
Kurs
Agentische Systeme mit LangChain entwerfen
3 Std.
12.1K
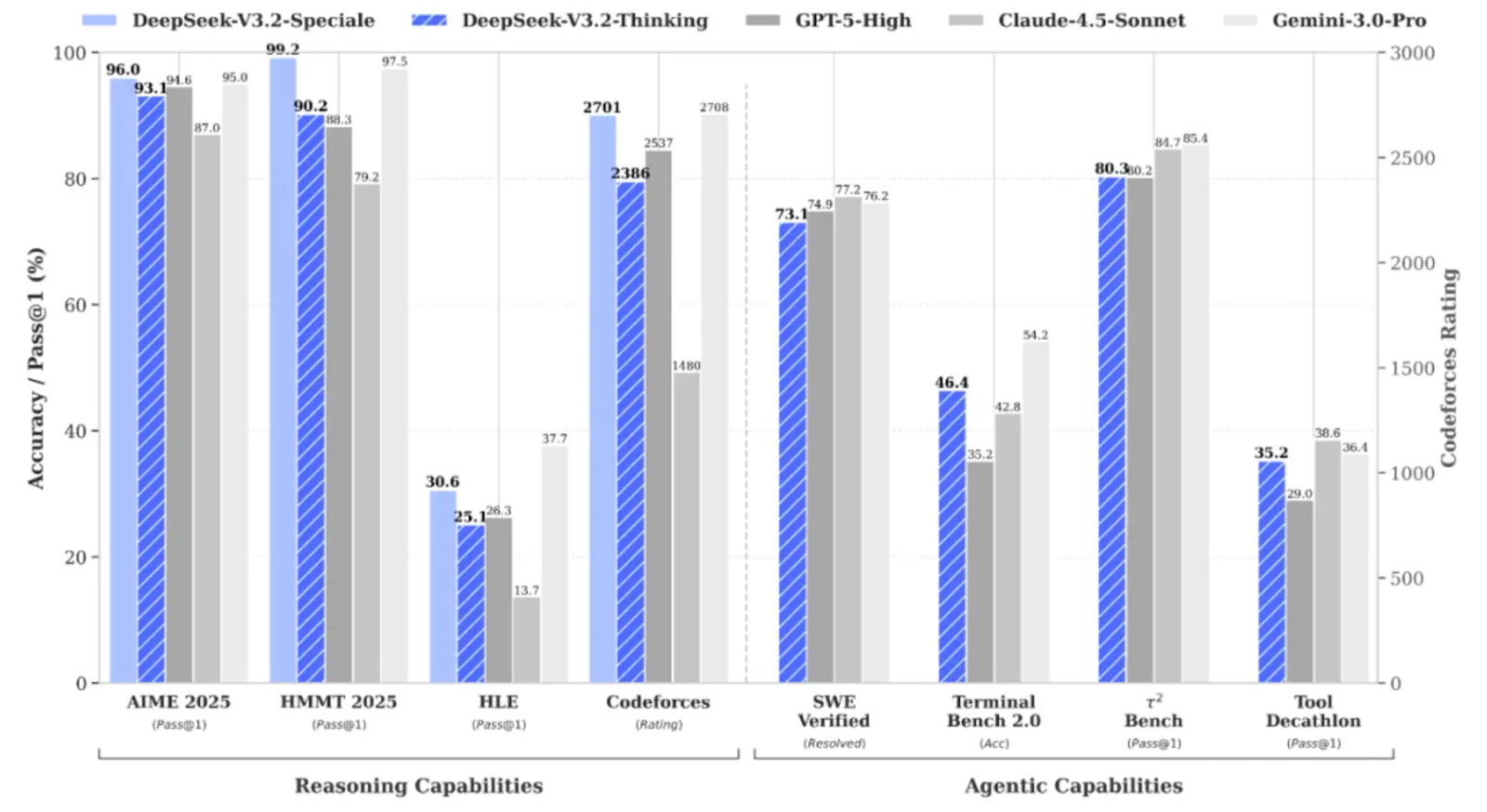
DeepSeek V3.2 Speciale ist ein hochleistungsfähiges Schlussfolgerungsmodell, das für komplexe, durch Tools unterstützte Arbeitsabläufe optimiert ist. Anstatt Fragen einfach direkt zu beantworten, ist es so gemacht, dass man Tools für den Aufbau von agentenbasierten Analysesystemen planen, begründen und koordinieren kann.
In diesem Tutorial nutzen wir DeepSeek V3.2 Speciale, um einen KI-Datenanalysten-Agenten zu erstellen, der auf jeder CSV-Datei läuft. Der Ablauf sieht so aus:
Am Ende hast du eine Streamlit-App mit klaren Plänen und reproduzierbaren Analyseschritten. Wenn du mehr über KI-Agenten erfahren möchtest, empfehle ich dir, dir den Skill Track „Grundlagen von KI-Agenten” anzuschauen.
