
Kurs
Feinabstimmung mit Llama 3
2 Std.
3.7K
T5Gemma 2 ist eine Familie von leichter, offener Encoder-Decoder-Modelle von Google, die auf Gemma 3 basieren und mehrsprachige und multimodale Eingaben unterstützen.
Mit einem Kontextfenster von bis zu 128K in über 140 Sprachen und parametereffizienten Designoptionen wie gebundenen Einbettungen und zusammengeführter Aufmerksamkeit eignen sich diese Modelle super für die Textgenerierung und das Verständnis von Bildern, während sie gleichzeitig klein genug sind, um auf einem Laptop zu laufen.
In diesem Tutorial zeigen wir dir, wie du ein Encoder-Decoder-Modell auf einem LaTeX-OCR-Datensatz feinabstimmst. Das Ziel ist, mit möglichst wenigen Trainingsbeispielen eine starke Leistung zu erreichen.
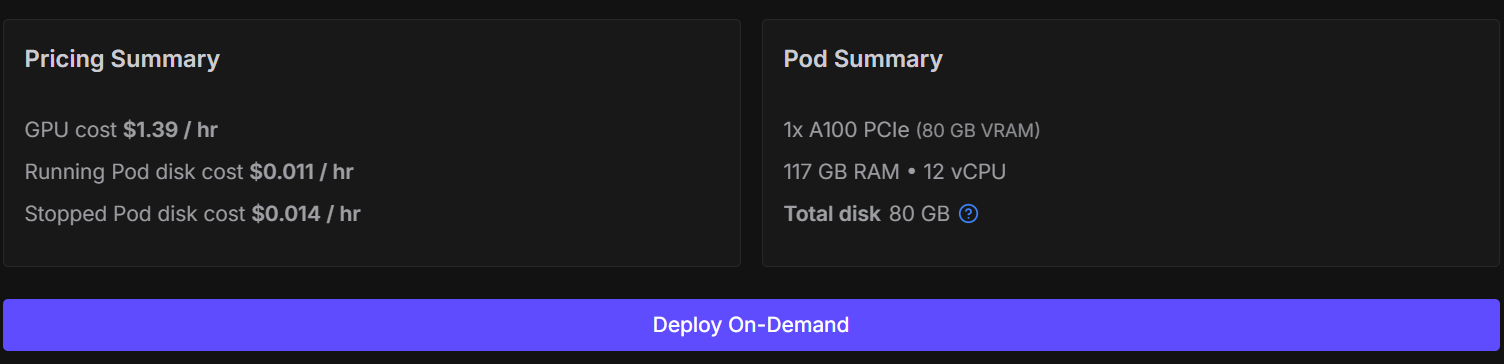
Man kann dieses Modell zwar auf Kaggle oder Google Colab optimieren, aber das führt oft zu instabilen Sitzungen, Verbindungsabbrüchen und deutlich langsamerem Training. Um diese Probleme zu vermeiden und die Einrichtung einfach und zuverlässig zu halten, nehmen wir eine NVIDIA A100 GPU.
Du kannst einen A100 auf RunPod für etwa 1,39 $ pro Stundemieten , und der ganze Trainingsprozess in diesem Tutorial sollte weniger als 30 Minuten dauern . Mit dieser Konfiguration bekommst du eine konstante Leistung, ohne dich mit Speicherbeschränkungen rumschlagen zu müssen.
Geh zuerst zu RunPod und mach einen neuen Pod mit dem neuesten PyTorch-Image. Wähle eine Maschine vom Typ „ “ 1× A100.
