Curso
Biomedical Image Analysis in Python
4 h
23.4K
SAM2 es un modelo básico desarrollado por Meta para la segmentación visual provocable en imágenes y vídeos. A diferencia de su predecesor SAMque se centraba principalmente en imágenes estáticas, SAM2 está diseñado para manejar también las complejidades de la segmentación de vídeo.
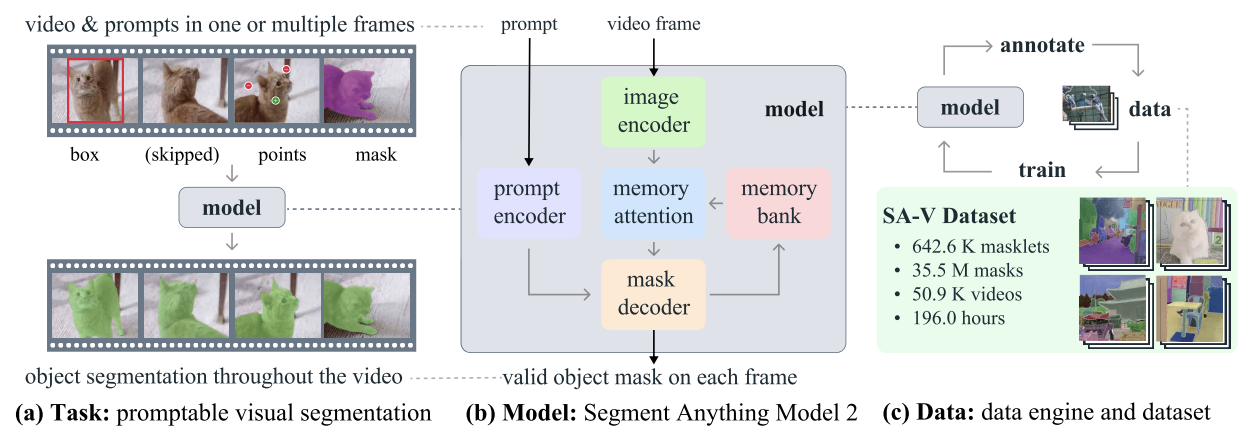
SAM2 - Tarea, Modelo y Datos (Fuente: Ravi et al., 2024)
Emplea una arquitectura de transformador con memoria streaming, que permite el procesamiento de vídeo en tiempo real. En el entrenamiento de SAM 2 se utilizó un conjunto de datos amplio y variado que incluía el novedoso conjunto de datos SA-V, que incluye más de 600.000 anotaciones de máscaras que abarcan 51.000 vídeos.
Su motor de datos, que permite la recogida interactiva de datos y la mejora del modelo, le confiere la capacidad de segmentar todo lo posible. Este motor permite que SAM 2 aprenda y se adapte continuamente, haciéndolo más eficiente en el manejo de datos nuevos y desafiantes. Sin embargo, para tareas específicas del dominio u objetos poco comunes, el ajuste fino es esencial para lograr un rendimiento óptimo.
En el contexto de SAM 2, el ajuste fino es el proceso de entrenar más el modelo SAM 2 preentrenado en un conjunto de datos específico para mejorar su rendimiento en una tarea o dominio concretos. Aunque SAM 2 es una potente herramienta entrenada en un conjunto de datos amplio y diverso, su naturaleza de uso general no siempre da resultados óptimos para tareas especializadas o poco frecuentes.
Por ejemplo, si estás trabajando en un proyecto de imágenes médicas que requiere la identificación de tipos específicos de tumores, el rendimiento del modelo podría quedarse corto debido a su entrenamiento generalizado.
El proceso de ajuste
El ajuste fino de SAM 2 aborda esta limitación permitiéndote adaptar el modelo a tu conjunto de datos específico. Este proceso mejora la precisión del modelo y lo hace más eficaz para tu caso de uso único.