DeepSeek V3.2 Speciale ist die Variante der DeepSeek V3.2-Familie mit hoher Rechenleistung und verstärktem Reinforcement Learning, die speziell für tiefgreifende Schlussfolgerungen und nicht für zwanglose Unterhaltungen entwickelt wurde.
Es bringt die Leistung so weit, dass es bei komplizierten Aufgaben mit Modellen wie Gemini 3 Pro mithalten kann, und hat sogar Goldmedaillen bei Benchmarks wie IMO, CMO, ICPC World Finals und IOI 2025 geholt.
DeepSeek V3.2 Speciale ist optimiert für:
V3.2 Speciale unterstützt nur den Denkmodus und kann im Moment keine Tools über die offizielle API aufrufen. Du kannst nicht einfach die Datei „ temperature “ anpassen und erwarten, dass du beim ersten Versuch sauberes JSON bekommst. Das Speciale-Modell wird lange nachdenken und seine Überlegungen oft mit der endgültigen Antwort vermischen.
In diesem Abschnitt machen wir einen KI-Datenanalysten-Agenten mit einem DeepSeek V3.2 Speciale-Modell, das in eine Streamlit-App eingebettet ist. Auf hoher Ebene macht die fertige App Folgendes:
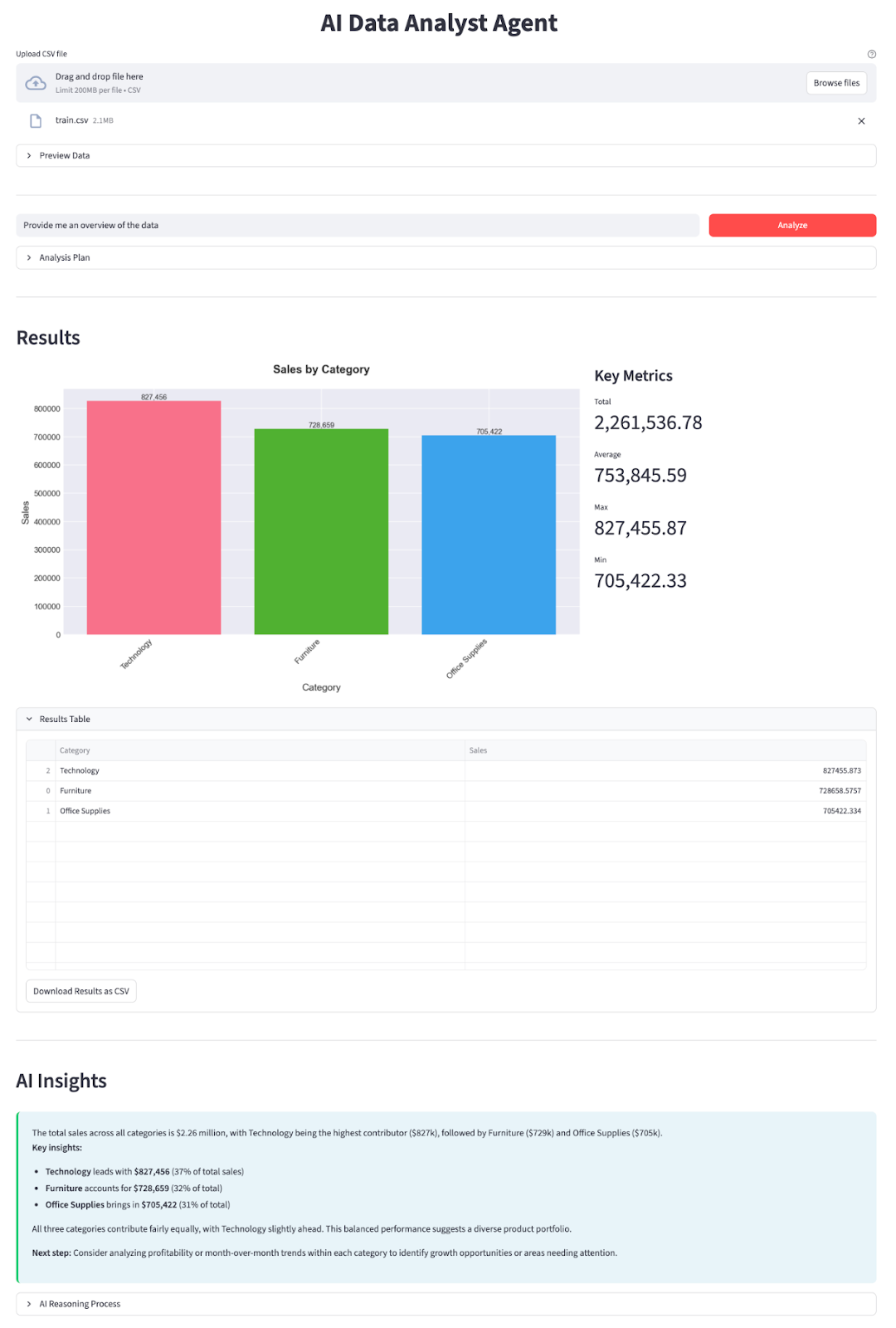
Lass es uns Schritt für Schritt aufbauen.
