Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
99.8K
Aunque la mayoría de la gente asocia Google con los motores de búsqueda, la empresa también tiene profundas raíces en el sector de la ciencia de datos. Ofrece sistemáticamente productos y soluciones de vanguardia destinados a obtener el máximo beneficio de los datos. Uno de sus productos, Vertex AI, se lanzó en 2021 para simplificar el proceso de aprendizaje automático a escala empresarial.
En este tutorial, aprenderemos a iniciarnos en la plataforma Vertex AI de Google y a utilizarla para cubrir una amplia gama de tareas del ciclo de vida del ML. Nos iremos con un modelo desplegado que podemos utilizar para enviar peticiones que generen predicciones para una tarea de clasificación.
Un ciclo de vida típico del aprendizaje automático consta de muchas etapas:
Todas estas etapas y subetapas requieren un conjunto diferente de herramientas y un equipo diverso de expertos para coordinarlas.
Vertex AI de Google Cloud agiliza y unifica todo este proceso en una única plataforma.
Mientras que las aplicaciones ML a gran escala requieren especialistas experimentados, Vertex AI capacita a usuarios de cualquier nivel de habilidad:
Hay muchas cosas que no mencionaremos en esta sección, ya que podrás trabajar en la mayoría de ellas tú mismo en este tutorial.
Antes de empezar a explorar la plataforma, tenemos que mencionar su matriz: los servicios en la nube de Google. Los Servicios en la Nube de Google incluyen una amplia gama de soluciones de computación en la nube que proporcionan capacidades de almacenamiento, redes, bases de datos, análisis y aprendizaje automático.
Estos servicios trabajan juntos en sincronía con Vertex AI para unificar tu flujo de trabajo de aprendizaje automático. Aquí tienes un desglose de los servicios que se utilizan a menudo con Vertex AI:
Los servicios de Google Cloud siempre están disponibles desde tu cuenta de Google si visitas cloud.google.com. Si nunca los has utilizado, haz clic en "Empezar gratis" para obtener tu prueba gratuita.
Si no, puedes ir directamente a console.cloud.google. com para que podamos empezar.
Descargo de responsabilidad: Si quieres seguir el tutorial, prepárate para gastarte 25-30 $ en Vertex AI. Utilizaremos las configuraciones más baratas.
Cuando visites tu Consola de Google Cloud, lo más probable es que acabes en la siguiente página de bienvenida:
Enumera el nombre de tu espacio de trabajo; el mío es ibexprogramming.com.
Lo primero que haremos será crear un proyecto. Los proyectos de Google Cloud son unidades de organización de alto nivel para gestionar recursos para una tarea específica. Aquí tienes un GIF sobre cómo crear uno:
Una vez creado el proyecto, selecciónalo para que en la barra superior de la página aparezca esto:
![]()
Ahora, tienes que crear una cuenta de facturación porque Vertex AI necesita información de facturación para habilitar sus servicios. No te preocupes: no se te cobrará hasta que utilices recursos de pago. Así que dirígete a https://console.cloud.google.com/billing:
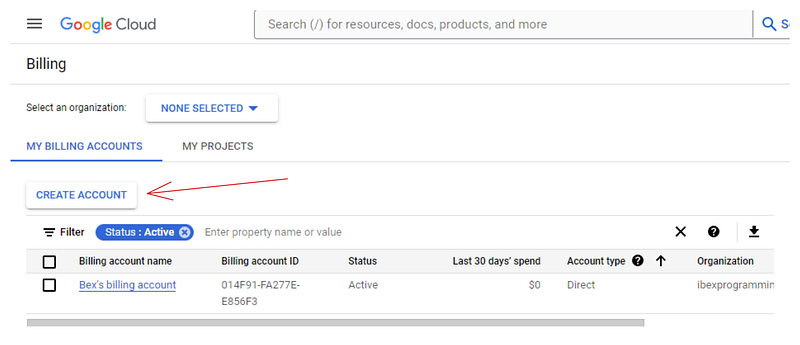
Si aún no tienes una cuenta como la mía, haz clic en "Crear cuenta" y sigue las instrucciones que se muestran. Vincularemos esta cuenta de facturación a la nuestra en la siguiente sección.
Después, vuelve a https://console.cloud.google.com/ y haz clic en el botón "Ver todos los productos" situado en la parte inferior de la página:
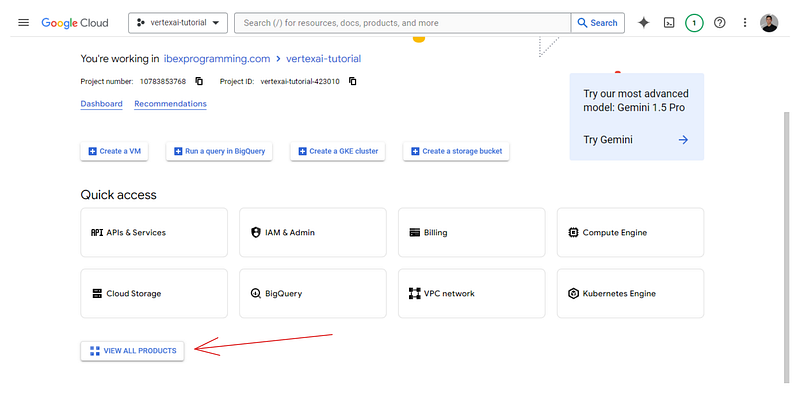
En la página siguiente aparecerá una lista de todos los servicios que ofrece Google Cloud para tu proyecto. Busca "Vértice AI" (Ctrl + F) y fíjalo a tu menú para acceder fácilmente. Después, haz clic en el propio servicio:
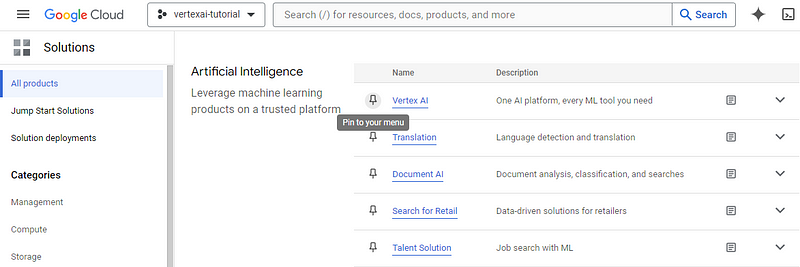
Esto te dirigirá a tu panel de Vertex AI. Puede que aparezca una ventana pidiéndote que actives la API Vertex AI: elige "Activar". Si la ventana no aparece, puedes hacer clic en el botón "Habilitar todos los permisos de la API" para hacer lo mismo.
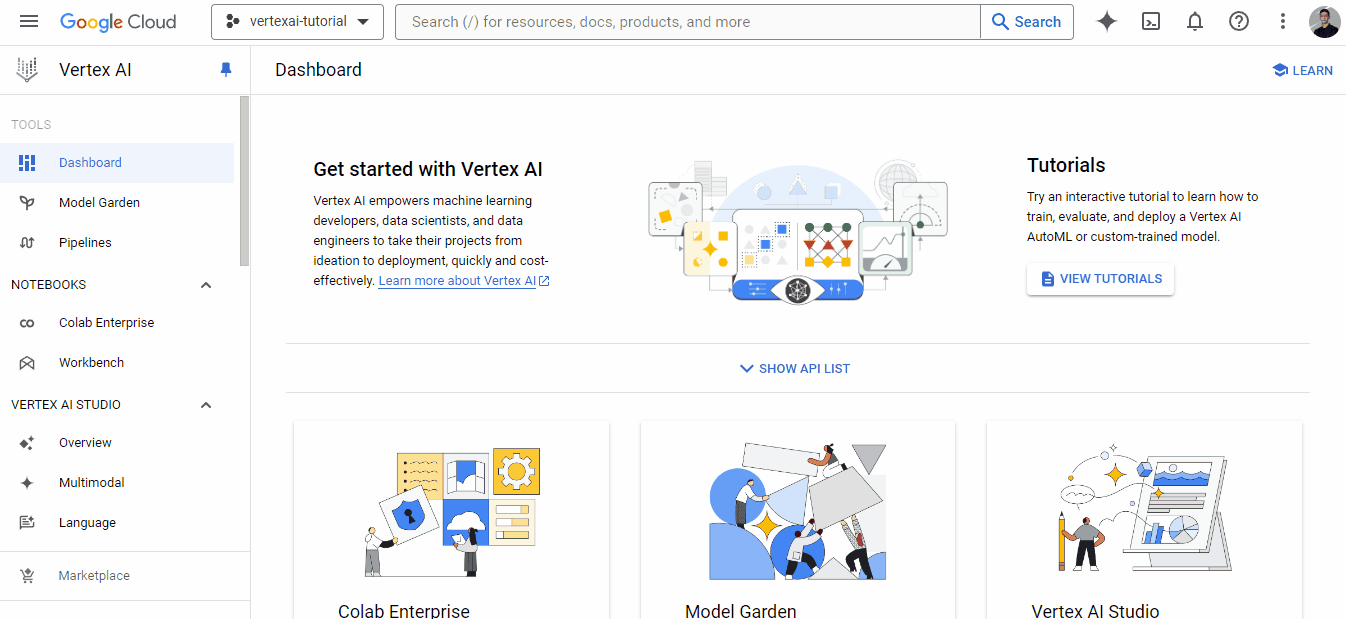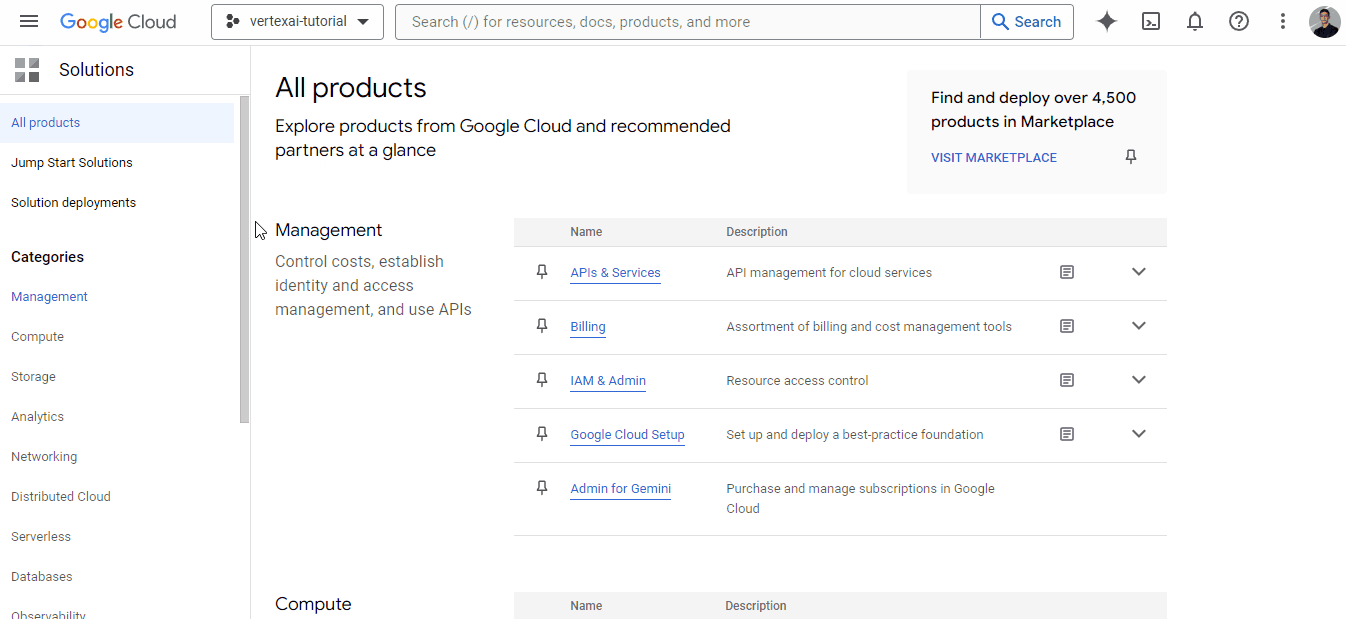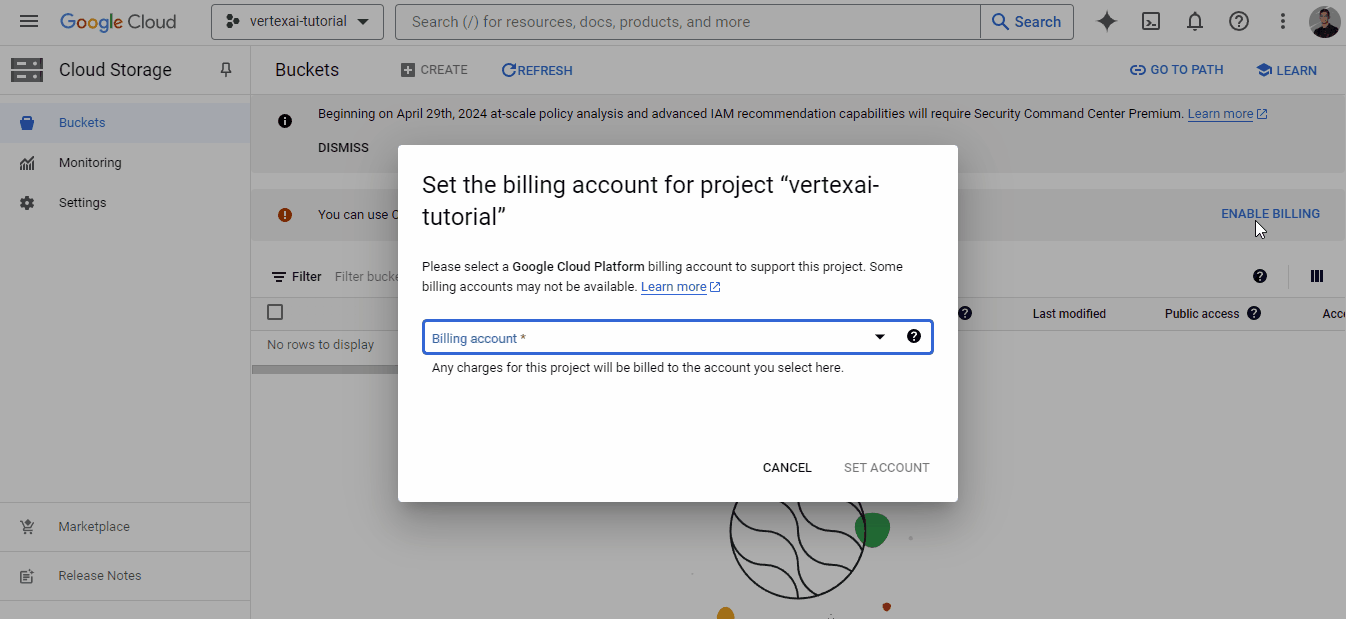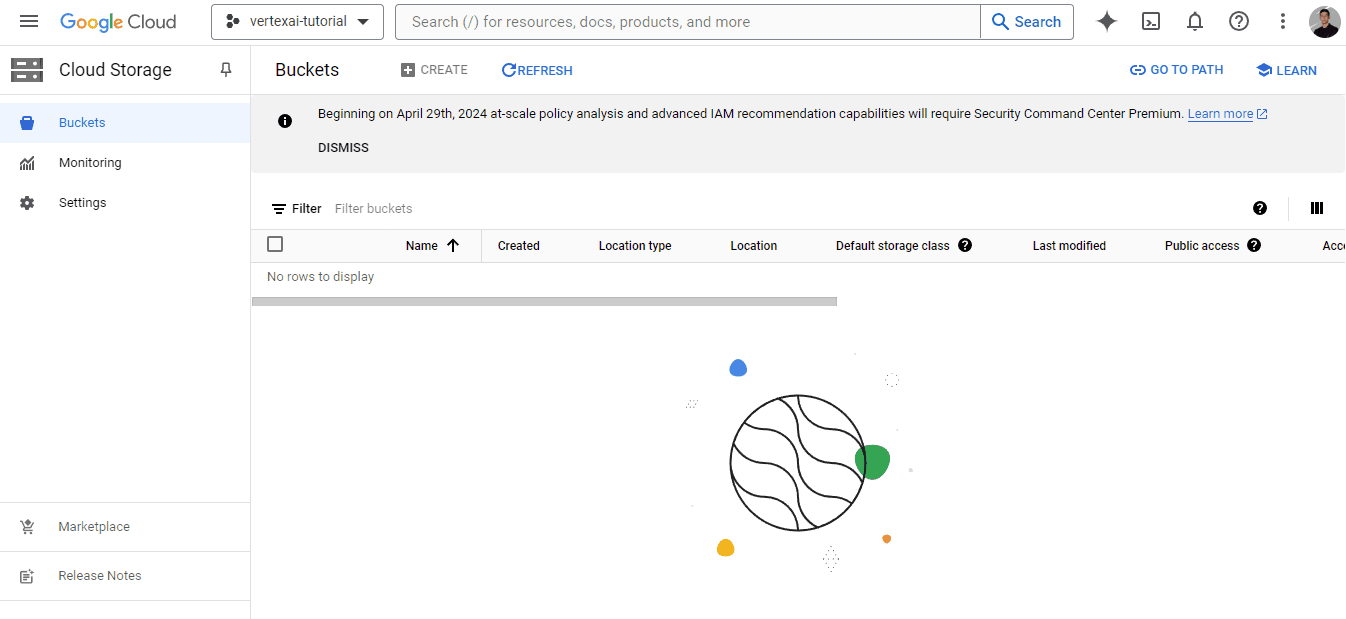
Ahora estamos preparados para cargar un conjunto de datos en Vertex AI.
