f.get("value")
if col not in filtered.columns:
continue
try:
val_cast = pd.to_numeric(val)
except Exception:
val_cast = val
if op == "==":
filtered = filtered[filtered[col] == val_cast]
elif op == "!=":
filtered = filtered[filtered[col] != val_cast]
elif op == ">":
filtered = filtered[filtered[col] > val_cast]
elif op == "<":
filtered = filtered[filtered[col] < val_cast]
elif op == ">=":
filtered = filtered[filtered[col] >= val_cast]
elif op == "<=":
filtered = filtered[filtered[col] <= val_cast]
elif op == "contains":
filtered = filtered[filtered[col].astype(str).str.contains(str(val_cast), case=False, na=False)]
return filteredPour chaque filtre, nous vérifions que la colonne existe, et nous convertissons la valeur en nombre si possible, puis nous appliquons la comparaison appropriée. Tous les filtres sont appliqués de manière séquentielle, ce qui vous permet de combiner naturellement des conditions telles que « Région contient Ouest » et « Année >= 2021 ».
Cette fonction permet de relier les contraintes de langage naturel du plan aux sous-ensembles de lignes.
Nous mettons actuellement en œuvre le Data Worker, qui est une couche mince qui lit le plan JSON et exécute les agrégations pandas correspondantes.
def run_analysis_plan(df: pd.DataFrame, plan: dict) -> pd.DataFrame:
op = plan.get("operation")
target_col = plan.get("target_column")
group_by = plan.get("group_by") or []
filters = plan.get("filters") or []
metric = plan.get("metric", "sum")
if filters:
df = apply_filters(df, filters)
if not op or not target_col or target_col not in df.columns:
return df.head(20)
if op in ("aggregate_compare", "group_by_summary", "filter_then_aggregate"):
if not group_by:
if metric == "sum":
value = df[target_col].sum()
elif metric == "mean":
value = df[target_col].mean()
elif metric == "count":
value = df[target_col].count()
elif metric == "max":
value = df[target_col].max()
elif metric == "min":
value = df[target_col].min()
else:
raise ValueError(f"Unsupported metric: {metric}")
return pd.DataFrame({f"{metric}_{target_col}": [value]})
if metric == "sum":
agg_df = df.groupby(group_by)[target_col].sum().reset_index()
elif metric == "mean":
agg_df = df.groupby(group_by)[target_col].mean().reset_index()
elif metric == "count":
agg_df = df.groupby(group_by)[target_col].count().reset_index()
elif metric == "max":
agg_df = df.groupby(group_by)[target_col].max().reset_index()
elif metric == "min":
agg_df = df.groupby(group_by)[target_col].min().reset_index()
else:
raise ValueError(f"Unsupported metric: {metric}")
agg_df = agg_df.sort_values(by=target_col, ascending=False)
return agg_df
return df.head(20)Nous commençons par décomposer le plan en opération, colonne cible, colonnes de regroupement, filtres et paramètres métriques. T
Ensuite, les filtres sont appliqués via la fonction apply_filters(). Si le plan fait référence à une colonne non valide, nous nous rabattons sur l'affichage d'un simple aperçu.
Sinon, pour les opérations prises en charge, nous effectuons soit une agrégation sur l'ensemble de la table, soit un regroupement suivi d'opérations telles que somme, moyenne, nombre, maximum ou minimum, puis nous trions le résultat par colonne de métrique.
Il s'agit du cœur de la couche des outils : le LLM détermine ce qu'il convient de calculer, et cette fonction détermine comment le calculer en toute sécurité avec pandas.