Zuerst installierst du die wichtigsten Abhängigkeiten und holst dir einen API-Schlüssel von der API-Plattform von DeepSeek:
pip install streamlit pandas matplotlib seaborn python-dotenv openaiWir werden ein paar Kernbibliotheken wie Streamlit für die interaktive Web-App-Benutzeroberfläche, Pandas zum Laden und Bearbeiten von CSV-Daten sowie Matplotlib und Seaborn zum Erstellen von Diagrammen und Visualisierungen nutzen. Die Bibliothek python-dotenv wird benutzt, um Umgebungsvariablen aus einer .env-Datei zu laden, und OpenAI als Client für die Kommunikation mit der OpenAI-kompatiblen API von DeepSeek.
Als Nächstes logg dich bei der DeepSeek-API-Plattform ein, geh zum Tab „API-Schlüssel” und klick auf „Neuen API-Schlüssel erstellen”.
Gib deinem Schlüssel zum Schluss einen Namen und kopiere den generierten Schlüssel.
Leg deinen DeepSeek-API-Schlüssel als Umgebungsvariable fest:
export DEEPSEEK_API_KEY="your_api_key_here"Jetzt ist unsere Umgebung fertig.
Nachdem die Abhängigkeiten installiert sind, müssen wir sie als Nächstes in unser Skript einbinden und den DeepSeek-Client anschließen, der unsere Planer- und Erklärer-Agenten antreibt.
import io
import json
import os
import re
from datetime import datetime
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import streamlit as st
from dotenv import load_dotenv
from openai import OpenAI
plt.style.use('seaborn-v0_8-darkgrid')
sns.set_palette("husl")
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
if not DEEPSEEK_API_KEY:
raise RuntimeError("Please set DEEPSEEK_API_KEY env variable.")
DEEPSEEK_BASE_URL = os.getenv(
"DEEPSEEK_BASE_URL",
"https://api.deepseek.com/v3.2_speciale_expires_on_20251215",
)
client = OpenAI(
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)Der obige Code-Block macht drei Sachen. Es importiert unsere Kernbibliotheken, wendet einen Plotstil an und lädt Umgebungsvariablen von .env. Dann liest es „ DEEPSEEK_API_KEY “, überprüft es und baut einen OpenAI-Client, der auf den temporären V3.2 Speciale-Endpunkt von DeepSeek zeigt, damit jeder nachfolgende LLM-Aufruf über das richtige Modell läuft.
Hey, DeepSeek V3.2 Speciale läuft gerade über einen temporären Endpunkt, der am 15. Dezember 2025 abläuft. Danach kann sich die Bereitstellungs-URL ändern, aber der Modellname bleibt deepseek-reasoner. Die neuesten Endpunkte und Nutzungsdetails findest du in der offiziellen DeepSeek-Dokumentation.
Nachdem der Client eingerichtet ist, legen wir unsere beiden Agenten fest – einen für die Planung der Analyse und einen für die Erklärung der Ergebnisse.
Sobald der Client eingerichtet ist, können wir den Planner Agent erstellen, der entscheidet, welche Analysen mit den Daten durchgeführt werden sollen. Anstatt das Modell direkt auf das DataFrame zugreifen zu lassen, bitten wir es, einen strukturierten JSON-Plan zu erstellen, den unser Python-„Datenarbeiter“ sicher ausführen kann.
Der Planer sieht eine Textbeschreibung des Datensatzes zusammen mit der Frage des Benutzers und gibt ein JSON-Objekt zurück, das die Operation, Gruppierungsspalten, Filter, Metrik und den Diagrammtyp beschreibt.
def call_planner_llm(schema_text: str, question: str) -> tuple[dict, str]:
system_prompt = """
You are a data analysis planner. Convert user questions into JSON plans.
JSON Structure (REQUIRED):
{
"operation": "group_by_summary",
"group_by": ["column_name"],
"filters": [],
"target_column": "column_to_analyze",
"metric": "sum",
"need_chart": true,
"chart_type": "bar"
}
Fields:
- operation: Always use "group_by_summary" (most flexible)
- group_by: Columns to group by (e.g., ["Product Name"] or ["Category", "Region"])
- filters: Optional filters, e.g., [{"column": "Year", "op": "==", "value": "2023"}]
- target_column: Column to aggregate (must exist in schema!)
- metric: One of: sum, mean, count, max, min
- need_chart: true (always show chart)
- chart_type: bar, line, or pie
Quick Rules:
- Use ONLY columns from the provided schema
- For "this year", look for year columns or use the latest year in data
- For "top N", use appropriate group_by and metric
- For comparisons, use filters to split groups
Think briefly, then output the complete JSON.