Hay varias formas de añadir un conjunto de datos a Vertex AI. En esta sección, utilizaremos un archivo CSV local por simplicidad.
Para el artículo, utilizaremos el conjunto de datos Dry Bean del repositorio de Aprendizaje Automático de la UCI. Contiene 13.000 instancias de judías y sus 15 medidas numéricas.
La tarea consiste en clasificarlas en siete tipos de judías: Seker, Barbunya, Bombay, Cali, Dermosan, Horoz y Sira.
Tras la descarga, guarda el archivo Excel dentro del ZIP descargado en tu directorio local:
from pathlib import Path
cwd = Path.cwd()
data_path = cwd / "data" / "Dry_Bean_Dataset.xlsx"
A continuación, podemos leer este archivo con pandas y guardarlo de nuevo como CSV:
import pandas as pd
beans = pd.read_excel(data_path)
beans.shape
(13611, 17)Ten en cuenta que la función read_excel requiere que instales la biblioteca openpyxl con PIP.
Genial, ya tenemos el conjunto de datos como un DataFrame. Volvamos a guardarlo como CSV:
beans.to_csv(cwd / "data" / "dry_bean.csv", index=False)Como hemos mencionado antes, necesitamos un Google Storage Bucket para almacenar nuestros datos brutos. Sigue el GIF que aparece a continuación para navegar hasta el panel de control del producto:
El GIF muestra que, para empezar a utilizar los servicios de almacenamiento, necesitamos vincular una cuenta de facturación, lo que hacemos utilizando la que creamos anteriormente. A continuación, podrás crear un cubo con un nombre único global:
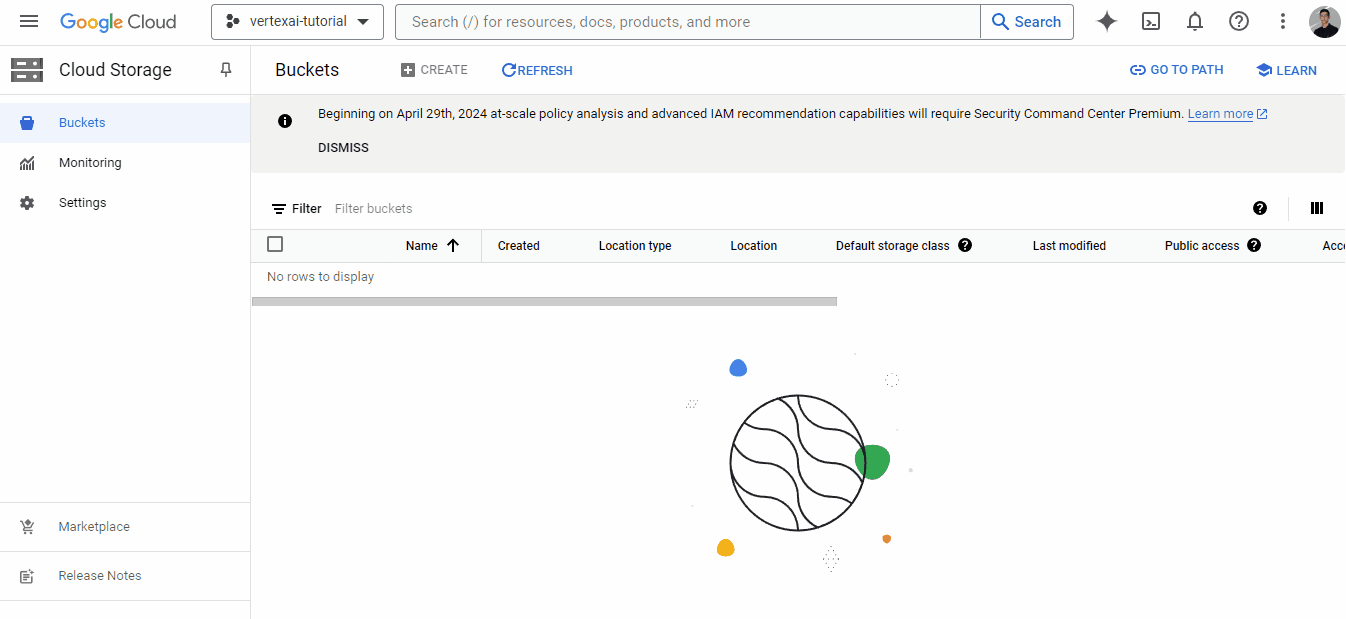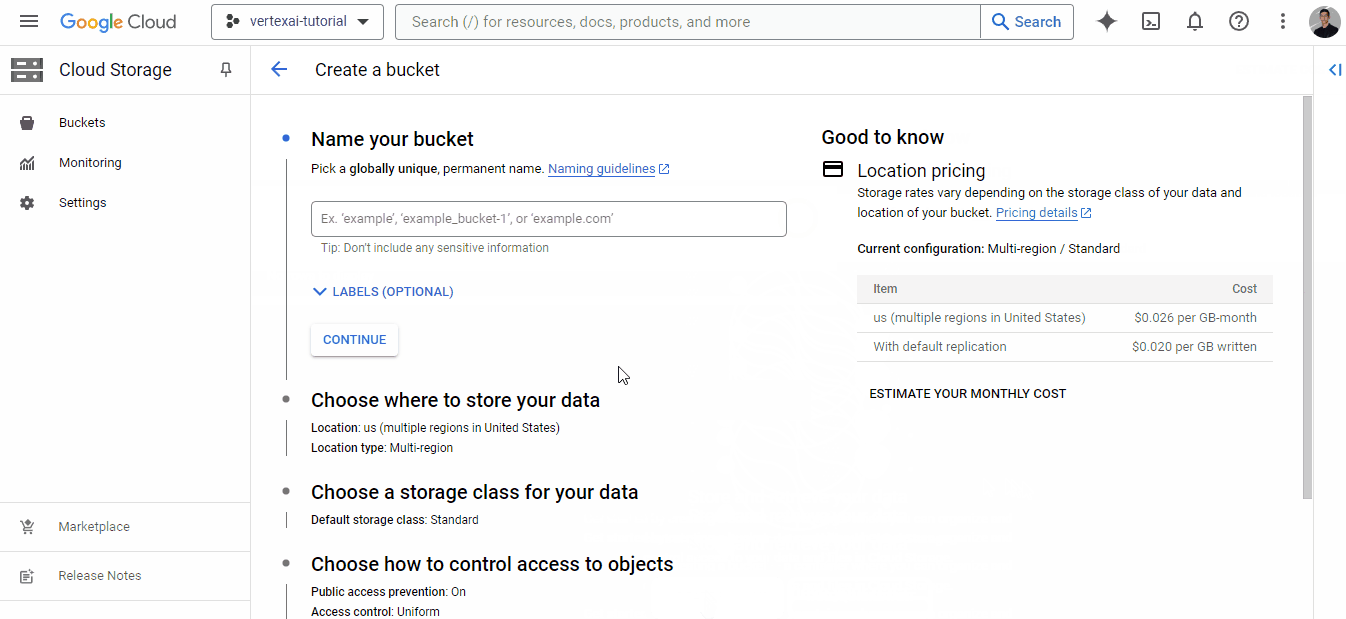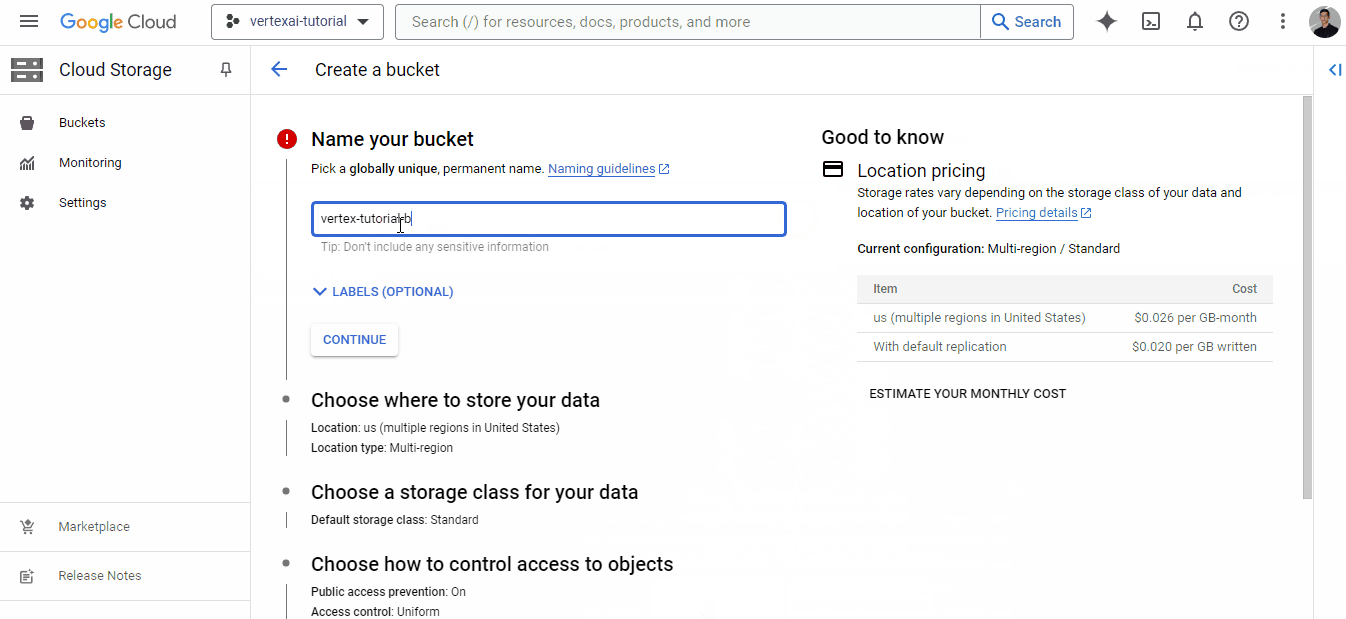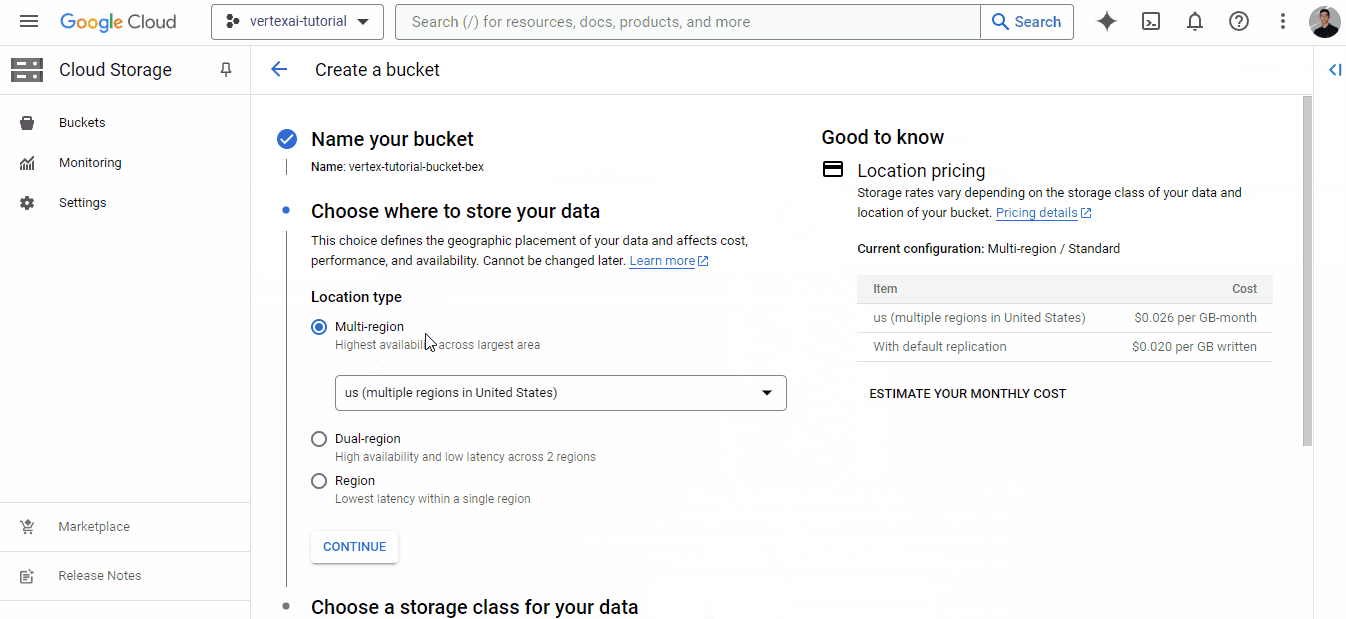
Una vez que encuentres un nombre único, haz clic en "Continuar" hasta que se cree el cubo - puedes elegir opciones por defecto para todos los campos.
Ahora, estamos listos para ingerir el archivo CSV que hemos guardado en la sección anterior.
