
programa
Desarrollo de aplicaciones de IA
21 h
Gemini 2.0 Flash tiene una ventana de contexto de 1.000.000 de tokens, lo que permite el procesamiento completo del conjunto de datos sin necesidad de mecanismos de fragmentación o recuperación. Además, es rentable en comparación con modelos más grandes como Gemini Ultra.
Muchas aplicaciones utilizan generación aumentada por recuperación (RAG) para el análisis de datos estructurados, pero Gemini 2.0 Flash elimina la necesidad de RAG porque:
Si quieres utilizar Gemini 2.0 Flash Lite para optimizar costes, puedes hacerlo, pero ten en cuenta que en el momento de publicar este artículo, tiene una velocidad limitada a 60 consultas por minuto y sólo está disponible en la región us-central1.
Vamos a esbozar los pasos principales que vamos a dar:
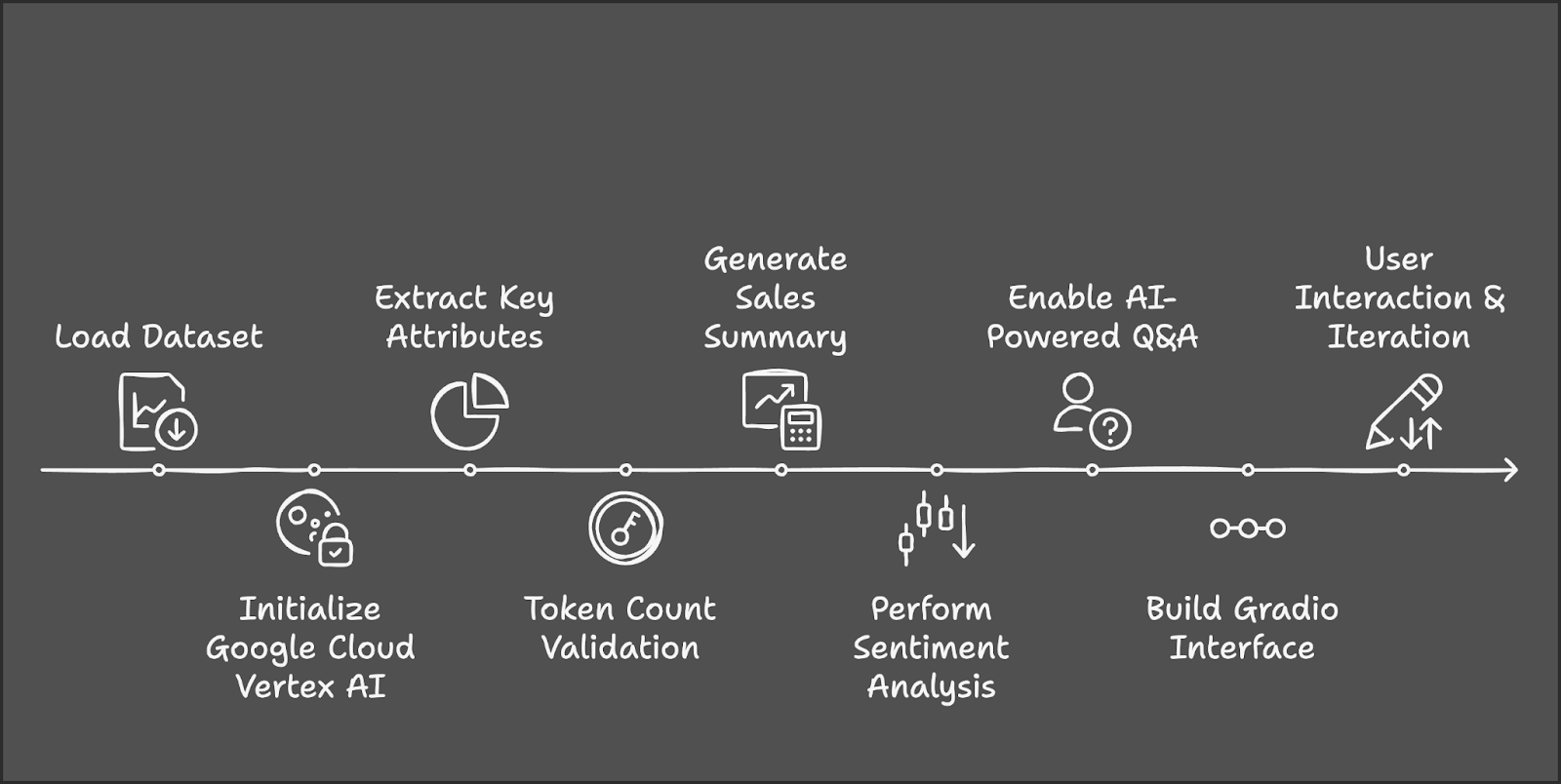
Antes de empezar, asegurémonos de que tenemos instaladas las siguientes herramientas y bibliotecas:
Ejecuta los siguientes comandos para instalar las dependencias necesarias:
!pip install gradio -q
!pip install --upgrade --quiet google-genai
!pip install datasets -q
!pip install tiktoken -q
!pip install kaggle -qUna vez instaladas las dependencias anteriores, ejecuta los siguientes comandos de importación:
import sys
import os
import tiktoken
from datasets import load_dataset
import pandas as pd
import gradio as gr
import vertexai
from vertexai.preview.generative_models import GenerativeModelUtilizaremos el conjunto de datos conjunto de datos de Ventas SAAS de AWS para este proyecto, que está disponible en Kaggle. Empieza configurando las credenciales de Kaggle y pasando el autor y el nombre del conjunto de datos, respectivamente.
# Set Kaggle API credentials
os.environ["KAGGLE_CONFIG_DIR"] = os.path.expanduser("~/.kaggle")
# Download dataset
!kaggle datasets download -d nnthanh101/aws-saas-sales --unzipAhora que el conjunto de datos se ha descargado en nuestro entorno, podemos empezar a trabajar con él. Utilizaremos la biblioteca pandas para cargar y leer el conjunto de datos de la ruta.