Enfin, nous transformons le tableau obtenu en un graphique qui correspond à l'chart_type du plan, afin d'obtenir à la fois des chiffres et des éléments visuels dans le résultat.
def generate_chart(df: pd.DataFrame, plan: dict):
if not plan.get("need_chart") or df.empty:
return None
chart_type = plan.get("chart_type", "bar")
group_by = plan.get("group_by") or []
target_col = plan.get("target_column")
if not target_col or target_col not in df.columns:
return None
fig, ax = plt.subplots(figsize=(10, 6))
if group_by and len(group_by) > 0:
x_col = group_by[0]
if x_col not in df.columns:
return None
plot_df = df.head(15)
if chart_type == "bar":
bars = ax.bar(range(len(plot_df)), plot_df[target_col], color=sns.color_palette("husl", len(plot_df)))
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
ax.set_ylabel(target_col, fontsize=12)
ax.set_xlabel(x_col, fontsize=12)
for i, (bar, val) in enumerate(zip(bars, plot_df[target_col])):
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{val:,.0f}' if abs(val) > 100 else f'{val:.2f}',
ha='center', va='bottom', fontsize=9)
elif chart_type == "line":
ax.plot(range(len(plot_df)), plot_df[target_col], marker='o', linewidth=2, markersize=8)
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
ax.set_ylabel(target_col, fontsize=12)
ax.set_xlabel(x_col, fontsize=12)
ax.grid(True, alpha=0.3)
elif chart_type == "pie" and len(plot_df) <= 10:
ax.pie(plot_df[target_col], labels=plot_df[x_col], autopct='%1.1f%%', startangle=90)
ax.axis('equal')
else:
bars = ax.bar(range(len(plot_df)), plot_df[target_col])
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
title = f"{target_col} by {x_col}"
else:
ax.bar([target_col], [df[target_col].iloc[0]])
title = f"{target_col}"
ax.set_title(title, fontsize=14, fontweight='bold', pad=20)
fig.tight_layout()
buf = io.BytesIO()
fig.savefig(buf, format="png", dpi=150, bbox_inches='tight')
buf.seek(0)
plt.close(fig)
return bufNous avons consulté les articles chart_type, group_by et target_column du plan et avons créé un graphique Matplotlib. La fonction d'generate_chart() s ci-dessus renvoie un tampon PNG en mémoire que l'application Streamlit affiche à côté des indicateurs clés.
Grâce à ces fonctions d'aide, le reste du système devient beaucoup plus simple. Le planificateur utilise get_schema_description pour concevoir l'analyse, le responsable des données utilise les fonctions preprocess_dates(), apply_filters() et run_analysis_plan() pour traiter les chiffres, et la fonction generate_chart() transforme le tableau final en graphique.
Maintenant que nous disposons des fonctions de planification, de traitement des données, d'explication et d'assistance, nous pouvons intégrer l'ensemble dans une application Streamlit.
st.set_page_config(
page_title="AI Data Analyst Agent",
page_icon="📊",
layout="wide",
initial_sidebar_state="expanded"
)
st.markdown("""
<style>
.main-header {
font-weight: 700;
text-align: center;
}
.sub-header {
text-align: center;
}
.metric-card {
background-
border-radius: 0.5rem;
border-left: 4px solid #1f77b4;
}
.insight-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #2ecc71;
}
</style>
""", unsafe_allow_html=True)
st.markdown("<h1 class='main-header'>AI Data Analyst Agent</h1>", unsafe_allow_html=True)
uploaded_file = st.file_uploader("Upload CSV file", type=["csv"], help="Upload any CSV file to get started")
if uploaded_file is not None:
try:
df = pd.read_csv(uploaded_file)
df = preprocess_dates(df)
except Exception as e:
st.error(f"Error loading CSV: {e}")
st.stop()
with st.expander("Preview Data", expanded=False):
col1, col2, col3 = st.columns(3)
col1.metric("Total Rows", f"{len(df):,}")
col2.metric("Total Columns", len(df.columns))
col3.metric("Memory Usage", f"{df.memory_usage(deep=True).sum() / 1024**2:.1f} MB")
st.dataframe(df.head(100), width='stretch', height=300)
st.markdown("**Numeric Columns Summary:**")
numeric_cols = df.select_dtypes(include=['number']).columns
if len(numeric_cols) > 0:
st.dataframe(df[numeric_cols].describe(), width='stretch')
st.markdown("---")
col1, col2 = st.columns([4, 1])
with col1:
question = st.text_input(
" Ask a question about your data",
placeholder="e.g., Which product category had the highest sales last year?",
label_visibility="collapsed"
)
with col2:
analyze_button = st.button("Analyze", type="primary", width='stretch')
if analyze_button and question.strip():
with st.spinner("Analyzing data..."):
schema_text = get_schema_description(df)
try:
plan, planner_reasoning = call_planner_llm(schema_text, question)
except Exception as e:
st.error(f" Planner agent failed: {e}")
st.stop()
with st.expander(" Analysis Plan", expanded=False):
col1, col2 = st.columns(2)
with col1:
st.json(plan)
with col2:
if planner_reasoning:
st.markdown("**AI Reasoning Process:**")
st.text_area("Planner Reasoning", planner_reasoning[:1000] + "..." if len(planner_reasoning) > 1000 else planner_reasoning,
height=200, label_visibility="collapsed")
try:
result_df = run_analysis_plan(df, plan)
except Exception as e:
st.error(f" Error running analysis: {e}")
st.info(" Tip: Try rephrasing your question or be more specific about the columns you want to analyze.")