""".strip()
messages = [
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": f"Dataset:\n{schema_text}\n\nQuestion:\n{question}\n\nReminder: After analyzing, output the complete JSON plan.",
},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
max_tokens=8192,
)
message = resp.choices[0].message
content = message.content or ""
content = content.strip()
reasoning_content = getattr(message, 'reasoning_content', None) or ""
finish_reason = resp.choices[0].finish_reason
def extract_json_from_text(text: str) -> dict | None:
if not text:
return None
try:
return json.loads(text)
except json.JSONDecodeError:
pass
code_block_match = re.search(r'```(?:json)?\s*(\{[\s\S]*?\})\s*```', text, re.DOTALL)
if code_block_match:
try:
return json.loads(code_block_match.group(1))
except json.JSONDecodeError:
pass
def find_all_json_objects(s):
objects = []
depth = 0
start_idx = None
in_string = False
escape_next = False
for i, char in enumerate(s):
if escape_next:
escape_next = False
continue
if char == '\\':
escape_next = True
continue
if char == '"' and not in_string:
in_string = True
elif char == '"' and in_string:
in_string = False
elif not in_string:
if char == '{':
if depth == 0:
start_idx = i
depth += 1
elif char == '}':
depth -= 1
if depth == 0 and start_idx is not None:
objects.append(s[start_idx:i+1])
start_idx = None
return objects
for candidate in find_all_json_objects(text):
try:
parsed = json.loads(candidate)
if isinstance(parsed, dict) and any(k in parsed for k in ['operation', 'target_column', 'metric', 'group_by']):
return parsed
except json.JSONDecodeError:
continue
for i in range(len(text)):
if text[i] == '{':
decoder = json.JSONDecoder()
try:
parsed, _ = decoder.raw_decode(text[i:])
if isinstance(parsed, dict) and any(k in parsed for k in ['operation', 'target_column', 'metric', 'group_by']):
return parsed
except json.JSONDecodeError:
continue
return None
if reasoning_content:
plan = extract_json_from_text(reasoning_content)
if plan is not None:
return plan, reasoning_content
plan = extract_json_from_text(content)
if plan is not None:
return plan, reasoning_content
error_msg = (
f"Planner returned non-JSON content.\n"
f"Finish reason: {finish_reason}\n"
f"Content received: {repr(content[:500]) if content else '(empty)'}\n"
f"Reasoning content length: {len(reasoning_content) if reasoning_content else 0}\n"
f"Reasoning content sample: {reasoning_content[:500] if reasoning_content else '(none)'}"
)
if finish_reason == "length":
error_msg += "\n\nNote: Response was truncated due to token limit. The model didn't finish generating the JSON."
raise ValueError(error_msg)Zuerst definiert der „ system_prompt ” den Vertrag für den Planner Agent, der die Benutzerfrage in einen JSON-Plan umwandelt, und legt genau fest, welche Felder wir erwarten, wie zum Beispiel eine Liste von „ group_by ”-Spalten, optionale „ filters ”, eine „ target_column ”, eine „ metric ” und eine „ chart_type ”.
Wir packen auch ein paar Heuristiken rein (wie zum Beispiel, wie man mit „dieses Jahr“ oder „Top N“ umgeht), damit sich das Modell eher wie ein junger Datenanalyst als wie ein allgemeiner Chatbot verhält.
Als Nächstes erstellen wir die Systemmeldung, die die Anweisungen enthält, und packen zwei Sachen rein: eine Textbeschreibung des Datensatzschemas (Spaltennamen, Datentypen, Beispielzeilen) und die Frage des Benutzers. Dadurch hat das Modell genug Kontext, um passende Spaltennamen zu finden und eine sinnvolle Aggregation für die gestellte Frage zu wählen.
DeepSeek V3.2 Speciale wird dann über client.chat.completions.create() aufgerufen. Da es sich um ein Argumentationsmodell handelt, kann es zwei Arten von Ergebnissen liefern: einen sichtbaren Inhaltsstrang und einen internen reasoning_content Strang, in dem oft das meiste „Denken” und die endgültige Antwort stecken. Wir holen beides aus der Antwort raus und behalten die finish_reason im Auge, damit wir Kürzungen erkennen können.
Die Hauptarbeit läuft in der Funktion „ extract_json_from_text() “ ab. Weil Argumentationsmodelle nicht immer sauberes JSON liefern, packen wir es in ein Markdown. Um den Planer stabil zu machen, probiert diese Hilfsfunktion mehrere Strategien nacheinander aus:
json.loadsFür jeden Kandidaten werden nur Objekte akzeptiert, die wie ein gültiger Plan aussehen, d. h. sie müssen mindestens eines der folgenden Felder enthalten: operation, target_column, metric oder group_by.
Zum Schluss verbinden wir alles miteinander, indem wir die Funktion „ extract_json_from_text() “ auf „ reasoning_content “ anwenden.
Zusammen machen diese Teile aus jeder Frage in natürlicher Sprache und jedem Schema-Snapshot einen strukturierten Analyseplan.