dataset_path = "path_to_your_data.csv" # Load dataset from specified path
dataset_df = pd.read_csv(dataset_path) Este conjunto de datos contiene 9.994 transacciones con columnas como:
Para utilizar Gemini 2.0 Flash, necesitamos autenticarnos con Google Cloud.
if "google.colab" in sys.modules:
from google.colab import auth
auth.authenticate_user()Para inicializar la IA de Vértice, busca la API de IA de Vértice y actívala (asegúrate de que la facturación está activada en tu cuenta).
Guarda el ID y la ubicación del proyecto para futuras consultas. Ejecutar Gemini 2.0 Flash para este proyecto costó unos 0,07 $ por aproximadamente cinco llamadas a la API.
# Set up Google Cloud Vertex AI
PROJECT_ID = "Your_project_id"
LOCATION = "Your_location"
vertexai.init(project=PROJECT_ID, location=LOCATION)
model = GenerativeModel("gemini-2.0-flash")Para saber más sobre Vertex AI, consulta este tutorial introductorio sobre IA de vértices.
Paso 4: Preprocesamiento de datos
Para garantizar un tratamiento adecuado de los datos, normaliza los nombres de las columnas y extrae las categorías clave. Encontramos industrias y productos únicos que actúan como fuente de nuestras rebajas en la demo. Si utilizas un conjunto de datos diferente, elige las categorías en consecuencia.
# Normalize column names to prevent key errors
df.columns = df.columns.str.strip().str.lower()
print("Dataset columns:", df.columns) # Debugging
# Extract unique industry names and product categories
unique_industries = sorted(df["industry"].dropna().unique().tolist())
unique_industries.insert(0, "All Industries") # Add "All Industries" option
unique_products = sorted(df["product"].dropna().unique().tolist())
unique_products.insert(0, "All Products") # Add "All Products" optionAhora que hemos procesado nuestro conjunto de datos, vamos a contar los tokens. Como Gemini 2.0 Flash tiene un límite de 1.000.000 de fichas, es importante calcular el número de fichas del conjunto de datos antes de pasarlo al modelo. Este conjunto de datos tiene 805447 fichas.