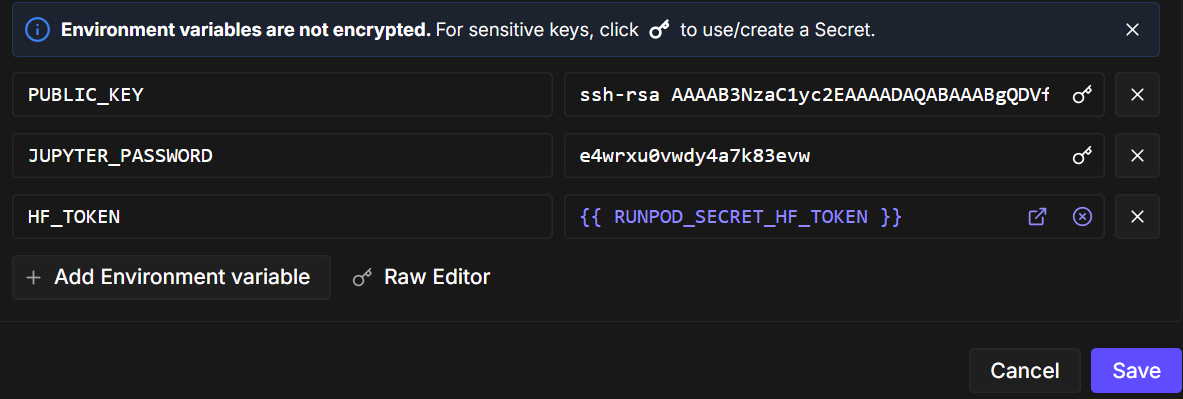
Als Nächstes bearbeitest du die Pod-Konfiguration und fügst eine Umgebungsvariable namens „ HF_TOKEN “ hinzu. Dieses Token ist nötig, um:
Sobald der Pod fertig ist, starte das Notebook und installiere die benötigten Python-Pakete. Stell sicher, dass du die neueste Version von transformers benutzt.
!pip -q install -U accelerate datasets pillow sentencepiece safetensors
!pip install --quiet "transformers==5.0.0rc1"
!pip install --quiet --no-deps trlJetzt importierst du die Bibliotheken und Hilfsprogramme, die wir im gesamten Notebook verwenden werden.
import torch
from datasets import load_dataset
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer, set_seedVor dem Training machen wir ein paar Einstellungen, die für A100-GPUs optimiert sind. Das Setzen eines Startwerts sorgt für Reproduzierbarkeit, und das Aktivieren von TF32 verbessert die Leistung, ohne die Stabilität des bf16-Trainings zu beeinträchtigen.
set_seed(42)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
print("CUDA:", torch.cuda.is_available(), torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)
print("bf16 supported:", torch.cuda.is_available() and torch.cuda.is_bf16_supported())CUDA: True NVIDIA A100 80GB PCIe
bf16 supported: TrueIn diesem Tutorial nutzen wir den LaTeX-OCR-Datensatz von Hugging Face. Jedes Beispiel im Datensatz besteht aus:
Der Datensatz bietet mehrere Konfigurationen. Damit das Training effizient bleibt und unserem Ziel entspricht, aus begrenzten Daten zu lernen, werden wir die Größe des Datensatzes bewusst kontrollieren.
Lade zuerst die Trainings- und Validierungssätze. Um ein Szenario mit wenig Daten für die Feinabstimmung zu simulieren, mischen wir den Datensatz einfach und nehmen eine kleine Teilmenge:
Dadurch bleibt das Training schnell und das Modell kann trotzdem verallgemeinern.
DATASET_NAME = "full"
raw_train = load_dataset("linxy/LaTeX_OCR", name=DATASET_NAME, split="train")
raw_val = load_dataset("linxy/LaTeX_OCR", name=DATASET_NAME, split="validation")
train_ds = raw_train.shuffle(seed=42).select(range(1000))
val_ds = raw_val.shuffle(seed=42).select(range(200))
print(train_ds, val_ds)
print("Columns:", train_ds.column_names)Ausgabe:
Dataset({
features: ['image', 'text'],
num_rows: 1000
}) Dataset({
features: ['image', 'text'],
num_rows: 200
})
Columns: ['image', 'text']Um die Daten besser zu verstehen, schauen wir uns mal ein einzelnes Trainingsbeispiel an. Schau dir zuerst das Bild an.
