
Curso
Fine-Tuning with Llama 3
2 h
3.7K
O T5Gemma 2 é uma família de modelos de codificadores-decodificadores leves e de peso aberto do Google, baseados no Gemma 3, que suportam entradas multilíngues e multimodais.
Com uma janela de contexto de até 128K em mais de 140 idiomas e opções de design eficientes em termos de parâmetros, como incorporações vinculadas e atenção combinada, esses modelos são perfeitos para tarefas de geração de texto e compreensão de imagens, além de serem pequenos o suficiente para rodar em um laptop.
Neste tutorial, vamos aprender a ajustar um modelo codificador-decodificador em um conjunto de dados OCR do LaTeX. O objetivo é conseguir um bom desempenho usando o mínimo de amostras de treinamento.
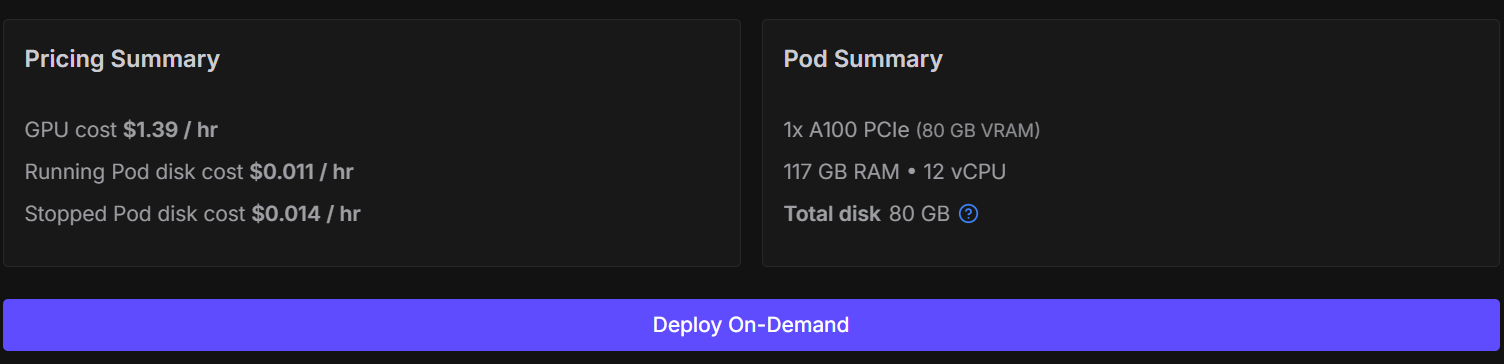
Embora seja possível ajustar esse modelo no Kaggle ou no Google Colab, fazer isso muitas vezes leva a sessões instáveis, desconexões de recursos e um treinamento bem mais lento. Pra evitar esses pontos de atrito e manter a configuração simples e confiável, vamos usar uma GPU NVIDIA A100.
Você pode alugar um A100 no RunPod por cerca de US$ 1,39 por hora, e o processo completo de treinamento neste tutorial deve levar menos de 30 minutos. Essa configuração oferece um desempenho consistente sem restrições de memória.
Comece acessando o RunPod e criando um novo pod usando a imagem PyTorch mais recente. Escolha uma máquina 1× A100.
