
Programa
Desenvolvimento de aplicativos de IA
21 h
O Gemini 2.0 Flash tem uma janela de contexto de 1.000.000 de tokens, o que permite o processamento completo do conjunto de dados sem a necessidade de mecanismos de recuperação ou de fragmentação. Além disso, ele é econômico em comparação com modelos maiores, como o Gemini Ultra.
Muitos aplicativos usam a geração aumentada por recuperação (RAG) para análise de dados estruturados, mas o Gemini 2.0 Flash elimina a necessidade de RAG porque:
Se quiser usar o Gemini 2.0 Flash Lite para otimizar o custo, você pode fazê-lo, mas saiba que, no momento da publicação deste artigo, ele está limitado a 60 consultas por minuto e só está disponível na região us-central1.
Vamos delinear as principais etapas que vamos seguir:
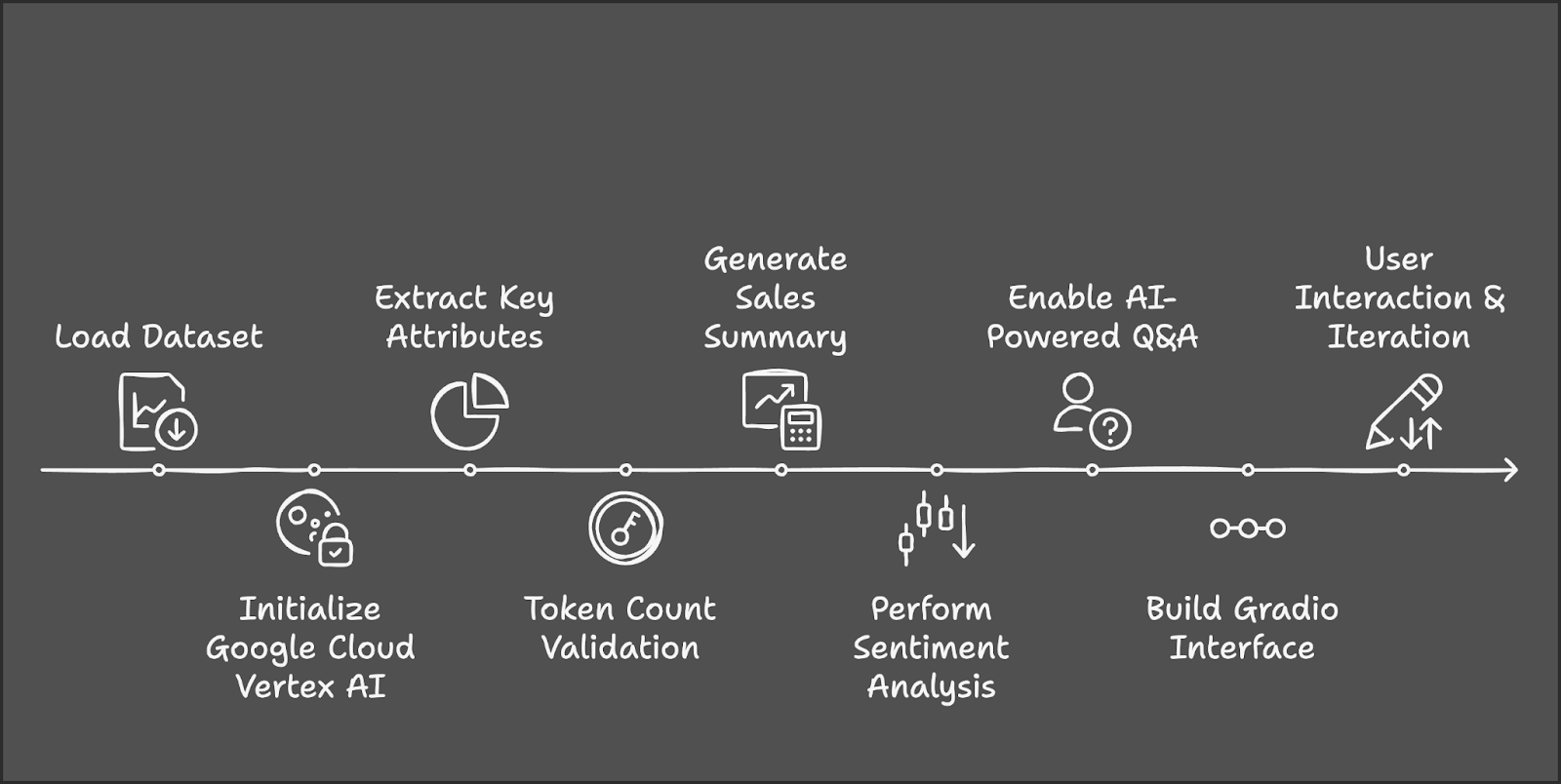
Antes de começarmos, vamos garantir que você tenha as seguintes ferramentas e bibliotecas instaladas:
Execute os seguintes comandos para instalar as dependências necessárias:
!pip install gradio -q
!pip install --upgrade --quiet google-genai
!pip install datasets -q
!pip install tiktoken -q
!pip install kaggle -qQuando as dependências acima estiverem instaladas, execute os seguintes comandos de importação:
import sys
import os
import tiktoken
from datasets import load_dataset
import pandas as pd
import gradio as gr
import vertexai
from vertexai.preview.generative_models import GenerativeModelUsaremos o conjunto de dados conjunto de dados do AWS SAAS Sales para este projeto, que está disponível no Kaggle. Comece configurando as credenciais do Kaggle e passando o nome do autor e do conjunto de dados, respectivamente.
# Set Kaggle API credentials
os.environ["KAGGLE_CONFIG_DIR"] = os.path.expanduser("~/.kaggle")
# Download dataset
!kaggle datasets download -d nnthanh101/aws-saas-sales --unzipAgora que o conjunto de dados foi baixado para o nosso ambiente, podemos começar a trabalhar com ele. Usaremos a biblioteca pandas para carregar e ler o conjunto de dados do caminho.
