
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Gemini 2.0 Flash hat ein Kontextfenster von 1.000.000 Token, das die vollständige Verarbeitung von Datensätzen ohne Chunking- oder Retrieval-Mechanismen ermöglicht. Außerdem ist es im Vergleich zu größeren Modellen wie Gemini Ultra kostengünstig.
Viele Anwendungen verwenden Retrieval-augmented Generation (RAG) für die Analyse strukturierter Daten, aber Gemini 2.0 Flash macht RAG überflüssig, denn:
Wenn du Gemini 2.0 Flash Lite zur Kostenoptimierung nutzen willst, kannst du das tun. Beachte aber, dass es zum Zeitpunkt der Veröffentlichung dieses Artikels auf 60 Abfragen pro Minute begrenzt ist und nur in der Region us-central1 verfügbar ist.
Lass uns die wichtigsten Schritte skizzieren, die wir unternehmen werden:
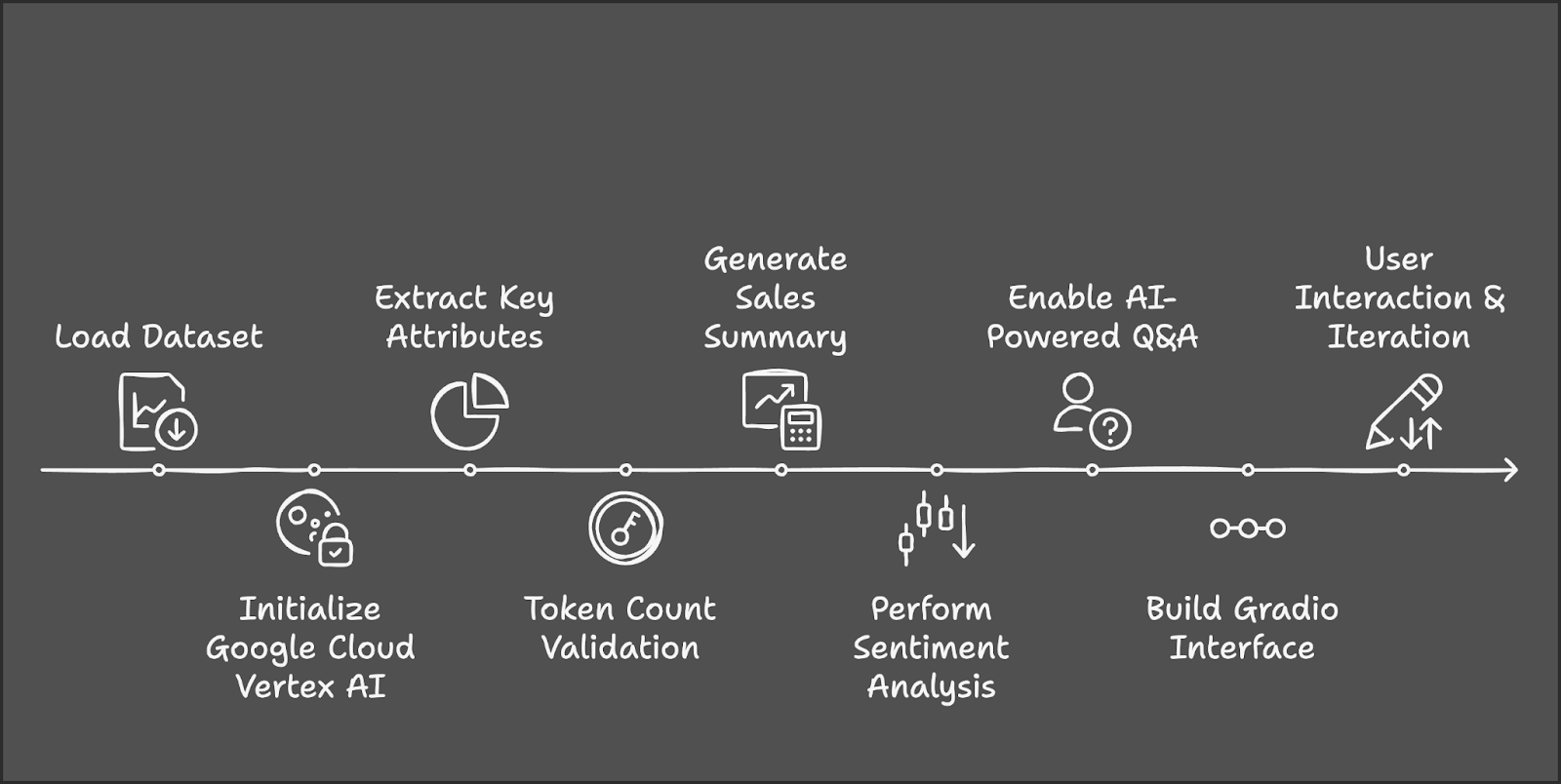
Bevor wir beginnen, müssen wir sicherstellen, dass wir die folgenden Tools und Bibliotheken installiert haben:
Führe die folgenden Befehle aus, um die notwendigen Abhängigkeiten zu installieren:
!pip install gradio -q
!pip install --upgrade --quiet google-genai
!pip install datasets -q
!pip install tiktoken -q
!pip install kaggle -qSobald die oben genannten Abhängigkeiten installiert sind, führst du die folgenden Importbefehle aus:
import sys
import os
import tiktoken
from datasets import load_dataset
import pandas as pd
import gradio as gr
import vertexai
from vertexai.preview.generative_models import GenerativeModelWir verwenden den AWS SAAS Sales-Datensatz für dieses Projekt, der auf Kaggle verfügbar ist. Beginne damit, die Kaggle-Zugangsdaten einzurichten und den Autor bzw. den Namen des Datensatzes anzugeben.
# Set Kaggle API credentials
os.environ["KAGGLE_CONFIG_DIR"] = os.path.expanduser("~/.kaggle")
# Download dataset
!kaggle datasets download -d nnthanh101/aws-saas-sales --unzipJetzt, wo der Datensatz in unsere Umgebung heruntergeladen wurde, können wir mit ihm arbeiten. Wir werden die Pandas-Bibliothek verwenden, um den Datensatz aus dem Pfad zu laden und zu lesen.