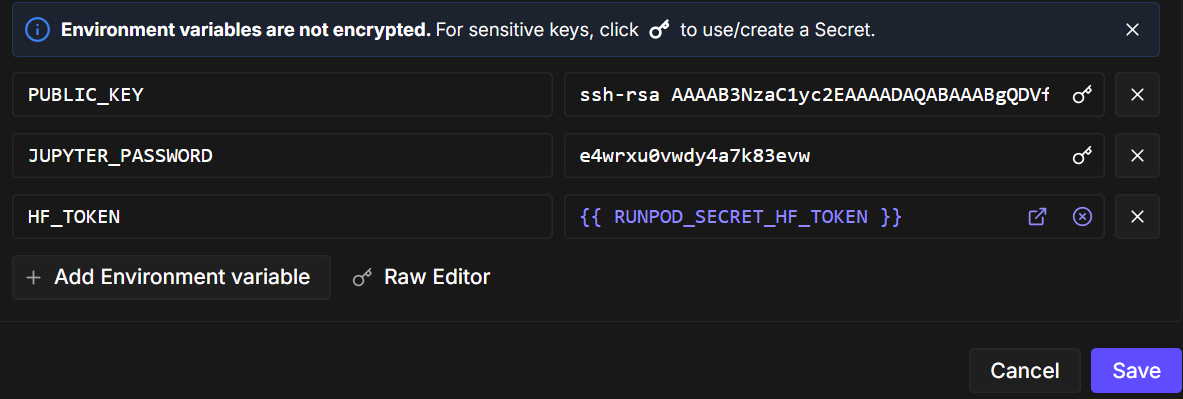
Depois, edite a configuração do pod e adicione uma variável de ambiente chamada ` HF_TOKEN`. Esse token é necessário para:
Quando o pod estiver pronto, abra o notebook e instale os pacotes Python necessários. Certifique-se de que está usando a versão mais recente do transformers.
!pip -q install -U accelerate datasets pillow sentencepiece safetensors
!pip install --quiet "transformers==5.0.0rc1"
!pip install --quiet --no-deps trlAgora, vamos importar as bibliotecas e utilitários que vamos usar ao longo do caderno.
import torch
from datasets import load_dataset
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer, set_seedAntes do treinamento, a gente aplica algumas configurações otimizadas para GPUs A100. Definir uma semente garante a reprodutibilidade, e ativar o TF32 melhora o desempenho sem afetar a estabilidade do treinamento do bf16.
set_seed(42)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
print("CUDA:", torch.cuda.is_available(), torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)
print("bf16 supported:", torch.cuda.is_available() and torch.cuda.is_bf16_supported())CUDA: True NVIDIA A100 80GB PCIe
bf16 supported: TrueNeste tutorial, usamos o conjunto de dados LaTeX OCR disponível no Hugging Face. Cada exemplo no conjunto de dados tem:
O conjunto de dados oferece várias configurações. Para manter o treinamento eficiente e alinhado com nosso objetivo de aprender com dados limitados, vamos controlar explicitamente o tamanho do conjunto de dados.
Primeiro, carregue as divisões de treinamento e validação. Para simular um cenário de ajuste fino com poucos dados, a gente embaralha o conjunto de dados aleatoriamente e escolhe um pequeno subconjunto:
Isso mantém o treinamento rápido, ao mesmo tempo que permite que o modelo generalize.
DATASET_NAME = "full"
raw_train = load_dataset("linxy/LaTeX_OCR", name=DATASET_NAME, split="train")
raw_val = load_dataset("linxy/LaTeX_OCR", name=DATASET_NAME, split="validation")
train_ds = raw_train.shuffle(seed=42).select(range(1000))
val_ds = raw_val.shuffle(seed=42).select(range(200))
print(train_ds, val_ds)
print("Columns:", train_ds.column_names)Resultado:
Dataset({
features: ['image', 'text'],
num_rows: 1000
}) Dataset({
features: ['image', 'text'],
num_rows: 200
})
Columns: ['image', 'text']Para entender melhor os dados, vamos ver um exemplo de treinamento. Primeiro, dá uma olhada na imagem.
train_ds[10]["image"]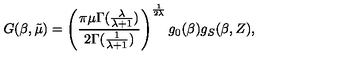
Depois, dá uma olhada na string LaTeX bruta que tá ligada a essa imagem.
train_ds[10]["text"]'G ( \\beta , \\tilde { \\mu } ) = \\left( \\frac { \\pi \\mu \\Gamma ( \\frac { \\lambda } { \\lambda + 1 } ) } { 2 \\Gamma ( \\frac { 1 } { \\lambda + 1 } ) } \\right) ^ { \\frac { 1 } { 2 \\lambda } } g _ { 0 } ( \\beta ) g _ { S } ( \\beta , Z ) ,'Por fim, podemos renderizar essa expressão LaTeX diretamente no caderno para ver se o texto bate com o conteúdo da imagem.