dataset_path = "path_to_your_data.csv" # Load dataset from specified path
dataset_df = pd.read_csv(dataset_path) Esse conjunto de dados contém 9.994 transações com colunas como:
Para usar o Gemini 2.0 Flash, você precisa se autenticar no Google Cloud.
if "google.colab" in sys.modules:
from google.colab import auth
auth.authenticate_user()Para inicializar o Vertex AI, procure a API do Vertex AI e a habilite (verifique se o faturamento está habilitado em sua conta).
Salve o ID e o local do projeto para referência futura. A execução do Gemini 2.0 Flash para esse projeto custou cerca de US$ 0,07 para aproximadamente cinco chamadas à API.
# Set up Google Cloud Vertex AI
PROJECT_ID = "Your_project_id"
LOCATION = "Your_location"
vertexai.init(project=PROJECT_ID, location=LOCATION)
model = GenerativeModel("gemini-2.0-flash")Para saber mais sobre o Vertex AI, confira este tutorial introdutório sobre Vertex AI.
Etapa 4: Pré-processamento de dados
Para garantir o tratamento adequado dos dados, normalize os nomes das colunas e extraia as principais categorias. Encontramos setores e produtos exclusivos que funcionam como fonte para nossa redução de preço na demonstração. Se você estiver usando um conjunto de dados diferente, escolha as categorias de acordo.
# Normalize column names to prevent key errors
df.columns = df.columns.str.strip().str.lower()
print("Dataset columns:", df.columns) # Debugging
# Extract unique industry names and product categories
unique_industries = sorted(df["industry"].dropna().unique().tolist())
unique_industries.insert(0, "All Industries") # Add "All Industries" option
unique_products = sorted(df["product"].dropna().unique().tolist())
unique_products.insert(0, "All Products") # Add "All Products" optionAgora que já processamos nosso conjunto de dados, vamos contar os tokens. Como o Gemini 2.0 Flash tem um limite de 1.000.000 de tokens, é importante calcular o número de tokens no conjunto de dados antes de passá-lo para o modelo. Esse conjunto de dados tem 805447 tokens.