dataset_path = "path_to_your_data.csv" # Load dataset from specified path
dataset_df = pd.read_csv(dataset_path) Dieser Datensatz enthält 9.994 Transaktionen mit Spalten wie:
Um Gemini 2.0 Flash zu nutzen, müssen wir uns bei Google Cloud authentifizieren.
if "google.colab" in sys.modules:
from google.colab import auth
auth.authenticate_user()Um Vertex AI zu initialisieren, suche nach Vertex AI API und aktiviere sie (stelle sicher, dass die Abrechnung in deinem Konto aktiviert ist).
Speichere die ID und den Ort des Projekts für spätere Zwecke. Der Betrieb von Gemini 2.0 Flash für dieses Projekt kostete etwa $0,07 für etwa fünf API-Aufrufe.
# Set up Google Cloud Vertex AI
PROJECT_ID = "Your_project_id"
LOCATION = "Your_location"
vertexai.init(project=PROJECT_ID, location=LOCATION)
model = GenerativeModel("gemini-2.0-flash")Wenn du mehr über Vertex AI erfahren möchtest, schau dir dieses Einführungs-Tutorial an Vertex-KI.
Schritt 4: Datenvorverarbeitung
Um eine korrekte Datenverarbeitung zu gewährleisten, normalisiere die Spaltennamen und extrahiere die Schlüsselkategorien. Wir finden einzigartige Branchen und Produkte, die als Quelle für unseren Abschlag in der Demo dienen. Wenn du einen anderen Datensatz verwendest, dann wähle deine Kategorien entsprechend.
# Normalize column names to prevent key errors
df.columns = df.columns.str.strip().str.lower()
print("Dataset columns:", df.columns) # Debugging
# Extract unique industry names and product categories
unique_industries = sorted(df["industry"].dropna().unique().tolist())
unique_industries.insert(0, "All Industries") # Add "All Industries" option
unique_products = sorted(df["product"].dropna().unique().tolist())
unique_products.insert(0, "All Products") # Add "All Products" optionNachdem wir unseren Datensatz verarbeitet haben, zählen wir nun die Token. Da Gemini 2.0 Flash ein Limit von 1.000.000 Token hat, ist es wichtig, die Anzahl der Token im Datensatz zu berechnen, bevor er an das Modell übergeben wird. Dieser Datensatz hat 805447 Token.