from IPython.display import display, Math, Latex
latex = train_ds[10]["text"]
display(Math(latex))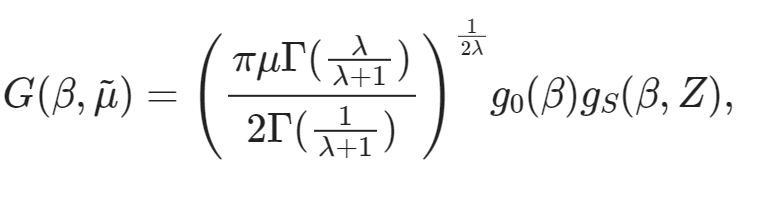
Agora que o conjunto de dados está pronto, o próximo passo é carregar o modeloT5Gemma-2 e seu processador correspondente. Vamos usar o variante 270M–270M, que oferece um equilíbrio sólido entre capacidade e eficiência e se encaixa perfeitamente em uma GPU de consumo.
MODEL_ID = "google/t5gemma-2-270m-270m"
processor = AutoProcessor.from_pretrained(MODEL_ID, use_fast=True)
model = AutoModelForSeq2SeqLM.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16, # A100 -> bf16
device_map="auto",
)O tokenizador é acessado através do processador. Alguns modelos de codificador-decodificador não definem um token de preenchimento por padrão, então adicionamos um, se necessário, e redimensionamos as incorporações de tokens do modelo de acordo.
tokenizer = processor.tokenizer
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": tokenizer.eos_token})
model.resize_token_embeddings(len(tokenizer))Para o OCR LaTeX, a gente orienta o modelo usando um pequeno prompt textual junto com a imagem de entrada. Essa solicitação deixa bem claro o que precisa ser feito e define o formato da resposta.
Por fim, definimos os comprimentos máximos das sequências para a entrada do codificador e o destino do decodificador. Esses valores são suficientes para a maioria das expressões matemáticas, mantendo o uso da memória sob controle.
PROMPT = "<start_of_image> Convert this image to LaTeX. Output only LaTeX."
MAX_INPUT_LEN = 128
MAX_TARGET_LEN = 256Antes de começar o ajuste fino, é legal fazer uma inferência de linha de base usando o modelo pré-treinado T5Gemma-2. Isso nos ajuda a entender como o modelo se comporta na tarefa de OCR do LaTeX sem nenhum treinamento específico para a tarefa e nos dá um ponto de referência para melhorias futuras.
Aqui vai um resumo do processo:
image = train_ds[20]["image"]
# prepare inputs
model_inputs = processor(text=PROMPT, images=image, return_tensors="pt")
model_inputs = {k: v.to("cuda") for k, v in model_inputs.items()}
# run inference
model = model.eval()
with torch.inference_mode():
generation = model.generate(
**model_inputs,
max_new_tokens=100,
do_sample=False,
num_beams=3,
repetition_penalty=1.2,
no_repeat_ngram_size=4,
early_stopping=True,
)
# decode
pred = processor.decode(generation[0], skip_special_tokens=True)
print("\n--- Model output ---")
print(pred)Exemplo de resultado do modelo pré-treinado:
--- Model output ---
Use this command to change this image's format:\usepackage[T1]{fontenc}\usepackage[utf8]{inputenc}\DeclareUnicodeUTF8{1234567890123}\begin{document}<tex>$\begin{equation}\begin{aligned}P=&\frac{1+(-)\frac{1}{2}\left(F_{1}(-)\frac{F_{2}(-Agora, vamos dar uma olhada no LaTeX da imagem original.
train_ds[20]["text"]Ground-truth:
'{ \\cal P } = \\frac { 1 + ( - ) ^ { F } { \\cal I } _ { 4 } ( - ) ^ { F _ { L } } } { 2 } .'Como era de se esperar, o modelo pré-treinado não produz uma transcrição LaTeX correta. Em vez disso, gera um modelo genérico do LaTeX e fragmentos sem relação. Esse comportamento é normal, já que o modelo básico não foi treinado especificamente para OCR LaTeX.
