
Course
Understanding ChatGPT
1 hr
424.4K
Imagine you’ve spent hours writing a piece of content.
You’re satisfied with the final product, so you push it out to the public.
After a while of being in the public domain, you realize you’re turning away a huge audience since many people don’t feel they have time to sit down and read through your work.
You contemplate narrating the content yourself, but time isn’t on your side. You flirt with the idea of hiring a narrator, but the quotes you’ve been getting are way beyond your budget, and the time it takes to find someone with the “right” voice is also a burden.
In typical 21st-century fashion, you look to technology for a solution. That’s when you learn about OpenAI’s Text-to-Speech (TTS) API.
For the remainder of this tutorial, we will cover OpenAI’s TTS API, namely, its key features, how to get started, customization, and real-world use cases.
Text-to-speech (TTS) is a type of assistive technology used to convert natural language, provided in text format, into speech. Namely, text-to-speech systems take words written on a computer (or any other digital device) and read the text aloud.
OpenAI’s TTS API is an endpoint that enables users to interact with their TTS AI model that converts text to natural-sounding spoken language. The model has two variations:
The endpoint comes prebuilt with six voices and, according to the OpenAI TTS Documentation, can be used to:
However, it’s important to note that OpenAI’s Usage Policies require users to provide clear discloser to end users that the TTS voice they hear is AI-generated and not a human voice.
Let’s look at how you can get started using the OpenAI Text-to-Speech API, covering the prerequisites and the steps you need to follow:
Once logged into your OpenAI account, you’ll be directed to the home screen. From here, navigate to the OpenAI logo in the top left-hand corner of the page to toggle the sidebar.
Select “API Keys.”
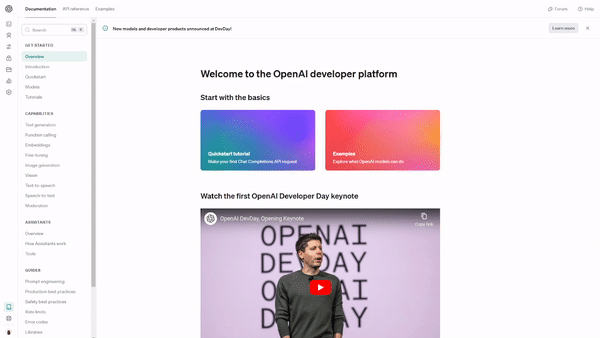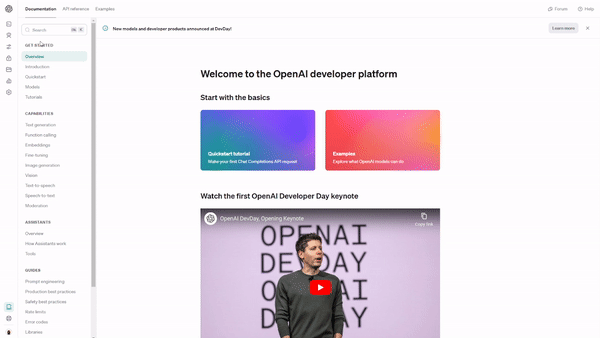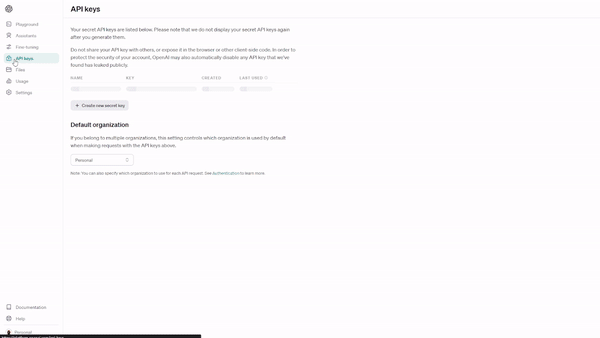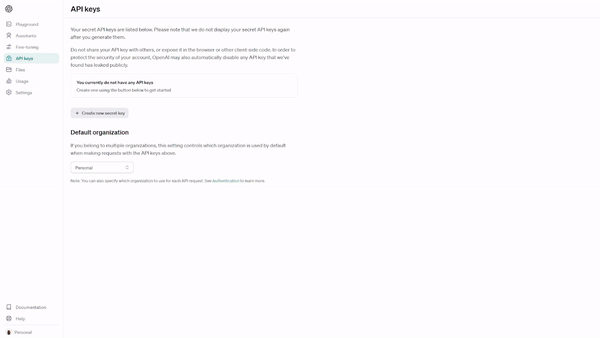
Select “Create new secret key” and give your API key a name – we named ours “tts-example.”
