Curso
Entendendo o ChatGPT
1 h
424.4K
Imagine que você passou horas escrevendo um conteúdo.
Você está satisfeito com o produto final, então o divulga para o público.
Depois de algum tempo em domínio público, você percebe que está afastando um grande público, pois muitas pessoas acham que não têm tempo para sentar e ler seu trabalho.
Você pensa em narrar o conteúdo por conta própria, mas o tempo não está do seu lado. Você flerta com a ideia de contratar um narrador, mas as cotações que tem recebido estão muito além do seu orçamento, e o tempo necessário para encontrar alguém com a voz "certa" também é um fardo.
No típico estilo do século XXI, você procura uma solução na tecnologia. É quando você fica sabendo sobre a API de conversão de texto em fala (TTS) da OpenAI.
No restante deste tutorial, abordaremos a API TTS da OpenAI, ou seja, seus principais recursos, como começar, personalização e casos de uso no mundo real.
A conversão de texto em fala (TTS) é um tipo de tecnologia assistiva usada para converter a linguagem natural, fornecida em formato de texto, em fala. Ou seja, os sistemas de conversão de texto em fala pegam palavras escritas em um computador (ou em qualquer outro dispositivo digital) e leem o texto em voz alta.
A API TTS da OpenAI é um ponto de extremidade que permite que os usuários interajam com seu modelo de IA TTS que converte texto em linguagem falada com som natural. O modelo tem duas variações:
O endpoint vem pré-construído com seis vozes e, de acordo com a documentação do OpenAI TTS, pode ser usado para:
No entanto, é importante observar que as Políticas de Uso da OpenAI exigem que os usuários divulguem claramente aos usuários finais que a voz TTS que eles ouvem é gerada por IA e não por uma voz humana.
Vamos ver como você pode começar a usar a API Text-to-Speech da OpenAI, abordando os pré-requisitos e as etapas que você precisa seguir:
Uma vez conectado à sua conta OpenAI, você será direcionado para a tela inicial. A partir daqui, navegue até o logotipo da OpenAI no canto superior esquerdo da página para alternar a barra lateral.
Selecione "Chaves de API".
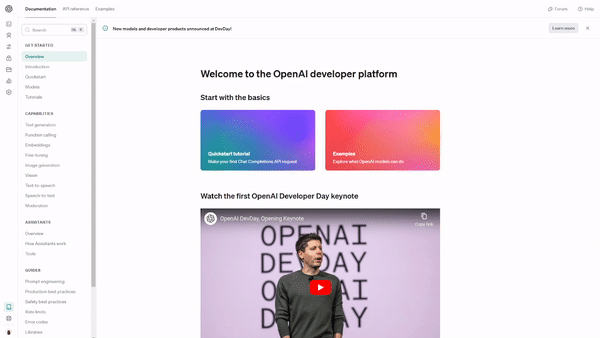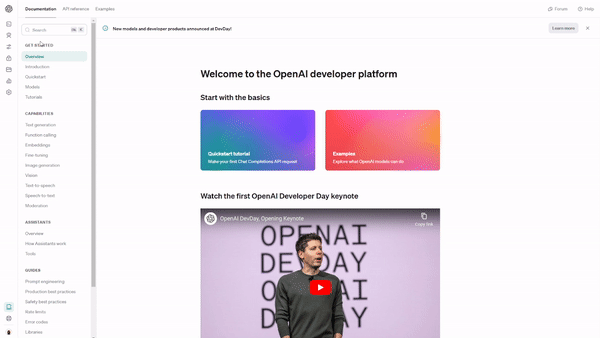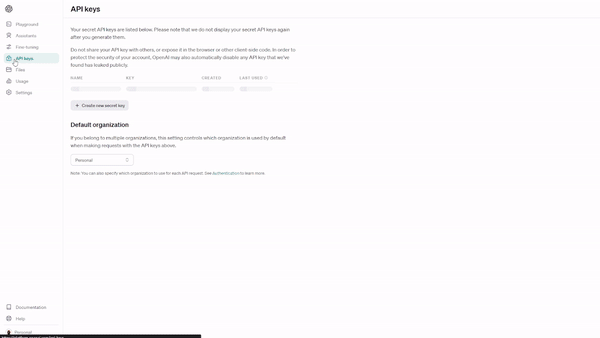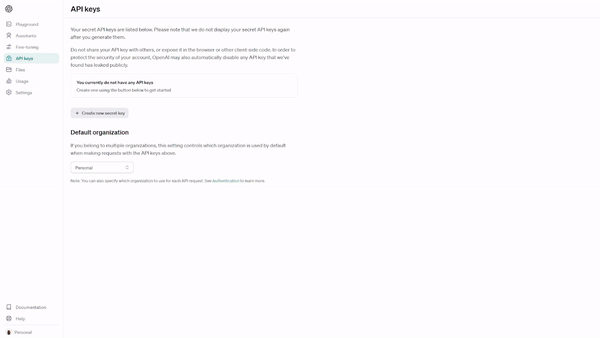
Selecione "Create new secret key" (Criar nova chave secreta ) e dê um nome à sua chave de API - chamamos a nossa de "tts-example".
Quando você criar sua chave de API, será gerada uma chave secreta. Não se esqueça de guardar a chave em um local seguro e protegido.
Agora que você já tem a chave, está pronto para começar!
Um ambiente virtual é usado para criar um contêiner ou ambiente isolado no qual as dependências relacionadas ao Python são instaladas para um projeto específico. É possível trabalhar com muitas versões diferentes do Python com seus vários pacotes.
Aprofundar o assunto dos ambientes virtuais está além do escopo deste artigo. Confira o tutorial Ambiente virtual em Python para saber mais sobre como criar um.