Sobald der Datenverarbeiter die Analyse mit Pandas durchgeführt hat, schicken wir die Ergebnis-Tabelle zusammen mit dem JSON-Plan zurück an DeepSeek und machen daraus eine Zusammenfassung mit konkreten Erkenntnissen.
def call_explainer_llm(question: str, plan: dict, result_summary: list) -> tuple[str, str]:
system_prompt = """
You are a senior data analyst explaining insights to business stakeholders.
The user asked a question about their CSV data.
Another agent already designed an analysis plan and we executed it in Python.
You will now explain the results in clear, engaging, non-technical language.
Requirements:
- Start with a direct 1-2 sentence answer to their question
- Use bullet points (3-5 points) to highlight key insights, trends, or comparisons
- Include specific numbers and percentages where relevant
- Use business-friendly language (avoid technical jargon like "aggregation", "groupby")
- If the data shows interesting patterns, point them out
- End with a brief recommendation or next step if appropriate
Keep it concise and actionable.
""".strip()
limited_summary = result_summary[:20] if len(result_summary) > 20 else result_summary
user_content = f"""
User question:
{question}
Analysis performed:
{json.dumps(plan, indent=2)}
Results (top rows):
{json.dumps(limited_summary, indent=2)}
Total rows in result: {len(result_summary)}
""".strip()
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content},
]
resp = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
max_tokens=2048,
)
message = resp.choices[0].message
content = message.content or ""
content = content.strip()
reasoning_content = getattr(message, 'reasoning_content', None) or ""
if not content:
if reasoning_content:
content = reasoning_content.strip()
return (content if content else "Unable to generate explanation from the model response.",
reasoning_content)Der Explainer-Agent fängt damit an, den „ system_prompt “ einzustellen, der DeepSeek sagt, dass es sich wie ein erfahrener Datenanalyst verhalten soll, der mit den Leuten aus dem Unternehmen redet. Wir sagen dir genau, wie die Antwort aussehen soll, und geben dir noch ein paar Tipps, wie du sie am besten formulierst.
Als Nächstes machen wir uns an „ user_content “, das dem Modell den ganzen Kontext gibt, den es braucht. Wir übergeben die ursprüngliche Frage, den JSON-Analyseplan (damit er weiß, welche Berechnungen durchgeführt wurden) und die Gesamtzahl der Zeilen.
Dann stellen wir die Nachrichtenliste zusammen und rufen DeepSeek V3.2 Speciale über client.chat.completions.create() auf. Genau wie im Planer kann das Modell Text sowohl in „ content “ als auch in „ reasoning_content “ zurückgeben. Deshalb fügen wir beide hinzu und greifen auf „ reasoning_content “ zurück, wenn „ content “ leer ist.
Am Ende gibt die Funktion ein Tupel zurück, das sowohl die Erklärung als auch die Rohdaten-Begründungszeichenfolge enthält, die im Expander angezeigt wird.
Mit diesem Explainer Agent ist der Kreis geschlossen:
Bevor wir DeepSeek irgendwas planen lassen können, müssen wir die Daten klar beschreiben und sie für die Analyse aufbereiten. Das wird mit ein paar Hilfsfunktionen gemacht.
Der Planner Agent kann dein DataFrame nicht direkt sehen, deshalb schicken wir ihm eine kompakte Textzusammenfassung des Datensatzes.
def get_schema_description(df: pd.DataFrame, max_rows: int = 3) -> str:
schema_lines = ["Columns:"]
for col, dtype in df.dtypes.items():
if dtype == 'object' and df[col].nunique() < 20:
unique_vals = df[col].dropna().unique()[:5]
schema_lines.append(f"- {col} ({dtype}) - sample values: {', '.join(map(str, unique_vals))}")
else:
schema_lines.append(f"- {col} ({dtype})")
sample = df.head(max_rows).to_markdown(index=False)
return "\n".join(schema_lines) + "\n\nSample rows:\n" + sampleDieser Helfer durchläuft alle Spalten. Es gibt auch ein paar Beispielwerte für Sachen wie Produktnamen, Regionen oder Kategorien. F
Schließlich fügt es eine kurze Markdown-Tabelle mit den ersten paar Zeilen hinzu, damit das Modell konkrete Beispiele zum Nachdenken hat.
Diese Schema-Zeichenkette ist die Sicht des Planers auf deine Daten, die es ihm ermöglicht, gültige Spaltennamen und Gruppierungen auszuwählen.
