
Cours
Comprendre ChatGPT
1 h
424.8K
Imaginez que vous ayez passé des heures à rédiger un contenu.
Vous êtes satisfait du produit final et vous le présentez au public.
Après un certain temps dans le domaine public, vous vous rendez compte que vous vous privez d'un vaste public, car de nombreuses personnes ne pensent pas avoir le temps de s'asseoir et de lire votre travail.
Vous envisagez de raconter le contenu vous-même, mais le temps ne joue pas en votre faveur. Vous flirtez avec l'idée d'engager un narrateur, mais les devis que vous avez reçus dépassent largement votre budget, et le temps nécessaire pour trouver quelqu'un avec la "bonne" voix est également un fardeau.
Comme le veut la tradition du 21e siècle, vous vous tournez vers la technologie pour trouver une solution. C'est alors que vous découvrez l'API Text-to-Speech (TTS) d'OpenAI.
Dans la suite de ce tutoriel, nous aborderons l'API TTS d'OpenAI, à savoir ses principales fonctionnalités, la manière de démarrer, la personnalisation et les cas d'utilisation réels.
La synthèse vocale est un type de technologie d'assistance utilisé pour convertir le langage naturel, fourni sous forme de texte, en parole. Les systèmes de synthèse vocale prennent des mots écrits sur un ordinateur (ou tout autre appareil numérique) et les lisent à haute voix.
L'API TTS d'OpenAI est un point d'accès qui permet aux utilisateurs d'interagir avec leur modèle d'IA TTS qui convertit le texte en langage parlé à consonance naturelle. Le modèle se décline en deux variantes :
Le point d'arrivée est livré avec six voix et, selon la documentation OpenAI TTS, il peut être utilisé pour :
Toutefois, il est important de noter que les politiques d'utilisation de l'OpenAI exigent des utilisateurs qu'ils indiquent clairement aux utilisateurs finaux que la voix TTS qu'ils entendent est générée par l'IA et n'est pas une voix humaine.
Voyons comment vous pouvez commencer à utiliser l'API de synthèse vocale OpenAI, en couvrant les conditions préalables et les étapes que vous devez suivre :
Une fois connecté à votre compte OpenAI, vous serez dirigé vers l'écran d'accueil. À partir de là, naviguez vers le logo OpenAI dans le coin supérieur gauche de la page pour faire basculer la barre latérale.
Sélectionnez "Clés API".
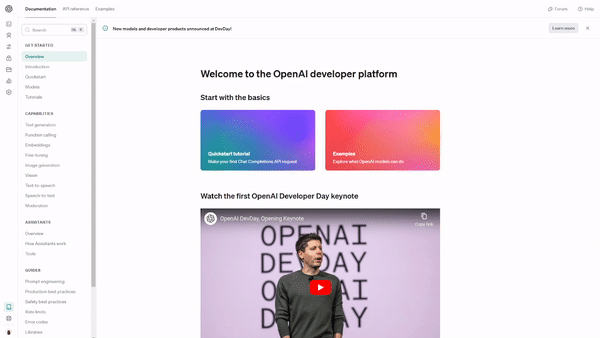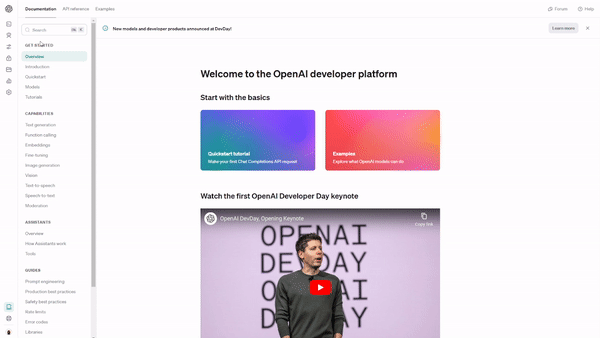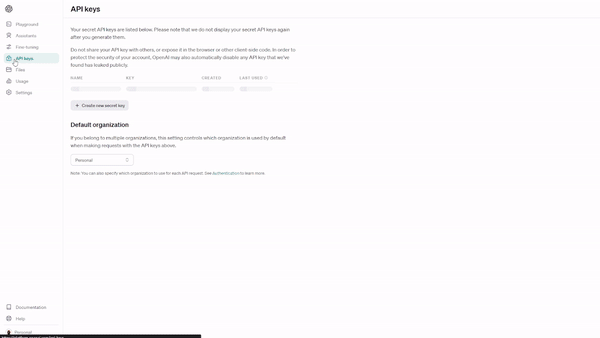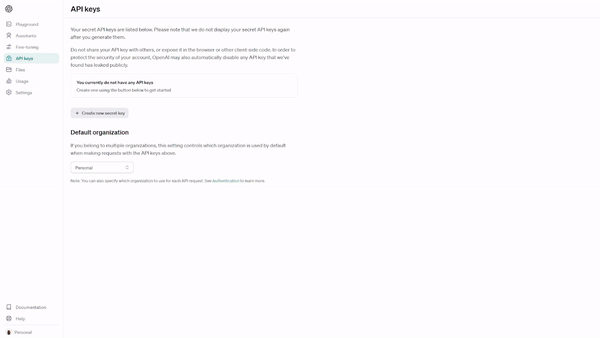
Sélectionnez "Create new secret key" et donnez un nom à votre clé API - nous avons nommé la nôtre "tts-example".
Lorsque vous créez votre clé API, une clé secrète est générée. Veillez à conserver la clé dans un endroit sûr.
Maintenant que vous avez la clé, vous êtes prêt à commencer !
Un environnement virtuel est utilisé pour créer un conteneur ou un environnement isolé dans lequel les dépendances liées à Python sont installées pour un projet spécifique. On peut travailler avec de nombreuses versions différentes de Python avec ses différents paquets.
L'approfondissement des environnements virtuels dépasse le cadre de cet article. Consultez le didacticiel sur l 'environnement virtuel en Python pour en savoir plus sur la création d'un tel environnement.
Le point d'accès à la parole prend en compte trois éléments clés :
La documentation d'OpenAI sur la synthèse vocale contient un exemple de demande ; nous n'avons donc pas à réinventer la roue.
Voici un exemple de demande :
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)Dans l'état actuel des choses, le code ne s'exécute pas.
La raison pour laquelle il ne fonctionne pas est que nous n'avons pas transmis la clé API que nous avons générée à l'étape 1 à notre client OpenAI...
La façon la plus simple de résoudre ce problème est d'ajouter un paramètre api_key où nous pouvons transmettre notre clé secrète à l'objet OpenAI().
Par exemple :
client = OpenAI(api_key="secret key goes here") C'est une mauvaise pratique en Python.
Au lieu de cela, nous utiliserons dotenv pour lire la clé secrète à partir d'un fichier .env.
La première chose à faire est d'installer dotenv dans votre environnement virtuel. Exécutez cette commande à partir de votre environnement virtuel :
pip install python-dotenvMaintenant que dotenv est installé, nous pouvons créer un fichier .env, qui contient des paires clé-valeur, et définir les valeurs comme variables d'environnement.
Cela nous permet de dissimuler notre clé secrète, même si le code est partagé publiquement.
Tout d'abord, nous devons créer un fichier .env et y insérer ce qui suit :
SECRET_KEY = "insert your secret key token here" Dans notre fichier main.py, nous pouvons maintenant appeler nos variables d'environnement en utilisant dotenv.
Voici à quoi ressemble le code.
import os
from pathlib import Path
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
SECRET_KEY = os.getenv("SECRET_KEY")
client = OpenAI(api_key=SECRET_KEY)
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)Le code s'exécute maintenant.
Le comportement par défaut du code est de produire un fichier MP3 de l'audio parlé. Si vous préférez un autre format de fichier, vous pouvez configurer la sortie dans l'un des formats pris en charge.
Il existe des tonnes de voix et d'accents différents dans le monde.
Bien qu'il soit impossible de capturer chacune d'entre elles, le système TTS d'OpenAI a tenté de refléter la diversité du monde dans lequel nous vivons en intégrant six voix uniques dans l'API :
Ceux-ci peuvent véhiculer différentes personnalités, ou vous pouvez les utiliser en fonction de vos préférences. Il vous suffit de définir le site voice que vous souhaitez utiliser en utilisant le paramètre vocal dans l'objet client.
response = client.audio.speech.create(
model="tts-1",
voice="alloy", # Update this to change voice
input="Today is a wonderful day to build something people love!"
)Consultez la documentation de l'API de synthèse vocale OpenAI pour en savoir plus sur les voix disponibles.
Vous pouvez également modifier le format de sortie.
La réponse par défaut de l'API est un fichier MP3 de votre texte converti. Cependant, OpenAI fournit une gamme d'autres formats pour répondre à vos besoins et préférences. Par exemple :
TLDR : le choix de la sortie que vous sélectionnez peut avoir un impact sur la qualité audio, la taille du fichier et la compatibilité du fichier avec différents appareils et applications.
En ce qui concerne la prise en charge des langues, le modèle de synthèse vocale suit le modèle Whisper utilisé pour la synthèse vocale ; les voix sont optimisées pour l'anglais mais sont prises en charge dans plusieurs autres langues.
Maintenant que nous savons comment configurer l'API TTS, voyons quelques exemples d'utilisation.
Imaginons que vous ayez écrit un livre ou un article de blog et que vous souhaitiez l'étendre à un public plus large en le convertissant en format audio. Si vous procédiez à l'ancienne, vous devriez trouver un narrateur (ou le faire vous-même), ce qui peut prendre beaucoup de temps.
L'API OpenAI TTS peut être utilisée pour raccourcir ce processus ; tout ce que vous avez à faire est de transmettre le document texte à l'API, qui le convertira en parole.
Au lieu de donner des cours collectifs, les professeurs de langues peuvent utiliser l'API de synthèse vocale d'OpenAI pour créer des cours personnalisés pour les élèves utilisant différentes langues et dialectes. Bien que les voix soient optimisées pour la langue anglaise, l'API peut toujours être utilisée pour générer du contenu audio dans plusieurs langues.
L'API OpenAI TTS peut être utilisée pour créer des voix d'IA plus réalistes et plus expressives que les systèmes TTS traditionnels. Les développeurs de jeux vidéo peuvent exploiter cette capacité et l'appliquer aux personnages afin de rendre l'expérience plus immersive pour les joueurs.
Un autre cas d'utilisation pourrait être la création d'assistants virtuels et de chatbots plus attrayants que les assistants traditionnels existants.
Les limites de débit pour l'API OpenAI TTS commencent à 50 requêtes par minute (RPM) pour les comptes payants, et la taille maximale d'entrée est de 4096 caractères - ce qui équivaut à environ 5 minutes d'audio à la vitesse par défaut.
En ce qui concerne les modèles TTS, les prix sont les suivants :
Si vous cherchez un moyen économique d'intégrer l'API TTS dans un petit projet, il est préférable d'opter pour le modèle TTS standard. Le modèle TTS HD est légèrement plus cher mais offre un son haute définition, ce qui est idéal lorsque la qualité de votre son est primordiale - en savoir plus sur les prix des modèles audio d'OpenAI.
L'API de synthèse vocale d'OpenAI est un point d'accès permettant aux utilisateurs de générer un son de haute qualité à partir d'un texte. Le modèle TTS-1 est optimisé pour la synthèse vocale en temps réel, tandis que le modèle TTS-1-HD est optimisé pour la qualité.
Dans cet article de blog, nous avons abordé les sujets suivants :
Consultez ces ressources intéressantes pour poursuivre votre apprentissage :
Commencez dès aujourd'hui votre voyage dans l'IA !
Cours
Cours
Cours