# Initialize tokenizer (use "cl100k_base" for Gemini/GPT models)
encoder = tiktoken.get_encoding("cl100k_base")
# Choose relevant text columns
text_columns = ['industry', 'product', 'sales', 'quantity', 'discount', 'profit']
# Create a combined text column for tokenization
df["combined_text"] = df[text_columns].astype(str).agg(" | ".join, axis=1)
# Function to count tokens
def count_tokens(texts):
total_tokens = sum(len(encoder.encode(str(text))) for text in texts)
return total_tokens
# Calculate total tokens
total_tokens = count_tokens(df["combined_text"].dropna().tolist())
print(f"Total tokens in the dataset: {total_tokens}")Wir verwenden Tiktoken für die Tokenisierung wie folgt:
cl100k_base Tokenizer von Tiktoken, der für Gemini- und GPT-Modelle optimiert ist.combined_text und berechne die Gesamtzahl der Token in allen Zeilen.Jetzt können wir an den Analysten-Teilen der Demo arbeiten. Diese Funktion erstellt eine Zusammenfassung der Verkäufe basierend auf der ausgewählten Branche und dem Produkt.
def summarize_sales(industry, product):
filtered_data = df.copy()
if industry != "All Industries":
filtered_data = filtered_data[filtered_data["industry"] == industry]
if product != "All Products":
filtered_data = filtered_data[filtered_data["product"] == product]
if filtered_data.empty:
return "No sales data available for the selected industry and product."
# Create sales report
total_sales = filtered_data["sales"].sum()
total_quantity = filtered_data["quantity"].sum()
total_profit = filtered_data["profit"].sum()
avg_discount = filtered_data["discount"].mean()
sales_text = f"""
Sales Data for {industry} - {product}:
- Total Sales: ${total_sales:,.2f}
- Total Quantity Sold: {total_quantity}
- Total Profit: ${total_profit:,.2f}
- Average Discount: {avg_discount:.2f}%
"""
# Generate summary using Gemini 2.0 Flash
response = model.generate_content(sales_text, stream=True)
response_text = "".join(chunk.text for chunk in response)
return response_textDie Funktion summarize_sales() filtert den Datensatz anhand der ausgewählten Branche und des Produkts, berechnet wichtige Umsatzkennzahlen wie Gesamtumsatz, verkaufte Menge, Gewinn und Durchschnittsrabatt und formatiert die Daten in einer strukturierten Eingabeaufforderung. Diese Eingabeaufforderung wird dann an das Gemini 2.0 Flash-Modell weitergegeben, um eine übersichtliche Zusammenfassung der Verkäufe zu erstellen.
Auf ähnliche Weise definieren wir eine weitere Funktion, die eine Stimmungsanalyse auf der Grundlage des Gesamtgewinns durchführt.
def analyze_sales_sentiment(industry, product):
filtered_data = dataset_df.copy()
if industry != "All Industries":
filtered_data = filtered_data[filtered_data["industry"] == industry]
if product != "All Products":
filtered_data = filtered_data[filtered_data["product"] == product]
if filtered_data.empty:
return "No sales data available for sentiment analysis."
total_sales = filtered_data["sales"].sum()
total_profit = filtered_data["profit"].sum()
# Define sentiment labels based on profit margins
if total_profit > 500000:
sentiment_label = "Positive"
elif total_profit > 100000:
sentiment_label = "Neutral"
else:
sentiment_label = "Negative"
sentiment_text = f"""
The total sales for {industry} - {product} is ${total_sales:,.2f},
with a total profit of ${total_profit:,.2f}.
Based on market trends, this performance is considered {sentiment_label}.
Analyze the sentiment of sales performance for this product.
"""
# Generate sentiment analysis using Gemini Flash 2.0
response = model.generate_content(sentiment_text, stream=True)
# Collect response text
response_text = "".join(chunk.text for chunk in response)
return response_textDie Funktion analyze_sales_sentiment() analysiert die Verkaufsstimmung, indem sie den Datensatz anhand der ausgewählten Branche und des Produkts filtert, den Gesamtumsatz und den Gesamtgewinn berechnet und eine KI-gestützte Stimmungsanalyse mit Gemini 2.0 Flash erstellt. Das Modell erhält dann eine strukturierte Zusammenfassung der Verkaufsleistung, so dass es die Stimmung dynamisch bewerten kann, anstatt sich nur auf feste Gewinnschwellen zu verlassen.