# Initialize tokenizer (use "cl100k_base" for Gemini/GPT models)
encoder = tiktoken.get_encoding("cl100k_base")
# Choose relevant text columns
text_columns = ['industry', 'product', 'sales', 'quantity', 'discount', 'profit']
# Create a combined text column for tokenization
df["combined_text"] = df[text_columns].astype(str).agg(" | ".join, axis=1)
# Function to count tokens
def count_tokens(texts):
total_tokens = sum(len(encoder.encode(str(text))) for text in texts)
return total_tokens
# Calculate total tokens
total_tokens = count_tokens(df["combined_text"].dropna().tolist())
print(f"Total tokens in the dataset: {total_tokens}")Utilizamos Tiktoken para la tokenización:
cl100k_base de Tiktoken, optimizado para los modelos Gemini y GPT.combined_text y calcula el número total de tokens de todas las filas.Ahora, podemos trabajar en las partes analistas de la demo. Esta función genera un resumen de ventas basado en el sector y el producto seleccionados.
def summarize_sales(industry, product):
filtered_data = df.copy()
if industry != "All Industries":
filtered_data = filtered_data[filtered_data["industry"] == industry]
if product != "All Products":
filtered_data = filtered_data[filtered_data["product"] == product]
if filtered_data.empty:
return "No sales data available for the selected industry and product."
# Create sales report
total_sales = filtered_data["sales"].sum()
total_quantity = filtered_data["quantity"].sum()
total_profit = filtered_data["profit"].sum()
avg_discount = filtered_data["discount"].mean()
sales_text = f"""
Sales Data for {industry} - {product}:
- Total Sales: ${total_sales:,.2f}
- Total Quantity Sold: {total_quantity}
- Total Profit: ${total_profit:,.2f}
- Average Discount: {avg_discount:.2f}%
"""
# Generate summary using Gemini 2.0 Flash
response = model.generate_content(sales_text, stream=True)
response_text = "".join(chunk.text for chunk in response)
return response_textLa función summarize_sales() filtra el conjunto de datos basándose en el sector y el producto seleccionados, calcula las métricas de ventas clave, como las ventas totales, la cantidad vendida, el beneficio y el descuento medio, y da formato a los datos en una consulta estructurada. A continuación, este aviso se pasa al modelo Gemini 2.0 Flash para generar un resumen de ventas conciso.
Del mismo modo, definimos otra función que realiza un análisis de sentimiento basado en el beneficio total.
def analyze_sales_sentiment(industry, product):
filtered_data = dataset_df.copy()
if industry != "All Industries":
filtered_data = filtered_data[filtered_data["industry"] == industry]
if product != "All Products":
filtered_data = filtered_data[filtered_data["product"] == product]
if filtered_data.empty:
return "No sales data available for sentiment analysis."
total_sales = filtered_data["sales"].sum()
total_profit = filtered_data["profit"].sum()
# Define sentiment labels based on profit margins
if total_profit > 500000:
sentiment_label = "Positive"
elif total_profit > 100000:
sentiment_label = "Neutral"
else:
sentiment_label = "Negative"
sentiment_text = f"""
The total sales for {industry} - {product} is ${total_sales:,.2f},
with a total profit of ${total_profit:,.2f}.
Based on market trends, this performance is considered {sentiment_label}.
Analyze the sentiment of sales performance for this product.
"""
# Generate sentiment analysis using Gemini Flash 2.0
response = model.generate_content(sentiment_text, stream=True)
# Collect response text
response_text = "".join(chunk.text for chunk in response)
return response_textLa función analyze_sales_sentiment() analiza el sentimiento de las ventas filtrando el conjunto de datos en función del sector y el producto seleccionados, calculando las ventas totales y el beneficio total, y generando un análisis del sentimiento impulsado por IA utilizando Gemini 2.0 Flash. A continuación, el modelo recibe un resumen estructurado del rendimiento de las ventas, lo que le permite evaluar el sentimiento de forma dinámica en lugar de basarse únicamente en umbrales de beneficios fijos.