Ahora, volvamos a nuestro panel Vertex AI y echemos un vistazo a la pestaña Conjuntos de datos:
Lo encontrarás vacío, así que haz clic en el botón "+Crear":
Dale un nombre único al conjunto de datos y elige la opción tabular:
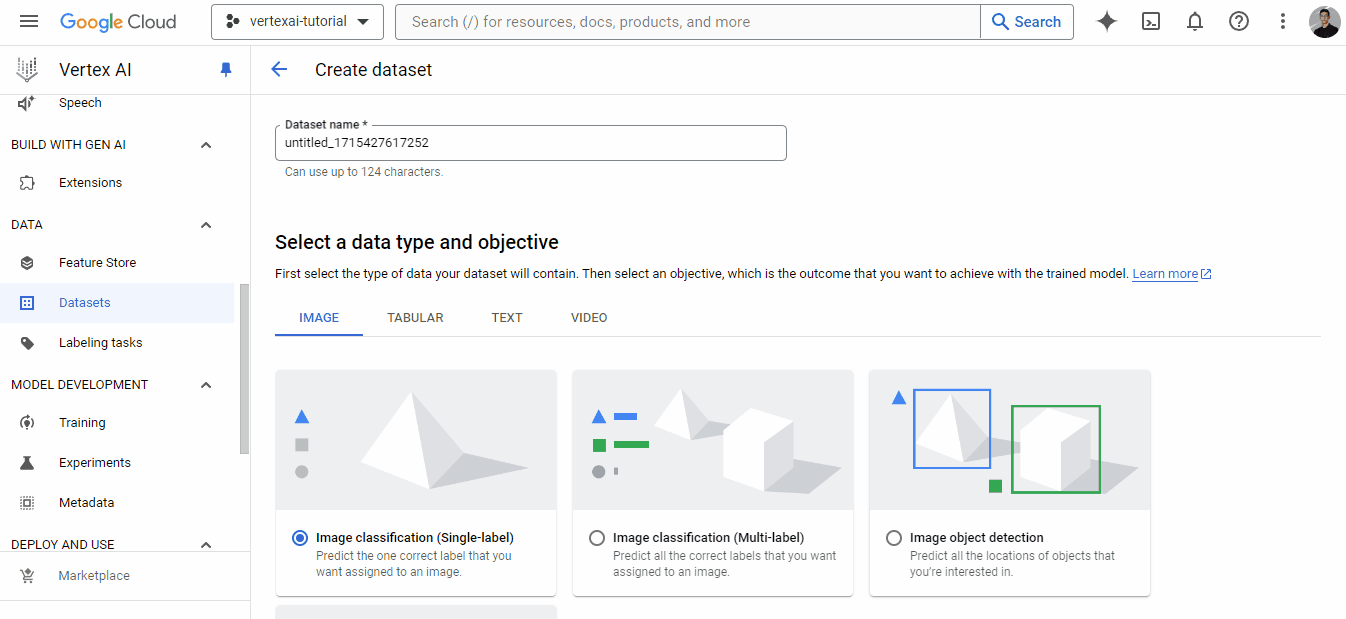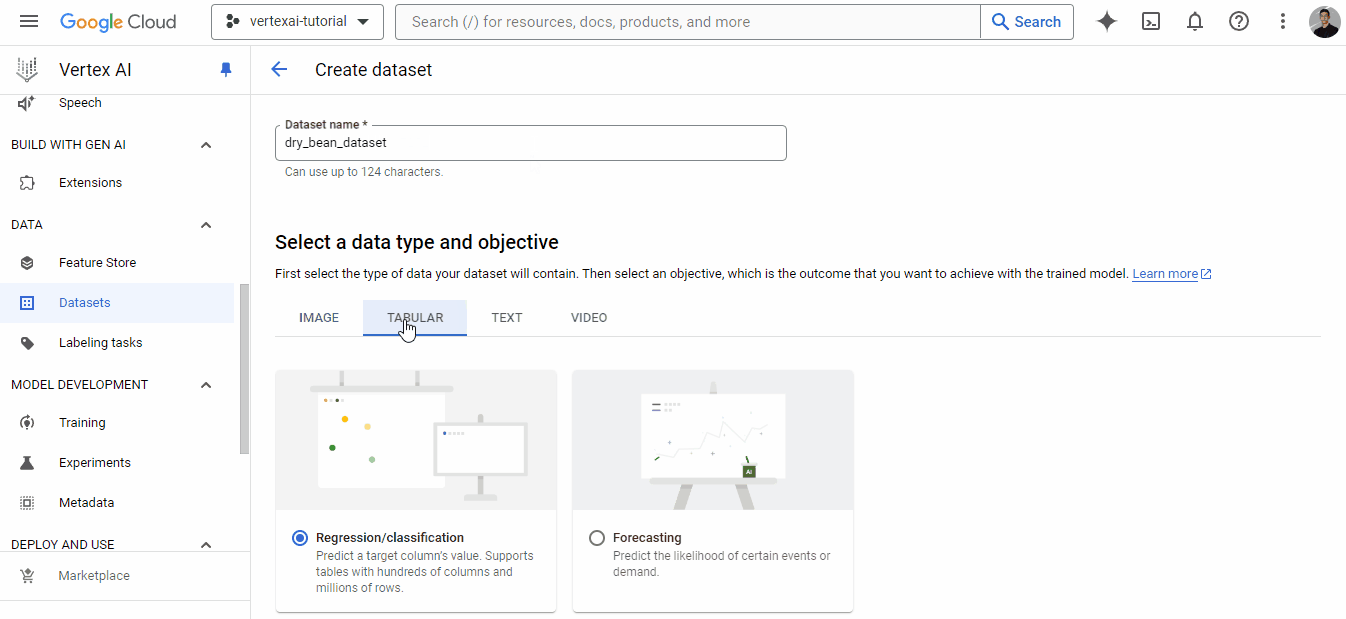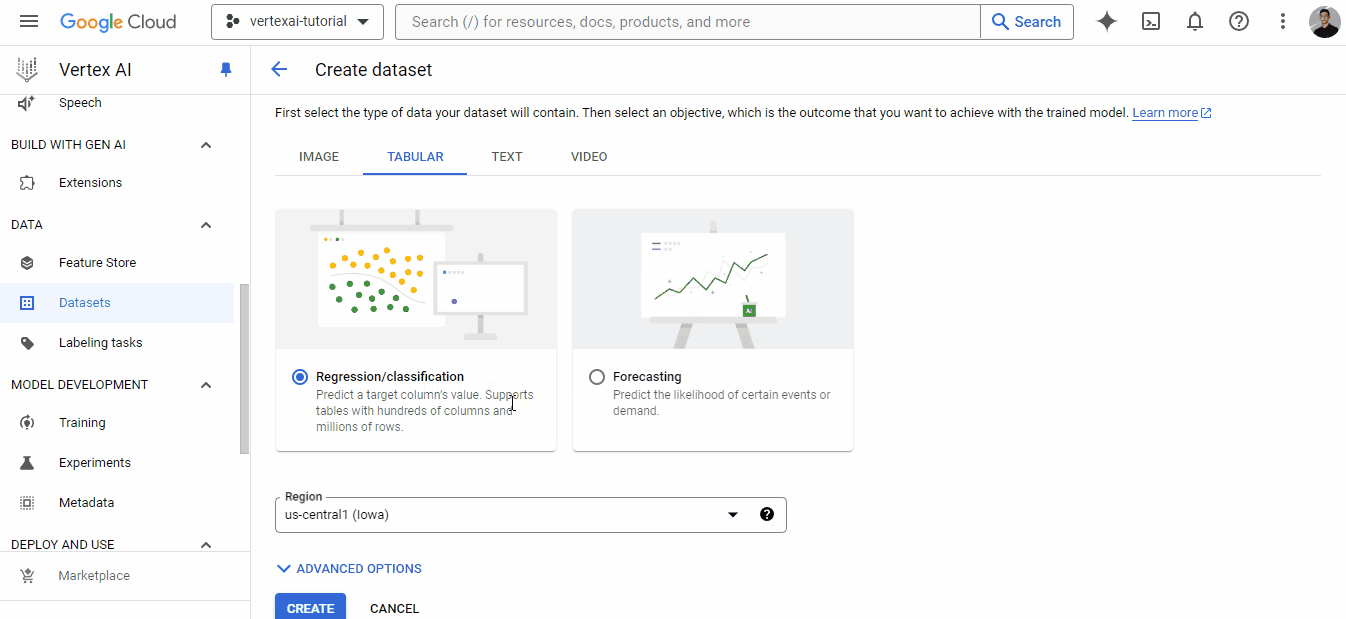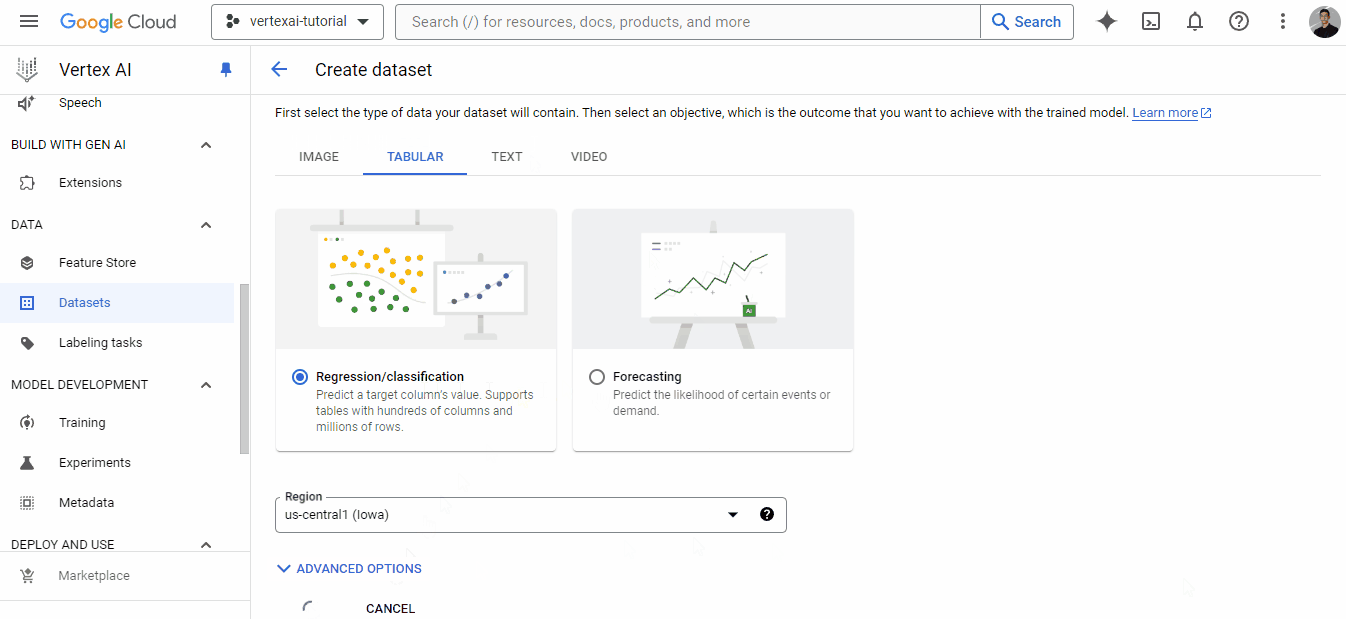
A continuación, la plataforma te muestra las opciones de origen. Elige subir un archivo CSV local, y para la ruta de Almacenamiento en la Nube, elige el cubo que acabas de crear:
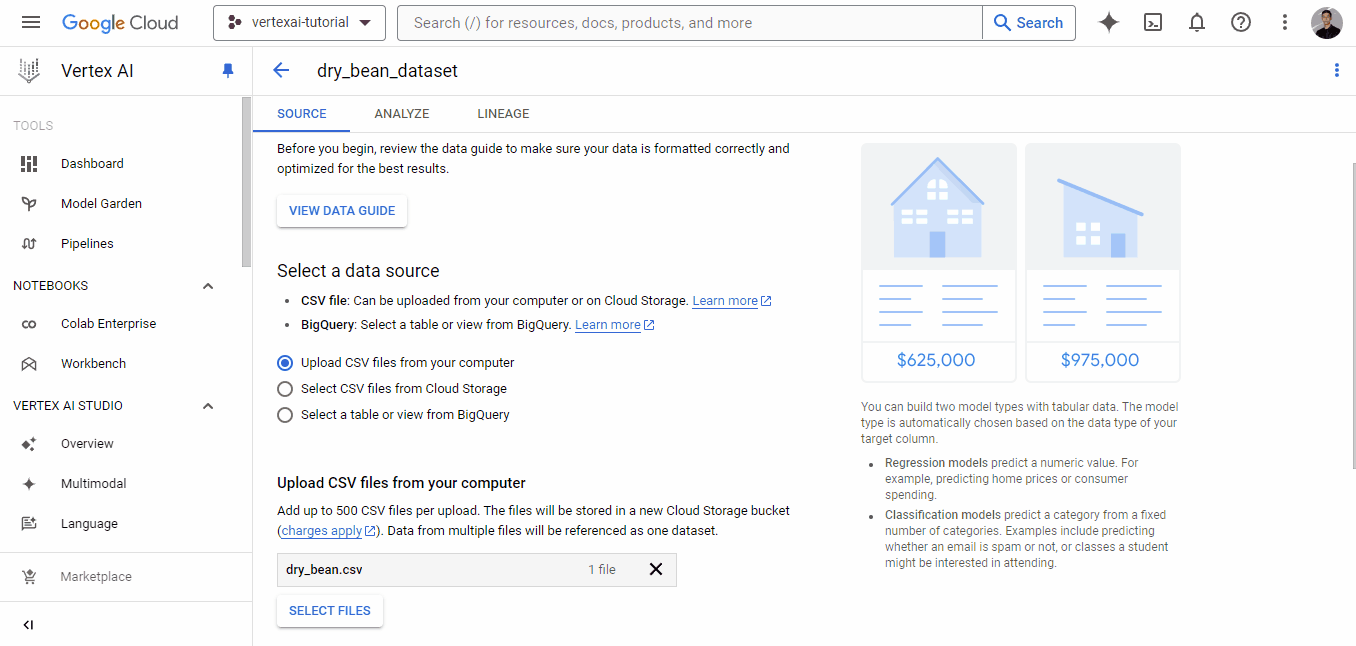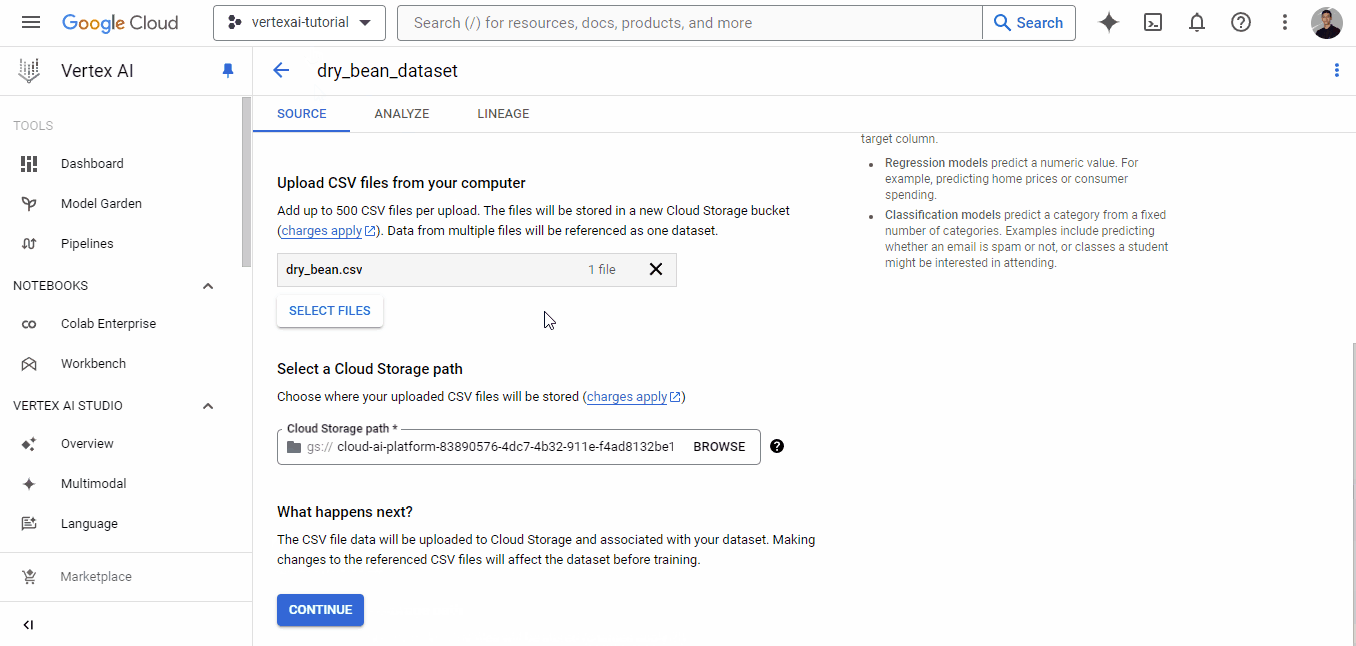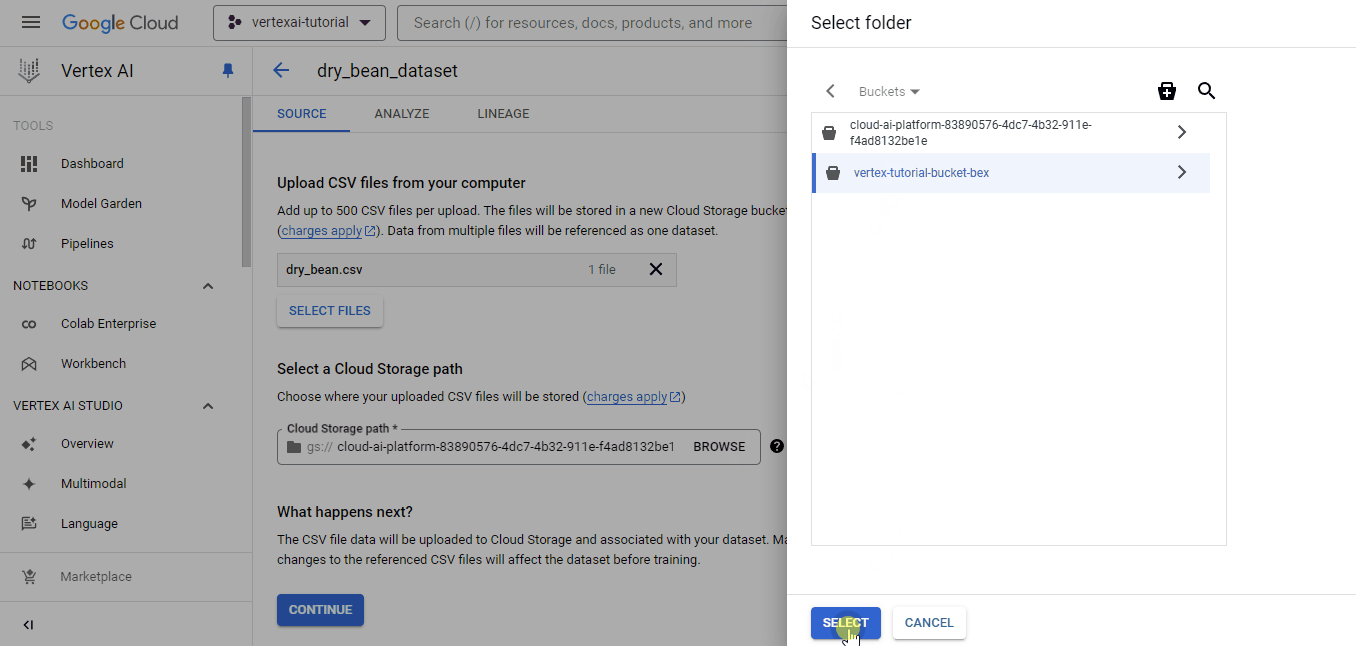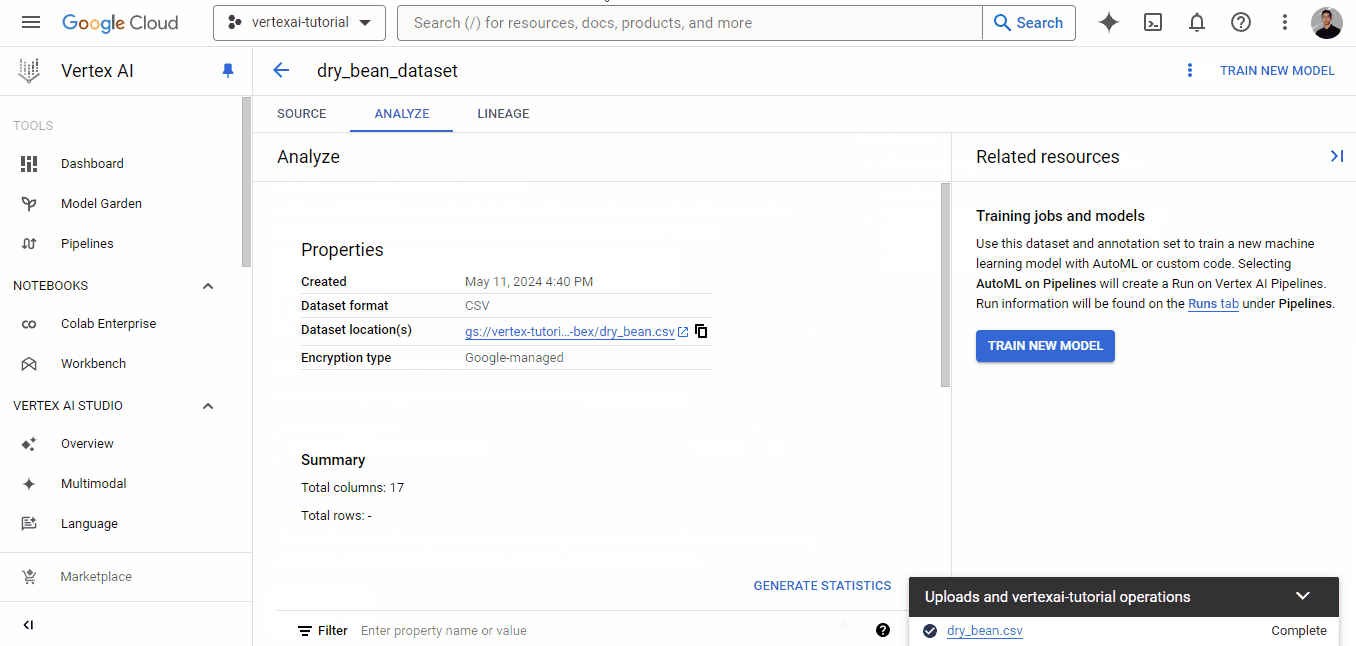
Una vez que el conjunto de datos se haya cargado correctamente, se te mostrará la pestaña "Analizar", que muestra metadatos básicos sobre el archivo CSV. También verás un botón "ENTRENAR NUEVO MODELO", que iniciará un trabajo de entrenamiento AutoML.
