
Curso
Ajuste fino con Llama 3
2 h
3.7K
T5Gemma 2 es una familia de modelos de codificador-decodificador ligeros y de peso abierto de Google, basados en Gemma 3, que admiten entradas multilingües y multimodales.
Con una ventana de contexto de hasta 128 K en más de 140 idiomas y opciones de diseño eficientes en cuanto a parámetros, como incrustaciones vinculadas y atención fusionada, estos modelos son muy adecuados para tareas de generación de texto y comprensión de imágenes, al tiempo que siguen siendo lo suficientemente pequeños como para ejecutarse en un ordenador portátil.
En este tutorial, aprenderemos a ajustar un modelo codificador-decodificador en un conjunto de datos OCR de LaTeX. El objetivo es lograr un rendimiento sólido utilizando un número mínimo de muestras de entrenamiento.
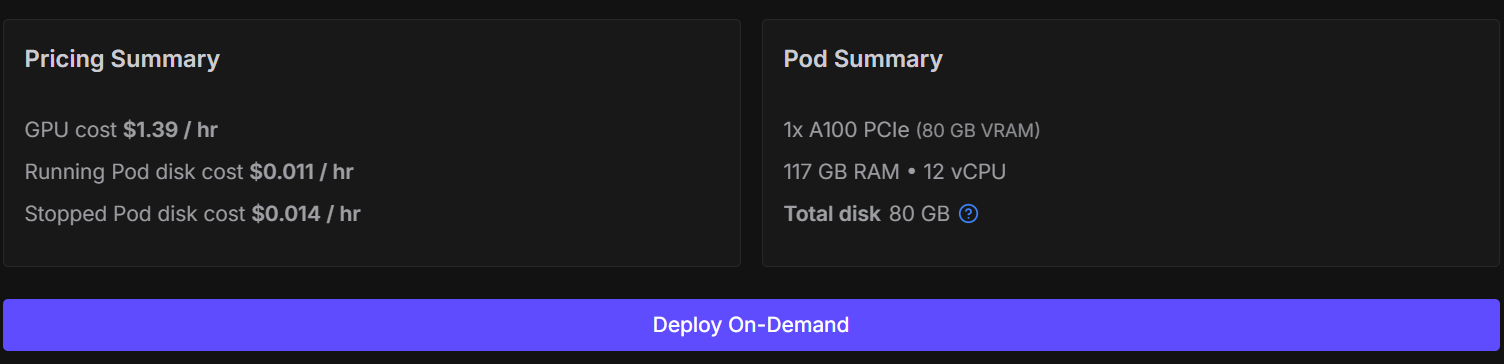
Aunque es posible ajustar este modelo en Kaggle o Google Colab, hacerlo a menudo provoca sesiones inestables, desconexiones de recursos y un entrenamiento significativamente más lento. Para evitar estos puntos de fricción y mantener una configuración sencilla y fiable, utilizaremos una GPU NVIDIA A100.
Puedes alquilar un A100 en RunPod por alrededor de 1,39 dólares la hora, y el proceso completo de formación de este tutorial te llevará menos de 30 minutos. Esta configuración te ofrece un rendimiento constante sin tener que lidiar con limitaciones de memoria.
Empieza por ir a RunPod y crear un nuevo pod utilizando la última imagen de PyTorch. Selecciona una máquina 1× A100.