Jetzt sind alle wichtigen logischen Funktionen vorhanden. Als Nächstes arbeiten wir daran, mit Gradio eine interaktive Benutzeroberfläche zu erstellen.
with gr.Blocks() as demo:
gr.Markdown("# AI-Powered SaaS Sales Analysis")
industry_dropdown = gr.Dropdown(choices=unique_industries, label="Select an Industry")
product_dropdown = gr.Dropdown(choices=unique_products, label="Select a Product")
summarize_btn = gr.Button("Summarize Sales Trends")
summary_output = gr.Textbox(label="Sales Trend Summary")
summarize_btn.click(summarize_sales, inputs=[industry_dropdown, product_dropdown], outputs=summary_output)
demo.launch(debug=True)Dieser Code erstellt eine interaktive Gradio-Benutzeroberfläche für die KI-gestützte SaaS-Verkaufsanalyse, bei der die Nutzer eine Branche und ein Produkt aus Dropdown-Menüs auswählen und auf eine Schaltfläche klicken können, um eine Verkaufsübersicht zu erstellen. Die ausgewählten Eingaben werden an die Funktion summarize_sales() weitergegeben, die die Daten verarbeitet und die Ergebnisse in einem Textfeld anzeigt. Die Gradio-App wird dann für die Echtzeit-Interaktion gestartet.
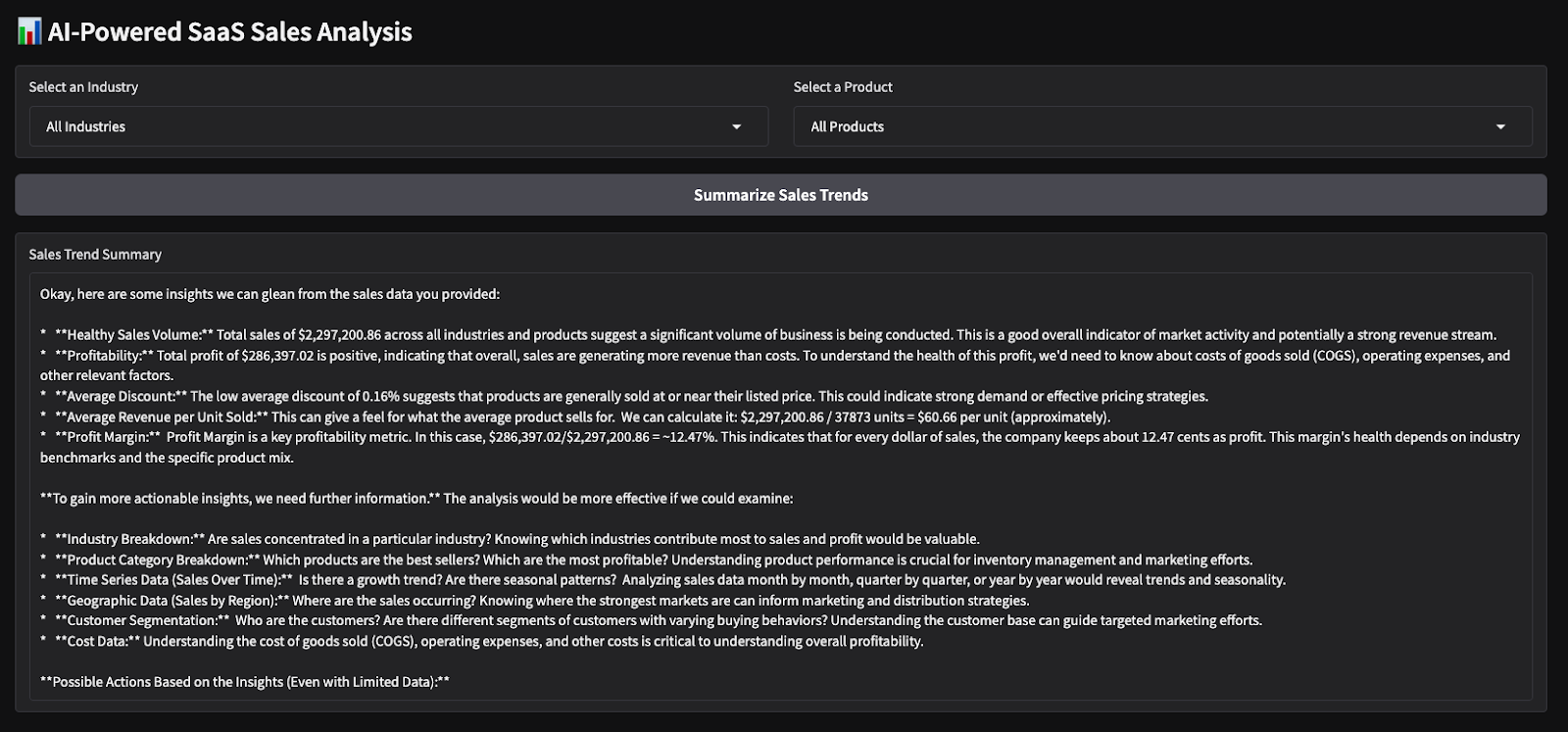
Hier sind die Ergebnisse eines kurzen Tests, den ich durchgeführt habe. Ich habe alle Branchen und Produkte ausgewählt und das Modell dann gebeten, eine Umsatzübersicht zu erstellen und eine Stimmungsanalyse für die gewählten Parameter durchzuführen.