train_ds[10]["image"]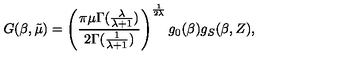
Als Nächstes checkst du die mit diesem Bild verbundene LaTeX-Zeichenkette.
train_ds[10]["text"]'G ( \\beta , \\tilde { \\mu } ) = \\left( \\frac { \\pi \\mu \\Gamma ( \\frac { \\lambda } { \\lambda + 1 } ) } { 2 \\Gamma ( \\frac { 1 } { \\lambda + 1 } ) } \\right) ^ { \\frac { 1 } { 2 \\lambda } } g _ { 0 } ( \\beta ) g _ { S } ( \\beta , Z ) ,'Schließlich können wir diesen LaTeX-Ausdruck direkt im Notizbuch rendern, um zu überprüfen, ob der Text mit dem Bildinhalt übereinstimmt.
from IPython.display import display, Math, Latex
latex = train_ds[10]["text"]
display(Math(latex))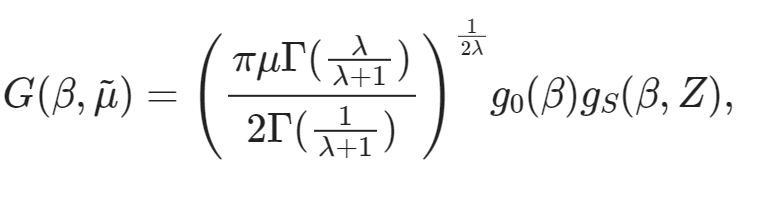
Jetzt, wo der Datensatz fertig ist, geht's weiter mit dem Laden des T5Gemma-2-Modells „ “ und dem dazugehörigen Prozessor. Wir werden die 270M–270M, die ein gutes Gleichgewicht zwischen Leistung und Effizienz bietet und problemlos auf eine Consumer-GPU passt.
MODEL_ID = "google/t5gemma-2-270m-270m"
processor = AutoProcessor.from_pretrained(MODEL_ID, use_fast=True)
model = AutoModelForSeq2SeqLM.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16, # A100 -> bf16
device_map="auto",
)Der Zugriff auf den Tokenizer erfolgt über den Prozessor. Einige Encoder-Decoder-Modelle haben standardmäßig kein Padding-Token, also fügen wir bei Bedarf eins hinzu und passen die Größe der Token-Einbettungen des Modells entsprechend an.
tokenizer = processor.tokenizer
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": tokenizer.eos_token})
model.resize_token_embeddings(len(tokenizer))Bei LaTeX OCR steuern wir das Modell mit einer kurzen Textanweisung, die mit dem Eingabebild gepaart ist. Diese Eingabeaufforderung macht die Aufgabe klar und legt das Ausgabeformat fest.
Zum Schluss legen wir die maximalen Sequenzlängen für den Encoder-Input und das Decoder-Ziel fest. Diese Werte reichen für die meisten mathematischen Ausdrücke aus und halten gleichzeitig den Speicherverbrauch im Griff.
PROMPT = "<start_of_image> Convert this image to LaTeX. Output only LaTeX."
MAX_INPUT_LEN = 128
MAX_TARGET_LEN = 256Bevor du mit der Feinabstimmung anfängst, ist es sinnvoll, eine Basis-Inferenz, mit dem vortrainierten T5Gemma-2-Modell durchzuführen . Das hilft uns zu verstehen, wie sich das Modell bei der LaTeX-OCR-Aufgabe ohne aufgabenspezifisches Training verhält, und gibt uns einen Anhaltspunkt für spätere Verbesserungen.