# Initialize tokenizer (use "cl100k_base" for Gemini/GPT models)
encoder = tiktoken.get_encoding("cl100k_base")
# Choose relevant text columns
text_columns = ['industry', 'product', 'sales', 'quantity', 'discount', 'profit']
# Create a combined text column for tokenization
df["combined_text"] = df[text_columns].astype(str).agg(" | ".join, axis=1)
# Function to count tokens
def count_tokens(texts):
total_tokens = sum(len(encoder.encode(str(text))) for text in texts)
return total_tokens
# Calculate total tokens
total_tokens = count_tokens(df["combined_text"].dropna().tolist())
print(f"Total tokens in the dataset: {total_tokens}")Usamos o Tiktoken para tokenização da seguinte forma:
cl100k_base do Tiktoken, otimizado para os modelos Gemini e GPT.combined_text e calcule o número total de tokens em todas as linhas.Agora, podemos trabalhar nas partes analíticas da demonstração. Essa função gera um resumo de vendas com base no setor e no produto selecionados.
def summarize_sales(industry, product):
filtered_data = df.copy()
if industry != "All Industries":
filtered_data = filtered_data[filtered_data["industry"] == industry]
if product != "All Products":
filtered_data = filtered_data[filtered_data["product"] == product]
if filtered_data.empty:
return "No sales data available for the selected industry and product."
# Create sales report
total_sales = filtered_data["sales"].sum()
total_quantity = filtered_data["quantity"].sum()
total_profit = filtered_data["profit"].sum()
avg_discount = filtered_data["discount"].mean()
sales_text = f"""
Sales Data for {industry} - {product}:
- Total Sales: ${total_sales:,.2f}
- Total Quantity Sold: {total_quantity}
- Total Profit: ${total_profit:,.2f}
- Average Discount: {avg_discount:.2f}%
"""
# Generate summary using Gemini 2.0 Flash
response = model.generate_content(sales_text, stream=True)
response_text = "".join(chunk.text for chunk in response)
return response_textA função summarize_sales() filtra o conjunto de dados com base no setor e no produto selecionados, calcula as principais métricas de vendas, como vendas totais, quantidade vendida, lucro e desconto médio, e formata os dados em um prompt estruturado. Esse prompt é então passado para o modelo Gemini 2.0 Flash para gerar um resumo de vendas conciso.
Da mesma forma, definimos outra função que realiza a análise de sentimentos com base no lucro total.
def analyze_sales_sentiment(industry, product):
filtered_data = dataset_df.copy()
if industry != "All Industries":
filtered_data = filtered_data[filtered_data["industry"] == industry]
if product != "All Products":
filtered_data = filtered_data[filtered_data["product"] == product]
if filtered_data.empty:
return "No sales data available for sentiment analysis."
total_sales = filtered_data["sales"].sum()
total_profit = filtered_data["profit"].sum()
# Define sentiment labels based on profit margins
if total_profit > 500000:
sentiment_label = "Positive"
elif total_profit > 100000:
sentiment_label = "Neutral"
else:
sentiment_label = "Negative"
sentiment_text = f"""
The total sales for {industry} - {product} is ${total_sales:,.2f},
with a total profit of ${total_profit:,.2f}.
Based on market trends, this performance is considered {sentiment_label}.
Analyze the sentiment of sales performance for this product.
"""
# Generate sentiment analysis using Gemini Flash 2.0
response = model.generate_content(sentiment_text, stream=True)
# Collect response text
response_text = "".join(chunk.text for chunk in response)
return response_textA função analyze_sales_sentiment() analisa o sentimento de vendas filtrando o conjunto de dados com base no setor e no produto selecionados, calculando o total de vendas e o lucro total e gerando uma análise de sentimento com tecnologia de IA usando o Gemini 2.0 Flash. Em seguida, o modelo recebe um resumo estruturado do desempenho das vendas, permitindo que ele avalie o sentimento dinamicamente em vez de depender apenas de limites fixos de lucro.
Agora, temos todas as principais funções lógicas implementadas. Em seguida, trabalharemos na criação de uma interface de usuário interativa com o Gradio.