Nesta seção, criamos um coletor personalizado de dados de imagem-texto para agrupar corretamente imagens, prompts e alvos LaTeX para ajuste fino. Como o T5Gemma-2 é um modelo codificador-decodificador multimodal, o classificador é super importante pra garantir que as imagens e o texto fiquem alinhados corretamente e sejam passados pro modelo no formato esperado.
Especificamente, o classificador:
Juntas, essas etapas garantem um treinamento estável, um cálculo correto das perdas e uma convergência confiável ao ajustar o modelo nos dados OCR do LaTeX.
from typing import Any, Dict, List
import torch
from PIL import Image as PILImage
tokenizer = processor.tokenizer
tokenizer.padding_side = "right"
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({"pad_token": tokenizer.eos_token})
pad_id = tokenizer.pad_token_id
PROMPT = "<start_of_image> Convert this equation image to LaTeX. Output only LaTeX."
MAX_TARGET_LEN = 256
def collate_fn(examples: List[Dict[str, Any]]) -> Dict[str, torch.Tensor]:
images, prompts, targets = [], [], []
for ex in examples:
im = ex["image"]
if isinstance(im, PILImage.Image):
im = im.convert("RGB")
elif isinstance(im, dict) and "path" in im:
im = PILImage.open(im["path"]).convert("RGB")
else:
raise ValueError(f"Unexpected image type: {type(im)}")
# IMPORTANT: one image per sample -> nested list
images.append([im])
prompts.append(PROMPT)
targets.append(ex["text"])
# ✅ NO truncation here (prevents image-token mismatch)
model_inputs = processor(
text=prompts,
images=images,
padding=True,
truncation=False,
return_tensors="pt",
)
labels = tokenizer(
targets,
padding=True,
truncation=True,
max_length=MAX_TARGET_LEN,
return_tensors="pt",
)["input_ids"]
labels[labels == pad_id] = -100
model_inputs["labels"] = labels
return model_inputsNesta seção, vamos definir a configuração de treinamento e as configurações de otimização para ajustar o T5Gemma-2 na tarefa de OCR do LaTeX. A configuração é bem simples e otimizada pra um treinamento rápido em uma única GPU A100, usando um pequeno conjunto de dados e uma única época de treinamento.
Para reduzir a sobrecarga e acelerar as coisas, desativamos a avaliação e o salvamento de pontos de verificação e nos concentramos apenas em passagens para frente e para trás eficientes.
from transformers import Seq2SeqTrainingArguments
args = Seq2SeqTrainingArguments(
output_dir="t5gemma2-latex-ocr-1k",
# --- core training ---
num_train_epochs=1,
per_device_train_batch_size=8,
gradient_accumulation_steps=1,
learning_rate=1e-4,
warmup_steps=15,
lr_scheduler_type="linear",
# --- precision / speed ---
bf16=True,
fp16=False,
tf32=True,
# --- memory ---
gradient_checkpointing=True,
# --- stop extra work (this is the big speed win) ---
eval_strategy="no",
predict_with_generate=False,
save_strategy="no",
report_to="none",
# --- dataloader ---
dataloader_num_workers=0,
remove_unused_columns=False,
# --- logging ---
logging_steps=10,
)Por fim, a gente inicializa o Seq2SeqTrainer. Passamos explicitamente nosso coletor de dados personalizado para que o treinador possa construir corretamente lotes multimodais que combinam imagens, instruções e sequências-alvo LaTeX durante o treinamento.
trainer = Seq2SeqTrainer(
model=model,
args=args,
train_dataset=train_ds,
eval_dataset=val_ds,
data_collator=collate_fn,
)Com tudo pronto, agora podemos começar a ajustar o modelo. O treinamento começa com uma ligação para o instrutor.