Éstas son las principales ventajas de afinar SAM 2:
Para empezar con la puesta a punto de SAM 2, necesitarás cumplir los siguientes requisitos previos:
Software y otros requisitos:
La calidad de tu conjunto de datos es crucial para afinar el modelo SAM 2. Las imágenes o vídeos anotados de alta calidad con máscaras de segmentación precisas son esenciales para conseguir un rendimiento óptimo. Las anotaciones precisas permiten que el modelo aprenda las características correctas, lo que conduce a una mayor precisión de segmentación y solidez en las aplicaciones del mundo real.
El primer paso consiste en adquirir el conjunto de datos, que constituye la columna vertebral del proceso de entrenamiento. Obtuvimos nuestros datos de Kaggleuna plataforma fiable que proporciona una amplia gama de conjuntos de datos. Utilizando la API de Kaggle, descargamos los datos en el formato requerido, asegurándonos de que las imágenes y las correspondientes máscaras de segmentación estuvieran fácilmente disponibles para su posterior procesamiento.
Tras descargar los conjuntos de datos, realizamos los siguientes pasos:
Como el modelo SAM2 requiere la introducción de datos en formatos específicos, los convertimos de la siguiente manera:
A continuación, las imágenes y máscaras procesadas se organizan en sus respectivas carpetas para facilitar el acceso durante el proceso de ajuste. Además, las rutas a estas imágenes y máscaras se escriben en un archivo CSV (train.csv ) para facilitar la carga de datos durante el entrenamiento.
El último paso consistió en validar el conjunto de datos para garantizar su exactitud:
Aquí un cuaderno rápido que te guiará a través del código para la creación de conjuntos de datos. Puedes seguir esta ruta de creación de datos o utilizar directamente cualquier conjunto de datos disponible en Internet con el mismo formato que el mencionado en los requisitos previos.
Segmento Cualquier cosa El Modelo 2 contiene varios componentes, pero el truco aquí para un ajuste más rápido es entrenar sólo los componentes ligeros, como el descodificador de máscaras y el codificador de avisos, en lugar de todo el modelo. Los pasos para afinar este modelo son los siguientes:
Para iniciar el proceso de ajuste, necesitamos instalar la biblioteca SAM-2, que es crucial para el Modelo de Todo Segmento (SAM2). Este modelo está diseñado para manejar con eficacia diversas tareas de segmentación. La instalación consiste en clonar el repositorio SAM-2 de GitHub e instalar las dependencias necesarias.
!git clone https://github.com/facebookresearch/segment-anything-2
%cd /content/segment-anything-2
!pip install -q -e .Este fragmento de código garantiza que la biblioteca SAM2 está correctamente instalada y lista para ser utilizada en nuestro flujo de trabajo de ajuste.
Una vez instalada la biblioteca SAM-2, el siguiente paso es adquirir el conjunto de datos que utilizaremos para el ajuste. Utilizamos un conjunto de datos disponible en Kaggle, concretamente un conjunto de datos de segmentación de TAC de tórax que contiene imágenes y máscaras de pulmones, corazón y tráquea.
El conjunto de datos contiene:
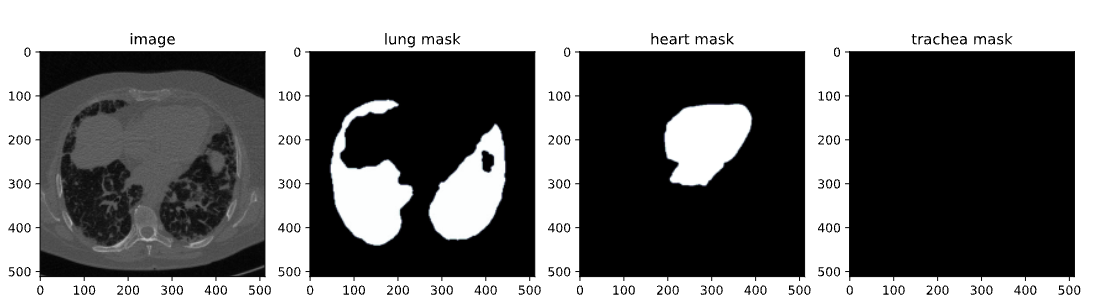
Imagen del conjunto de datos del TAC
En este blog, sólo utilizaremos imágenes y máscaras de pulmones para la segmentación. La API de Kaggle nos permite descargar conjuntos de datos directamente a nuestro entorno. Empezamos subiendo el archivo kaggle.json desde Kaggle para acceder fácilmente a cualquier conjunto de datos.