Sin embargo, no utilizaremos ese botón, ya que es para principiantes completos en ML. En su lugar, utilizaremos Vertex AI Workbench para configurar un entorno de codificación Jupyterlab y recursos informáticos para ejecutar tanto AutoML como bibliotecas personalizadas.
Como Vertex AI es una plataforma unificada, también ofrece entornos de desarrollo llamados bancos de trabajo. Para crear un banco de trabajo, ve a su propia pestaña y sigue las instrucciones del GIF que aparece a continuación:
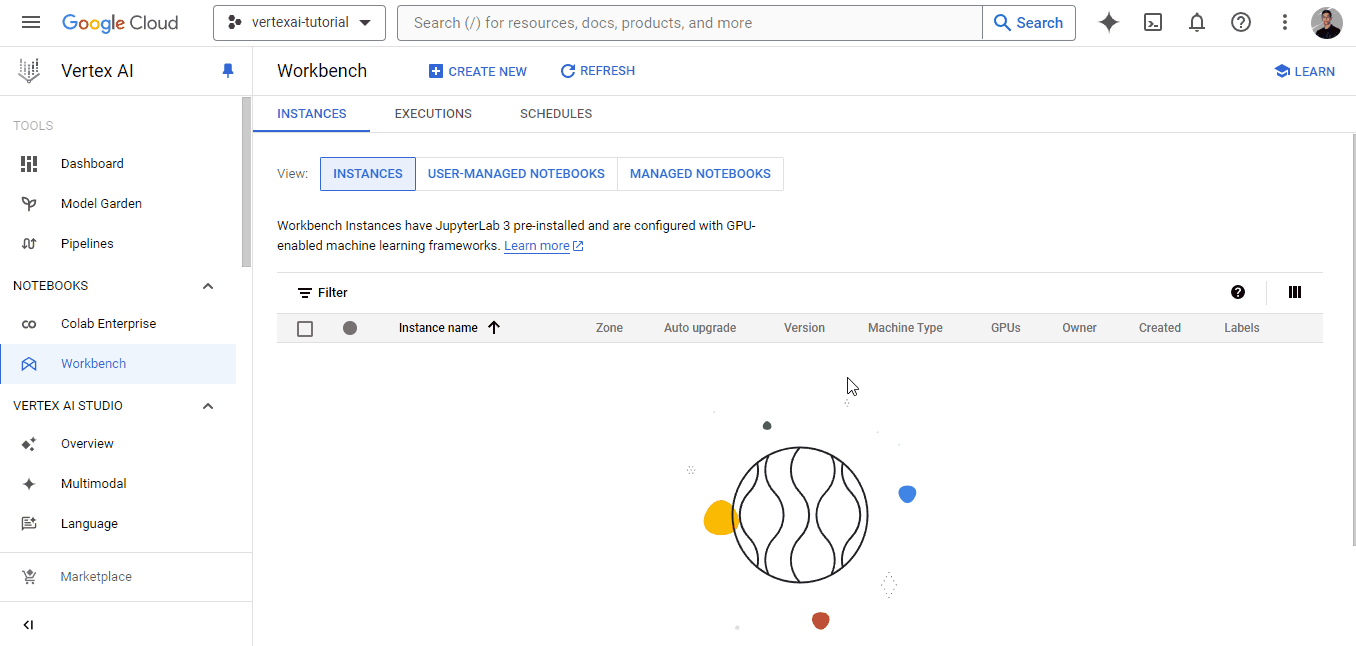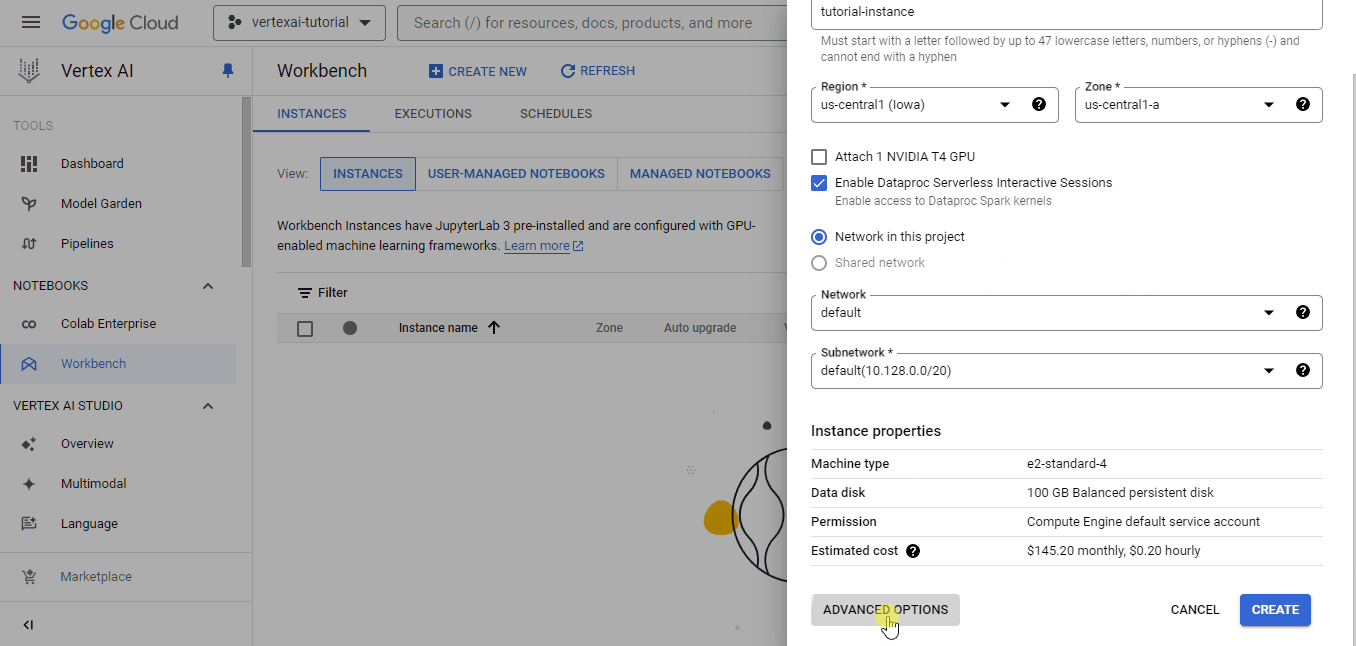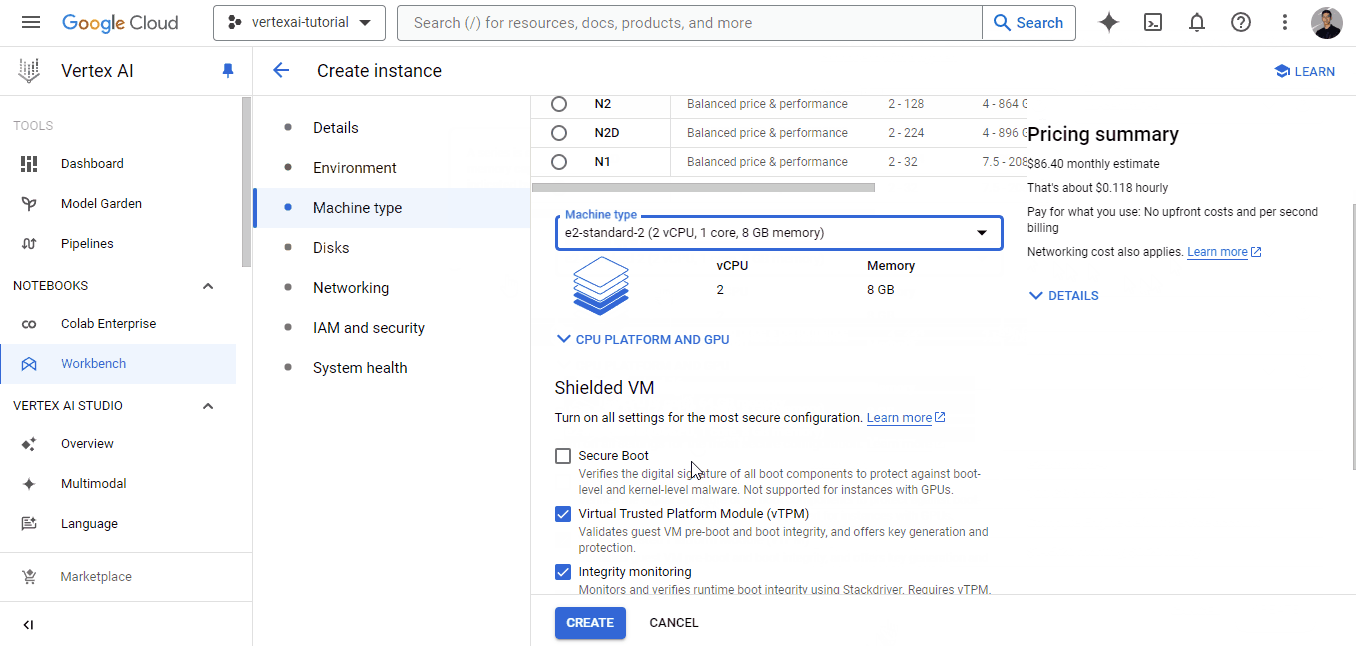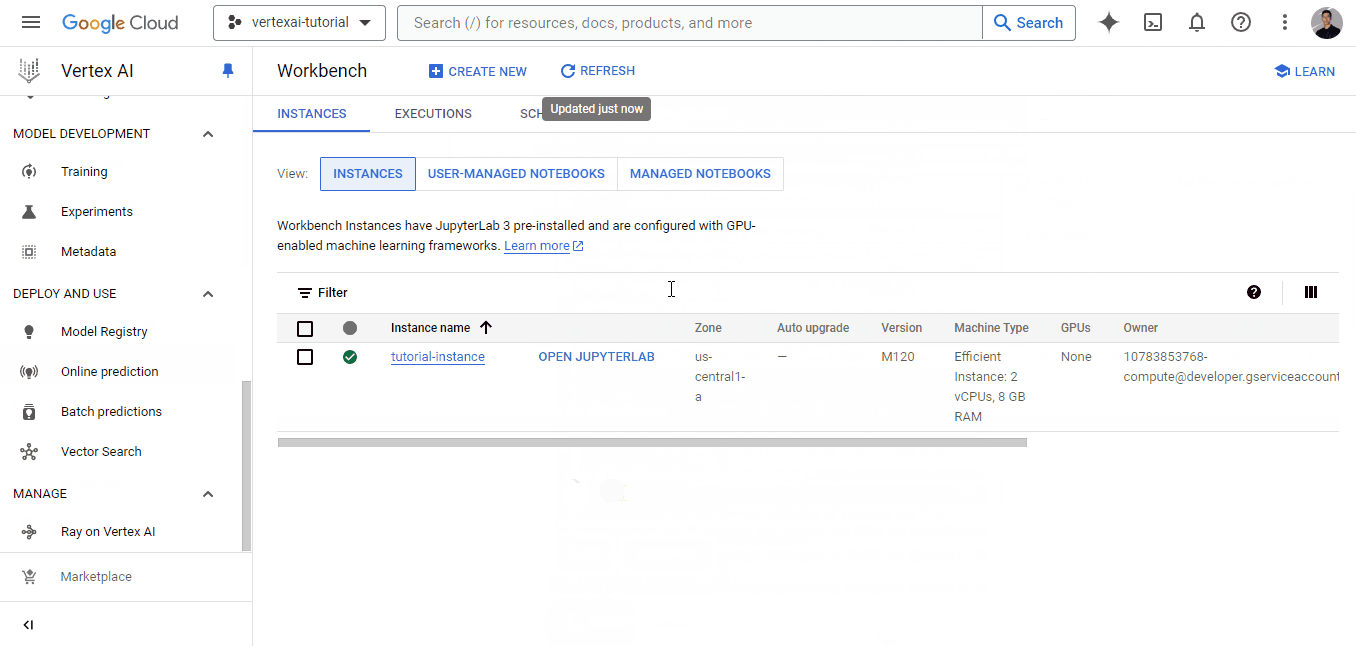
Cada banco de trabajo viene con Jupyterlab 3 preinstalado. Así, sólo tienes que configurar las opciones de hardware en función de tu presupuesto y necesidades. Como tenemos un conjunto de datos bastante pequeño, elegí la instancia más débil para la ilustración, que sólo cuesta ~0,12 $ la hora (recomiendo elegir una máquina con más núcleos de CPU para que los cálculos sean más rápidos).
También he cambiado la duración del apagado en reposo a 10 minutos para que el entorno se detenga automáticamente si me olvido de apagarlo.
El banco de trabajo tardará algún tiempo en inicializarse. Cuando lo haga, aparecerá el botón "ABRIR JUPYTERLAB", y podremos hacer clic en él:
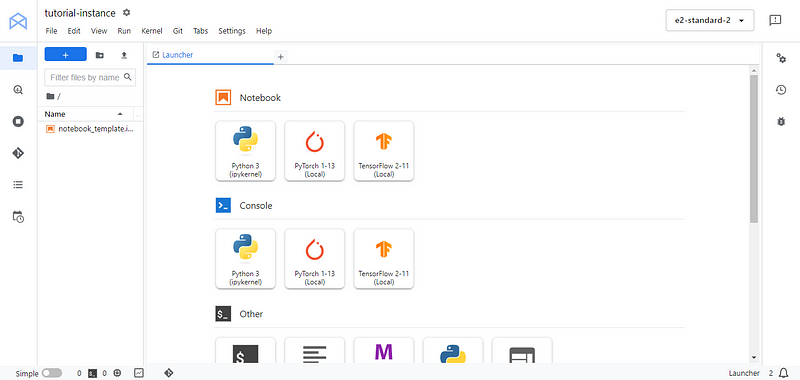
Nos dirigiremos a la conocida interfaz de Jupyterlab. Desde ahí, crea un nuevo cuaderno Python 3 y renómbralo como quieras. En la primera celda, instala/actualiza Google Cloud services SDK google-cloud-aiplatform:
!pip3 install --upgrade --quiet google-cloud-aiplatform
A continuación, puedes listar los proyectos disponibles en tu cuenta con gcloud config list:
!gcloud config list
[compute]
region = us-central1
[core]
account = # HIDDEN #
disable_usage_reporting = True
project = vertexai-tutorial-423010
[dataproc]
region = us-central1
Your active configuration is: [default]
gcloud y gsutil son utilidades de terminal disponibles en todos los bancos de trabajo. Te permiten gestionar eficazmente tus servicios de Google Cloud.
A partir de la salida impresa, guarda la siguiente información como variables Python:
PROJECT_ID = 'vertexai-tutorial-423010'
BUCKET_URI = 'gs://vetex-tutorial-bucket-bex'
REGION = 'us-central1'
No olvides cambiar BUCKET_URI por tu propio nombre de cubo. A continuación, importa el submódulo aiplatform e inicialízalo:
from google.cloud import aiplatform as ai
ai.init(project=PROJECT_ID, location=REGION, staging_bucket=BUCKET_URI)
aiplatform servirá como SDK para interactuar con las funciones de la IA de Vértice.
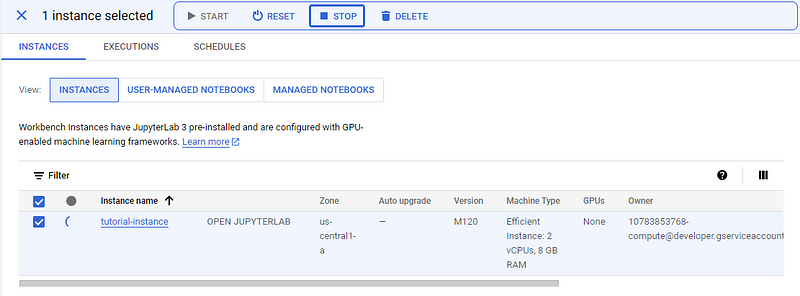
Cuando termines de seguir el tutorial o hagas una pausa, no olvides PARAR la instancia para evitar costes no deseados.
Ahora vamos a entrenar un modelo con AutoML, que, como hemos dicho antes, se encarga de todo el trabajo pesado por nosotros y nos devuelve el mejor modelo que pudo entrenar para el conjunto de datos dado. Esto significa que, para aprovechar al máximo AutoML, debes asegurarte de que el conjunto de datos al que alimentas es de la mayor calidad posible. Por lo tanto, merece la pena tomarse un tiempo para diseñar nuevas funciones y realizar previamente cualquier paso de preprocesamiento.
AutoML preprocesa internamente el conjunto de datos, pero no puede solucionar todos los problemas de tu conjunto de datos.
Sin embargo, en esta sección sólo entrenaremos un modelo AutoML de referencia sin preprocesamiento ni ingeniería de rasgos, por simplicidad.
Lo primero que queremos hacer es cargar el conjunto de datos CSV de nuestro cubo y pasar algún tiempo explorándolo. Recuerda, EDA es un paso importante, ¡y puedes aprender más en nuestro curso de Análisis Exploratorio de Datos en Python!
import pandas as pd
# Path to your CSV file in GCS bucket
gcs_path = "gs://vertex-tutorial-bucket-bex/dry_bean.csv"
beans = pd.read_csv(gcs_path)
beans.head()

La buena noticia es que los pandas pueden descargar archivos de las rutas GCS. La única pega es que el código anterior sólo funciona en los bancos de trabajo de Vertex AI, puesto que ya están autenticados con tus credenciales de Google Cloud.
No realizaremos un análisis profundo del conjunto de datos, ya que nos distraería del punto principal del artículo. Así que nos contentaremos con imprimir algunas estadísticas y gráficos resumidos:
beans.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 13611 entries, 0 to 13610
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Area 13611 non-null int64
1 Perimeter 13611 non-null float64
2 MajorAxisLength 13611 non-null float64
3 MinorAxisLength 13611 non-null float64
4 AspectRation 13611 non-null float64
5 Eccentricity 13611 non-null float64
6 ConvexArea 13611 non-null int64
7 EquivDiameter 13611 non-null float64
8 Extent 13611 non-null float64
9 Solidity 13611 non-null float64
10 roundness 13611 non-null float64
11 Compactness 13611 non-null float64
12 ShapeFactor1 13611 non-null float64
13 ShapeFactor2 13611 non-null float64
14 ShapeFactor3 13611 non-null float64
15 ShapeFactor4 13611 non-null float64
16 Class 13611 non-null object
dtypes: float64(14), int64(2), object(1)
memory usage: 1.8+ MB
Así pues, hay 15 características numéricas y una única columna de destino -Class. Sólo hay ~13k registros y no faltan valores. Esto simplificará mucho el entrenamiento.
Guardemos los nombres de las características en una lista aparte, ya que podríamos necesitarlos más adelante:
feature_names = beans.columns.tolist()
Ahora, vamos a crear un diagrama de pares de algunas características que parecen importantes:
import seaborn as sns
sns.pairplot(
beans,
vars=["Area", "MajorAxisLength", "MinorAxisLength", "Eccentricity", "roundness"],
hue="Class",
);
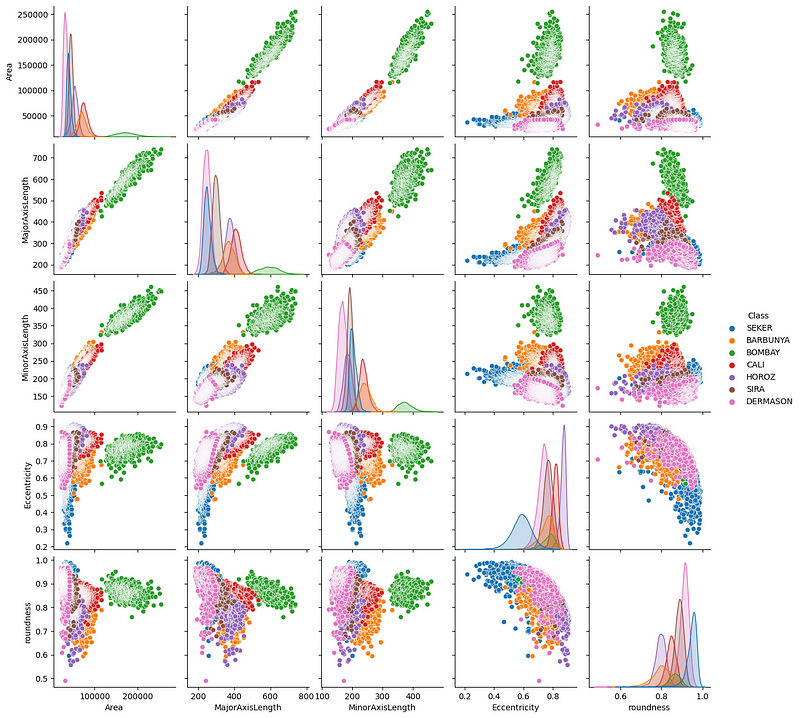
Vemos algunas tendencias interesantes: principalmente, parece que las judías Bombay (verdes) se separan claramente de las demás en cuanto a sus medidas físicas.
Vamos a trazar también una matriz de correlaciones:
import matplotlib.pyplot as plt
correlation = beans.corr(numeric_only=True)
# Create a square heatmap with center at 0
sns.heatmap(correlation, center=0, square=True, cmap="coolwarm", vmin=-1, vmax=1)
plt.show()
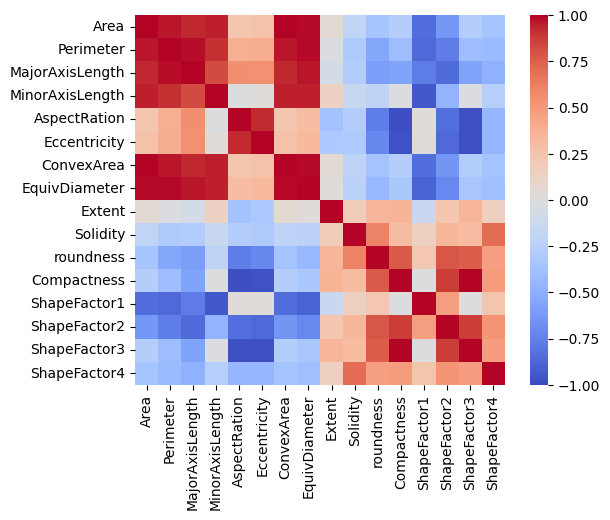
Tenemos unas cuantas características casi perfectamente correlacionadas y eso tiene sentido, ya que están relacionadas con mediciones físicas. Sin embargo, también tenemos unos cuantos pares de rasgos que no muestran ninguna correlación o muy poca.
Llegados a este punto, te dejo que continúes esta exploración e intentes encontrar algunas preguntas que responder sobre el conjunto de datos.
Para iniciar un trabajo de entrenamiento AutoML, primero necesitamos un objeto conjunto de datos compatible con él:
ds = ai.TabularDataset.create(
display_name="dry_bean_dataset", gcs_source=gcs_path
)
TabularDataset created.
type(ds)google.cloud.aiplatform.datasets.tabular_dataset.TabularDataset
ds.resource_name
'projects/10783853768/locations/us-central1/datasets/4978116960081412096'
Utilizamos el método TabularDataset.create para inicializarlo como ds. La IA de los vértices le asigna un nombre propio, accesible a través de su atributo resource_name.
Ahora, inicializamos el trabajo con la clase ai.AutoMLTabularTrainingJob. Requiere dos argumentos:
job = ai.AutoMLTabularTrainingJob(
display_name="dry-bean-classification",
optimization_prediction_type="classification",
)
A continuación, ejecutamos el método run del trabajo:
model = job.run(
dataset=ds,
target_column="Class",
training_fraction_split=0.8,
validation_fraction_split=0.1,
test_fraction_split=0.1,
model_display_name="baseline-classification-model",
disable_early_stopping=False,
)
Los parámetros del método se explican por sí mismos. El código tardará algún tiempo en terminar de ejecutarse (dependiendo de tu potencia de cálculo).
Si vas a la pestaña "DESARROLLO DE MODELOS > FORMACIÓN" de tu panel de control y haces clic en el nombre del trabajo, verás el progreso de la formación en directo. La imagen siguiente muestra que el entrenamiento está en la fase de preprocesamiento:
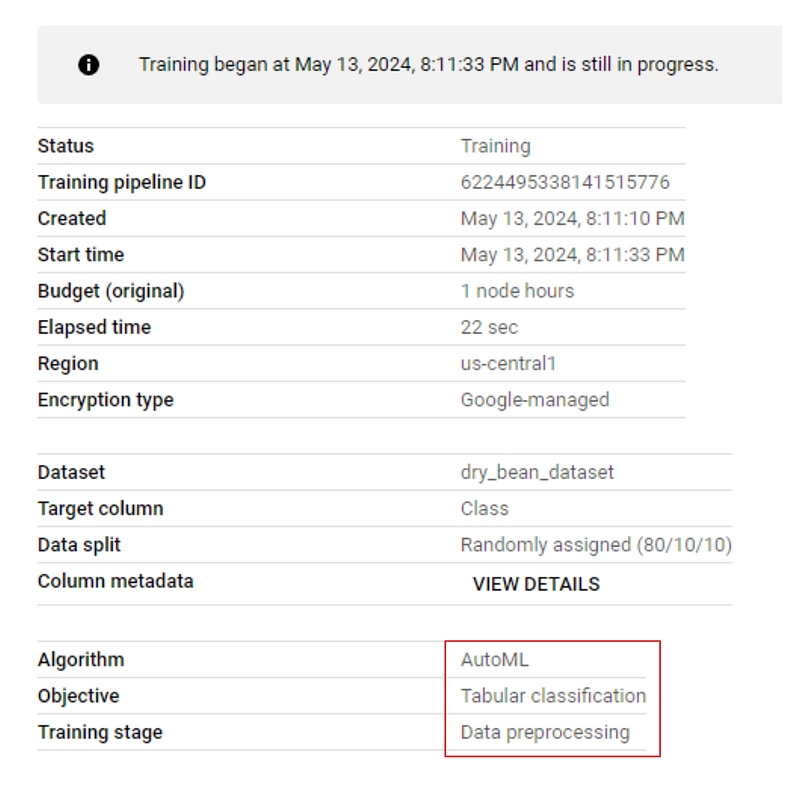
Una vez finalizado el entrenamiento, ve de nuevo a la pestaña de entrenamiento y haz clic en el nombre del modelo. Esta vez, habrá métricas de rendimiento enumeradas junto al modelo:
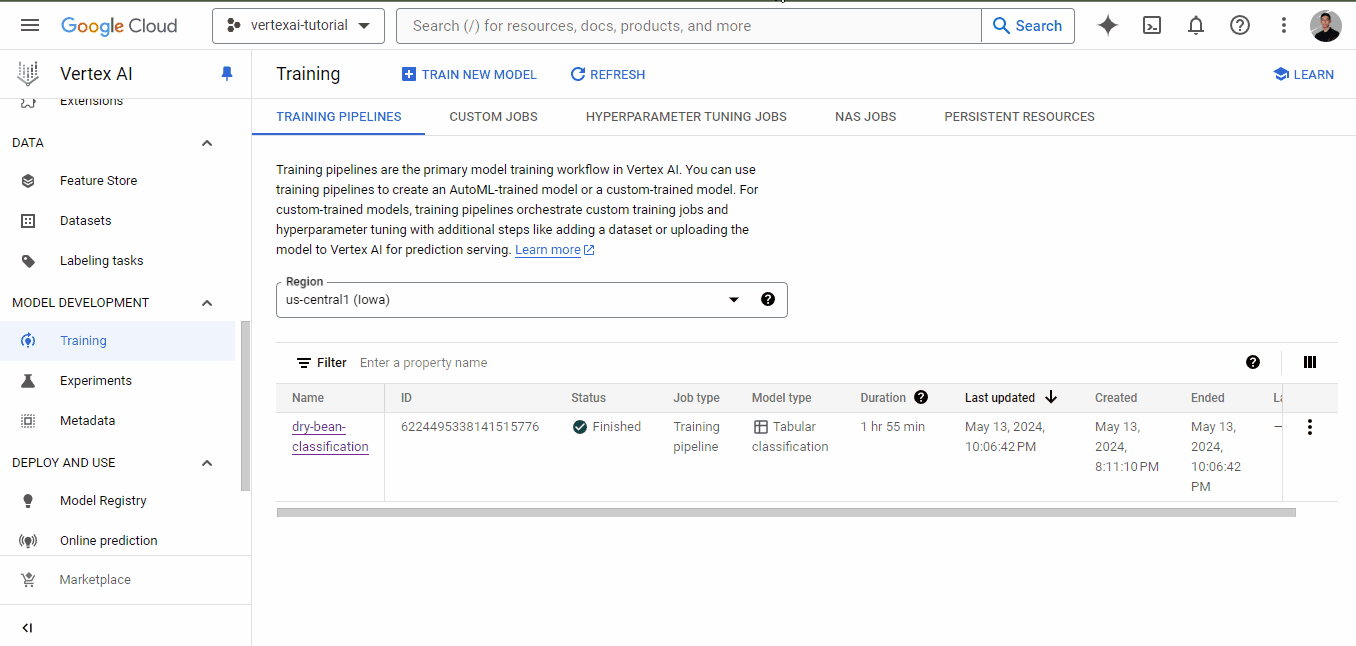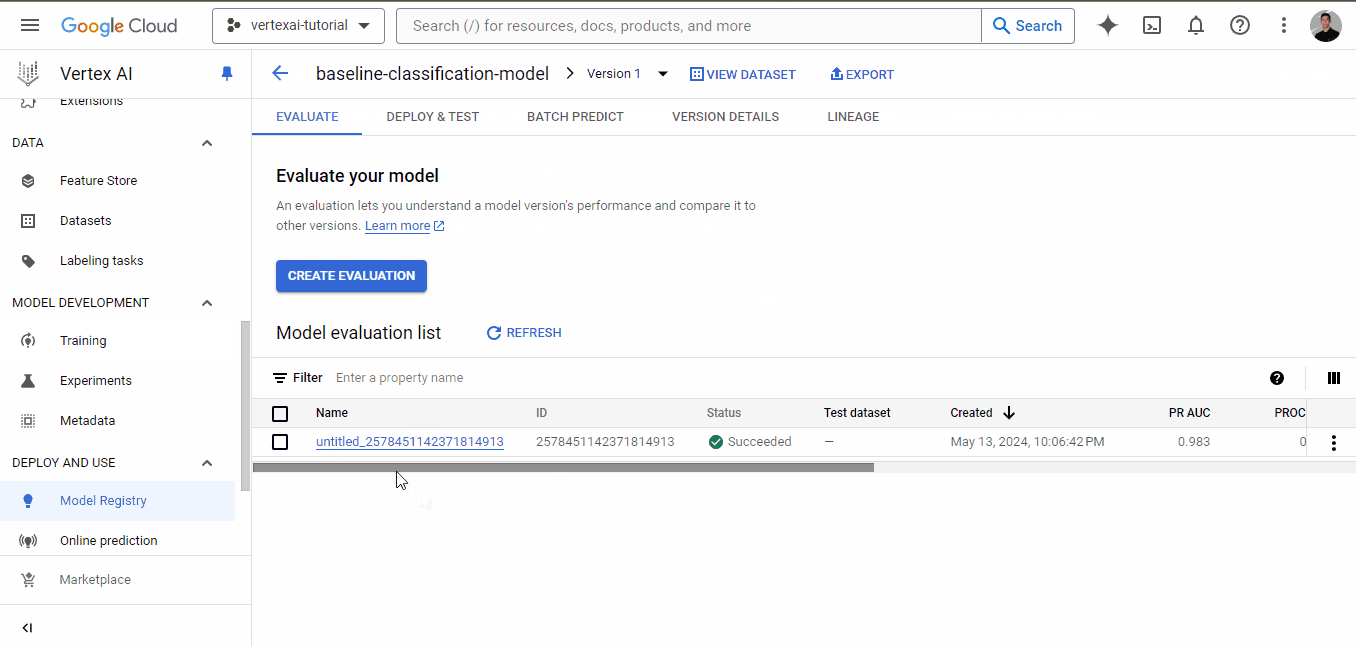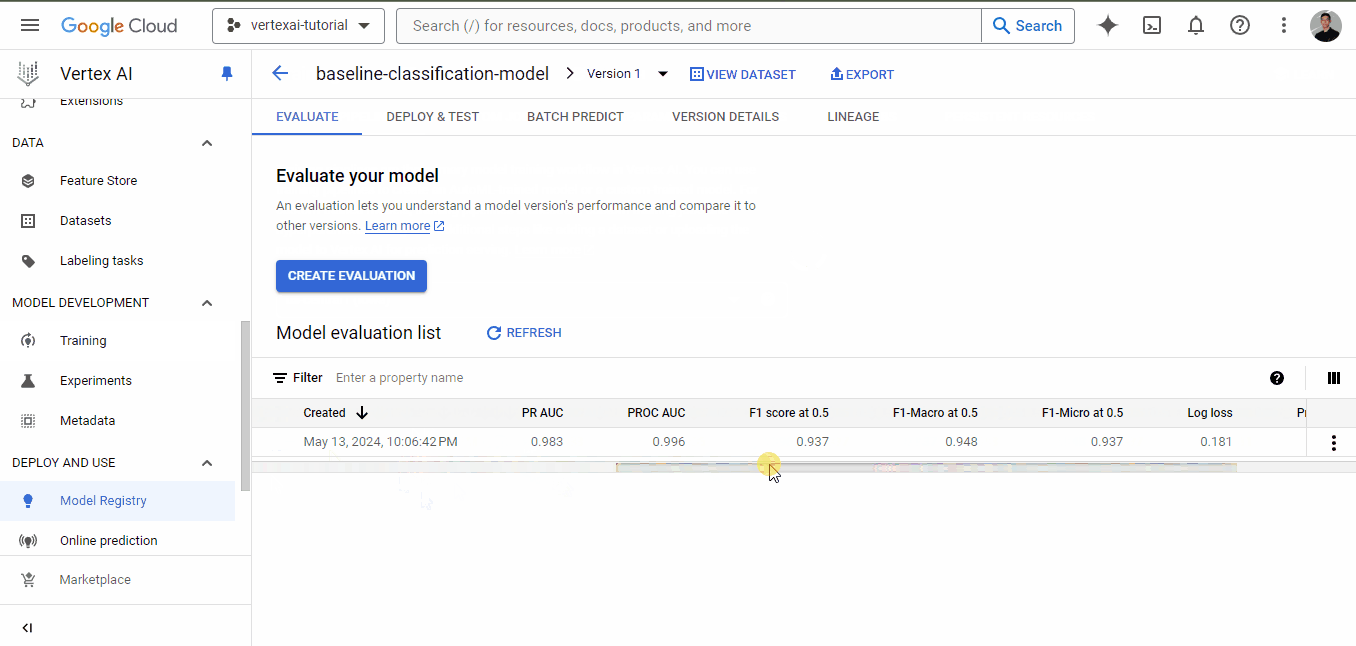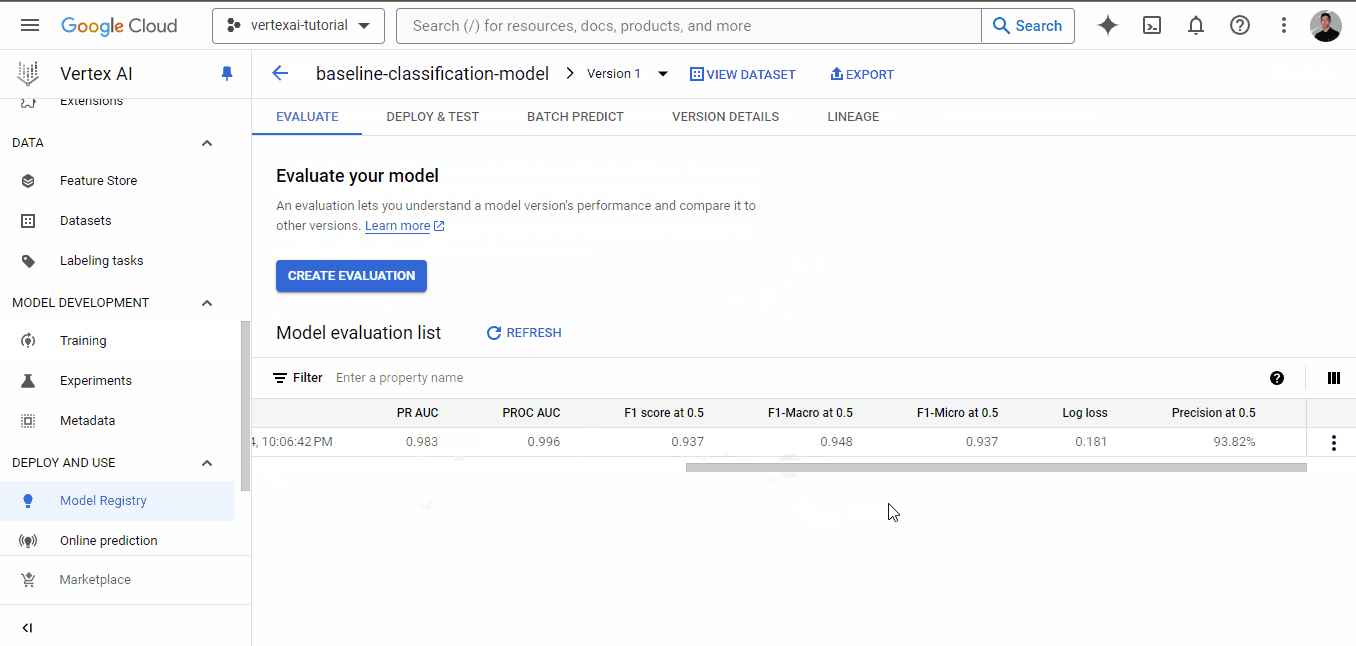
Como puedes ver, incluso para un modelo de referencia, tenemos métricas muy buenas, todas por encima de 0,90.
Ahora podemos desplegar este model con una sola línea de código:
endpoint = model.deploy(machine_type="n1-standard-4")
El método deploy sólo requiere un único argumento: el tipo de máquina para ejecutar la inferencia. En realidad, no ejecutaré la línea anterior, ya que el despliegue conlleva costes adicionales mientras el modelo esté en línea.
Sin embargo, si lo ejecutas, el método deploy devuelve un objeto Endpoint al que podemos enviar peticiones:
prediction = endpoint.predict(
[
{
"Area": "30099",
"Perimeter": "638.8209999999999",
"MajorAxisLength": "237.14191130827916",
"MinorAxisLength": "162.3034300714102",
"AspectRation": "1.4611022774068396",
"Eccentricity": "0.7290928631259719",
"ConvexArea": "30477",
"EquivDiameter": "195.76321681302556",
"Extent": "0.8036043251902283",
"Solidity": "0.9875972044492568",
"roundness": "0.9268374259664279",
"Compactness": "0.8255108332939839",
"ShapeFactor1": "0.007878730566074592",
"ShapeFactor2": "0.002256976927384019",
"ShapeFactor3": "0.6814681358857279",
"ShapeFactor4": "0.9956946453228307",
}
]
)
print(prediction)
Tiene un método predict que acepta una lista de muestras para predecir. Las muestras deben darse en formato JSON.
También puedes utilizar el panel de control para desplegar modelos. Si vas a la pestaña "REGISTRO DE MODELOS", verás que el modelo aparece allí. Haz clic en su nombre y elige la pestaña "DESPLIEGUE Y PRUEBA":
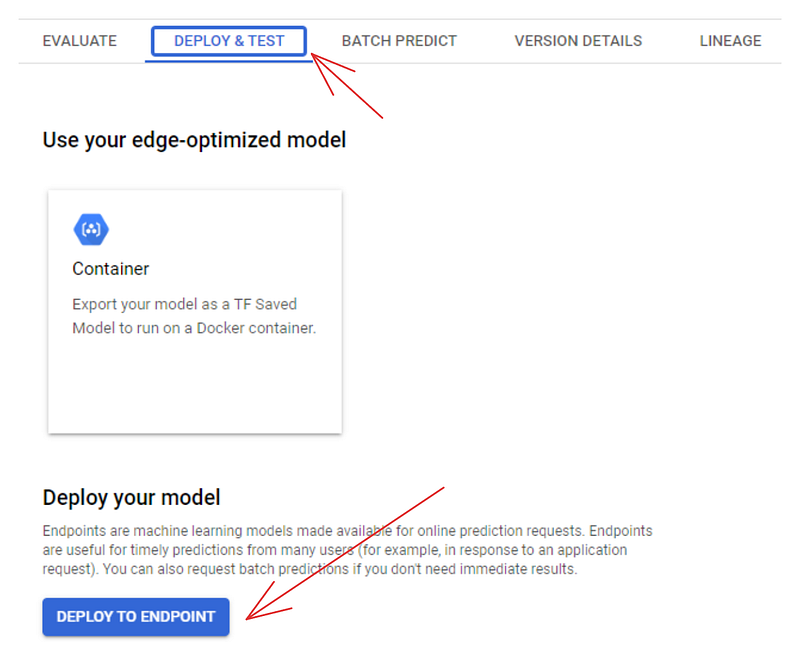
Si haces clic en el botón "DESPLIEGUE A ENDPOINT", accederás a otra página en la que podrás configurar la máquina para desplegar tu modelo. Pero antes de hacerlo, puedes probarlo en la zona situada debajo del botón de despliegue:
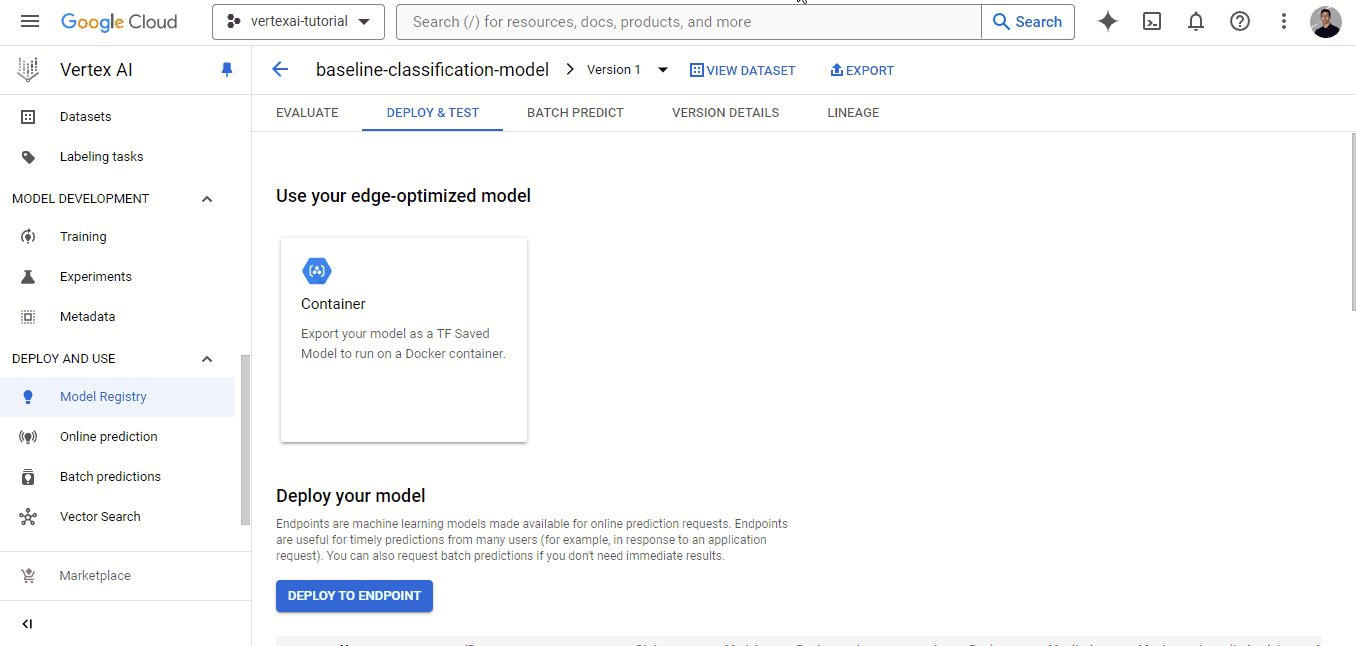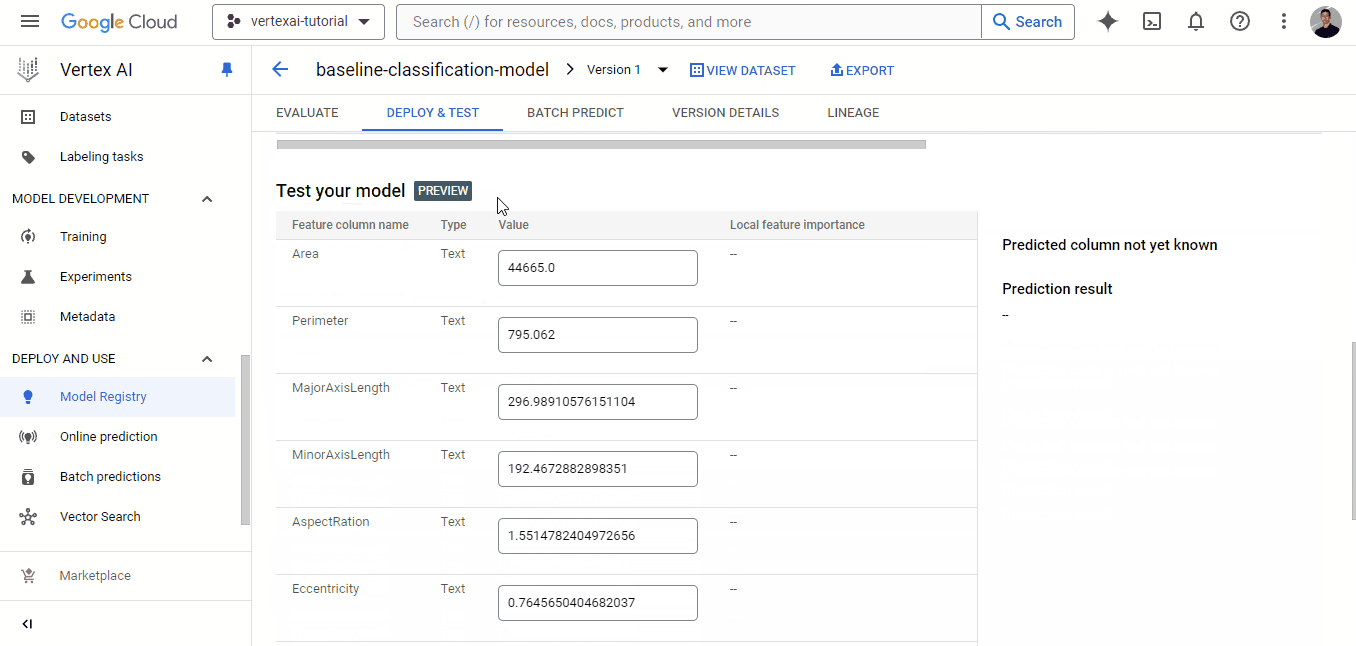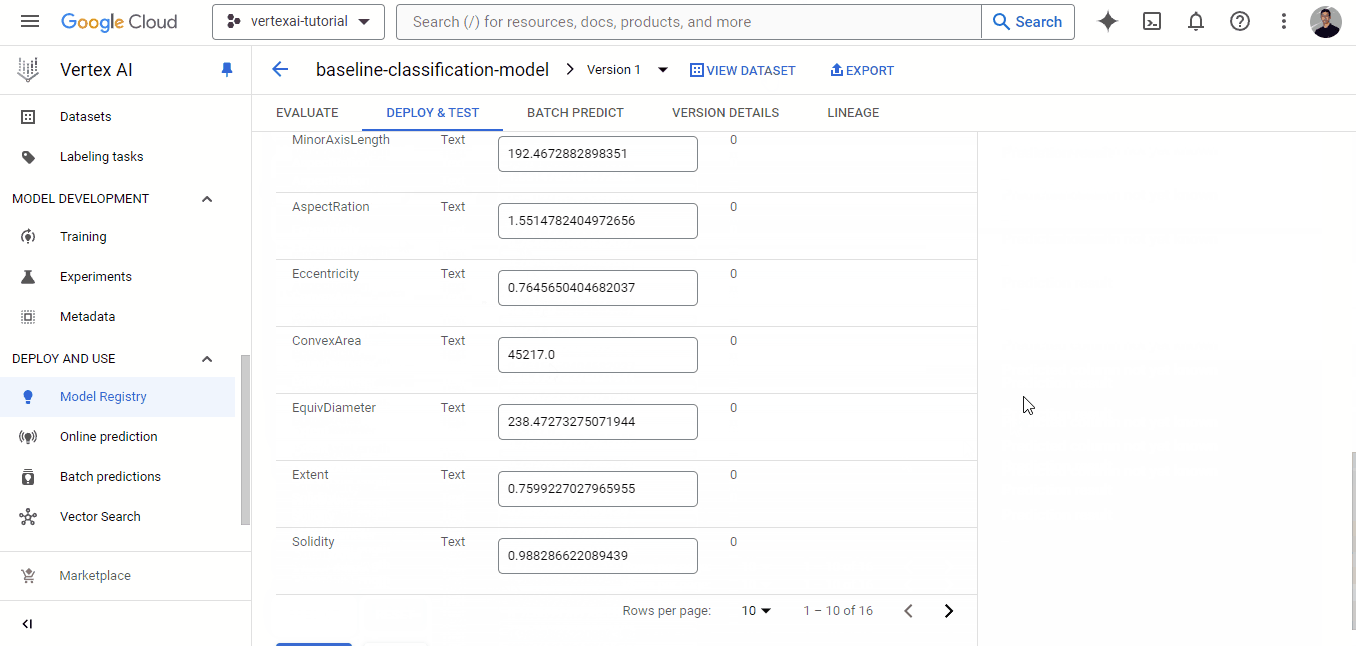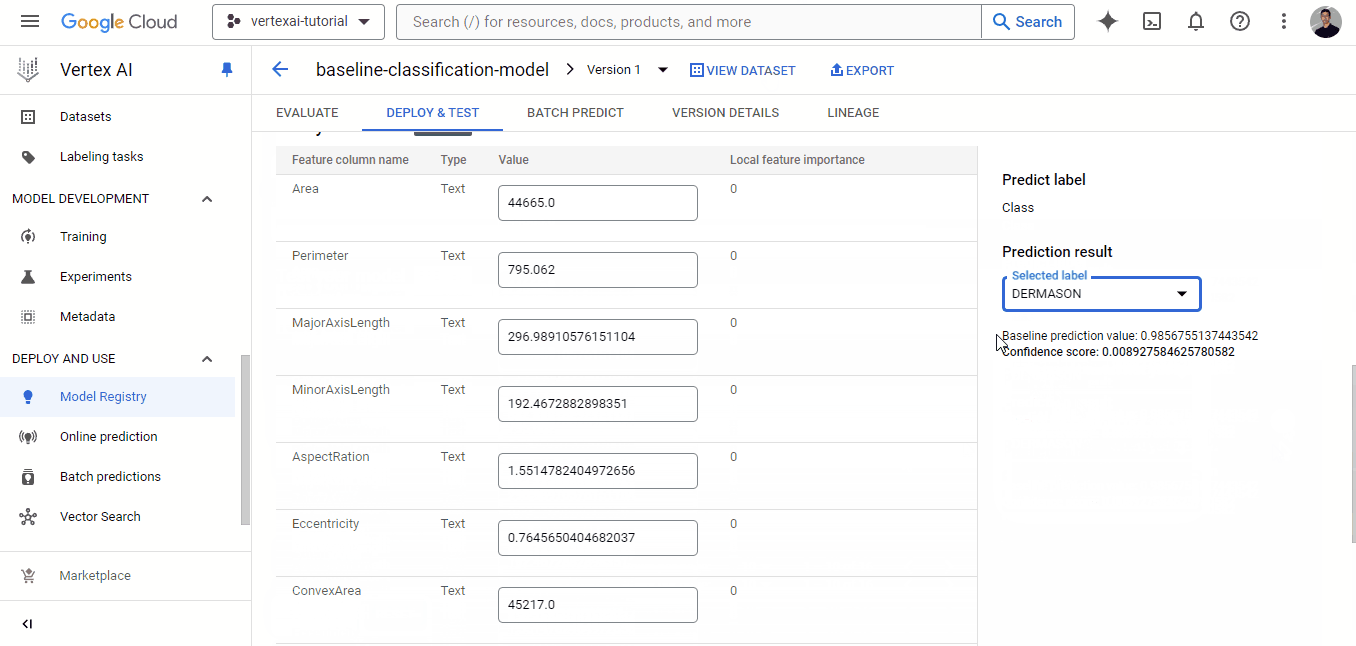
El despliegue de modelos personalizados en Vertex AI es más difícil que el de los modelos AutoML y también cuesta más porque habrá algunos contenedores Docker implicados además de tu Workbench y los gastos de despliegue. Si te animas, ¡vamos!
El entrenamiento personalizado implica empezar con un script de entrenamiento del modelo personalizado. En este guión, podemos hacer cualquier cosa siempre que
A continuación, este script de formación debe convertirse en un contenedor Docker y luego enviarse al Registro de Contenedores de Google. A partir de ahí, podemos utilizar el SDK Python de Vertex AI o el panel de control para entrenar el modelo personalizado.
En primer lugar, vamos a crear la estructura de directorios tal y como recomienda este laboratorio de código de Google. En tu mesa de trabajo, cambia al terminal iniciando un nuevo lanzador:
A continuación, crea un nuevo directorio llamado "frijoles secos" y cámbiate en él:
$ mkdir dry-beans
$ cd dry-beans/
Dentro de dry-beans, crea otro directorio llamado trainer y dentro de él, el archivo Python train.py:
$ mkdir trainer
$ touch trainer/train.py
A continuación, crea un nuevo archivo Dockerfile:
$ touch Dockerfile
Abre el archivo y pega el siguiente contenido:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-6
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Install XGBoost
RUN pip install xgboost==1.6.2
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Este Dockerfile utiliza la imagen oficial de aprendizaje profundo proporcionada por Google Container Registry con TensorFlow instalado. El archivo copia nuestro directorio trainer y luego instala XGBoost. Al final, ejecutará nuestro script Python.
El propio script debe cargar el conjunto de datos de judías secas de nuestro cubo GCP, entrenar un clasificador XGBoost en él y volver a guardar el modelo en el cubo. He escrito un sencillo script que realiza esas tareas en este gist de GitHub (no lo comparto aquí para ahorrar espacio).
Copia/pega el código del gist en train.py. Luego, de nuevo en el terminal, instala XGBoost, ya que no viene preinstalado en el Workbench que hayas elegido, y ejecuta el script:
$ pip install xgboost==1.6.2
$ python trainer/train.py
Si el script se ejecuta sin errores, continúa introduciendo estas dos variables en el terminal:
$ PROJECT_ID='vertexai-tutorial-423010' # Replace with your PROJECT_ID from earlier
$ IMAGE_URI="gcr.io/$PROJECT_ID/dry-beans:v1" # This stays the same
Estas variables se utilizarán cuando construyamos el contenedor y así lo hacemos:
$ docker build ./ -t $IMAGE_URI
La construcción llevará algún tiempo. Cuando termine, ejecuta el contenedor para asegurarte de que todo funciona correctamente:
$ docker run $IMAGE_URI
Model trained successfully!
Model uploaded successfully!
Si recibes los mensajes de éxito anteriores, entonces el contenedor está listo para empujar:
$ docker push $IMAGE_URIEn este punto, la mayor parte de la batalla está hecha. Ahora podemos cambiar al panel de control y crear un trabajo de entrenamiento personalizado utilizando el contenedor que acabamos de empujar. Así que dirígete a la pestaña "REGISTRO DE MODELOS" y haz clic en "CREAR":
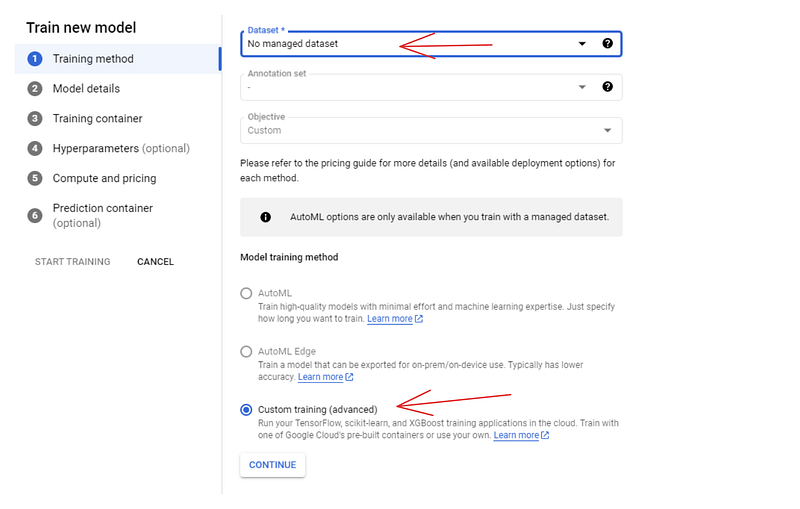
Para el método de entrenamiento, elige las opciones "Conjunto de datos no gestionado" y "Entrenamiento personalizado". En el siguiente panel (Detalles del modelo), dale un nombre al modelo -dry-beans-classifier.
En el panel del contenedor de entrenamiento:
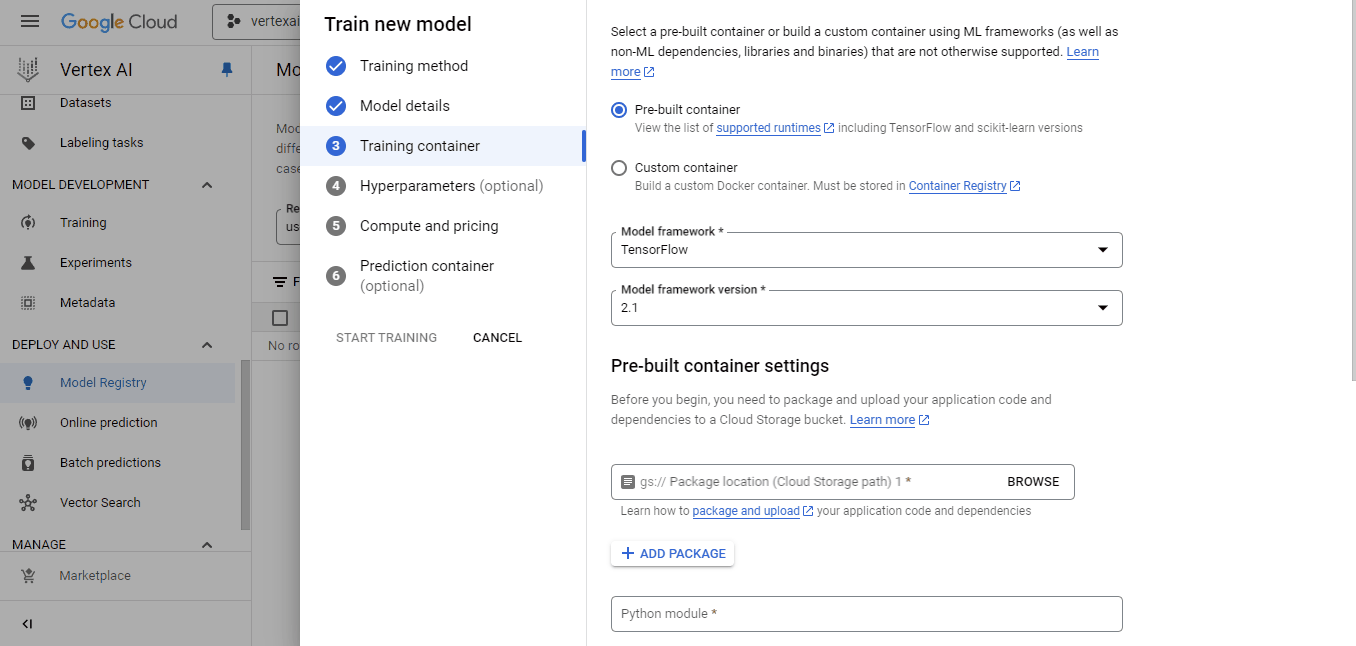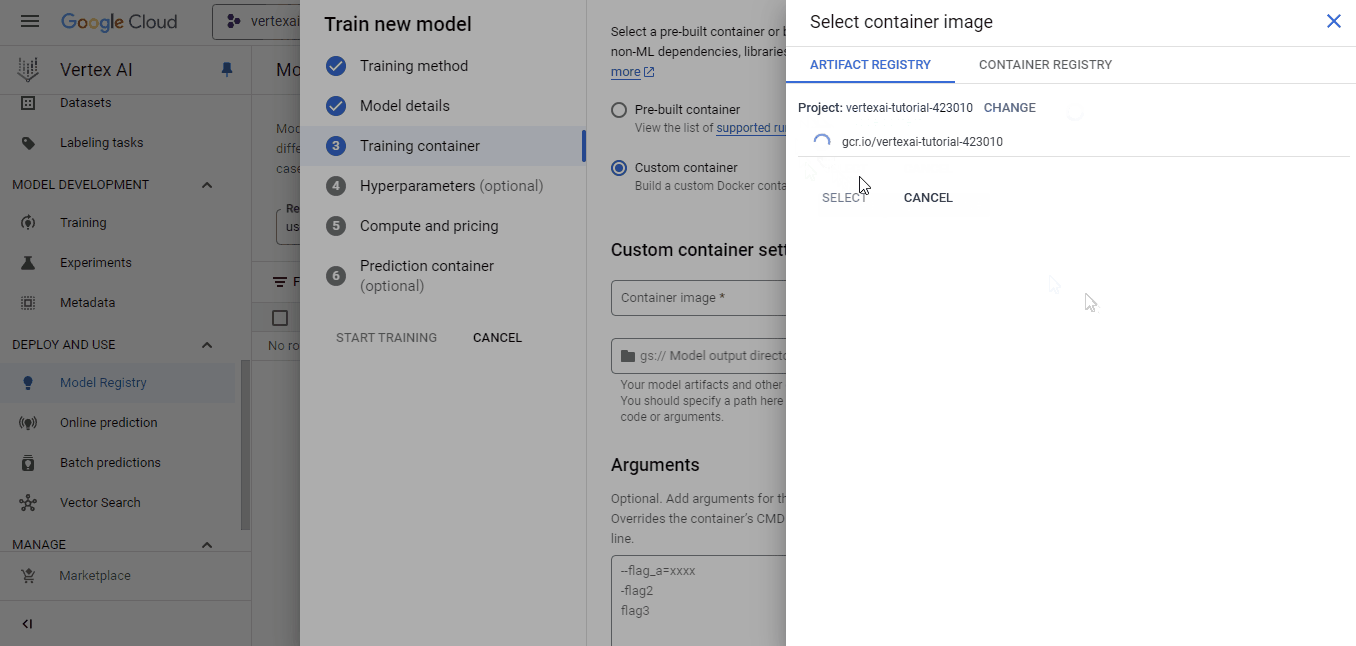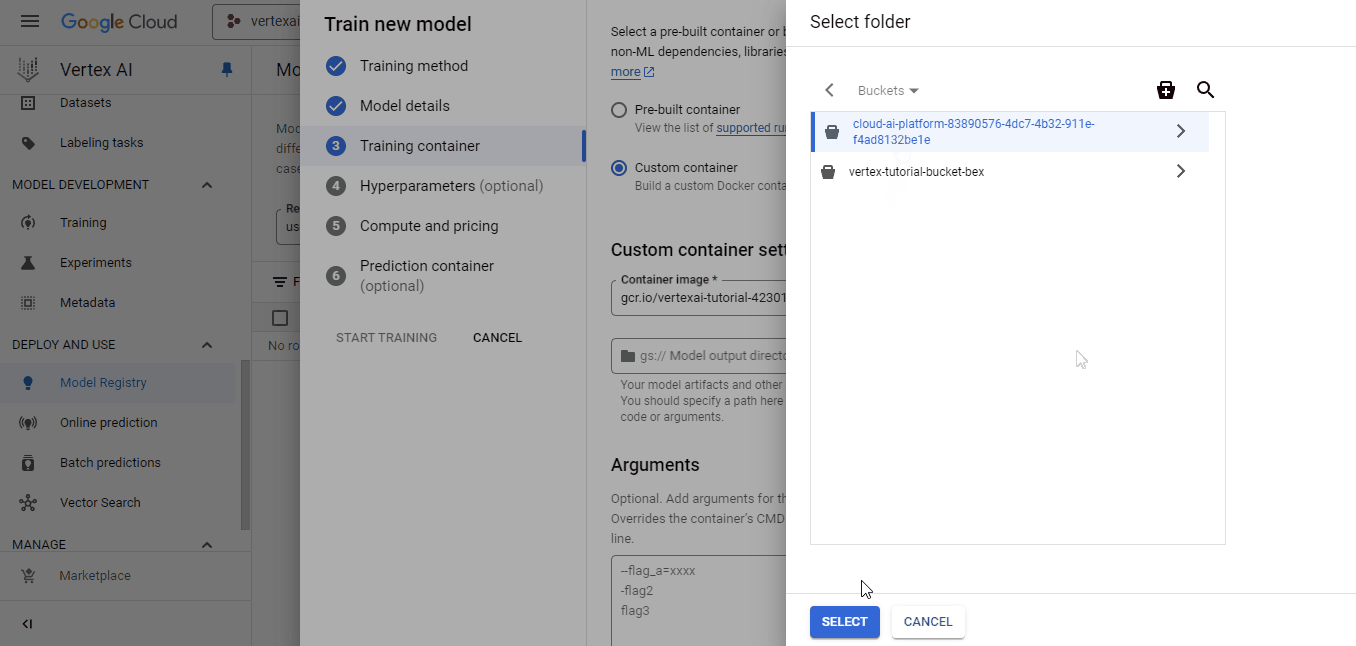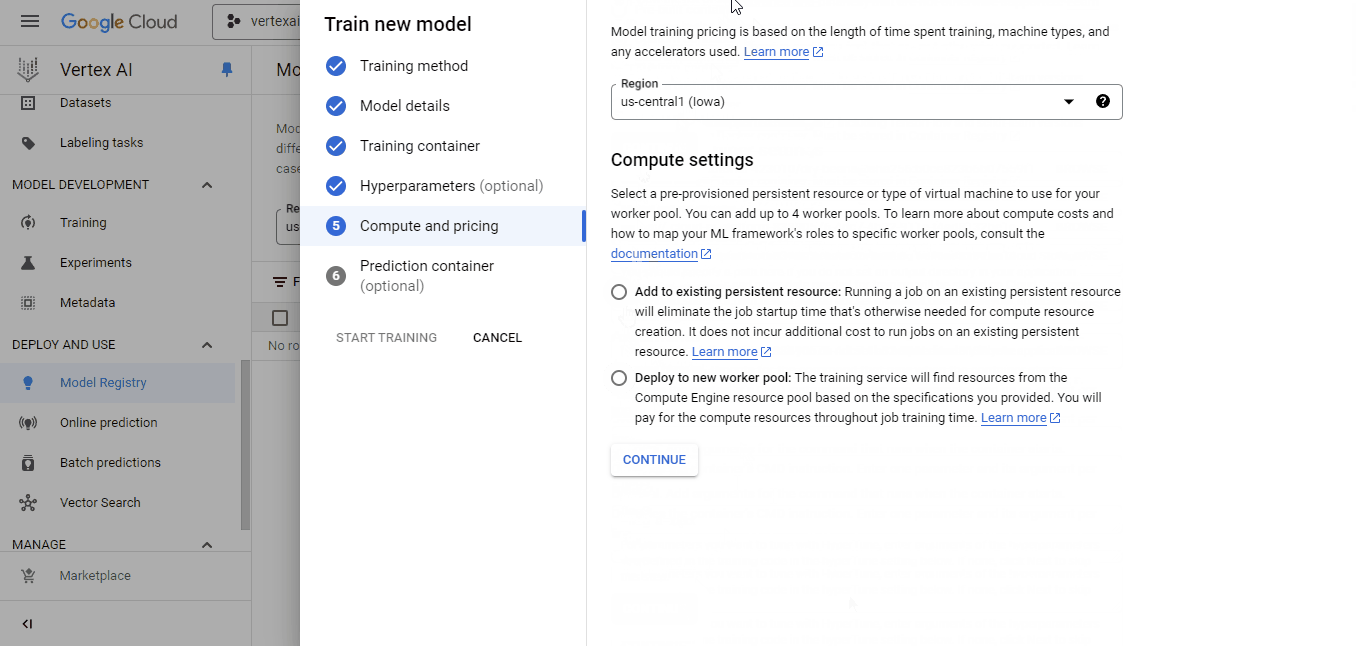
Selecciona el contenedor que hemos empujado para la imagen personalizada y el cubo cloud-ai-platform para la salida del modelo. A continuación, haz clic en Continuar hasta que llegues al panel "Computación y precios":
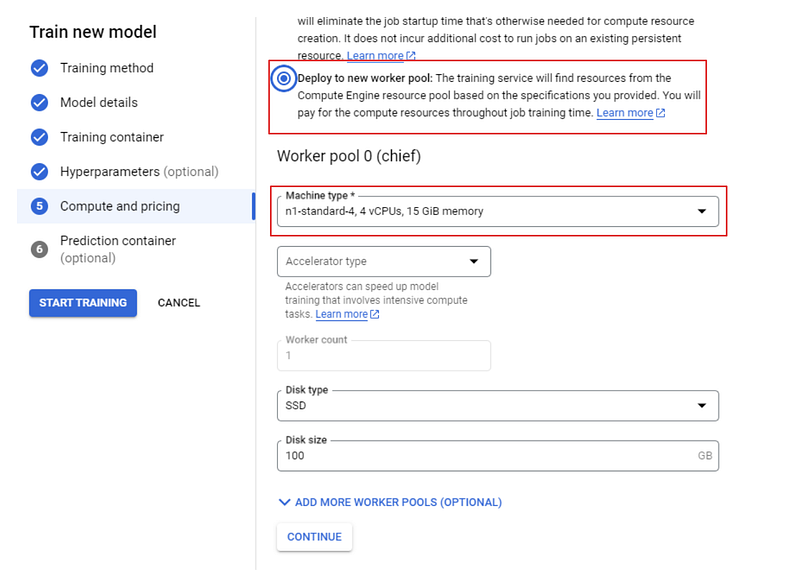
Elige una máquina n1 estándar con 4 CPUs y, por último, haz clic en "INICIAR ENTRENAMIENTO". A continuación, pasa a la pestaña "FORMACIÓN" de tu panel de control.
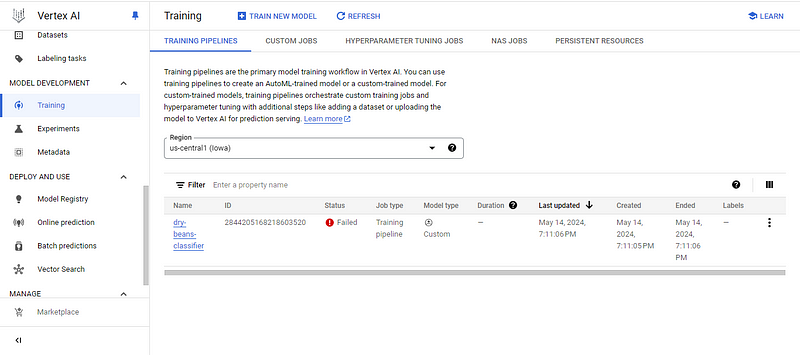
En este punto, verás una de dos cosas:
Yo tengo el primero, así que investiguemos por qué haciendo clic en el nombre del modelo:
![]()
El error me dice que he superado el número de CPUs de entrenamiento personalizadas permitidas. He profundizado en el tema y lo que he encontrado es muy decepcionante.
Normalmente, GCP da al menos 20 cuotas de CPU para cualquier región de cálculo, pero tras comprobar mi perfil, descubrí que mi cuota era sólo 1. Esto significaba que no podía ejecutar ningún trabajo de entrenamiento personalizado, ya que todas las máquinas que ofrece Google tienen al menos dos CPU.
Intenté aumentar mi cuota utilizando las respuestas de este hilo de StackOverflow, pero no funcionaron. El mensaje que recibí fue que a los nuevos usuarios de Vertex AI sólo se les permitía una única CPU. Si quisiera aumentar mi cuota, tendría que enviar un ticket de soporte, que, como resulta, no es gratuito (necesitas un contrato de soporte de pago).
Así que, si tienes mala suerte como yo, prueba las respuestas del hilo SO. A algunas personas les han funcionado, pero si a ti no, tu única opción es ponerte en contacto con el servicio de asistencia.
Pero si tienes suerte y termina tu entrenamiento, entonces podrás desplegar el modelo siguiendo los mismos pasos que he descrito para los modelos AutoML.
Vertex AI es una plataforma masiva con muchas funciones. En este tutorial, apenas hemos arañado la superficie, pero hemos cubierto los bloques de construcción más importantes de la plataforma. Si dominas la creación de cubos de almacenamiento, bancos de trabajo y trabajos de formación, estarás bien equipado para explorar el resto de la plataforma.
Si quieres saber más sobre los servicios de Google Cloud, consulta estos recursos relacionados recomendados:
¡Continúa hoy tu viaje por la IA!
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Kurtis Pykes
Tutorial
Arunn Thevapalan