Wir erkennen automatisch Datums-Spalten und fügen Hilfsfelder wie „ _year “ und „ _year_month “ hinzu, was es DeepSeek einfacher macht, Fragen wie „letztes Jahr“ oder „nach Monat“ zu beantworten.
def preprocess_dates(df: pd.DataFrame) -> pd.DataFrame:
df = df.copy()
date_columns = []
for col in df.columns:
if pd.api.types.is_datetime64_any_dtype(df[col]):
date_columns.append(col)
continue
if any(x in col.lower() for x in ['date', 'time', 'day']):
try:
df[col] = pd.to_datetime(df[col], errors='coerce')
if df[col].notna().sum() > 0:
date_columns.append(col)
except:
pass
for col in date_columns:
if col in df.columns and pd.api.types.is_datetime64_any_dtype(df[col]):
df[f'{col}_year'] = df[col].dt.year
df[f'{col}_month'] = df[col].dt.month
df[f'{col}_year_month'] = df[col].dt.to_period('M').astype(str)
return dfZuerst checken wir die Spalten und wenn eine Spalte schon ein Datums- oder Zeitwert ist oder ihr Name auf ein Datum hindeutet (wie „ order_date “ oder „ day “), versuchen wir, sie mit „ pd.to_datetime “ zu analysieren. Für jede Datumsspalte erstellen wir Merkmale wie „ _year “, „ _month “ und „ _year_month “.
Durch diese Vorverarbeitung kann der Planer sicher auf die Spalten „ year “ und „ year_month “ zugreifen, ohne dass du für jeden Datensatz manuell Zeitmerkmale erstellen musst.
Der Planer kann einfache Zeilenfilter zum Plan hinzufügen, und dieser Helfer macht daraus Pandas-Filter.
def apply_filters(df: pd.DataFrame, filters: list) -> pd.DataFrame:
if not filters:
return df
filtered = df.copy()
for f in filters:
col = f.get("column")
op = f.get("op")
val = f.get("value")
if col not in filtered.columns:
continue
try:
val_cast = pd.to_numeric(val)
except Exception:
val_cast = val
if op == "==":
filtered = filtered[filtered[col] == val_cast]
elif op == "!=":
filtered = filtered[filtered[col] != val_cast]
elif op == ">":
filtered = filtered[filtered[col] > val_cast]
elif op == "<":
filtered = filtered[filtered[col] < val_cast]
elif op == ">=":
filtered = filtered[filtered[col] >= val_cast]
elif op == "<=":
filtered = filtered[filtered[col] <= val_cast]
elif op == "contains":
filtered = filtered[filtered[col].astype(str).str.contains(str(val_cast), case=False, na=False)]
return filteredFür jeden Filter checken wir, ob die Spalte da ist, und wandeln den Wert, wenn möglich, in eine Zahl um. Dann machen wir den passenden Vergleich. Alle Filter werden nacheinander angewendet, sodass du Bedingungen wie „Region enthält West“ und „Jahr >= 2021“ ganz einfach kombinieren kannst.
Diese Funktion verbindet die Beschränkungen der natürlichen Sprache aus dem Plan mit den Zeilenuntergruppen.
Jetzt machen wir das Data Worker der eine dünne Schicht ist, die den JSON-Plan liest und die entsprechenden Pandas-Aggregationen ausführt.
def run_analysis_plan(df: pd.DataFrame, plan: dict) -> pd.DataFrame:
op = plan.get("operation")
target_col = plan.get("target_column")
group_by = plan.get("group_by") or []
filters = plan.get("filters") or []
metric = plan.get("metric", "sum")
if filters:
df = apply_filters(df, filters)
if not op or not target_col or target_col not in df.columns:
return df.head(20)
if op in ("aggregate_compare", "group_by_summary", "filter_then_aggregate"):
if not group_by:
if metric == "sum":
value = df[target_col].sum()
elif metric == "mean":
value = df[target_col].mean()
elif metric == "count":
value = df[target_col].count()
elif metric == "max":
value = df[target_col].max()
elif metric == "min":
value = df[target_col].min()
else:
raise ValueError(f"Unsupported metric: {metric}")
return pd.DataFrame({f"{metric}_{target_col}": [value]})
if metric == "sum":
agg_df = df.groupby(group_by)[target_col].sum().reset_index()
elif metric == "mean":
agg_df = df.groupby(group_by)[target_col].mean().reset_index()
elif metric == "count":
agg_df = df.groupby(group_by)[target_col].count().reset_index()
elif metric == "max":
agg_df = df.groupby(group_by)[target_col].max().reset_index()
elif metric == "min":
agg_df = df.groupby(group_by)[target_col].min().reset_index()
else:
raise ValueError(f"Unsupported metric: {metric}")
agg_df = agg_df.sort_values(by=target_col, ascending=False)
return agg_df
return df.head(20)Zuerst schauen wir uns den Plan mit den Parametern „Operation“, „Zielspalte“, „Gruppierungsspalten“, „Filter“ und „Metrik“ genauer an. T
Dann werden Filter über die Funktion „ apply_filters() “ angewendet. Wenn der Plan auf eine ungültige Spalte verweist, zeigen wir stattdessen einfach eine einfache Vorschau an.