Para obtener kaggle.json, ve a la pestaña Configuración de tu perfil de usuario y selecciona Crear nuevo token. Esto activará la descarga de Kaggle. json, un archivo que contiene tus credenciales de la API.
# get dataset from Kaggle
from google.colab import files
files.upload() # This will prompt you to upload the kaggle.json file
!mkdir -p ~/.kaggle
!mv kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download -d polomarco/chest-ct-segmentationDescomprime los datos:
!unzip chest-ct-segmentation.zip -d chest-ct-segmentationCon el conjunto de datos listo, comencemos el proceso de ajuste. Como he mencionado anteriormente, la clave aquí es ajustar sólo los componentes ligeros de SAM2, como el descodificador de máscaras y el codificador de avisos, en lugar de todo el modelo. Este enfoque es más eficaz y requiere menos recursos.
Para el proceso de ajuste fino, necesitamos empezar con los pesos del modelo SAM2 preentrenado. Estos pesos, llamados "puntos de control", son el punto de partida para el entrenamiento posterior. Los puntos de control se han entrenado en una amplia gama de imágenes, y ajustándolos a nuestro conjunto de datos específico, podemos conseguir un mejor rendimiento en nuestras tareas objetivo.
!wget -O sam2_hiera_tiny.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_tiny.pt"
!wget -O sam2_hiera_small.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_small.pt"
!wget -O sam2_hiera_base_plus.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_base_plus.pt"
!wget -O sam2_hiera_large.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_large.pt"En este paso, descargamos varios puntos de control SAM-2 que corresponden a distintos tamaños de modelo (por ejemplo, diminuto, pequeño, base_plus, grande). La elección del punto de control puede ajustarse en función de los recursos informáticos disponibles y de la tarea específica que se esté realizando.
Con el conjunto de datos descargado, el siguiente paso es prepararlo para el entrenamiento. Esto implica dividir el conjunto de datos en conjuntos de entrenamiento y de prueba, y crear estructuras de datos que puedan introducirse en el modelo SAM 2 durante el ajuste fino.
%cd /content/segment-anything-2
import os
import pandas as pd
import cv2
import torch
import torch.nn.utils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
from sklearn.model_selection import train_test_split
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
# Path to the chest-ct-segmentation dataset folder
data_dir = "/content/segment-anything-2/chest-ct-segmentation"
images_dir = os.path.join(data_dir, "images/images")
masks_dir = os.path.join(data_dir, "masks/masks")
# Load the train.csv file
train_df = pd.read_csv(os.path.join(data_dir, "train.csv"))
# Split the data into two halves: one for training and one for testing
train_df, test_df = train_test_split(train_df, test_size=0.2, random_state=42)
# Prepare the training data list
train_data = []
for index, row in train_df.iterrows():
image_name = row['ImageId']
mask_name = row['MaskId']
# Append image and corresponding mask paths
train_data.append({
"image": os.path.join(images_dir, image_name),
"annotation": os.path.join(masks_dir, mask_name)
})
# Prepare the testing data list (if needed for inference or evaluation later)
test_data = []
for index, row in test_df.iterrows():
image_name = row['ImageId']
mask_name = row['MaskId']
# Append image and corresponding mask paths
test_data.append({
"image": os.path.join(images_dir, image_name),
"annotation": os.path.join(masks_dir, mask_name)
})
Dividimos el conjunto de datos en un conjunto de entrenamiento (80%) y un conjunto de prueba (20%) para asegurarnos de que podemos evaluar el rendimiento del modelo después del entrenamiento. Los datos de entrenamiento se utilizarán para afinar el modelo SAM 2, mientras que los datos de prueba se utilizarán para la inferencia y la evaluación.
Tras dividir tu conjunto de datos en conjuntos de entrenamiento y de prueba, el siguiente paso consiste en crear máscaras binarias, seleccionar puntos clave dentro de estas máscaras y visualizar estos elementos para asegurarte de que los datos se procesan correctamente.