Hier ist eine kurze Zusammenfassung des Prozesses:
image = train_ds[20]["image"]
# prepare inputs
model_inputs = processor(text=PROMPT, images=image, return_tensors="pt")
model_inputs = {k: v.to("cuda") for k, v in model_inputs.items()}
# run inference
model = model.eval()
with torch.inference_mode():
generation = model.generate(
**model_inputs,
max_new_tokens=100,
do_sample=False,
num_beams=3,
repetition_penalty=1.2,
no_repeat_ngram_size=4,
early_stopping=True,
)
# decode
pred = processor.decode(generation[0], skip_special_tokens=True)
print("\n--- Model output ---")
print(pred)Beispielausgabe aus dem vortrainierten Modell:
--- Model output ---
Use this command to change this image's format:\usepackage[T1]{fontenc}\usepackage[utf8]{inputenc}\DeclareUnicodeUTF8{1234567890123}\begin{document}<tex>$\begin{equation}\begin{aligned}P=&\frac{1+(-)\frac{1}{2}\left(F_{1}(-)\frac{F_{2}(-Schauen wir uns jetzt mal das LaTeX-Code für dasselbe Bild an.
train_ds[20]["text"]Grundlegende Wahrheit:
'{ \\cal P } = \\frac { 1 + ( - ) ^ { F } { \\cal I } _ { 4 } ( - ) ^ { F _ { L } } } { 2 } .'Wie erwartet, liefert das vortrainierte Modell keine korrekte LaTeX-Transkription. Stattdessen macht es generische LaTeX-Boilerplate und nicht zusammenhängende Teile. Das ist normal, weil das Basismodell nicht extra für LaTeX-OCR trainiert wurde.
In diesem Abschnitt erstellen wir einen benutzerdefinierten Bild-Text-Daten-Sortierer, um Bilder, Eingabeaufforderungen und LaTeX-Ziele für die Feinabstimmung richtig zu gruppieren. Weil T5Gemma-2 ein multimodales Encoder-Decoder-Modell ist, ist der Collator echt wichtig, um sicherzustellen, dass Bilder und Text richtig ausgerichtet sind und im erwarteten Format an das Modell weitergegeben werden.
Genauer gesagt, der Sortierer:
Zusammen sorgen diese Schritte für ein stabiles Training, eine korrekte Verlustberechnung und zuverlässige Konvergenz beim Feinabstimmen des Modells auf LaTeX-OCR-Daten.
from typing import Any, Dict, List
import torch
from PIL import Image as PILImage
tokenizer = processor.tokenizer
tokenizer.padding_side = "right"
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": tokenizer.eos_token})
pad_id = tokenizer.pad_token_id
PROMPT = "<start_of_image> Convert this equation image to LaTeX. Output only LaTeX."
MAX_TARGET_LEN = 256
def collate_fn(examples: List[Dict[str, Any]]) -> Dict[str, torch.Tensor]:
images, prompts, targets = [], [], []
for ex in examples:
im = ex["image"]
if isinstance(im, PILImage.Image):
im = im.convert("RGB")
elif isinstance(im, dict) and "path" in im:
im = PILImage.open(im["path"]).convert("RGB")
else:
raise ValueError(f"Unexpected image type: {type(im)}")
# IMPORTANT: one image per sample -> nested list
images.append([im])
prompts.append(PROMPT)
targets.append(ex["text"])
# ✅ NO truncation here (prevents image-token mismatch)
model_inputs = processor(
text=prompts,
images=images,
padding=True,
truncation=False,
return_tensors="pt",
)
labels = tokenizer(
targets,
padding=True,
truncation=True,
max_length=MAX_TARGET_LEN,
return_tensors="pt",
)["input_ids"]
labels[labels == pad_id] = -100
model_inputs["labels"] = labels
return model_inputsIn diesem Abschnitt legen wir die Trainingskonfiguration und die Optimierungseinstellungen fest, um T5Gemma-2 für die LaTeX-OCR-Aufgabe fein abzustimmen. Das Setup ist absichtlich einfach gehalten und für schnelles Training auf einer einzelnen A100-GPU optimiert, wobei ein kleiner Datensatz und eine einzige Trainingsepochen verwendet werden.