trainer.train()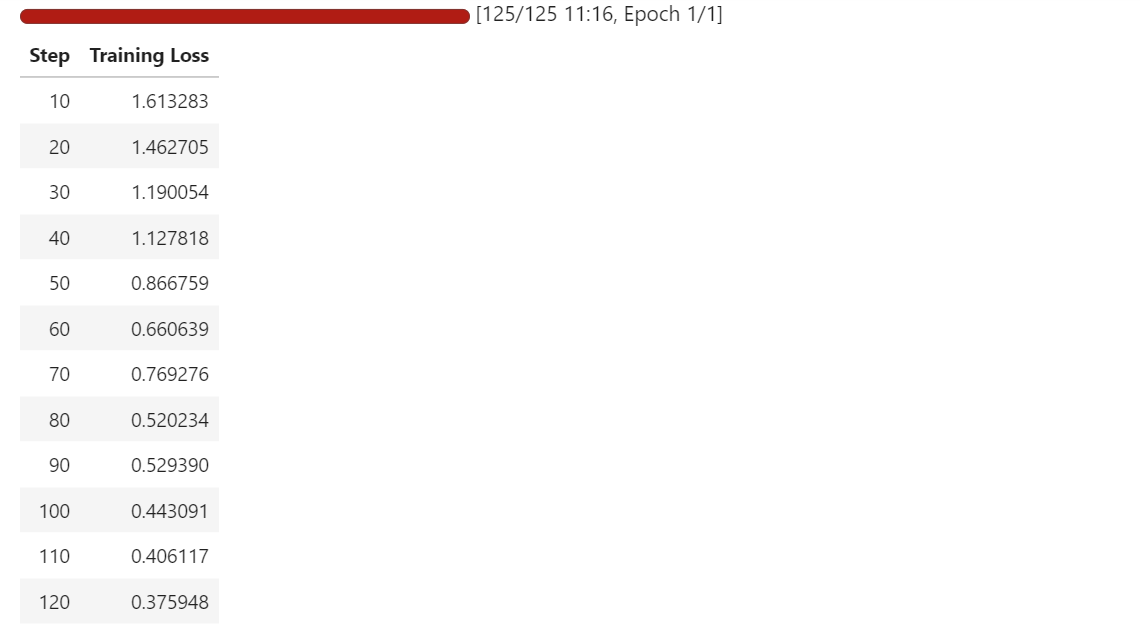
Durante o treinamento, a perda diminui aos poucos, mostrando que o modelo está aprendendo a mapear melhor as imagens das equações para suas representações correspondentes em LaTeX.
Mesmo com um conjunto de dados pequeno e só uma época, o modelo começa a se adaptar rapidinho à tarefa de OCR.
Depois de ajustar tudo, a gente faz a inferência de novo em uma amostra de treinamento e em uma amostra de validação para ver como os resultados do modelo mudaram.
Comparado com a linha de base, que produzia principalmente modelos genéricos do LaTeX, o modelo ajustado agora gera um LaTeX estruturado que se aproxima bastante da forma e dos símbolos das equações-alvo.
Começamos testando o mesmo exemplo de treinamento de antes. A imagem passa pelo processador, os tokens são gerados pelo modelo e, em seguida, decodificados de volta para LaTeX.
# pick a sample
image = train_ds[10]["image"]
# prepare inputs
model_inputs = processor(text=PROMPT, images=image, return_tensors="pt")
model_inputs = {k: v.to("cuda") for k, v in model_inputs.items()}
# run inference
model = model.eval()
with torch.inference_mode():
generation = model.generate(
**model_inputs,
max_new_tokens=100,
do_sample=False,
num_beams=3,
repetition_penalty=1.2,
no_repeat_ngram_size=4,
early_stopping=True,
)
# decode
pred = processor.decode(generation[0], skip_special_tokens=True)
print(pred)Como você pode ver, agora temos uma saída LaTeX adequada, sem texto aleatório ou sem relação. No exemplo de treinamento, a previsão está bem alinhada com a verdade fundamental, com os erros restantes principalmente em frações, índices e alguns tokens mal posicionados.