A continuación, edita la configuración del pod y añade una variable de entorno llamada ` HF_TOKEN`. Este token es necesario para:
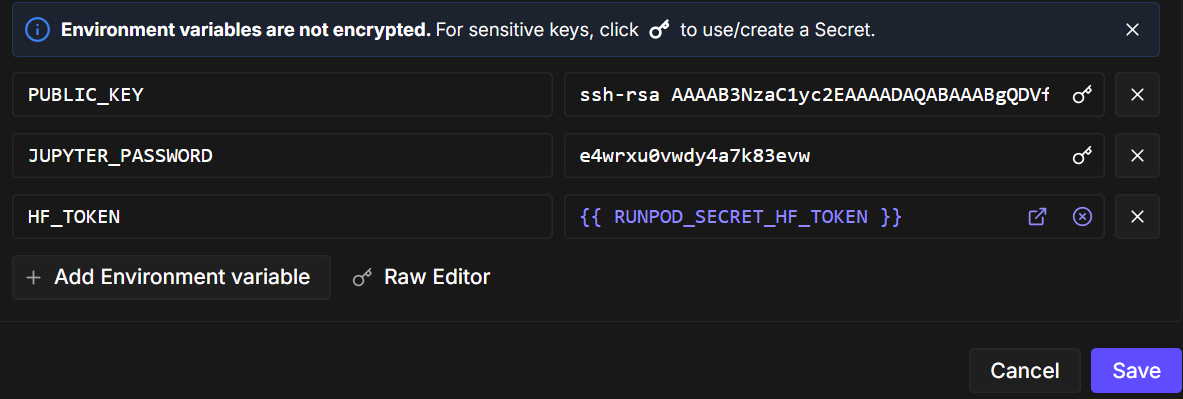
Una vez que el pod esté listo, inicia el cuaderno e instala los paquetes Python necesarios. Asegúrate de que estás utilizando la última versión de transformers.
!pip -q install -U accelerate datasets pillow sentencepiece safetensors
!pip install --quiet "transformers==5.0.0rc1"
!pip install --quiet --no-deps trlAhora, importemos las bibliotecas y utilidades que usaremos a lo largo del cuaderno.
import torch
from datasets import load_dataset
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer, set_seedAntes del entrenamiento, aplicamos algunas configuraciones optimizadas para las GPU A100. Establecer una semilla garantiza la reproducibilidad, y habilitar TF32 mejora el rendimiento sin afectar a la estabilidad del entrenamiento de bf16.
set_seed(42)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
print("CUDA:", torch.cuda.is_available(), torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)
print("bf16 supported:", torch.cuda.is_available() and torch.cuda.is_bf16_supported())CUDA: True NVIDIA A100 80GB PCIe
bf16 supported: TrueEn este tutorial, utilizamos el conjunto de datos LaTeX OCR disponible en Hugging Face. Cada ejemplo del conjunto de datos consta de:
El conjunto de datos ofrece múltiples configuraciones. Para que el entrenamiento siga siendo eficiente y esté en consonancia con nuestro objetivo de aprender a partir de datos limitados, controlaremos explícitamente el tamaño del conjunto de datos.
Primero, carga las divisiones de entrenamiento y validación. Para simular un escenario de ajuste fino con pocos datos, barajamos aleatoriamente el conjunto de datos y seleccionamos un pequeño subconjunto:
Esto mantiene la rapidez del entrenamiento y, al mismo tiempo, permite que el modelo generalice.
DATASET_NAME = "full"
raw_train = load_dataset("linxy/LaTeX_OCR", name=DATASET_NAME, split="train")
raw_val = load_dataset("linxy/LaTeX_OCR", name=DATASET_NAME, split="validation")
train_ds = raw_train.shuffle(seed=42).select(range(1000))
val_ds = raw_val.shuffle(seed=42).select(range(200))
print(train_ds, val_ds)
print("Columns:", train_ds.column_names)Salida:
Dataset({
features: ['image', 'text'],
num_rows: 1000
}) Dataset({
features: ['image', 'text'],
num_rows: 200
})
Columns: ['image', 'text']Para comprender mejor los datos, veamos un ejemplo de entrenamiento. Primero, examina la imagen.
train_ds[10]["image"]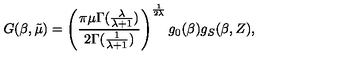
A continuación, examina la cadena LaTeX sin procesar asociada a esa imagen.
train_ds[10]["text"]'G ( \\beta , \\tilde { \\mu } ) = \\left( \\frac { \\pi \\mu \\Gamma ( \\frac { \\lambda } { \\lambda + 1 } ) } { 2 \\Gamma ( \\frac { 1 } { \\lambda + 1 } ) } \\right) ^ { \\frac { 1 } { 2 \\lambda } } g _ { 0 } ( \\beta ) g _ { S } ( \\beta , Z ) ,'Por último, podemos representar esta expresión LaTeX directamente en el cuaderno para verificar que el texto coincide con el contenido de la imagen.
from IPython.display import display, Math, Latex
latex = train_ds[10]["text"]
display(Math(latex))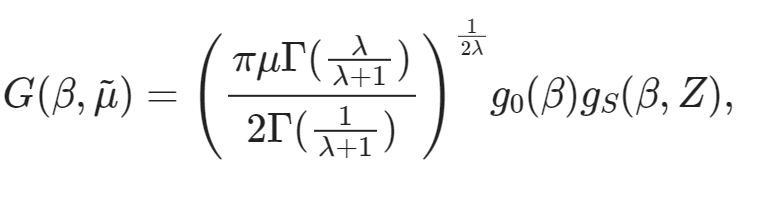
Ahora que el conjunto de datos está listo, el siguiente paso es cargar el modeloT5Gemma-2 y su procesador correspondiente. Usaremos el variante 270M-270M, que ofrece un buen equilibrio entre capacidad y eficiencia y se adapta perfectamente a una GPU de consumo.
MODEL_ID = "google/t5gemma-2-270m-270m"
processor = AutoProcessor.from_pretrained(MODEL_ID, use_fast=True)
model = AutoModelForSeq2SeqLM.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16, # A100 -> bf16
device_map="auto",
)Se accede al tokenizador a través del procesador. Algunos modelos de codificador-decodificador no definen un token de relleno de forma predeterminada, por lo que añadimos uno si es necesario y redimensionamos las incrustaciones de tokens del modelo en consecuencia.
tokenizer = processor.tokenizer
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": tokenizer.eos_token})
model.resize_token_embeddings(len(tokenizer))Para LaTeX OCR, guiamos el modelo utilizando una breve indicación textual junto con la imagen de entrada. Esta indicación especifica claramente la tarea y limita el formato de salida.
Por último, definimos las longitudes máximas de secuencia para la entrada del codificador y el objetivo del decodificador. Estos valores son suficientes para la mayoría de las expresiones matemáticas, al tiempo que mantienen el uso de la memoria bajo control.
PROMPT = "<start_of_image> Convert this image to LaTeX. Output only LaTeX."
MAX_INPUT_LEN = 128
MAX_TARGET_LEN = 256Antes de comenzar con el ajuste fino, resulta útil ejecutar una inferencia de referencia utilizando el modelo T5Gemma-2 preentrenado. Esto nos ayuda a comprender cómo se comporta el modelo en la tarea de OCR de LaTeX sin ningún tipo de entrenamiento específico para la tarea y nos proporciona un punto de referencia para futuras mejoras.
A continuación, se ofrece un resumen conciso del proceso:
image = train_ds[20]["image"]
# prepare inputs
model_inputs = processor(text=PROMPT, images=image, return_tensors="pt")
model_inputs = {k: v.to("cuda") for k, v in model_inputs.items()}
# run inference
model = model.eval()
with torch.inference_mode():
generation = model.generate(
**model_inputs,
max_new_tokens=100,
do_sample=False,
num_beams=3,
repetition_penalty=1.2,
no_repeat_ngram_size=4,
early_stopping=True,
)
# decode
pred = processor.decode(generation[0], skip_special_tokens=True)
print("\n--- Model output ---")
print(pred)Ejemplo de resultado del modelo preentrenado:
--- Model output ---
Use this command to change this image's format:\usepackage[T1]{fontenc}\usepackage[utf8]{inputenc}\DeclareUnicodeUTF8{1234567890123}\begin{document}<tex>$\begin{equation}\begin{aligned}P=&\frac{1+(-)\frac{1}{2}\left(F_{1}(-)\frac{F_{2}(-Ahora, veamos el código LaTeX real para la misma imagen.
train_ds[20]["text"]Realidad sobre el terreno:
'{ \\cal P } = \\frac { 1 + ( - ) ^ { F } { \\cal I } _ { 4 } ( - ) ^ { F _ { L } } } { 2 } .'Como era de esperar, el modelo preentrenado no produce una transcripción LaTeX correcta. En su lugar, genera plantillas genéricas de LaTeX y fragmentos no relacionados. Este comportamiento es normal, ya que el modelo base no ha sido entrenado específicamente para el OCR de LaTeX.