Um den Aufwand zu reduzieren und die Dinge zu beschleunigen, deaktivieren wir die Auswertung und das Speichern von Checkpoints und konzentrieren uns nur auf effiziente Vorwärts- und Rückwärtsdurchläufe.
from transformers import Seq2SeqTrainingArguments
args = Seq2SeqTrainingArguments(
output_dir="t5gemma2-latex-ocr-1k",
# --- core training ---
num_train_epochs=1,
per_device_train_batch_size=8,
gradient_accumulation_steps=1,
learning_rate=1e-4,
warmup_steps=15,
lr_scheduler_type="linear",
# --- precision / speed ---
bf16=True,
fp16=False,
tf32=True,
# --- memory ---
gradient_checkpointing=True,
# --- stop extra work (this is the big speed win) ---
eval_strategy="no",
predict_with_generate=False,
save_strategy="no",
report_to="none",
# --- dataloader ---
dataloader_num_workers=0,
remove_unused_columns=False,
# --- logging ---
logging_steps=10,
)Zum Schluss initialisieren wir die Funktion „ Seq2SeqTrainer “. Wir geben unseren benutzerdefinierten Daten-Collator explizit weiter, damit der Trainer während des Trainings multimodale Batches erstellen kann, die Bilder, Anweisungsaufforderungen und LaTeX-Zielsequenzen kombinieren.
trainer = Seq2SeqTrainer(
model=model,
args=args,
train_dataset=train_ds,
eval_dataset=val_ds,
data_collator=collate_fn,
)Jetzt, wo alles fertig ist, können wir mit der Feinabstimmung des Modells loslegen. Das Training startet mit einem einzigen Anruf beim Trainer.
trainer.train()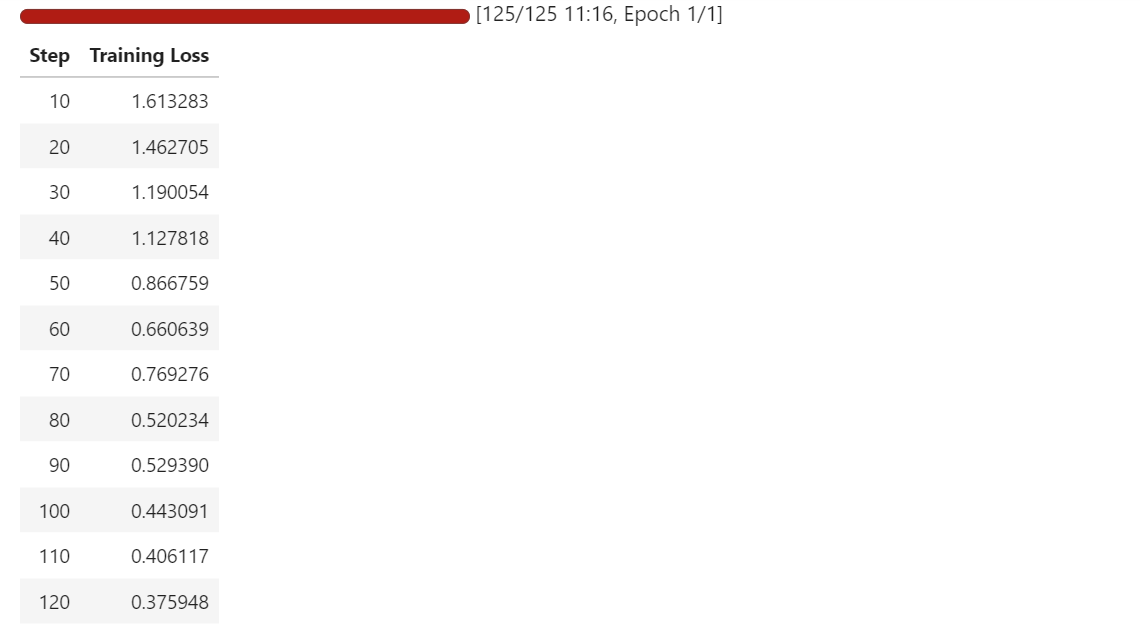
Während des Trainings wird der Verlust immer kleiner, was zeigt, dass das Modell lernt, Gleichungsbilder besser ihren entsprechenden LaTeX-Darstellungen zuzuordnen.