G ( \beta , \tilde { \mu } ) = \left( \frac { \pi \mu \Gamma } { 2 \Gamma } \lambda _ { + 1 } ^ { \lambda } \right) \right) ^ { \frac { 1 } { 9 \Gamma } g _ { 0 } ( \beta ) g _ { S } ( \theta , Z ) , \right) , \qquad G ( \bar { \Depois, a gente testa o modelo em uma amostra de validação para verificar a generalização.
image = val_ds[10]["image"]
# prepare inputs
model_inputs = processor(text=PROMPT, images=image, return_tensors="pt")
model_inputs = {k: v.to("cuda") for k, v in model_inputs.items()}
# run inference
model = model.eval()
with torch.inference_mode():
generation = model.generate(
**model_inputs,
max_new_tokens=100,
do_sample=False,
num_beams=3,
repetition_penalty=1.2,
no_repeat_ngram_size=4,
early_stopping=True,
)
# decode
pred = processor.decode(generation[0], skip_special_tokens=True)
print(pred)No exemplo de validação, o modelo ainda segue a estrutura e os símbolos corretos do LaTeX, embora ocasionalmente cometa erros na colocação de colchetes, termos entre parênteses e expressões mais longas.
f ( p , p ^ { \prime } ) = \ln \left\{ \frac { ( p _ { i } - p _ { j } ) ^ { 2 } } { \left( \frac { \psi ( p _ j ) - g ( p ; p _ { s } ) \psi ( \psi _ { i ] } ) \right\} . . . g ( \psi ; \psi ) - g \left( p ; \psi _Quando comparado com a verdade fundamental, a estrutura geral está claramente alinhada, e o modelo está produzindo uma aproximação próxima, em vez de resultados irrelevantes.
print(val_ds[10]["text"])f ( p , p ^ { \prime } ) = \ln \left\{ \frac { ( p _ { i } - p _ { j } ) ^ { 2 } } { ( p _ { i } + p _ { j } ) ^ { 2 } } \right\} \left[ \psi ( p _ { j } ) - g ( p _ { i } , p _ { j } ) \psi ( p _ { i } ) \right] .No geral, os resultados após o ajuste fino mostram uma melhora clara. O modelo não fica mais tentando adivinhar modelos genéricos do LaTeX e, em vez disso, gera LaTeX parecido com equações que se assemelha bastante aos alvos do conjunto de dados, mesmo com um pequeno conjunto de treinamento e um curto período de ajuste fino.
Depois que o treinamento estiver pronto, o primeiro passo é salvar o modelo ajustado localmente para poder usá-lo de novo mais tarde para inferência.
trainer.save_model()Depois, a gente manda o modelo pro Hugging Face Hub pra que outras pessoas possam acessar, reutilizar e desenvolver a partir dele.
trainer.push_to_hub()Ao dar uma olhada nos arquivos do repositório, você pode perceber que a configuração do processador nem sempre é incluída ao enviar o modelo pelo treinador.
Como o processador precisa lidar corretamente com imagens e texto, nós o enviamos explicitamente de forma separada para garantir que o modelo possa ser carregado e usado sem configurações extras.
processor.push_to_hub(repo_id="kingabzpro/t5gemma2-latex-ocr-1k")
Com essa etapa, o repositório tem tudo que precisa para carregar o modelo e o processador com uma única chamada. Agora você pode visitar kingabzpro/t5gemma2-latex-ocr-1k no Hugging Face para acessar o modelo ajustado e começar a usá-lo para OCR LaTeX ou outras experiências.
Agora que o modelo ajustado foi publicado no Hugging Face Hub, podemos carregá-lo direto para inferência usando a API pipeline. Essa é a maneira mais simples de testar o modelo sem precisar mexer manualmente em processadores, tokenizadores ou lógica de geração.