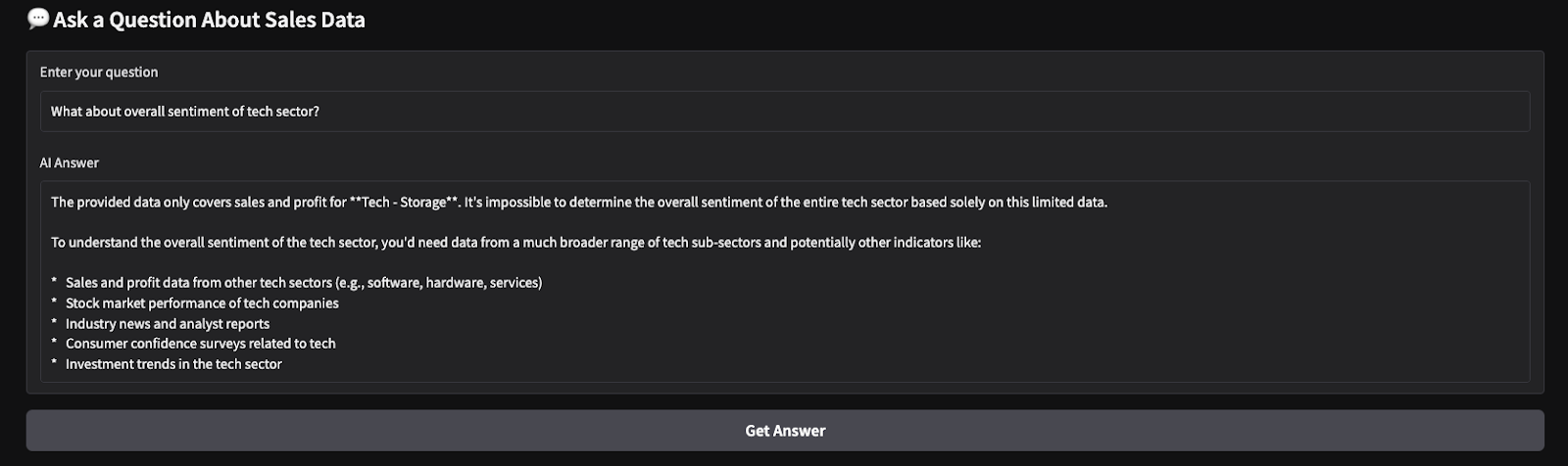
In diesem Tutorial haben wir mit Gemini 2.0 Flash ein KI-gestütztes Tool für SaaS-Verkaufseinblicke entwickelt, das die Echtzeitanalyse von SaaS-Verkaufsdaten ermöglicht. Wir nutzten das große Kontextfenster von Gemini 2.0 Flash, um strukturierte Daten ohne RAG zu verarbeiten und integrierten eine Gradio-basierte interaktive Schnittstelle für eine einfache Benutzerinteraktion.
Ich ermutige dich, dieses Tutorial an deinen eigenen Anwendungsfall anzupassen. Um mehr über die Entwicklung von Apps mit Gemini 2.0 zu erfahren, empfehle ich diese Tutorials:
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