En esta sección, creamos un clasificador personalizado de datos de imagen y texto para agrupar correctamente imágenes, indicaciones y objetivos LaTeX para el ajuste fino. Dado que T5Gemma-2 es un modelo codificador-decodificador multimodal, el clasificador desempeña un papel fundamental a la hora de garantizar que las imágenes y el texto estén alineados correctamente y se transmitan al modelo en el formato esperado.
En concreto, el clasificador:
En conjunto, estos pasos garantizan un entrenamiento estable, un cálculo correcto de las pérdidas y una convergencia fiable al ajustar el modelo con datos OCR de LaTeX.
from typing import Any, Dict, List
import torch
from PIL import Image as PILImage
tokenizer = processor.tokenizer
tokenizer.padding_side = "right"
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": tokenizer.eos_token})
pad_id = tokenizer.pad_token_id
PROMPT = "<start_of_image> Convert this equation image to LaTeX. Output only LaTeX."
MAX_TARGET_LEN = 256
def collate_fn(examples: List[Dict[str, Any]]) -> Dict[str, torch.Tensor]:
images, prompts, targets = [], [], []
for ex in examples:
im = ex["image"]
if isinstance(im, PILImage.Image):
im = im.convert("RGB")
elif isinstance(im, dict) and "path" in im:
im = PILImage.open(im["path"]).convert("RGB")
else:
raise ValueError(f"Unexpected image type: {type(im)}")
# IMPORTANT: one image per sample -> nested list
images.append([im])
prompts.append(PROMPT)
targets.append(ex["text"])
# ✅ NO truncation here (prevents image-token mismatch)
model_inputs = processor(
text=prompts,
images=images,
padding=True,
truncation=False,
return_tensors="pt",
)
labels = tokenizer(
targets,
padding=True,
truncation=True,
max_length=MAX_TARGET_LEN,
return_tensors="pt",
)["input_ids"]
labels[labels == pad_id] = -100
model_inputs["labels"] = labels
return model_inputsEn esta sección, definimos la configuración de entrenamiento y los ajustes de optimización para ajustar T5Gemma-2 en la tarea de OCR de LaTeX. La configuración es intencionadamente sencilla y está optimizada para un entrenamiento rápido en una sola GPU A100, utilizando un pequeño conjunto de datos y una sola época de entrenamiento.
Para reducir los gastos generales y acelerar el proceso, desactivamos la evaluación y el almacenamiento de puntos de control y nos centramos únicamente en pasadas hacia adelante y hacia atrás eficientes.
from transformers import Seq2SeqTrainingArguments
args = Seq2SeqTrainingArguments(
output_dir="t5gemma2-latex-ocr-1k",
# --- core training ---
num_train_epochs=1,
per_device_train_batch_size=8,
gradient_accumulation_steps=1,
learning_rate=1e-4,
warmup_steps=15,
lr_scheduler_type="linear",
# --- precision / speed ---
bf16=True,
fp16=False,
tf32=True,
# --- memory ---
gradient_checkpointing=True,
# --- stop extra work (this is the big speed win) ---
eval_strategy="no",
predict_with_generate=False,
save_strategy="no",
report_to="none",
# --- dataloader ---
dataloader_num_workers=0,
remove_unused_columns=False,
# --- logging ---
logging_steps=10,
)Por último, inicializamos el Seq2SeqTrainer. Pasamos explícitamente nuestro clasificador de datos personalizado para que el entrenador pueda construir correctamente lotes multimodales que combinen imágenes, indicaciones de instrucciones y secuencias objetivo LaTeX durante el entrenamiento.
trainer = Seq2SeqTrainer(
model=model,
args=args,
train_dataset=train_ds,
eval_dataset=val_ds,
data_collator=collate_fn,
)Con todo configurado, ahora podemos empezar a ajustar el modelo. La formación se inicia con una sola llamada al formador.