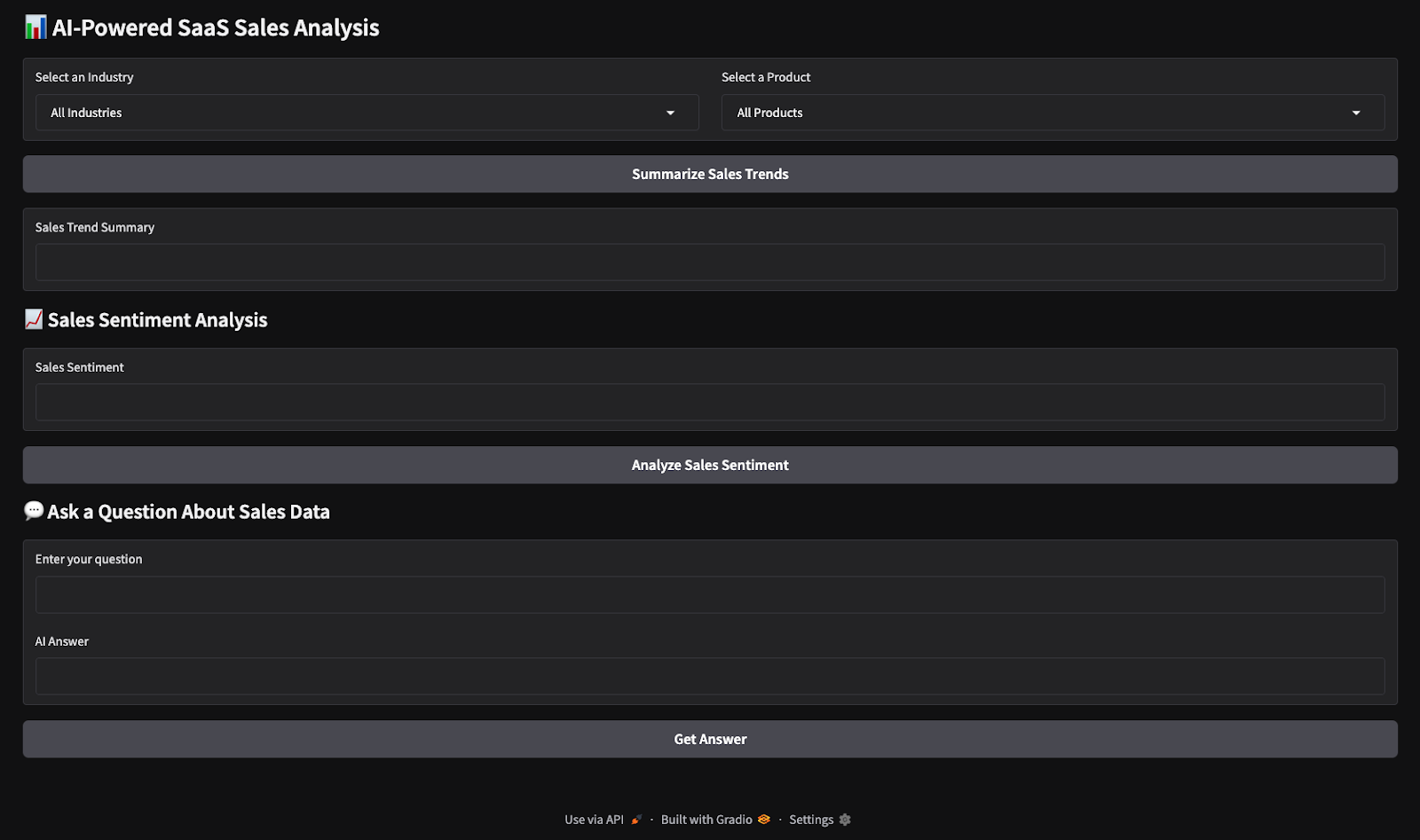
with gr.Blocks() as demo:
gr.Markdown("# AI-Powered SaaS Sales Analysis")
industry_dropdown = gr.Dropdown(choices=unique_industries, label="Select an Industry")
product_dropdown = gr.Dropdown(choices=unique_products, label="Select a Product")
summarize_btn = gr.Button("Summarize Sales Trends")
summary_output = gr.Textbox(label="Sales Trend Summary")
summarize_btn.click(summarize_sales, inputs=[industry_dropdown, product_dropdown], outputs=summary_output)
demo.launch(debug=True)Esse código cria uma UI Gradio interativa para análise de vendas de SaaS com IA, em que os usuários podem selecionar um setor e um produto nos menus suspensos e clicar em um botão para gerar um resumo de vendas. As entradas selecionadas são passadas para a função summarize_sales(), que processa os dados e retorna insights, exibidos em uma caixa de texto. O aplicativo Gradio é então iniciado para interação em tempo real.