1. Leer y redimensionar imágenes: El proceso comienza seleccionando al azar una imagen y su correspondiente máscara del conjunto de datos. La imagen se convierte de formato BGR a RGB, que es el formato de color estándar para la mayoría de los modelos de aprendizaje profundo. La anotación correspondiente (máscara) se lee en escala de grises. A continuación, tanto la imagen como la máscara de anotación se redimensionan a una dimensión máxima de 1024 píxeles, manteniendo la relación de aspecto para garantizar que los datos se ajustan a los requisitos de entrada del modelo y reducir la carga computacional.
def read_batch(data, visualize_data=False):
# Select a random entry
ent = data[np.random.randint(len(data))]
# Get full paths
Img = cv2.imread(ent["image"])[..., ::-1] # Convert BGR to RGB
ann_map = cv2.imread(ent["annotation"], cv2.IMREAD_GRAYSCALE) # Read annotation as grayscale
if Img is None or ann_map is None:
print(f"Error: Could not read image or mask from path {ent['image']} or {ent['annotation']}")
return None, None, None, 0
# Resize image and mask
r = np.min([1024 / Img.shape[1], 1024 / Img.shape[0]]) # Scaling factor
Img = cv2.resize(Img, (int(Img.shape[1] * r), int(Img.shape[0] * r)))
ann_map = cv2.resize(ann_map, (int(ann_map.shape[1] * r), int(ann_map.shape[0] * r)), interpolation=cv2.INTER_NEAREST)
2. Binarización de máscaras de segmentación: La máscara de anotación multiclase (que puede tener varias clases de objetos etiquetados con distintos valores de píxel) se convierte en una máscara binaria. Esta máscara resalta todas las regiones de interés de la imagen, simplificando la tarea de segmentación a un problema de clasificación binaria: objeto frente a fondo. A continuación, la máscara binaria se erosiona utilizando un núcleo de 5x5.
La erosión reduce ligeramente el tamaño de la máscara, lo que ayuda a evitar los efectos de límite al seleccionar los puntos. Esto garantiza que los puntos seleccionados estén bien dentro del interior del objeto, en lugar de cerca de sus bordes, que podrían ser ruidosos o ambiguos.
Los puntos clave se seleccionan dentro de la máscara erosionada. Estos puntos actúan como indicaciones durante el proceso de ajuste, guiando al modelo sobre dónde debe centrar su atención. Los puntos se seleccionan aleatoriamente del interior de los objetos para garantizar que sean representativos y no estén influidos por límites ruidosos.
### Continuation of read_batch() ###
# Initialize a single binary mask
binary_mask = np.zeros_like(ann_map, dtype=np.uint8)
points = []
# Get binary masks and combine them into a single mask
inds = np.unique(ann_map)[1:] # Skip the background (index 0)
for ind in inds:
mask = (ann_map == ind).astype(np.uint8) # Create binary mask for each unique index
binary_mask = np.maximum(binary_mask, mask) # Combine with the existing binary mask
# Erode the combined binary mask to avoid boundary points
eroded_mask = cv2.erode(binary_mask, np.ones((5, 5), np.uint8), iterations=1)
# Get all coordinates inside the eroded mask and choose a random point
coords = np.argwhere(eroded_mask > 0)
if len(coords) > 0:
for _ in inds: # Select as many points as there are unique labels
yx = np.array(coords[np.random.randint(len(coords))])
points.append([yx[1], yx[0]])
points = np.array(points)
3. Visualización: Este paso es crucial para verificar que los pasos del preprocesamiento de datos se han ejecutado correctamente. Inspeccionando visualmente los puntos de la máscara binarizada, puedes asegurarte de que el modelo recibirá la información adecuada durante el entrenamiento. Por último, la máscara binaria se remodela y se formatea correctamente (con dimensiones adecuadas para la entrada del modelo), y los puntos también se remodelan para su uso posterior en el proceso de entrenamiento. La función devuelve la imagen procesada, la máscara binaria, los puntos seleccionados y el número de máscaras encontradas.