trainer.train()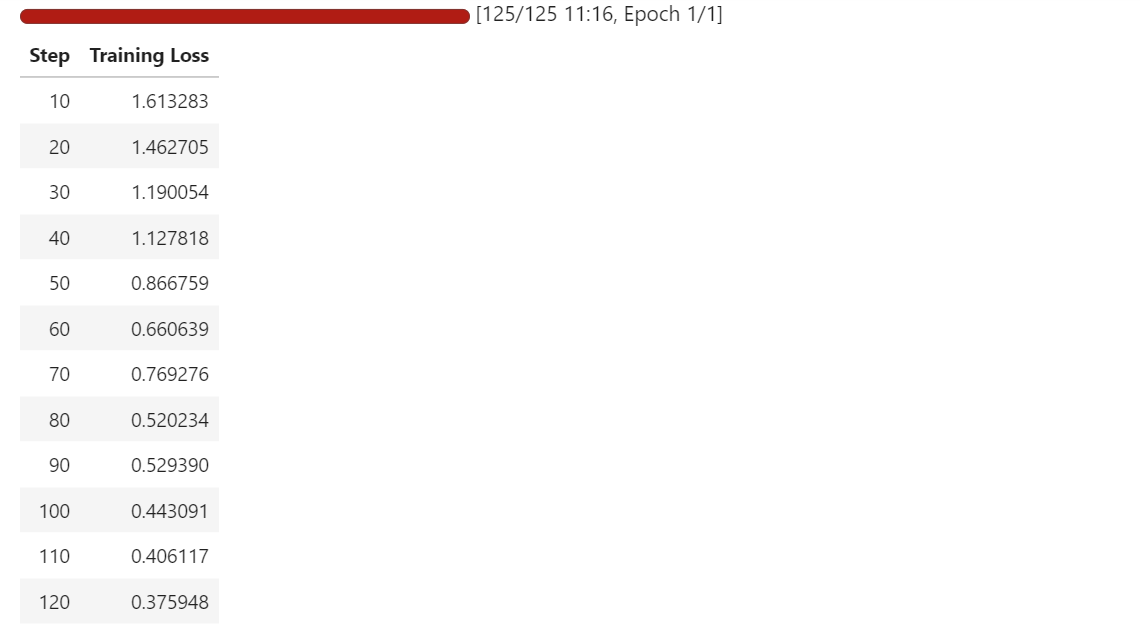
Durante el entrenamiento, la pérdida disminuye gradualmente, lo que indica que el modelo está aprendiendo a mapear mejor las imágenes de ecuaciones con sus representaciones LaTeX correspondientes.
Incluso con un conjunto de datos pequeño y una sola época, el modelo comienza a adaptarse rápidamente a la tarea de OCR.
Después del ajuste, volvemos a ejecutar la inferencia en una muestra de entrenamiento y una muestra de validación para ver cómo han cambiado los resultados del modelo.
En comparación con el modelo de referencia, que en su mayoría producía plantillas genéricas de LaTeX, el modelo ajustado ahora genera LaTeX estructurado que se ajusta estrechamente a la forma y los símbolos de las ecuaciones de destino.
Comenzamos probando con el mismo ejemplo de entrenamiento que antes. La imagen pasa por el procesador, el modelo genera tokens y, a continuación, se vuelven a decodificar en LaTeX.
# pick a sample
image = train_ds[10]["image"]
# prepare inputs
model_inputs = processor(text=PROMPT, images=image, return_tensors="pt")
model_inputs = {k: v.to("cuda") for k, v in model_inputs.items()}
# run inference
model = model.eval()
with torch.inference_mode():
generation = model.generate(
**model_inputs,
max_new_tokens=100,
do_sample=False,
num_beams=3,
repetition_penalty=1.2,
no_repeat_ngram_size=4,
early_stopping=True,
)
# decode
pred = processor.decode(generation[0], skip_special_tokens=True)
print(pred)Como puedes ver, ahora obtenemos una salida LaTeX adecuada, en lugar de texto aleatorio o sin relación. En el ejemplo de entrenamiento, la predicción coincide en gran medida con la verdad fundamental, y los errores restantes se encuentran principalmente en fracciones, índices y algunos tokens mal colocados.