Há três entradas principais que o ponto de extremidade de fala recebe:
Na documentação de conversão de texto em fala da OpenAI, há um exemplo de solicitação; portanto, não precisamos reinventar a roda.
Veja a seguir um exemplo de solicitação:
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)Da forma como está, o código não será executado.
O motivo pelo qual ele não será executado é que não passamos a chave de API que geramos na etapa 1 para nosso cliente OpenAI...
A maneira mais fácil de resolver esse problema é adicionar um parâmetro api_key no qual podemos passar nossa chave secreta para o objeto OpenAI().
Por exemplo:
client = OpenAI(api_key="secret key goes here") Fazer isso é uma prática ruim em Python.
Em vez disso, usaremos o dotenv para ler a chave secreta de um arquivo .env.
A primeira coisa que você deve fazer é instalar o dotenv em seu ambiente virtual. Execute esse comando em seu ambiente virtual:
pip install python-dotenvAgora que o dotenv está instalado, podemos criar um arquivo .env, que contém pares de valores-chave, e definir os valores como variáveis de ambiente.
Isso nos permite ocultar nossa chave secreta, mesmo que o código seja compartilhado publicamente.
Em primeiro lugar, devemos criar um arquivo .env e inserir o seguinte:
SECRET_KEY = "insert your secret key token here" Em nosso arquivo main.py, agora podemos chamar nossas variáveis de ambiente usando dotenv.
Veja a seguir a aparência do código.
import os
from pathlib import Path
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
SECRET_KEY = os.getenv("SECRET_KEY")
client = OpenAI(api_key=SECRET_KEY)
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)Agora o código é executado.
O comportamento padrão do código é gerar um arquivo MP3 do áudio falado. Se preferir um formato de arquivo diferente, você pode configurar a saída para qualquer um dos formatos suportados.
Há muitas vozes e sotaques diferentes no mundo.
Embora seja impossível capturar cada uma delas, o TTS da OpenAI tentou refletir o mundo diversificado em que vivemos integrando seis vozes exclusivas incorporadas à API:
Eles podem transmitir personalidades diferentes, ou você pode usá-los de acordo com sua preferência. Tudo o que você precisa fazer é definir o endereço voice que deseja usar usando o parâmetro de voz no objeto do cliente.
response = client.audio.speech.create(
model="tts-1",
voice="alloy", # Update this to change voice
input="Today is a wonderful day to build something people love!"
)Consulte a documentação da API de conversão de texto em fala da OpenAI para saber mais sobre as vozes disponíveis.
Você também pode alterar o formato de saída.
A resposta padrão da API é um arquivo MP3 com o texto convertido. No entanto, a OpenAI oferece uma variedade de outros formatos para atender às suas necessidades e preferências. Por exemplo:
TLDR: a escolha da saída selecionada pode afetar a qualidade do áudio, o tamanho do arquivo e a compatibilidade do arquivo com vários dispositivos e aplicativos.
Em termos de suporte a idiomas, o modelo de conversão de texto em fala segue o modelo Whisper usado para conversão de texto em fala; as vozes são otimizadas para o inglês, mas têm suporte para vários outros idiomas.
Agora que sabemos como configurar a API TTS, vamos dar uma olhada em alguns exemplos de como você pode usá-la.
Digamos que você tenha escrito um livro ou uma publicação de blog e queira expandir seu alcance para um público mais amplo convertendo-o em áudio. Se você fizesse as coisas à moda antiga, teria que encontrar um narrador (ou narrar você mesmo), o que pode ser um processo longo.
A API OpenAI TTS pode ser usada para encurtar esse processo; tudo o que você deve fazer é passar o documento de texto para a API, e ela o converterá em fala.
Em vez de dar aulas em grupo, os professores de idiomas podem usar a API de conversão de texto em fala da OpenAI para criar aulas personalizadas para alunos que usam vários idiomas e dialetos. Apesar de as vozes serem otimizadas para o idioma inglês, a API ainda pode ser usada para gerar conteúdo de áudio em vários idiomas.
A API OpenAI TTS pode ser usada para criar vozes de IA que soam mais realistas e expressivas do que os sistemas TTS tradicionais. Os desenvolvedores de videogames podem aproveitar esse recurso e aplicá-lo aos personagens para tornar a experiência mais imersiva para os jogadores.
Outro caso de uso pode ser a criação de assistentes virtuais e chatbots que sejam mais envolventes do que os tradicionais existentes.
Os limites de taxa da API OpenAI TTS começam em 50 solicitações por minuto (RPM) para contas pagas, e o tamanho máximo de entrada é de 4096 caracteres, o que equivale a aproximadamente 5 minutos de áudio na velocidade padrão.
Com relação aos modelos TTS, os preços são os seguintes:
Se estiver procurando uma maneira econômica de integrar a API TTS em um projeto pequeno, talvez seja melhor optar pelo modelo TTS padrão. O modelo TTS HD é um pouco mais caro, mas oferece áudio de alta definição, o que é ideal quando a qualidade do seu áudio é fundamental - saiba mais sobre os preços dos modelos de áudio da OpenAI.
A API de conversão de texto em fala da OpenAI é um ponto de extremidade para os usuários gerarem áudio falado de alta qualidade a partir de texto. Ele vem com seis vozes integradas, e os usuários podem selecionar um dos dois modelos, TTS-1 e TTS-1-HD, dependendo do caso de uso; o modelo TTS-1 é otimizado para conversão de texto em fala em tempo real, enquanto o TTS-1-HD é otimizado para qualidade.
Nesta postagem do blog, abordamos o assunto:
Confira estes recursos interessantes para continuar seu aprendizado:
Comece sua jornada de IA hoje mesmo!
Curso
Curso
Curso
blog
Richie Cotton
8 min
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Matt Crabtree