### Continuation of read_batch() ###
if visualize_data:
# Plotting the images and points
plt.figure(figsize=(15, 5))
# Original Image
plt.subplot(1, 3, 1)
plt.title('Original Image')
plt.imshow(img)
plt.axis('off')
# Segmentation Mask (binary_mask)
plt.subplot(1, 3, 2)
plt.title('Binarized Mask')
plt.imshow(binary_mask, cmap='gray')
plt.axis('off')
# Mask with Points in Different Colors
plt.subplot(1, 3, 3)
plt.title('Binarized Mask with Points')
plt.imshow(binary_mask, cmap='gray')
# Plot points in different colors
colors = list(mcolors.TABLEAU_COLORS.values())
for i, point in enumerate(points):
plt.scatter(point[0], point[1], c=colors[i % len(colors)], s=100, label=f'Point {i+1}') # Corrected to plot y, x order
# plt.legend()
plt.axis('off')
plt.tight_layout()
plt.show()
binary_mask = np.expand_dims(binary_mask, axis=-1) # Now shape is (1024, 1024, 1)
binary_mask = binary_mask.transpose((2, 0, 1))
points = np.expand_dims(points, axis=1)
# Return the image, binarized mask, points, and number of masks
return img, binary_mask, points, len(inds)
# Visualize the data
Img1, masks1, points1, num_masks = read_batch(train_data, visualize_data=True)
El código anterior devuelve la siguiente figura que contiene la imagen original del conjunto de datos junto con su máscara binarizada y su máscara binarizada con puntos.

Imagen original, máscara binarizada y máscara binarizada con puntos para el conjunto de datos.
El ajuste fino del modelo SAM2 implica varios pasos, como cargar el modelo, configurar el optimizador y el programador, y actualizar iterativamente los pesos del modelo basándose en los datos de entrenamiento.
Carga los puntos de control del modelo:
sam2_checkpoint = "sam2_hiera_small.pt" # @param ["sam2_hiera_tiny.pt", "sam2_hiera_small.pt", "sam2_hiera_base_plus.pt", "sam2_hiera_large.pt"]
model_cfg = "sam2_hiera_s.yaml" # @param ["sam2_hiera_t.yaml", "sam2_hiera_s.yaml", "sam2_hiera_b+.yaml", "sam2_hiera_l.yaml"]
sam2_model = build_sam2(model_cfg, sam2_checkpoint, device="cuda")
predictor = SAM2ImagePredictor(sam2_model)
Empezamos construyendo el modelo SAM2 utilizando los puntos de control preentrenados. A continuación, el modelo se envuelve en una clase predictora, lo que simplifica el proceso de configuración de imágenes, codificación de indicaciones y descodificación de máscaras.
Configuramos varios hiperparámetros para asegurarnos de que el modelo aprende eficazmente, como la tasa de aprendizaje, el decaimiento del peso y los pasos de acumulación del gradiente. Estos hiperparámetros controlan el proceso de aprendizaje, incluida la rapidez con la que el modelo actualiza sus pesos y cómo evita el sobreajuste. Siéntete libre de jugar con ellas.
# Train mask decoder.
predictor.model.sam_mask_decoder.train(True)
# Train prompt encoder.
predictor.model.sam_prompt_encoder.train(True)
# Configure optimizer.
optimizer=torch.optim.AdamW(params=predictor.model.parameters(),lr=0.0001,weight_decay=1e-4) #1e-5, weight_decay = 4e-5
# Mix precision.
scaler = torch.cuda.amp.GradScaler()
# No. of steps to train the model.
NO_OF_STEPS = 3000 # @param
# Fine-tuned model name.
FINE_TUNED_MODEL_NAME = "fine_tuned_sam2"
El optimizador se encarga de actualizar los pesos del modelo, mientras que el programador ajusta la tasa de aprendizaje durante el entrenamiento para mejorar la convergencia. Afinando estos parámetros, podemos conseguir una mayor precisión de segmentación.
El proceso real de ajuste fino es iterativo, en el que en cada paso se pasa por el modelo un lote de imágenes y máscaras sólo para pulmones, y se calcula la pérdida y se utiliza para actualizar los pesos del modelo.