Ahora ya tenemos todas las funciones lógicas clave. A continuación, trabajaremos en la creación de una interfaz de usuario interactiva con Gradio.
with gr.Blocks() as demo:
gr.Markdown("# AI-Powered SaaS Sales Analysis")
industry_dropdown = gr.Dropdown(choices=unique_industries, label="Select an Industry")
product_dropdown = gr.Dropdown(choices=unique_products, label="Select a Product")
summarize_btn = gr.Button("Summarize Sales Trends")
summary_output = gr.Textbox(label="Sales Trend Summary")
summarize_btn.click(summarize_sales, inputs=[industry_dropdown, product_dropdown], outputs=summary_output)
demo.launch(debug=True)Este código crea una interfaz de usuario interactiva de Gradio para el análisis de ventas de SaaS impulsado por IA, en la que los usuarios pueden seleccionar un sector y un producto en menús desplegables y hacer clic en un botón para generar un resumen de ventas. Las entradas seleccionadas se pasan a la función summarize_sales(), que procesa los datos y devuelve las percepciones, mostradas en un cuadro de texto. A continuación, se inicia la app Gradio para interactuar en tiempo real.
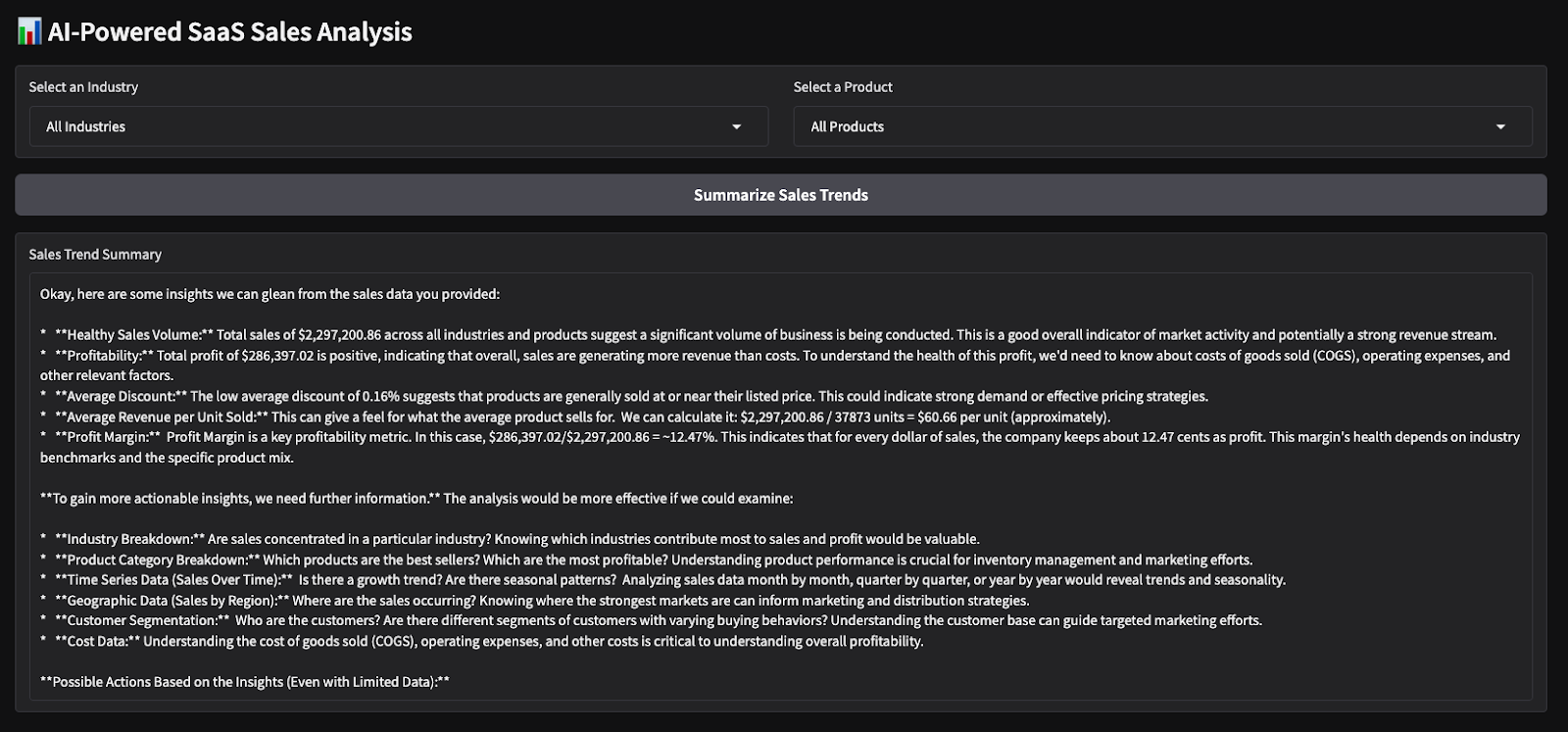
Estos son los resultados de una prueba rápida que he realizado. Elegí todas las industrias y productos, y luego pedí al modelo que produjera un resumen de ventas y realizara un análisis de sentimiento sobre los parámetros elegidos.