Carregamos o modelo do Hub e criamos um pipeline de image-text-to-text:
from transformers import pipeline
generator = pipeline(
"image-text-to-text",
model="kingabzpro/t5gemma2-latex-ocr-1k",
)Depois, fazemos a inferência em uma amostra de validação usando a mesma instrução de prompt de antes.
generator(
val_ds[10]["image"],
text="<start_of_image> Convert this image to LaTeX. Output only LaTeX.",
generate_kwargs={"do_sample": False, "max_new_tokens": 100},
)Como você pode ver, o resultado já está bem próximo do LaTeX correto.
[{'input_text': '<start_of_image> Convert this image to LaTeX. Output only LaTeX.',
'generated_text': '<start_of_image> Convert this image to LaTeX. Output only LaTeX.f ( p , p ^ { \\prime } ) = \\ln \\left\\{ \\begin{array} { \\begin{array} { \\begin{array} { \\begin{array} { \\begin{array} { \\end{array} \\right\\} \\begin{array} { \\begin{array} { \\begin{array} { \\end{array} \\right\\} \\begin{array} { \\begin{array} { \\begin{array} {'}]Vamos tentar outra amostra de validação e pós-processar a saída para manter apenas a string LaTeX.
preds = generator(
val_ds[30]["image"],
text="<start_of_image> Convert this image to LaTeX. Output only LaTeX.",
generate_kwargs={"do_sample": False, "max_new_tokens": 100},
)
prompt = preds[0]["input_text"]
gen = preds[0]["generated_text"]
# remove the prompt if the model echoed it
if gen.startswith(prompt):
gen = gen[len(prompt):]
# remove any leftover special tokens / separators
gen = gen.replace("<start_of_image>", "").strip()
if gen.startswith("."):
gen = gen[1:].strip()
print("\nCLEAN PREDICTED LaTeX:\n", gen)Desta vez, o resultado é limpo e pode ser usado diretamente como LaTeX:
CLEAN PREDICTED LaTeX:
T _ { M N } = \left\{ g N \nu \partial _ { M P _ { } } \cdot \left\{ g ^ { N } \nu \partial _ { M P _ { } } \cdot \left\{ g ^ { N } \nu \partial _ { M P _ { } } \cdot \left\{ g ^ { N } \nu \partial _ { M P _ { } } \cdot \left\{ g ^ {Neste ponto, o modelo pode ser usado como um sistema OCR LaTeX pronto para uso. Você pode implementá-lo por trás de uma API, integrá-lo a um pipeline de processamento de documentos ou continuar ajustando-o com mais dados para obter uma precisão ainda melhor.
Se você tiver algum problema ao executar o código acima, dá uma olhada no caderno auxiliar. Ele tem o código completo junto com os resultados de cada etapa pra te ajudar no processo.
Quando comecei a treinar o modelo, tratei-o como qualquer modelo de linguagem grande com um codificador de imagens. Depois de tentar várias vezes, percebi que essa abordagem não funciona para modelos sequência-para-sequência, codificador-decodificador.
Tive que repensar toda a configuração, incluindo o coletor de dados, o treinador e os argumentos de treinamento, e até mesmo como a inferência é feita.
Neste tutorial, a gente deu uma olhada em um fluxo de trabalho completo para ajustar o T5Gemma-2 em uma tarefa de OCR do LaTeX, começando pela configuração do ambiente e inspeção do conjunto de dados até a compilação personalizada de dados, treinamento eficiente e avaliação pós-treinamento.
Usando um pequeno conjunto de dados e uma única GPU A100, mostramos que um modelo multimodal codificador-decodificador pode aprender rapidamente a gerar LaTeX estruturado e significativo a partir de imagens de equações.
No final, o modelo ajustado foi muito além da saída genérica padrão e produziu LaTeX semelhante a equações que corresponde de perto à verdade fundamental, mostrando como o ajuste fino de modelos abertos modernos pode ser acessível e eficaz para tarefas reais de OCR e compreensão de documentos.
Se você está procurando mais exemplos práticos de ajuste fino de LLMs, recomendo conferir o curso curso Ajuste fino com Llama 3.
Cursos mais populares do DataCamp
Curso
Curso
Curso
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt