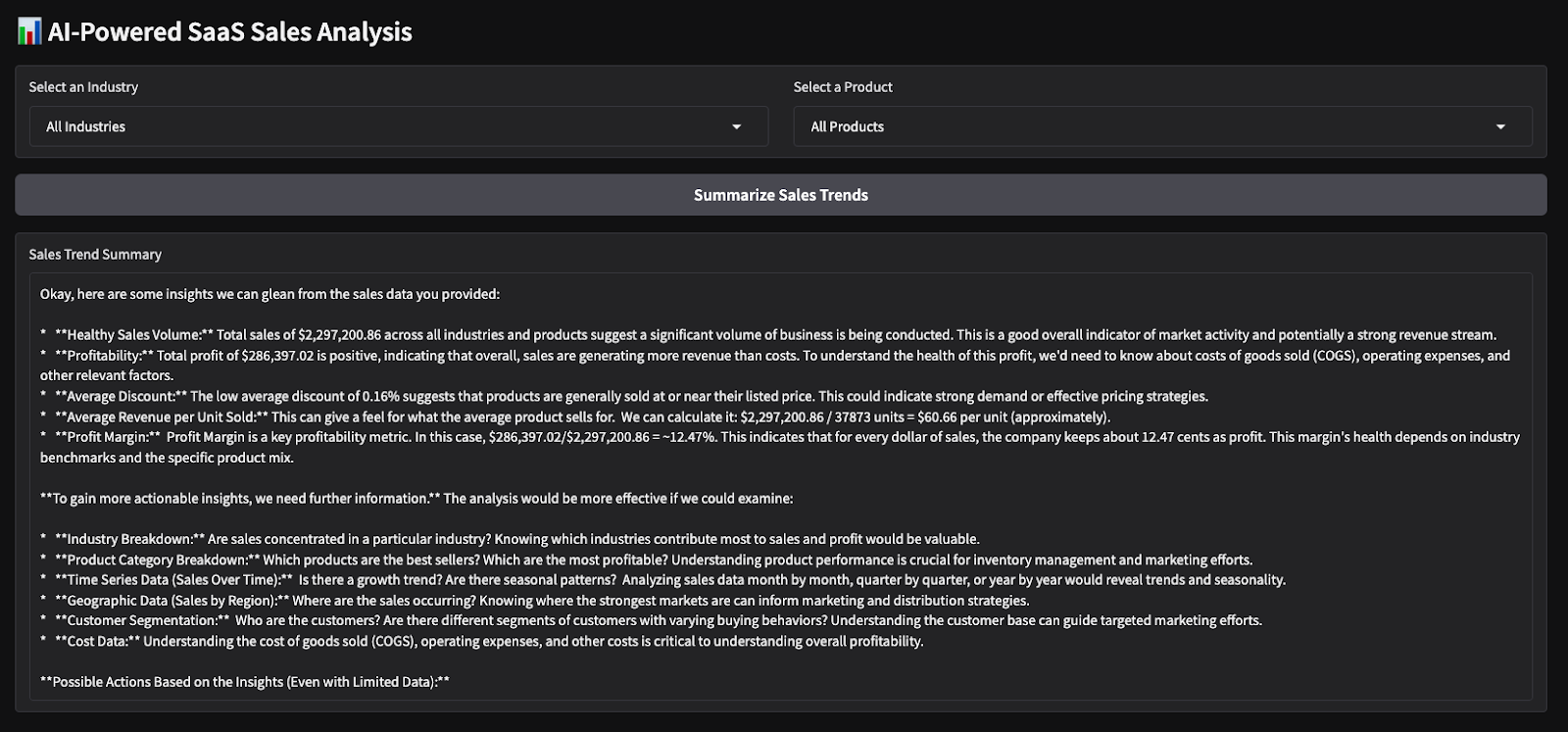
Aqui estão os resultados de um teste rápido que executei. Escolhi todos os setores e produtos e, em seguida, solicitei ao modelo que produzisse um resumo de vendas e fizesse uma análise de sentimentos sobre os parâmetros escolhidos.