# Initialize scheduler
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=500, gamma=0.2) # 500 , 250, gamma = 0.1
accumulation_steps = 4 # Number of steps to accumulate gradients before updating
for step in range(1, NO_OF_STEPS + 1):
with torch.cuda.amp.autocast():
image, mask, input_point, num_masks = read_batch(train_data, visualize_data=False)
if image is None or mask is None or num_masks == 0:
continue
input_label = np.ones((num_masks, 1))
if not isinstance(input_point, np.ndarray) or not isinstance(input_label, np.ndarray):
continue
if input_point.size == 0 or input_label.size == 0:
continue
predictor.set_image(image)
mask_input, unnorm_coords, labels, unnorm_box = predictor._prep_prompts(input_point, input_label, box=None, mask_logits=None, normalize_coords=True)
if unnorm_coords is None or labels is None or unnorm_coords.shape[0] == 0 or labels.shape[0] == 0:
continue
sparse_embeddings, dense_embeddings = predictor.model.sam_prompt_encoder(
points=(unnorm_coords, labels), boxes=None, masks=None,
)
batched_mode = unnorm_coords.shape[0] > 1
high_res_features = [feat_level[-1].unsqueeze(0) for feat_level in predictor._features["high_res_feats"]]
low_res_masks, prd_scores, _, _ = predictor.model.sam_mask_decoder(
image_embeddings=predictor._features["image_embed"][-1].unsqueeze(0),
image_pe=predictor.model.sam_prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=True,
repeat_image=batched_mode,
high_res_features=high_res_features,
)
prd_masks = predictor._transforms.postprocess_masks(low_res_masks, predictor._orig_hw[-1])
gt_mask = torch.tensor(mask.astype(np.float32)).cuda()
prd_mask = torch.sigmoid(prd_masks[:, 0])
seg_loss = (-gt_mask * torch.log(prd_mask + 0.000001) - (1 - gt_mask) * torch.log((1 - prd_mask) + 0.00001)).mean()
inter = (gt_mask * (prd_mask > 0.5)).sum(1).sum(1)
iou = inter / (gt_mask.sum(1).sum(1) + (prd_mask > 0.5).sum(1).sum(1) - inter)
score_loss = torch.abs(prd_scores[:, 0] - iou).mean()
loss = seg_loss + score_loss * 0.05
# Apply gradient accumulation
loss = loss / accumulation_steps
scaler.scale(loss).backward()
# Clip gradients
torch.nn.utils.clip_grad_norm_(predictor.model.parameters(), max_norm=1.0)
if step % accumulation_steps == 0:
scaler.step(optimizer)
scaler.update()
predictor.model.zero_grad()
# Update scheduler
scheduler.step()
if step % 500 == 0:
FINE_TUNED_MODEL = FINE_TUNED_MODEL_NAME + "_" + str(step) + ".torch"
torch.save(predictor.model.state_dict(), FINE_TUNED_MODEL)
if step == 1:
mean_iou = 0
mean_iou = mean_iou * 0.99 + 0.01 * np.mean(iou.cpu().detach().numpy())
if step % 100 == 0:
print("Step " + str(step) + ":\t", "Accuracy (IoU) = ", mean_iou)
En cada iteración, el modelo procesa un lote de imágenes, calcula las máscaras de segmentación y las compara con la verdad del terreno para calcular la pérdida. A continuación, esta pérdida se utiliza para ajustar las ponderaciones del modelo, mejorando gradualmente su rendimiento. Tras un entrenamiento de unas 3000 épocas, obtenemos una precisión (IoU - Intersección sobre Unión) de aproximadamente el 72%.
A continuación, el modelo puede utilizarse para la inferencia, donde predice máscaras de segmentación en imágenes nuevas no vistas. Empieza con lasfunciones de ayuda read_images y get_points para obtener la imagen de inferencia y su máscara junto con los puntos clave.
def read_image(image_path, mask_path): # read and resize image and mask
img = cv2.imread(image_path)[..., ::-1] # Convert BGR to RGB
mask = cv2.imread(mask_path, 0)
r = np.min([1024 / img.shape[1], 1024 / img.shape[0]])
img = cv2.resize(img, (int(img.shape[1] * r), int(img.shape[0] * r)))
mask = cv2.resize(mask, (int(mask.shape[1] * r), int(mask.shape[0] * r)), interpolation=cv2.INTER_NEAREST)
return img, mask
def get_points(mask, num_points): # Sample points inside the input mask
points = []
coords = np.argwhere(mask > 0)
for i in range(num_points):
yx = np.array(coords[np.random.randint(len(coords))])
points.append([[yx[1], yx[0]]])
return np.array(points)A continuación, carga las imágenes de muestra que desees para la inferencia, junto con los pesos recién afinados, y realiza la inferencia configurando torch.no_grad().
# Randomly select a test image from the test_data
selected_entry = random.choice(test_data)
image_path = selected_entry['image']
mask_path = selected_entry['annotation']
# Load the selected image and mask
image, mask = read_image(image_path, mask_path)
# Generate random points for the input
num_samples = 30 # Number of points per segment to sample
input_points = get_points(mask, num_samples)
# Load the fine-tuned model
FINE_TUNED_MODEL_WEIGHTS = "fine_tuned_sam2_1000.torch"
sam2_model = build_sam2(model_cfg, sam2_checkpoint, device="cuda")
# Build net and load weights
predictor = SAM2ImagePredictor(sam2_model)
predictor.model.load_state_dict(torch.load(FINE_TUNED_MODEL_WEIGHTS))
# Perform inference and predict masks
with torch.no_grad():
predictor.set_image(image)
masks, scores, logits = predictor.predict(
point_coords=input_points,
point_labels=np.ones([input_points.shape[0], 1])
)
# Process the predicted masks and sort by scores
np_masks = np.array(masks[:, 0])
np_scores = scores[:, 0]
sorted_masks = np_masks[np.argsort(np_scores)][::-1]
# Initialize segmentation map and occupancy mask
seg_map = np.zeros_like(sorted_masks[0], dtype=np.uint8)
occupancy_mask = np.zeros_like(sorted_masks[0], dtype=bool)
# Combine masks to create the final segmentation map
for i in range(sorted_masks.shape[0]):
mask = sorted_masks[i]
if (mask * occupancy_mask).sum() / mask.sum() > 0.15:
continue
mask_bool = mask.astype(bool)
mask_bool[occupancy_mask] = False # Set overlapping areas to False in the mask
seg_map[mask_bool] = i + 1 # Use boolean mask to index seg_map
occupancy_mask[mask_bool] = True # Update occupancy_mask
# Visualization: Show the original image, mask, and final segmentation side by side
plt.figure(figsize=(18, 6))
plt.subplot(1, 3, 1)
plt.title('Test Image')
plt.imshow(image)
plt.axis('off')
plt.subplot(1, 3, 2)
plt.title('Original Mask')
plt.imshow(mask, cmap='gray')
plt.axis('off')
plt.subplot(1, 3, 3)
plt.title('Final Segmentation')
plt.imshow(seg_map, cmap='jet')
plt.axis('off')
plt.tight_layout()
plt.show()En este paso, utilizamos el modelo afinado para generar máscaras de segmentación para las imágenes de prueba. A continuación, las máscaras predichas se visualizan junto con las imágenes originales y las máscaras de la verdad sobre el terreno para evaluar el rendimiento del modelo.

Imagen de segmentación final en los datos de prueba
El ajuste fino de SAM2 ofrece una forma práctica de mejorar sus capacidades para tareas específicas. Tanto si trabajas en imágenes médicas, vehículos autónomos o edición de vídeo, el ajuste fino te permite utilizar SAM2 para tus necesidades únicas. Siguiendo esta guía, podrás adaptar SAM2 a tus proyectos y conseguir resultados de segmentación de vanguardia.
Para casos de uso más avanzados, considera la posibilidad de ajustar componentes adicionales de SAM2, como el codificador de imágenes. Aunque esto requiere más recursos, ofrece mayor flexibilidad y mejoras de rendimiento.
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Dimitri Didmanidze