Ansonsten machen wir bei den unterstützten Operationen entweder eine Aggregation über die ganze Tabelle oder wir führen eine Gruppierung durch, gefolgt von Operationen wie Summe, Mittelwert, Anzahl, Maximalwert oder Minimalwert, und sortieren das Ergebnis nach der Metrikspalte.
Das ist das Herzstück der Tool-Ebene: Das LLM entscheidet, was berechnet werden soll, und diese Funktion entscheidet, wie das mit Pandas sicher gemacht wird.
Zum Schluss machen wir aus der Tabelle ein Diagramm, das zum Plan „ chart_type “ passt, sodass wir sowohl Zahlen als auch Bilder in der Ausgabe haben.
def generate_chart(df: pd.DataFrame, plan: dict):
if not plan.get("need_chart") or df.empty:
return None
chart_type = plan.get("chart_type", "bar")
group_by = plan.get("group_by") or []
target_col = plan.get("target_column")
if not target_col or target_col not in df.columns:
return None
fig, ax = plt.subplots(figsize=(10, 6))
if group_by and len(group_by) > 0:
x_col = group_by[0]
if x_col not in df.columns:
return None
plot_df = df.head(15)
if chart_type == "bar":
bars = ax.bar(range(len(plot_df)), plot_df[target_col], color=sns.color_palette("husl", len(plot_df)))
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
ax.set_ylabel(target_col, fontsize=12)
ax.set_xlabel(x_col, fontsize=12)
for i, (bar, val) in enumerate(zip(bars, plot_df[target_col])):
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{val:,.0f}' if abs(val) > 100 else f'{val:.2f}',
ha='center', va='bottom', fontsize=9)
elif chart_type == "line":
ax.plot(range(len(plot_df)), plot_df[target_col], marker='o', linewidth=2, markersize=8)
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
ax.set_ylabel(target_col, fontsize=12)
ax.set_xlabel(x_col, fontsize=12)
ax.grid(True, alpha=0.3)
elif chart_type == "pie" and len(plot_df) <= 10:
ax.pie(plot_df[target_col], labels=plot_df[x_col], autopct='%1.1f%%', startangle=90)
ax.axis('equal')
else:
bars = ax.bar(range(len(plot_df)), plot_df[target_col])
ax.set_xticks(range(len(plot_df)))
ax.set_xticklabels(plot_df[x_col], rotation=45, ha='right')
title = f"{target_col} by {x_col}"
else:
ax.bar([target_col], [df[target_col].iloc[0]])
title = f"{target_col}"
ax.set_title(title, fontsize=14, fontweight='bold', pad=20)
fig.tight_layout()
buf = io.BytesIO()
fig.savefig(buf, format="png", dpi=150, bbox_inches='tight')
buf.seek(0)
plt.close(fig)
return bufWir checken die Seiten chart_type, group_by und target_column aus dem Plan und erstellen eine Matplotlib-Abbildung. Die Funktion „ generate_chart() “ oben gibt einen PNG-Puffer im Speicher zurück, den die Streamlit-App neben den wichtigsten Kennzahlen anzeigt.
Mit diesen Hilfsfunktionen wird der Rest des Systems viel einfacher. Der Planer nutzt „ get_schema_description “, um die Analyse zu gestalten, der Datenverarbeiter nutzt die Funktionen „ preprocess_dates() “, „ apply_filters() “ und „ run_analysis_plan() “, um die Zahlen zu berechnen, und die Funktion „ generate_chart() “ macht aus der endgültigen Tabelle ein Diagramm.
Jetzt, wo wir die Funktionen für Planung, Datenverarbeitung, Erläuterung und Unterstützung haben, können wir alles in eine Streamlit-App packen.