G ( \beta , \tilde { \mu } ) = \left( \frac { \pi \mu \Gamma } { 2 \Gamma } \lambda _ { + 1 } ^ { \lambda } \right) \right) ^ { \frac { 1 } { 9 \Gamma } g _ { 0 } ( \beta ) g _ { S } ( \theta , Z ) , \right) , \qquad G ( \bar { \A continuación, probamos el modelo en una muestra de validación para comprobar la generalización.
image = val_ds[10]["image"]
# prepare inputs
model_inputs = processor(text=PROMPT, images=image, return_tensors="pt")
model_inputs = {k: v.to("cuda") for k, v in model_inputs.items()}
# run inference
model = model.eval()
with torch.inference_mode():
generation = model.generate(
**model_inputs,
max_new_tokens=100,
do_sample=False,
num_beams=3,
repetition_penalty=1.2,
no_repeat_ngram_size=4,
early_stopping=True,
)
# decode
pred = processor.decode(generation[0], skip_special_tokens=True)
print(pred)En el ejemplo de validación, el modelo sigue la estructura y los símbolos correctos de LaTeX, aunque ocasionalmente comete errores en la colocación de corchetes, términos entre paréntesis y expresiones más largas.
f ( p , p ^ { \prime } ) = \ln \left\{ \frac { ( p _ { i } - p _ { j } ) ^ { 2 } } { \left( \frac { \psi ( p _ j ) - g ( p ; p _ { s } ) \psi ( \psi _ { i ] } ) \right\} . . . g ( \psi ; \psi ) - g \left( p ; \psi _En comparación con la realidad, la estructura general está claramente alineada y el modelo está produciendo una aproximación cercana en lugar de resultados sin relación.
print(val_ds[10]["text"])f ( p , p ^ { \prime } ) = \ln \left\{ \frac { ( p _ { i } - p _ { j } ) ^ { 2 } } { ( p _ { i } + p _ { j } ) ^ { 2 } } \right\} \left[ \psi ( p _ { j } ) - g ( p _ { i } , p _ { j } ) \psi ( p _ { i } ) \right] .En general, los resultados posteriores al ajuste fino muestran una clara mejora. El modelo ya no adivina plantillas genéricas de LaTeX, sino que produce LaTeX similar a ecuaciones que se asemeja mucho a los objetivos del conjunto de datos, incluso con un conjunto de entrenamiento pequeño y un ajuste fino breve.
Una vez completado el entrenamiento, el primer paso es guardar el modelo ajustado localmente para que pueda reutilizarse más adelante para la inferencia.
trainer.save_model()A continuación, enviamos el modelo al Hugging Face Hub para que otros puedan acceder a él, reutilizarlo y desarrollarlo.
trainer.push_to_hub()Durante la inspección de los archivos del repositorio, es posible que observes que la configuración del procesador no siempre se incluye al enviar el modelo a través del entrenador.
Dado que el procesador debe manejar correctamente tanto imágenes como texto, lo enviamos explícitamente por separado para garantizar que el modelo se pueda cargar y utilizar sin necesidad de configuraciones adicionales.
processor.push_to_hub(repo_id="kingabzpro/t5gemma2-latex-ocr-1k")
Con este paso, el repositorio contiene todo lo necesario para cargar el modelo y el procesador con una sola llamada. Ahora puedes visitar kingabzpro/t5gemma2-latex-ocr-1k en Hugging Face para acceder al modelo ajustado y empezar a utilizarlo para el OCR de LaTeX o para realizar más experimentos.
Ahora que el modelo ajustado se ha publicado en Hugging Face Hub, podemos cargarlo directamente para la inferencia utilizando la API pipeline. Esta es la forma más sencilla de probar el modelo sin tener que manejar manualmente procesadores, tokenizadores o lógica de generación.