Selbst mit einem kleinen Datensatz und nur einer Epoche fängt das Modell an, sich schnell an die OCR-Aufgabe anzupassen.
Nach der Feinabstimmung führen wir die Inferenz erneut auf beiden Trainingsstichprobe und einer Validierungsstichprobe durch, um zu sehen, wie sich die Ergebnisse des Modells verändert haben.
Im Vergleich zur Basisversion, die meistens nur allgemeine LaTeX-Boilerplate-Texte erzeugt hat, macht das optimierte Modell jetzt strukturierte LaTeX-Texte, die ziemlich genau der Form und den Symbolen der Zielgleichungen entsprechen.
Wir fangen damit an, dass wir dasselbe Trainingsbeispiel wie vorher testen. Das Bild wird durch den Prozessor geschickt, das Modell macht Tokens und dann werden sie wieder in LaTeX umgewandelt.
# pick a sample
image = train_ds[10]["image"]
# prepare inputs
model_inputs = processor(text=PROMPT, images=image, return_tensors="pt")
model_inputs = {k: v.to("cuda") for k, v in model_inputs.items()}
# run inference
model = model.eval()
with torch.inference_mode():
generation = model.generate(
**model_inputs,
max_new_tokens=100,
do_sample=False,
num_beams=3,
repetition_penalty=1.2,
no_repeat_ngram_size=4,
early_stopping=True,
)
# decode
pred = processor.decode(generation[0], skip_special_tokens=True)
print(pred)Wie du siehst, kriegen wir jetzt eine ordentliche LaTeX-Ausgabe und keinen zufälligen oder zusammenhanglosen Text. Im Trainingsbeispiel stimmt die Vorhersage ziemlich gut mit der tatsächlichen Wahrheit überein, wobei die restlichen Fehler hauptsächlich bei Brüchen, Indizes und ein paar falsch platzierten Tokens auftreten.
G ( \beta , \tilde { \mu } ) = \left( \frac { \pi \mu \Gamma } { 2 \Gamma } \lambda _ { + 1 } ^ { \lambda } \right) \right) ^ { \frac { 1 } { 9 \Gamma } g _ { 0 } ( \beta ) g _ { S } ( \theta , Z ) , \right) , \qquad G ( \bar { \Als Nächstes testen wir das Modell an einer Validierungsstichprobe , um die Verallgemeinerung zu checken.
image = val_ds[10]["image"]
# prepare inputs
model_inputs = processor(text=PROMPT, images=image, return_tensors="pt")
model_inputs = {k: v.to("cuda") for k, v in model_inputs.items()}
# run inference
model = model.eval()
with torch.inference_mode():
generation = model.generate(
**model_inputs,
max_new_tokens=100,
do_sample=False,
num_beams=3,
repetition_penalty=1.2,
no_repeat_ngram_size=4,
early_stopping=True,
)
# decode
pred = processor.decode(generation[0], skip_special_tokens=True)
print(pred)Im Validierungsbeispiel hält sich das Modell immer noch an die richtige LaTeX-Struktur und die richtigen Symbole, auch wenn es manchmal Fehler bei der Klammerplatzierung, bei Ausdrücken in Klammern und bei längeren Ausdrücken macht.