st.stop()
st.markdown("---")
st.markdown("## Results")
chart_buf = generate_chart(result_df, plan)
if chart_buf is not None:
col1, col2 = st.columns([2, 1])
with col1:
st.image(chart_buf)
with col2:
st.markdown("### Key Metrics")
target_col = plan.get("target_column")
if target_col in result_df.columns:
st.metric("Total", f"{result_df[target_col].sum():,.2f}")
st.metric("Average", f"{result_df[target_col].mean():,.2f}")
st.metric("Max", f"{result_df[target_col].max():,.2f}")
st.metric("Min", f"{result_df[target_col].min():,.2f}")
else:
st.info("Chart generation skipped (not applicable for this query)")
with st.expander("Results Table", expanded=True):
st.dataframe(result_df, width='stretch', height=400)
csv_data = result_df.to_csv(index=False)
st.download_button(
label="Download Results as CSV",
data=csv_data,
file_name=f"analysis_results_{datetime.now().strftime('%Y%m%d_%H%M%S')}.csv",
mime="text/csv"
)
with st.spinner("Generating insights..."):
result_df_serializable = result_df.copy()
for col in result_df_serializable.columns:
if pd.api.types.is_datetime64_any_dtype(result_df_serializable[col]):
result_df_serializable[col] = result_df_serializable[col].astype(str)
elif pd.api.types.is_period_dtype(result_df_serializable[col]):
result_df_serializable[col] = result_df_serializable[col].astype(str)
result_summary = result_df_serializable.to_dict(orient="records")
explanation, explainer_reasoning = call_explainer_llm(
question=question,
plan=plan,
result_summary=result_summary,
)
st.markdown("---")
st.markdown("## AI Insights")
st.markdown(f'<div class="insight-box">{explanation}</div>', unsafe_allow_html=True)
if explainer_reasoning:
with st.expander(" AI Reasoning Process", expanded=False):
st.text_area("Explainer Reasoning", explainer_reasoning[:1500] + "..." if len(explainer_reasoning) > 1500 else explainer_reasoning,
height=300, label_visibility="collapsed")En haut, nous configurons la page avec l'st.set_page_config e et le CSS pour styliser le tableau de bord. L'utilisateur commence par télécharger un fichier CSV, que nous chargeons dans un DataFrame, traitons à l'aide d'preprocess_dates, puis affichons dans unaperçu d' . L'aperçu contient le nombre de lignes/colonnes, l'utilisation de la mémoire et un résumé rapide.
En arrière-plan, nous construisons un schéma à l'aide de la fonction get_schema_description(), appelons call_planner_llm pour obtenir un plan JSON, et affichons à la fois le plan et le raisonnement du modèle dans un expandeur. Le Data Worker exécute ensuite le plan avec pandas, et la sectionRésultats de l' affiche un graphique provenant de generate_chart ainsi que les indicateurs clés.
Enfin, nous appelons call_explainer_llm avec la question, le plan et le résumé des résultats afin de générer une explication pour l' AI Insights , avec un expandeur de raisonnement IA pour ceux qui souhaitent en savoir plus.
Veuillez enregistrer tous les éléments sous le nom app.py et exécutez :
streamlit run app.pyDans la vidéo ci-dessous, vous pouvez observer une version abrégée du flux de travail en action :
Meilleurs cours DataCamp
Cours
Cours
Cours