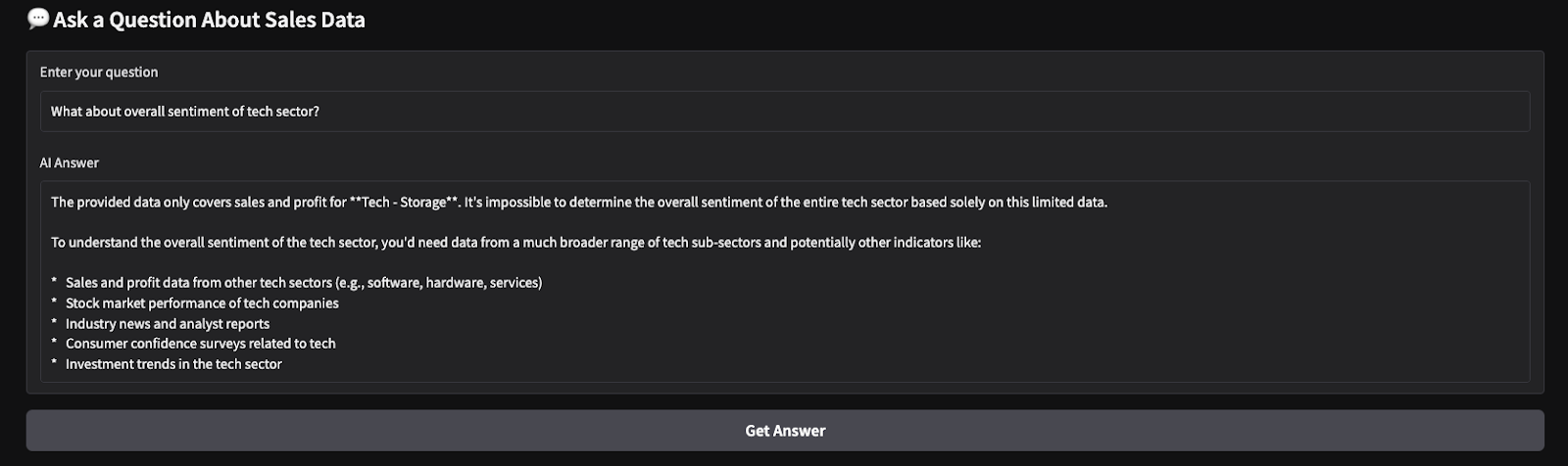
En este tutorial, construimos una herramienta de análisis de ventas de SaaS impulsada por IA utilizando Gemini 2.0 Flash, que permite el análisis en tiempo real de los datos de ventas de SaaS. Utilizamos la gran ventana contextual de Gemini 2.0 Flash para procesar datos estructurados sin RAG e integramos una interfaz interactiva basada en Gradio para facilitar la interacción del usuario.
Te animo a que adaptes este tutorial a tu propio caso de uso. Para saber más sobre cómo crear aplicaciones con Géminis 2.0, te recomiendo estos tutoriales:
Aprende IA con estos cursos
programa
programa
Curso
blog
Matt Crabtree
13 min
blog
Ryan Ong
8 min
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Dimitri Didmanidze