f ( p , p ^ { \prime } ) = \ln \left\{ \frac { ( p _ { i } - p _ { j } ) ^ { 2 } } { \left( \frac { \psi ( p _ j ) - g ( p ; p _ { s } ) \psi ( \psi _ { i ] } ) \right\} . . . g ( \psi ; \psi ) - g \left( p ; \psi _Im Vergleich zur tatsächlichen Situation passt die Gesamtstruktur gut und das Modell liefert ziemlich genaue Ergebnisse statt irgendwelcher unpassenden.
print(val_ds[10]["text"])f ( p , p ^ { \prime } ) = \ln \left\{ \frac { ( p _ { i } - p _ { j } ) ^ { 2 } } { ( p _ { i } + p _ { j } ) ^ { 2 } } \right\} \left[ \psi ( p _ { j } ) - g ( p _ { i } , p _ { j } ) \psi ( p _ { i } ) \right] .Insgesamt zeigen die Ergebnisse nach der Feinabstimmung eine deutliche Verbesserung. Das Modell rät nicht mehr einfach bei generischen LaTeX-Vorlagen, sondern macht stattdessen LaTeX-Formeln, die den Zielen im Datensatz ziemlich ähnlich sind, selbst mit einem kleinen Trainingssatz und einem kurzen Feinabstimmungslauf.
Sobald das Training fertig ist, speicherst du das fein abgestimmte Modell erst mal lokal, damit du es später für die Inferenz wiederverwenden kannst.
trainer.save_model()Als Nächstes schicken wir das Modell zum Hugging Face Hub, damit andere drauf zugreifen, es wiederverwenden und darauf aufbauen können.
trainer.push_to_hub()Beim Checken der Repository-Dateien fällt dir vielleicht auf, dass die Prozessorkonfiguration nicht immer dabei ist, wenn das Modell durch den Trainer geschickt wird.
Da der Prozessor sowohl Bilder als auch Text richtig verarbeiten muss, schicken wir ihn extra separat, damit das Modell ohne zusätzliche Einstellungen geladen und genutzt werden kann.
processor.push_to_hub(repo_id="kingabzpro/t5gemma2-latex-ocr-1k")
Mit diesem Schritt hat das Repository alles, was man braucht, um das Modell und den Prozessor mit einem einzigen Aufruf zu laden. Du kannst jetzt die Seite kingabzpro/t5gemma2-latex-ocr-1k auf Hugging Face besuchen, um auf das fein abgestimmte Modell zuzugreifen und es für LaTeX-OCR oder weitere Experimente zu nutzen.
Jetzt, wo das optimierte Modell auf dem Hugging Face Hub veröffentlicht ist, können wir es direkt für die Inferenz über die API „ pipeline “ laden. Das ist die einfachste Art, das Modell zu testen, ohne sich manuell mit Prozessoren, Tokenizern oder Generierungslogik beschäftigen zu müssen.
Wir laden das Modell aus dem Hub und erstellen eine Pipeline namens „ image-text-to-text “:
from transformers import pipeline
generator = pipeline(
"image-text-to-text",
model="kingabzpro/t5gemma2-latex-ocr-1k",
)Als Nächstes machen wir eine Inferenz auf einer Validierungsprobe und benutzen dabei die gleiche Anweisungsaufforderung wie vorher.
generator(
val_ds[10]["image"],
text="<start_of_image> Convert this image to LaTeX. Output only LaTeX.",
generate_kwargs={"do_sample": False, "max_new_tokens": 100},
)Wie du siehst, ist die Ausgabe schon ziemlich nah am richtigen LaTeX.