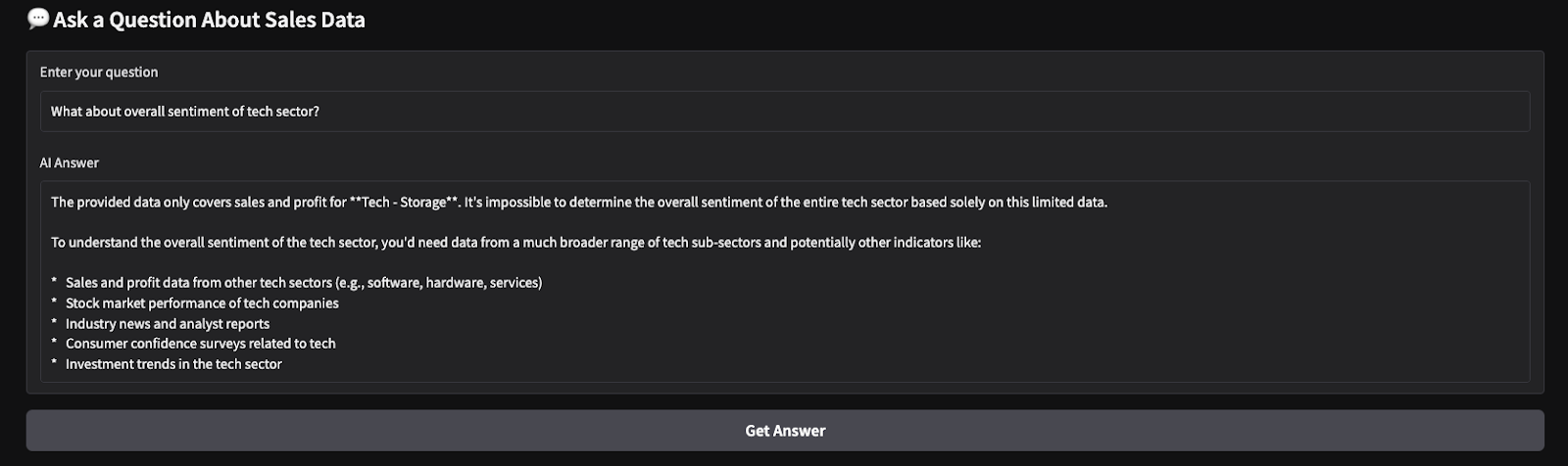
Neste tutorial, criamos uma ferramenta de insights de vendas de SaaS com tecnologia de IA usando o Gemini 2.0 Flash, permitindo a análise em tempo real dos dados de vendas de SaaS. Usamos a grande janela de contexto do Gemini 2.0 Flash para processar dados estruturados sem RAG e integramos uma interface interativa baseada no Gradio para facilitar a interação do usuário.
Recomendo que você adapte este tutorial ao seu próprio caso de uso. Para saber mais sobre como criar aplicativos com o Gemini 2.0, recomendo estes tutoriais:
Aprenda IA com estes cursos!
Programa
Programa
Curso
blog
Ryan Ong
8 min
Tutorial
Ryan Ong
Tutorial
Matt Crabtree
Tutorial
Dimitri Didmanidze
Tutorial
Josep Ferrer