When you create your API key, a secret key will be generated. Be sure to save the key somewhere safe and secure.
Now you’ve got the key, you’re ready to get started!
A Virtual Environment is used to create a container or isolated environment where the Python-related dependencies are installed for a specific project. One can work with many different versions of Python with its various packages.
Getting into more depth with virtual environments is beyond the scope of this article. Check out the Virtual Environment in Python tutorial to learn more about creating one.
There’s three key inputs the speech endpoint takes:
In OpenAI’s text-to-speech documentation, there’s a sample request; thus, we don’t have to reinvent the wheel.
Here’s how a sample request looks:
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)As things stand, the code won’t run.
The reason it won’t run is that we haven’t passed the API key we generated in step one to our OpenAI client…
The easiest way to solve this problem is to add an api_key parameter where we can pass our secret key to the OpenAI() object.
For example:
client = OpenAI(api_key="secret key goes here") Doing this is bad practice in Python.
Instead, we will use dotenv to read the secret key from a .env file.
The first thing you must do is install dotenv into your virtual environment. Run this command from your virtual environment:
pip install python-dotenvNow dotenv is installed, we can create a .env file, which contains key-value pairs, and set the values as environment variables.
This allows us to conceal our secret key, even if the code is shared publicly.
First things first, we must create a .env file and insert the following:
SECRET_KEY = "insert your secret key token here" In our main.py file, we can now call our environment variables using dotenv.
Here’s how the code looks.
import os
from pathlib import Path
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
SECRET_KEY = os.getenv("SECRET_KEY")
client = OpenAI(api_key=SECRET_KEY)
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)Now the code runs.
The default behavior of the code is to output an MP3 file of the spoken audio. If you would prefer a different file format, you can configure the output to any of the supported formats.
There are tons of different voices and accents in the world.
While it may be impossible to capture each and every single one, OpenAI’s TTS attempted to reflect the diverse world we live in by integrating six unique built-in voices into the API:
These can convey different personalities, or you may use them based on your preference. All you have to do is set the voice you wish to use using the voice parameter in the client object.
response = client.audio.speech.create(
model="tts-1",
voice="alloy", # Update this to change voice
input="Today is a wonderful day to build something people love!"
)Check out the OpenAI text-to-speech API documentation to learn more about the available voices.
You can also alter the output format.
The default response of the API is an MP3 file of your converted text. However, OpenAI provides a range of other formats to cater to your needs and preferences. Such as:
TLDR: the choice of output you select may impact the audio quality, file size, and the file's compatibility with various devices, as well as applications.
In terms of language support, the text-to-speech model follows the Whisper model used for speech-to-text; the voices are optimized for English but have support for several other languages.
Now that we know how to set up the TTS API, let’s have a look at some examples of how you can use it.
Let’s say you’ve written a book or blog post and want to expand its reach to a wider audience by converting it to audio. If you did things the old-fashioned way, you would have to find a narrator (or narrate it yourself), which can be a long process.
The OpenAI TTS API can be used to shorten this process; all you would do is pass the text document to the API, and it will convert it to speech.
Instead of teaching group lessons, language teachers can use OpenAI’s text-to-speech API to create personalized lessons for students using various languages and dialects. Despite the voices being optimized for the English language, the API can still be used to generate audio content in several languages.
The OpenAI TTS API can be used to create AI voices that sound more realistic and expressive than traditional TTS systems. Video game developers may leverage this capability and apply it to characters to make the experience more immersive for players.
Another use case may be to create virtual assistants and chatbots that are more engaging than the traditional ones in existence.
The rate limits for the OpenAI TTS API begin at 50 Request Per Minute (RPM) for paid accounts, and the maximum input size is 4096 characters – equivalent to approximately 5 minutes of audio at default speed.
With regards to the TTS models, pricing is as follows:
If you’re looking for a cost-effective way to integrate the TTS API into a small project, you may be better off opting for the standard TTS model. The TTS HD model is slightly more pricey but offers high-definition audio, which is ideal when the quality of your audio is paramount – learn more about pricing for OpenAI’s audio models.
OpenAI’s text-to-speech API is an endpoint for users to generate high-quality spoken audio from text. It comes with six built-in voices, and users can select one of two models, TTS-1 and TTS-1-HD, depending on their use case; the TTS-1 model is optimized for real-time text-to-speech, while TTS-1-HD is optimized for quality.
In this blog post, we’ve covered:
Check out these cool resources to continue your learning:
Start Your AI Journey Today!
Course
Course
Course
blog
Austin Chia
11 min
Tutorial
Abid Ali Awan
Tutorial
François Aubry
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Stanislav Karzhev