st.set_page_config(
page_title="AI Data Analyst Agent",
page_icon="📊",
layout="wide",
initial_sidebar_state="expanded"
)
st.markdown("""
<style>
.main-header {
font-weight: 700;
text-align: center;
}
.sub-header {
text-align: center;
}
.metric-card {
background-
border-radius: 0.5rem;
border-left: 4px solid #1f77b4;
}
.insight-box {
background-
border-radius: 0.5rem;
border-left: 4px solid #2ecc71;
}
</style>
""", unsafe_allow_html=True)
st.markdown("<h1 class='main-header'>AI Data Analyst Agent</h1>", unsafe_allow_html=True)
uploaded_file = st.file_uploader("Upload CSV file", type=["csv"], help="Upload any CSV file to get started")
if uploaded_file is not None:
try:
df = pd.read_csv(uploaded_file)
df = preprocess_dates(df)
except Exception as e:
st.error(f"Error loading CSV: {e}")
st.stop()
with st.expander("Preview Data", expanded=False):
col1, col2, col3 = st.columns(3)
col1.metric("Total Rows", f"{len(df):,}")
col2.metric("Total Columns", len(df.columns))
col3.metric("Memory Usage", f"{df.memory_usage(deep=True).sum() / 1024**2:.1f} MB")
st.dataframe(df.head(100), width='stretch', height=300)
st.markdown("**Numeric Columns Summary:**")
numeric_cols = df.select_dtypes(include=['number']).columns
if len(numeric_cols) > 0:
st.dataframe(df[numeric_cols].describe(), width='stretch')
st.markdown("---")
col1, col2 = st.columns([4, 1])
with col1:
question = st.text_input(
" Ask a question about your data",
placeholder="e.g., Which product category had the highest sales last year?",
label_visibility="collapsed"
)
with col2:
analyze_button = st.button("Analyze", type="primary", width='stretch')
if analyze_button and question.strip():
with st.spinner("Analyzing data..."):
schema_text = get_schema_description(df)
try:
plan, planner_reasoning = call_planner_llm(schema_text, question)
except Exception as e:
st.error(f" Planner agent failed: {e}")
st.stop()
with st.expander(" Analysis Plan", expanded=False):
col1, col2 = st.columns(2)
with col1:
st.json(plan)
with col2:
if planner_reasoning:
st.markdown("**AI Reasoning Process:**")
st.text_area("Planner Reasoning", planner_reasoning[:1000] + "..." if len(planner_reasoning) > 1000 else planner_reasoning,
height=200, label_visibility="collapsed")
try:
result_df = run_analysis_plan(df, plan)
except Exception as e:
st.error(f" Error running analysis: {e}")
st.info(" Tip: Try rephrasing your question or be more specific about the columns you want to analyze.")
st.stop()
st.markdown("---")
st.markdown("## Results")
chart_buf = generate_chart(result_df, plan)
if chart_buf is not None:
col1, col2 = st.columns([2, 1])
with col1:
st.image(chart_buf)
with col2:
st.markdown("### Key Metrics")
target_col = plan.get("target_column")
if target_col in result_df.columns:
st.metric("Total", f"{result_df[target_col].sum():,.2f}")
st.metric("Average", f"{result_df[target_col].mean():,.2f}")
st.metric("Max", f"{result_df[target_col].max():,.2f}")
st.metric("Min", f"{result_df[target_col].min():,.2f}")
else:
st.info("Chart generation skipped (not applicable for this query)")
with st.expander("Results Table", expanded=True):
st.dataframe(result_df, width='stretch', height=400)
csv_data = result_df.to_csv(index=False)
st.download_button(
label="Download Results as CSV",
data=csv_data,
file_name=f"analysis_results_{datetime.now().strftime('%Y%m%d_%H%M%S')}.csv",
mime="text/csv"
)
with st.spinner("Generating insights..."):
result_df_serializable = result_df.copy()
for col in result_df_serializable.columns:
if pd.api.types.is_datetime64_any_dtype(result_df_serializable[col]):
result_df_serializable[col] = result_df_serializable[col].astype(str)
elif pd.api.types.is_period_dtype(result_df_serializable[col]):
result_df_serializable[col] = result_df_serializable[col].astype(str)
result_summary = result_df_serializable.to_dict(orient="records")
explanation, explainer_reasoning = call_explainer_llm(
question=question,
plan=plan,
result_summary=result_summary,
)
st.markdown("---")
st.markdown("## AI Insights")
st.markdown(f'<div class="insight-box">{explanation}</div>', unsafe_allow_html=True)
if explainer_reasoning:
with st.expander(" AI Reasoning Process", expanded=False):
st.text_area("Explainer Reasoning", explainer_reasoning[:1500] + "..." if len(explainer_reasoning) > 1500 else explainer_reasoning,
height=300, label_visibility="collapsed")st.set_page_config Oben richten wir die Seite mit HTML und CSS ein, um das Dashboard zu gestalten. Der Benutzer lädt erst mal eine CSV-Datei hoch, die wir dann in einen DataFrame laden, durch „ preprocess_dates “ schicken und in einem„ “ mit Zeilen-/Spaltenanzahl, Speicherverbrauch und einer kurzen Zusammenfassung anzeigen.
Hinter den Kulissen erstellen wir mit der Funktion „ get_schema_description() “ ein Schema, rufen „ call_planner_llm “ auf, um einen JSON-Plan zu bekommen, und zeigen sowohl den Plan als auch die Argumentation des Modells in einem Expander an. Der Datenarbeiter macht dann den Plan mit Pandas klar, und im Abschnitt„ -Ergebnisse“ gibt's ein Diagramm von generate_chart zusammen mit den wichtigsten Kennzahlen.
Zum Schluss rufen wir „ call_explainer_llm “ mit der Frage, dem Plan und der Zusammenfassung der Ergebnisse auf, um eine Erklärung für die KI-Einblicke Box zu erstellen, mit einem optionalen AI-Begründungsprozess für alle, die einen Blick hinter die Kulissen werfen möchten.
Speicher alles als „ app.py ” und starte:
streamlit run app.pyIm folgenden Video kannst du eine gekürzte Version des Arbeitsablaufs in Aktion sehen:
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
Aditya Sharma
Tutorial
Moez Ali