[{'input_text': '<start_of_image> Convert this image to LaTeX. Output only LaTeX.',
'generated_text': '<start_of_image> Convert this image to LaTeX. Output only LaTeX.f ( p , p ^ { \\prime } ) = \\ln \\left\\{ \\begin{array} { \\begin{array} { \\begin{array} { \\begin{array} { \\begin{array} { \\end{array} \\right\\} \\begin{array} { \\begin{array} { \\begin{array} { \\end{array} \\right\\} \\begin{array} { \\begin{array} { \\begin{array} {'}]Probieren wir noch ein Validierungsbeispiel aus und bearbeiten die Ausgabe nach, um nur die LaTeX-Zeichenkette zu behalten.
preds = generator(
val_ds[30]["image"],
text="<start_of_image> Convert this image to LaTeX. Output only LaTeX.",
generate_kwargs={"do_sample": False, "max_new_tokens": 100},
)
prompt = preds[0]["input_text"]
gen = preds[0]["generated_text"]
# remove the prompt if the model echoed it
if gen.startswith(prompt):
gen = gen[len(prompt):]
# remove any leftover special tokens / separators
gen = gen.replace("<start_of_image>", "").strip()
if gen.startswith("."):
gen = gen[1:].strip()
print("\nCLEAN PREDICTED LaTeX:\n", gen)Dieses Mal ist das Ergebnis sauber und kann direkt als LaTeX verwendet werden:
CLEAN PREDICTED LaTeX:
T _ { M N } = \left\{ g N \nu \partial _ { M P _ { } } \cdot \left\{ g ^ { N } \nu \partial _ { M P _ { } } \cdot \left\{ g ^ { N } \nu \partial _ { M P _ { } } \cdot \left\{ g ^ { N } \nu \partial _ { M P _ { } } \cdot \left\{ g ^ {Jetzt kann das Modell als Drop-in-LaTeX-OCR-System genutzt werden. Du kannst es hinter einer API einsetzen, in eine Dokumentenverarbeitungs-Pipeline integrieren oder mit mehr Daten weiter optimieren, um eine noch bessere Genauigkeit zu erreichen.
Wenn du beim Ausführen des obigen Codes Probleme hast, schau dir bitte das Hilfsnotizbuchan. Es hat den kompletten Code und zeigt dir bei jedem Schritt die Ergebnisse, um dir den Prozess zu erklären.
Als ich mit dem Training des Modells angefangen habe, habe ich es wie jedes andere große Sprachmodell mit einem Bild-Encoder behandelt. Nachdem ich ein paar Mal gescheitert bin, habe ich gemerkt, dass dieser Ansatz bei Sequenz-zu-Sequenz- und Encoder-Decoder-Modellen nicht klappt.
Ich musste das ganze Setup überdenken, vom Datenkollator über den Trainer und die Trainingsargumente bis hin zur Art und Weise, wie die Inferenz durchgeführt wird.
In diesem Tutorial haben wir einen kompletten Arbeitsablauf durchgespielt, um T5Gemma-2 für eine LaTeX-OCR-Aufgabe zu optimieren. Wir haben mit der Einrichtung der Umgebung und der Überprüfung des Datensatzes angefangen und sind dann zu benutzerdefinierter Datenzusammenstellung, effizientem Training und Bewertung nach dem Training übergegangen.
Mit einem kleinen Datensatz und einer einzigen A100-GPU haben wir gezeigt, dass ein multimodales Encoder-Decoder-Modell schnell lernen kann, aus Gleichungsbildern strukturiertes, sinnvolles LaTeX zu generieren.
Am Ende hat das fein abgestimmte Modell weit mehr als nur allgemeine Standardausgaben geliefert und LaTeX-Formeln erzeugt, die der tatsächlichen Situation ziemlich nahe kommen. Das zeigt, wie zugänglich und effektiv die Feinabstimmung moderner offener Modelle für echte OCR- und Dokumentenverständnisaufgaben sein kann.
Wenn du nach mehr praktischen Beispielen für die Feinabstimmung von LLMs suchst, empfehle ich dir den Kurs Kurs „Fine-Tuning mit Llama 3”.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
Tutorial
Mark Pedigo
Tutorial
Laiba Siddiqui