Cargamos el modelo desde el Hub y creamos un canal de trabajo de « image-text-to-text » (Crear y publicar modelos):
from transformers import pipeline
generator = pipeline(
"image-text-to-text",
model="kingabzpro/t5gemma2-latex-ocr-1k",
)A continuación, ejecutamos la inferencia en una muestra de validación utilizando la misma instrucción que antes.
generator(
val_ds[10]["image"],
text="<start_of_image> Convert this image to LaTeX. Output only LaTeX.",
generate_kwargs={"do_sample": False, "max_new_tokens": 100},
)Como puedes ver, el resultado ya se acerca mucho al LaTeX correcto.
[{'input_text': '<start_of_image> Convert this image to LaTeX. Output only LaTeX.',
'generated_text': '<start_of_image> Convert this image to LaTeX. Output only LaTeX.f ( p , p ^ { \\prime } ) = \\ln \\left\\{ \\begin{array} { \\begin{array} { \\begin{array} { \\begin{array} { \\begin{array} { \\end{array} \\right\\} \\begin{array} { \\begin{array} { \\begin{array} { \\end{array} \\right\\} \\begin{array} { \\begin{array} { \\begin{array} {'}]Probemos con otra muestra de validación y procesemos posteriormente el resultado para conservar solo la cadena LaTeX.
preds = generator(
val_ds[30]["image"],
text="<start_of_image> Convert this image to LaTeX. Output only LaTeX.",
generate_kwargs={"do_sample": False, "max_new_tokens": 100},
)
prompt = preds[0]["input_text"]
gen = preds[0]["generated_text"]
# remove the prompt if the model echoed it
if gen.startswith(prompt):
gen = gen[len(prompt):]
# remove any leftover special tokens / separators
gen = gen.replace("<start_of_image>", "").strip()
if gen.startswith("."):
gen = gen[1:].strip()
print("\nCLEAN PREDICTED LaTeX:\n", gen)En esta ocasión, el resultado es limpio y directamente utilizable como LaTeX:
CLEAN PREDICTED LaTeX:
T _ { M N } = \left\{ g N \nu \partial _ { M P _ { } } \cdot \left\{ g ^ { N } \nu \partial _ { M P _ { } } \cdot \left\{ g ^ { N } \nu \partial _ { M P _ { } } \cdot \left\{ g ^ { N } \nu \partial _ { M P _ { } } \cdot \left\{ g ^ {En este punto, el modelo se puede utilizar como un sistema OCR LaTeX listo para usar. Puedes implementarlo detrás de una API, integrarlo en un proceso de procesamiento de documentos o seguir perfeccionándolo con más datos para obtener una precisión aún mayor.
Si tienes algún problema al ejecutar el código anterior, consulta el cuaderno de ayuda. Contiene el código completo junto con los resultados de cada paso para guiarte a través del proceso.
Cuando comencé a entrenar el modelo, lo traté como cualquier modelo de lenguaje grande con un codificador de imágenes. Después de fracasar varias veces, me di cuenta de que este enfoque no funciona para los modelos secuencia a secuencia, codificador-decodificador.
Tuve que replantearme toda la configuración, incluyendo el recopilador de datos, el entrenador y los argumentos de entrenamiento, e incluso cómo se realiza la inferencia.
En este tutorial, hemos recorrido un flujo de trabajo completo para ajustar T5Gemma-2 en una tarea de OCR de LaTeX, desde la configuración del entorno y la inspección del conjunto de datos hasta la recopilación de datos personalizada, el entrenamiento eficiente y la evaluación posterior al entrenamiento.
Utilizando un pequeño conjunto de datos y una única GPU A100, demostramos que un modelo multimodal codificador-decodificador puede aprender rápidamente a generar código LaTeX estructurado y significativo a partir de imágenes de ecuaciones.
Al final, el modelo ajustado fue mucho más allá de los resultados genéricos estándar y produjo ecuaciones LaTeX muy similares a la realidad, lo que demuestra lo accesibles y eficaces que pueden ser los modelos abiertos modernos ajustados para tareas reales de OCR y comprensión de documentos.
Si buscas más ejemplos prácticos sobre el ajuste fino de los LLM, te recomiendo que eches un vistazo al curso curso Ajuste con Llama 3.
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Aashi Dutt
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze


